图形渲染处理器技术分析(上)
1 指令处理概览
我们可以将处理器的操作大致分为五个阶段,如下图所示。

指令处理的五个阶段:指令获取、操作数获取、执行、内存访问、寄存器写入。

指令的多时钟周期管线图。图中时间从左到右在页面上前进,指令从页面的顶部到底部前进。管线阶段的表示沿指令轴放置在每个部分,占据适当的时钟周期。图中显示了每个阶段之间的管线寄存器,数据路径以图形方式表示管线的五个阶段,但命名每个管线阶段的矩形也同样有效。
第1步是从内存中获取指令。机器的底层组织并不重要,该机器可以是冯·诺依曼机器(共享指令和数据存储器),也可以是哈佛机器(专用指令存储器)。提取阶段有逻辑元件来计算下一条指令的地址,如果当前指令不是分支,那么需要将当前指令的大小(4字节)添加到存储在PC中的地址。但如果当前指令是分支,那么下一条指令的地址取决于分支的结果和目标。此信息从处理器中的其他单元获得。
第2步是解码“指令并从寄存器中取出操作数。不同指令类型所需的处理非常不同,例如加载存储指令使用专用的存储单元,而算术指令则不使用。为了解码指令,处理器有专用的逻辑电路,根据指令中的字段生成信号,这些信号随后被其他模块用来正确处理指令。像Intel处理器这样的商用处理器有非常复杂的解码单元,解码x86指令集非常复杂。不管解码的复杂程度如何,解码过程通常包括以下步骤:
- 提取操作数的值,计算嵌入的立即数并将其扩展到32或64位,以及生成关于指令处理的附加信息。
- 生成关于指令的更多信息的过程包括生成处理器专用信号。例如,可以为加载/存储指令生成“启用内存单元”形式的信号,对于存储指令,可以生成一个禁用寄存器写入功能的信号。
第3步是执行算术和逻辑运算。它包含一个能够执行所有算术和逻辑运算的算术和逻辑单元(ALU),ALU还需要计算加载存储操作的有效地址,通常情况下处理器的这一部分也计算分支的结果。
ALU(算术逻辑单元)包含用于对数据值执行算术和逻辑计算的元素,通常包含加法器、乘法器、除法器,并具有计算逻辑位运算的单元。
第4步包含用于处理加载存储指令的存储单元。该单元与存储器系统接口,并协调从存储器加载和存储值的过程。典型处理器中的内存系统相当复杂,其中一些复杂性是在处理器的这一部分中实现的。
第5步是将ALU计算的值或从存储器单元获得的加载值写入寄存器文件。
单个指令所需的处理称为指令周期。使用前面给出的简化的两步描述,指令周期如下图所示,这两个步骤被称为获取周期和执行周期。只有在机器关闭、发生某种不可恢复的错误或遇到使计算机停止的程序指令时,程序执行才会停止。

基本指令周期。
考虑一个使用假设机器的简单示例,该机器包括下图中列出的特性。处理器包含一个称为累加器(AC)的数据寄存器,指令和数据都是16位长,因此使用16位字组织内存是方便的。指令格式为操作码提供4位,因此可以有多达24=1624=16个不同的操作码,并且可以直接寻址多达212=4096212=4096(4K)个字的内存。

假想机器的特性。
下图说明了部分程序执行,显示了内存和处理器寄存器的相关部分。所示的程序片段将地址940处的存储字的内容添加到地址941处的内存字的内容,并将结果存储在后一位置。需要三条指令,可以描述为三个获取和三个执行周期:
1、PC包含300,即第一条指令的地址。该指令(十六进制值1940)被加载到指令寄存器IR中,PC递增。注意,此过程涉及使用内存地址寄存器和内存缓冲寄存器。为了简单起见,这些中间寄存器被忽略。
2、IR中的前4位(第一个十六进制数字)表示要加载AC,剩余的12位(三个十六进制数字)指定要加载数据的地址(940)。
3、从位置301获取下一条指令(5941),并且PC递增。
4、添加AC的旧内容和位置941的内容,并将结果存储在AC中。
5、从位置302取出下一条指令(2941),并且PC递增。
6、AC的内容存储在位置941中。

程序执行示例(内存和寄存器的内容为十六进制)。
特定指令的执行周期可能涉及对内存的不止一次引用。此外,指令可以指定I/O操作,而不是内存引用。考虑到这些额外的考虑因素,图下图提供了基本指令周期的更详细的视图,该图采用状态图的形式。对于任何给定的指令周期,某些状态可能为空,而其他状态可能被访问多次。


指令周期状态图。
状态描述如下:
- 指令地址计算(iac):确定要执行的下一条指令的地址,通常需要在前一条指令的地址上添加一个固定的数字,例如如果每条指令的长度为16位,并且内存被组织为16位字,则在前一个地址上加1。相反,如果内存被组织为可单独寻址的8位字节,则在前一个地址上加2。
- 指令获取(if):将指令从其内存位置读入处理器。
- 指令操作解码(iod):分析指令以确定要执行的操作类型和要使用的操作数。
- 操作数地址计算(oac):如果操作涉及对内存中的操作数的引用或通过I/O可用的操作数,则确定操作数的地址。
- 操作数获取(of):从内存中获取操作数或从I/O中读取操作数。
- 数据操作(do):执行指令中指示的操作。
- 操作数存储(os):将结果写入内存或输出到I/O。
下图显示了包括中断周期处理的修订指令周期状态图:

下图左是非直接时钟周期,右是中断时钟周期:

下图通过指出每种模块类型的主要输入和输出形式,说明了所需的交换类型:

微处理器寄存器组织示例:

2 处理器结构
2.1 处理器单元
处理器内部包含了诸多单元,诸如获取单元、数据路径和控制单元、操作数获取单元、执行单元(分支单元、ALU)、内存访问单元、寄存器回写单元等等。
下图显示了获取单元电路的实现。在一个周期中需要执行两个基本操作:1、下一个PC(程序计数器)的计算;2、获取指令。

电路中有两种元件:
- 第一类元件是寄存器、存储器、算术和逻辑电路,用于处理数据值。
- 第二类元素是决定数据流方向的控制单元。处理器中的控制单元通常生成信号以控制所有多路复用器(multiplexer),被称为控制信号(control signal),因为其作用是控制信息流。
因此,我们可以从概念上认为处理器由两个不同的子系统组成:
- 数据路径(data path)。它包含存储和处理信息的所有元素。例如,数据存储器、指令存储器、寄存器文件和ALU(算术逻辑单元)是数据路径的一部分。内存和寄存器存储信息,而ALU处理信息,例如,它将两个数字相加,并产生和作为结果,或者它可以计算两个数字的逻辑函数。
- 控制路径(control path)。它通过生成信号来引导信息的正确流动,生成一个信号,指示多路复用器在分支目标和默认下一个PC之间进行选择。在这种情况下,多路复用器由信号isBranchTaken控制。
我们可以将控制路径和数据路径视为电路的两个不同元件,就像城市的交通网络一样。道路和红绿灯类似于数据路径,控制交通灯的电路构成了控制路径,控制路径决定灯光转换的时间。在现代智慧城市中,控制城市中所有交通灯的过程通常是集成的。如果有可能智能控制交通,使汽车绕过交通堵塞和事故现场。类似地,处理器的控制单元相当智能,它的工作是尽可能快地执行指令。现代处理器的控制单元已经非常复杂。
数据路径(data path):数据路径由处理器中专用于存储、检索和处理数据的所有元素组成,如寄存器、内存和ALU。
控制路径(control path):控制路径主要包含控制单元,其作用是生成适当的信号来控制数据路径中指令和数据的移动。

数据路径和控制路径之间的关系。
现在看看执行指令。首先将指令分为两种类型:分支和非分支。分支指令由计算分支结果和最终目标的专用分支单元处理,非分支指令由ALU(算术逻辑单元)处理。分支单元的电路如下图所示:

使用多路复用器在返回地址(op1)的值和指令中嵌入的branchT目标之间进行选择。isRet信号控制多路复用器,如果它等于1就选择op1,否则选择分支目标。多路复用器branchPC的输出被发送到提取单元。
下图显示了包含ALU的执行单元部分。ALU的第一个操作数(A)始终为op1(从操作数获取单元获得),但第二个操作数(B)可以是寄存器或符号扩展立即数,由控制单元生成的isImmediate信号决定,isImmediate信号等于指令中立即数位的值,如果是1,则图中的多路复用器选择immx作为操作数,如果为0,则选择op2作为操作数。ALU将一组信号作为输入,统称为aluSignals,aluSignals由控制单元生成,并指定ALU操作的类型。ALU的结果称为aluResult。

下图显示了ALU的一种设计。ALU包含一组模块,每个模块计算单独的算术或逻辑函数,如加法或除法。其次,每个模块都有一个启用或禁用它的专用信号,例如,当我们想执行简单的加法时,没有理由启用除法器。有几种方法可以启用或禁用单元,最简单的方法是为每个输入位使用一个传输门(transmission gate,见下下图),如果信号(S)打开,则输出反映输入值。否则,它将保持其以前的值。因此,如果启用信号关闭,则模块不会看到新的输入。因此,它不会耗散功率,并被有效禁用。

ALU。

传输门。
总之,下图展示了执行单元(分支单元和ALU)的完整设计。要设置输出(aluResult),需要一个多路复用器,可以从ALU中的所有模块中选择正确的输出,没有在图中显示此多路复用器。

执行单元(分支和ALU单元)。
下图显示了内存访问单元。它有两个输入{数据和地址,地址由ALU计算,它等于ALU的结果(aluResult),加载和存储指令都使用这个地址,地址保存在传统上称为MAR(内存地址寄存器)的寄存器中。

内存单元。
通过连接所有部分来形成整体。到目前为止,已经将处理器分为五个基本单元:指令获取单元(IF)、操作数获取单元(OF)、执行单元(EX)、内存访问单元(MA)和寄存器写回单元(RW)。是时候把所有的部分结合起来,看看统一的图片了(下图,省略了详细的电路,只关注数据和控制信号的流动)。

一个基础处理器。
2.2 控制单元
一个简单处理器的硬接线控制单元可以被认为是一个黑盒子,它以6位作为输入(5个操作码位和1个立即数位),并产生22个控制信号作为输出。如下图所示。

硬接线控制单元的抽象。

控制单元的结构图。
硬接线控制单元快速高效,这就是今天大多数商用处理器使用硬接线控制单元的原因,但硬接线控制单元并不十分灵活,例如在处理器出厂后,不可能更改指令的行为,甚至不可能引入新指令。有时如果功能单元中存在错误,需要更改指令的执行方式,例如如果乘法器存在设计缺陷,那么理论上可以使用加法器和移位单元运行布斯乘法算法。然而,我们需要一个非常复杂的控制单元来动态地重新配置指令的执行方式。
支持灵活的控制单元还有其他更实际的原因。某些指令集(如x86)具有重复指令给定次数的rep指令,它们还具有复杂的字符串指令,可以处理大量数据,支持此类指令需要非常复杂的数据路径。原则上,我们可以通过精心设计的控制单元来执行这些指令,而这些控制单元又有简单的处理器来处理这些指令,这些子处理器可以生成用于实现复杂CISC指令的控制信号。
数据路径和控制信号。

