一、选题的背景
通过新书榜和推荐榜来分析小说分类和人气之间的关系,让作者能加了解读者的需求,写出令读者感兴趣的题材来吸引读者。热门的小说分类是社会文化普遍认可的体现,了解和分析社会文化对于提升和改善社会文化起着重要作用。了解热门小说分类让新人作者选择题材时有份参考,以至于写出的小说分类偏门而鲜有人关注,减少新人作者的时间和精力成本。
二、主题式网络爬虫设计方案
实现思路:本次设计方案主要使用requests库爬取网页信息和响应数据并保存为文件,然后使用pandas库对文件进行分析和数据可视化。
技术难点:
- 爬取过程中部分页面的信息被隐藏
- 对爬取的信息进行数据可视化
三、主题页面的结构特征分析
- 主题页面的结构与特征分析

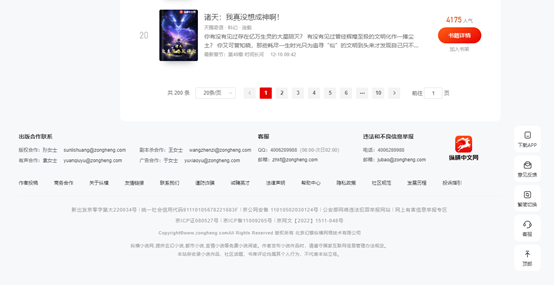
(1) 导航栏位于界面顶部
(2) 作品榜单导航栏在页面左侧
(3) 中间是内容区,显示不同作品榜单导航栏下的内容
(4) 内容区的底部是分页部分
(5) 页面底部是网站信息和网站服务
2. Htmls 页面解析

<header class="h_space"> 顶部导航栏
<section class=”rank-nav”> 侧边导航栏,其内容是作品榜单
<section class=”rank-content”> 内容区
<div class=”rank-content—pagination”> 分页部分
<div class=”footer”> 页面底部
3. 节点(标签)查找方法与遍历方法
(1) 查找方法:find
(2) 遍历方法for
四、网络爬虫程序设计
Part1: 爬取新书榜和推荐榜的网页数据并分别保存为result_new.csv和result_hot.csv文件

import csv
import json
import requests
def get_url(url):
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Referer': 'https://www.zongheng.com/rank?nav=new-book-subscribe&rankType=9'
}
cateFineId = 0
cateType = 0
pageNum = 1
pageSize = 20
rankNo = ''
period = 0
rankType = 4
# csv文件
result_csv = 'result.csv'
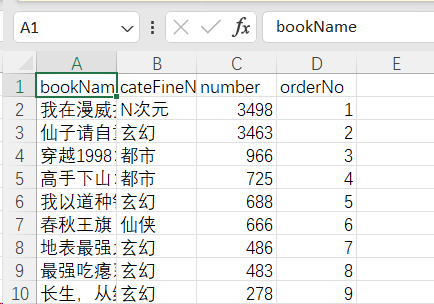
# 0 bookName 书名 || 1 cateFineName 分类 || 2 number 数量 || orderNo 3 排行
# data_list = ["书名", "分类", "人气", "排行"]
data_list = ["bookName", "cateFineName", "number", "orderNo"]
with open(result_csv, 'a+', encoding='gbk', newline='') as ff:
writer = csv.writer(ff)
writer.writerow(data_list)
# 爬取十个页面
for item in range(1,11):
pageNum = item
data = {
"cateFineId": cateFineId,
"cateType": cateType,
"pageNum": pageNum,
"pageSize": pageSize,
"period": period,
"rankNo": rankNo,
"rankType": rankType
}
# 请求
res = requests.post(url, headers=headers, data=data)
with open("res.txt", "w", encoding="utf-8") as file:
file.write(res.text)
f = open('res.txt', encoding='utf-8')
txt = []
for line in f:
txt.append(line.strip())
# 数组转字符串
str_data = ''.join(txt)
# 字符串转json
data = json.loads(str_data)
if "result" in data:
# 取result里面的数据
res_data = data["result"]
# print(res_data)
# 遍历取resultList里面的数据
for res in res_data["resultList"]:
res_list = []
# print(res)
# print(res["bookName"])
res_list.append(res["bookName"])
res_list.append(res["cateFineName"])
res_list.append(res["number"])
