前言 本文提出了一个分层的数据关联策略来寻找低分检测框中的真实目标,这缓解了目标丢失和轨迹不连续的问题。这个简单通用的数据关联策略在2D和3D设置下都表现良好。另外,由于在3D场景中预测对象在世界坐标系中的速度比较容易,本文提出了一种辅助的运动预测策略,将检测到的速度与卡尔曼滤波器结合起来,以解决运动突变和短期消失的问题。
ByteTrackV2在nuScenes 3D MOT基准测试中相机(56.4\% AMOTA)和激光雷达(70.1\% AMOTA)模式下都位居榜首。此外,它是无参数化的,可以与各种检测器结合,所以在实际应用中更具竞争力。
本文转载自深蓝AI
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
原文链接:https://arxiv.org/abs/2303.15334
源代码:https://github.com/ifzhang/ByteTrack-V2
1. 框架构建
二维多目标跟踪和三维多目标跟踪本质上是一样的。这两个任务都要定位对象,并获得对象在不同帧之间对应关系。但是,它们通常由不同领域的研究人员独立解决,因为输入数据来自不同的模式。二维MOT基于图像平面,图像信息在对象对应中起着基本作用。基于外观的跟踪器从图像中提取对象外观特征,然后计算特征距离作为对应关系。三维MOT通常在世界坐标系统中执行。更容易通过空间相似性区分不同对象,如三维IoU或点距离。下图显示了二维MOT和三维MOT的可视化结果。
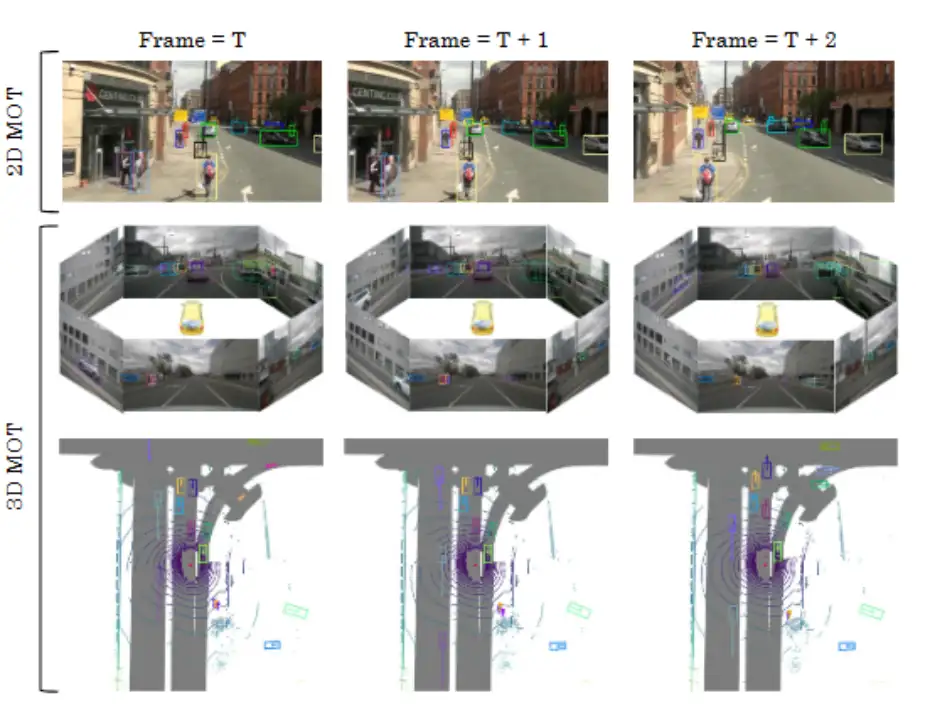
本文利用三个模块解决二维和三维MOT任务,分别是检测、运动预测和数据关联。首先,对象检测器生成二维/三维检测框和分数。在开始帧中,检测到的对象被初始化为轨迹。然后,卡尔曼滤波器等运动预测器预测以下一帧中轨迹的位置。运动预测在图像平面和三维空间都容易实现。最后,根据一些空间相似性,检测框与轨迹的预测位置相关联。检测是整个MOT框架的基础。由于视频中的复杂场景,检测器容易产生不完美的预测。高分数的检测框通常包含更多真阳性,而低分数的检测框则不然。但是,简单地消除所有低分数框是次优的,因为低分数检测框有时也会指示对象的存在,例如被遮挡的对象。滤除这些对象会对MOT造成不可逆转的错误,导致明显的丢失检测和破碎轨迹,如下图b所示。