带内部总线的CPU。
2.3 基于微程序的处理器
前面已经研究了带有硬接线控制单元的处理器,设计了一个包含处理和执行指令所需的所有元素的数据路径。在输入操作数之间有选择的地方,添加了一个多路复用器,它由来自控制单元的信号控制。控制单元将指令的内容作为输入,并生成所有控制信号。现代高性能处理器通常采用这种设计风格。请注意,效率是有代价的,成本是灵活性。我们可能需要添加更多的多路复用器,并为每个新指令生成更多的控制信号。其次,在处理器交付给客户后,不可能向处理器添加新指令。有时候,我们渴望这样的灵活性。
通过引入将ISA中的指令转换为一组简单微指令的转换表,可以引入这种额外的灵活性。每个微指令都可以访问处理器的所有锁存器和内部状态元素。通过执行一组与指令关联的微指令,我们可以实现该指令的功能,这些微指令或微代码保存在微代码表中。通常可以通过软件修改该表的内容,从而改变硬件执行指令的方式。有几个原因需要这种灵活性,允许我们添加新指令或修改现有指令的行为。其中一些原因如下:
- 处理器在执行某些指令时有时会出现错误。因为设计师在设计过程中犯下的错误,或者是由于制造缺陷,其中一个著名的例子是英特尔奔腾处理器中的除法错误,英特尔不得不召回它卖给客户的所有奔腾处理器。如果可以动态地更改除法指令的实现,那么就不必调用所有处理器。因此可以得出结论,处理器的某种程度的可重构性有助于解决在设计和制造过程的各个阶段可能引入的缺陷。
- 英特尔奔腾4等处理器,以及英特尔酷睿i3和英特尔酷睿i7等更高版本的处理器,通过执行存储在内存中的一组微指令来实现一些复杂的指令。通常使用微码来实现数据串或指令的复杂操作,这些操作会导致一系列重复计算,意味着英特尔处理器在内部将复杂指令替换为包含简单指令的代码段,使得处理器更容易实现复杂的指令。我们不需要对数据路径进行不必要的更改,添加额外的状态、多路复用器和控制信号来实现复杂的指令。
- 当今的处理器只是芯片的一部分,有许多其他元件,被称为片上系统(system-on-chip,SOC)。例如,手机中的芯片可能包含处理器、视频控制器、相机接口、声音和网络控制器。处理器供应商通常会硬连线一组简单的指令,而与视频和音频控制器等外围设备接口的许多其他指令都是用微码编写的。根据应用程序域和外围组件集,可以定制微码。
- 有时使用一组专用微指令编写自定义诊断例程。这些例行程序在芯片运行期间测试芯片的不同部分,报告故障并采取纠正措施。这些内置自检(BIST)例程通常是可定制的,并以微码编写。例如,如果我们希望高可靠性,那么我们可以修改在CPU上执行可靠性检查的指令的行为,以检查所有组件。但是,为了节省时间,可以压缩这些例程以检查更少的组件。
因此,我们观察到,有一些令人信服的理由能够以编程方式改变处理器中指令的行为,以实现可靠性、实现附加功能并提高可移植性。因此,现代计算系统,尤其是手机和平板电脑等小型设备使用的芯片依赖于微码。这种微码序列通常被称为固件。
现代计算系统,尤其是手机、调制解调器、打印机和平板电脑等小型设备,使用的芯片依赖于微码。这种微码序列通常被称为固件(firmware)。
因此,让我们设计一个基于微程序的处理器,即使在处理器被制造并发送给客户之后,它也能为我们提供更大的灵活性来定制指令集。需要注意,常规硬接线处理器和微编程处理器之间存在着基本的权衡。权衡是效率与灵活性,不能指望有一个非常灵活的处理器,它既快速又省电。
2.4 微编程数据路径
让我们为微程序处理器设计数据路径,修改处理器的数据路径。处理器有一些主要单元,如提取单元、寄存器文件、ALU、分支单元和内存单元。这些单元是用导线连接的,只要有可能有多个源操作数,我们就在数据路径中添加一个多路复用器。控制单元的作用是为多路复用器生成所有控制信号。
问题是多路复用器的连接是硬接线的,不能建立任意连接,例如,不能将存储单元的输出发送到执行单元的输入。因此我们希望有一个组件之间没有固定互连的设计,理论上任何单位都可以向任何其他单位发送数据。
最灵活的互连是基于总线的结构。总线是一组连接所有单元的普通铜线,支持一个写入,在任何时间点支持多个读者。例如,单元A可以在某个时间点写入总线,所有其他单元都可以获得单元A写入的值。如果需要,可以将数据从一个单元发送到另一个单元,或从一个装置发送到一组其他单元。控制单元需要确保在任何时间点,只有一个单元写入总线,需要处理正在写入的值的单元从总线读取值。
现在让我们继续设计我们为硬连线处理器引入的所有单元的简化版本,这些简化版本可以适当地用于我们的微程序处理器的数据路径。
让我们从解释微程序处理器的设计原理开始。我们为每个单元添加寄存器,这些寄存器存储特定单元的输入数据,专用输出寄存器存储单元生成的结果,这两组寄存器都连接到公共总线。与硬连线处理器不同的是,在不同的单元之间存在大量的耦合,微程序处理器中的单元是相互独立的。他们的工作是执行一组操作,并将结果返回总线。每个单元就像编程语言中的一个函数,它有一个由一组寄存器组成的接口,用于读取数据,通常需要1个周期来计算其输出,然后该单元将输出值写入输出寄存器。
根据上述原理,下图中展示了提取单元的设计,它有两个寄存器:pc(程序计数器)和ir(指令寄存器)。pc寄存器可以从总线读取其值,也可以将其值写入总线,没有将ir连接到总线,因为没有其他单位对指令的确切内容感兴趣,其他单位只对指令的不同字段感兴趣。因此,有必要解码指令并将其分解为一组不同的字段,由解码单元完成。

微程序处理器中的提取单元。
解码单元在功能上类似于操作数获取单元,但我们不在该单元中包含寄存器文件,而将其视为微程序处理器中的一个独立单元。下图显示了操作数获取单元的设计。

微程序处理器中的解码单元。
我们将解码单元和寄存器文件组合成一个单元,称为硬连线处理器的操作数获取单元,但更期望在微程序处理器中保持寄存器文件独立,因为在硬连线处理器中,它在解码指令后立即被访问。然而,微程序处理器可能不是这样——在指令执行期间,可能需要多次访问它。

微程序处理器中的寄存器文件。
ALU的结构如下图所示,有两个输入寄存器,A和B。ALU对寄存器A和B中包含的值执行操作,操作的性质由args值指定。例如,如果指定了加法运算,则ALU将寄存器A和B中包含的值相加。如果指定了减法运算,那么将从A中包含的数值减去B中的值,对于cmp指令,ALU更新标志。使用两个标志来指定相等和大于条件,分别保存在寄存器标志flags.E和标志flags.GT中,然后ALU运算的结果保存在寄存器aluResult中。此处还假设ALU在总线上指定args值后需要1个周期才能执行。

微程序处理器中的ALU。
内存单元如下图所示。与硬连线处理器一样,它有两个源寄存器:mar(内存地址寄存器)和mdr(内存数据寄存器),mar缓冲内存地址,mdr缓冲需要存储的值。还需要一组参数来指定内存操作的性质:加载或存储,加载操作完成后,ldResult寄存器中的数据可用。

微程序处理器中的存储单元。
综上,微程序处理器中的数据路径总览如下:

3 管线处理器
3.1 管线概述
假设前面介绍的硬连线处理器需要一个周期来获取、执行和将指令的结果写入寄存器文件或内存。在电气层面上,是通过从提取单元经由其他单元流到寄存器写回单元的信号来实现的,而电信号从一个单元传播到另一个单元需要时间。
例如,从指令存储器中获取指令需要一些时间。然后需要时间从寄存器文件读取值,并用ALU计算结果。内存访问和将结果写回寄存器文件也是相当耗时的操作。需要等待所有这些单独的子操作完成,然后才能开始处理下一条指令,意味着电路中有大量的空闲,当操作数获取单元执行其工作时,所有其他单元都处于空闲状态。同样,当ALU处于活动状态时,所有其他单元都处于非活动状态。如果我们假设五个阶段(IF、OF、EX、MA、RW)中的每一个都需要相同的时间,那么在任何时刻,大约80%的电路都是空闲的!这代表了计算能力的浪费,空闲资源绝对不是一个好主意。
如果能找到一种方法让芯片的所有单元保持忙碌,那么就能提高执行指令的速度。
管线流程
不妨类比一下前面讨论的简单单周期处理器中的空闲问题。当一条指令在EX阶段时,下一条指令可以在OF阶段,而后续指令可以在IF阶段。事实上,如果在处理器中有5个阶段,简单地假设每个阶段花费的时间大致相同,可以假设同时处理5条指令,每条指令在处理器的不同单元中进行处理。类似于流水线中的汽车,指令在处理器中从一个阶段移动到另一个阶段。此策略确保处理器中没有任何空闲单元,因为处理器中的所有不同单元在任何时间点都很忙。
在此方案中,指令的生命周期如下。它在周期n中进入IF阶段,在周期n+1中进入OF阶段,周期n+2中进入EX阶段,循环n+3中进入MA阶段,最后在周期n+4中完成RW阶段的执行。这种策略被称为流水线(pipelining,又名管线、管道),实现流水线的处理器被称为流水处理器(pipelined processor)。五个阶段(IF、OF、EX、MA、RW)的顺序在概念上一个接一个地布置,称为流水线(pipeline,类似于汽车装配线)。下图显示了流水线数据路径的组织。

流水线数据路径。
上图中,数据路径分为五个阶段,每个阶段处理一条单独的指令。在下一个周期中,每条指令都会传递到下一个阶段,如图所示。
性能优势
现在,让我们考虑流水线处理器的情况,假设阶段是平衡的,意味着执行每个阶段需要相同的时间,大多数时候,处理器设计人员都会尽可能最大程度地实现这个目标。因此可以将r除以5,得出执行每个阶段需要r/5纳秒的结论,可以将循环时间设置为r/5。循环结束后,流水线每个阶段中的指令进入下一阶段,RW阶段的指令移出流水线并完成执行,同时,新指令进入IF阶段。如下图所示。

流水线中的指令。
如果我们可以用5阶段流水线获得5倍的优势,那么按照同样的逻辑,应该可以用100阶段流水线得到100倍的优势。事实上,可以不断增加阶段的数量,直到一个阶段只包含一个晶体管。但情况并非如此,流水线处理器的性能存在根本性的限制,不可能通过增加流水线阶段的数量来任意提高处理器的性能。在一定程度上,增加更多的阶段会适得其反。
下图a描述了不使用流水线的指令序列的时序,显然是一个浪费的过程,即使是非常简单的流水线也可以大大提高性能。下图b显示了两阶段流水线方案,其中两个不同指令的I级和E级同时执行。流水线的两个阶段是指令获取阶段和执行指令的执行/内存阶段,包括寄存器到内存和内存到寄存器的操作,因此我们看到第二条指令的指令提取阶段可以与执行/存储阶段的第一部分并行执行。然而,第二条指令的执行/存储阶段必须延迟,直到第一条指令清除流水线的第二阶段。该方案的执行率可以达到串行方案的两倍,两个问题阻碍了实现最大加速。首先,我们假设使用单端口内存,并且每个阶段只能访问一个内存,需要在某些指令中插入等待状态。第二,分支指令中断顺序执行流,为了以最小的电路来适应这种情况,编译器或汇编器可以将NOOP指令插入到指令流中。
通过允许每个阶段进行两次内存访问,可以进一步改进流水线,产生了下图c所示的序列。现在最多可以重叠三条指令,其改进程度为3倍,同样,分支指令会导致加速比达不到可能的最大值,请注意数据依赖性也会产生影响。如果一条指令需要被前一条指令更改的操作数,则需要延迟,同样可以通过NOOP实现。
由于RISC指令集的简单性和规则性,分为三个或四个阶段的设计很容易完成。下图d显示了4阶段管线的结果,一次最多可以执行四条指令,最大可能的加速是4倍。再次注意,使用NOOP来解释数据和分支延迟。

3.2 管线阶段
流水线处理器使用的电子构造有所不同,下面是不同阶段的一种设计:

流水线处理器中的IF阶段。

流水线处理器中的OF阶段。

流水线处理器中的EX阶段。

流水线处理器中的MA阶段。

流水线处理器中的RW阶段。
现在通过下图显示的带有流水线寄存器的数据路径来总结关于简单流水线的讨论。注意,我们的处理器设计已经变得相当复杂,图表大小已经达到了一页,不想引入更复杂的图表。

流水线数据路径。
下图显示了流水线数据路径的抽象。该图主要包含不同单元的框图,并显示了四个流水线寄存器。我们将使用该图作为讨论先进流水线的基线。回想一下,rst寄存器操作数可以是指令的rs1字段,也可以是ret指令的返回地址寄存器。在ra和rs1之间选择多路复用器是基线流水线设计的一部分,为了简单起见,没有在图中显示它,假设它是寄存器文件单元的一部分。类似地,选择第二寄存器操作数(在rd和rs2之间)的多路复用器也被假定为寄存器文件单元的一部分,因此图中未示出,只显示选择第二个操作数(寄存器或立即数)的多路复用器。

下图显示了三条指令通过管道时的流水线图,每一行对应于每个流水线阶段,列对应于时钟周期。在示例代码中,有三条相互之间没有任何依赖关系的指令,将这些指令分别命名为:[1]、[2]和[3]。最早的指令[1]在第一个周期进入流水线的IF阶段,在第五个周期离开流水线。类似地,第二条指令[2]在第二个周期中进入流水线的IF阶段,在第六个周期中离开流水线。这些指令中的每一条都会在每个循环中前进到流水线的后续阶段,流水线图中每条指令的轨迹都是一条朝向右下角的对角线。请注意,在考虑指令之间的依赖性之后,这个场景将变得相当复杂。


流水线示意图。
下面是构建流水线图的规则:
- 构建一个单元网格,该网格有5行和N列,其中N是希望考虑的时钟周期总数,每5行对应于一个流水线阶段。
- 如果指令([k])在周期m中进入流水线,那么在第一行的第m列中添加一个与[k]对应的条目。
- 在第(m+1)个周期中,指令可以停留在同一阶段(因为流水线可能会停顿,稍后将描述),也可以移动到下一行(OF阶段)。在网格单元中添加相应的条目。
- 以类似的方式,指令按顺序从IF级移动到RW级,它从不后退,但可以在连续的周期中保持在同一阶段。
- 一个单元格中不能有两个条目。
- 在指令离开RW阶段后,最终将其从流水线图中删除。
根据以上规则举个简单的例子,假设有以下代码:
add r1, r2, r3
sub r4, r2, r5
mul r5, r8, r9
为上述代码段构建的流水线图如下(假设第一条指令在周期1中进入流水线):

条件分支对指令流水线操作的影响:

6阶段的CPU指令管线:

一个备选的管线描述:

下图a将加速因子绘制为在没有分支的情况下执行的指令数的函数。正如可能预期的,在极限(n趋近正无穷),有k倍的加速。图b显示了作为指令管道中级数函数的加速因子。在这种情况下,加速因子接近可以在没有分支的情况下馈送到管道中的指令数。因此,管线阶段数越大,加速的可能性越大。然而,作为一个实际问题,额外管线阶段的潜在收益会因成本增加、阶段之间的延迟以及遇到需要刷新管线的分支而抵消。

3.3 管线冲突
让我们考虑下面的代码片段:
add r1, r2, r3
sub r3, r1, r4
此处的加法指令生成寄存器r1的值,子指令将其用作源操作数,这些指令构建一个流水线图如下所示。

