选题背景介绍
核污水数据可视化是一个具有重要意义的选题,其背景主要涉及到核能发展、环境保护、数据科学和信息传播等多个方面。
首先,随着核能在全球能源结构中的地位逐渐提升,核能设施的运行和核废料处理成为重要的议题。其中,核污水的产生和处理是一个关键环节。由于核污水中含有放射性物质,其处理和处置需要严格监管和科学评估。因此,对核污水数据的监测和可视化呈现,有助于公众和决策者更好地理解核污水的来源、处理过程和潜在风险。
其次,环境保护意识的提高使得公众对核能设施的环境影响保持高度关注。通过核污水数据可视化,可以直观地展示核污水处理和监测的实际情况,帮助公众更好地理解核能设施的环境影响,促进环保决策的科学化和民主化。
此外,数据科学的发展为核污水数据的处理、分析和可视化提供了技术支持。数据可视化作为一种直观的信息表达方式,能够将复杂的数据以易于理解的形式呈现给公众,提高信息传播的效率和效果。通过数据可视化,人们可以更加深入地了解核污水的处理和监测情况,发现潜在的问题和风险,为相关决策提供科学依据。
综上所述,核污水数据可视化选题背景涉及多个领域,包括核能发展、环境保护、数据科学和信息传播等。该选题具有重要的现实意义和实践价值,有助于提高公众的科学素养和环保意识,促进相关领域的技术创新和发展。
。
选题意义
核污水数据可视化的选题意义主要表现在:
1.提升公众认知与参与度:核能作为一种重要的能源形式,其应用和影响日益广泛。然而,由于核能技术的复杂性和核污水的潜在风险,公众往往对此存在一定程度的误解和担忧。通过核污水数据可视化,可以直观地呈现核污水的产生、处理和监测过程,帮助公众更好地理解核能设施的运行情况和核污水的处理效果,从而提高公众的认知度和参与度。
2.辅助决策科学化:核污水数据的可视化不仅有助于公众理解,还可以为决策者提供重要的参考依据。通过对核污水数据的实时监测和可视化,决策者可以更加准确地了解核污水的处理效果和潜在风险,从而做出更加科学和合理的决策。
促进数据科学与环保的交叉研究:核污水数据可视化涉及到数据科学和环保两个领域。通过将数据科学的方法和技术应用于环保领域,可以促进两个领域的交叉融合和创新发展,为解决环保问题提供更多元化的方法和思路。
3.增强国际合作与交流:随着全球环境问题日益严重,国际合作与交流在环保领域的重要性愈发凸显。通过核污水数据可视化,可以促进不同国家和地区之间在核能安全和环保领域的交流与合作,共同推动全球环保事业的发展。
4.引导技术创新与应用:数据可视化技术的发展为核污水数据的处理、分析和呈现提供了更多可能性。通过核污水数据可视化的研究和实践,可以引导相关技术的创新和应用,推动数据科学与环保领域的深度融合,为未来的环保事业提供更多先进的技术支持。
数据分析步骤
目标网站:https://www.weibo.com/
通过微博的高级搜索接口进行关键词相关微博搜索。
1.根据关键词和时间,获取微博ID列表
get_mid 的函数:用于根据关键词和时间范围爬取微博的mid,并保存到 ./data/mid_list.csv 文件中。
具体步骤如下:
a.引入所需的库,包括 requests 和 beautifulsoup4。
b.定义一个函数 get_mid(keyword, start_date, end_date),该函数接受关键词、起始日期和结束日期作为参数。
c.在函数内部,使用 requests 库发送GET请求,访问微博搜索页面,并通过传递关键词和时间参数来搜索相关微博。
d.使用 beautifulsoup4 解析返回的HTML页面,并提取出微博的mid。
e. 将mid保存到 ./data/mid_list.csv 文件中。
2.根据博文ID获取微博评论信息:
get_comment 函数,用于根据微博ID采集微博的详细信息,并保存到 ./data/data.csv 文件中。
具体步骤如下:
a.定义一个函数 get_comment(mid),该函数接受微博ID作为参数。
b.在函数内部,使用 requests 库发送GET请求,访问微博评论页面,并通过传递微博ID参数来获取评论信息。
c.使用 beautifulsoup4 解析返回的HTML页面,并提取出评论的详细信息,包括用户ID、昵称、内容、时间、转发数、评论数、点赞数、IP属地和设备信息。
d.将评论信息保存到 ./data/data.csv 文件中。
3.主程序:
a.在主程序中,调用 get_mid 函数获取微博ID列表,并保持到 all_mid_list 中。