为了解决消除低分数框引起的目标丢失和轨迹不连续问题,本文提出了一个检测驱动的分层数据关联策略。它充分利用从高分到低分的所有检测框。我们发现,检测框与轨迹之间的运动相似度为低分数检测框中的真实对象提供了强有力的判别依据。我们首先根据运动相似度将高分数检测框与轨迹相关联。与CenterTrack类似,我们采用卡尔曼滤波器预测轨迹在新帧中的位置。预测框和检测框之间的二维或三维IoU即为相似度。然后,我们对剩余的轨迹和低分数检测框进行第二次关联,使用相同的运动相似度来恢复真实对象并消除背景。关联结果如上图c所示。
2. 算法精解
作者在一个简单统一的框架中解决二维和三维MOT问题。它包含三个部分:目标检测、运动预测和数据关联。
2.1 问题公式化
多目标跟踪。多目标跟踪。多目标跟踪的目标是实现在视频中估计多个对象轨迹。假设我们要 在一个视频中获得 个轨迹 。每个轨迹 , 包含一个对象在一段时间内的位置信息, 即从帧 到帧 , 其中对象出 现。在二维 MOT 中, 对象 在帧 中的位置可以表示为 , , 其中 是图像平面中二维对象边界框的左上和右下 坐标。在三维 MOT 中, 跟踪过程通常在三维世界坐标中执行。对象 在帧 的三维 位置可以表示为 , 其中 是对象 中心的三维世界位置, 是对象方向, 是对象尺寸。数据关联。本方案遵循多目标跟踪中流行的跟踪即检测范式, 首先检测单个视频 帧中的对象, 然后将它们在帧之间关联起来, 并随时间形成轨迹。假设我们在帧 有 个检测和 个历史轨迹, 我们的目标是将每个检测分配给视频中具有相同身 份的一个轨迹。令 表示由所有可能关联(或匹配)组成的空间。在多目标跟踪设置 下, 每个检测最多匹配一个轨迹, 每个轨迹最多匹配一个检测。我们将空间 定义 如下:
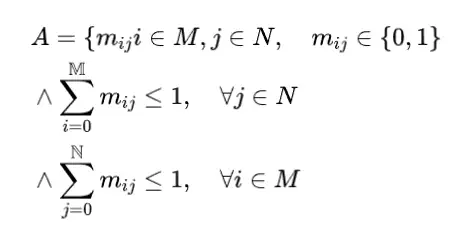
其中 ,
我们在所有检测和轨迹之间计算一个相似性矩阵如下:
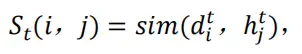
其中相似度可以通过一些空间距离计算, 如 IoU 或 L2 距离。我们的目标是获得最优匹配 ,其中匹配检测和轨迹之间的总相似度(或分数)最高:
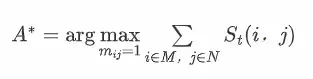
2.2 基础知识
二维目标检测器。本方案采用YOLOX作为二维目标检测器。YOLOX是一个无锚框检测器,配备先进的检测技术,如解耦的头和前沿的标签分配策略SimOTA。它还采用强大的数据增强,如mosaic和mixup来进一步提高检测性能。与其他现代检测器相比,YOLOX在速度和准确率之间实现了优秀的平衡,在实际应用中非常有吸引力。
