本文档译自 preshing.com 的文章"An Introduction to Lock-Free Programming",作者 Jeff Preshing,原文参见此处
概述 - Overview
无锁编程是一项艰难的挑战,不仅因为其本身的复杂性,还因为首先要穿透到这个主题就已经相当困难。
我很幸运,因为我对无锁编程的第一次认识是在 Bruce Dawson 的优秀而全面的白皮书《无锁编程注意事项》。和许多人一样,我获得了将 Bruce 的建议付诸实践的机会,在 Xbox 360 等平台上开发和调试无锁代码。
从那时起,已经出现了很多很好的资料,从抽象理论和正确性证明到实际示例和硬件细节,不一而足。我将在脚注中留下一份参考文献清单。不过要注意,其中的一些信息可能与其他信息的切入点不同:例如,一些资料假设顺序一致性,从而避开了通常困扰无锁 C/C++ 代码的内存序问题。新的 C++ 11 标准原子库给工作带来了另一个难题,挑战了我们许多人表达无锁算法的方式。
在这篇文章中,我想重新介绍无锁编程,首先定义它,然后将大部分信息提炼成几个关键概念。我将用流程图展示这些概念是如何相互关联的,然后深入到细节中去。任何深入研究无锁编程的程序员都应该已经了解如何使用互斥锁和其他高级同步对象(如信号量和事件)编写正确的多线程代码。
无锁编程是什么? - What Is It?
人们通常将无锁编程描述为没有互斥锁的编程,互斥锁也通常直接称为锁。这是事实,但这只是故事的一部分。基于学术文献的普遍接受的定义更宽泛一些。从本质上讲,无锁只是一个用于描述代码的属性,它没有过多地阐释这些代码应该如何编写。
基本上,如果程序的某些部分满足以下条件,那么该部分可以被正确地认为是无锁的。相反,如果代码的给定部分不满足这些条件,那么该部分就不是无锁的。
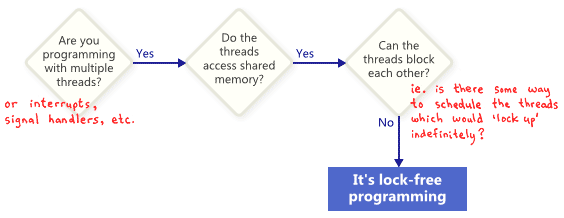
从这个意义上说,无锁中的锁并不是直接指互斥锁,而是指以某种方式“锁定”整个应用程序的可能性,它可能是死锁、活锁,也可能仅仅是某些线程调度决策。最后一种说法听起来不常见,但却是关键。Shared mutexes are ruled out trivially, because as soon as one thread obtains the mutex, your worst enemy could simply never schedule that thread again。当然,真正的操作系统的工作方式没那么简单,这只是定义术语的比方。
下面是一个简单的示例,它不包含互斥锁,但仍然可能导致程序“锁定”。作为对读者的练习,尝试考虑一种调度方式,让两个线程都能不退出循环(最初 X = 0)。
// X = 0;
while (X == 0)
{
X = 1 - X;
}
没人指望大型应用程序完全不使用锁。不过我们总是会需要一些特定的无锁操作。例如,在无锁队列中,可能有一些无锁操作,如 push、pop,可能还有 isEmpty 等等。
Herlihy & Shavit,《多处理器编程艺术》一书的作者,倾向于用类的方法来表达这样的操作,然后得出了无锁的简洁定义(见幻灯片150):"In an infinite execution, infinitely often some method call finishes." 换句话说,只要程序能够继续调用那些无锁操作,最终完成操作的数量就一定会不断增加。也就是说,从算法角度看,在进行这些操作期间系统没有“锁定”的可能。