b.将获取的微博ID列表读取出来,再调用 get_comment 函数获取微博的详细信息,并最终将数据保存为 CSV 和 Excel 格式文件。
爬虫程序设计
Part1博文数据

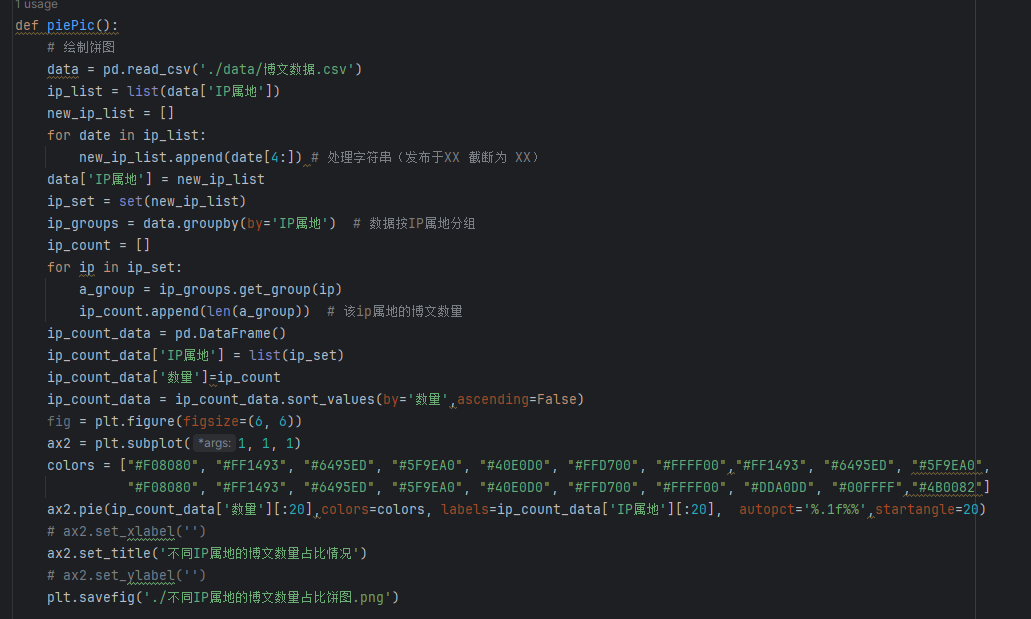
Part2不同IP属地的博文数量占比饼图,图&代码

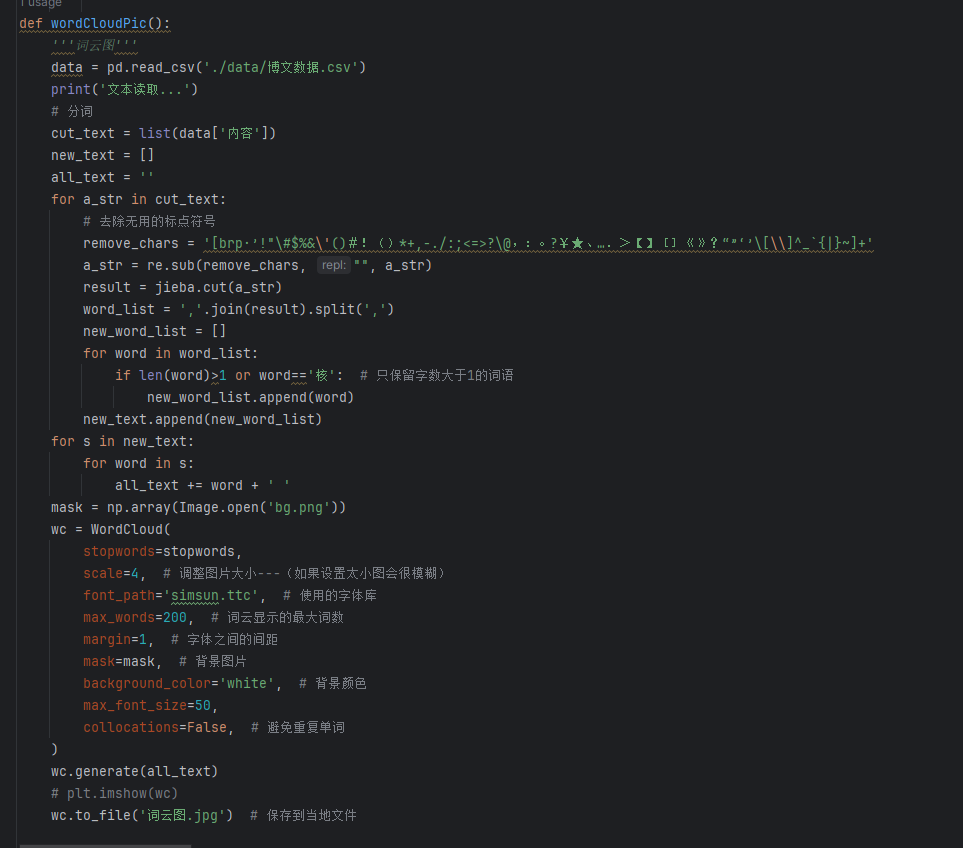
Part3词云诗,图&代码

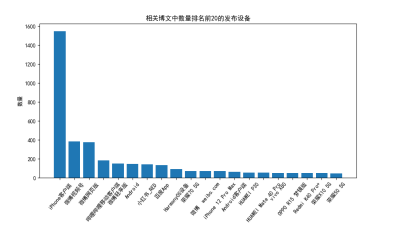

Part4相关博文中数量排名前20的发布设备,图&代码
爬虫程序设计全部代码如下:
1.mport datetime
2.import requests
3.import re
4.import time
5.import matplotlib.pyplot as plt
6.import numpy as np
7.import PIL.Image as Image
8.import re
9.import pandas as pd
10.import jieba
11.from wordcloud import WordCloud,STOPWORDS
12.# 去除停用词
13.stopwords = STOPWORDS
14.# stopwords.add('')
15.#代理ip全局参数
16.ip = "" # 请求时使用的ip值
17.# 代理ip列表,来自免费代理ip网站
18.# 通过代理ip爬虫防止被封禁
19.agency_ip = [
20. 'http://49.86.58.36:9999',
21. 'http://182.84.144.91:3256',
22. 'http://171.35.213.44:9999',
23. 'http://114.67.108.243:8081',
24. 'http://211.24.95.49:47615',
25. 'http://192.168.110.254:8088'
26. ]
27.proxies = {'http': 'http://192.168.110.254:8088'}
28.def url_get(url):
29. headers = {
30. # 采用手机端cookie伪造手机客户端登录
31. 'cookie': 'T_WM=44510275861; XSRF-TOKEN=66e0d4; '
32. 'WEIBOCN_FROM=1110003030; SCF=AheGnLEmc4M73LF1z_1ZCFDawGhwqwWJpSOYnVr1VnUwnbCoI5nLZcZOBZDdnxrz0gUUuxWAPMqTWpX0T5BQWeg.; '
33. 'SUB=2A25IjuOiDeRhGeBM7VoQ9C_OzTiIHXVr4nlqrDV6PUJbktANLVrDkW1NRNiQjiy1e2vW_qYxK6F39D_Zgm4tSfvI; '
34. 'SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9Wh8ISvZwL5BoTXsgjksVeK45NHD95QceoqReKBpeoqXWs4DqcjsUs8jwJyk; '
35. 'SSOLoginState=1703580658;
36.MLOGIN=1; M_WEIBOCN_PARAMS=luicode%3
37.D10000011%26lfid%3D1076033144744040%26fid%3D100103type%253D1%2526q%253D%25E9%25AB%2598%25E7%25BA%
38.25A7%25E6%2590%259C%25E7%25B4%25A2%26uicode%3D10000011',
39. 'user-agent': 'Mozilla/5.0 (Wi
40.ndows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36',
41. 'Referer': 'https://s.weibo.com/weibo?q=%E
42.6%97%A5%E6%9C%AC%E6%8E%92%E6%94%BE%E6%A0%B8%E6%B1%A1%E6%B0%B4&typeall=1&suball=1&Refer=g&page=1',
43. 'x-requested-with': 'XMLHttpRequest'
