序列化模块:json模块 / pickle模块
【一】概要
json 模块和 pickle 模块都是 Python 中用于序列化和反序列化数据的工具,但它们有一些重要的区别:
- 可读性和可编辑性:
json生成的数据是以文本形式表示的,具有良好的可读性,并且可以手动编辑。pickle生成的数据是二进制格式的,不具有人类可读性,但可以包含更多种类的 Python 对象。
- 跨语言支持:
- JSON 是一种通用的数据交换格式,支持多种编程语言,不仅限于 Python。
pickle是 Python 特有的序列化格式,不适用于与其他语言交换数据。
- 安全性:
- JSON 是一种文本格式,通常被认为相对安全,因为它可以通过人类读取和编辑,减少了潜在的安全风险。
pickle生成的二进制数据包含了执行代码的信息,因此在不受信任的环境中反序列化pickle数据可能存在安全风险。
- 支持的对象类型:
json可以序列化基本的数据类型(字典、列表、字符串等)以及它们的组合。不支持一些特殊的 Python 对象,如自定义类的实例。pickle可以序列化几乎所有 Python 对象,包括自定义类的实例、函数等,但对于某些特殊对象可能存在限制。
- 使用场景:
json通常用于 Web 开发中的数据传输、配置文件、API 接口等需要与其他语言交互的场景。pickle通常用于本地持久化和 Python 特有的应用场景,例如缓存、保存 Python 对象状态等。
综合考虑这些因素,选择使用 json 还是 pickle 取决于具体的使用场景和需求。如果需要跨语言支持、可读性和编辑性重要,或者在不受信任的环境中使用,推荐使用 json。如果只在 Python 中使用,并且需要序列化复杂的 Python 对象,可以考虑使用 pickle。
【二】常见用法
json
-
json.dump(obj,fp)-
将 Python 对象
obj编码成 JSON 格式的字符串,并将结果写入文件对象fp中。 -
obj是要编码的对象。 -
fp是一个文件对象,用于写入 JSON 数据。 -
其他参数
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
-
-
json.load(fp)- 从文件对象
fp中读取 JSON 格式的数据,解码为 Python 对象。 fp是一个文件对象,包含了 JSON 数据。- 其他参数
json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
- 从文件对象
-
json.dumps(obj)- 将 Python 对象
obj编码成 JSON 格式的字符串。 obj是要编码的对象。- 参数和
json.dump中的参数相似,但不需要文件对象。 json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
- 将 Python 对象
-
json.loads(s)- 从 JSON 格式的字符串
s中解码出 Python 对象。 s是包含 JSON 数据的字符串。- 参数和
json.load中的参数相似。 json.loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
- 从 JSON 格式的字符串
pickle
pickle.dump(obj, file, protocol=None)- 其他参数(obj, file, protocol=None,
*,fix_imports=True,buffer_callback=None) - 将 Python 对象
obj序列化,并将结果写入文件对象file中。 protocol是协议版本号,可选,默认为最高可用版本。fix_imports控制是否尝试导入丢失的模块。buffer_callback可用于设置缓冲回调函数(在某些情况下需要)。
- 其他参数(obj, file, protocol=None,
pickle.load(file)- 其他参数(file,
*,fix_imports=True,encoding='ASCII',errors='strict',buffers=None) - 从文件对象
file中读取序列化的对象,并返回原始对象。 fix_imports控制是否尝试导入丢失的模块。encoding和errors用于指定文本数据的编码和错误处理方式。buffers是一个包含缓冲区的可选参数。
- 其他参数(file,
【三】详解
【1】什么是序列?
- 序列(Sequence): 在计算机科学中,序列是一种数据结构,用于存储按顺序排列的一组元素。这些元素可以是字符、数字、对象等。字符串、列表和元组都是 Python 中常见的序列类型。
【2】什么是序列化?
