现在ChatGPT非常的火,大家都使用大数据模型来生成内容,后续机器人,仿真机器人的行为控制,也将会是AI领域很火的一个方向之一,这个方向就可以和游戏高度契合,游戏通过3D角色来仿真,通过训练AI行为来控制机器人的一些动作与决策,今天我们以”足球游戏”为背景,来详细的讲解,如何基于 “左右互博”强化训练,让两对机器仿真的足球队员来进行智能的经行一场AI比赛。先来看下训练后的效果,如图:
先介绍一下训练环境, ML插件是针对Unity为AI 深度学习专门做的一个插件。它基于TensorFlow深度学习框架, 并针对游戏开发相关的AI训练与工具做了一层封装,引入了很多算法,能帮助我们轻松的训练出游戏AI与相关的工具。
本案例为本文根据双人足球基础之上尝试改进的五人足球。本案例使用了Unity的ML-Agents组件开发而成,这里使用了多智能体强化学习的算法MA-POCA,双方队伍相互学习相互博弈,促进共同进步,可以不断自我进化,从而成长为更加聪明的AI。在本案例中每一队分为前锋Striker、后卫Guard、守门员Goalie三个职业。其中前锋两人、后卫两人,守门员一人,比起原来的双人足球,需要训练的模型多出来两个,并且人数上多出来三个,训练难度大大提高。
模型数据输入:
对于模型的输出,这里采取离散的输出形式, 模型的输入维度过高,会导致模型的复杂度增加, 大大降低训练速度。我们在自己的电脑上训练,由于硬件的限制我们不能有太多的模型数据输入维度,我们用自己的电脑来训练尽量用一些关键的一些核心维度,来达到我们的训练目标。我们这里采取的一些关键维度的核心数据主要包括了:射线传感器等。
使用射线传感器的好处是既没有像网格一样有太高维度的输入,行为模式也比单纯的数据输入容易学习。缺点是射线会被阻挡而且在远端较为稀疏,因此往往探测不到较为全面的信息。
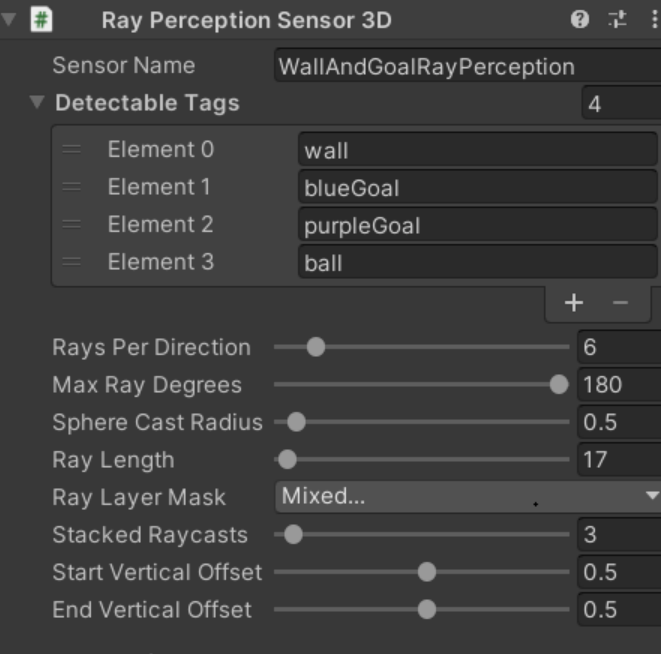
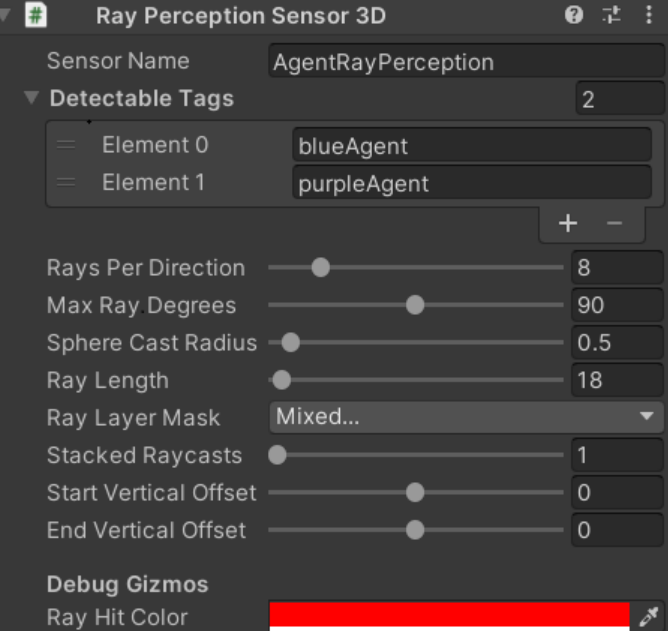
其中阻挡问题可以使用多个射线组件来进行弥补,每个组件探测其中的一层,实际上本案例就是这么处理的,其中第一个传感器探测墙壁球门以及球的位置,第二个传感器则探测敌我双方的智能体。

我这里开了两个环境进行了两天的训练,训练接近一千万个step,其中三个模型的ELO均能到达1400分以上。Guard和Striker的训练结果比较令人满意,Goalie差强人意,主要问题是探测球的传感器射线数目太少,因此本人建议对于守门员应当把球的标签放到拥有更加茂密射线的第二个传感器中。
奖励函数的设置
奖励设置也非常有讲究,好的奖励函数设置可以大大加快训练过程:
首先对于前锋Striker,我们应当鼓励其进行进攻,因此每当球更加接近敌方球门,应当给予其奖励,当相反球接近我方球门时,应当给予惩罚。
对于守门员这种非常有别于其他智能体的行动模式,应当设立更加特别的奖励函数。我们不鼓励守门员离球门过远,因此当智能体离球门超过一定距离时,给予惩罚,离得越远惩罚越高。并且我们鼓励守门员能很好防守接近球门的每一球,因此当球远离球门时应当给予加分,相反靠近球门给予减分。
《《《《《插入代码》》》》
对于集体奖励,在原有的进球得分的基础上,我们加上球往敌方球门方向移动得分,往己方球门移动减分的奖励函数,来使奖励变得更加稠密。添加此函数并在FixedUpdate中调用(前面需要获取球的刚体和双方球门的Transform):
《《《《插入代码》》》》
训练参数设置:
同样的,训练使用了MA-POCA算法,并且在这种对称性博弈的环境中我们使用了self-play,并且我们应当使用课程学习来使训练更加平滑,在训练前期我们可以设置更大的碰球奖励来时智能体积极与球进行互动,在后期减少其奖励来使策略变得更加多元化。
我们需要配置前锋,后卫,守门员三种智能体的训练参数,以及过程各个阶段的参数。
《《插入代码》》
调整完参数以后开始训练,训练两天以后,两个团队的对战效果就已经很不错了。