res_list.append(res["orderNo"])
# (名字,模式(a+)是追加的意思,编码,分隔符
# with open(result_csv, 'a+', encoding='utf-8', newline='')as f:
with open(result_csv, 'a+', encoding='gbk', newline='') as f:
writer = csv.writer(f)
writer.writerow(res_list)
return res;
def main():
url = input("请输入链接地址:")
res = get_url(url)
if __name__ == "__main__":
main()
# https://www.zongheng.com/api/rank/details 需要输入的链接地址Part2: 取出result_hot.csv文件的数据并生成推荐榜热点词的词云图

import pandas as pd
import jieba
import wordcloud
# 读取文本
df = pd.read_csv('result_hot.csv', encoding='gbk')
list = []
# 循环取出书名
for item in df.values:
if item[0] == 'bookName':
continue
list.append(item[0])
str_data = ''.join(list)
# 字符串转json
data = list
print(data)
str_list = ''.join(list)
ls = jieba.lcut(str_list) # 生成分词列表
text = ' '.join(ls) # 连接成字符串
stopwords = ["的","是","了"] # 去掉不需要显示的词
wc = wordcloud.WordCloud(font_path="STHUPO.TTF",
width = 1000,
height = 700,
background_color='white',
max_words=50,stopwords=str_list)
# STHUPO.TTF电脑本地字体,写可以写成绝对路径
wc.generate(text) # 加载词云文本
wc.to_file("wordcloud.png") # 保存词云文件Part3: 根据result_new.csv文件生成同分类下平均每本书人气的直方图
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
import numpy as np
df = pd.read_csv('result_new.csv', encoding='gbk')
# 删除重复值(数据清洗)
df = df.drop_duplicates()
cate_list = []
for item in df['cateFineName'].value_counts().index:
cate_list.append(item)
# temp = 'N次元' 是第一次比较的值
temp = 'N次元'
cate_num = 0
num_sum = 0
order_sum = 0
all_list = []
# 平均人气
for item in df.groupby('cateFineName').value_counts().index:
if(temp != item[0]):
all_list.append(temp)
#总人气 / 同分类书的数量 = 同分类下平均每本书的人气 ->直方图
all_list.append(int(order_sum/cate_num)) #保留两位小数
temp = item[0]
order_sum = 0
cate_num = 0
temp = item[0]
num_sum = int(item[2]) + num_sum
order_sum = int(item[3]) + order_sum
cate_num = cate_num + 1
arr = np.array(all_list)
# 一位数组转二位数组
arr_re = arr.reshape(9, 2)
# 转df
df = pd.DataFrame(arr_re)
# 解决乱码
sns.set_style('whitegrid',{'font.sans-serif':['simhei','Arial']})
list = []
for item in df[1].values:
list.append(int(item))
print(list)
sns.barplot(x=df[0].values, y=list)
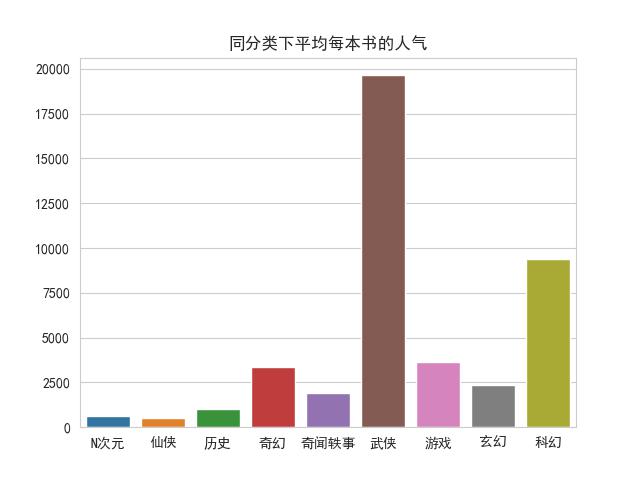
plt.title('同分类下平均每本书的人气')
# 保存图片
plt.savefig('barplot.jpg')