- 序列化(Serialization): 序列化是将数据结构或对象转换为可以存储或传输的格式的过程。在序列化中,数据被编码成字节流或其他格式,以便在存储到文件、传输到网络或存储在数据库中。序列化的目的是将数据转换为通用格式,使其能够在不同系统或环境中传递和重建。
- 在 Python 中,常见的序列化格式包括 JSON、pickle 等。序列化通常涉及将对象转换为字符串或字节流。
【3】什么是反序列化?
- 反序列化(Deserialization): 反序列化是序列化的逆过程,即将序列化后的数据重新转换为原始的数据结构或对象。这样可以从文件、网络等位置读取数据,并在程序中使用。反序列化的过程是将字节流或其他格式的数据还原为原始的数据结构。
- 在 Python 中,反序列化是通过解析 JSON 字符串、使用 pickle 模块等实现的。反序列化过程的目标是从序列化的数据中还原出原始的对象或数据结构。

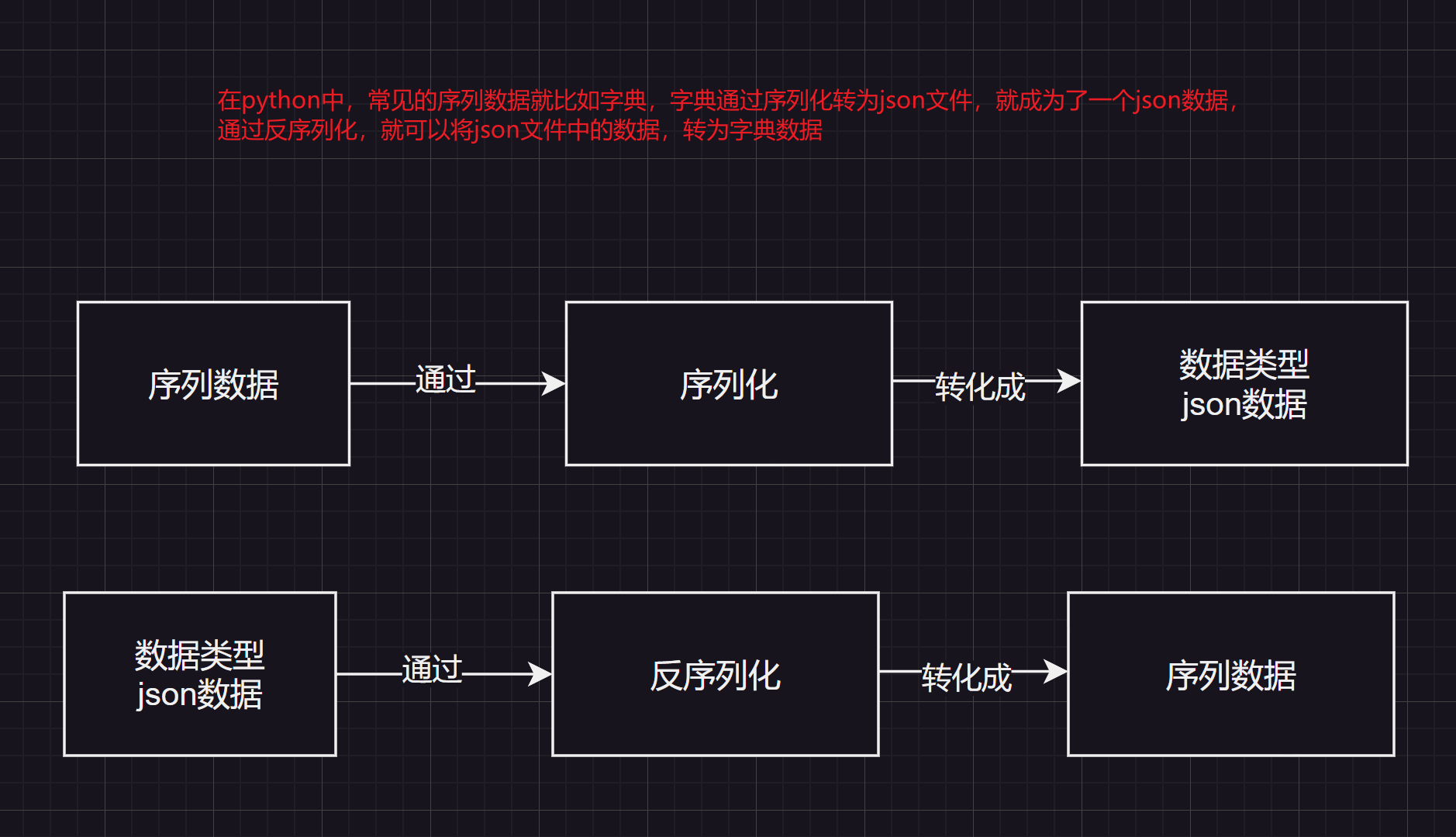
【4】JSON
JSON文件
-
JSON 文件是一种通用的数据交换格式,可以被几乎所有编程语言支持。由于其简洁性和易读性,JSON 成为跨语言数据交换的标准之一。
-
不同编程语言提供了相应的库或模块,用于解析(反序列化)和生成(序列化)JSON 数据。例如:
-
Python: 使用
json模块进行 JSON 数据的序列化和反序列化。 -
JavaScript: 可以使用
JSON.parse()和JSON.stringify()方法来处理 JSON 数据。 -
Java: 提供了
org.json、Gson等库来处理 JSON 数据。 -
C#: 提供了
Newtonsoft.Json(Json.NET)等库来处理 JSON 数据。 -
Ruby: 提供了
json标准库来处理 JSON 数据。 -
PHP: 提供了
json_encode()和json_decode()函数来处理 JSON 数据。
-
JSON 文件的基本结构:
- 对象(Object): 由花括号
{}包裹,包含键值对,每个键值对之间用逗号分隔。
{
"name": "User",
"age": 21,
"city": "Shanghai"
}
- 数组(Array): 由方括号
[]包裹,包含一组数值、字符串、对象等,每个元素之间用逗号分隔。
[
"apple",
"orange",
"banana"
]
- 值(Value): 可以是字符串、数字、布尔值、对象、数组、
null。
{
"name": "User",
"age": 21,
"isStudent": false,
"grades": [95, 85, 92],
"address": {
"street": "123 Main St",
"city": "Anytown"
},
"other": null
}
-
JSON文件不可以出现两个对象(object)
# 正确的情况
{
"user001": {
"age": 20,
"gender": "male"
},
"user002": {
"age": 18,
"gender": "female"
}
}
# 错误的情况
{
"user001": {
"age": 20,
"gender": "male"
}
}
'''此处就出现了两个对象'''
{
"user002": {
"age": 18,
"gender": "female"
}
}
# 错误信息 "JSON standard allows only one top-level value"
-
json文件中只有双引号作为引号
- 当使用
json.dump上传的字典数据将自动将引号转为双引号 - 如果手动输入json数据时,输入了单引号,将会有错误信息提示
- JSON standard allows only double quoted string as property key
JSON standard does not allow single quoted strings
- JSON standard allows only double quoted string as property key
