一、ShardingSphere中间件:
1、简介:
(1)、概述:
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这三款相互独立的产品组成。他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
1)、Sharding-JDBC:定位为轻量级Java框架,在JDBC层提供额外工具包;
2)、Sharding-Proxy;定位为透明化的数据库代理端 ,提供封装数据库二进制协议的服务端版本;
3)、Sharding-Sidecar:定位为kubernetes的云原生数据库代理(规划中)。
(2)、定位:
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。
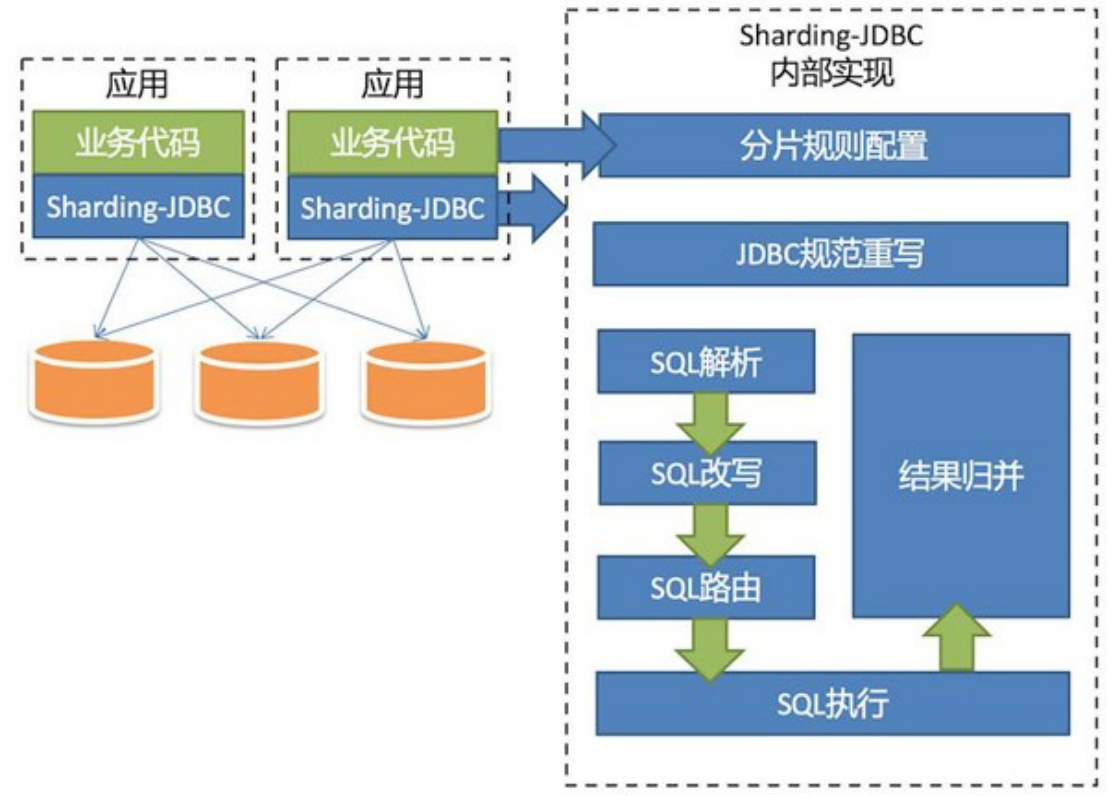
二、四大分片策略:
1、标准分片策略(StandardShardingStrategy):
标准分片策略(StandardShardingStrategy): 只支持对单个分片键为依据的分库分表,并提供了两种分片算法:
(1)、PreciseShardingAlgorithm(精准分片):
在使用标准分片策略时,精准分片算法时必须实现的算法,用于SQL语句含有 >,>=,<=,<,=,IN 和 BETWEEN AND 操作符;
1)、YML:
spring: shardingsphere: sharding: # 默认数据源,未分片的表默认执行库 default-data-source-name: mydb-1 # 表策略配置 tables: # t_user 是逻辑表 t_user: databaseStrategy: standard: # 分片键 shardingColumn: age # 精准分库算法 preciseAlgorithmClassName: com.demo.module.config.MyDBPreciseShardingAlgorithm tableStrategy: standard: # 分片键 shardingColumn: age # 精准分表算法 preciseAlgorithmClassName: com.demo.module.config.MyTablePreciseShardingAlgorithm
2)、精准分库算法:
实现 PreciseShardingAlgorithm 接口,并重写 doSharding()。
public class MyDBPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Integer> { @Override public String doSharding(Collection<String> databaseNames, PreciseShardingValue<Integer> shardingValue) { /** * databaseNames 所有分片库的集合 * shardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片键,value 为从 SQL 中解析出的分片键的值 */ for (String databaseName : databaseNames) { // 根据年龄判断,未成年 -> mydb-1, 已成年 -> mydb-2 String value = String.valueOf(shardingValue.getValue() < 18 ? 1 : 2); if (databaseName.endsWith(value)) { return databaseName; } } throw new IllegalArgumentException("分片失败,databaseNames:" + databaseNames); } }
3)、精准分表算法:
实现 PreciseShardingAlgorithm 接口,并重写 doSharding()。
public class MyTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<Integer> { @Override public String doSharding(Collection<String> tableNames, PreciseShardingValue<Integer> shardingValue) { /** * tableNames 对应分片库中所有分片表的集合 * shardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片键,value 为从 SQL 中解析出来的分片键的值 */ for (String tableName : tableNames) { // 取模算法,分片键 % 表数量 + 1 String value = String.valueOf(shardingValue.getValue() % tableNames.size() + 1); if (tableName.endsWith(value)) { return tableName; } } throw new IllegalArgumentException("分片失败,tableNames:" + tableNames); } }
(2)、RangeShardingAlgorithm(范围分片):
非必选的,用于处理含有 BETWEEN AND 的分片处理。
1)、YML:
spring: shardingsphere: sharding: # 默认数据源,未分片的表默认执行库 default-data-source-name: mydb-1 # 表策略配置 tables: # t_user 是逻辑表 t_user: databaseStrategy: standard: # 分片键 shardingColumn: age # 精准分库算法 preciseAlgorithmClassName: com.demo.module.config.MyDBPreciseShardingAlgorithm # 范围分库算法 rangeAlgorithmClassName: com.demo.module.config.MyDBRangeShardingAlgorithm
