mysql数据库innoDB存储引擎来源
1、二叉查找树

从图中看出每个节点都存储着key和data,key就是表中的id,data代表中一行数据。
二叉查找树的特点就是任意节点的左子节点的key都小于当前节点的key,右子节点的key值都大于当前节点的key
应用场景:
- 查询id为17的key值,首先找到根节点,用id值和当前根节点作比较,大于当前节点取右子节点作为当前节点。
- 继续拿id为17的key值与当前节点13作比较,大于取右节点key为17作为当前节点。
- 拿id为17与当前节点17作比较,相等就取出来。
- 总共匹配了三次,如果不使用二叉查找就得查询七次。
2、平衡二叉树
在极端情况下二叉查找树会退化成单向链表。
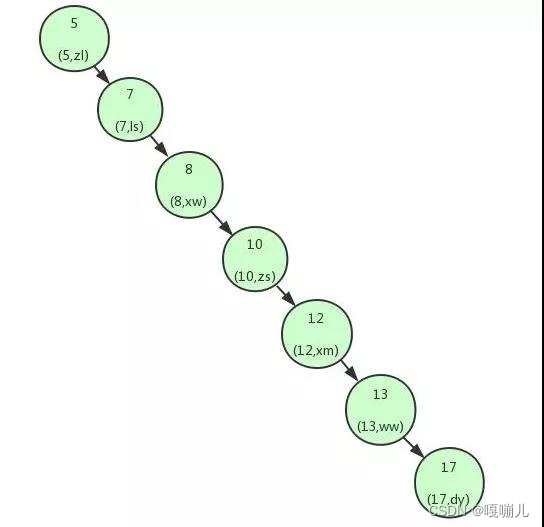
如果数据比较极端会生成上述的二叉查找树,如果查询id为17的数据也需要匹配七次,只要二叉查找树的高度过高并且不平衡效率就会极低。
为了解决此问题就引出了平衡二叉树。
平衡二叉树的特点就是满足二叉查找树的基础上,添加一个新的要求,每个节点的左右子节点的高度差距不能超过1.
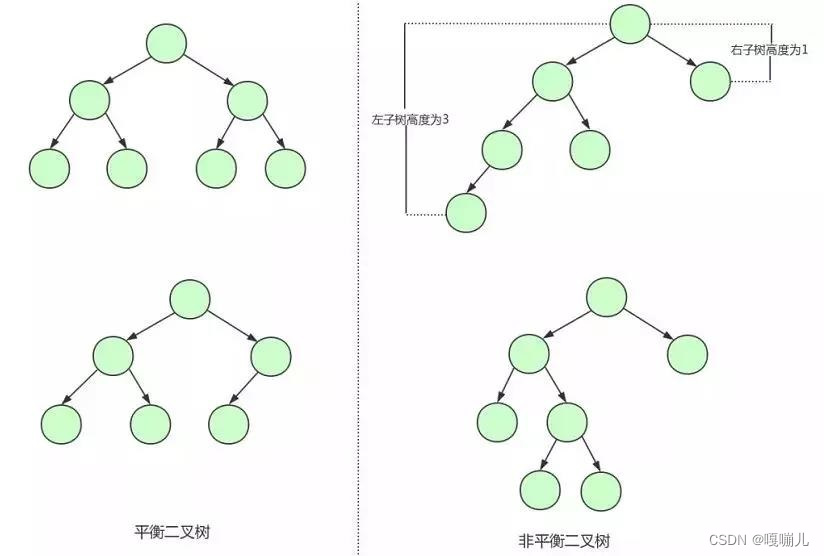
PS:如果对数据进行新增、修改、删除导致平衡二叉树不平衡时,那么平衡二叉树就根据节点的数据进行保持平衡。
PS:平衡二叉树相对于二叉查找树会更加稳定。
3、B树
数据库保证数据不丢失,将数据存储在磁盘中,相对于存储在内存中,查询速度差距几百倍或上万倍,而性能差距较大的主要原因就是频繁的IO操作。而当数据量较大的时候平衡二叉树就是出现n层的情况(平衡二叉树和二叉查找树的共同特点就是每个节点既存key也存data)。

