一、选题的背景:
股票数据分析是一个非常重要的领域,它可以帮助投资者做出更明智的投资决策。选取这个选题的背景主要有以下几点:
1. 市场波动:股票市场不断波动,价格的涨跌对投资者来说是一个重要的影响因素。通过对股票数据进行分析,可以揭示市场的走势和各种趋势,帮助投资者更好地了解市场状况,制定合理的投资策略。
2. 信息爆炸:随着网络技术的发展,投资者可以轻松获取大量的股票数据和相关信息。然而,面对如此庞大的数据量,如何从中提取有用的信息成为一个挑战。股票数据分析提供了一种系统性的方法,可以帮助投资者在海量数据中找到关键指标,识别投资机会。
3. 风险管理:投资股票存在风险,尤其是在高度波动的市场环境下。通过对股票数据进行分析,可以评估投资的风险水平并制定相应的风险管理策略。例如,通过对历史数据和现有市场条件的分析,可以评估股票价格的波动范围和潜在的损失,帮助投资者做出更明智的决策。
综上所述,股票数据分析的选题背景主要是为了帮助投资者更好地理解市场、评估风险和抓住投资机会,提高投资的成功率和回报率。
二、网络爬虫的设计方案:
爬虫可分为:通用爬虫,主题爬虫,增量爬虫。其中通用网络爬虫所爬取的目标数据是巨大的,并且爬行的范围也是非常大的,正是由于其爬取的数据是海量数据,故而对于这类爬虫来说,其爬取的性能要求是非常高的。主要应用于大型搜索引擎中,有非常高的应用价值,但是通用爬虫需要遵守robots协议。
主题爬虫(也叫聚焦爬虫):是面向特定需求的一种网络爬虫程序。聚焦爬虫拥有一个控制中心,负责对整个爬虫系统进行管理和监控,主要包括控制用户交互,初始化爬行器,确定主题,协调各模块之间的工作,爬行过程等。它是有选择的进行网页爬取,通用爬虫的目标是全网的资源,但是聚焦爬虫爬取的是一开始就选择好的主题内容,可以很好的节省了网络资源,由于保存的页面数量少所以更新速度很快,可以为某一类特殊人群提供服务,它主要是用于特定信息的爬取。本文就是实现对东方财富网中深圳A股总共244页的内容进行爬取。
增量式爬虫:它爬取的是网页上已经更新过的内容,没有更新或者是没有改变的内容就不爬取。通用的商业搜索引擎就是属于这类的。
总的来说。通用爬虫是搜索引擎的爬虫,是搜索引擎的重要组成部分,采用的是优先爬取有深度优先爬行策略;聚焦爬虫针对特定网站的爬虫,如本文就是实现对东方财富网中深圳A股总共244页的内容进行爬取;增量式爬虫,主要商用。
主题爬虫,又称聚焦爬虫,作为“面向特定主题”的一种网络爬虫程序。它的难点主要有以下两点:
(一)主题相关度计算:即计算当前已经抓下来的页面的主题相关程度。对主题相关度超过某一规定阈值的,即与主题相关的网页,将其保存到网页库;不相关的,则抛弃不管。
(二)主题相关度预测:主题相关度预测是针对待抓URL的。也就是我们在分析当前已下载网页时所分离出来的哪些URLS。我们要通过计算它们的主题预测值来决定接下来是否对该URL所对应的网页进行抓取。
在本文的实现中我们的技术方案总的来说就是实现对获取页面中的数据进行分析与解析,然后通过整个数据中选出自己需要的股票的代码,名称,最新价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收,量比,换手率,市盈率(动态),市净率这些参数,对最终爬取的数据做本地化保存与后续分析。
三、数据分析的实现步骤:
1.数据源:http://quote.eastmoney.com/center/gridlist.html?st=ChangePercent&sr=-1#sz_a_board

2.对该网站发出访问请求,请求成功。

3.主题页面的结构特征分析
(1)在本次实验中我们选择Chrome浏览器对页面进行分析,首先打开待爬取页面的地址(http://quote.eastmoney.com/center/gridlist.html?st=ChangePercent&sr=-1#sz_a_board)然后打开Chrome浏览器的检查功能如图所示:

