试题一 软件架构(架构风格、质量属性)
【问题1】(9分)
在架构评估过程中,质量属性效用树(utility tree)是对系统质量属性进行识别和优先级排序的重要工具。 请将合适的质量属性名称填入图1-1中(1)、(2)空白处,并从题干中的(a)-(i)中选择合适的质量属性描述,填入(3)-(6)空白处,完成该平台的效用树。

【问题2】(16分)
针对该系统的功能,赵工建议采用解释器(interpreter)架构风格,李工建议采用管道过滤器(pipe-and-filter)的架构风格,王工则建议采用隐式调用(implicit invocation)架构风格。请针对平台的核心应用场景,从机器学习流程定义的灵活性和学习算法的可扩展性两个方面对三种架构风格进行对比与分析,并指出该平台更适合采用哪种架构风格。
本题系统中有多个应用场景提到了系统分角色有不同的操作流程与界面,以及在修改扩充系统时,
需要能够在限定时间内快速完成任务。基于这样的情况,我们从两方面进行分析:
解释器:机器学习流程定义的灵活性高,可扩展能力强,
因为解释器风格可以通过自定义流程规则及配套流程解释引擎开发,
做到用户层面的流程完全定义,而不需要修改代码,所以无论是修改已有的业务流程,
还是要扩展不同的角色,创建新角色的流程都非常便利。
管道过滤器:机器学习流程定义的灵活性较低,可扩展能力较弱,
因为管道过滤器是把数据处理职能做成过滤器,把数据传递做成管道,此时如果流程不发生变化,
