go语言调度gmp原理(2)
创建goroutine
通过runtime.newproc函数调用,runtime.newproc的入参是参数大小和表示函数的指针funcval,它会获取goroutine以及调用方的程序计数器,然后调用runtime.newproc1函数获取新的goroutine、结构体、将其加入处理器的运行队列,并在满足条件时调用runtime.wakep唤醒新的处理器执行goroutine
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}
runtime.newproc1会根据传入参数初始化一个g结构体,我们将该函数分成一下三个部分介绍其实现:
- 获取或者创建新的goroutine结构体
- 将传入的参数移到goroutine的栈上
- 更新goroutine调度相关属性
首先了解goroutine结构体的创建过程
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
if fn == nil {
fatal("go of nil func value")
}
mp := acquirem() // disable preemption because we hold M and P in local vars.
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
if newg.stack.hi == 0 {
throw("newproc1: newg missing stack")
}
if readgstatus(newg) != _Gdead {
throw("newproc1: new g is not Gdead")
}
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame
totalSize = alignUp(totalSize, sys.StackAlign)
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
if isSystemGoroutine(newg, false) {
sched.ngsys.Add(1)
} else {
// Only user goroutines inherit pprof labels.
if mp.curg != nil {
newg.labels = mp.curg.labels
}
if goroutineProfile.active {
// A concurrent goroutine profile is running. It should include
// exactly the set of goroutines that were alive when the goroutine
// profiler first stopped the world. That does not include newg, so
// mark it as not needing a profile before transitioning it from
// _Gdead.
newg.goroutineProfiled.Store(goroutineProfileSatisfied)
}
}
// Track initial transition?
newg.trackingSeq = uint8(fastrand())
if newg.trackingSeq%gTrackingPeriod == 0 {
newg.tracking = true
}
casgstatus(newg, _Gdead, _Grunnable)
gcController.addScannableStack(pp, int64(newg.stack.hi-newg.stack.lo))
if pp.goidcache == pp.goidcacheend {
// Sched.goidgen is the last allocated id,
// this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch].
// At startup sched.goidgen=0, so main goroutine receives goid=1.
pp.goidcache = sched.goidgen.Add(_GoidCacheBatch)
pp.goidcache -= _GoidCacheBatch - 1
pp.goidcacheend = pp.goidcache + _GoidCacheBatch
}
newg.goid = pp.goidcache
pp.goidcache++
if raceenabled {
newg.racectx = racegostart(callerpc)
if newg.labels != nil {
// See note in proflabel.go on labelSync's role in synchronizing
// with the reads in the signal handler.
racereleasemergeg(newg, unsafe.Pointer(&labelSync))
}
}
if trace.enabled {
traceGoCreate(newg, newg.startpc)
}
releasem(mp)
return newg
}
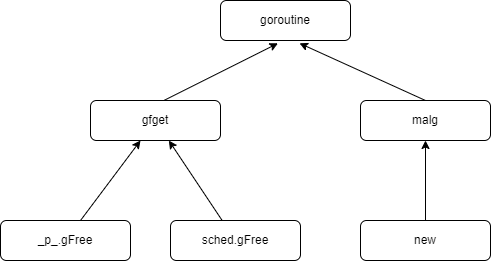
上述代码会先从处理器的gfree列表中查找空闲goroutine,如果不存在空闲goroutine,就会通过runtime.malg创建一个栈大小足够的新结构体
初始化结构体
runtime.gfget通过两种方式获取新的runtime.g
- 从goroutine所在处理器的gFree列表或者调度器的sched.gFree列表中获取runtime.g
- 调用runtime.malg生成一个新的runtime.g,并将结构体追加到全局的goroutine列表allgs中
rutime.gfget中包含两部分逻辑,他们会根据处理器中gFree列表中goroutine的数量做出不同的决策
- 当处理器的goroutine列表为空时,会将调度器持有的空闲goroutine转移到当前处理器上,直到gFree列表中的goroutine数量达到32
- 当处理器的goroutine数量充足时,会从列表头部返回一个新的goroutine
func gfget(pp *p) *g {
retry:
if pp.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) {
lock(&sched.gFree.lock)
// Move a batch of free Gs to the P.
for pp.gFree.n < 32 {
// Prefer Gs with stacks.
gp := sched.gFree.stack.pop()
if gp == nil {
gp = sched.gFree.noStack.pop()
if gp == nil {
break
}
}
sched.gFree.n--
pp.gFree.push(gp)
pp.gFree.n++
}
unlock(&sched.gFree.lock)
goto retry
}
gp := pp.gFree.pop()
if gp == nil {
return nil
}
pp.gFree.n--
if gp.stack.lo != 0 && gp.stack.hi-gp.stack.lo != uintptr(startingStackSize) {
// Deallocate old stack. We kept it in gfput because it was the
// right size when the goroutine was put on the free list, but
// the right size has changed since then.