2)、代码实现:
实现 PreciseShardingAlgorithm 接口,并重写 doSharding()。
public class MyDBRangeShardingAlgorithm implements RangeShardingAlgorithm<Integer> { /** * 数据库分片符号 */ private final String DATABASE_SPLIT_SYMBOL = "-"; @Override public Collection<String> doSharding(Collection<String> databaseNames, RangeShardingValue<Integer> rangeShardingValue) { Set<String> result = new LinkedHashSet<>(); // between and 的起始值 Range<Integer> valueRange = rangeShardingValue.getValueRange(); boolean hasLowerBound = valueRange.hasLowerBound(); boolean hasUpperBound = valueRange.hasUpperBound(); // 计算最大值和最小值(未成年 -> mydb-1, 已成年 -> mydb-2) int lower; if (hasLowerBound) { lower = valueRange.lowerEndpoint() < 18 ? 1 : 2; } else { lower = getLowerEndpoint(databaseNames); } int upper; if (hasUpperBound) { upper = valueRange.upperEndpoint() < 18 ? 1 : 2; } else { upper = getUpperEndpoint(databaseNames); } // 循环范围计算分库逻辑 for (int i = lower; i <= upper; i++) { for (String databaseName : databaseNames) { String value = String.valueOf(i); if (databaseName.endsWith(value)) { result.add(databaseName); } } } return result; } // -------------------------------------------------------------------------------------------------------------- // 私有方法 // -------------------------------------------------------------------------------------------------------------- /** * 获取 最小分片值 * @param databaseNames 数据库名 * @return 最小分片值 */ private int getLowerEndpoint(Collection<String> databaseNames) { if (CollectionUtils.isNotEmpty(databaseNames)) { return databaseNames.stream().filter(o -> o != null && o.contains(DATABASE_SPLIT_SYMBOL)) .mapToInt(o -> { String[] splits = o.split(DATABASE_SPLIT_SYMBOL); return Integer.valueOf(splits[splits.length - 1]); }).min().orElse(-1); } return -1; } /** * 获取 最大分片值 * @param databaseNames 数据库名 * @return 最大分片值 */ private int getUpperEndpoint(Collection<String> databaseNames) { if (CollectionUtils.isNotEmpty(databaseNames)) { return databaseNames.stream().filter(o -> o != null && o.contains(DATABASE_SPLIT_SYMBOL)) .mapToInt(o -> { String[] splits = o.split(DATABASE_SPLIT_SYMBOL); return Integer.valueOf(splits[splits.length - 1]); }).max().orElse(-1); } return -1; } }
(3)、注意:
一旦我们没配置范围分片算法,而SQL中又用到 BETWEEN AND 或者 LIKE 等,那么 SQL 将按全库、表路由的方式逐一执行,查询性能会很差。
使用四种分片策略的方式大致相同,都要实现相应的 ShardingAlgorithm 接口,并重写 doSharding() 方法,只是配置稍有不同,doSharding() 方法本身只是个空方法,需要我们自行处理分库、分表逻辑。
2、复合分片策略(ComplexShardingStrategy):
SQL语言中有 >,>=,<=,<,=,IN 和 BETWEEN AND 等操作符,不同的是复合分片策略支持对多个分片键操作.