plt.show()Part4: 根据result_new.csv文件生成不同分类下书的数量占全部新书数量的比例
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv('result_new.csv', encoding='gbk')
# 删除重复值(数据清洗)
df = df.drop_duplicates()
cate_list = []
for item in df['cateFineName'].value_counts().index:
cate_list.append(item)
labels = 'Frogs', 'Hogs', 'Dogs', 'Logs' # 定义标签
colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral'] # 每一块的颜色
plt.pie(df['cateFineName'].value_counts().values, labels=cate_list, autopct='%1.1f%%', startangle=90)
plt.axis('equal') # 显示为圆(避免比例压缩为椭圆)
plt.rcParams['font.sans-serif']=['SimHei']
# 保存饼图
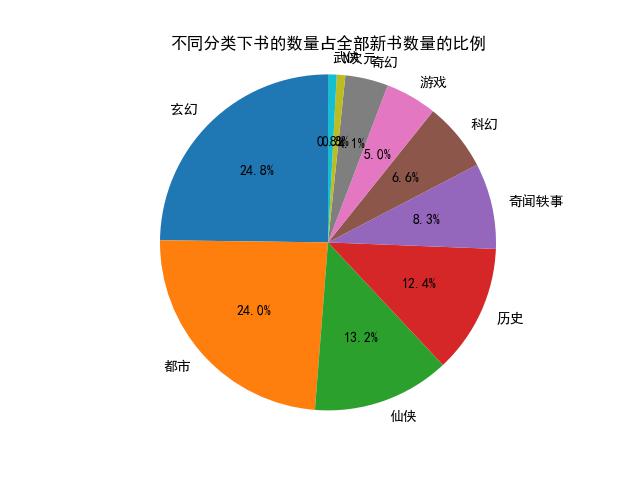
plt.title('不同分类下书的数量占全部新书数量的比例')
plt.savefig('pie.jpg')
plt.show()Part5: 根据result_hot.csv文件画出在不同排名下各种分类书的散点图,并画出回归曲线
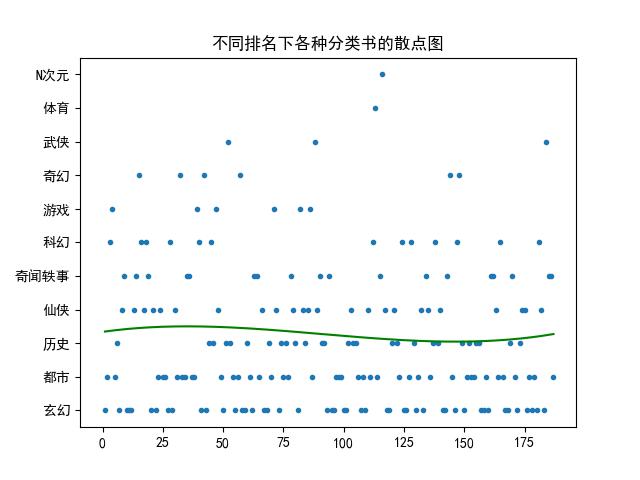
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#标题
plt.title('不同排名下各种分类书的散点图')
#中文乱码
plt.rcParams['font.sans-serif']=['SimHei']
df = pd.read_csv('result_hot.csv', encoding='gbk')
# print(df.groupby('cateFineName').value_counts().index)
print(df['cateFineName'].value_counts().index)
cate = []
cate_num = 0
# 循环排序分类并给每个分类设一个id
for item in df['cateFineName'].value_counts().index:
cate.append(item)
cate_num = cate_num + 1
cate.append(cate_num)
cate_arr = np.array(cate)
x_list = []
y_list = []
i_sum= 0
for item in df.values:
for i in df['cateFineName'].value_counts().index:
if i == item[1]:
x_list.append(i_sum)
y_list.append(int(item[3]))
i_sum=0
break
else:
i_sum = i_sum + 1
x = np.array(y_list)
y = np.array(x_list)
z1 = np.polyfit(x, y,3) # 用3次多项式拟合,输出系数从高到0
p1 = np.poly1d(z1) # 使用次数合成多项式
y_pre = p1(x)
plt.plot(x, y, '.')
plt.plot(x, y_pre, c="green")
z = np.array([x_list, y_list])
plt.scatter(x=[0, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160],y=['玄幻', '都市', '历史', '仙侠', '奇闻轶事', '科幻', '游戏', '奇幻', '武侠', '体育', 'N次元'],data=z, c="green", s=0, alpha=0.9)
plt.savefig('scatter.jpg')
plt.show()五、总结
1.根据词云图的显示,可以了解人们对修仙、养后宫、重生、开挂等相关内容感兴趣。
2.根据直方图可以了解人们对武侠、科幻、奇幻、游戏等小说分类比较感兴趣。
3.根据饼图了解到新书中科幻、仙侠、历史、玄幻占大多数,也是大多数人比较喜欢的小说类型。
4.根据散点图可知,在推荐榜单中玄幻、都市、历史、仙侠这些类型的小说分布在推荐榜中的大部分位置。
综上,我认为对于新人作者可以从玄幻、都市、历史、仙侠类型出发写小说,先建立一部分人气,给自己一点正向反馈,才能更好更积极地继续创作。对于我自己,我在这次课程设计中学到了很多,通过课程设计我遇到了很多问题并一个个解决,做到了知其理并行其事。