- 当使用
import json
# 写入的字典数据是单引号
python_obj = {'user': '001', 'age': 18, 'hobby': []}
with open("01.json", "w", encoding='utf-8') as fp:
json.dump(obj=python_obj, fp=fp)
# 写入json文件后将自动转为双引号
{"user": "001", "age": 18, "hobby": []}
- 当使用
json.load()方法从 JSON 文件中加载数据时,Python 的json模块会灵活地接受 JSON 文件中的字符串,无论是单引号还是双引号。
import json
# 有双引号,有单引号
python_obj = {"user": '001', 'age': 18, 'hobby': []}
with open("01.json", "w", encoding='utf-8') as fp:
json.dump(obj=python_obj, fp=fp)
with open('01.json', 'r', encoding='utf8') as fp:
data = json.load(fp)
print(data)
# {'user': '001', 'age': 18, 'hobby': []}
【5】json.dump
import json
data_dict = {'user': 1, 'age': 20, 'hobby': []}
with open('01.json', 'w', encoding='utf8') as fp:
json.dump(obj=data_dict, fp=fp, ensure_ascii=False)
# 01.json
{
"user": 1,
"age": 20,
"hobby": []
}
【6】json.load
with open('01.json', 'r', encoding='utf8') as fp:
data = json.load(fp)
print(data, type(data))
# {'user': 1, 'age': 20, 'hobby': []} <class 'dict'>
【7】json.dumps
- 将Python对象转换为json字符串
- json转换完的字符串类型的字典中的字符串是由
""表示的
python_dict = {'user': 1, 'age': 20, 'hobby': []}
print(type(python_dict)) # <class 'dict'>
json_txt = json.dumps(python_dict)
print(json_txt, type(json_txt))
# {"user": 1, "age": 20, "hobby": []}
# <class 'str'>
【8】json.loads
- 将json字符串转换为Python对象
json_txt = '''
{
"user": 1,
"age": 20,
"hobby": []
}
'''
print(type(json_txt)) # <class 'str'>
python_dict = json.loads(json_txt)
print(python_dict, '\n', type(python_dict))
# {'user': 1, 'age': 20, 'hobby': []}
# <class 'dict'>
【9】其他参数
Serialize obj to a JSON formatted str.(字符串表示的json对象)
Skipkeys:
默认值是False
如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None)设置为False时,就会报TypeError的错误。
此时设置成True,则会跳过这类key
ensure_ascii:
当它为True的时候
所有非ASCII码字符显示为\uXXXX序列