(1)、YML:
spring:
shardingsphere:
sharding:
# 表策略配置
tables:
# t_user 是逻辑表
t_user:
databaseStrategy:
standard:
# 分片键
shardingColumn: age
# 精准分库算法
preciseAlgorithmClassName: com.demo.module.config.MyDBPreciseShardingAlgorithm
# 范围分库算法
rangeAlgorithmClassName: com.demo.module.config.MyDBRangeShardingAlgorithm
(2)、代码实现:
public class MyDBComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<Integer> { /** * 复合分库 * * @param databaseNames 全部库名集合(用于筛选) * @param complexKeysShardingValue 复合分片值 * @return 需要用到的库名集合 */ @Override public Collection<String> doSharding(Collection<String> databaseNames, ComplexKeysShardingValue<Integer> complexKeysShardingValue) { // 精准分片-得到每个分片键对应的值 Collection<Integer> ageValues = this.getPreciseShardingValue(complexKeysShardingValue, "age"); Collection<Integer> salaryValues = this.getPreciseShardingValue(complexKeysShardingValue, "salary"); // 精准分片-根据两个分片键进行分库 List<String> ageSuffix = ageValues.stream().map(o -> o < 18 ? "1" : "2").collect(Collectors.toList()); List<String> salarySuffix = salaryValues.stream().map(o -> o < 5000 ? "1" : "2").collect(Collectors.toList()); List<String> shardingSuffix = getShardingSuffix(ageSuffix, salarySuffix); // 范围分片-得到每个分片键对应的值 Range<Integer> ageRange = this.getRangeShardingValue(complexKeysShardingValue, "age"); Range<Integer> salaryRange = this.getRangeShardingValue(complexKeysShardingValue, "salary"); // 范围分片-根据两个分片键进行分库 ageSuffix = getRangeSuffix(ageRange); salarySuffix = getRangeSuffix(salaryRange); shardingSuffix.addAll(getShardingSuffix(ageSuffix, salarySuffix)); return shardingSuffix.stream().distinct().collect(Collectors.toList()); } // -------------------------------------------------------------------------------------------------------------- // 私有方法 // -------------------------------------------------------------------------------------------------------------- /** * 获取 分库的范围 * @param range 分片值范围 * @return 分库范围 */ private List<String> getRangeSuffix(Range<Integer> range) { boolean isValid = range != null && (range.hasLowerBound() || range.hasUpperBound()); if (isValid) { List<String> rangeSuffix = new ArrayList<>(); int lowerEndpoint = range.hasLowerBound() ? range.lowerEndpoint() < 18 ? 1 : 2 : 1; int upperEndpoint = range.hasUpperBound() ? range.upperEndpoint() < 18 ? 1 : 2 : 2; for (int i = lowerEndpoint; i <= upperEndpoint; i++) { rangeSuffix.add(String.valueOf(i)); } return rangeSuffix; } return new ArrayList<>(0); } /** * 获取 库名集合 * @param ageSuffix age分片值 * @param salarySuffix salary分片值 * @return 库名集合 */ private List<String> getShardingSuffix(List<String> ageSuffix, List<String> salarySuffix) { List<String> dbNames = new ArrayList<>(); ageSuffix = ageSuffix == null ? new ArrayList<>(0) : ageSuffix; salarySuffix = salarySuffix == null ? new ArrayList<>(0) : salarySuffix; for (String age : ageSuffix) { for (String salary : salarySuffix) { dbNames.add(String.format("mydb-%s-%s", age, salary)); } } return dbNames.stream().distinct().collect(Collectors.toList()); } /** * 获取 分片键对应的值 * * @param shardingValue 复合分片值 * @param key 分片键 * @return 值 */ private Collection<Integer> getPreciseShardingValue(ComplexKeysShardingValue<Integer> shardingValue, final String key) { // 判断非空 if (StringUtils.isEmpty(key) || shardingValue == null) { return