主要提出了一种数据集Instruction-based IE,要求模型根据指令来提取信息。
1. Instruction
为IE任务创建特定的数据集式消耗事时间与资源的。
面对这些挑战的常见方法:
Seq2seq提出
TANL将其视为自然语言增强的翻译任务。
UIE提出一种text-to-structure的生成框架来面对多重的IE任务。
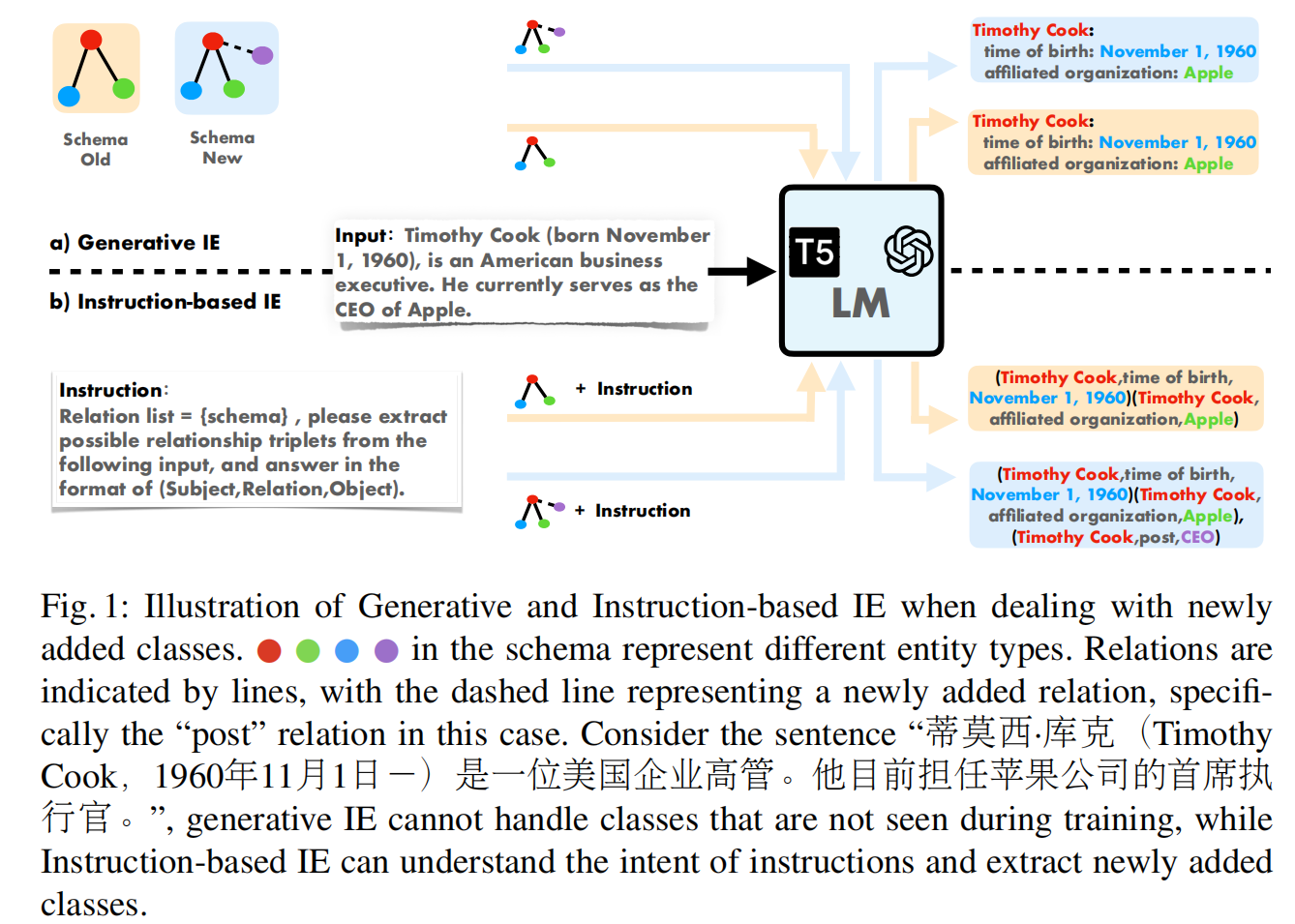
存在的缺陷:
训练过程中模式固定,难以应用到测试过程。
once-and-for-all训练
而Instruction-based IE可以实现指令的变化导致结果的变化,更加先进。
本数据集包含270000弱监督数据(来源于中文Wikipedia),
1000个经过高质量注释的数据。
2 Task Definition:Instruction-based IE

将IE视为指令驱动的文本生成任务。
指令名为\(I\),自然语言形式的处理要求
提取要求\(S\),需要提取的实体/类型的类别
格式要求\(T\),一般要求JSON字符串形式或者元组形式
整体格式如下:
\(Y=M(I,X)\)

3 Dataset Construction for InstructIE
3.1 Data Source
主要包含两大部分:Wikidata和Chinese Wikipedia
Chinese Wikipedia:提取维基百科的文档,划分为若干段落(50-300字符),
最终得到1.8million段落
Wikidata:知识图谱,采用Wikidata的一个子集
3.2 Data Preparation
- Instruction-based Information Instruction InstructIE Extractioninstruction-based information instruction instructie instruction-based instructie extraction relation document-level relation-aware extraction multi-instance entity-level end-to-end extraction extraction end-to-end generation language applications approaches extraction learning document-level table-to-graph generation extraction pre-training transformer span-based extraction