是可以通过这种方式实现的,但一旦流程变化,或是扩展功能,需要对过滤器进行修改调整,
或是流程在程序层面重建,此时必须修改代码完成任务。
隐式调用:机器学习流程定义的灵活性一般,可扩展能力一般,隐式调用强调的是通过间接方式
进行调用,如采用事件机制,要完成某个动作时先触发事件,事件与相关动作关联,
以提升灵活度,本题中可把角色执行业务的流程用事件触发。这种做法比管道过滤器强,
但弱于完全自定义的解释器。
试题二 系统开发(用例图、顺序图填空、模型对比)

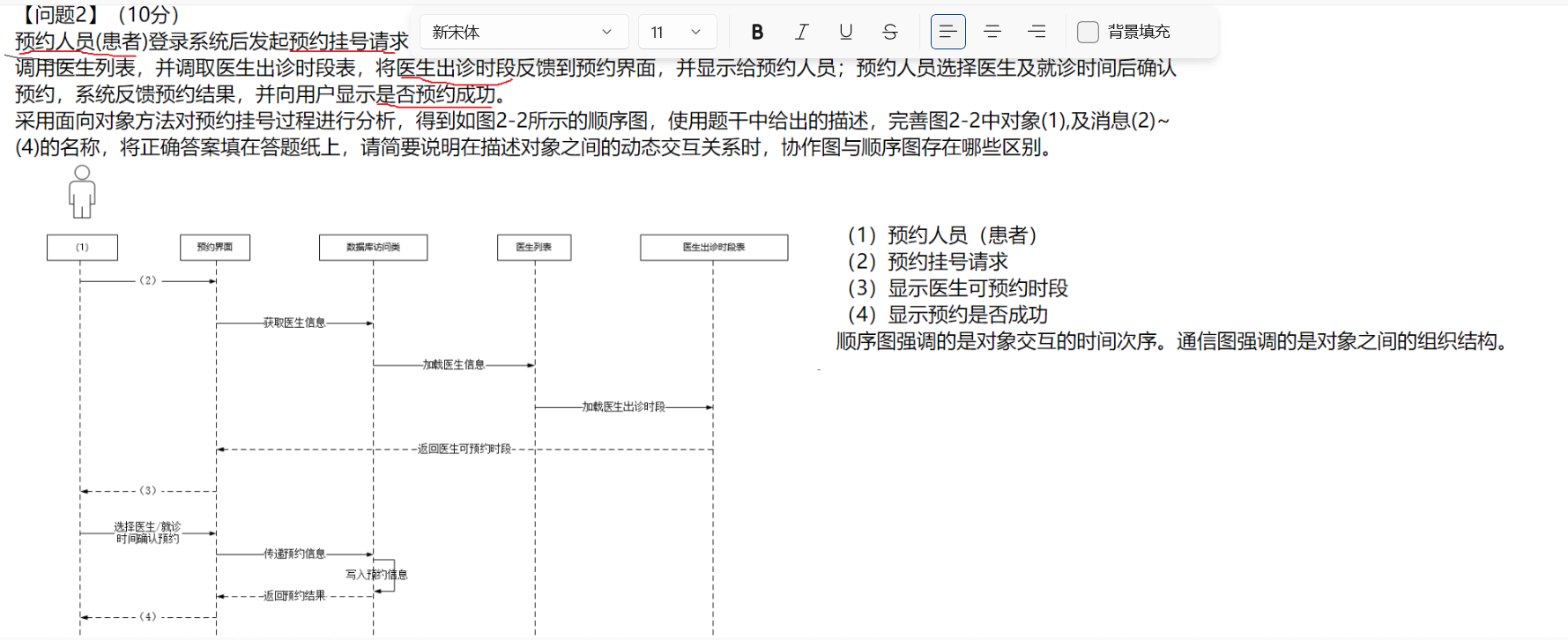
【问题3】(9分)
采用面向对象方法开发软件,通常需要建立对象模型、动态模型和功能模型,请分别介绍这3种模型,并详细说明它们之间的关联关系,针对上述模型,说明哪些模型可用于软件的需求分析?
概念:
对象模型描述了系统的静态结构,一般使用对象图来建模。
对象模型是整个体系中最基础,最核心的部分。
动态模型描述了系统的交互次序,一般使用状态图来建模。
功能模型描述 了系统的数据变换,一般使用数据流图来建模。
相互关系:
对象模型描述了动态模型和功能模型所操作的数据结构,
对象模型中的操作对应于动态模型中事件和功能模型中的函数;
动态模型描述了对象模型的控制结构,告诉我们哪些决策是依赖于对象值,
哪些引起对象的变化,并激活功能;
功能模型描述了由对象模型中操作和动态模型中动作所激活的功能,
而功能模型作用在对象模型说明的数据上,同时还表示了对对象值的约束。
试题三 嵌入式


数据定义:数据定义要反映业务模式的本质,确保数据架构为业务提供全面、一致、完整的
高质量数据。数据定义要划分应用系统边界,明确数据引用关系,定义应用系统间的基础接口。
定义数据模型主要包括:数据概念模型、数据逻辑模型、数据物理模型和数据标准。
数据分布:数据分布是数据系统分布的基础。包含数据业务、数据分析和数据存储。
数据业务是分析业务数据在业务各环节的创建、引用、修改或删除的关系。
数据分析是在单一应用系统中的分析数据结构与应用系统各功能间的引用关系,分析数据在多个系统
间的引用关系。
数据存储包含分析数据集中存储和数据分布存储两种模式,要根据需求选择数据分布策略。
数据管理:数据管理是要制定贯穿数据生命周期的各项管理制度,包括:数据模型与数据标准管理,
数据分布管理,数据质量管理和数据安全管理等制度。确定数据管理组织或岗位。

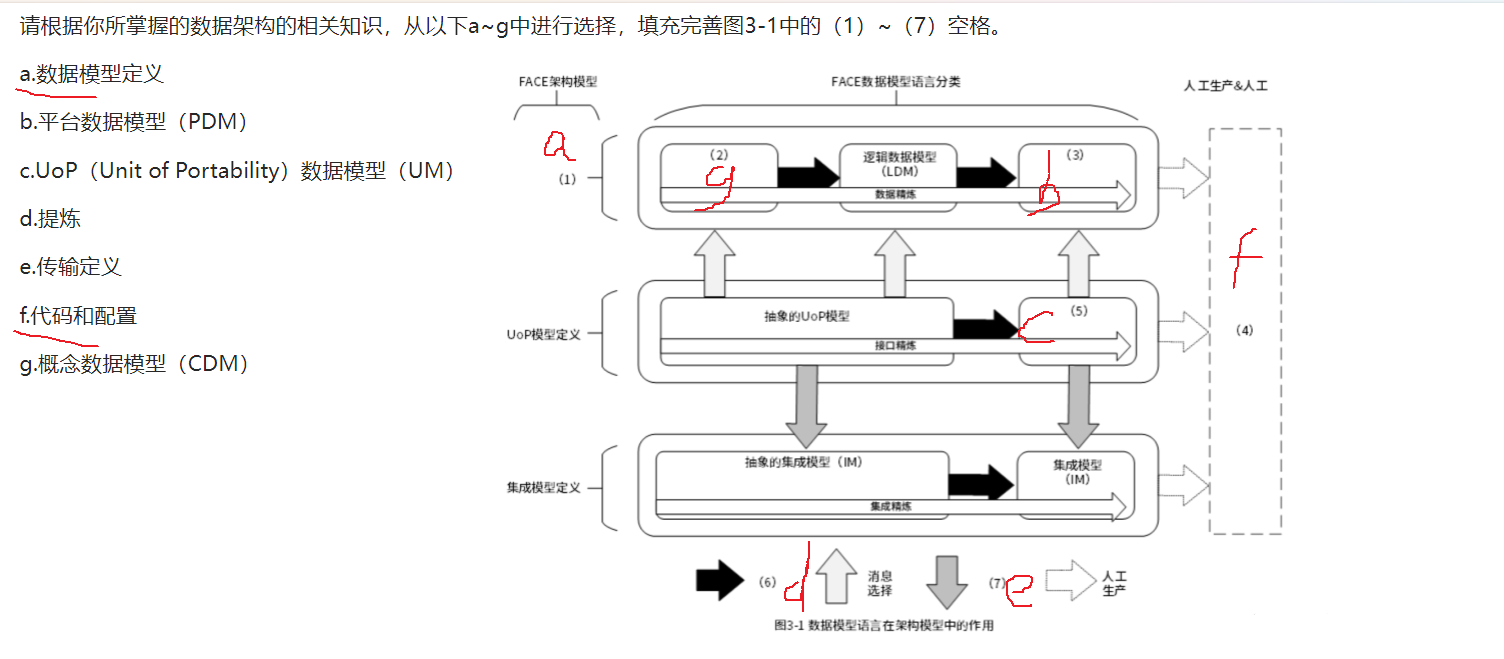
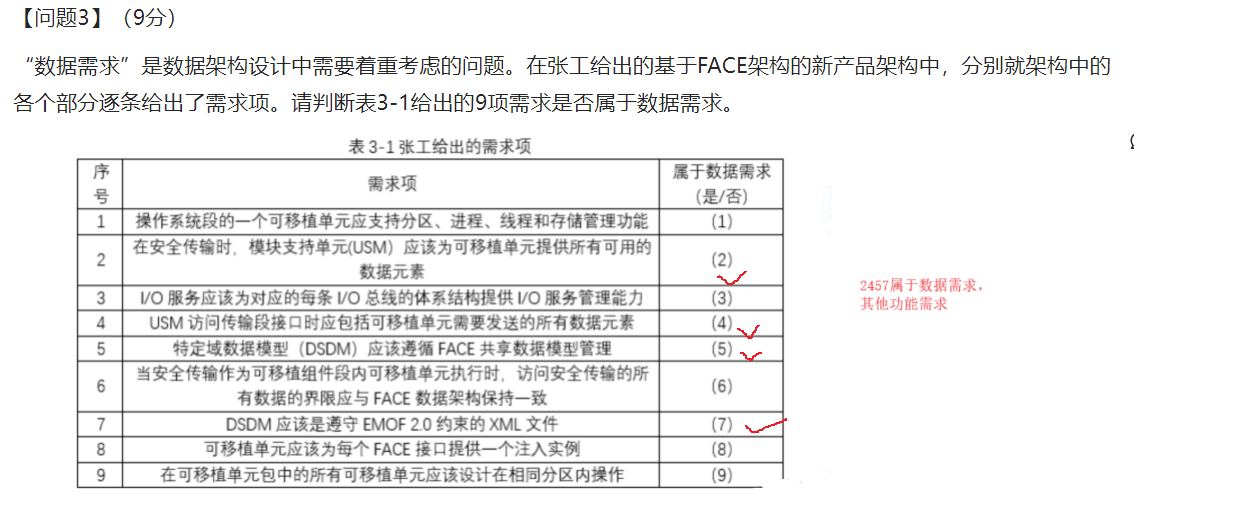
试题四 数据库(反规范化设计方法、数据不一致、redis 同步)

常见的反规范化技术包括:
(1)增加冗余列:增加冗余列是指在多个表中具有相同的列,它常用来在查询时避免连接操作。
(2)增加派生列:增加派生列指增加的列可以通过表中其他数据计算生成。它的作用是在查询时减少计算量,从而加快查询速度。
(3)重新组表:重新组表指如果许多用户需要查看两个表连接出来的结果数据,则把这两个表重新组成一个表来减少连接而提高性能。
(4)分割表:有时对表做分割可以提高性能。
用户查询商品信息应该采用:增加冗余列。
用户查询商品信息时,需要显示药品信息(药品表中),供应商信息(供应商表),库存信息(库存表中),此时查询的是药品表,但表中缺了供应商的信息和库存信息,可以通过增加冗余列的方式把这些信息并过来。以避免连接操作带来的查询性能下降。
【问题2】(9分)
王工认为,反规范化设计可提高查询的性能,但必然会带来数据的不一致性问题。请用200字以内的文字说明在反规范化设计中,解决数据不一致性问题的三种常见方法,并说明该系统应该采用哪种方法。
针对反规范化数据不一致问题,可采用的解决方案包括:
1、触发器数据同步
2、应用程序数据同步
3、物化视图
4、批处理同步
本系统应采用触发器数据同步方式
【问题3】(7分)
该系统采用了Redis来实现某些特定功能(如当前热销药品排名等),同时将药品关系数据放到内存以提高商品查询的性能,但必然会造成Redis和MySQL的数据实时同步问题。
(1) Redis的数据类型包括String、 Hash、 List、 Set和ZSet等,请说明实现当前热销药品排名的功能应该选择使用哪种数据类型。
(2)请用200字以内的文字解释说明解决Redis和MySQL数据实时同步问题的常见方案。
(1)热销药品排名适合用:ZSet,即有序集合类型
(2)
1、实时同步方案,先查缓存,查不到再从DB查询,并保存到缓存;更新缓存时先更新数据库,再将缓存设置过期。