(2)对这些数据进行精细定位的结果如图所示:可以发现所有数据都被规律的存放在<tbody>节点中。

(一)数据爬取
1.导入相关库:本实验主要用到requests、re、pandas、matplotlib四个库实现爬虫与数据分析。
1 # 导入requests库 2 3 import requests 4 5 # 导入正则表达式所需要用到的库re 6 import re 7 # 导入数据分析所用到的库pandas 8 import pandas as pd 9 # 导入matplotlib 10 import matplotlib.pyplot as plt 11 # 利用time实现暂停打印信息 12 import time 13 # numpy 14 import numpy as np
2.配置cookie信息和头文件相关程
1 2 cookies = { 3 'qgqp_b_id': '02d480cce140d4a420a0df6b307a945c', 4 5 'cowCookie': 'true', 6 7 'em_hq_fls': 'js', 8 9 'intellpositionL': '1168.61px', 10 11 'HAList': 'a-sz-300059-%u4E1C%u65B9%u8D22%u5BCC%2Ca-sz-000001-%u5E73%u5B89%u94F6%u884C', 12 13 'st_si': '07441051579204', 14 15 'st_asi': 'delete', 16 17 'st_pvi': '34234318767565', 18 19 'st_sp': '2021-09-28%2010%3A43%3A13', 20 21 'st_inirUrl': 'http%3A%2F%2Fdata.eastmoney.com%2F', 22 23 'st_sn': '31', 24 25 'st_psi': '20211020210419860-113300300813-5631892871', 26 27 'intellpositionT': '1007.88px', 28 }
3.对该URL发送请求与获得的结果如下图所示:
1 # 配置头文件 2 headers = { 3 4 # 即为页面中分析时'Connection'对应的值 5 'Connection': 'keep-alive', 6 7 # 即为页面中分析时'User-Agent'对应的值 8 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50', 9 10 # 即为页面中分析时'DNT'对应的值 11 'DNT': '1', 12 13 # 即为页面中分析时'Accept'对应的值 14 'Accept': '*/*', 15 16 # 即为页面中分析时'Referer'对应的值 17 'Referer': 'http://quote.eastmoney.com/', 18 19 # 即为页面中分析时'Accept-Language'对应的值 20 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
1 # 所有信息等待存入放入列表 2 all_message = [] 3 4 # 总共爬取网页上244页的内容 5 for page in range(1,244): 6 7 params = ( 8 9 # 解析到的URL中对应的cb参数 10 ('cb', 'jQuery1124031167968836399784_1615878909521'), 11 12 # 解析到的URL中对应的pn参数 13 ('pn', str(page)), 14 15 # 解析到的URL中对应的pz参数 16 ('pz', '20'), 17 18 # 解析到的URL中对应的po参数 19 ('po', '1'), 20 21 # 解析到的URL中对应的np参数 22 ('np', '1'), 23 24 # 解析到的URL中对应的ut参数 25 ('ut', 'bd1d9ddb04089700cf9c27f6f7426281'), 26 27 # 解析到的URL中对应的fltt参数 28 ('fltt', '2'), 29 30 # 解析到的URL中对应的invt参数 31 ('invt', '2'), 32 33 # 解析到的URL中对应的fid参数 34 ('fid', 'f3'), 35 36 # 解析到的URL中对应的fs参数 37 ('fs', 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23,m:0 t:81 s:2048'), 38 39 # 解析到的URL中对应的fields参数 40 ('fields', 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152'), 41 )
4.通过正则表达式实现对其正确检测,并获取对应内容:
1 # 获取股票代码 2 daimas = re.findall('"f12":(.*?),', response.text) 3 4 # 获取股票名称 5 names = re.findall('"f14":"(.*?)"', response.atext) 6 7 # 获取最新价 8 zuixinjias = re.findall('"f2":(.*?),', response.text) 9 10 # 获取涨跌幅 11 zhangdiefus = re.findall('"f3":(.*?),', response.text) 12 13 # 获取涨跌额 14 zhangdiees = re.findall('"f4":(.*?),', response.text) 15 16 # 获取成交量 17 chengjiaoliangs = re.findall('"f5":(.*?),', response.text) 18 19 # 获取成交额 20 chengjiaoes = re.findall('"f6":(.*?),', response.text) 21 22 # 获取振幅 23 zhenfus = re.findall('"f7":(.*?),', response.text) 24 25 # 获取今日最高点 26 zuigaos = re.findall('"f15":(.*?),', response.text) 27 28 # 获取今日最低点 29 zuidis = re.findall('"f16":(.*?),', response.text) 30 31 # 获取今日开盘价格 32 jinkais = re.findall('"f17":(.*?),', response.text) 33 34 # 获取昨日收盘价格 35 zuoshous = re.findall('"f18":(.*?),', response.text) 36 37 # 获取量比 38 liangbis = re.findall('"f10":(.*?),', response.text) 39 40 # 获取换手率 41 huanshoulvs = re.findall('"f8":(.*?),', response.text) 42 43 # 获取市盈率 44 shiyinglvs = re.findall('"f9":(.*?),', response.text) 45 46 # 获取市净率 47 shijinglvs = re.findall('"f23":(.*?),', response.text)
5.保存数据,并存储为.csv文件