通过上图可知数据量比较大的情况下平衡二叉树也会出现性能问题,因为单个节点只存单个key和单个data,为了解决此问题就从单节点入手。
创建一种可存储多个key和data的节点,这就是B树。

PS:存储单元称之为页(页其实就是每个磁盘的磁盘块)
通过上述图可知B树的特点就是单个节点可存储多个key和data,从而减少了树的高度,减少了磁盘IO读取操作次数,效率就上去了。
应用场景:查询id为29的数据
- 首先查询到页1,判断id为29在17和35中间,所以定位到页1中的p2指向页3。
- 判断id为29在页2中26和30中间,所以定位到页3中的p2指向页8。
- 在页8中在做比较,直接匹配到了id为29的数据。
4、B+树
B+就是B树的升级版,首先看下B+树的数据结构
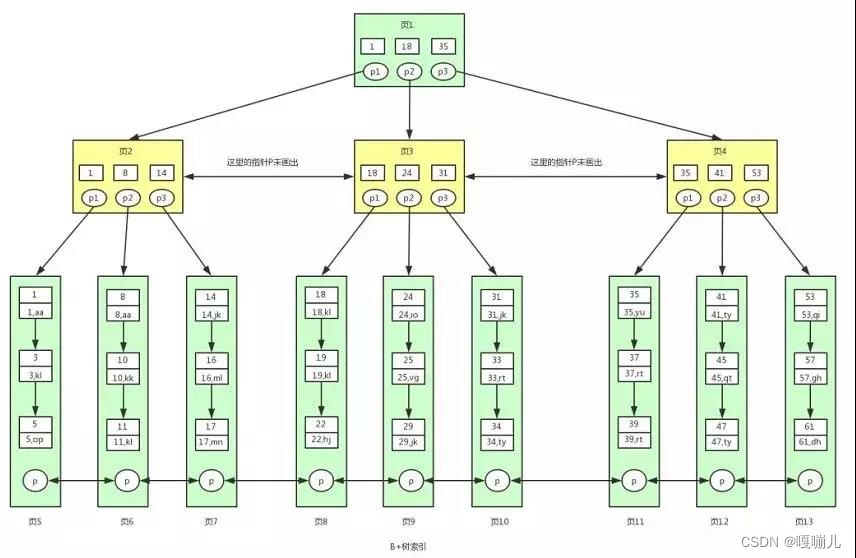
B树和B+树的区别:
B+树除了叶子节点外,其它节点都存储多个key,只有叶子节点存储data,而B树则每个节点都存储key和data。
为什么要这样改变?
- 在innoDB存储引擎中,数据库的页大小是固定的,默认为16k。如果节点不存储data存储更多的key,那么就可以尽可能减少树的高度,查询从而减少读取磁盘IO次数。
- B+树子节点中存储的数据都是有序排列的,如果使用B+树完成范围查询、排序查询、分组查询、去重查询就会很简单,效率特别高。而B树就不可以,数据都是分散在各个节点上。
- B+树的每页之间是一个双向链表进行链接,叶子节点中的数据采用单向链表进行链接。但是需要记得一旦是B树可以加链表。
PS:InnoDB的存储结构就是B+树,聚集索引就是上面的结构。myisam依然用的B+树,结构一样,唯一不同的就是叶子节点中存储的不是data而是data的文件地址。
5、聚集索引和非聚集索引
- 聚集索引(聚簇索引):如果数据库使用innoDB存储引擎,那么表中的数据必须有一个主键,如果用户不创建,系统也会帮你创建一个隐式的主键。
- 之所以一定要有主键是因为B+树的key就是主键。如果
以主键生成的B+树索引就成为聚集索引。 以主键以外的列作为key构建B+树索引称为非聚集索引
使用聚集索引查询
select * from user where id>=18 and id<40
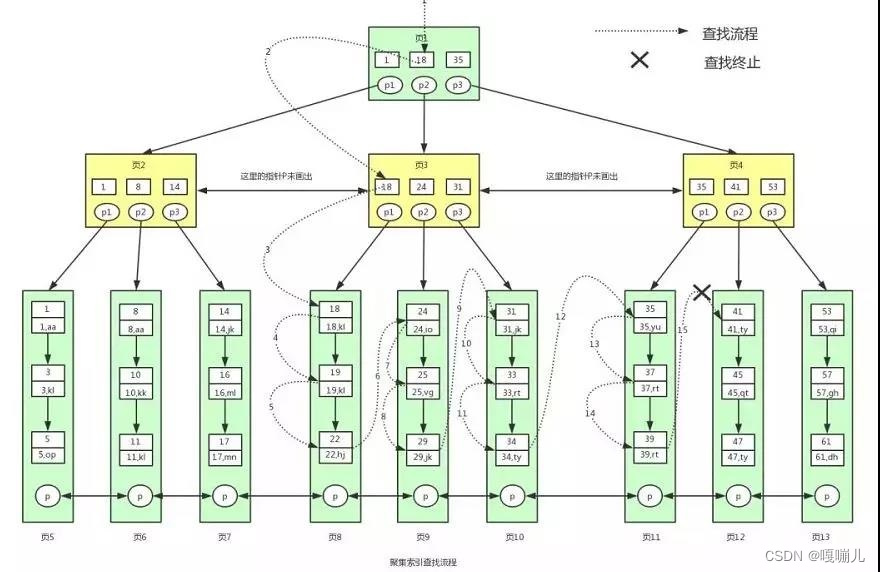
核心思想:根节点常驻内存所以不需要进行磁盘IO操作
根据各个节点找到对应的p,根据p的指针找到对应的下一页。最终达到叶子节点,通过二分查找法定位数据位置,通过单向链表或者当前页的数据,再通过双向链表获取到下一页数据,最终获取到所有数据。
使用非聚集索引查找