这样一来,无锁编程的一个重要观察结果是,如果某个线程被挂起,它也不会阻止其他线程通过它们自己的无锁操作继续执行任务(有锁编程里,一旦某个占有锁的线程被挂起,其他线程只能干瞪眼了)。这暗示了在编写中断处理程序和实时系统时无锁编程的价值,在这些系统中,某些任务必须在特定的时间限制内完成,而不管程序的其余部分处于什么状态。
无锁编程技术 - Lock-Free Programming Techniques
事实证明,当你试图满足无锁编程的非阻塞条件时,会出现一系列技术:原子操作、内存屏障、避免 ABA 问题,仅举几例。这些就是让无锁编程很快变得可怕的地方。
那么这些技术是如何相互关联的呢?为了说明这一点,我把下面的流程图放在一起。我将在下面详细说明每一项。
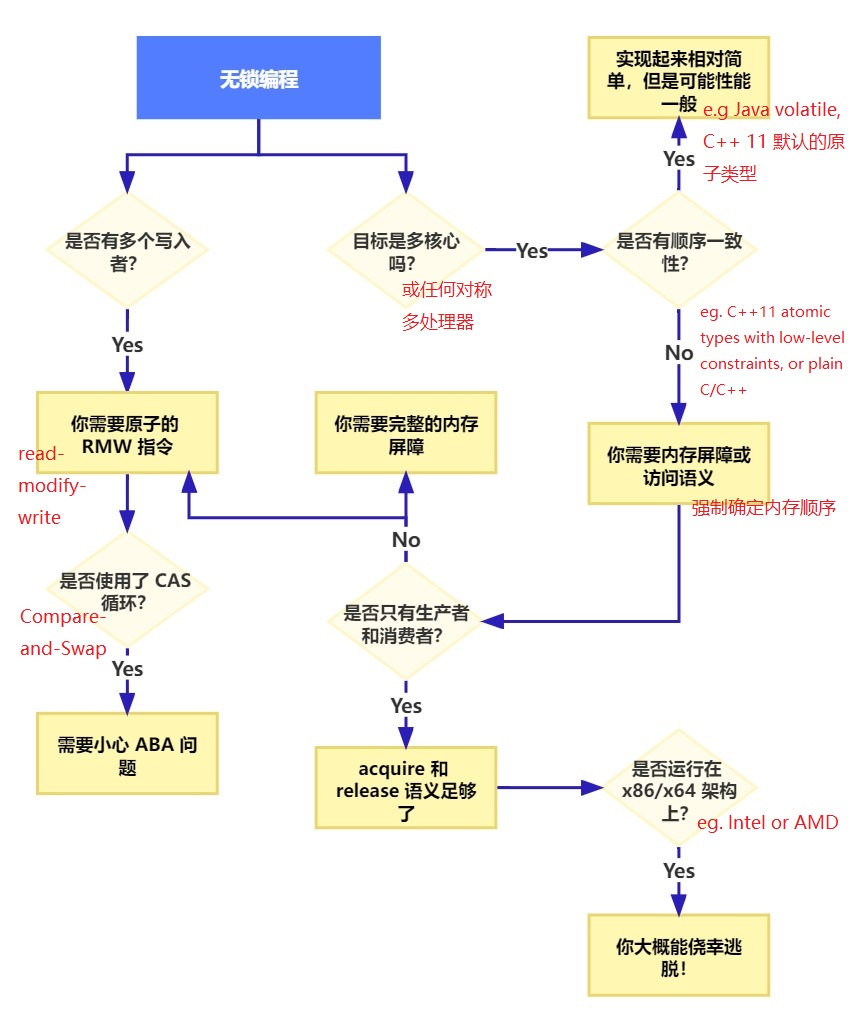
原子的读取、修改、写入操作 - Atomic Read-Modify-Write Operations
原子操作是以一种看起来不可分割的方式操作内存的操作:没有线程可以观察到此操作半途而废。在现代处理器上,许多操作已经是原子化的。例如,简单类型的对齐读写通常是原子的。
读-改-写(RMW)操作更进一步,允许你原子地执行更复杂的事务。当无锁算法必须支持多个写入者时,它们特别有用,因为当多个线程尝试在同一地址上执行 RMW 操作时,它们将有效地排成一行并一次一个地执行这些操作。在之前的博客中,我已经谈到了 RMW 操作,比如在实现轻量级互斥锁、递归互斥锁和轻量级日志系统时。
RMW 操作的例子包括 Win32 上的 InterlockedIncrement,iOS 上的 OSAtomicAdd32, C++ 11 中的 std::atomic<int>::fetch_add。请注意,C++ 11 原子标准并不能保证实现在每个平台上都是无锁的,因此最好了解你的平台和工具链的功能。你可以调用 std::atomic<>::is_lock_free 来确认。
不同的 CPU 系列以不同的方式支持 RMW。PowerPC 和 ARM 等处理器公开了store-link/load-conditonal指令,这些指令有效地允许你在较低级别实现自己的 RMW 原语,尽管这并不常见。常见的 RMW 操作通常是足够的。
如流程图所示,即使在单处理器的系统上,原子 RMW 也是无锁编程的必要部分。如果没有原子性,线程可能会在事务进行到一半时中断,从而可能导致不一致的状态。
CAS循环 - Compare-And-Swap Loops
也许最常讨论的 RMW 操作是 Compare-And-Swap(CAS)。在 Win32 上,CAS 是通过 InterlockedCompareExchange 等一系列内置函数提供的。通常,程序员会在循环中执行 CAS 以重复尝试事务。此模式通常用于将共享变量复制到局部变量,然后执行一些尝试性工作,最后试图使用 CAS 发布更改:
void LockFreeQueue::push(Node* newHead)
{
for (;;)
{
// Copy a shared variable (m_Head) to a local.
Node* oldHead = m_Head;
// Do some speculative work, not yet visible to other threads.
newHead->next = oldHead;
// Next, attempt to publish our changes to the shared variable.