存储结果如下:

6.将所有数据写入字典,为后续本地化存储,最终打印出字典中的信息如图所示:


7.股票行业中最有用的值通常是股票的最新价和涨跌幅,为此,在数据清洗和处理的过程中我选择涨幅最高的100支股票进行后续的分析,对于涨幅最高的100支股票,我按顺序做出了其最新价的折线变化,发现涨幅越高的股票价格越高。


通过数据分析得出的曲线图,可以明显看出股票的涨幅。

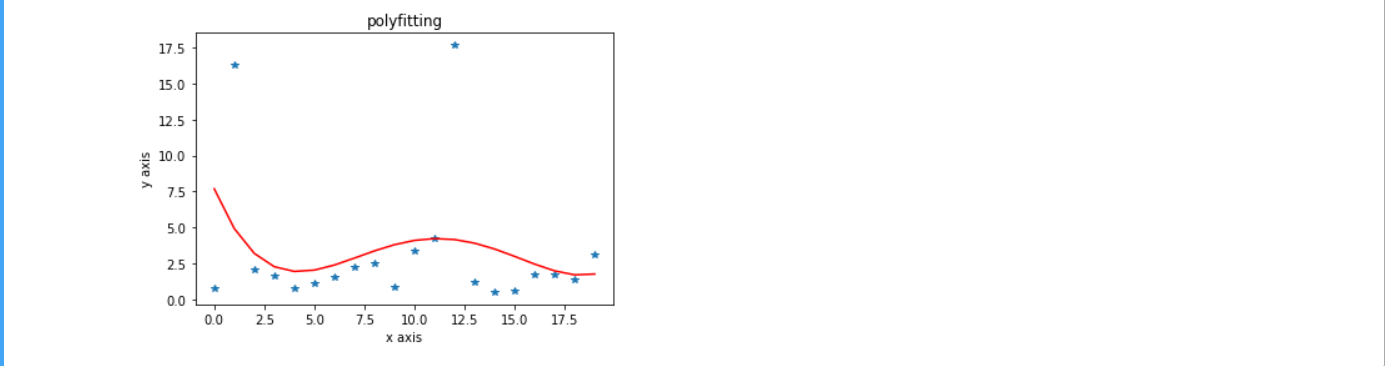
利用曲线拟合拟合出来的换手率和涨幅的关系,可以清晰的得出股票涨幅与换手率的关联。
数据分析及可视化到这里就结束了,接下来就是本文的全部代码 :
1 # 导入requests库 2 import requests 3 # 导入正则表达式所需要用到的库re 4 import re 5 # 导入数据分析所用到的库pandas 6 import pandas as pd 7 # 导入matplotlib 8 import matplotlib.pyplot as plt 9 # 利用time实现暂停打印信息 10 import time 11 # numpy 12 import numpy as np 13 14 # 写入cookie信息 15 cookies = { 16 # 即为页面中分析时'qgqp_b_id'对应的值 17 'qgqp_b_id': '02d480cce140d4a420a0df6b307a945c', 18 19 # 即为页面中分析时'cowCookie'对应的值 20 'cowCookie': 'true', 21 22 # 即为页面中分析时'em_hq_fls'对应的值 23 'em_hq_fls': 'js', 24 25 # 即为页面中分析时'intellpositionL'对应的值 26 'intellpositionL': '1168.61px', 27 28 # 即为页面中分析时'HAList'对应的值 29 'HAList': 'a-sz-300059-%u4E1C%u65B9%u8D22%u5BCC%2Ca-sz-000001-%u5E73%u5B89%u94F6%u884C', 30 31 # 即为页面中分析时'st_si'对应的值 32 'st_si': '07441051579204', 33 34 # 即为页面中分析时'st_asi'对应的值 35 'st_asi': 'delete', 36 37 # 即为页面中分析时'st_pvi'对应的值 38 'st_pvi': '34234318767565', 39 40 # 即为页面中分析时'st_sp'对应的值 41 'st_sp': '2021-09-28%2010%3A43%3A13', 42 43 # 即为页面中分析时'st_inirUrls'对应的值 44 'st_inirUrl': 'http%3A%2F%2Fdata.eastmoney.com%2F', 45 46 # 即为页面中分析时'st_sn'对应的值 47 'st_sn': '31', 48 49 # 即为页面中分析时'st_psi'对应的值 50 'st_psi': '20211020210419860-113300300813-5631892871', 51 52 # 即为页面中分析时'intellpositionT'对应的值 53 'intellpositionT': '1007.88px', 54 } 55 56 # 配置头文件 57 headers = { 58 # 即为页面中分析时'Connection'对应的值 59 'Connection': 'keep-alive', 60 61 # 即为页面中分析时'User-Agent'对应的值 62 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50', 63 64 # 即为页面中分析时'DNT'对应的值 65 'DNT': '1', 66 67 # 即为页面中分析时'Accept'对应的值 68 'Accept': '*/*', 69 70 # 即为页面中分析时'Referer'对应的值 71 'Referer': 'http://quote.eastmoney.com/', 72 73 # 即为页面中分析时'Accept-Language'对应的值 74 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 75 } 76 # 所有信息等待存入放入列表 77 all_message = [] 78 79 # 总共爬取网页上244页的内容 80 for page in range(1,244): 81 params = ( 82 # 解析到的URL中对应的cb参数 83 ('cb', 'jQuery1124031167968836399784_1615878909521'), 84 85 # 解析到的URL中对应的pn参数 86 ('pn', str(page)), 87 88 # 解析到的URL中对应的pz参数 89 ('pz', '20'), 90 91 # 解析到的URL中对应的po参数 92 ('po', '1'), 93 94 # 解析到的URL中对应的np参数 95 ('np', '1'), 96 97 # 解析到的URL中对应的ut参数 98 ('ut', 'bd1d9ddb04089700cf9c27f6f7426281'), 99 100 # 解析到的URL中对应的fltt参数 101 ('fltt', '2'), 102 103 # 解析到的URL中对应的invt参数 104 ('invt', '2'), 105 106 # 解析到的URL中对应的fid参数 107 ('fid', 'f3'), 108 109 # 解析到的URL中对应的fs参数 110 ('fs', 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23,m:0 t:81 s:2048'), 111 112 # 解析到的URL中对应的fields参数 113 ('fields', 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152'), 114 ) 115 116 # 对当前页数发送请求 117 response = requests.get('http://67.push2.eastmoney.com/api/qt/clist/get', headers=headers, params=params, 118 cookies=cookies, verify=False) 119 120 # 打印请求结果 121 122 #print(response.text) 123 124 # time.sleep(100) 125 126 # 判断请求是否成功 127 128 if response.status_code == 200: 129 print("请求成功") 130 # 打印请求结果 131 print(response.text) 132 else: 133 print("请求失败,状态码:", response.status_code) 134 # 获取股票代码 135 daimas = re.findall('"f12":(.*?),', response.text) 136 137 # 获取股票名称 138 names = re.findall('"f14":"(.*?)"', response.text) 139 140 # 获取最新价 141 zuixinjias = re.findall('"f2":(.*?),', response.text) 142 143 # 获取涨跌幅 144 zhangdiefus = re.findall('"f3":(.*?),', response.text) 145 146 # 获取涨跌额 147 zhangdiees = re.findall('"f4":(.*?),', response.text) 148 149 # 获取成交量 150 chengjiaoliangs = re.findall('"f5":(.*?),', response.text) 151 152 # 获取成交额 153 chengjiaoes = re.findall('"f6":(.*?),', response.text) 154 155 # 获取振幅 156 zhenfus = re.findall('"f7":(.*?),', response.text) 157 158 # 获取今日最高点 159 zuigaos = re.findall('"f15":(.*?),', response.text) 160 161 # 获取今日最低点 162 zuidis = re.findall('"f16":(.*?),', response.text) 163 164 # 获取今日开盘价格 165 jinkais = re.findall('"f17":(.*?),', response.text) 166 167 # 获取昨日收盘价格 168 zuoshous = re.findall('"f18":(.*?),', response.text) 169 170 # 获取量比 171 liangbis = re.findall('"f10":(.*?),', response.text) 172 173 # 获取换手率 174 huanshoulvs = re.findall('"f8":(.*?),', response.text) 175 176 # 获取市盈率 177 shiyinglvs = re.findall('"f9":(.*?),', response.text) 178 179 # 获取市净率 180 shijinglvs = re.findall('"f23":(.*?),', response.text) 181 # 将不同股票信息写入字典 182 183 for i in range(len(daimas)): 184 dict = { 185 # 获取对应股票代码 186 "代码": daimas[i], 187 # 获取对应股票名称 188 "名称": names[i], 189 # 获取对应股票最新价 190 "最新价":zuixinjias[i], 191 # 获取对应股票涨跌幅 192 "涨跌幅":zhangdiefus[i], 193 # 获取对应股票涨跌额 194 "涨跌额":zhangdiees[i], 195 # 获取对应股票成交量 196 "成交量":chengjiaoliangs[i], 197 # 获取对应股票成交额 198 "成交额":chengjiaoes[i], 199 # # 获取对应股票振幅 200 "振幅":zhenfus[i], 201 # 获取对应股票最高点 202 "最高":zuigaos[i], 203 # 获取对应股票最低点 204 "最低":zuidis[i], 205 # 获取对应股票开盘价格 206 "今开":jinkais[i], 207 # 获取对应股票昨日收盘价格 208 "昨收":zuoshous[i], 209 # 获取对应股票量比 210 "量比":liangbis[i], 211 # 获取对应股票最换手率 212 "换手率":huanshoulvs[i], 213 # 获取对应股票市盈率(动态) 214 "市盈率(动态)":shiyinglvs[i], 215 # 获取对应股票市净率 216 "市净率":shijinglvs[i] 217 } 218 219 # 打印字典信息 220 221 # print(dict) 222 223 # 把一支股票的所有信息以字典的形式存入列表 224 all_message.append(dict) 225 226 # 打印所有股票构成的列表 227 228 # print(all_message) 229 230 # 将其存储为pandas格式 231 result_pd = pd.DataFrame(all_message) 232 233 # 指定文件保存路径 234 save_path = "C:\\Users\\asus\\Desktop\\东方财富_photo.csv" 235 236 # 保存DataFrame为CSV文件 237 result_pd.to_csv(save_path) 238 239 # 打印保存文件的路径 240 print(f"文件已保存到:{save_path}") 241 242 # 数据清洗和处理时我们选择涨幅最高的100支股票进行后续分析 243 244 # 读取本地CSV 245 df = pd.read_csv("C:\\Users\\asus\\Desktop\\东方财富_photo.csv") 246 247 # 根据涨幅进行排序 248 df_sort = df.sort_values(by='涨跌幅',ascending=False) 249 250 # # 打印排序结果 251 # print(df_sort) 252 # 253 # # 打印排序后原始数据长度 254 # print(len(df_sort)) 255 # 对排序后的数据取前100行 256 new_df = df_sort.head(100) 257 258 # # 打印原始数据清洗与筛选后的 259 # print(df_sort) 260 # 261 # # 打印筛选后的长度 262 # print(len(new_df)) 263 # 画图 264 # 主要利用matplotlib和pandas自带的画图功能 265 266 # 绘制涨幅最高的100支股票最新价折线图 267 pd_cje = new_df['最新价'].tolist() 268 269 # 打印结果 270 # print(pd_cje) 271 272 # 打印是否转换成列表 273 # print(type(pd_cje)) 274 275 # 设置x刻度 276 my_x_ticks = np.arange(0, 101, 5) 277 278 # 设置y刻度 279 my_y_ticks = np.arange(0, 101, 5) 280 281 # 配置x刻度 282 plt.xticks(my_x_ticks) 283 284 # 配置y刻度 285 plt.yticks(my_y_ticks) 286 287 # 画图 288 plt.plot(range(len(pd_cje)), pd_cje) 289 290 # 展示 291 plt.show() 292 # 绘制散点图并拟合 293 my_y = new_df['换手率'].tolist() 294 295 my_x = [i for i in range(len(my_y))] 296 297 # 用4次多项式拟合 298 z1 = np.polyfit(my_x, my_y, 4) 299 300 p1 = np.poly1d(z1) 301 302 # 也可以使用yvals=np.polyval(z1,x) 303 yvals=p1(my_x) 304 305 # 绘制散点和曲线 306 plot1=plt.plot(my_x, my_y, '*',label='original values') 307 308 plot2=plt.plot(my_x, yvals, 'r',label='polyfit values') 309 310 # 图标 311 plt.xlabel('x axis') 312 313 plt.ylabel('y axis') 314 315 # 标题 316 plt.title('polyfitting') 317 318 # 展示 319 plt.show()
四、总结
对本课程设计的整体完成情况做一个总结,通过这次利用python代码爬虫爬取网站数据并分析,让我掌握了最基础的数据分析知识,体验了数据分析的乐趣,包括数据预处理,数据清洗,异常值的查找等,数据的合并和分组及聚合,还有数据可视化来直观的观察.分析数据。虽然学的不是很精通,部分代码还是需要借鉴下课本,网络。但在这次课程设计中还是学到了很多,不止是进一步的复习了课本上的知识内容,还学习了他人的代码思路并加以思考形成自己的思路。虽然作品仍有残缺不是很完美,但希望可以越来越进步!