基于相机的三维目标检测器。本方案遵循多相机三维目标检测设置,它通过在BEV中学习强大的统一表示展示了优势。我们利用PETRv2作为基于相机的三维目标检测器。它建立在PETR之上,将Transformer基础的二维目标检测器DETR扩展到多视图三维,通过将三维坐标的位置信息编码到图像特征中。PETRv2利用前几帧的时间信息来提升检测性能。
基于激光雷达的三维目标检测器。我们采用CenterPoint和TransFusion-L作为基于激光雷达的三维目标检测器。CenterPoint利用关键点检测器找到对象的中心,然后简单地回归其他三维属性。它还在第二阶段使用对象上的额外点特征来细化这些三维属性。TransFusion-L由卷积Backbone和基于Transformer decoder的检测头组成。它从激光雷达点云中预测三维边界框,使用稀疏对象查询集。
基本运动模型。基本运动模型。我们在二维和三维 MOT 中都利用卡尔曼滤波器作为基本运动模型。类似于 DeepSORT, 我们在二维跟踪中定义一个八维状态空间 , , 其中 是二维边界框中心位置、宽高比 (width/height)和边界框高度。 是图像平面中的各向速度。在三维跟踪中, 我们遵循 AB3DMOT 定义一个十维状态空间, 其中 是三维边界框中心位 置, 是对象大小, 是对象方向, 是三维空间中的各向 速度。与 AB3DMOT 不同, 我们在三维世界坐标中定义状态空间, 以消除自运动 的影响。我们直接采用具有恒速运动和线性观测模型的标准卡尔曼滤波器。帧 1中的运动预测过程在二维和三维跟踪中可以表示为:
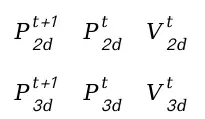
每个轨迹更新后的状态是轨迹和匹配检测(或观测)的加权平均。权重由轨迹和匹配检测的不确定性确定,遵循贝叶斯规则。
2.3 互补三维运动预测
我们提出了一个互补的三维运动预测策略,以解决驾驶场景中的目标突变运动和短期消失问题。具体来说,我们采用检测到的速度进行短期关联,采用卡尔曼滤波器进行长期关联。在三维场景中,现代检测器有能力通过时间建模预测准确的短期速度。卡尔曼滤波器通过基于历史信息的状态更新对长期速度建模。我们通过双向预测策略最大化两种运动模型的优势。我们采用卡尔曼滤波器进行前向预测,采用检测器预测的对象速度进行后向预测。后向预测负责活跃轨迹的短期关联,而前向预测在对象丢失后重新出现时进行长期关联。图4说明了互补运动预测策略。
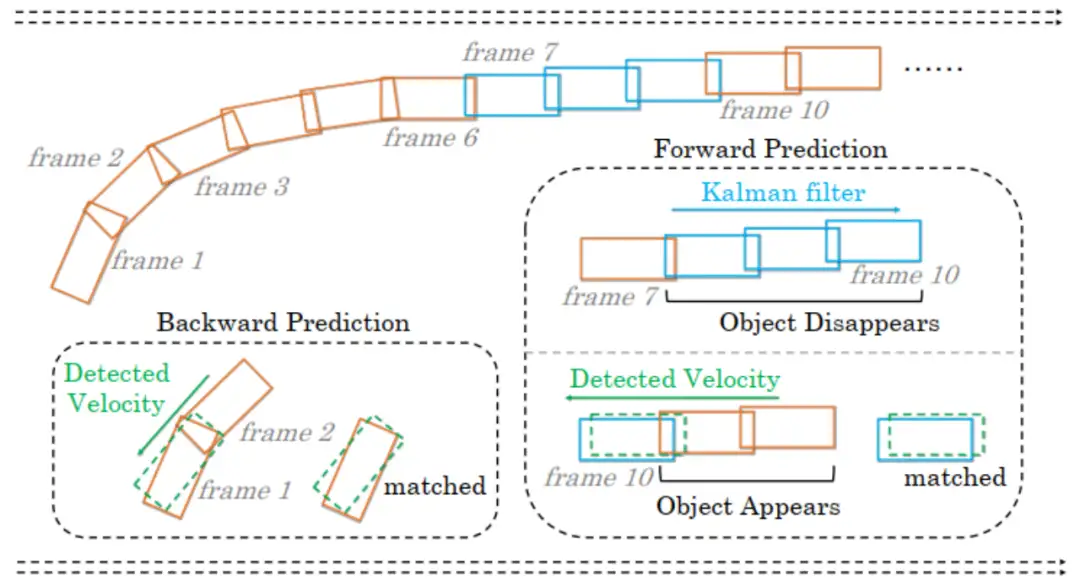