显示RAW(写入后读取)危险的流水线图。
显示了有一个问题。指令1在第f个周期中写入r1的值,指令2需要在第3个周期中读取其值。这显然是不可能的,我们在两条指令的相关流水线阶段之间添加了一个箭头,以指示存在依赖关系。由于箭头向左(时间倒退),我们无法在管道中执行此代码序列,被称为数据冲突(亦称数据危险,data hazard),冲突被定义为流水线中错误执行指令的可能性,这种特殊情况被归类为数据冲突,除非采取适当措施,否则指令2可能会得到错误的数据。
冲突(hazard)被定义为流水线中错误执行指令的可能性,表示由于无法获得正确的数据而导致错误执行的可能性。
这种特定类型的数据危险被称为RAW(写入后读取)冲突。上面语句的减法指令试图读取r1,需要由加法指令写入。在这种情况下,读取会在写入之后。
请注意,这不是唯一一种数据冲突,另外两种类型的数据危害是WAW(写入后写入)和WAR(读取后写入)冲突,这些冲突在我们的流水线中不是问题,因为我们从不改变指令的顺序,前一条指令总是在后一条指令之前。相比之下,现代处理器具有以不同顺序执行指令的无序(out-of-order)流水线。
在有序流水线(如我们的流水线)中,前一条指令总是在流水线中的后一条指令之前。现代处理器使用无序(out-of-order)流水线来打破这一规则,并且可以让后面的指令在前面的指令之前执行。
让我们看看下面的汇编代码段:
add r1, r2, r3
sub r1, r4, r3
指令1和指令2正在写入寄存器r1。按照顺序,流水线r1将以正确的顺序写入,因此不存在WAW危险。然而,在无序流水线中,我们有在指令1之前完成指令2的风险,因此r1可能会以错误的值结束。这便是WAW冲突的一个例子。读者应该注意,现代处理器通过使用一种称为寄存器重命名(register renaming)的技术确保r1不会得到错误的值。
让我们举一个潜在WAR冲突的例子:
add r1, r2, r3
add r2, r5, r6
指令2试图写入r2,而指令1将r2作为源操作数。如果指令2先被执行,那么指令1可能会得到错误的r2值。实际上,由于寄存器重命名等方案,这在现代处理器中不会发生。我们需要理解,冲突是发生错误的理论风险,但不是真正的风险,因为采取了足够的措施来确保程序不会被错误地执行。
本文将主要关注RAW危害,因为WAW和WAR危害仅与现代无序处理器相关。让我们概述一下解决方案的性质,为了避免RAW危险,有必要确保流水线知道它包含一对指令,其中一条指令写入寄存器,另一条指令按程序顺序稍后从同一寄存器读取。它需要确保使用者指令正确地从生产者指令接收操作数(在本例中为寄存器)的值,我们将研究硬件和软件方面的解决方案。
现在看看当我们在流水线中有分支指令时会出现的另一种危险,假设有下面的代码片段:
[1]: beq .foo
[2]: mov r1, 4
[3]: add r2, r4, r3
...
...
.foo:
[100]: add r4, r1, r2
下图展示了前三条指令的流水线图:

此处,分支的结果在循环3中被确定,并被传送到提取单元,提取单元从周期4开始提取正确的指令。如果执行了分支,则不应执行指令2和3。可悲的是,在周期2和周期3中,无法知道分支的结果。因此,这些指令将被提取,并将成为流水线的一部分。如果执行分支,则指令2和3可能会破坏程序的状态,从而导致错误,指令2和指令3被称为错误路径中的指令。这种情况称为控制冲突(control hazard)。如果分支的结果与其实际结果不同,则会执行的指令被认为是错误的。例如,如果执行分支,则程序中分支指令之后的指令路径错误。
控制冲突(control hazard)表示流水线中错误执行的可能性,因为分支错误路径中的指令可能会被执行并将结果保存在内存或寄存器文件中。
为了避免控制冲突,有必要识别错误路径中的指令,并确保其结果不会提交到寄存器文件和内存。应该有一种方法使这些指令无效,或者完全避免它们。
当不同的指令试图访问同一个资源,而该资源不能允许所有指令在同一周期内访问它时,就会出现结构冲突。让我们举个例子。假设我们有一条加法指令,可以从内存中读取一个操作数,它可以具有以下形式:
add r1, r2, 10[r3]
结构冲突(structural hazard)是指由于资源限制,指令可能无法执行。例如,当多个指令试图在同一周期内访问一个功能单元时,可能会出现这种情况,并且由于容量限制,该单元无法允许所有感兴趣的指令继续执行。在这种情况下,冲突中的一些指令需要暂停执行。
此处,有一个寄存器源操作数r2和一个内存源操作数10[r3],进一步假设流水线在OF阶段读取内存操作数的值。现在让我们来看一个潜在的冲突情形:
[1]: st r4, 20[r5]
[2]: sub r8, r9, r10
[3]: add r1, r2, 10[r3]
请注意,这里没有控制和数据冲突,尽管如此,让我们考虑流水线图中存储指令处于MA阶段时的一点。此时,指令2处于EX阶段,指令3处于OF阶段。请注意,在此循环中,指令1和3都需要访问存储单元。但如果我们假设内存单元每个周期只能服务一个请求,那么显然存在冲突情况,其中一条指令需要暂停执行。这种情况是结构冲突的一个例子。
由于具有典范性,后面我们把重点放在努力消除RAW和控制冲突上。
3.4 管线冲突解决
软件方案
现在,让我们找出一种避免RAW冲突的方法,假设有以下代码:
[1]: add r1, r2, r3
[2]: sub r3, r1, r4
指令2要求OF级中的r1值。然而,此时,指令1处于EX阶段,它不会将r1的值写回寄存器文件,因此不能允许指令2在流水线中继续。一个简单的软件解决方案是聪明的编译器可以分析代码序列并意识到存在RAW冲突,它可以在这些指令之间引入nop指令,以消除任何RAW冲突。考虑以下代码序列:
[1]: add r1, r2, r3
[2]: nop
[3]: nop
[4]: nop
[5]: sub r3, r1, r4
当子指令到达OF阶段时,加法指令将写入其值并离开流水线,因此子指令将获得正确的值。请注意,添加nop指令是一个成本高昂的解决方案,因为我们实际上是在浪费计算能力。在这个例子中,添加nop指令基本上浪费了3个周期。然而,如果考虑更长的代码序列,那么编译器可能会重新排序指令,这样就可以最小化nop指令的数量。任何编译器干预的基本目标都必须是在生产者和消费者指令之间至少有3条指令。
举个具体的例子,重新排序以下代码段,并添加足够数量的nop指令,以使其在流水线上正确执行:
add r1, r2, r3 ; 1
add r4, r1, 3 ; 2
add r8, r5, r6 ; 3
add r9, r8, r5 ; 4
add r10, r11, r12 ; 5
add r13, r10, 2 ; 6
答案是:
add r1, r2, r3 ; 1
add r8, r5, r6 ; 3
add r10, r11, r12 ; 5
nop
add r4, r1, 3 ; 2
add r9, r8, r5 ; 4
add r13, r10, 2 ; 6
我们需要理解这里的两个重要点:第一个是nop指令的能力,第二个是编译器的能力,编译器是确保程序正确性和提高性能的重要工具。在这种情况下,我们希望以这样一种方式重新排序代码,即引入最小数量的nop指令。
接下尝试使用相同的技术解决控制冲突。
如果再次查看流水线图,就会发现分支指令和分支目标处的指令之间至少需要两条指令,这是因为在EX阶段结束时得到分支结果和分支目标。此时,流水线中还有两条指令。当分支指令分别处于OF和EX阶段时,这些指令已被提取,它们可能执行错了路径。在EX阶段确定分支目标和结果之后,我们可以继续在IF阶段获取正确的指令。
现在考虑当不确定分支结果时提取的这两条指令。如果分支的PC等于p1,则它们的地址分别为p1+4和p1+8。如果不采取行动,它们不会执行错误路径。但是,如果执行分支,则需要从管道中丢弃这些指令,因为它们位于错误的路径上。
让我们看看一个简单的软件解决方案,其中硬件假设分支指令之后的两条指令没有在错误的路径上,这两条指令的位置称为延迟时隙(delay slot)。通常可以通过在分支后插入两条nop指令来确保延迟间隙中的指令不会引入错误,但这样做不会获得任何额外的性能,可以取而代之地对在分支指令之前执行的两条指令进行绑定,并将它们移动到分支之后的两个延迟时隙中。
请注意,我们不能随意将指令移动到延迟时隙,不能违反任何数据依赖约束,还需要避免RAW冲突,另外,我们不能将任何比较指令移动到延迟时隙中。如果没有适当的指令可用,那么我们总是可以返回到普通的解决方案并插入nop指令。也有可能我们只需要找到一条可以重新排序的指令,然后只需要在分支指令之后插入一条nop指令。延迟分支方法是一种非常有效的方法,可以减少需要添加以避免控制冲突的nop指令的数量。
在简单流水线数据路径中,分支后获取的两条指令的PC分别等于p1+4和p1+8(p1是分支指令的PC)。由于编译器确保这些指令始终在正确的路径上,而不管分支的结果如何,因此我们不会通过获取它们来提交错误。在确定分支的结果之后,如果不执行分支,则获取的下一条指令的PC等于p1+12,或者如果执行分支,PC等于分支目标。因此,在这两种情况下,在确定分支的结果后都会获取正确的指令,可以得出结论,软件解决方案在流水线版本的处理器上正确执行程序。
总之,软件技术的关键是延迟时隙的概念。在分支之后需要两个延迟时隙,因为不确定后续的两条指令,它们可能在错误的路径上。然而,使用智能编译器,可以设法将执行的指令移动到延迟时隙,而不管分支的结果如何。因此可以避免在延迟时隙中放置nop指令,从而提高性能。这种分支指令被称为延迟分支指令(delayed branch instruction)。
如果处理器假定在其结果确定之前获取的所有后续指令都在正确的路径上,则分支指令称为延迟分支(delayed branch)。如果处理器在提取分支指令的时间与确定其结果之间提取n条指令,那么我们就说我们有n个延迟时隙。编译器需要确保正确路径上的指令占用延迟时隙,并且不会引入额外的控制或RAW冲突。编译器还可以在延迟时隙中引入nop指令。
现在举个例子。重新排序下面的汇编代码,以便在具有延迟分支的流水线处理器上正确运行,假设每个分支指令有两个延迟时隙。
add r1, r2, r3 ; 1
add r4, r5, r6 ; 2
b .foo ; 3
add r8, r9, r10 ; 4
答案:
b .foo ; 3
add r1, r2, r3 ; 1
add r4, r5, r6 ; 2
add r8, r9, r10 ; 4
硬件方案
上面研究了消除RAW和控制冲突的软件解决方案,但编译器方法不是很通用,原因是:
- 首先,程序员总是可以手动编写汇编代码,并尝试在处理器上运行它。在这种情况下,错误的可能性很高,因为程序员可能没有正确地重新排序代码以消除冲突。
- 其次,还有可移植性问题。为一条流水线编写的一段汇编代码可能无法在遵循相同ISA的另一条流水线上运行,因为它可能具有不同数量的延迟时隙或不同数量的阶段。如果我们的汇编程序不能在使用相同ISA的不同机器之间移植,那么引入汇编程序的主要目标之一就失败了。
让我们尝试在硬件层面设计解决方案,硬件应确保无论汇编程序如何,都能正确运行,输出应始终与单周期处理器产生的输出相匹配。为了设计这样的处理器,需要确保指令永远不会接收错误的数据,并且不会执行错误的路径指令。可以通过确保以下条件成立来实现:
- 数据锁定(Data-Lock)。我们不能允许指令离开OF阶段,除非它从寄存器文件接收到正确的数据,意味着需要有效地暂停IF和OF阶段,并让其余阶段执行,直到OF阶段中的指令可以安全地读取其操作数。在此期间,从OF阶段传递到EX阶段的指令需要是nop指令。
- 分支锁定(Branch-Lock)。我们从不在错误的路径上执行指令,要么暂停处理器直到结果已知,要么使用技术确保错误路径上的指令不能将其更改提交到内存或寄存器。
在流水线的纯硬件实现中,有时需要阻止新指令进入流水线阶段,直到某个条件停止保持。停止流水线阶段接受和处理新数据的概念称为流水线暂停(pipeline stall)或流水线互锁(pipeline interlock)。其主要目的是确保程序执行的正确性。
如果我们确保数据锁定和分支锁定条件都成立,那么流水线将正确执行指令。请注意,这两种情况都要求管道的某些阶段可能需要暂停一段时间,这些暂停也称为流水线互锁。换言之,通过保持流水线空闲一段时间,可以避免执行可能导致错误执行的指令。下表是纯软件和硬件方案实现流水线的整个逻辑的利弊。请注意,在软件解决方案中,我们尝试重新排序代码,然后插入最小数量的nop指令,以消除冲突的影响。相比之下,在硬件解决方案中,我们动态地暂停部分流水线,以避免在错误的路径中执行指令,或使用错误的操作数值执行指令。暂停流水线相当于让某些阶段保持空闲,并在其他阶段插入nop指令。
|
属性 |
软件 |
硬件(互锁) |
|
可移植性 |
仅限于特定处理器 |
程序可以在任何处理器上运行 |
|
分支 |
通过使用延迟时隙,可能没有性能损失 |
本文需要暂停流水线2个周期 |
|
RAW冲突 |
可以通过代码调度消除它们 |
需要暂停流水线 |
|
性能 |
高度依赖于程序的特性 |
带联锁的流水线的基本版本会比软件慢 |
我们观察到,软件解决方案的效率高度依赖于程序的性质,可以对某些程序中的指令重新排序,以完全隐藏RAW冲突和分支的有害影响。然而,在某些程序中,我们可能没有找到足够的可以重新排序的指令,因此被迫插入大量nop指令,会降低性能。相比之下,一个遵守数据锁和分支锁条件的纯硬件方案,只要检测到可能错误执行的指令,就会暂停流水线。这是一种通用方法,比纯软件解决方案慢。
现在可以将硬件和软件解决方案结合起来,重新排序代码,使其尽可能对流水线友好,然后在带有互锁的流水线上运行它。注意,在这种方法中,编译器不保证正确性,只是将生产者指令和消费者指令尽可能分开,并在支持它们的情况下利用延迟分支。这减少了我们需要暂停流水线的次数,并确保了两全其美。在设计带互锁的流水线前,下面借助流水线图来研究互锁的性质。
现在绘制带有互锁的流水线图,考虑下面的代码片段。
add r1, r2, r3
sub r4, r1, r2

