| Q | A |
|---|---|
| 这个项目属于哪个课程 | 2023数据采集与融合技术 |
| 组名、项目简介 | 组名:喵喵队、项目需求:设计出一个交互友好的多源异构数据的采集与融合的小应用 、项目目标:通过在网页中上传文本、图片、视频或音频分析其中的情感 、项目开展技术路线:前端3件套、Python、flask |
| 团队成员学号 | 102102143、102102140、102102141、102102152、102102117、102102114、102102121、102102132 |
| 这个项目目标 | 通过在网页中上传文本、图片、视频或音频分析其中的情感 |
项目整体介绍:
项目名称:多模态情感分析系统
项目背景:
- 在当前的数字化时代,情感分析在各种应用中变得越来越重要,如客户服务、市场分析和社交媒体监控。多模态情感分析能够提供比单一模态更丰富、更准确的情感识别和分析。
项目目标:
- 开发一个多模态情感分析系统,能够通过Bv号处理和分析文本、图片、音频和视频数据,从而提供综合的情感分析结果。
技术路线:
-
前端开发:
-
使用HTML、CSS和JavaScript进行界面设计,实现用户与系统的交互。
-
通过用户给出的bv号进行查询
-
-
后端开发:
-
使用Python进行后端逻辑的编写。
-
利用Flask搭建简易后端框架。
-
-
数据处理与分析:
-
文本分析:调用华为云NLP情感分析API。
-
视频分析
- 提取视频中的音频部分。
- 对提取的音频进行分析,使用同音频分析的方法。
-
音频分析
- 使用openai开源的whisper进行音频分析。
- 对上传的音频文件进行特征提取和情感识别。
-
-
结果输出与展示:将分析结果通过前端界面展示。
最终效果:
通过在本地上传文件进行分析并且得到结果
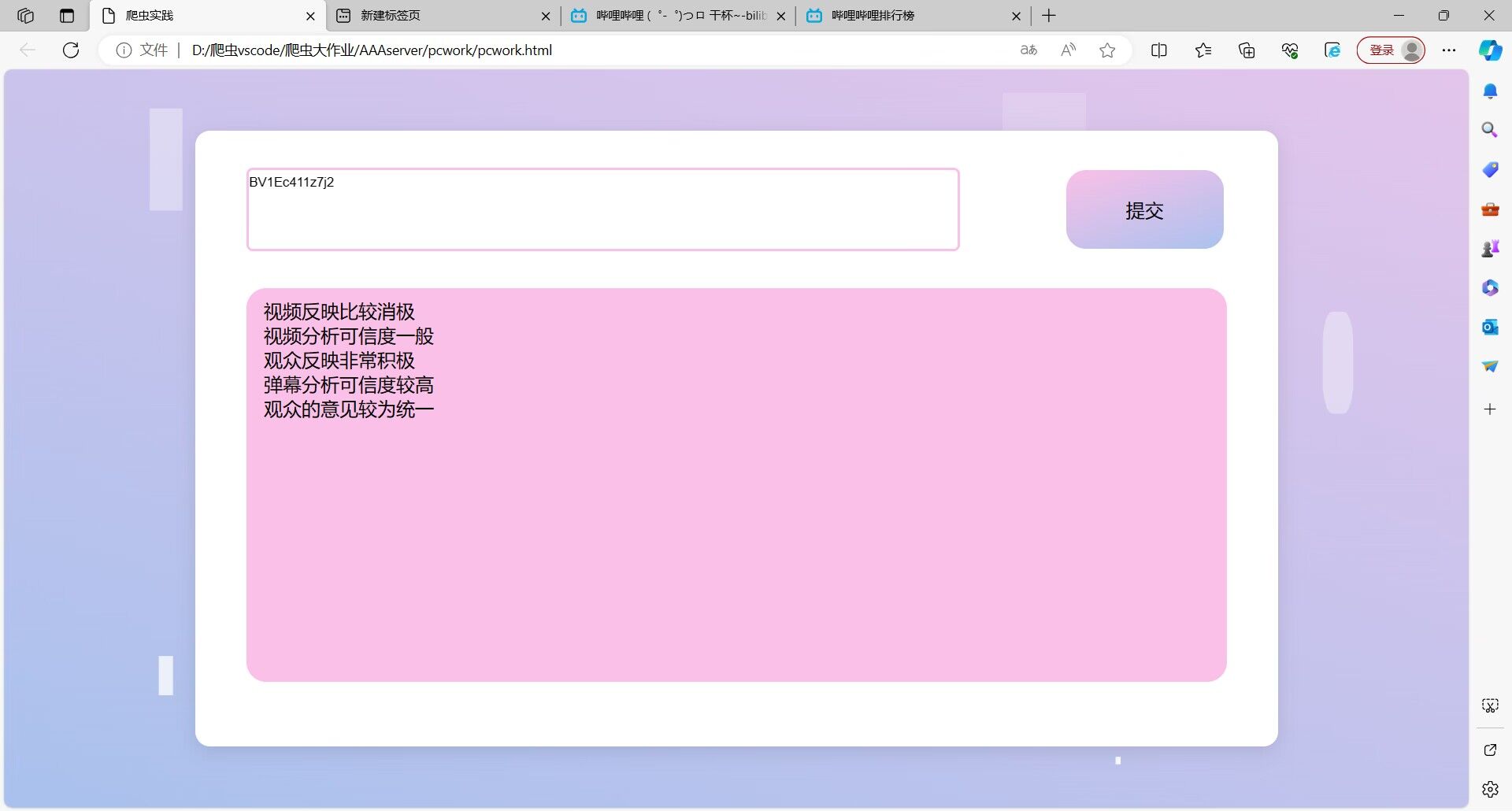
我自己负责的:
我负责的是爬取b战的图像视频,语音,自动识别转文字(存入txt),详细步骤注释在代码中,语音转文字采用whisper库base模型,最后整合在一起为get_bilibili_video函数,让后端容易调用。
import requests
import json
import re
import os
import whisper
# 定义一个函数,接受一个bv号作为参数,返回一个包含视频文件名、音频文件名、转录文本和其他信息的列表
def get_bilibili_video(bv):
# 根据bv号构造视频网址
url = f'https://www.bilibili.com/video/{bv}/'
model = whisper.load_model('base')
# 设置请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76",
"Referer": "https://www.bilibili.com/", # 设置防盗链
}
resp = requests.get(url=url, headers=header)
