前言
没想到干完lca的时间比tarjan的还要长(我不能这么弱下去了!!)
前置知识
-
dfs序
这东西有点类似于时间戳(dfn),但是它分为两部分(回溯之前和回溯之后)。并且dfs序还分为两种。这里只介绍一倍的dfs序。
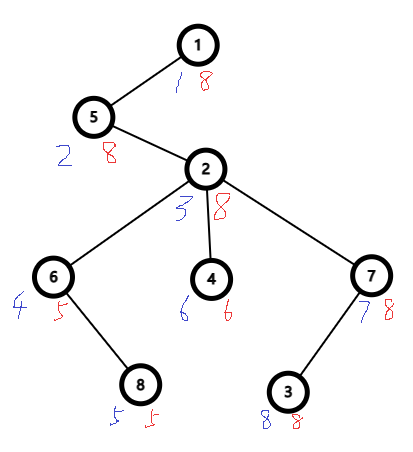
如上图,蓝色代表左端点,红色代表右端点,(学过Tarjan的都知道),蓝色其实就是这棵树的dfn(时间戳,即遍历节点的顺序),很显然是在递归之前标记好的,相应地,红色就是在回溯时标记好的。这样标记的意义显而易见,每一个节点都可以表示为一个闭区间,配合树状数组或线段树可在树上实现链上操作,比如说更新某个节点或节点及以下的子树的权值,以及查询某颗子树的权值和。详见例题1和例题2。代码如下:
点击查看代码
void dfs(int x, int fa) { in[x] = ++cnt; // in[x] 表示节点 x 的左端点 for (int i = 0; i < ver[x].size(); ++i) { int y = ver[x][i]; if (y == fa || in[y]) continue; dfs(y, x); } out[x] = cnt; // out[x] 表示节点 x 的右端点 }二倍的dfs序较为简单,在这里只给出图片和代码,大家自行理解,不再做详细介绍。
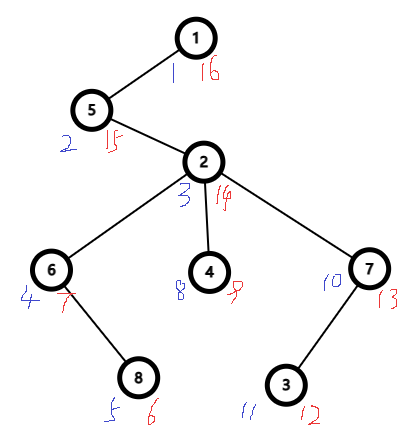
代码如下:
点击查看代码
void dfs(int x, int fa) { in[x] = ++cnt; // in[x] 表示节点 x 的左端点 for (int i = 0; i < ver[x].size(); ++i) { int y = ver[x][i]; if (y == fa || in[y]) continue; dfs(y, x); } out[x] = ++cnt; // out[x] 表示节点 x 的右端点 } -
倍增
字面意思就是成倍增长。这里我们只介绍倍增思想的衍生算法ST表求解RMQ(区间最值问题),倍增LCA将会在下面的板块单独介绍。
倍增一般是以 \(2^n, n \in \mathbb Z\) 为基准而成倍增长。据此思想设 \(f[\ i\ ][\ j\ ]\) 表示从下标为 \(i\) 的位置到下标为 \(i + 2^j - 1\) 的位置的最值,显然这段区间长是 \(2^j\) ,亦可得边界 \(f[\ i\ ][\ 0\ ] = a[\ i\ ]\) ,其中 \(a[\ ]\) 为原序列。既然边界下标是小的,我们就可以用小的推大的,怎么推,用倍增。递推式为 \(f[\ i\ ][\ j\ ] = max(f[\ i\ ][\ j - 1\ ],\ f[\ i + 2^{j - 1}\ ][\ j - 1\ ])\) ,还原一下就是区间 \([\ i,\ i + 2^j - 1\ ]\) 的最值由 \([\ i,\ i + 2^{j - 1} - 1\ ]\) 和 \([\ i + 2^{j - 1},\ i + 2^{j} - 1\ ]\) 这两个长度为 \(2^{j-1}\) 区间取得最值。
若查询区间 \([\ l, \ r\ ]\) 的最值,其区间长 \(len = r - l + 1\) ,令 \((int)t = \log_2len\),我们可以从区间 \([\ l,\ l + 2 ^ t - 1\ ]\) 和 \([\ r - 2 ^ t + 1\ ,\ r\ ]\) 取得最值,可证得这两段区间能覆盖整个要查询的区间以及不超过边界。
PS:这东西本质上就是倍增优化DP。
LCA的朴素算法
最最最最最最朴素的算法就是从下向上标记。显然,最最最最最最坏的情况就是一条链,两个查询的节点一个是根节点,一个是叶节点。设一共有 \(n\) 个节点,则每次查询时间复杂度是 \(O(n)\) ,多次查询的话必定超时无疑。
LCA的倍增算法(在线)
其实就是倍增对朴素算法的小优化。朴素算法每次只往上跳一个,而倍增优化每次往上跳 \(2^i\) 个。我们先要用dfs预处理出来每个节点的 \(2^i\) 倍祖先是谁,考虑最坏的情况(树退化成链),\(i_{max} = \log_2n\) ,显然每次查询的最坏时间复杂度是 \(O(\log_2n)\) ,设共有 \(m\) 组查询,那么总的时间复杂度为 \(O((n + m)\log_2n)\) ,可以接受。
LCA的Tarjan算法(离线)
这是用并查集对朴素算法的小优化。在树上跑一遍dfs,将正在访问的节点标记为 \(1\) ,已经访问完的标记为 \(2\) ,还没访问的标记为 \(0\) 。在跑dfs同时遍历与当前节点(一定被标记为 \(1\) )有关的查询,如果要查询的另一个节点被标记为 \(2\) ,那么就用并查集找到其祖先,这个找到的祖先就是二者的LCA。因为这棵树上的所有被标记为 \(1\) 的节点和它们之间的一条边构成一条链,并且正在访问的被标记为 \(1\) 的节点一定在链的最末端(最顶端一定是根节点),通过并查集找到的 \(1\) 一定是正在访问的本身或其它 \(1\) 节点。找到答案以后就把它存起来就好,跑完dfs以后将答案统一输出。