// If the shared variable hasn't changed, the CAS succeeds and we return.
// Otherwise, repeat.
if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead)
return;
}
}
看起来循环锁定了控制流,但这样的循环仍然符合无锁的条件,因为如果一个线程的测试失败,就意味着它在另一个线程的测试中一定成功了。无论何时实现 CAS 循环,都必须特别注意避免 ABA 问题。
顺序一致性 - Sequential Consistency
顺序一致性意味着所有线程都对内存操作的发生顺序达成一致,并且该顺序与程序源代码中的操作顺序也一致。在顺序一致性下,不会经历像我在前一篇文章中演示的那个内存序重排的恶作剧。
实现顺序一致性的一种简单(但显然不切实际)的方法是禁用编译器优化,并强制所有线程在单个处理器上运行。处理器永远不会看到自己的内存执行结果出了问题,即使线程在任意时间被抢占和调度。
有些编程语言甚至在多处理器环境中运行的优化代码提供了顺序一致性。在 C++ 11 中,你可以将所有共享变量声明为带有默认内存排序约束的 C++ 11 原子类型。在 Java 中,可以将所有共享变量标记为 volatile。这是我之前的文章中的例子,用 C++ 11 风格重写:
std::atomic<int> X(0), Y(0);
int r1, r2;
void thread1()
{
X.store(1);
r1 = Y.load();
}
void thread2()
{
Y.store(1);
r2 = X.load();
}
因为 C++11 原子类型保证了顺序一致性,所以结果 r1 = r2 = 0 是不可能的。为了实现这一点,编译器会在后台输出额外的指令——通常是 Memmory Fence 和/或 RMW 操作。与程序员直接处理内存排序的指令相比,这些附加指令可能会使实现效率降低。
内存序 - Memory Ordering
正如流程图所示,每当你为多核(或任何对称多处理器)进行无锁编程时,如果你的环境没法保证顺序一致性,则必须考虑如何防止内存重排序。
在当今的体系结构中,执行正确内存排序的工具通常分为三类,它们既可以防止编译器重排序,也可以防止处理器重排序:
- 一个轻量级的 Sync 或 Fence 指令,我将在以后的帖子中讨论。
- 一个完整的 Memmory Fence 指令,我在前面已经演示过了。
- 提供获取(acquire)或释放(release)语义的内存操作。
acquire 语义防止对后面的操作进行内存序重排,release 语义防止对前面的操作进行内存序重排。这些语义特别适用于生产者/消费者关系的情况,其中一个线程发布一些信息,另一个线程读取信息。我也将在未来的文章中详细讨论这一点。
不同的处理器有不同的内存模型 - Different Processors Have Different Memory Models
当涉及到内存重排序时,不同的 CPU 系列有不同的习惯。这些规则由每个 CPU 供应商编写,硬件严格遵循这些规则。例如,PowerPC 和 ARM 处理器可以改变内存写入相对于指令本身的顺序,但通常情况下,英特尔和 AMD 的 x86/64 系列处理器不会。我们会认为前者的处理器有一个更宽松的内存模型。
那么,就出现了一种将这些特定于平台的细节抽象出来的想法,特别是 C++ 11 已经为我们提供了一种编写可移植无锁代码的标准方法。但目前,我认为大多数无锁程序员至少应该对平台差异有一些认识。如果有一个最关键的区别需要记住的话,那就是在 x86/64 的指令级别,每次从内存加载都带有 acquire 语义,而每次存储到内存都提供 release 语义——至少对于非 SSE 指令和非写合并(Write-Combined)内存来说是这样。因此,在过去,编写无锁代码是很常见的,这种代码在 x86/64 上能工作,但在其他处理器上会失败。
如果你对处理器如何以及为什么执行内存重排序的硬件细节感兴趣,我推荐《并行编程难吗》中的附录C。在任何情况下,请记住,由于编译器对指令进行重排序,因此也可能发生内存重排序。
在这篇文章中,我没有说太多关于无锁编程的实际方面,比如:我们什么时候该实施无锁编程?我们到底需要实施多少?我也没有提到验证无锁算法的重要性。尽管如此,我希望对于一些读者来说,这篇介绍已经提供了对无锁概念的基本认识,这样你就可以继续阅读其他内容,而不会感到太困惑。像往常一样,如果你发现任何不准确的地方,请在评论中告诉我。
其它参考资料
- Anthony Williams 的博客 和他的书, C++ Concurrency in Action
- Dmitriy V’jukov 的网站 和各种 论坛的讨论
- Bartosz Milewski 的博客
- Charles Bloom 博客中的 Low-Level Threading 系列
- Doug Lea 的 JSR-133 Cookbook
- Howells 和 McKenney 关于 memory-barriers.txt 的文档
- Hans Boehm 收集的关于 C++11 内存模型的 链接
- Herb Sutter 的 Effective Concurrency 系列