obj = re.compile(r'window.__playinfo__=(.*?)</script>', re.S)
html_data = obj.findall(resp.text)[0] # 从列表转换为字符串
# 转化为字典的形式
json_data = json.loads(html_data)
# 格式化输出
# pprint(json_data)
# video 和 audio分别是视频和音频 因此爬取下来以后,还需要将两个合并
videos = json_data['data']['dash']['video'] # 这里得到的是一个列表
# 只需要baseUrl即可
# print(videos)
video_url = videos[0]['baseUrl'] # 视频地址
# 同理,音频地址为
audios = json_data['data']['dash']['audio']
audio_url = audios[0]['baseUrl']
# 生成视频文件名和音频文件名,以bv号和p数为前缀
video_name = f'{bv}_p{videos[0]["id"]}.mp4'
audio_name = f'{bv}_p{videos[0]["id"]}.mp3'
# 下载视频和音频
resp1 = requests.get(url=video_url, headers=header)
with open(video_name, mode='wb') as f:
f.write(resp1.content)
resp2 = requests.get(url=audio_url, headers=header)
with open(audio_name, mode='wb') as f:
f.write(resp2.content)
command = r'ffmpeg -i ' + video_name + ' -i ' + audio_name + ' -acodec copy -vcodec copy ' + video_name[
:-4] + '_output.mp4'
os.system(command=command)
# 对音频文件进行语音识别,返回一个字典,包含转录文本和其他信息
result = model.transcribe(audio_name)
# 打印结果
# print(result)
# 将转录文本保存到一个文本文件中
with open(video_name[:-4] + '.txt', "w", encoding="utf-8") as f:
f.write(result["text"])
# 返回一个包含视频文件名、音频文件名、转录文本和其他信息的列表
return [video_name, audio_name, result["text"]]
# 调用函数,输入一个bv号
bv = input("请输入一个bv号:")
result_list = get_bilibili_video(bv)
# 打印结果列表
print(result_list)