只需在dump时将ensure_ascii设置为False即可
此时存入json的中文即可正常显示。
If check_circular is false, then the circular reference check for container types will be skipped and a circular reference will result in an OverflowError (or worse).
If allow_nan is false, then it will be a ValueError to serialize out of range float values (nan, inf, -inf) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (NaN, Infinity, -Infinity).
indent:
应该是一个非负的整型
如果是0就是顶格分行显示
如果为空就是一行最紧凑显示
否则会换行且按照indent的数值显示前面的空白分行显示
这样打印出来的json数据也叫pretty-printed json
separators:
分隔符
实际上是(item_separator, dict_separator)的一个元组
默认的就是(‘,’,’:’);
这表示dictionary内keys之间用“,”隔开
而KEY和value之间用“:”隔开。
default(obj) is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError.
sort_keys:
将数据根据keys的值进行排序。
To use a custom JSONEncoder subclass (e.g. one that overrides the .default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.
ensure_ascii = False:
- 在 Python 的
json模块中,ensure_ascii是json.dump()和json.dumps()函数的一个可选参数。它是一个布尔值,默认为True。 - 当
ensure_ascii设置为True时,表示确保生成的 JSON 数据中的所有非 ASCII 字符都会被转义为 Unicode 转义序列。这样做是为了确保生成的 JSON 字符串是纯 ASCII 的,适用于大多数场景,尤其是在处理传输或存储时。 - 当
ensure_ascii设置为False时,表示允许非 ASCII 字符直接保留在生成的 JSON 字符串中,而不进行转义。这在一些特殊需求的情况下可能会更有用,但要注意,生成的 JSON 字符串可能包含非 ASCII 字符,可能在某些情况下导致问题。- 当
ensure_ascii为True时,中文字符会以\uXXXX的形式进行转义,其中XXXX是相应中文字符的 Unicode 编码。这样做是为了确保生成的 JSON 数据是纯 ASCII 的。
- 当
import json
python_obj = {"user": '月亮', 'age': 18, 'hobby': []}
with open("01.json", "w", encoding='utf-8') as fp:
json.dump(obj=python_obj, fp=fp)
# \u6708\u4eae
{"user": "\u6708\u4eae", "age": 18, "hobby": []}
# 指定ensure_ascii 参数
import json
python_obj = {"user": '月亮', 'age': 18, 'hobby': []}
with open("01.json", "w", encoding='utf-8') as fp:
json.dump(obj=python_obj, fp=fp, ensure_ascii=False)
{"user": "月亮", "age": 18, "hobby": []}