2、异步队列方式同步,可采用消息中间件处理。
3、通过数据库插件完成数据同步。
4、利用触发器进行缓存同步。
试题五 Web应用(云平台智能家居,看图填空,TCP/UDP 区别)
【问题1】(8分)
请用400字以内的文字简要描述基于家庭网关的传统智能家居管理系统和基于云平台的智能家居管理系统在网关管理、数据处理和系统性能等方面的特点,以说明项目组选择李工设计思路的原因。
网关管理:云平台更强,可以实现远程网关管理,可以对不同地点的多种设备进行统一管理,
管理能力更强。
数据处理:数据一般经由网关传递到云上数据库中,再进行处理,这样对数据进行分析、挖掘更便利,同时存储在云端,数据更安全,有容灾能力。
系统性能:数据存在云上数据库中,通信效率更高,同时云也有更强的数据处理能力,
所以会更高效。
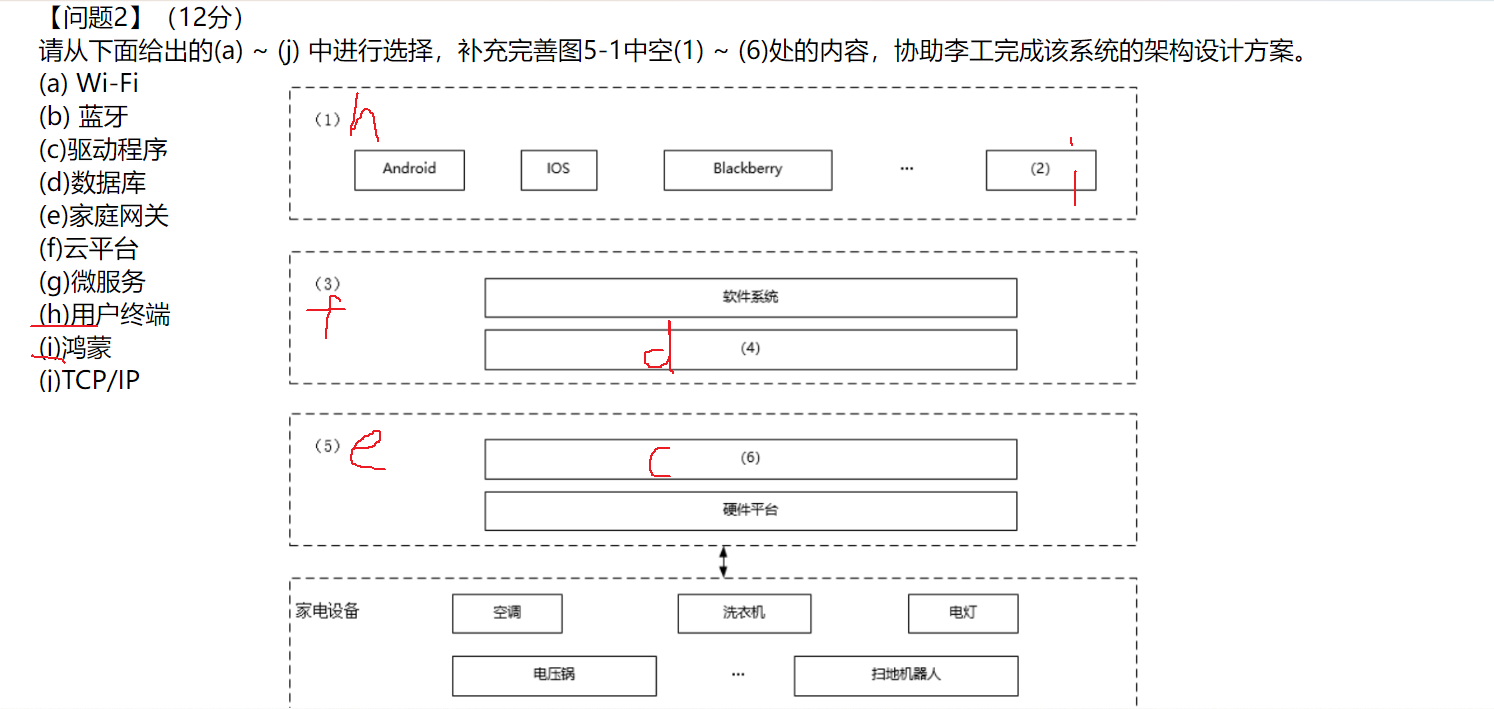
【问题3】(5分)
该系统需实现用户终端与服务端的双向可靠通信,请用300字以内的文字从数据传输可靠性的角度对比分析TCP和UDP通信协议的不同,并说明该系统应采用哪种通信协议。
该系统应采用TCP协议,这样才能保障用户终端和服务端之间的双向可靠通信。
TCP是一种面向连接的、可靠的、基于字节流的传输层通信协议。TCP之所以可靠,
是因为建立连接时有3次握手,通信时有回应机制,所以丢了包,能重传以保障通信可靠性。
UDP是一种面向无连接的传输层通信协议,丢了包不会重传,所以不能保障通信可靠性。