new ArrayList<>(0); } // 根据 分片键 取值 Collection<Integer> valueSet = new ArrayList<>(); Map<String, Collection<Integer>> columnNameAndShardingValueMap = shardingValue.getColumnNameAndShardingValuesMap(); Map<String, String> columnNameMap = columnNameAndShardingValueMap.keySet().stream().filter(Objects::nonNull) .collect(Collectors.toMap(String::toUpperCase, o -> o, (k1, k2) -> k1)); if (columnNameMap.containsKey(key.toUpperCase())) { String columnName = columnNameMap.get(key.toUpperCase()); valueSet.addAll(columnNameAndShardingValueMap.get(columnName)); } return valueSet; } /** * 获取 分片键对应的值 * * @param shardingValue 复合分片值 * @param key 分片键 * @return 值 */ private Range<Integer> getRangeShardingValue(ComplexKeysShardingValue<Integer> shardingValue, final String key) { // 判断非空 if (StringUtils.isEmpty(key) || shardingValue == null) { return null; } // 根据 分片键 取值 Map<String, Range<Integer>> columnNameAndRangeValuesMap = shardingValue.getColumnNameAndRangeValuesMap(); Map<String, String> columnNameMap = columnNameAndRangeValuesMap.keySet().stream().filter(Objects::nonNull) .collect(Collectors.toMap(String::toUpperCase, o -> o, (k1, k2) -> k1)); if (columnNameMap.containsKey(key.toUpperCase())) { String columnName = columnNameMap.get(key.toUpperCase()); return columnNameAndRangeValuesMap.get(columnName); } else { return null; } } }
3、行表达式分片策略(InlineShardingStrategy):
适用于做简单的分片算法,无需自定义分片算法,省去了繁琐的代码开发,是四种分片策略中最为简单的
相关YML配置:
spring: shardingsphere: sharding: # 表策略配置 tables: # t_user 是逻辑表 t_user: # 分表节点 可以理解为分表后的那些表 比如 t_user_1 ,t_user_2 ,t_user_3 actualDataNodes: mydb.t_user_$->{1..3} tableStrategy: inline: # 根据哪列分表 shardingColumn: age # 分表算法 例如:age为奇数 -> t_user_2; age为偶数 -> t_user_1 algorithmExpression: t_user_$->{age % 2 + 1}
4、Hint分片策略(HintShardingStrategy):
分片键值不从 SQL 中解析,而是由外部进行指定分片信息,让 SQL 在指定的分库、分表中执行。
(1)、使用场景:
如果我们希望用户表 t_user 用 age 做分片键进行分库分表,但是 t_user 表中却没有 age 这个字段,这时可以通过 Hint API 在外部手动指定分片键或分片库
(2)、YML:
spring: shardingsphere: sharding: # 表策略配置 tables: # t_user 是逻辑表 t_user: # 分表节点 可以理解为分表后的那些表 比如 t_user_1 ,t_user_2 actualDataNodes: mydb.t_user_$->{1..2} tableStrategy: hint: # 复合分库算法 algorithmClassName: com.demo.module.config.MyTableHintShardingAlgorithm
(3)、代码实现:
public class MyTableHintShardingAlgorithm implements HintShardingAlgorithm<Integer> { @Override public Collection<String> doSharding(Collection<String> tableNames, HintShardingValue<Integer> hintShardingValue) { List<String> result = new ArrayList<>(); for (Integer shardingValue : hintShardingValue.getValues()) { result.add(shardingValue < 18 ? "t_user_1" : "t_user_2"); } return result; } }
(4)、外部指定:
@Test void hintSaveTest() { // 清除掉上一次的规则,否则会报错 HintManager.clear(); // HintManager API 工具类实例 HintManager hintManager = HintManager.getInstance(); // 直接指定对应具体的数据库 hintManager.addDatabaseShardingValue("mydb",0); // 设置表的分片键值,自定义操作哪个分片中 hintManager.addTableShardingValue("t_user" , 18); // 在读写分离数据库中,Hint 可以强制读主库 hintManager.setMasterRouteOnly(); List<TUser> users = new ArrayList<>(3); users.add(new TUser("ACGkaka_1", "123456", 10, 3000)); users.add(new TUser("ACGkaka_2", "123456", 18, 4000)); users.add(new TUser("ACGkaka_3", "123456", 15, 6000)); users.add(new TUser("ACGkaka_4", "123456", 19, 7000)); userService.saveBatch(users); }
三、相关参考: