实验01 Python爬虫
实验学时:2学时
实验类型:验证
实验要求:必修
一、实验目的
- 理解爬虫技术
- 掌握正则表达式、网络编程
- 掌握re、socket、urllib、requests、lxml模块及其函数的使用
二、实验要求
分析所需爬取信息网页的源代码,使用re、socket、urllib、requests、lxml模块及其函数爬取网页内容,并分析网页内容、提取所需要的数据 。
三、实验内容
任务1. 使用urllib抓取网页数据:
(1)确定网址字符串,如:‘http://www.baidu.com’
(2)向网站发出请求,把字符串传入request对象
(3)把请求返回的信息赋值到response对象
(4)写入txt文件
用Python编写程序实现。
参考代码如下:
#coding:utf-8
import urllib.request
def main():
#请求的头部,User-Agent为浏览器的类型
header={'User-Agent':'Mozilla/5.0(Windows NT 6.1;WOW64) AppleWebKit/537.36(KHTML,like Gecko)Chrome/58.0.3029.96 Safari/537.36'}
#request请求对象,请求某一网站的内容
request=urllib.request.Request('http://www.xmut.edu.cn',headers=header)
#网站的响应
response1=urllib.request.urlopen('http://www.xmut.edu.cn')
response2=urllib.request.urlopen(request)
#读取响应信息的字节流
html=response1.read()
#信息写入文件
f=open('./AL9-7.txt','wb')
f.write(html)
f.close()
if __name__=="__main__":
main()
任务2. 使用requests模块爬取百度首页文件的内容,输出响应对象的类型、状态码和头信息。用Python编写程序实现。
参考代码如下:
#coding:utf-8
import requests
def main():
url='http://www.baidu.com'
response=requests.get(url)
print(type(response))#输出响应对象的内容
print(response.status_code)#输出响应状态码
print(response.headers)#输出响应的头信息
print(response.text)#输出响应的内容
if __name__=="__main__":
main()
任务3. 使用requests和lxml模块爬取某网站的内容,转换成html对象,解析html结点内容,存入数据文件中。
参考代码如下:

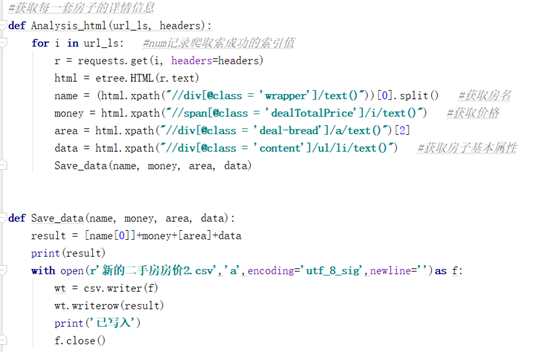

课外练习:(特别强调:爬取的数据只能作为学习练习用,用完删除,不能作其他用途,否则涉及侵权违法行为,责任自负,与学校老师无关!)
任务4. 爬取百度贴吧的数据,用Python编写程序实现。
任务5. 爬取豆瓣电影网站的数据,用Python编写程序实现。
任务6. 用Python爬取网络相片。
http://c.biancheng.net/python_spider/crawl-photo.html