Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
关键词:GRU、Encoder-Decoder
? 研究主题
提出了Encoder-Decoder结构,采用两个RNN作为解码器与编码器
提出了一个新单元-GRU(门控循环单元)
对比与SMT(统计机器翻译)性能上的变化
✨创新点:
- 采用Seq2Seq结构,相对传统的SMT系统,其能够读取不定长度的序列并生成非固定长度结果序列;
- 提出一个新的GRU单元,相对于LSTM简化计算量
? 讨论&解释
RNN Encoder-Decoder
- unit:其中每个单元,都是公式(1)中的h,f为一个非线性激活函数,f可以是sigmoid/lstm/gru等,每个单元通过上个单元的ht-1与本单元的input推理得到ht,并作为下个单元的输入传出
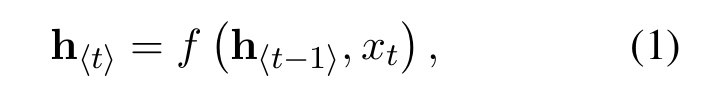
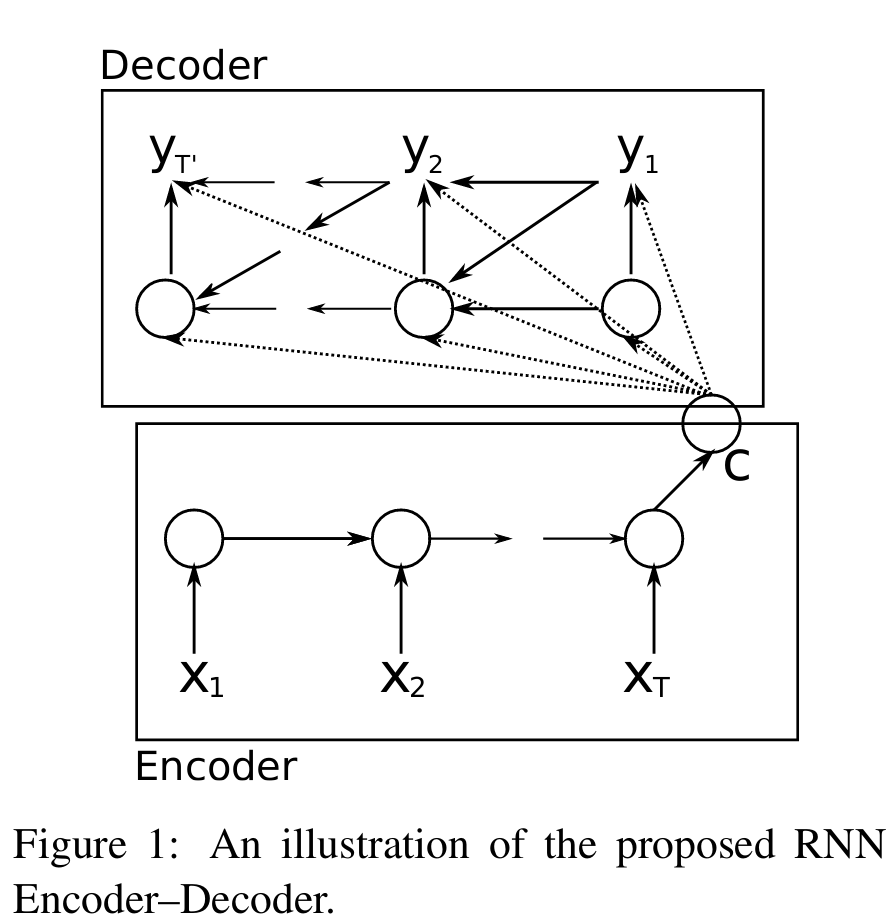
- encoder-decoder:学习将可变长度序列编码为固定长度向量c,并将给定的固定长度向量c解码回可变长度序列。
- c:则可看做为整个输入序列的特征,包含了input的位置信息与内容信息
- decoder:结合c、上层解码器中rnn单元ht-1、上层推理结果yt-1,推理词表概率yt
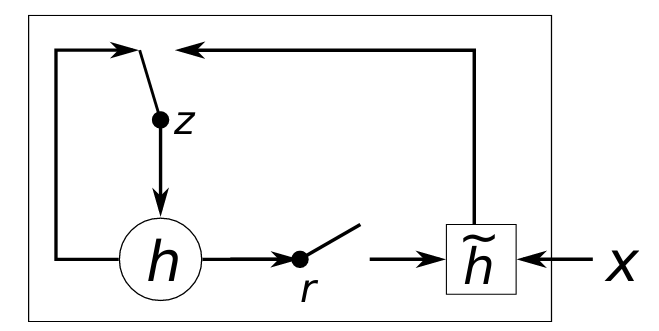
GRU-Gated recurrent unit
- r=reset gate,采用sigmoid函数将其映射到(0,1)范围内,控制对h~的改变量,W和U为学习权重;
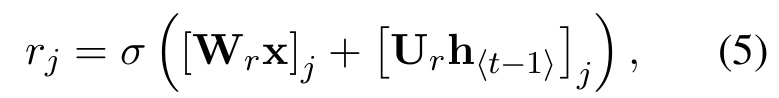
- z=update gate,控制ht-1的记忆量,同样映射到(0,1)范围内;
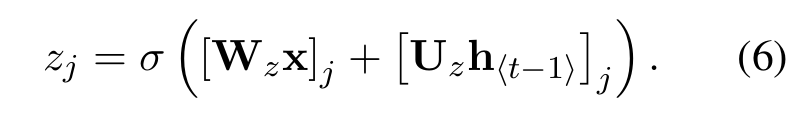
- 从而得到h与h~更新公式:
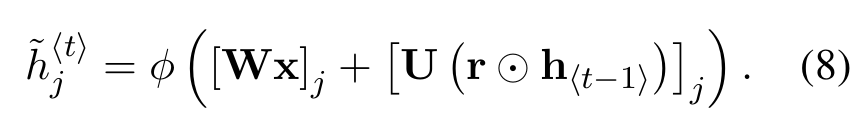
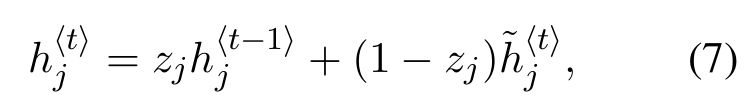
? 设计与实现
未实现,暂不讨论。。。
? 其他思考
创新性地提出了Encoder-Decoder模型结构,提取特征向量c用于解码,破解了输入与输出向量长度一致的限制,但仍存在两点问题or优化空间:
- 对于过长句子,仅解释部分output,不需要全局特征c进行计算,但仍然需要等待c计算完成(引入Attention机制,对每个y只需要关注部分x)
- 由于c固定,需要等待Encoder依次对input读取计算完后,才能进行Decoder。(Transfomer不采用RNN框架,实现并联计算)
- Encoder-Decoder Representations Statistical Translation Learningencoder-decoder representations statistical representations deepwalk learning online statistical encoder-decoder statistical complexity parameters exercises encoder-decoder recognition framework semantics observation uncertainty statistical probability transformer-based encoder-decoder transformer representations translation