带气泡的流水线图。
指令[1]写入寄存器r1,指令[2]从r1读取,显然存在RAW依赖关系。为了确保数据锁定条件,我们需要确保指令[2]仅在读取了指令[1]写入的r1值时才离开OF阶段,仅在循环6中可行(上图),然而指令[2]在周期3中到达OF阶段。如果没有冲突,则理想情况下它会在周期4中进入EX阶段。由于我们有互锁,指令[2]也需要在周期4、5和6中保持在OF阶段中。问题是,当EX阶段在周期4、5和6中没有处理有效指令时,它会做什么?类似地,MA阶段在周期5、6和7中不处理任何有效的指令。我们需要有一种方法来禁用流水线阶段,这样我们就不会执行多余的工作,标准方法是将nop指令插入阶段。
再次参考上图。在循环3结束时,知道需要引入互锁,因此在周期4中,指令[2]保留在OF阶段,将nop指令插入EX阶段,该nop指令在周期5中移动到MA级,在周期6中移动到RW级。该nop命令称为流水线气泡。气泡是由互锁硬件动态插入的nop指令,在类似于正常指令的流水线阶段中移动。同样,在循环5和6中,我们需要插入管线气泡。最后,在周期7中,指令[2]可以自由地进入EX和后续阶段。气泡不起任何作用,因此当阶段遇到气泡时,没有任何控制信号打开。要注意的另一个微妙的点是,不能在同一个周期内对同一个寄存器进行读写,需要优先选择写入,因为它是较早的指令,而读取需要暂停一个周期。
实现气泡有两种方法:
- 可以在指令包中有一个单独的气泡位。每当位为1时,该指令将被解释为一个气泡。
- 可以将指令的操作码更改为nop的操作码,并将其所有控制信号替换为0。这种方法更具侵入性,但可以完全消除电路中的冗余工作。在前一种方法中,控制信号将打开,由其激活的单元将保持运行。硬件需要确保气泡不能对寄存器或内存进行更改。
流水线气泡(pipeline bubble)是由互锁硬件动态插入流水线寄存器中的nop指令,气泡以与正常指令相同的方式在流水线中传播。
总之,通过在流水线中动态插入气泡,可以避免数据冲突。
接下来阐述div和mod指令等慢指令的问题。在大多数流水线中,这些指令很可能需要n(n>1)个周期才能在EX阶段执行。在n个周期的每个周期中,ALU完成div或mod指令的部分处理。每个这样的循环被称为T状态(T State),通常一个阶段具有1T状态,但慢指令的EX阶段有许多T状态。因此,为了正确实现慢指令,需要暂停IF和OF阶段(n-1)个周期,直到操作完成。
为了简单起见,我们将不再讨论这个问题,相反,继续进行简单的假设,即所有流水线阶段都是平衡的,并且需要1个周期来完成它们的操作。现在看看控制冲突,首先考虑以下代码片段。
[1]: beq .foo
[2]: add r1, r2, r3
[3]: sub r4, r5, r6
....
....
.foo:
[4]: add r8, r9, r10
如果分支被执行,可以在流水线中插入气泡,而不是使用延迟分支,否则不需要做任何事情。假设分支被去掉,这种情况下的流水线图如下所示。
在这种情况下,指令[1]的分支条件的结果在循环3中决定。此时,指令[2]和[3]已经在流水线中(分别在IF和of阶段)。由于分支条件求值为take,我们需要取消指令[2]和[3],否则它们将被错误执行。因此将它们转换为气泡,如上图所示,指令[2]和[3]在循环4中转换为气泡。其次,在循环4从正确的分支目标(.foo)中提取,因此指令[4]进入流水线。两个气泡都经过所有流水线阶段,最后分别在循环6和7中离开流水线。
因此可以通过在流水线中动态引入气泡来确保这两个条件(数据锁定和分支锁定)。下面更详细地看看这些方法。
为了确保数据锁定条件,需要确保OF阶段中的指令与后续阶段中的任何指令之间没有冲突,冲突被定义为可能导致RAW冲突的情况。换句话说,如果后续阶段的指令写入由OF阶段的指令读取的寄存器,则存在冲突。因此需要两个硬件来实现数据锁定条件,第一步是检查是否存在冲突,第二步是确保流水线停止。
首先看看冲突检测硬件。冲突检测硬件需要将OF阶段中的指令的内容与其他三个阶段(即EX、MA和RW)中的每个指令的内容进行比较,如果与这些指令中的任何一条发生冲突,可以声明有冲突。让我们关注检测冲突的逻辑,简要介绍一下冲突检测电路的伪代码,设OF阶段中的指令为[A],后续阶段中的一条指令为[B]。检测冲突的算法伪代码如下所示:
Data: Instructions: [A] and [B]
Result: Conflict exists (true), no conflict (false)
1 if [A].opcode 2 (nop,b,beq,bgt,call) then
/* Does not read from any register */
2 return false
3 end
4 if [B].opcode 2 (nop, cmp, st, b, beq, bgt, ret) then
/* Does not write to any register */
5 return false
6 end
/* Set the sources */
7 src1 [A]:rs1
8 src2 [A]:rs2
9 if [A].opcode = st then
10 src2 [A]:rd
11 end
12 if [A].opcode = ret then
13 src1 ra
14 end
/* Set the destination */
15 dest [B]:rd
16 if [B].opcode = call then
17 dest ra
18 end
/* Check if the first operand exists */
19 hasSrc1 true
20 if [A].opcode 2 (not,mov) then
21 hasSrc1 false
22 end
/* Check the second operand to see if it is a register */
23 hasSrc2 true
24 if [A].opcode =2 (st) then
25 if [A]:I = 1 then
26 hasSrc2 false
27 end
28 end
/* Detect conflicts */
29 if (hasSrc1 = true) and (src1 = dest) then
30 return true
31 end
32 else if (hasSrc2 = true) and (src2 = dest) then
33 return true
34 end
35 return false
用硬件实现上述算法很简单,只需要一组逻辑门和多路复用器,大多数硬件设计者通常用硬件描述语言(如Verilog或VHDL)编写类似于上述算法的电路描述,并依靠智能编译器将描述转换为实际电路。
我们需要三个冲突检测器(OF↔EX,OF↔MA,OF↔RWOF↔EX,OF↔MA,OF↔RW)。如果没有冲突,则指令可以自由地进入EX阶段,但如果至少有一个冲突,则需要暂停IF和OF阶段。一旦指令通过OF阶段,它就保证拥有所有的源操作数。
现在来看看流水线的暂停。我们基本上需要确保在发生冲突之前,没有新的指令进入IF和OF阶段,这可以通过禁用PC和IF-OF流水线寄存器的写入功能来简单地确保。因此,它们不能接受时钟边缘(clock edge)上的新数据,将继续保持它们以前的值。
其次,还需要在流水线中插入气泡,例如从OF传递到EX阶段的指令需要是无效指令或气泡,可以通过传递nop指令来确保。因此确保数据锁定条件的电路是直接的,需要一个连接到PC的冲突检测器和IF-OF寄存器。在发生冲突之前,这两个寄存器将被禁用,无法接受新数据。我们强制OF-EX寄存器中的指令包含nop,流水线的增强电路图如下图所示。

带互锁的流水线的数据路径(实现数据锁定条件)。
接下来阐述分支锁定条件。
假设流水线中有一条分支指令(b、beq、bgt、call、ret)。如果有延迟时隙,那么数据路径与上图所示的相同,不需要做任何更改,因为执行的整个复杂性已经加载到了软件中。然而,将流水线暴露于软件有其利弊,如果在管线中添加更多阶段,那么现有的可执行文件可能会停止工作。为了避免这种情况,让我们设计一个不向软件暴露延迟时隙的流水线。
有两个设计选项:
- 第一种:可以假设在确定结果之前不采取分支。我们可以继续在分支之后获取这两条指令并进行处理,一旦在EX阶段决定了分支的结果,就可以根据结果采取适当的行动。如果未执行分支,则在分支指令之后获取的指令位于正确的路径上,无需再执行任何操作。但是,如果执行了分支,则必须取消这两条指令,并用流水线气泡(nop指令)替换它们。
- 第二种:暂停流水线,直到分支的结果被确定,而不管结果如何。
显然,第二种设计的性能低于假设不采用分支的第一种替代方案,例如,如果一个分支30%的时间没有被占用,那么对于第一个设计,30%的时间都在做有用的工作。然而,对于第二个选项,我们在获取分支指令后的2个周期中从未做过任何有用的工作。
因此,让我们从性能的角度考虑第一个设计,只有在分支被占用时,才取消分支后的两个指令,这种方法为预测不采用(predict not
taken),因为实际上是在预测不采取的分支。稍后,如果发现此预测错误,则可以取消错误路径中的指令。
如果分支指令的PC等于p,那么选择在接下来的两个周期中在p+4和p+8处获取指令。如果分支没有被执行,那么将继续执行。但是,如果分支被执行,那么将取消这两条指令,并将它们转换为流水线气泡。
我们不需要对数据路径进行任何重大更改,需要一个小型分支冲突单元,从EX阶段接收输入。如果执行分支,则在下一个周期中,它将If-OF和OF-EX阶段中的指令转换为流水线气泡。带有分支互锁单元的扩展数据路径如下图所示。

带互锁的流水线的数据路径(实现数据锁定和分支锁定条件)。
接下来阐述带转发(Forwarding)的流水线。
上面已经实现了一个带有互锁的流水线。互锁确保流水线正确执行,而不管指令之间的依赖性如何。对于数据锁定条件,我们建议在流水线中添加互锁,在寄存器文件中有正确的值之前,不允许指令离开操作数获取阶段。然而,下面将看到,不必总是添加互锁。事实上,在很多情况下,正确的数据已经存在于流水线寄存器中,尽管不存在于寄存器文件中。可以设计一种方法,将数据从内部流水线寄存器正确地传递到适当的功能单元。考虑以下代码:
add r1, r2, r3
sub r4, r1, r2
下图仅包含这两条指令的流水线图,(a)显示了带互锁的流水线图,(b)显示了无互锁和气泡的流水线图。现在尝试论证不需要在指令之间插入气泡。

(a)带互锁的流水线图,(b)无互锁和气泡的流水线图。
让我们深入查看上图(b)。指令1在EX阶段结束时产生其结果,或者在周期3结束时产生结果,并在周期5中写入寄存器文件。指令2在周期3开始时需要寄存器le中的r1值,显然是不可能的,因此建议添加流水线互锁来解决此问题。
让我们尝试另一种解决方案,允许指令执行,然后在循环3中,[2]将获得错误的值,允许它在周期4中进入EX阶段。此时,指令[1]处于MA阶段,其指令包包含正确的r1值。r1值是在前一个周期中计算的,存在于指令包的aluResult字段中,[1] 的指令包在周期4中位于EX-MA寄存器中。现如果在EX-MA的aluResult字段和ALU的输入之间添加一个连接,那么可以成功地将r1的正确值传输到ALU。我们的计算不会出错,因为ALU的操作数是正确的,因此ALU运算的结果也将被正确计算。
下图显示了我们在流水线图中的操作结果,将指令[1]的MA阶段添加到指令[2]的EX阶段。由于箭头不会在时间上倒退,因此可以将数据(r1的值)从一个阶段转发(forward)到另一个阶段。

在流水线中转发的示例。
转发(Forwarding)是一种通过阶段之间的直接连接在不同流水线阶段中的指令之间传输操作数值的方法,不使用寄存器文件跨指令传输操作数的值,从而避免昂贵的流水线互锁。
我们刚刚研究了一种非常强大的技术,可以避免管线中的停顿,称为转发。本质上,我们允许操作数的值在指令之间流动,方法是跨阶段直接传递它们,不使用寄存器文件跨指令传输值。转发的概念允许我们背靠背地(以连续的周期)执行指令[1]和[2],不需要添加任何暂停周期。因此,不需要重新排序代码或插入nop。
为了在指令[1]和[2]之间转发r1的值,我们在MA级和EX级之间添加了一个连接,上图9中通过在指令[1]和[2]的相应阶段之间画一个箭头来显示这种联系。这个箭头的方向是垂直向上的,由于它没有在时间上倒退,有可能转发该值,否则是不可能的。
现在让我们尝试回答一个一般性问题——可以在所有指令对之间转发值吗?注意,不需要是连续的指令,即使生产者和消费者ALU指令之间有一条指令,我们仍然需要转发值。现在尝试考虑管线中各阶段之间的所有可能的转发路径。
广泛遵循的转发基本原则如下:
- 在后期和早期之间添加了转发路径。
- 在管线中尽可能迟地转发一个值。例如,如果给定阶段不需要给定值,并且可以在稍后阶段从生产者指令中获取该值,那么我们等待在稍后阶段获取转发的值。
请注意,这两个基本原则都不影响程序的正确性,它们只允许消除冗余的转发路径。现在,系统地看看管道中需要的所有转发路径:
- RW --> MA:MA阶段需要来自RW阶段的转发路径,考虑下图所示的代码片段,指令[2]需要MA阶段(周期5)中的r1值,而指令[1]在周期4结束时从内存中获取r1值。因此,它可以在周期5中将其值转发给指令[2]。

- RW --> EX:下图所示的代码段显示了一条加载指令,它在周期4结束时获取寄存器r1的值,以及一条后续的ALU指令,它需要周期5中的r1值。因为不会在时间上倒退,所以可以转发该值。