systemstack(func() {
stackfree(gp.stack)
gp.stack.lo = 0
gp.stack.hi = 0
gp.stackguard0 = 0
})
}
if gp.stack.lo == 0 {
// Stack was deallocated in gfput or just above. Allocate a new one.
systemstack(func() {
gp.stack = stackalloc(startingStackSize)
})
gp.stackguard0 = gp.stack.lo + _StackGuard
} else {
if raceenabled {
racemalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
if msanenabled {
msanmalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
if asanenabled {
asanunpoison(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)
}
}
return gp
}
当调度器的gFree和处理器的gFree列表都不存在结构体时,运行时会调用runtime.malg初始化新的runtime.g结构,如果申请的堆栈大小大于0,这里会通过runtime.stackalloc分配2KB大小的栈空间
func malg(stacksize int32) *g {
newg := new(g)
if stacksize >= 0 {
stacksize = round2(_StackSystem + stacksize)
systemstack(func() {
newg.stack = stackalloc(uint32(stacksize))
})
newg.stackguard0 = newg.stack.lo + _StackGuard
newg.stackguard1 = ^uintptr(0)
// Clear the bottom word of the stack. We record g
// there on gsignal stack during VDSO on ARM and ARM64.
*(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0
}
return newg
}
runtime.malg返回的goroutine会存储到全局变量allgs中
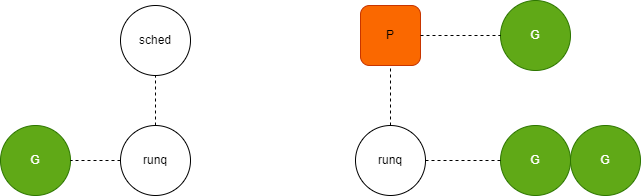
运行队列
runtime.runqput会将goroutine放到运行队列上,这既可能是全局的运行队列也可能是处理器的本地运行队列
func runqput(pp *p, gp *g, next bool) {
if randomizeScheduler && next && fastrandn(2) == 0 {
next = false
}
if next {
retryNext:
oldnext := pp.runnext
if !pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
// Kick the old runnext out to the regular run queue.
gp = oldnext.ptr()
}
retry:
h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with consumers
t := pp.runqtail
if t-h < uint32(len(pp.runq)) {
pp.runq[t%uint32(len(pp.runq))].set(gp)
atomic.StoreRel(&pp.runqtail, t+1) // store-release, makes the item available for consumption
return
}
if runqputslow(pp, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}
代码的核心逻辑如下
- 当next为true时,将goroutine设置到处理器的runnext作为助力器执行的下一个任务
- 当next为false且本地运行队列还有剩余空间时,将goroutine加入处理器持有的本地运行队列
- 当处理器的本地运行队列已经没有剩余空间时,就会把本地队列中的一部分goroutine和待加入的goroutine通过runtime.runqputslow添加到调度器持有的全局队列上
处理器本地的运行队列是数组构成的环形链表,它醉倒可以存储256个待执行任务
go语言有两个运行队列,其中一个是处理器的本地运行队列,另一个是调度器持有的全局运行队列,只有在本地运行队列没有剩余空间时才会使用全局运行队列。
调度信息
运行时创建goroutine时会通过下面的代码设置调度相关信息,前两行代码会分别将程序计数器和goroutine设置成runtime.goexit和新创建goroutine运行的函数
上述调度信息sched不是初始化后的goroutine的最终结果,它还需要经过runtime.gostartcallfn和runtime.gostartcall的处理
func gostartcallfn(gobuf *gobuf, fv *funcval) {
var fn unsafe.Pointer
if fv != nil {
fn = unsafe.Pointer(fv.fn)
} else {
fn = unsafe.Pointer(abi.FuncPCABIInternal(nilfunc))
}
gostartcall(gobuf, fn, unsafe.Pointer(fv))
}
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {
sp := buf.sp
sp -= goarch.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc
buf.sp = sp
buf.pc = uintptr(fn)
buf.ctxt = ctxt
}
调度信息的sp中存储了runtime.goexit函数的程序计数器,而pc中存储了传入函数的程序计数器。因为pc寄存器的作用是存储程序接下来运行的位置,所以pc的使用比较好理解,但是sp中存储的runtime.goexit会让人感到困惑,我们需要配合下面的调度循环来理解它的作用。