44. }
45. url = url
46. response = requests.get(url=url, headers=headers,timeout=10).text #,proxies=proxies
47. return response
48.def get_comment(mid_list):
49. headers2 = {
50. 'cookie': 'XSRF-TOKEN=3f20cd; WEIBOCN_FROM=1110006030; MLOGIN=1; M_WEIBOCN_PARAMS=oid%3D487485
51.6670431688%26lfid%3D102803%26luicode%3D20000174%26uicode%3D20000174; BAIDU_SSP_lcr=https://cn.bing.com/; __bid_n=186a32563a9eebb7a64207; FPTOKEN=Kp07sxcKEdSrxKDD2qaj+
52.kzvKOn/GHiqoa0XhPJwxgrdOXGK
53.bzR1/BvNlGSb8XVvqtJ5ZWJwGEQYs/dMi9Z0jgMp07pgzWtd4wYUj+QyV+xHKMcLFmwxb1vE6WidaBc0QiGX6Hfw95ed76W6K8l2
54.e8lL3orCFTjfYcMRHhOINauXrhkgp3nSyBGxrtkMo/KDZxDe7MRC8uxARajapJ4mgekVuSzmjLuEp3UOKr6Y0cVjvIksQOBb1cSJDv1cM
55.clp187HT/TlYJI4jZ56TExnGE5ehc/EGhKl98ZrB7dFXBDzuuJMz6CrLHBEgekWnHW/2b2RY5m47XKJ2hLdnFy2wqgUZ3I5f9s7pX9Gm
56.6Xdaumn/Fc0z4HNWwFyUf3knUhzIP4U7z7XVZBemdZg3SRFHg==|j21gNrGdnzGVIyEG38HDjm9KS7C2K/enQ5u6ST1ZnqE=|10|
57.3ebbcafc662f9d59d16db035c62b2cc1; loginScene=102003; SUB=_2A25JBL4xDeRhGeFG6VY
58.Z8yvOzz6IHXVqBsJ5rDV6PUJbkdAGLWfdkW1NeeupSkvr9IdDEfvmWXFC00UJREgsgq6D; T_W
59.M=94873592822; mweibo_short_token=0de3e9a046',
60. 'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1',
61. 'Referer': 'https://weibo.com/1259366365?refer_flag=1001030103',
62. # 'x-requested-with': 'XMLHttpRequest'
63. }
64. article_list = pd.DataFrame(columns=['ID','昵称','内容','时间','转发数','评论数','点赞数','IP属地','设备'])
-
#######
-
for i in range (0,len(mid_list)):
-
try: -
article_url = 'https://m.weibo.cn/detail/' + str(mid_list.iloc[i,1]) -
detail_response = requests.get(url=article_url, headers=headers2,timeout=10) # ,proxies=proxies -
# print(detail_response.text) -
html_text = detail_response.text -
record = [] -
# 楼主ID -
title_user_id = re.findall('.*?"id": (.*?),.*?', html_text)[1] -
record.append(title_user_id) -
# print("title_user_id = ", title_user_id) -
# 楼主昵称 -
title_user_NicName = re.findall('.*?"screen_name": "(.*?)",.*?', html_text)[0] -
record.append(title_user_NicName) -
# print("title_user_NicName = ", title_user_NicName) -
# 话题内容 -
find_title = re.findall('.*?"text": "(.*?)",.*?', html_text)[0] -
title_text = re.sub('<(S*?)[^>]*>.*?|<.*? />', '', find_title) # -
record.append(title_text) -
# print("title_text = ", title_text) -
# 时间 -
time_str = re.findall('.*?"created_at": "(.*?)",.*?', html_text)[0] -
time_str_format = time_str[4:] -
time_str_format = datetime.datetime.strptime(time_str_format, '%b %d %H:%M:%S +0800 %Y') -
record.append(str(time_str_format)) -
# 转发数 -
reposts_count = re.findall('.*?"reposts_count": (.*?),.*?', html_text)[0] -
record.append(reposts_count) -
# 评论数 -
comments_count = re.findall('.*?"comments_count": (.*?),.*?', html_text)[0] -
record.append(str(comments_count)) -
# 点赞数 -
attitudes_count = re.findall('.*?"attitudes_count": (.*?),.*?', html_text)[0] -
record.append(attitudes_count) -
# 博主ip -
region_name = re.findall('.*?"region_name": "(.*?)",.*?', html_text)[0] -
record.append(region_name) -
# 博主设备 -
source = re.findall('.*?"source": "(.*?)",.*?', html_text)[0] -
record.append(source) -
print("抓取微博("+str(i)+"):"+str(record)) -
len_ = len(article_list.index) -
article_list.loc[len_] = record # 写入dataframe article_list -
if((i+1)%50==0): -
print("【保存数据】:" + str(i) ) -
article_list.to_csv('./data/data.csv', encoding='utf-8', index=None, mode='a+', header=False) -
article_list = pd.DataFrame(columns=['ID','昵称','内容','时间','转发数','评论数','点赞数','IP属地','设备']) -
if (i == len(mid_list)-1 ): -
article_list.to_csv('./data/data.csv', encoding='utf-8', index=None, mode='a+', header=False) -
except: -
pass -
return article_list
118.def get_mid(keyword,s_day,start_page,end_page):
119. '''根据关键词和时间范围爬取微博的mid'''
120. time_ = s_day + ':' + s_day
121. keyword_ = keyword
122. page_ = start_page
123. end_page_ = end_page
124. mid_list= []
125. for i in range(page_,end_page_+1):
126. print("第 "+str(i)+" 页:")
127. url = 'https://s.weibo.com/weibo?q=' + keyword_ + '&typeall=1&suball=1×cope=custom:' + time_ + '&Refer=g&page=' + str(i)
128. response = url_get(url)
129. comment_ID = re.findall('(?<=mid=")\d{16}', response)
130. print(comment_ID)
131. mid_list =mid_list + comment_ID
132. # print(mid_list)
133. # mids = pd.DataFrame(mid_list)
134. # mids.to_csv('./data/mid_list.csv',encoding='utf-8')
135. return mid_list
136.def testIP():
137. '''
138. 从ip列表中取ip并测试,如果能用则返回当前ip值
139. :param targetUrl:
140. :param ip:
141. :return: eachip
142. '''
143. url = "https://m.weibo.cn/detail/4858309729590576"
144. # 伪造浏览器请求头
145. fake_headers = {
146. 'cookie': '__bid_n=186a32563a9eebb7a64207; FPTOKEN=Kp07sxcKEdSrxKDD2qaj+kzvKOn/GHiqoa0XhPJwxgrdOXGKbzR1/BvNlGSb8XVvqtJ5ZWJwGEQYs/dMi9Z0jgMp07pgzWtd4
147.wYUj+QyV+xHKMcLFmwxb1vE6WidaBc0QiGX6Hfw95ed76W6K8l2e8lL3orCFTjfYcMRHhOINauXrhkgp3nSyBGxrtkMo/KDZxDe7MRC8
148.uxARajapJ4mgekVuSzmjLuEp3UOKr6Y0cVjvIksQOBb1cSJDv1cMclp187HT/TlYJI4jZ56TExnGE5ehc/EGhKl98ZrB7dFXBDzuuJMz6CrLHBE
149.gekWnHW/2b2RY5m47XKJ2hLdnFy2wq
150.gUZ3I5f9s7pX9Gm6Xdaumn/Fc0z4HNWwFyUf3knUhzIP4U7z7XVZBemdZg3SRFHg|j21gNrGdnzGVIyEG38HDjm9KS7C2K/enQ5u6
151.ST1ZnqE=|10|3ebbcafc662f9d59d16db035c62b2cc1; T_WM=58222512405; XSRF-TOKEN=937a78; WEIBOCN_FROM
152.=1110006030; mweibo_short_token=84ce04929d; MLOGIN=0; M_WEIBOCN_PARAMS=luicode%3D10000011%26lfid%3D102803%26uicode%3D20000174',
153. 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/118.0',
154. 'Referer': 'https://s.weibo.com/weibo?q=高级搜索',
155. 'x-requested-with': 'XMLHttpRequest'
156. }
157. for eachip in agency_ip:
158. # 代理ip
159. proxies = {'http': eachip}
160. try:
161. response = requests.get(url,
162. headers=fake_headers,
163. proxies=proxies,
164. timeout=6)
165. return eachip # 返回结果值
166. except:
167. print("ip不可用")
168.def wordCloudPic():
169. '''词云图'''
170. data = pd.read_csv('./data/博文数据.csv')
171. print('文本读取...')
172. # 分词
173. cut_text = list(data['内容'])
174. new_text = []
175. all_text = ''
176. for a_str in cut_text:
177. # 去除无用的标点符号
178. remove_chars = '[brp·’!"#$%&'()#!()*+,-./:;<=>?@,:。?¥★、….>【】[]《》?“”‘’[\]^`{|}~]+'
179. a_str = re.sub(remove_chars, "", a_str)
180. result = jieba.cut(a_str)
181. word_list = ','.join(result).split(',')
182. new_word_list = []
183. for word in word_list:
184. if len(word)>1 or word'核': # 只保留字数大于1的词语
185. new_word_list.append(word)
186. new_text.append(new_word_list)
187. for s in new_text:
188. for word in s:
189. all_text += word + ' '
190. mask = np.array(Image.open('bg.png'))
191. wc = WordCloud(
192. stopwords=stopwords,
193. scale=4, # 调整图片大小---(如果设置太小图会很模糊)
194. font_path='simsun.ttc', # 使用的字体库
195. max_words=200, # 词云显示的最大词数
196. margin=1, # 字体之间的间距
197. mask=mask, # 背景图片
198. background_color='white', # 背景颜色
199. max_font_size=50,
200. collocations=False, # 避免重复单词
201. )
202. wc.generate(all_text)
203. # plt.imshow(wc)
204. wc.to_file('词云图.jpg') # 保存到当地文件
205.def piePic():
206. # 绘制饼图
207. data = pd.read_csv('./data/博文数据.csv')
208. ip_list = list(data['IP属地'])
209. new_ip_list = []
210. for date in ip_list:
211. new_ip_list.append(date[4:]) # 处理字符串(发布于XX 截断为 XX)
212. data['IP属地'] = new_ip_list
213. ip_set = set(new_ip_list)
214. ip_groups = data.groupby(by='IP属地') # 数据按IP属地分组
215. ip_count = []
216. for ip in ip_set:
217. a_group = ip_groups.get_group(ip)
218. ip_count.append(len(a_group)) # 该ip属地的博文数量
219. ip_count_data = pd.DataFrame()
220. ip_count_data['IP属地'] = list(ip_set)
221. ip_count_data['数量']=ip_count
222. ip_count_data = ip_count_data.sort_values(by='数量',ascending=False)
223. fig = plt.figure(figsize=(6, 6))
224. ax2 = plt.subplot(1, 1, 1)
225. colors = ["#F08080", "#FF1493", "#6495ED", "#5F9EA0", "#40E0D0", "#FFD700", "#FFFF00","#FF1493", "#6495ED", "#5F9EA0",
226. "#F08080", "#FF1493", "#6495ED", "#5F9EA0", "#40E0D0", "#FFD700", "#FFFF00", "#DDA0DD", "#00FFFF","#4B0082"]
227. ax2.pie(ip_count_data['数量'][:20],colors=colors, labels=ip_count_data['IP属地'][:20], autopct='%.1f%%',startangle=20)
228. # ax2.set_xlabel('')
229. ax2.set_title('不同IP属地的博文数量占比情况')
230. # ax2.set_ylabel('')
231. plt.savefig('./不同IP属地的博文数量占比饼图.png')
232.def barPic():
233. # 绘制柱状图
234. data = pd.read_csv('./data/博文数据.csv')
235. data = data.dropna() # 除去 nan 无效值
236. equ_list = list(data['设备'])
237. equ_set = set(equ_list)
238. equ_groups = data.groupby(by='设备') # 数据按设备分组
239. equ_count = []
240. for equ in equ_set:
241. a_group = equ_groups.get_group(equ)
242. equ_count.append(len(a_group)) # 该设备的数量
243. equ_count_data = pd.DataFrame()
244. equ_count_data['设备'] = list(equ_set)
245. equ_count_data['数量']=equ_count
246. equ_count_data = equ_count_data.sort_values(by='数量',ascending=False)
247. x = range(0, 20)
248. fig = plt.figure(figsize=(10, 6))
249. ax2 = plt.subplot(1, 1, 1)
250. ax2.bar(x, equ_count_data['数量'][:20])
251. plt.xticks(x, equ_count_data['设备'][:20], rotation=50) # rotation=-50表示x轴坐标旋转
252. ax2.set_ylabel(r'数量')
253. ax2.set_title('相关博文中数量排名前20的发布设备')
254. plt.subplots_adjust(left=0.1, right=0.9, top=0.9, bottom=0.25)
255. plt.savefig('相关博文中数量排名前20的发布设备.png')
256. plt.show()
257.def topBlogger():
258. data = pd.read_csv('./data/博文数据.csv')
259. data_sort = data.sort_values('转发数',ascending=False)
260. names= list(data_sort['昵称'])
261. counts = list(data_sort['转发数'])
262. top10_name=[]
263. top10_count = []
264. for i in range(len(names)):
265. if len(top10_name)==10:
266. break
267. if names[i] not in top10_name:
268. top10_count.append(counts[i])
269. top10_name.append(names[i])
270. x = range(0, 10)
271. fig = plt.figure(figsize=(6, 6))
272. ax2 = plt.subplot(1, 1, 1)
273. ax2.bar(x,top10_count )
274. plt.xticks(x, top10_name, rotation=50) # rotation=-50表示x轴坐标旋转
275. ax2.set_ylabel(r'转发量')
276. ax2.set_title('相关博文中转发数量前十的博主')
277. plt.subplots_adjust(left=0.1, right=0.9, top=0.9, bottom=0.25)
278. plt.savefig('相关博文中转发数量前十的博主.png')
279. plt.show()
280.if name == 'main':
281. # 存储博文id
282. all_mid_list = []
283. # 遍历每日的博文,获取博文id
284. for i in range(100,120): # 今天开始往前100天
285. # 对时间参数进行处理
286. s_day = (datetime.datetime.now()+datetime.timedelta(days=(-i))).strftime("%Y-%m-%d")
287. print("日期:" + str(s_day))
288. mid_list = get_mid('日本排放核污水',s_day, 1, 10) # 根据搜索关键词获取博文id
289. all_mid_list+=mid_list
290. # 存储为dataframe格式
291. mids = pd.DataFrame(all_mid_list)
292. mids.to_csv('./data/mid_list.csv',encoding='utf-8')
293. mid_list = pd.read_csv('./data/mid_list.csv') # 读取上一步采集的博文id
294. article_list = get_comment(mid_list) # 根据博文id 采集博文详细信息
295. data = pd.read_csv('./data/data.csv',names=['ID','昵称','内容','时间','转发数','评论数','点赞数','IP属地','设备']) # 读取采集的数据
296. data.to_csv('./data/博文数据.csv',encoding='utf-8') # 另存一份csv格式
297. data.to_excel('./data/博文数据.xls') # 另存一份excel格式
298. '''绘图'''
299. wordCloudPic() # 词云图
300. piePic() # 饼图
301. barPic() # 柱状图
302. topBlogger() # 前十博主
总结:
核污水数据可视化是一个涉及核能安全、环境保护、数据科学和信息传播等多个领域的综合性选题。通过对核污水数据的实时监测和可视化呈现,该选题旨在提高公众的科学素养和环保意识,促进相关决策的科学化和民主化。
在研究和实践过程中,核污水数据可视化涉及到的关键技术包括数据采集、处理、分析和可视化等方面。通过这些技术的应用,可以更加准确地监测核污水的产生和处理过程,发现潜在的问题和风险,为相关决策提供科学依据。
同时,核污水数据可视化还涉及到多个利益相关方的参与和合作。包括核能设施运营商、环境保护机构、数据科学研究者、媒体和公众等。通过多方合作和交流,可以促进信息共享和知识传播,推动核能安全和环保事业的发展。
总体而言,核污水数据可视化是一个具有重要现实意义和实践价值的选题。它不仅有助于提高公众的科学素养和环保意识,还可以促进相关领域的技术创新和发展。在未来,随着数据科学和环保领域的进一步发展,核污水数据可视化将会发挥更加重要的作用,为解决全球环境问题提供更多先进的技术和思路。