实现啦!
数据爬取
对于Python爬取数据这一内容,直接使用短短的几行代码就能够实现:
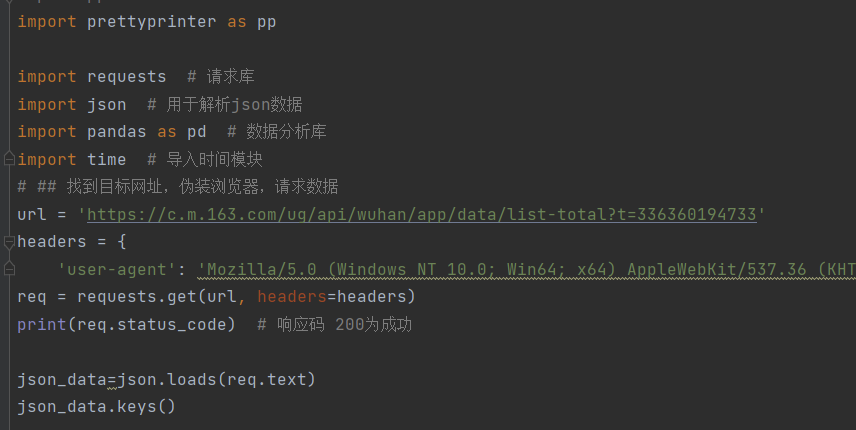
然后根据数据的具体情况,将相关数据存储到后缀名为.csv的文件中:


数据可视化
将存储到.csv文件的数据读取出来,然后将他与Python的数据可视化联系起来,这样就很轻松地实现数据可视化啦!
import requests # 请求库
import json # 用于解析json数据
import pandas as pd # 数据分析库
import time # 导入时间模块
# 找到目标网址,伪装浏览器,请求数据
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=328100359682'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
req = requests.get(url, headers=headers)
print(req.status_code) # 响应码 200为成功
# print(req.text)
# ## 使用Json模块对响应内容进行初步解析
data_json = json.loads(req.text) # 使用json.loads将json字符串转化为字典
ata_json.keys()
data = data_json['data']
data.keys()
import pprint
pp = pprint.PrettyPrinter(indent=2) # 2个空格缩进
# pp.pprint(data['areaTree']) #查看data数据结构
# ## 世界各国实时数据爬取
# ### 获取areaTree数据
areaTree = data['areaTree'] # 获取各国数据
pp.pprint(data['areaTree'][0]) # 查看data['areaTree']数据格式
# ### 封装函数并获取数据
# 将提取数据的方法进行封装
def get_data(data, info_list):
info = pd.DataFrame(data)[info_list] # 主要信息
today_data = pd.DataFrame([i['today'] for i in data]) # 提取today的数据
today_data.columns = ['today_' + i for i in today_data.columns] # 更改列名
total_data = pd.DataFrame([i['total'] for i in data]) # 提取total的数据
total_data.columns = ['total_' + i for i in total_data] # 更改列名
return pd.concat([info, today_data, total_data], axis=1) # 将info.today,total数据进行合并
today_world = get_data(areaTree, ['id', 'lastUpdateTime', 'name']) # 调用封装的函数获取数据
today_world.head()
# ### 封装函数并存储数据
def save_data(data, name):
file_name = name + '_' + time.strftime('%Y_%m_%d', time.localtime(time.time())) + '.csv'
data.to_csv(file_name, sep=',', encoding='utf-8-sig')
print(file_name + ' 保存成功! ')
save_data(today_world, 'today_world') # 调用函数保存数据
country_dict = {num: name for num, name in zip(today_world['id'], today_world['name'])}
start = time.time()
for country_id in country_dict:
try:
# 按照各国id,访问各国的数据,并获取json数据
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + country_id
req2 = requests.get(url, headers=headers)
data_json = json.loads(req2.text)
# 提取各国的数据,然后写入各国的名称
country_data = get_data(data_json['data']['list'], 'date')
country_data['name'] = country_dict[country_id]
# 合并数据
if country_id == '9577772':
alltime_country = country_data
else:
alltime_country = pd.concat([alltime_country, country_data])
print('-' * 20, country_dict[country_id], '抓取成功', country_data.shape,
'以获取数据大小', alltime_country.shape, '累计耗时', round(time.time() - start), '-' * 20)
# time.sleep(5)
except:
print('-' * 20, country_dict[provience_id], '数据抓取失败', '-' * 20)
save_data(alltime_country, 'alltime_country')
# ## 数据处理
# ### 更换数据列名
td_wd = pd.read_csv('today_world_2021_12_26.csv')
ac = pd.read_csv('alltime_country_2021_12_26.csv')
name_dict = {
'id': '编号', 'lastUpdateTime': '更新时间', 'name': '名称', 'today_confirm': '当日新增确诊',
'today_suspect': '当日新增疑似', 'today_heal': '当日新增治愈', 'today_dead': '当日新增死亡', 'today_severe': '当日新增重症',
'today_storeConfirm': '当日现存确诊', 'today_input': '当日新增输入', 'total_confirm': '累计确诊', 'total_suspect': '累计疑似',
'total_heal': '累计治愈', 'total_dead': '累计死亡', 'total_severe': '累计重症', 'total_input': '累计输入'
}
td_wd.rename(columns=name_dict, inplace=True)
ac.rename(columns=name_dict, inplace=True)
td_wd.head()
# ### 数据描述
td_wd = td_wd.drop(columns=['Unnamed: 0'])
ac = ac.drop(columns=['Unnamed: 0'])
td_wd.describe()
td_wd['当日现存确诊'] = td_wd['累计确诊'] - td_wd['累计治愈'] - td_wd['累计死亡']
td_wd['病死率'] = (td_wd['累计死亡'] / td_wd['累计确诊']).apply(lambda x: format(x, '.2f'))
td_wd['病死率'] = td_wd['病死率'].astype('float')
ac['当日现存确诊'] = ac['累计确诊'] - ac['累计治愈'] - ac['累计死亡']
ac['病死率'] = (ac['累计死亡'] / ac['累计确诊']).apply(lambda x: format(x, '.2f'))
ac['病死率'] = ac['病死率'].astype('float')
print('统计nan值:')
td_wd_nan = td_wd.isnull().sum() / len(td_wd)
td_wd_nan.apply(lambda x: format(x, '.1%'))
td_wd.sort_values('病死率', ascending=False, inplace=True)
td_wd.head()
td_wd.set_index('名称', inplace=True) # 索引改为国家名称
wd_top10 = td_wd.sort_values('病死率', ascending=False)[:10]
wd_top10 = wd_top10[['累计确诊', '累计死亡', '病死率']]
wd_top10
cn = []
for i in wd_top10.index[:5]:
cn.append(i)
# ## 数据可视化
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['figure.dpi'] = 120
wd_top10.sort_values('病死率').plot.barh(subplots=True, layout=(1, 3), sharex=False, sharey=True, figsize=(7, 4))
plt.show()
ac.describe()
print('统计nan值:')
ac_nan = ac.isnull().sum() / len(ac)
ac_nan.apply(lambda x: format(x, '.1%'))
hisc = {} # 存储最近几天历史数据的字典
ac['date'] = ac['date'].apply(lambda x: x[-5:])
ac
for i in ac.index:
name = ac['名称'][i]
if name not in hisc.keys():
hisc[name] = []
hisc[name].append(list(ac.loc[i]))
else:
hisc[name].append(list(ac.loc[i]))
# cn = list(hisc.keys())
ds1 = {}
q = 0
for i in cn:
if i not in ds1.keys():
ds1[i] = []
for j in hisc[i]:
ds1[i].append(j[0])
else:
for j in hisc[i]:
ds1[i].append(j[0])
d = 0
for i in cn:
d += 1
if d == 1:
p_a = ds1[i]
continue
else:
p_b = ds1[i]
p_a = set(p_a) & set(p_b)
ppd = list(p_a)
ds2 = {}
ppd.sort()
s = 0
for i in cn:
for j in hisc[i]:
if j[0] in ppd:
if i not in ds2.keys():
ds2[i] = []
ds2[i].append(j[1])
else:
ds2[i].append(j[1])
ds2k = list(ds2.keys())
for i in ds2k:
plt.plot(ppd, ds2[i])
plt.xticks(rotation=60) # 横坐标每个值旋转60度
plt.xticks(range(0, len(ppd), 3))
plt.legend(cn)
plt.title('当日新增确诊')
plt.show()
s = 0
ds2 = {}
for i in cn:
for j in hisc[i]:
if j[0] in ppd:
if i not in ds2.keys():
ds2[i] = []
ds2[i].append(j[2])
else:
ds2[i].append(j[2])
ds2k = list(ds2.keys())
for i in ds2k:
plt.plot(ppd, ds2[i])
plt.xticks(rotation=60) # 横坐标每个值旋转60度
plt.xticks(range(0, len(ppd), 3))
plt.legend(cn)
plt.title('当日新增治愈')
plt.show()
s = 0
ds2 = {}
for i in cn:
for j in hisc[i]:
if j[0] in ppd:
if i not in ds2.keys():
ds2[i] = []
ds2[i].append(j[3])
else:
ds2[i].append(j[3])
ds2k = list(ds2.keys())
for i in ds2k:
plt.plot(ppd, ds2[i])
plt.xticks(rotation=60) # 横坐标每个值旋转60度
plt.xticks(range(0, len(ppd), 3))
plt.legend(cn)
plt.title('当日新增死亡')
plt.show()
s = 0
ds2 = {}
for i in cn:
for j in hisc[i]:
if j[0] in ppd:
if i not in ds2.keys():
ds2[i] = []
ds2[i].append(j[-1])
else:
ds2[i].append(j[-1])
ds2k = list(ds2.keys())
for i in ds2k:
plt.plot(ppd, ds2[i])
plt.xticks(rotation=60) # 横坐标每个值旋转60度
plt.xticks(range(0, len(ppd), 3))
plt.legend(cn)
plt.title('病死率')
plt.show()
s = 0
ds2 = {}
for i in cn:
for j in hisc[i]:
if j[0] in ppd[-1]:
if i not in ds2.keys():
ds2[i] = []
ds2[i].append(j[7])
else:
ds2[i].append(j[7])
ds2k = list(ds2.keys())
sd = []
for i in ds2k:
sd.append(ds2[i][0])
print(sd)
plt.bar(cn, sd)
plt.xticks(rotation=60) # 横坐标每个值旋转60度
plt.legend(cn)
plt.title('累计治愈')
plt.show()