- MA --> EX:下图所示的代码段显示了一条ALU指令,该指令在周期3结束时计算寄存器r1的值,以及一条连续的ALU指令在周期4中需要r1的数值。在这种情况下,还可以通过在MA和EX级之间添加互连(转发路径)来转发数据。

- RW --> OF:通常OF阶段不需要转发路径,因为它没有任何功能单元,不需要立即使用值,可以稍后根据原则2转发价值。然而,唯一的例外是从RW阶段转发,无法稍后转发该值,因为指令将不在管线中。因此有必要添加从RW到OF级的转发路径,需要RW --> OF转发的代码段示例如下图所示。指令[1]通过在周期4结束时从内存中读取r1的值来生成r1值,然后它在周期5中将r1值写入寄存器文件。同时,指令[4]尝试在周期5的OF阶段读取r1值,不幸的是,这里存在冲突。因此,我们建议通过在RW和OF阶段之间添加转发路径来解决冲突。因此,禁止指令[4]读取r1值的寄存器文件。相反,指令[4]]使用RW --> OF转发路径从指令[1]获取r1值。

不需要添加以下转发路径:MA-->OF和EX-->OF,因为我们可以使用以下转发路径(RW-->EX)和(MA-->EX)。根据原则2,需要避免冗余转发路径,因此不添加从MA和EX级到OF级的转发路径。我们不向IF阶段添加转发路径,因为在这个阶段,还没有解码指令,不知道其操作数。
现在又衍生了一个问题:转发是否完全消除了数据冲突?
现在回答这个问题。先考量ALU指令,它们在EX阶段产生结果,并准备在MA阶段前进,任何后续的使用者指令都需要前一条ALU指令在EX阶段最早生成的操作数的值。此时可以实现成功的转发,因为操作数的值在MA阶段已经可用。如果生产者指令已离开流水线,则任何后续指令都可以使用任何可用的转发路径或从寄存器文件获取值。如果生产者指令是ALU指令,那么总是可以将ALU运算的结果转发给消费者指令。为了证明这一事实,需要考虑所有可能的指令组合,并判断是否可以将输入操作数转发给使用者指令。
唯一显式生成寄存器值的其他指令是加载指令。请记住,存储指令不会写入任何寄存器。让我们看看加载指令,加载指令在MA阶段结束时产生其值,因此它准备在RW阶段转发其值。考虑下图中的代码片段及其流水线图。

加载-使用冲突。
指令[1]是写入寄存器r1的加载指令,指令[2]是使用寄存器r1作为源操作数的ALU指令,加载指令在周期5开始时准备好转发。不幸的是,ALU指令在周期4开始时需要r1的值,故而需要在流水线图中绘制一个箭头,该箭头在时间上向后流动。因此,在这种情况下,转发是不可能的。
加载-使用冲突(Load-Use Hazard)是指加载指令将加载的值提供给在EX阶段需要该值的紧随其后的指令的情况。即使有转发,管线也需要在加载指令之后插入一个暂停周期。
这是需要在管线中引入暂停循环的唯一情况,这种情况被称为加载-使用冲突,加载指令将加载的值提供给在EX阶段需要该值的紧随其后的指令。消除加载-使用冲突的标准方法是允许管线插入气泡,或者使用编译器重新排序指令或插入nop指令。
总之,具有转发的管线确实可能需要互锁,唯一的特殊情况是加载-使用冲突。
请注意,如果在存储加载值的加载指令之后有一个存储指令,那么我们不需要插入暂停循环,因为存储指令需要MA阶段的值。此时,加载指令处于RW阶段,可以转发该值。
如果要实现管线的转发,需要根据不同的管线阶段来实现。
支持转发的OF阶段如下图所示,基线管道中没有转发的多路复用器用较浅的颜色着色,而为实现转发而添加的附加多路复用器被着色为较深的颜色。

下图显示了修改后的EX阶段。EX级从OF级获得的三个输入是A(第一个ALU操作数)、B(第二个ALU运算数)和op2(第二寄存器操作数)。对于A和B,我们添加了两个复用器M3和M4,以在OF级中计算的值和分别从MA和RW级转发的值之间进行选择。对于可能包含存储值的op2字段,我们不需要MA --> EX转发,因为在MA阶段需要存储值,因此我们可以使用RW --> MA转发,从而减少一条转发路径。因此,多路复用器M5具有两个输入(默认值和从RW级转发的值)。

下图显示了具有额外转发支持的MA阶段。内存地址在EX阶段计算,并保存在指令包的aluResult字段中,内存单元直接使用该值作为地址。然而,在存储的情况下,需要存储的值(op2)可以从RW阶段转发,因此添加了多路复用器M6,它在指令包中的op2字段和从RW级转发的值之间进行选择。电路的其余部分保持不变。

下图显示了RW阶段。因为是最后一个阶段,所以它不使用任何转发值。但是,它将写入寄存器le的值分别发送到MA、EX和OF阶段。

下图将所有部分放在一起,并显示了支持转发的管线。总之,我们需要添加6个多路复用器,并在单元之间进行一些额外的互连,以传递转发的值。我们设想一个专用的转发单元,它为多路复用器(图中未示出)计算控制信号。除了这些小的更改,不需要对数据路径进行其他重大更改。

带转发的流水线数据路径(简图)。
我们在讨论转发时使用了一个简图(上图)。需要注意的是,实际电路现在变得相当复杂。除了对数据路径的扩展,还需要添加一个专用转发单元来为多路复用器生成控制信号。详细图片如下图所示。

现在将互锁逻辑添加到管线中,需要数据锁定和分支锁定条件的互锁逻辑。请注意,现在已经成功处理了除加载-使用冲突以外的所有RAW冲突。在加载-使用冲突的情况下,只需要停止一个周期,大大简化了数据锁定电路。如果EX阶段有加载指令,就需要检查加载指令和OF阶段的指令之间是否存在RAW数据依赖关系,不需要考虑的唯一RAW冲突是加载-存储依赖性,即加载写入包含存储值的寄存器,我们不需要暂停,因为可以将要存储的值从RW转发到MA阶段。对于所有其他数据依赖性,需要通过引入气泡将管线暂停1个周期,此举可以解决加载-使用冲突,确保分支锁定条件的电路保持不变。还需要检查EX阶段中的指令,如果它是一个执行的分支,需要使if和OF阶段的指令无效。最后应注意,互锁始终优先于转发。
3.5 性能标准和测量
本节讨论流水线处理器的性能。
需要首先在处理器的上下文中定义性能的含义。大多数时候,当我们查找笔记本电脑或智能手机的规格时,会被大量的术语淹没,比如时钟频率、RAM和硬盘大小,遗憾的是,这些术语都不能直接表示处理器的性能。计算机标签上从未明确提及性能的原因是“性能”一词相当模糊,处理器的性能一词总是指给定的程序或汇编,因为处理器对不同程序的性能不同。
给定一个程序P,让我们尝试量化给定处理器的性能。如果P在A上执行P的时间比在B上执行P所需的时间短,那么处理器A比处理器B性能更好。因此,量化给定程序的性能非常简单,测量运行程序所需的时间,然后计算其倒数,这个数字可以解释为与处理器相对于程序的性能成正比。
首先计算运行程序P所需的时间:

- 每秒的周期数是处理器的时钟频率(f)。

- 每个指令的平均周期数称为CPI(Cycles per instruction),其逆数(每个周期的指令数)称为IPC(Instructions per cycle)。
- 最后一项是指令数(缩写为#insts)。注意,是动态指令的数量,或者处理器实际执行的指令数量,不是程序可执行文件中的指令数。
静态指令是程序的二进制或可执行文件包含指令列表里的每条指令。
动态指令是静态指令的实例,当指令进入流水线时由处理器创建。
我们现在可以将性能P定义为与时间τ成反比的量(称为性能等式):

因此可以得出结论,处理器相对于程序的性能与IPC和频率成正比,与指令数成反比。
现在看看单周期处理器的性能。对于所有指令,其CPI都等于1,性能与 成正比,是一个相当微不足道的结果。当增加频率时,单周期处理器会按比例变快。同样,如果能够将程序中的指令数量减少X倍,那么性能也会增加X倍。让我们考虑流水线处理器的性能,分析更为复杂,见解也非常深刻。
成正比,是一个相当微不足道的结果。当增加频率时,单周期处理器会按比例变快。同样,如果能够将程序中的指令数量减少X倍,那么性能也会增加X倍。让我们考虑流水线处理器的性能,分析更为复杂,见解也非常深刻。
下面阐述性能方程中的三个项:
- 指令数量。程序中指令的数量取决于编译器的智能,真正智能的编译器可以通过从ISA中选择正确的指令集并使用智能代码转换来减少指令。例如,程序员通常有一些归类为死代码的代码,此代码对最终输出没有影响,聪明的编译器可以删除它能找到的所有死代码。附加指令的另一个来源是溢出和恢复寄存器的代码,编译器通常对非常小的函数执行函数内联,这种优化动态地移除这些函数,并将它们的代码粘贴到调用函数的代码中。对于小函数,是一个非常有用的优化,可以摆脱溢出和恢复寄存器的代码。还有许多编译器优化有助于减少代码大小,本节假设指令的数量是常数,只关注硬件方面。
- 计算周期总数。假设一个理想的管线不需要插入任何气泡或停滞,它将能够每个周期完成一条指令,因此CPI为1。假设一个包含n条指令的程序,并让流水线有k个阶段,让我们计算所有n条指令离开流水线所需的周期总数。
第一条指令在周期1中进入流水线,在周期k中离开流水线,每个周期都会有一条指令离开流水线。在(n-1) 周期,所有指令都会离开流水线,循环总数为n+k- 1。CPI等于:

请注意,CPI趋于1,因为n趋于正无穷。
- 与频率的关系。让指令在单周期处理器上完成执行所需的最大时间为
 ,也称为算法工作总量。我们在计算时忽略了流水线寄存器的延迟。现在将数据路径划分为k个流水线阶段,需要添加k−1个流水线寄存器。设流水线寄存器的延迟为l,如果假设所有流水线阶段都是平衡的(做同样的工作,花费同样的时间),那么最慢的指令在一个阶段完成工作所需的时间等于
,也称为算法工作总量。我们在计算时忽略了流水线寄存器的延迟。现在将数据路径划分为k个流水线阶段,需要添加k−1个流水线寄存器。设流水线寄存器的延迟为l,如果假设所有流水线阶段都是平衡的(做同样的工作,花费同样的时间),那么最慢的指令在一个阶段完成工作所需的时间等于 。每阶段的总时间等于电路延迟和流水线寄存器的延迟:
。每阶段的总时间等于电路延迟和流水线寄存器的延迟:

现在,最小时钟周期时间必须等于流水线阶段的延迟,因为设计流水线时的假设是每个阶段只需要一个时钟周期。因此,最小时钟周期时间( )或最大频率(f)等于:
)或最大频率(f)等于:

下面计算管线的性能。简单地假设性能等于(f/CPI),因为指令数是常数(n)。

尝试通过选择正确的k值来最大化性能,有:

需要在CPI方程中纳入停顿的影响,假设指令(n)的数量非常大。让理想的CPI是 ,在本例,=1,有:
,在本例,=1,有:

为了最大化性能,需要将分母最小化,得到:

为了确定管线阶段的最佳数量的性能,假设n是正无穷,因此(n+k−1)/n趋近于1,因此有:

大多数时候,我们不会衡量处理器对一个程序的性能。考虑一组已知的基准程序,并测量处理器相对于所有程序的性能,以获得统一的图形。大多数处理器供应商通常总结其处理器相对于SPEC(Standard Performance Evaluation Corporation)的性能基准,发布用于测量、总结和报告处理器和软件系统性能的基准套件。
计算机架构通常使用SPEC CPU基准套件来衡量处理器的性能。SPEC CPU 2006基准有两种程序类型:整数算术基准(SPECint)和浮点基准(SPECfp)有12个用C/C++编写的SPECint基准测试。基准测试包含C编译器、基因测序器、AI引擎、离散事件模拟器和XML处理器的部分,在类似的线路上,SPECfp套件包含17个程序,解决了物理、化学和生物学领域的不同问题。
大多数处理器供应商通常计算SPEC分数,代表处理器的性能,建议的过程是采用基准测试在参考处理器上花费的时间与基准测试在给定处理器上花费时间的比率,SPEC分数等于所有比率的几何平均值。在计算机体系结构中,当我们报告平均相对性能(如SPEC分数)时,通常使用几何平均值。对于报告平均执行时间(绝对时间),可以使用算术平均值。
有时报告的不是SPEC分数,而是平均每秒执行的指令数,而对于科学程序,则是平均每秒浮点运算数,这些指标提供了处理器或处理器系统的速度指示。通常使用以下术语:
- KIPS:每秒千(103103)条指令。
- MIPS:每秒百万(106106)条指令。
- MFLOPS:每秒百万(106106)次浮点运算。
- GFLOPS:每秒千兆(109109)次浮点运算。
- TFLOPS:每秒万亿(10121012)次浮点运算。
- PFLOPS:每秒千万亿(10151015)次浮点运算。
现在通过查看性能、编译器设计、处理器架构和制造技术之间的关系来总结讨论。再次考虑性能等式:

如果最终目标是最大化性能,那么需要最大化频率(f)和IPC,同时最小化动态指令(#insts)的数量。有三个变量在我们的控制之下,即处理器架构、制造技术和编译器。请注意,此处使用术语“构架”来指代处理器的实际组织和设计,然而文献通常使用体系结构来指ISA和处理器的设计。下面详细阐述每个变量。
- 编译器
通过使用智能编译器技术,可以减少动态指令的数量,也可以减少暂停的数量,将改善IPC。下面示例通过重新排序add和ld指令来删除一个暂停周期。在类似的行中,编译器通常会分析数百条指令,并对它们进行最佳排序,以尽可能减少暂停。
; -----示例1-----
; 在不违反程序正确性的情况下重新排序以下代码,以减少暂停。
add r1, r2, r3
ld r4, 10[r5]
sub r1, r4, r2
;答案
ld r4, 10[r5]
add r1, r2, r3
sub r1, r4, r2
; 没有加载-使用冲突,程序的逻辑保持不变。
; -----示例2-----
; 在不违反程序正确性的情况下重新排序以下代码,以减少暂停。假设有2个延迟时隙的延迟分支.
add r1, r2, r3
ld r4, 10[r5]
sub r1, r4, r2
add r8, r9, r10
b .foo
; 答案
add r1, r2, r3
ld r4, 10[r5]
b .foo
sub r1, r4, r2
add r8, r9, r10
; 消除了加载-使用风险,并最佳地使用了延迟时隙。
- 架构
我们使用流水线设计了一个高级架构。请注意,流水线本身并不能提高性能,由于暂停,与单周期处理器相比,流水线减少了程序的IPC。流水线的主要好处是它允许我们以更高的频率运行处理器,最小周期时间从单循环流水线的 减少到k级流水线机器的/k+l。由于每个周期都完成一条新指令的执行,除非出现暂停,所以可以在流水线机器上更快地执行一组指令,指令执行吞吐量要高得多。
减少到k级流水线机器的/k+l。由于每个周期都完成一条新指令的执行,除非出现暂停,所以可以在流水线机器上更快地执行一组指令,指令执行吞吐量要高得多。
流水线的主要好处是以更高的频率运行处理器,可以确保更高的指令吞吐量(更多的指令每秒完成执行)。与单周期处理器相比,流水线本身减少了程序的IPC,也增加了处理任何单个指令所需的时间。
延迟分支和转发等技术有助于提高流水线机器的IPC,我们需要专注于通过各种技术提高复杂管线的性能。需要注意的重要一点是,架构技术影响频率(通过流水线阶段的数量)和IPC(通过转发和延迟分支等优化)。
- 制造工艺
制造工艺影响晶体管的速度,进而影响组合逻辑块和锁存器的速度,晶体管越小,速度越快。因此总算法工作量()和锁存延迟(l)也在稳步减少,可以在更高的频率下运行处理器,从而提高性能。制造技术只影响我们运行处理器的频率,对IPC或指令数量没有任何影响。
总之,可以用下图总结这一段的讨论。

性能、编译器、架构和技术之间的关系。
请注意,总体情况并不像本节描述的那么简单,还需要考虑功率和复杂性问题。通常,由于复杂性的增加,实现超过20个阶段的流水线非常困难。其次,大多数现代处理器都有严重的功率和温度限制,这个问题也称为功率墙(power wall,下图)。通常不可能提高频率,因为我们无法承受功耗的增加,根据经验法则,功率随频率的立方而增加,将频率增加10%会使功耗增加30%以上,非常之大。设计者越来越避免以非常高的频率运行的深度流水线设计。

英特尔x86微处理器的时钟频率和功耗超过八代30年。奔腾4在时钟频率和功率上有了戏剧性的飞跃,但在性能上没有那么出色。Prescott的热问题导致了奔腾4系列的报废。Core 2系列恢复为更简单的流水线,具有更低的时钟速率和每个芯片多个处理器。Core i5管道紧随其后。
关于性能,最后要进一步讨论的是功率和温度的问题。
功率和温度问题在这些年变得越来越重要。高性能处理器芯片通常在正常操作期间消耗60-120W的功率。,如果在一台服务器级计算机中有四个芯片,那么将大致消耗400W的功率。一般来说,计算机中的其他组件,如主存储器、硬盘、外围设备和风扇,也会消耗类似的电量,总功耗约为800W。如果增加额外的开销,例如电源、显示硬件的非理想效率,则功率需求将达到约1KW。一个拥有100台服务器的典型服务器场将需要100千瓦的电力来运行计算机。此外还需要冷却装置(如空调),通常为了去除1W的热量,需要0.5W的冷却功率,因此服务器农场的总功耗约为150千瓦。相比之下,一个典型的家庭的额定功率为6-8千瓦,意味着一个服务器农场消耗的电力相当于20-25个家庭使用的电力,非常显而易见。请注意,包含100台机器的服务器场是一个相对较小的设置,实际上,有更大的服务器农场,包含数千台机器,需要兆瓦的电力,足以满足一个小镇的需求。
现在考虑真正的小型设备,比如手机处理器,由于电池寿命有限,功耗也是一个重要问题。所有人都会喜欢电池续航很长的设备,尤其是功能丰富的智能手机。现在考虑更小的设备,例如嵌入身体内部的小型处理器,用于医疗应用,通常在起搏器等设备中使用小型微芯片。在这种情况下,不想强迫患者携带重型电池,或经常给电池充电,从而给患者带来不便。为了延长电池寿命,重要的是尽可能减少耗电。
此外,温度是一个非常密切相关的概念。结合下图中芯片的典型封装图,通常有一个200-400平方毫米的硅管芯(silicon die),管芯是指包含芯片电路的矩形硅块。由于这一小块硅耗散60-100W的功率(相当于6-10个CFL灯泡),除非采取额外措施冷却硅管芯,否则其温度可能会升至200摄氏度。首先在硅管芯上添加一块5cm x 5cm的镀镍铜板,就是所谓的扩散器,扩散器通过传播热量,从而消除热点,有助于在模具上形成均匀的温度分布。需要一个扩散器,因为芯片的所有部分都不会散发相同的热量,例如ALU通常耗散大量热量,而存储元件相对较冷。其次,散热取决于程序的性质,对于整数基准测试,浮点ALU是空闲的,会更冷。为了确保热量正确地从硅管芯流到扩散器,通常添加一种导热凝胶,称为热界面材料(TIM)。

大多数芯片都有一种结构,即散热器顶部的散热器。它是一种铜基结构,具有一系列鳍片,如上图所示。添加了一系列鳍片以增加其表面积,确保处理器产生的大部分热量可以散发到周围的空气中。在台式机、笔记本电脑和服务器中使用的芯片中,有一个风扇安装在散热器上,或者安装在计算机机箱中,将空气吹过散热器,确保热空气被驱散,而来自外部的冷空气流过散热器。散热器、散热器和风扇的组合有助于散热处理器产生的大部分热量。
尽管采用了先进的冷却技术,处理器仍能达到60-100摄氏度。在玩高度互动的电脑游戏时,或者在运行天气模拟等大量数据处理应用程序时,芯片上的温度最高可达120摄氏度,足以烧开水、煮蔬菜,甚至在冬天温暖一个小房间,我们不需要买加热器,只需要运行一台计算机!请注意,温度有很多有害影响:
- 片上铜线和晶体管的可靠性随着温度的升高呈指数下降。由于一种被称为NBTI(负偏置温度不稳定性)的效应,芯片往往会随着时间老化,老化有效地减缓了晶体管的速度。因此,有必要随着时间的推移降低处理器的频率,以确保正确的操作。
- 一些功耗机制(如泄漏功率)取决于温度,意味着随着温度的升高,总功率的泄漏分量也随之升高,进一步提高了温度。
总之,为了降低电费、降低冷却成本、延长电池寿命、提高可靠性和减缓老化,降低芯片上的功率和温度非常重要。现在让我们快速回顾一下主要的功耗机制。主要关注两种机制,即动态和泄漏功率(leakage power),泄漏功率也称为静态功率。
先阐述动态功率。
可以把芯片的封装看作一个封闭的黑盒子,有电能流入,热量流出。在足够长的时间段内,流入芯片的电能的量完全等于根据能量守恒定律作为热量耗散的能量的量。此处忽略了沿I/O链路发送电信号所损失的能量,但与整个芯片的功耗相比,该能量可以忽略不计。
任何由晶体管和铜线组成的电路都可以被建模为具有电阻器、电容器和电感器的等效电路。电容器和电感器不散热,但电阻器将流经电阻器的一部分电能转换为热量,这是电能在等效电路中转化为热能的唯一机制。
现在考虑一个小电路,它有一个电阻器和一个电容器,如下图所示,电阻器代表电路中导线的电阻,电容器表示电路中晶体管的等效电容。需要注意的是,电路的不同部分,例如晶体管的栅极,在给定的时间点具有一定的电势,意味着晶体管的栅极起着电容器的作用,从而存储电荷。类似地,晶体管的漏极和源极具有等效的漏极电容和源极电容。通常不会在简单的分析中考虑等效电感,因为大多数导线通常很短,并且它们不起电感器的作用。

具有电阻和电容的电路。
耗散的功率与频率和电源电压的平方成正比,请注意,该功耗表示由于输入和输出中的转变而引起的电阻损耗,它被称为动态功率。因此有:

动态功率(dynamic power)是由于电路中所有晶体管的输入和输出转变而消耗的累积功率。
下面阐述静态功率(泄露功率)。
请注意,动态功耗不是处理器中唯一的功耗机制,静态或泄漏功率是高性能处理器功耗的主要组成部分,大约占处理器总功率预算的20-40%。
到目前为止,我们一直假设晶体管在截止状态时不允许任何电流流过,电容器的端子之间或NMOS晶体管的栅极和源极之间绝对没有电流流过,所有这些假设都不是严格正确的。在实践中,没有任何结构是完美的绝缘体,即使在关闭状态下,也有少量电流流过其端子。可以在理想情况下不应该通过电流的其他接口上有许多其他泄漏电源,这种电流源统称为泄漏电流,相关的功率耗散称为泄漏功率。
泄漏功率耗散有不同的机制,如亚阈值泄漏和栅极诱导漏极泄漏。研究人员通常使用BSIM3模型中的以下方程计算泄漏功率(主要捕获亚阈值泄漏):

其中:

注意,泄漏功率通过 变量取决于温度。为了显示温度相关性,可以简化方程以获得以下方程:
变量取决于温度。为了显示温度相关性,可以简化方程以获得以下方程:

上述公式中,A和B是常数。大约20年前,当晶体管阈值电压较高时(约500 mV),泄漏功率与温度呈指数关系,因此温度的小幅度升高将转化为泄漏功率的大幅度增加。然而,如今的阈值电压在100-150 mV之间,因此温度和泄漏之间的关系变得近似线性。
需要注意的是,泄漏功率始终由电路中的所有晶体管耗散,泄漏电流的量可能很小,但是当考虑数十亿晶体管的累积效应时,泄漏功率耗散的总量是相当大的,甚至可能成为动态功率的很大一部分。由此,设计人员试图控制温度以控制泄漏功率。总功率由下式给出:

下面来建模温度。
对芯片上的温度建模是一个相当复杂的问题,需要大量的热力学和传热背景知识,这里陈述一个基本结果。让我们把硅管芯的面积分成一个网格,将网格点编号为1 ... m,功率向量Ptot表示每个网格点耗散的总功率,类似地,让每个网格点的温度由向量T表示。对于大量网格点,功率和温度通常由以下线性方程关联:

 被称为环境温度,是周围空气的温度。
被称为环境温度,是周围空气的温度。- A是m * m矩阵,也称为热阻矩阵。根据公式,温度(T)的变化和功耗彼此线性相关。
请注意,在 是温度的函数,和上述公式形成反馈回路。因此,我们需要假设温度的初始值,计算泄漏功率,估计新的温度,计算泄漏功耗,并不断迭代直到值收敛。
是温度的函数,和上述公式形成反馈回路。因此,我们需要假设温度的初始值,计算泄漏功率,估计新的温度,计算泄漏功耗,并不断迭代直到值收敛。
4 高级技术
本节将简要介绍实现处理器的高级技术。请注意,本节绝不是独立的,其主要目的是为读者提供额外学习的指导。本节将介绍几个大幅度提高性能的广泛范例,这些技术被最先进的处理器采用。
现代处理器通常使用非常深的流水线(12-20阶段)在同一周期内执行多条指令,并采用先进技术消除流水线中的冲突。让我们看看一些常见的方法。
4.1 分支预测
让我们从IF阶段开始,看看如何做得更好。如果在管线中有一个执行的分支,那么IF阶段尤其需要在管线中暂停2个周期,然后需要开始从分支目标中提取。随着我们添加更多的线线阶段,分支惩罚(branch penalty)从2个周期增加到20多个周期,使得分支指令非常昂贵,会严重限制性能。因此,有必要避免管线暂停,即使对于已采取的分支也是如此。
如果可以预测分支的方向,也可以预测分支目标,那会怎么样?在这种情况下,提取单元可以立即从预测的分支目标开始提取。如果在稍后的时间点发现预测错误,则需要取消预测错误的分支指令之后的所有指令,并将其从管线中丢弃,这种指令也称为推测指令(speculative instruction)。
现代处理器通常根据预测执行大量指令集,例如预测分支的方向,并相应地从预测的分支目标开始提取指令,稍后执行分支指令时验证预测。如果发现预测错误,则从管线中丢弃所有错误获取或执行的指令,这些指令称为推测指令(speculative instruction)。相反,正确获取并执行的指令,或其预测已验证的指令称为非推测指令。
请注意,禁止推测性指令更改寄存器文件或写入内存系统是极其重要的,因此需要等待指令变得非推测性,然后才允许它们进行永久性的更改。第二,不允许它们在非推测之前离开管线,但如果需要丢弃推测指令,那么现代管线采用更简单的机制,通常会删除在预测失败的分支指令之后获取的所有指令,而不是选择性地将推测指令转换为管线气泡。这个简单的机制在实践中非常有效,被称为管线刷新(pipeline flush)。
现代处理器通常采用一种简单的方法,即丢弃管线中的所有推测指令。它们完全完成所有指令的执行,直到出现预测失误的指令,然后清理整个管线,有效地删除在预测失误指令之后获取的所有指令。这种机制称为管线刷新(pipeline flush)。
现在概述分支预测中的主要挑战:
- 如果一条指令是一个分支,需要在提取阶段首先读取,如果是分支,需要读取分支目标的地址。
- 接下来,需要预测分支的预期方向。
- 有必要监测预测指令的结果。如果存在预测失误,那么需要在稍后的时间点执行管线刷新,以便能够有效地删除所有推测指令。
在分支的情况下检测预测失误是相当直接的,将预测添加到指令包中,并用实际结果验证预测。如果它们不同,那么安排管线刷新。主要的挑战是预测分支指令的目标及其结果。
现代处理器使用称为分支目标缓冲器(BTB)的简单硬件结构,它是一个简单的内存阵列,保存最后N(从128到8192不等)条分支指令的程序计数器及其目标。找到匹配的可能性很高,因为程序通常表现出一定程度的局部性,意味着它们倾向于在一段时间内重复执行同一段代码,例如循环,因此BTB中的条目往往会在很短的时间内被重复使用。如果存在匹配,那么也可以自动推断该指令是分支。
要有效地预测分支的方向要困难得多,但可以利用后面阐述的模式。程序中的大多数分支通常位于循环或if语句中,其中两个方向的可能性不大,事实上,一个方向的可能性远大于另一个方向,例如循环中的分支占用了大部分时间。有时if语句仅在某个异常条件为真时才求值,大多数情况下,与这些if语句关联的分支都不会被执行。类似地,对于大多数程序,设计者观察到几乎所有的分支指令都遵循特定的模式,它们要么对一个方向有强烈的偏倚,要么可以根据过去的历史进行预测,要么可以基于其它分支的行为进行预测。当然,这种说法没有理论依据,只是处理器设计者的观察结果,因此他们设计了预测器来利用程序中的这种模式。
本节讨论一个简单的2位分支预测器。假设有一个分支预测表,该表为表中的每个分支分配一个2位值,如下图所示。

如果该值为00或01,则预测该分支不会被执行。如果它等于10或11,那么预测分支被执行。此外,每次执行分支时,将相关计数器递增1,每次不执行分支时将计数器递减1。为了避免溢出,不将11递增1以产生00,也不将00递减以产生11。我们遵循饱和算术的规则,即(二进制):11+1=1111+1=11和00−1=0000−1=00。这个2位值被称为2位饱和计数器,其状态图如下图所示。

预测分支有两种基本操作:预测和训练。为了预测分支,我们在分支预测表中查找其程序计数器的值,在特定情况下,使用pc地址的最后n位来访问2n个条目的分支预测表。读取2位饱和计数器的值,并根据其值预测分支,当得到分支的实际结果时,我们训练通过使用饱和算法递增或递减计数器的值。
现在看看这个预测器的工作原理,考虑一段简单的C代码及其等效的汇编代码:
void main()
{
foo();
...
foo();
}
int foo()
{
int i, sum = 0
for(i=0; i < 10; i++)
{
sum = sum + i;
}
return sum;
}
.main:
call .foo
...
call .foo
.foo:
mov r0, 0 /* sum = 0 */
mov r1, 0 /* i = 0 */
.loop:
add r0, r0, r1 /* sum = sum + i */
add r1, r1, 1 /* i = i + 1 */
cmp r1, 10 /* compare i with 10 */
bgt .loop /* if(r1 > 10) jump to .loop */
ret
让我们看看循环中的分支语句bgt .loop,对于除最后一次之外的所有迭代,都会执行分支。如果在状态10下启动预测器,那么第一次,分支预测正确(采取),计数器递增并等于11,对于后续的每一次迭代,都会正确地预测分支。然而,在最后一次迭代中,需要将其预测为未采取,这里有一个错误的预测,因此,2位计数器递减,并设置为10。现在考虑一下再次调用函数foo时的情况,2位计数器的值为10,并且分支bgt .loop被正确预测为采用。
因此,2位计数器方案在预测方案中增加了一点延迟(或过去的历史)。如果分支历史上一直在一个方向,那么一个异常不会改变预测。这个模式对于循环非常有用,正如在这个简单的例子中看到的那样,循环最后一次迭代中分支指令的方向总是不同的,但下一次进入循环时,分支的预测是正确的,正如本例所示。请注意,这只是其中一种模式,现代分支预测程序可以利用更多类型的模式。
程序优化提示:
- 为编译器提供尽可能多的有关正在执行的操作的信息。
- 尽可能使用常量和局部变量。如果语言允许,请定义原型并声明静态函数。
- 尽可能使用数组而不是指针。
- 避免不必要的类型转换,并尽量减少浮点到整数的转换。
- 避免溢出和下溢。
- 使用适当的数据类型(如float、double、int)。
- 考虑用乘法代替除法。
- 消除所有不必要的分支。
- 尽可能使用迭代而不是递归。
- 首先使用最可能的情况构建条件语句(例如if、switch、case)。
- 在结构中按尺寸顺序声明变量,首先声明尺寸最大的变量。
- 当程序出现性能问题时,请在开始优化程序之前对程序进行概要分析。(评测是将代码分成小块,并对每一小块进行计时,以确定哪一块花费的时间最多的过程。)
- 切勿仅基于原始性能放弃算法。只有当所有算法都完全优化时,才能进行公平的比较。
- 过程内联(procedure inlining),用函数体替换对函数的调用,用调用者的参数替换过程的参数。
- 循环转换(loop
transformation),可以减少循环开销,改善内存访问,并更有效地利用硬件。
- 循环展开(loop-unrolling)。在执行多次迭代的循环中,例如那些传统上由For语句控制的循环,循环展开loop-unrolling的优化通常有用。循环展开包括进行循环,多次复制身体,并减少执行转换后的循环的次数。循环展开减少了循环开销,并为许多其他优化提供了机会。
- 复杂的循环转换,如交换嵌套循环和阻塞循环以获得更好的内存行为。
- 局部和全局优化。在专用于局部和全局优化的过程中,执行以下优化:
- 局部优化在单个基本块内工作。局部优化过程通常作为全局优化的先导和后续运行,以在全局优化前后“清理”代码。
- 全局优化跨多个基本块工作。
- 全局寄存器分配为代码区域的寄存器分配变量。寄存器分配对于在现代处理器中获得良好性能至关重要。
- 更具体地,有子表达式消除(Common subexpression elimination)、削减强度(Strength reduction)、常量传播(Constant propagation)、拷贝传播(Copy propagation)、死存储消除(Dead store elimination)等操作。
如果使用两个位,则可以使用它们来记录相关指令执行的最后两个实例的结果,或者以其他方式记录状态。下图显示了一种典型的方法,假设算法从流程图的左上角开始。只要执行遇到的每个后续条件分支指令,决策过程就预测将执行下一个分支,如果单个预测错误,则算法继续预测下一个分支被执行。只有在没有采取两个连续分支的情况下,算法才会转移到流程图的右侧,随后该算法将预测在一行中的两个分支被取下之前不会取下分支,因此该算法需要两个连续的错误预测来改变预测决策。

分支预测流程图。
预测过程可以用有限状态机更紧凑地表示,如下图所示,许多文献通常使用有限状态机表示。

分支预测状态图。
下图将该方案与从未采取的预测策略进行了对比。使用前一种策略,指令获取阶段总是获取下一个顺序地址。如果执行了分支,处理器中的某些逻辑会检测到这一点,并指示从目标地址提取下一条指令(除了刷新管道之外)。分支历史表被视为缓存,每个预取都会触发分支历史表中的查找。如果未找到匹配项,则使用下一个顺序地址进行提取,如果找到匹配,则根据指令的状态进行预测:下一个顺序地址或分支目标地址被馈送到选择逻辑。

为了弥补依赖性,已经开发了代码重组技术,首先考虑分支指令。延迟分支(Delayed branch)是一种提高流水线效率的方法,它使用的分支在执行以下指令后才生效(因此称为延迟),紧接在分支之后的指令位置被称为延迟槽(delay slot)。这个奇怪的过程如下表所示。在标记为“正常分支”的列中,有一个正常的符号指令机器语言程序。执行102之后,下一条要执行的指令是105。为了规范流水线,在这个分支之后插入一个NOOP。但是,如果在101和102处的指令互换,则可以实现提高的性能。

下图显示了结果。图a显示了传统管线方法。JUMP指令在时间4被获取,在时间5,JUMP指令与指令103(ADD指令)被获取的同时被执行。因为发生了JUMP,它更新了程序计数器,所以必须清除流水线中的指令103,在时间6,作为JUMP的目标的指令105被加载。
图b显示了典型RISC组织处理的相同管线,时间是一样的,但由于插入了NOOP指令,不需要特殊的电路来清除管线,NOOP简单地执行而没有效果。
图c显示了延迟分支的使用。JUMP指令在ADD指令之前的时间2获取,ADD指令在时间3获取。但请注意,ADD指令是在执行JUMP指令有机会改变程序计数器之前获取的。因此,在时间4期间,在获取指令105的同时执行ADD指令,保留了程序的原始语义,但执行需要两个更少的时钟周期。

4.2 延迟加载
类似延迟分支的策略称为延迟加载(delayed load),可以用于加载指令。在LOAD指令中,将成为加载目标的寄存器被处理器锁定。然后,处理器继续执行指令流,直到它到达需要该寄存器的指令为止,此时它将空闲,直到加载完成。如果编译器可以重新排列指令,以便在加载过程中完成有用的工作,那么效率就会提高。
4.3 循环展开
另一种提高指令并行性的编译器技术是循环展开(loop unrolling)。展开会多次复制循环体,称为展开因子(u),并按步骤u而不是步骤1进行迭代:
- 减少环路开销
- 通过提高流水线性能提高指令并行性
- 改进寄存器、数据缓存或TLB位置
下图在一个示例中说明了所有三种改进。循环开销减少了一半,因为在测试之前执行了两次迭代,并在循环结束时分支。由于可以在存储第一次赋值的结果和更新循环变量的同时执行第二次赋值,因此提高了指令并行性。如果将数组元素分配给寄存器,寄存器局部性将得到改善,因为在循环体中使用了两次a[i]和a[i+1],从而将每次迭代的加载次数从三次减少到两次。

指令流水线的设计不应与应用于系统的其他优化技术分离,例如流水线的指令调度和寄存器的动态分配应该一起考虑,以实现最大的效率。
4.4 顺序管线的问题
在简单管线中,每个周期只执行一条指令,但并非绝对必要。我们可以设计一个处理器,比如最初的英特尔奔腾,它有两条并行管线。该处理器可以在一个周期内同时执行两条指令。这些管道具有额外的功能单元,因此两条管线中的指令都可以在没有任何重大结构冲突的情况下执行。该策略增加了IPC,但也使处理器更加复杂。这样的处理器被称为包含多个顺序执行管线,因为可以在同一个周期内向执行单元发布多条指令。每个周期可以执行多条指令的处理器也称为超标量处理器(superscalar processor)。
其次,这种处理器被称为有序处理器(in-order processor),因为它按程序顺序执行指令,程序顺序是指令的动态实例在程序中出现时的执行顺序。例如,单周期处理器或流水线处理器按程序顺序执行指令。
每个周期可以执行多条指令的处理器称为超标量处理器(superscalar processor)。
有序处理器按程序顺序执行指令。程序顺序被定义为指令的动态实例的顺序,与顺序执行程序的每条指令时所感知的顺序相同。

超标量组织与普通标量组织的比较。

超标量和超流水线方法的比较。

超标量处理的概念描述。
现在,我们需要寻找两条管线的依赖性和潜在冲突。其次,转发逻辑也要复杂得多,因为结果可以从任一管线转发。英特尔发布的原始奔腾处理器有两条管线,即U管线和V管线。U管线可以执行任何指令,而V管线仅限于简单指令。指令作为2-指令束(2-instruction bundle)获取,指令束中的前一条指令被发送到U管线,后一条指令则被发送到V管线。这种策略允许并行地执行这些指令。
让我们尝试在概念上设计一个简单的处理器,它采用了原始奔腾处理器的两条流水线:U和V。我们设想了一个组合的指令和操作数获取单元,它形成2-指令束,并被发送到两个流水线以同时执行。但如果指令不满足某些约束,则该单元形成1-指令束并将其发送到U流水线。无论何时,我们生成这样的束,都可以广泛遵守一些通用规则,应该避免具有RAW依赖性的两条指令,在这种情况下,管线将暂停。
其次,需要特别注意内存指令,因为它们之间的依赖关系在EX阶段结束之前无法发现。假设指令束中的第一条指令是存储指令,第二条指令是加载指令,并且它们碰巧访问相同的内存地址。需要在EX阶段结束时检测这种情况,并将值从存储转发到加载。对于相反的情况,当第一条指令是加载指令,第二条指令是存储到相同地址时,需要暂停存储指令,直到加载完成。如果指令束中的两条指令都存储到同一地址,那么前面的指令是冗余的,可以转换为nop。因此,需要设计一个符合这些规则的处理器,并具有复杂的互锁和转发逻辑。
下面展示一个简单的例子。为以下汇编代码绘制一个流水线图,假设流水线中存在2个问题。
[1]: add r1, r2, r3
[2]: add r4, r5, r6
[3]: add r9, r8, r8
[4]: add r10, r9, r8
[5]: add r3, r1, r2
[6]: ld r6, 10[r1]
[7]: st r6, 10[r1]
此处,流水线图包含每个阶段的两个条目,因为两个指令可以同时在一个阶段中。我们首先观察到可以并行执行指令[1]和[2],但不能并行执行指令[3]和[4],因为指令[3]写入r9,而指令[4]将r9作为源操作数。我们不能在同一个周期内执行这两条指令,因为r9的值是在EX阶段产生的,也是EX阶段需要的。我们继续并行执行[4]和[5],在指令[4]的情况下,可以使用转发来获得r9的值。最后,我们不能并行执行指令[6]和[7],它们访问相同的内存地址,加载需要在存储开始之前完成,因此插入了另一个气泡。管线图如下:

4.5 EPIC和VLIW处理器
现在,我们可以用软件(而不是用硬件)准备指令束。编译器对代码的可见性要高得多,并且可以执行广泛的分析以创建多指令束。英特尔和惠普设计的安腾处理器是一款基于类似原理的非常经典的处理器。让我们首先从定义术语开始:EPIC和VLIW。
VLIW(Very Long Instruction Word,超长指令字):编译器创建的指令束之间没有依赖关系,硬件并行执行每个包中的指令,正确性的全部责任在于编译器。
EPIC(Explicitly Parallel Instruction Computing,显式并行指令计算):这种范例扩展了VLIW计算,但在这种情况下,无论编译器生成什么代码,硬件都会确保执行正确。
EPIC/VLIW处理器需要非常聪明的编译器来分析程序并创建指令包,例如如果一个处理器有4条流水线,那么每个束包含4条指令。编译器创建束,以便束中的指令之间不存在依赖关系。设计EPIC/VLIW处理器的更广泛的目标是将所有的复杂性转移到软件上,编译器以这样一种方式排列束,可以最大限度地减少处理器中所需的互锁、转发和指令处理逻辑。
但事后看来,这类处理器未能兑现承诺,因为硬件无法像设计者最初计划的那样简单。高性能处理器仍然需要相当复杂的硬件,并且需要一些复杂的架构特性。这些特性增加了硬件的复杂性和功耗。
4.6 乱序管线
到目前为止,我们一直在主要考虑有序管线,这些管线按照指令在程序中出现的顺序执行指令,但并不是绝对必要的。考虑下面的代码片段:
[1]: add r1, r2, r3
[2]: add r4, r1, r1
[3]: add r5, r4, r2
[4]: mul r6, r5, r2
[5]: div r8, r9, r10
[6]: sub r11, r12, r13
上面代码中,由于数据依赖性,我们被限制按顺序执行指令1到4。然而,可以并行执行指令5和6,因为它们不依赖于指令1-4。如果无序执行指令5、6,不会牺牲正确性,例如如果可以在一个周期内发出两条指令,那么可以一起提交(1,5),然后提交(2,6),最后提交指令3和4。在这种情况下,可以通过在前两个周期内执行2条指令,在4个周期中执行6条指令的序列。这种可能在每个周期执行多条指令的处理器正是超标量处理器。
可以按照与其程序顺序不一致的顺序执行指令的处理器称为乱序(Out-Of-Order,OOO,亦称无序)处理器。

超标量指令执行和完成策略。

具备乱序完备的乱序执行组织。
乱序(OOO)处理器按顺序获取指令,在提取阶段之后,它继续解码指令。大多数真实世界的指令需要一个以上的解码周期,这些指令同时按程序顺序添加到称为重新排序缓冲区(reorder buffer,ROB)的队列中。解码指令后,需要执行一个称为寄存器重命名(register renaming)的步骤。大致思路是:由于执行的指令是无序的,可能会有WAR和WAW冲突。考虑下面的代码片段:
[1]: add r1, r2, r3
[2]: sub r4, r1, r2
[3]: add r1, r5, r6
[4]: add r9, r1, r7
如果在指令[1]之前执行指令[3]和[4],那么就有潜在的WAW冲突,因为指令[1]可能会覆盖指令[3]写入的r1的值,将导致错误的执行。因此,我们尝试重命名寄存器,以便消除这些冲突。大多数现代处理器都设计了一组架构寄存器(architectural register),这些寄存器与暴露于软件(汇编程序)的寄存器相同。此外,它们还有一组仅在内部可见的物理寄存器(physical register),重命名阶段将架构寄存器名转换为物理寄存器名,以消除WAR和WAW冲突。上面代码中仅存的冲突是RAW冲突,表明存在真正的数据依赖性。因此,重命名后的代码段将如下所示,假设物理寄存器的范围为p1 … p128。
[1]: add p1, p2, p3 /* p1 contains r1 */
[2]: sub p4, p1, p2
[3]: add p100, p5, p6 /* r1 is now begin saved in p100 */
[4]: add p9, p100, p7
我们通过将指令3中的r1映射到p100,消除了WAW冲突,唯一存在的依赖关系是指令之间的RAW依赖关系[1] --> [2] 和[3] --> [4],重命名后的指令进入指令窗口。请注意,到目前为止,指令一直在按顺序处理。
指令窗口或指令队列通常包含64-128个条目(参见下图),每条指令都监视其源操作数,只要一条指令的所有源操作数都准备好了,该指令就可以提交到其相应的功能单元。指令不必总是访问物理寄存器文件,还可以从转发路径中获取值。指令完成执行后,将结果的值广播给指令窗口中的等待指令。等待结果的指令,将其相应的源操作数标记为就绪,此过程称为指令唤醒(instruction wakeup)。现在,有可能在同一周期内准备好多条指令,为了避免结构冲突,指令选择单元选择一组指令执行。

我们需要另一种用于加载和存储指令的结构,称为加载-存储(load-store)队列,它按程序顺序保存加载和存储列表,允许加载通过内部转发机制获取其值,如果同一地址有较早的存储。
指令完成执行后,我们在重新排序缓冲区中标记其条目,指令按程序顺序离开重新排序缓冲区。如果一条指令由于某种原因不能快速完成,那么重新排序缓冲区中的所有指令都需要暂停。回想一下,重新排序缓冲区中的指令条目是按程序顺序排序的,指令需要按程序顺序保留重新排序缓冲区,以便我们能够确保精确的异常。
综上所述,无序处理器(OOO)的主要优点是它可以并行执行指令,这些指令之间没有任何RAW依赖关系。大多数程序通常在大多数时间点都有这样的指令集。此属性称为指令级并行(instruction level parallelism,ILP),现代OOO处理器旨在尽可能地利用ILP。
4.7 微操作
在执行程序时,计算机的操作由一系列指令周期组成,每个周期有一条机器指令。由于分支指令的存在,这个指令周期序列不一定与组成程序的指令序列相同,这里所指的是指令的执行时间序列。
每个指令周期都由一些较小的单元组成,其中一种方便的细分是获取、间接、执行和中断,只有获取和执行周期总是发生。然而,要设计控制单元,需要进一步细分描述,而进一步的细分是可能的。事实上,我们将看到每个较小的周期都涉及一系列步骤,每个步骤都涉及处理器寄存器。这些步骤称为微操作(micro-operation)。
前缀micro指的是每个步骤都非常简单,完成的很少,下图描述了各种概念之间的关系。总之,程序的执行包括指令的顺序执行,每个指令在由较短子周期(如获取、间接、执行、中断)组成的指令周期内执行。每个子周期的执行涉及一个或多个较短的操作,即微操作。

程序执行的组成要素。
微操作是处理器的功能操作或原子操作。本节将研究微操作,以了解如何将任何指令周期的事件描述为此类微操作的序列。将使用一个简单的示例,并展示微操作的概念如何作为控制单元设计的指南。
先阐述获取周期(Fetch Cycle)。
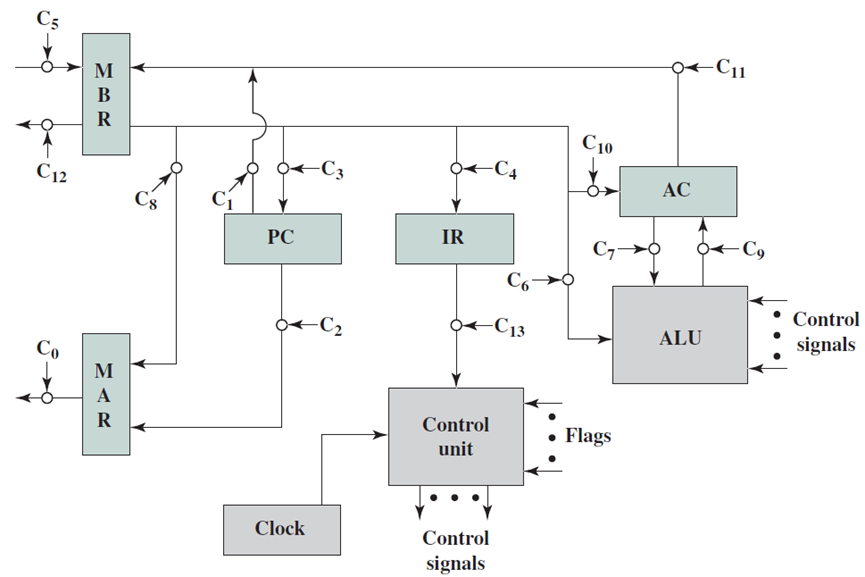
获取周期发生在每个指令周期的开始,并导致从内存中获取指令,涉及四个寄存器:
- 内存地址寄存器(MAR):连接到系统总线的地址线。它为读或写操作指定内存中的地址。
- 内存缓冲寄存器(MBR):连接到系统总线的数据线。它包含要存储在内存中的值或从内存中读取的最后一个值。
- 程序计数器(PC):保存要获取的下一条指令的地址。
- 指令寄存器(IR):保存获取的最后一条指令。
让我们从获取周期对处理器寄存器的影响的角度来看获取周期的事件序列。下图中显示了一个示例,在提取周期开始时,要执行的下一条指令的地址在程序计数器(PC)中,其中地址是1100100。
- 第一步是将该地址移动到内存地址寄存器(MAR),因为这是连接到系统总线地址线的唯一寄存器。
- 第二步是引入指令,所需地址(在MAR中)被放置在地址总线上,控制单元在控制总线上发出READ命令,结果出现在数据总线上,并被复制到内存缓冲寄存器(MBR)中。我们还需要将PC增加指令长度,以便为下一条指令做好准备。这两个动作(从内存中读取字,递增PC)互不干扰,所以可以同时执行它们以节省时间。
- 第三步是将MBR的内容移动到指令寄存器(IR),将释放MBR,以便在可能的间接循环期间使用。

事件顺序,获取周期。
因此,简单的提取周期实际上由三个步骤和四个微操作组成。每个微操作都涉及将数据移入或移出寄存器。只要这些动作不相互干扰,一步中就可以进行几个动作,从而节省时间。象征性地,我们可以将这一系列事件写成如下:

其中I是指令长度。需要对这个序列做几点评论,假设时钟可用于定时目的,并且它发出规则间隔的时钟脉冲。每个时钟脉冲定义一个时间单位,因此所有时间单位都具有相同的持续时间。每个微操作可以在单个时间单位的时间内执行,符号(t1、t2、t3)表示连续的时间单位。换句话说,我们有:
- 第一时间单位:将PC的内容移动到MAR。
- 第二时间单位:将MAR指定的内存位置的内容移动到MBR。按I递增PC的内容。
- 第三时间单位:将MBR的内容移动到IR。
注意,第二和第三微操作都发生在第二时间单位期间,第三个微操作可以与第四个微操作分组,而不影响提取操作:

微操作的分组必须遵循两个简单的规则:
- 必须遵循正确的事件顺序。因此,(MAR <--(PC))必须在(MBR <-- Memory)之前,因为内存读取操作使用MAR中的地址。
- 必须避免冲突。不应试图在一个时间单位内对同一寄存器进行读写,因为结果是不可预测的,例如微操作(MBR dMemory)和(IR dMBR)不应在同一时间单位内发生。
最后一点值得注意的是,其中一个微操作涉及相加。为了避免电路重复,可以由ALU执行此相加。ALU的使用可能涉及额外的微操作,取决于ALU的功能和处理器的组织。
此外,在非直接周期(Indirect Cycle)、中断周期(Interrupt Cycle)、执行周期(Execute Cycle)、指令周期(Instruction Cycle)等也涉及了类似的机制和原理。

指令周期流程图。
5 商业处理器案例
现在来看看一些真正的处理器的设计,这样就可以将迄今为止所学的所有概念放在实际的角度。后面将研究ARM、AMD和Intel三大处理器公司的嵌入式(用于小型移动设备)和服务器处理器。本节的目的不是比较和对比三家公司的处理器设计,甚至是同一家公司的不同型号。每一个处理器都是针对特定的细分市场进行优化设计的,并考虑到某些关键业务决策。因此,本节的重点是从技术角度研究设计,并了解设计的细微差别。
在对RISC机器的最初热情之后,人们越来越认识到:
- RISC设计可能会从包含一些CISC功能中受益。
- CISC设计可能从包含一些RISC功能中获益。结果是,较新的RISC设计,特别是PowerPC,不再是“纯”RISC,而较新的CISC设计,尤其是奔腾II和更高版本的奔腾型号,确实包含了一些RISC特性。
下表列出了一些处理器,并对它们进行了多个特性的比较。为了进行比较,以下是典型的RISC:
- 单个指令大小。
- 该大小通常为4字节。
- 少量数据寻址模式,通常少于五种,很难确定。在表中,寄存器和文字模式不计算在内,具有不同偏移量大小的不同格式分别计算在内。
- 无需进行一次内存访问以获取内存中另一个操作数的地址的间接寻址。
- 没有将加载/存储与算术相结合的操作(如从内存添加、添加到内存)。
- 每条指令不超过一个内存寻址操作数。
- 不支持加载/存储操作的数据任意对齐。
- 内存管理单元(MMU)对指令中的数据地址的最大使用次数。
- 整数寄存器说明符的位数等于或大于5,意味着一次至少可以显式引用32个整数寄存器。
- 浮点寄存器说明符的位数等于或大于4,意味着一次至少可以显式引用16个浮点寄存器。