后向预测可以计算如下:
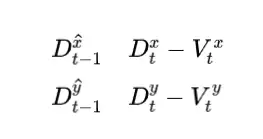
我们按照 3.2 节中描述采用卡尔曼滤波器进行前向预测:
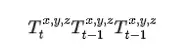
在第一关联中, 相似度在检测结果的后向预测和轨迹之间计算如下:
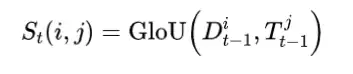
我们采用三维 GloU 作为相似度度量, 以解决检测框和轨迹框之间偶尔不重叠的问 题。我们使用匈牙利算法完成基于的身份分配。关联后,匹配的检测用于按标准卡尔曼滤波器更新规则更新匹配的轨迹 。当一个轨迹丢失时, 也就是没有匹配的检测时, 前向预测策略在对象再次出现时发挥重要作用。算法1中的 第二关联遵循与第一关联相同的过程。我们根据检测得分进一步增强运动预测, 通过自适应更新卡尔曼滤波器中的观测不 确定性矩阵 如下:
我们根据检测得分进一步增强运动预测,通过自适应更新卡尔曼滤波器中的观测不确定性矩阵如下:
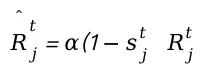
2.4 统一的二维和三维数据关联
我们为二维和三维MOT提出了一个简单有效且统一的数据关联方法。与只保留高分检测框的先前方法不同,我们保留每个检测框,并将它们分为高分和低分检测框。整个检测驱动的分层数据关联策略流程如下图所示。
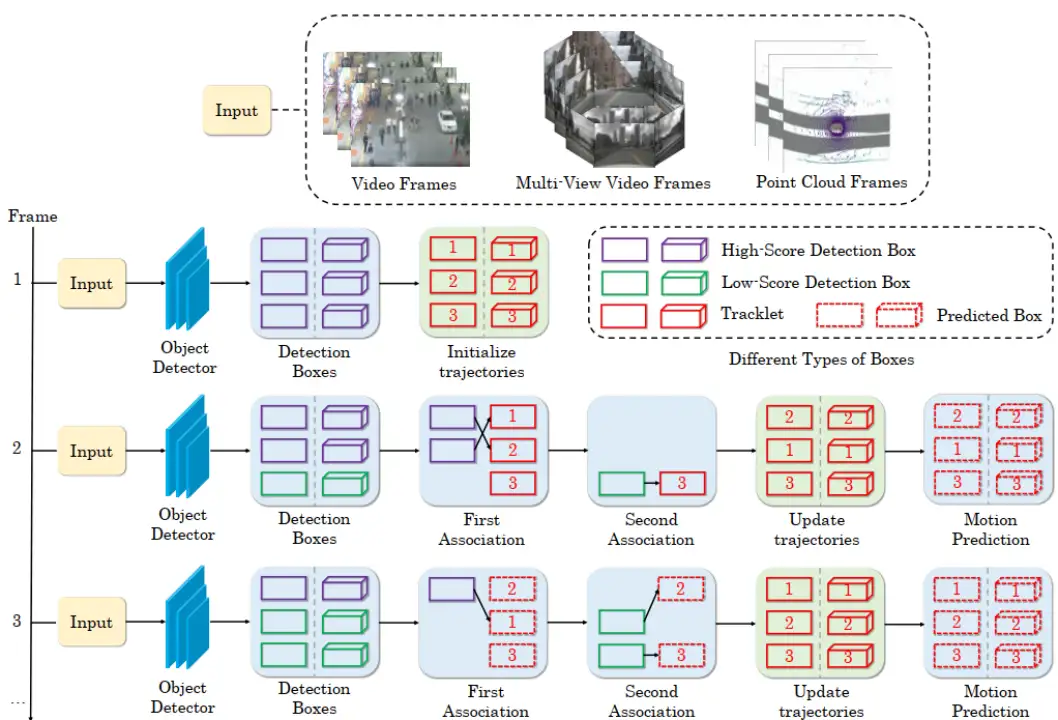
概述。在视频的第一帧中,我们将所有高分检测框初始化为轨迹。在后续帧中,我们首先将高分检测框与所有轨迹(包括丢失的轨迹)相关联。一些轨迹由于不匹配适当的高分检测框而未匹配,这通常发生在遮挡、运动模糊或尺寸变化时。然后,我们将低分检测框和这些未匹配的轨迹关联起来,同时恢复低分检测框中的对象并过滤背景。算法1展示了ByteTrackV2的伪代码。
检测框。对于视频中的每个帧, 我们使用检测器预测检测框和分数。我们根据检 测得分阈值 将所有检测框分为两部分。对于分数高的检测框, 我们将它们放入高分检测框 。对于分数低的检测框, 我们将它们放入低分检测框 。
运动预测。将低分检测框和高分检测框分开后,我们预测当前帧中每个轨迹的新位置。对于二维MOT,我们直接采用卡尔曼滤波器进行运动预测。对于三维MOT,我们利用3.3节中介绍的互补运动预测策略。
高分框关联。第一关联在高分检测框与所有轨迹 (包括丢失轨迹 )之间执行。相似度#1 (见下图) 可以通过检测框 与轨迹的预测框之间的空间距离计算, 如 IoU 或 L2 距离。然后, 我们采用匈牙利算法基于相似度完成匹配。我们保留末匹配的检测在 和末匹配的轨迹在 。

低分框关联。低分框关联。第二关联在第一关联后的剩余轨迹 和低分检测框 之间执行。我们使用相同的运动相似度#2 (见上图) 。我们保留末匹配轨迹 -remain, 仅删 除所有末匹配的低分检测框, 因为我们将它们视为背景。讨论。我们经验发现,当遮挡比例增加时,检测得分会下降。当发生遮挡时,得分首先下降然后上升,因为行人首先被遮挡然后重新出现。这启发我们首先根据运动相似度将高分框与轨迹相关联。如果一个轨迹没有匹配任何高分框,它很可能被遮挡并且检测得分下降。然后,我们将其与低分框关联以跟踪遮挡的目标。对于低分框中的误报,没有轨迹与其匹配。因此,我们将其删除。以上是我们的数据关联算法有效的关键所在。
3.结论
本文提出了ByteTrackV2,这是一个简单的MOT框架,旨在同时解决二维和三维MOT问题。ByteTrackV2结合了目标检测、运动预测和检测驱动的分层数据关联,使其成为MOT的全面解决方案。分层数据关联策略利用检测分数作为强有力的先验知识,在低分检测中识别正确的对象,减少目标丢失和轨迹不连续的问题。另外,本算法提出的在三维MOT中集成运动预测策略有效解决了目标的突变运动和短期消失问题。ByteTrackV2在二维和三维MOT基准测试中都取得了最先进的性能。而且,它具有很强的泛化能力,可以轻松地与不同的二维和三维检测器相结合,不需要任何可学习的参数。我们认为这个简单统一的跟踪框架将在实际应用中取得很好的成绩。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
比Meta「分割一切AI」更全能!港科大版图像分割AI来了:实现更强粒度和语义功能
Meta Segment Anything会让CV没前途吗?
CVPR'2023年AQTC挑战赛第一名解决方案:以功能-交互为中心的时空视觉语言对齐方法
6万字!30个方向130篇 | CVPR 2023 最全 AIGC 论文汇总
ICCV2023 | 当尺度感知调制遇上Transformer,会碰撞出怎样的火花?
新加坡国立大学提出最新优化器:CAME,大模型训练成本降低近一半!
SegNetr来啦 | 超越UNeXit/U-Net/U-Net++/SegNet,精度更高模型更小的UNet家族
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary