一、选题的背景
在当今社会,大数据已经成为了企业决策的重要依据。通过对客户进行细分分析,企业可以更好地了解客户的需求和行为,从而制定更加精准的营销策略,提高市场竞争力。要达到的数据分析目标是通过对客户数据的分析,找出不同客户群体的特征和需求,为企业提供有针对性的营销建议。从社会、经济、技术、数据来源等方面来看,随着互联网和移动互联网的快速发展,企业和个人产生的数据量呈现爆炸式增长,这为大数据分析提供了丰富的数据来源;同时,大数据技术的发展也为数据分析提供了强大的技术支持。
二、大数据分析设计方案
1.本数据集的数据内容与数据特征分析
本数据集的数据包括 客户ID,性别,客户年龄、客户年收入、客户的消费习惯。
- 客户ID:唯一标识客户的整数;
- 客户性别:区分男客户和女客户,使数据更加完整;
- 客户年龄:客户的出生年份,表示客户的年龄;
- 客户年收入:客户的年度收入,表示客户的消费能力;
- 客户的消费习惯:客户的购买行为和偏好,包括购买的商品类别、购买次数、购买金额等。
数据特征分析主要包括以下几个方面:
- 描述性统计分析:对客户年龄、客户年收入等数值型特征进行描述性统计分析,了解数据的基本情况;
- 分类特征分析:对客户的消费习惯等分类特征进行分析,找出不同类别的特征分布情况;
- 关联规则挖掘:分析不同特征之间的关联关系,如年龄与消费习惯的关系;
- 聚类分析:通过聚类算法将客户划分为不同的群体,找出每个群体的特征和需求。
2.数据分析的课程设计方案概述(包括实现思路与技术难点)
- 数据预处理:对原始数据进行清洗、缺失值处理、异常值处理等,为后续分析做好准备;
- 描述性统计分析:使用Python的pandas库进行描述性统计分析,如计算平均值、中位数、众数等;
- 聚类分析:使用K-means算法或层次聚类算法进行聚类分析,将客户划分为不同的群体;
三、数据分析步骤
1.数据源
数据来自kaggle:https://www.kaggle.com/datasets/govindkrishnadas/segment/data
2.数据清洗
导入库
#导入所需库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
plt.style.use('fivethirtyeight')
from sklearn.cluster import KMeans
import plotly as py
import plotly.graph_objects as go
import warnings
import os
warnings.filterwarnings('ignore')读取数据集并显示数据集前5行
#读取数据集并显示前5行
df=pd.read_csv('C:/Users/Administrator/Desktop/客户细分 —— k-means 聚类分析/Segmentation_dataset.csv')
df.head() 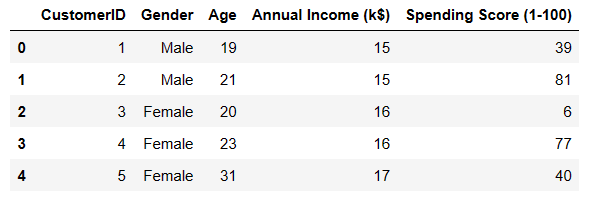
显示数据集的行和列的数量
#显示行列数
df.shape
本数据及共有1599行和5列
查看数据集是否异常
df.info()
数据集由 1599 个观测值(行)和 5 个特征变量(列)组成,无缺失值,无异常值,无重复值。数据类型包括字符串和整数,明确区分了两者。这简化了我们的分析过程。
查看各列缺失值数量
#查看各列缺失值数量
df.isnull().sum() 
各列的缺失值都为0,数据库中无缺失值
查看各列统计信息
#统计数据信息
df.describe() 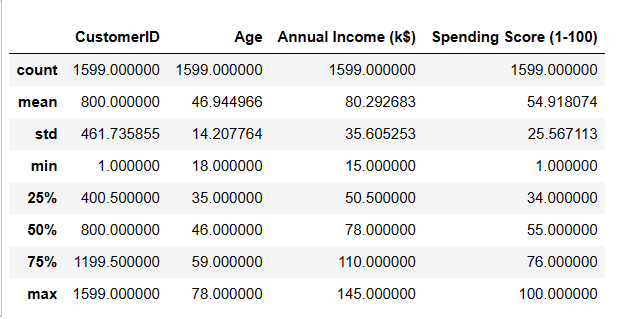
由数据集生成的统计表,包括计数、平均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值等统计指标。
3.数据分析及可视化
查看数据分布
#查看数据分布
sns.pairplot(df)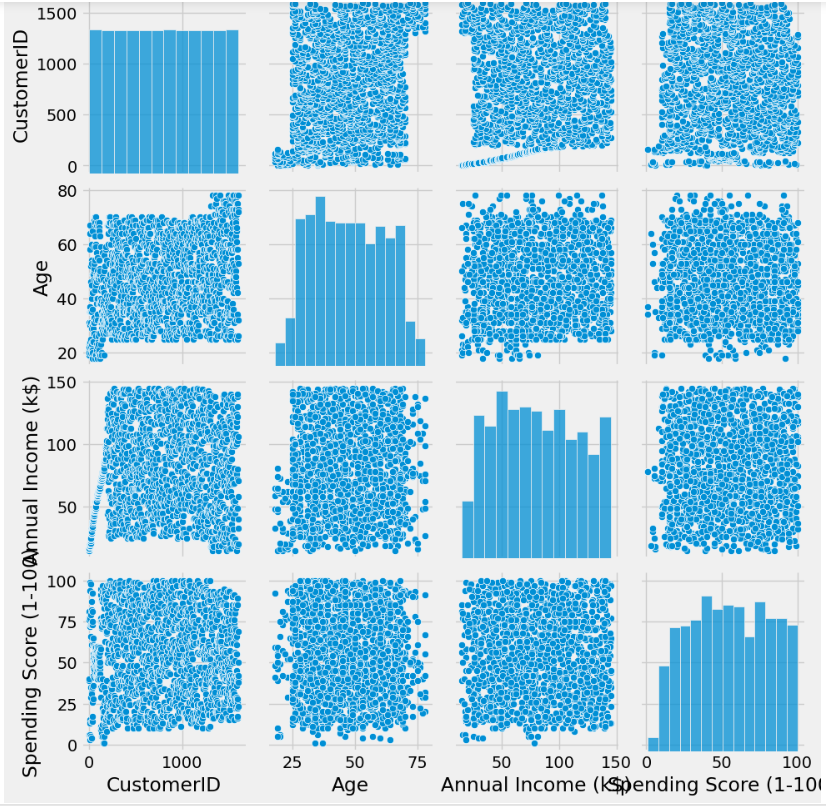
对每一对列生成一个散点图和一个直方图,以展示它们之间的关系。
单独查看直方图
#单独查看直方图
plt.figure(1,figsize=(12,6))
n=0
for x in ['Age','Annual Income (k$)','Spending Score (1-100)']:
n+=1
plt.subplot(1,3,n)
plt.subplots_adjust(hspace=0.5,wspace=0.5)
sns.distplot(df[x],bins=20)
plt.show()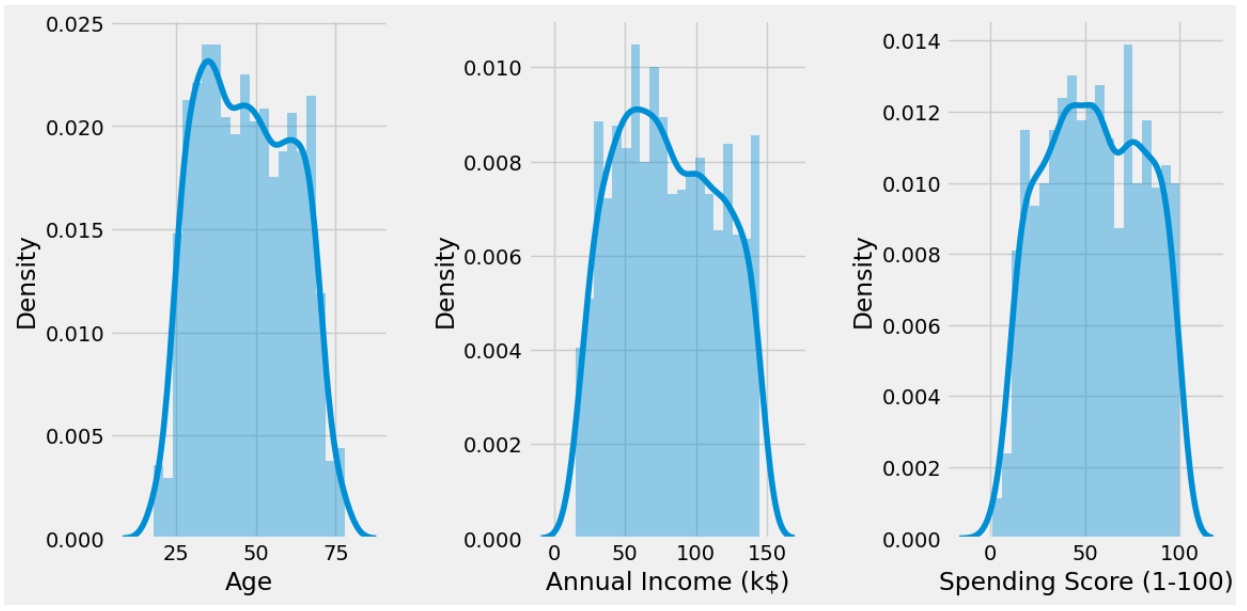
第一个柱状图显示了不同年龄段的人口密度,第二个柱状图显示了不同年龄段的支出得分(1-100),第三个柱状图显示了不同年龄段的平均年收入。从图中可以看出,随着年龄的增长,人口密度逐渐减少,而支出得分和平均年收入则呈现出不同的趋势。
样本数据中的性别比
#样本数据中的性别比
#计算每个性别的数量
df_gender_c = df['Gender'].value_counts()
#定义了标签、颜色等
p_lables = ['Female', 'Male']
p_color = ['lightcoral', 'lightskyblue']
p_explode = [0, 0.03]
# 绘图
#创建一个10x10的图形窗口
plt.figure(1,figsize=(10,10))
plt.pie(df_gender_c, labels=p_lables, colors=p_color, explode=p_explode, shadow=True, autopct='%.2f%%')
plt.title('Sex Ratio',fontsize=20)
plt.axis('off')
plt.legend(fontsize=14)
plt.legend()
plt.show()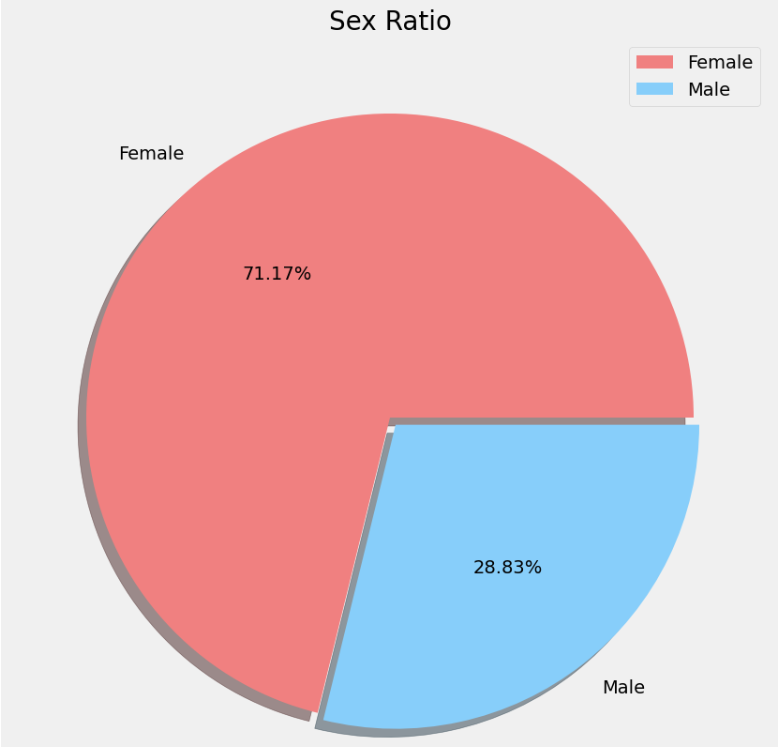
从图中可以看出,女性占总人口的比例为71.17%,而男性则占28.83%。这个图形的意义是直观地展示出不同性别在总体中所占的比例,有助于了解人口结构中的性别差异。
年龄与年收入之间的关系
# 导入matplotlib.pyplot库,用于绘制图形
import matplotlib.pyplot as plt
# 设置字体为SimHei,支持中文显示
plt.rcParams['font.sans-serif'] = [u'SimHei']
# 设置负号正常显示
plt.rcParams['axes.unicode_minus'] = False
# 创建一个12x6英寸的图形窗口
plt.figure(1,figsize=(12,6))
# 遍历性别列表,分别绘制男性和女性的散点图
for gender in ['Male','Female']:
# 使用scatter函数绘制散点图,x轴为年龄,y轴为年收入,数据来源为df中性别为当前性别的数据
plt.scatter(x='Age',y='Annual Income (k$)',data=df[df['Gender']==gender],
s=100,alpha=0.5,label=gender)
# 设置x轴标签为“Age”,y轴标签为“Annual Income (k$)”
plt.xlabel('Age'),plt.ylabel('Annual Income (k$)')
# 设置图形标题为“不同性别在年龄与年收入之间的关系”
plt.title('不同性别在年龄与年收入之间的关系')
# 显示图例
plt.legend()
# 显示图形
plt.show()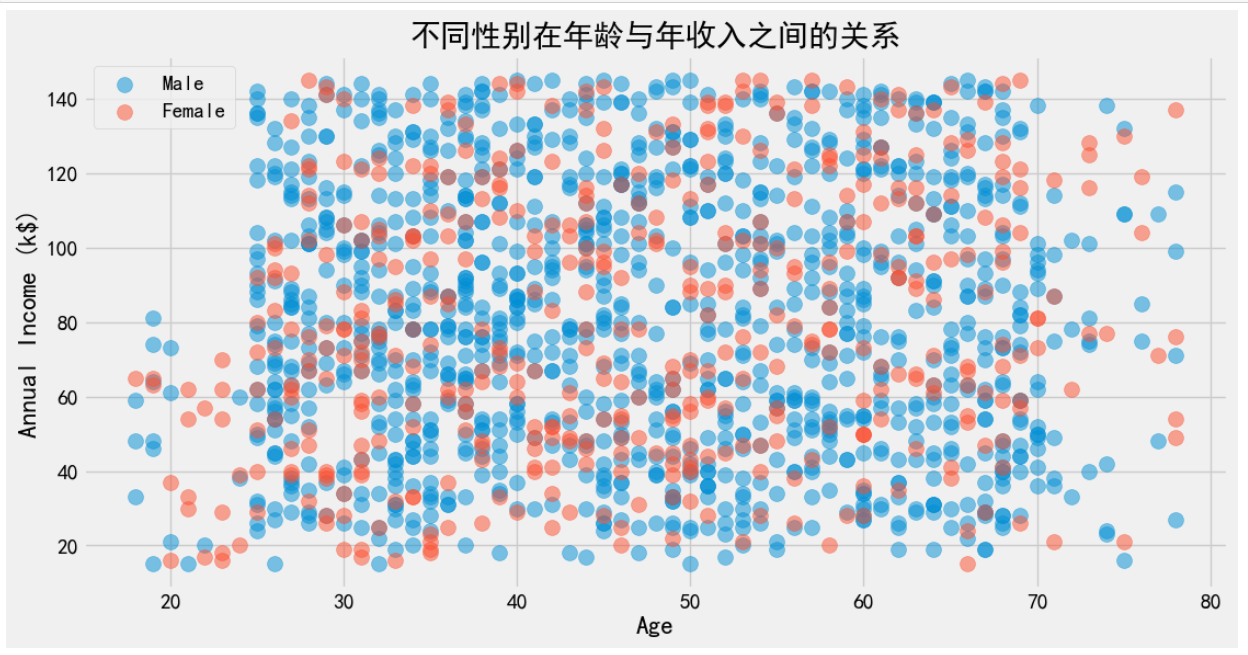
从图像中可以看出,不同性别在年龄与年收入之间存在差异。这意味着不同性别在相同年龄段的年收入水平可能存在差异,或者不同性别在不同年龄段的年收入水平也存在差异。
年龄与消费得分之间的关系
#不同性别在年龄与年收入之间的关系
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(1,figsize=(12,6))
for gender in ['Male','Female']:
plt.scatter(x='Age',y='Spending Score (1-100)',data=df[df['Gender']==gender],
s=100,alpha=0.5,label=gender)
plt.xlabel('Age'),plt.ylabel('Spending Score (1-100)')
plt.title('不同性别在年龄与消费得分之间的关系')
plt.legend()
plt.show()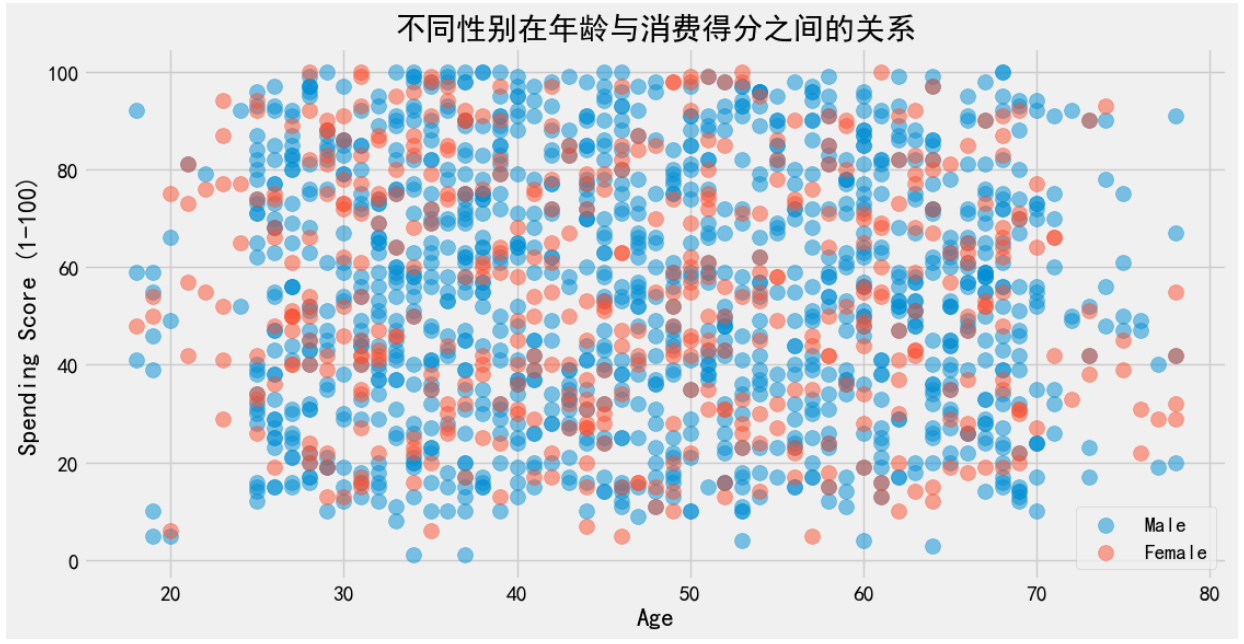
从图中可以看出,男性的消费得分普遍较高,而女性的消费得分则相对较低。随着年龄的增长,消费得分呈现出一定的波动性,但整体趋势是男性在年轻时消费得分较高,而女性在年长时消费得分较低。
年收入与消费得分之间的关系
#不同性别在年收入与消费得分之间的关系
plt.figure(1,figsize=(12,6))
for gender in ['Male','Female']:
plt.scatter(x='Annual Income (k$)',y='Spending Score (1-100)',data=df[df['Gender']==gender],
s=100,alpha=0.5,label=gender)
plt.xlabel('Annual Income (k$)'),plt.ylabel('Spending Score (1-100)')
plt.title('不同性别在年收入与消费得分之间的关系')
plt.legend()
plt.show()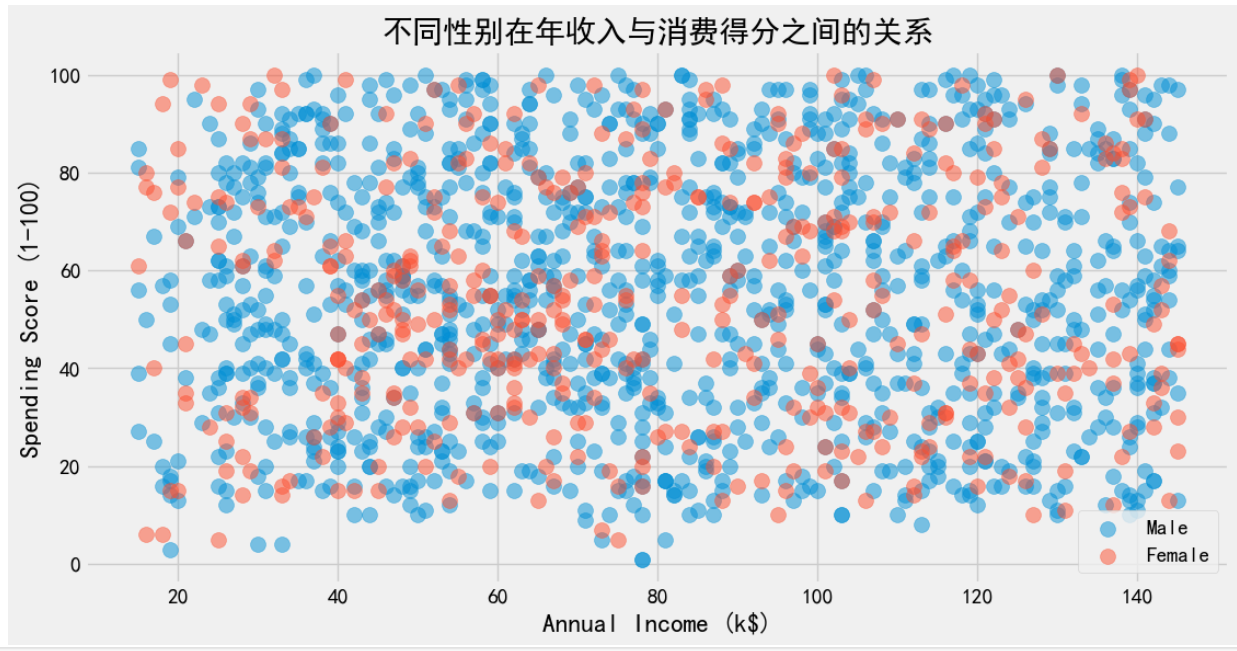
从图中可以看出,男性的消费得分普遍较高,而女性的消费得分相对较低。这可能反映了社会对男女角色和责任的不同期望和分配。
年龄与消费得分与年收入之间的分布
# 创建一个1行3列的图形,大小为12x6英寸
plt.figure(1,figsize=(12,6))
# 初始化计数器n
n=0
# 遍历三个类别(年龄、年收入和消费得分)
for cloname in ['Age','Annual Income (k$)','Spending Score (1-100)']:
# 增加计数器n的值
n+=1
# 创建第n个子图
plt.subplot(1,3,n)
# 调整子图之间的水平间距和垂直间距
plt.subplots_adjust(hspace=0.5,wspace=0.5)
# 使用箱线图展示不同性别在当前类别的数据分布情况
sns.boxenplot(x=cloname,y='Gender',data=df,palette='vlag')
# 使用散点图展示不同性别在当前类别的数据分布情况
sns.swarmplot(x=cloname,y='Gender',data=df,alpha=0.5)
# 如果当前子图是第一个子图,则不显示y轴标签
plt.ylabel('' if n==1 else '')
# 如果当前子图是第三个子图,则不显示标题
plt.title('不同性别的数据分布情况' if n==2 else '')
# 显示图形
plt.show()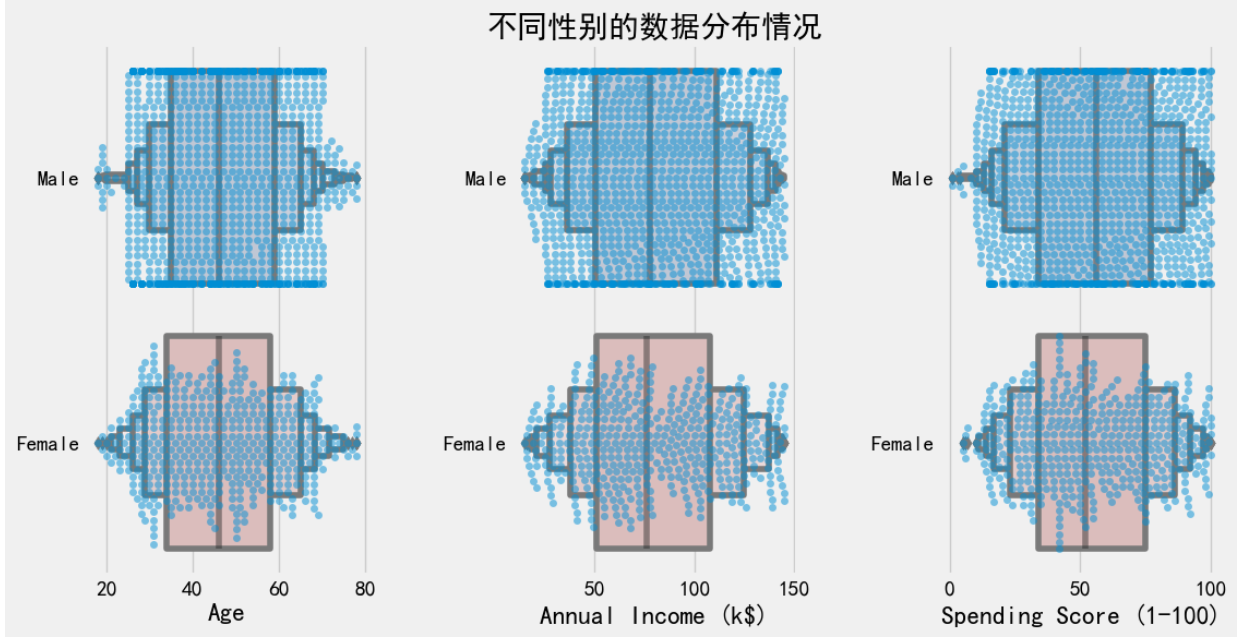
这张图展示了不同性别在年龄、年度收入和支出得分方面的变化情况。从图中可以看出,男性在这些指标上的分布较为集中,而女性则呈现出一定的分散趋势。这可能意味着男性在这些方面的表现相对稳定,而女性则存在一定的波动性。
4.使用k- means聚类进行分析
根据年龄和消费得分进行细分
# 从数据框df中提取'Age'和'Spending Score (1-100)'两列的数据,并将其转换为numpy数组x1
x1 = df[['Age', 'Spending Score (1-100)']].iloc[:, :].values
# 导入KMeans类
from sklearn.cluster import KMeans
# 初始化一个空列表inertia,用于存储每次迭代的inertia值
inertia = []
# 循环尝试不同的聚类数量(从1到10)
for i in range(1, 11):
# 创建KMeans对象,设置聚类数量、初始化方法、最大迭代次数、初始运行次数和随机种子
km = KMeans(n_clusters=i, init='k-means++', max_iter=300, n_init=10, random_state=0)
# 使用KMeans对象对数据进行拟合
km.fit(x1)
# 将当前迭代的inertia值添加到inertia列表中
inertia.append(km.inertia_)
# 创建一个大小为12x6的图形窗口
plt.figure(1, figsize=(12, 6))
# 绘制inertia值随聚类数量变化的曲线图
plt.plot(range(1, 11), inertia)
# 设置图形标题和坐标轴标签
plt.title('The Ebow Method', fontsize=20)
plt.xlabel('Number of Clusters')
plt.ylabel('inertia')
# 显示图形
plt.show()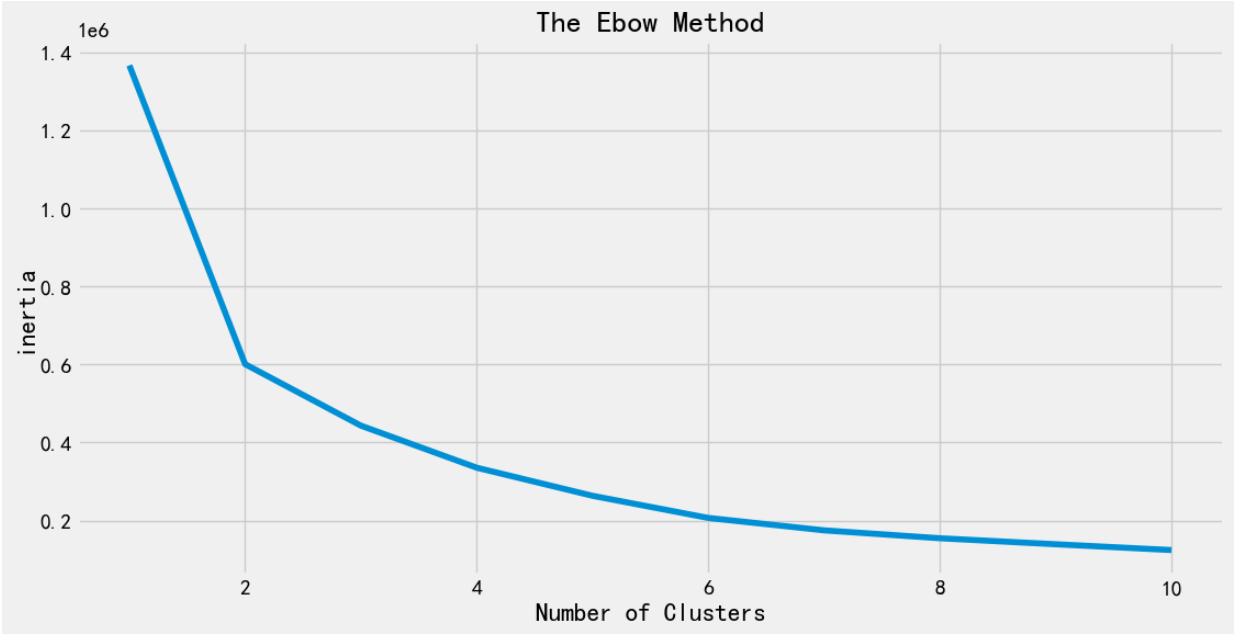
利用The Elbow Method手肘法则由图可知最佳聚类个数是1.0
# 创建KMeans对象,设置聚类数量为4,初始化方法为'k-means++',最大迭代次数为500,初始运行次数为10,随机种子为0
km = KMeans(n_clusters=4, init='k-means++', max_iter=500, n_init=10, random_state=0)
# 使用KMeans模型对数据x1进行拟合,并预测每个样本所属的簇
y_means = km.fit_predict(x1)
# 创建一个大小为16x8的图形窗口
plt.figure(1, figsize=(16, 8))
# 绘制属于簇0的样本点,颜色为蓝色,标签为'1',透明度为0.6
plt.scatter(x1[y_means == 0, 0], x1[y_means == 0, 1], s=200, c='blue', label='1', alpha=0.6)
# 绘制属于簇1的样本点,颜色为橙色,标签为'2',透明度为0.6
plt.scatter(x1[y_means == 1, 0], x1[y_means == 1, 1], s=200, c='orange', label='2', alpha=0.6)
# 绘制属于簇2的样本点,颜色为粉色,标签为'3',透明度为0.6
plt.scatter(x1[y_means == 2, 0], x1[y_means == 2, 1], s=200, c='pink', label='3', alpha=0.6)
# 绘制属于簇3的样本点,颜色为紫色,标签为'4',透明度为0.6
plt.scatter(x1[y_means == 3, 0], x1[y_means == 3, 1], s=200, c='purple', label='4', alpha=0.6)
# 绘制聚类中心点,颜色为红色,标签为'5',透明度为0.6
plt.scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:, 1], s=200, c='red', label='5', alpha=0.6)
# 设置y轴标签为'Spending Score (1-100)',x轴标签为'Age'
plt.ylabel('Spending Score (1-100)'), plt.xlabel('Age')
# 显示图例
plt.legend()
# 显示图形
plt.show()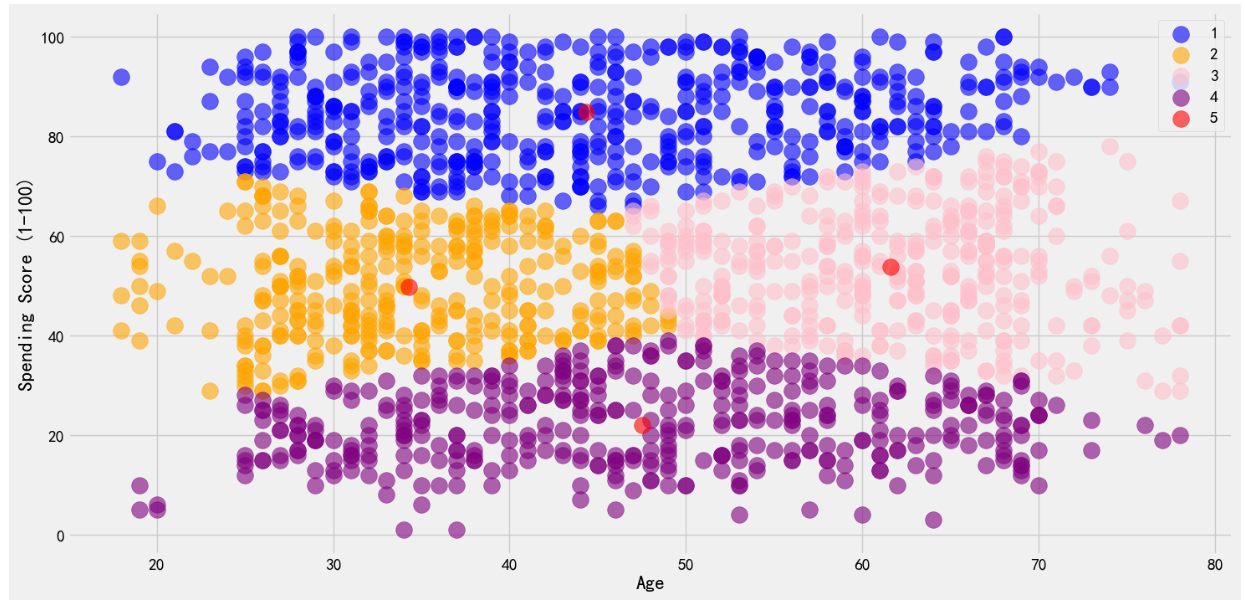
由图可知蓝色代表第一个簇,橙色代表第二个簇,粉红色代表第三个簇,紫色代表第四个簇。红色还用于表示聚类中心。可以了解不同颜色点在年龄和消费得分上的分布情况,以及它们所属的簇和聚类中心。
另两个的细分如上
使用KMeans算法对数据进行聚类,并绘制3D散点图展示聚类结果
#使用KMeans算法对数据进行聚类,并绘制3D散点图展示聚类结果
# 创建KMeans算法实例,设置聚类数量为6,初始化方法为'k-means++',运行次数为10,最大迭代次数为300,容差为0.0001,随机种子为100,使用'elkan'算法
algorithm = (KMeans(n_clusters=6, init='k-means++', n_init=10, max_iter=300, tol=0.0001, random_state=100, algorithm='elkan'))
# 使用算法对数据x3进行拟合
algorithm.fit(x3)
# 获取聚类标签
labels = algorithm.labels_
# 获取聚类中心
centroids = algorithm.cluster_centers_
# 将聚类标签添加到原始数据框df中
df['label'] = labels
# 创建3D散点图,x轴为年龄,y轴为消费得分(1-100),z轴为年收入(k$),根据聚类标签设置颜色和大小,同时设置线条颜色和宽度,透明度为0.8
trace1 = go.Scatter3d(
x=df['Age'],
y=df['Spending Score (1-100)'],
z=df['Annual Income (k$)'],
mode='markers',
marker=dict(
color=df['label'],
size=5,
line=dict(
color=df['label'],
width=5
),
opacity=0.8
)
)
# 定义绘图布局,设置高度、宽度、标题和坐标轴标题
data = [trace1]
layout = go.Layout(
height=1000,
width=1000,
title='Clusters!',
scene=dict(
xaxis=dict(title='Age'),
yaxis=dict(title='Spending Score (1-100)'),
zaxis=dict(title='Annual Income (k$)')
)
)
# 创建绘图对象,传入数据和布局
fig = go.Figure(data=data, layout=layout)
# 离线显示绘图结果
py.offline.iplot(fig)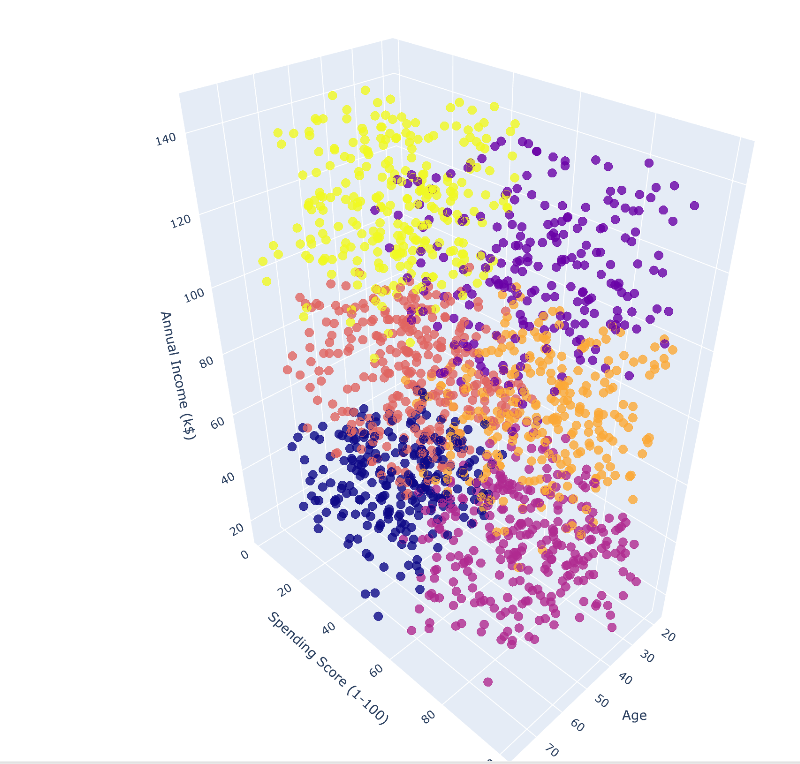
图中的每个彩色小点代表一个观察值,它们在X轴和Y轴上的位置分别表示"年龄"和"年度收入(千美元)"在Z轴的位置上表示消费得分。通过观察这些小点的密度和大小,我们可以了解到数据在这三个维度上的分布情况。
轮廓系数
# 导入轮廓系数计算函数
from sklearn.metrics import silhouette_score
# 初始化一个空列表,用于存储每个聚类数量对应的轮廓系数
score = []
# 遍历聚类数量从2到9
for i in range(2, 10):
# 使用KMeans算法对数据x1进行聚类,聚类数量为当前循环的变量i
model = KMeans(n_clusters=i).fit(x1)
# 计算聚类结果的轮廓系数,并将结果添加到score列表中
score.append(silhouette_score(x1, model.labels_, metric='euclidean'))
# 绘制轮廓系数与聚类数量的关系图
plt.plot(range(2, 10), score)
plt.xlabel('Age')
plt.ylabel('Spending Score (1-100)')
plt.show()
# 创建KMeans聚类模型,设置聚类数量为6,初始化方法为'k-means++'
kmeans = KMeans(n_clusters=6, init='k-means++')
# 使用x1数据进行聚类
kmeans.fit(x1)
# 计算x1数据的轮廓系数,使用欧氏距离作为度量标准
print(silhouette_score(x1, kmeans.labels_, metric='euclidean'))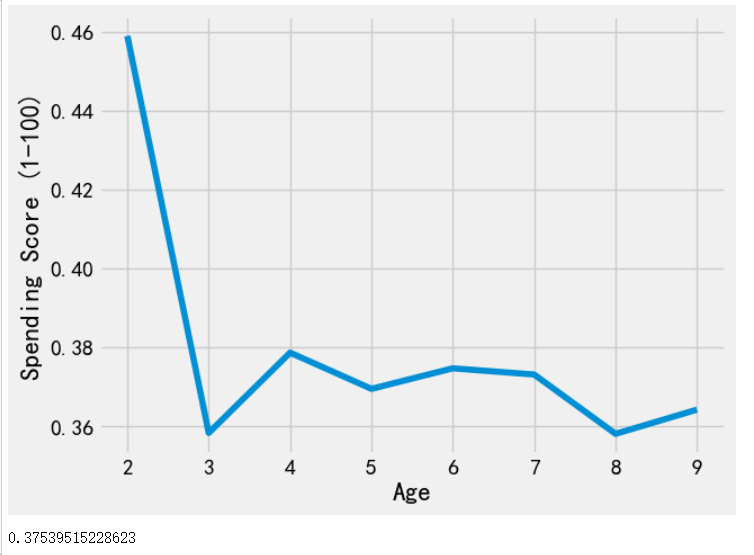
由图可知:年龄与消费得分之间的轮廓系数为0.37,接近于0,表示簇内外样本的距离相差不大,聚类效果一般。
5.完整程序源代码
1 #导入库 2 import numpy as np 3 import pandas as pd 4 import matplotlib.pyplot as plt 5 %matplotlib inline 6 import seaborn as sns 7 plt.style.use('fivethirtyeight') 8 from sklearn.cluster import KMeans 9 import plotly as py 10 import plotly.graph_objects as go 11 import warnings 12 import os 13 warnings.filterwarnings('ignore') 14 15 #读取数据集并显示前5行 16 df=pd.read_csv('C:/Users/Administrator/Desktop/客户细分 —— k-means 聚类分析/Segmentation_dataset.csv') 17 df.head() 18 19 df.shape 20 21 df.info() 22 23 df.dtypes 24 25 #查看各列缺失值数量 26 df.isnull().sum() 27 28 df.describe() 29 30 #查看数据分布 31 sns.pairplot(df) 32 33 #单独查看直方图 34 plt.figure(1,figsize=(12,6)) 35 n=0 36 for x in ['Age','Annual Income (k$)','Spending Score (1-100)']: 37 n+=1 38 plt.subplot(1,3,n) 39 plt.subplots_adjust(hspace=0.5,wspace=0.5) 40 sns.distplot(df[x],bins=20) 41 plt.show() 42 43 #样本数据中的性别比 44 #计算每个性别的数量 45 df_gender_c = df['Gender'].value_counts() 46 #定义了标签、颜色等 47 p_lables = ['Female', 'Male'] 48 p_color = ['lightcoral', 'lightskyblue'] 49 p_explode = [0, 0.03] 50 # 绘图 51 #创建一个10x10的图形窗口 52 plt.figure(1,figsize=(10,10)) 53 plt.pie(df_gender_c, labels=p_lables, colors=p_color, explode=p_explode, shadow=True, autopct='%.2f%%') 54 plt.title('Sex Ratio',fontsize=20) 55 plt.axis('off') 56 plt.legend(fontsize=14) 57 plt.legend() 58 plt.show() 59 60 # 导入matplotlib.pyplot库,用于绘制图形 61 import matplotlib.pyplot as plt 62 # 设置字体为SimHei,支持中文显示 63 plt.rcParams['font.sans-serif'] = [u'SimHei'] 64 # 设置负号正常显示 65 plt.rcParams['axes.unicode_minus'] = False 66 # 创建一个12x6英寸的图形窗口 67 plt.figure(1,figsize=(12,6)) 68 # 遍历性别列表,分别绘制男性和女性的散点图 69 for gender in ['Male','Female']: 70 # 使用scatter函数绘制散点图,x轴为年龄,y轴为年收入,数据来源为df中性别为当前性别的数据 71 plt.scatter(x='Age',y='Annual Income (k$)',data=df[df['Gender']==gender], 72 s=100,alpha=0.5,label=gender) 73 # 设置x轴标签为“Age”,y轴标签为“Annual Income (k$)” 74 plt.xlabel('Age'),plt.ylabel('Annual Income (k$)') 75 # 设置图形标题为“不同性别在年龄与年收入之间的关系” 76 plt.title('不同性别在年龄与年收入之间的关系') 77 # 显示图例 78 plt.legend() 79 # 显示图形 80 plt.show() 81 82 #不同性别在年龄与年收入之间的关系 83 import matplotlib.pyplot as plt 84 plt.rcParams['font.sans-serif'] = [u'SimHei'] 85 plt.rcParams['axes.unicode_minus'] = False 86 87 plt.figure(1,figsize=(12,6)) 88 for gender in ['Male','Female']: 89 plt.scatter(x='Age',y='Spending Score (1-100)',data=df[df['Gender']==gender], 90 s=100,alpha=0.5,label=gender) 91 plt.xlabel('Age'),plt.ylabel('Spending Score (1-100)') 92 plt.title('不同性别在年龄与消费得分之间的关系') 93 plt.legend() 94 plt.show() 95 96 #不同性别在年收入与消费得分之间的关系 97 plt.figure(1,figsize=(12,6)) 98 for gender in ['Male','Female']: 99 plt.scatter(x='Annual Income (k$)',y='Spending Score (1-100)',data=df[df['Gender']==gender], 100 s=100,alpha=0.5,label=gender) 101 plt.xlabel('Annual Income (k$)'),plt.ylabel('Spending Score (1-100)') 102 plt.title('不同性别在年收入与消费得分之间的关系') 103 plt.legend() 104 plt.show() 105 106 # 创建一个1行3列的图形,大小为12x6英寸 107 plt.figure(1,figsize=(12,6)) 108 # 初始化计数器n 109 n=0 110 # 遍历三个类别(年龄、年收入和消费得分) 111 for cloname in ['Age','Annual Income (k$)','Spending Score (1-100)']: 112 # 增加计数器n的值 113 n+=1 114 # 创建第n个子图 115 plt.subplot(1,3,n) 116 # 调整子图之间的水平间距和垂直间距 117 plt.subplots_adjust(hspace=0.5,wspace=0.5) 118 # 使用箱线图展示不同性别在当前类别的数据分布情况 119 sns.boxenplot(x=cloname,y='Gender',data=df,palette='vlag') 120 # 使用散点图展示不同性别在当前类别的数据分布情况 121 sns.swarmplot(x=cloname,y='Gender',data=df,alpha=0.5) 122 # 如果当前子图是第一个子图,则不显示y轴标签 123 plt.ylabel('' if n==1 else '') 124 # 如果当前子图是第三个子图,则不显示标题 125 plt.title('不同性别的数据分布情况' if n==2 else '') 126 # 显示图形 127 plt.show() 128 129 # 从数据框df中提取'Age'和'Spending Score (1-100)'两列的数据,并将其转换为numpy数组x1 130 x1 = df[['Age', 'Spending Score (1-100)']].iloc[:, :].values 131 # 导入KMeans类 132 from sklearn.cluster import KMeans 133 # 初始化一个空列表inertia,用于存储每次迭代的inertia值 134 inertia = [] 135 # 循环尝试不同的聚类数量(从1到10) 136 for i in range(1, 11): 137 # 创建KMeans对象,设置聚类数量、初始化方法、最大迭代次数、初始运行次数和随机种子 138 km = KMeans(n_clusters=i, init='k-means++', max_iter=300, n_init=10, random_state=0) 139 # 使用KMeans对象对数据进行拟合 140 km.fit(x1) 141 # 将当前迭代的inertia值添加到inertia列表中 142 inertia.append(km.inertia_) 143 144 # 创建一个大小为12x6的图形窗口 145 plt.figure(1, figsize=(12, 6)) 146 # 绘制inertia值随聚类数量变化的曲线图 147 plt.plot(range(1, 11), inertia) 148 # 设置图形标题和坐标轴标签 149 plt.title('The Ebow Method', fontsize=20) 150 plt.xlabel('Number of Clusters') 151 plt.ylabel('inertia') 152 # 显示图形 153 plt.show() 154 155 # 创建KMeans对象,设置聚类数量为4,初始化方法为'k-means++',最大迭代次数为500,初始运行次数为10,随机种子为0 156 km = KMeans(n_clusters=4, init='k-means++', max_iter=500, n_init=10, random_state=0) 157 # 使用KMeans模型对数据x1进行拟合,并预测每个样本所属的簇 158 y_means = km.fit_predict(x1) 159 # 创建一个大小为16x8的图形窗口 160 plt.figure(1, figsize=(16, 8)) 161 # 绘制属于簇0的样本点,颜色为蓝色,标签为'1',透明度为0.6 162 plt.scatter(x1[y_means == 0, 0], x1[y_means == 0, 1], s=200, c='blue', label='1', alpha=0.6) 163 # 绘制属于簇1的样本点,颜色为橙色,标签为'2',透明度为0.6 164 plt.scatter(x1[y_means == 1, 0], x1[y_means == 1, 1], s=200, c='orange', label='2', alpha=0.6) 165 # 绘制属于簇2的样本点,颜色为粉色,标签为'3',透明度为0.6 166 plt.scatter(x1[y_means == 2, 0], x1[y_means == 2, 1], s=200, c='pink', label='3', alpha=0.6) 167 # 绘制属于簇3的样本点,颜色为紫色,标签为'4',透明度为0.6 168 plt.scatter(x1[y_means == 3, 0], x1[y_means == 3, 1], s=200, c='purple', label='4', alpha=0.6) 169 # 绘制聚类中心点,颜色为红色,标签为'5',透明度为0.6 170 plt.scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:, 1], s=200, c='red', label='5', alpha=0.6) 171 # 设置y轴标签为'Spending Score (1-100)',x轴标签为'Age' 172 plt.ylabel('Spending Score (1-100)'), plt.xlabel('Age') 173 # 显示图例 174 plt.legend() 175 # 显示图形 176 plt.show() 177 178 x2=df[['Annual Income (k$)','Spending Score (1-100)']].iloc[:,:].values 179 from sklearn.cluster import KMeans 180 inertia=[] 181 for i in range(1,11): 182 km=KMeans(n_clusters=i,init='k-means++',max_iter=300,n_init=10,random_state=0) 183 km.fit(x2) 184 inertia.append(km.inertia_) 185 plt.figure(1,figsize=(12,6)) 186 plt.plot(range(1,11),inertia) 187 plt.title('The Ebow Method',fontsize=20) 188 plt.xlabel('Number of Clusters') 189 plt.ylabel('inertia') 190 plt.show() 191 192 km = KMeans(n_clusters = 5, init = 'k-means++', max_iter = 500,n_init = 10,random_state=0) 193 y_means = km.fit_predict(x2) 194 plt.figure(1,figsize = (16,8)) 195 plt.scatter(x2[y_means == 0,0],x2[y_means==0,1],s=200,c='blue', label='1', alpha=0.6) 196 plt.scatter(x2[y_means == 1,0],x2[y_means==1,1],s = 200,c='orange', label='2', alpha=0.6) 197 plt.scatter(x2[y_means == 2,0],x2[y_means==2,1],s = 200,c='pink', label='3', alpha=0.6) 198 plt.scatter(x2[y_means == 3,0],x2[y_means==3,1],s = 200,c='purple', label='4', alpha=0.6) 199 plt.scatter(x2[y_means == 5,0],x2[y_means==5,1],s = 200,c='green', label='5', alpha=0.6) 200 plt.scatter(km.cluster_centers_[:,0], km.cluster_centers_[:, 1], s = 200,c='red', label='6', alpha=0.6) 201 plt.ylabel('Spending Score (1-100)'), plt.xlabel('Annual Income (k$)') 202 plt.legend() 203 plt.show() 204 205 x3=df[['Age','Annual Income (k$)','Spending Score (1-100)']].iloc[:,:].values 206 from sklearn.cluster import KMeans 207 inertia=[] 208 for i in range(1,11): 209 km=KMeans(n_clusters=i,init='k-means++',max_iter=300,n_init=10,random_state=0) 210 km.fit(x3) 211 inertia.append(km.inertia_) 212 plt.figure(1,figsize=(12,6)) 213 plt.plot(range(1,11),inertia) 214 plt.title('The Elbow Method',fontsize=20) 215 plt.xlabel('Number of Clusters') 216 plt.ylabel('inertia') 217 plt.show() 218 219 #使用KMeans算法对数据进行聚类,并绘制3D散点图展示聚类结果 220 # 创建KMeans算法实例,设置聚类数量为6,初始化方法为'k-means++',运行次数为10,最大迭代次数为300,容差为0.0001,随机种子为100,使用'elkan'算法 221 algorithm = (KMeans(n_clusters=6, init='k-means++', n_init=10, max_iter=300, tol=0.0001, random_state=100, algorithm='elkan')) 222 # 使用算法对数据x3进行拟合 223 algorithm.fit(x3) 224 # 获取聚类标签 225 labels = algorithm.labels_ 226 # 获取聚类中心 227 centroids = algorithm.cluster_centers_ 228 229 # 将聚类标签添加到原始数据框df中 230 df['label'] = labels 231 # 创建3D散点图,x轴为年龄,y轴为消费得分(1-100),z轴为年收入(k$),根据聚类标签设置颜色和大小,同时设置线条颜色和宽度,透明度为0.8 232 trace1 = go.Scatter3d( 233 x=df['Age'], 234 y=df['Spending Score (1-100)'], 235 z=df['Annual Income (k$)'], 236 mode='markers', 237 marker=dict( 238 color=df['label'], 239 size=5, 240 line=dict( 241 color=df['label'], 242 width=5 243 ), 244 opacity=0.8 245 ) 246 ) 247 # 定义绘图布局,设置高度、宽度、标题和坐标轴标题 248 data = [trace1] 249 layout = go.Layout( 250 height=1000, 251 width=1000, 252 title='Clusters!', 253 scene=dict( 254 xaxis=dict(title='Age'), 255 yaxis=dict(title='Spending Score (1-100)'), 256 zaxis=dict(title='Annual Income (k$)') 257 ) 258 ) 259 # 创建绘图对象,传入数据和布局 260 fig = go.Figure(data=data, layout=layout) 261 # 离线显示绘图结果 262 py.offline.iplot(fig) 263 264 # 导入轮廓系数计算函数 265 from sklearn.metrics import silhouette_score 266 # 初始化一个空列表,用于存储每个聚类数量对应的轮廓系数 267 score = [] 268 # 遍历聚类数量从2到9 269 for i in range(2, 10): 270 # 使用KMeans算法对数据x1进行聚类,聚类数量为当前循环的变量i 271 model = KMeans(n_clusters=i).fit(x1) 272 # 计算聚类结果的轮廓系数,并将结果添加到score列表中 273 score.append(silhouette_score(x1, model.labels_, metric='euclidean')) 274 # 绘制轮廓系数与聚类数量的关系图 275 plt.plot(range(2, 10), score) 276 plt.xlabel('Age') 277 plt.ylabel('Spending Score (1-100)') 278 plt.show() 279 # 创建KMeans聚类模型,设置聚类数量为6,初始化方法为'k-means++' 280 kmeans = KMeans(n_clusters=6, init='k-means++') 281 # 使用x1数据进行聚类 282 kmeans.fit(x1) 283 # 计算x1数据的轮廓系数,使用欧氏距离作为度量标准 284 print(silhouette_score(x1, kmeans.labels_, metric='euclidean')) 285 286 # 轮廓系数 287 from sklearn.metrics import silhouette_score 288 score = [] 289 for i in range(2,10): 290 model = KMeans(n_clusters=i).fit(x2) 291 score.append(silhouette_score(x2, model.labels_, metric='euclidean')) 292 plt.plot(range(2,10),score) 293 plt.xlabel('Annual Income (k$)') 294 plt.ylabel('Spending Score (1-100)') 295 plt.show() 296 kmeans = KMeans( n_clusters = 6, init='k-means++') 297 kmeans.fit(x1) 298 print(silhouette_score(x2, kmeans.labels_, metric='euclidean')) 299 300 # 轮廓系数 301 from sklearn.metrics import silhouette_score 302 score = [] 303 for i in range(2,10): 304 model = KMeans(n_clusters=i).fit(x3) 305 score.append(silhouette_score(x3, model.labels_, metric='euclidean')) 306 plt.plot(range(2,10),score) 307 plt.xlabel('Age') 308 plt.ylabel('Annual Income (k$)') 309 plt.show() 310 kmeans = KMeans( n_clusters = 6, init='k-means++') 311 kmeans.fit(x1) 312 print(silhouette_score(x3, kmeans.labels_, metric='euclidean'))
四、总结
在Python数据分析课程设计中,我们进行了大数据分析—客户细分分析。通过这个设计,我们学习了如何使用Python进行数据分析和挖掘,掌握了常用的数据分析和挖掘算法,提高了对大数据分析的理解和应用能力。我们对客户数据进行了清洗和预处理,包括处理缺失值、异常值等,确保数据的质量和准确性。我们使用聚类分析将客户划分为不同的群体,每个群体具有相似的购买行为和偏好。
1.通过对数据分析和挖掘,我们可以得到以下有益的结论:
客户细分分析可以帮助企业更好地了解客户需求,从而提供更加精准的产品和服务。
通过聚类分析,我们可以将客户划分为不同的群体,每个群体具有相似的购买行为和偏好。
2.在完成此设计过程中,我得到了以下收获:
学会了使用Python进行数据分析和挖掘,包括数据清洗、数据转换、数据可视化等技术。
掌握了常用的数据分析和挖掘算法,如聚类分析、关联规则分析、分类预测等。
学会了使用常用的数据分析工具和库,如Pandas、NumPy、Matplotlib、Scikit-learn等。
提高了对大数据分析的理解和应用能力,能够将理论知识应用到实际问题中。