如果使用可非聚集索引,那么叶子节点存储的内容将会发生变化,聚集索引存储的是data,而非聚集索引存储的是当前数据对应的主键。
具体流程如下:

核心思想:定位查询到子节点中数据位置根据二分查找法查询到具体的data,此时data存储的是主键,拿到对应索引主键,再根据主键进行回表查询。(mylsam的叶子节点存储的是文件地址不是主键)
6、什么是回表?
表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
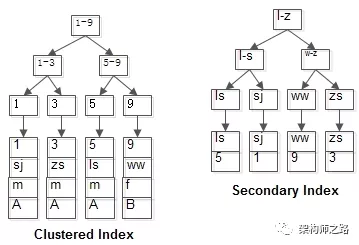
两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
普通索引(非聚集索引)无法直接定位到行记录,那么普通索引的查询过程是什么样子的?
例:select * from t where name='lisi';

如粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
7、如何避免回表?
- 索引覆盖首先是一种避免回表的一种方案,常用的是创建联合索引实现
第一条sql:
select id,name from t where name='lisi';

能够命中name索引,索引叶子节点存储了主键id,通过name索引就可以匹配到数据,无需回表操作符合覆盖索引。
第二条sql:
`select id,name,sex from t where name='lisi';
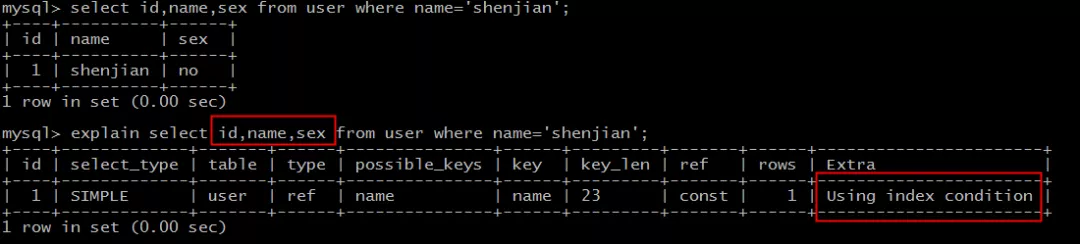
能命中name索引,索引叶子节点只存储了主键id,但是sex字段必须通过回表才能获取,不符合覆盖索引,效率低。
那如果把name单列索引升级成name和sex的联合索引。

执行计划不会选择覆盖查询几项注意事项:
- 尽量不要用
select *,不要用select索引中没有的字段 - where中不能包含对索引进行like的操作
总结
只要从辅助索引中直接能获取到数据,那么普通索引、联合索引都能实现索引覆盖的作用。