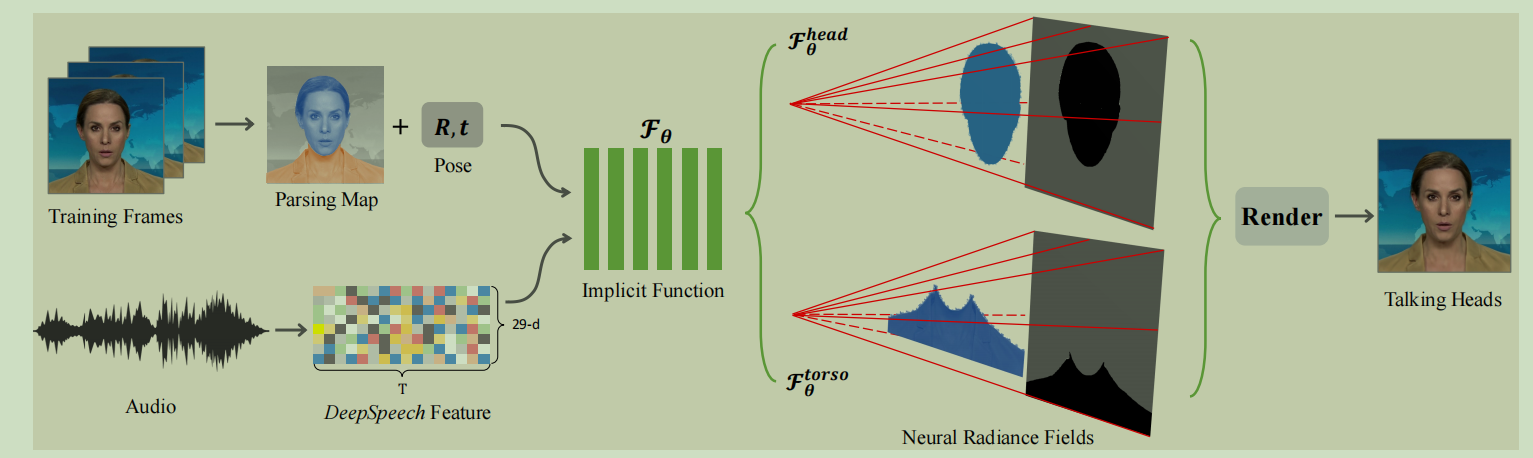
可以看看这个向量场的虚拟人像的效果.
看论文第三章:
3.2:
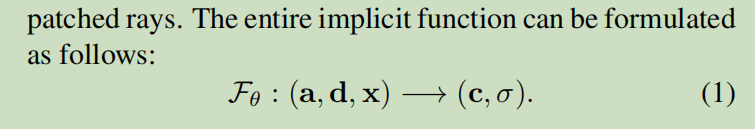
F_theta是一个神经网络, a是声音 d 是view direction, x是3d location.
普通的向量场是 F_theta: d,x ---> (c,σ) 表示d是一个方向, 表示观看者水平的偏移角度和数值的偏移角度. x是一个3d坐标表示看物体的像素位置. 返回c是颜色, σ是体积大小.也就是像素应该涂多大.
这个论文里面就是多加入了声音.
对于音频. 我们使用deepspeech. 生成每一个20ms到一个29维度向量. 把向量放入时间卷积里面用来去噪.
输入的是 16*29. 也就是把16针当做一个音频特征一起处理, 这样会减少噪音干扰. 确实16/50 s 这个粒度还可以.

这个公式从物理来. 可以看这个推导: https://zhuanlan.zhihu.com/p/574351707