很久以前就想研究一下到底是怎么因素影响银行个人存款,特别是大众客户(个人日均存款1万-10万元客户)的存款变化到底同说明有关系?
初步的设想是利用大学数学数据统计的基本方法,列出可能的影响因素,通过公开的数字进行分析评价,但受限于数据来源、数据规模、影响因数如服务质量、地域等的量化困难,一直没有认真的去分析过。
去年有了一次机会,某人工智能-机器学习竞赛的题目就是根据大宗客户三个月的金融性行为预测其存款是否会增长,就自学开展了相关的编程语言(python)和数学建模知识,并进行了预测,由于是第一次学习和参加比赛,成绩并不好,但感觉有一定的意义,决定写下我的参赛经历,供有相同想法的朋友参考。
由于消费者权益保护和数据保密的需要,这里并不公布具体的数据内容,仅公布数据结构和我的建模过程及验证情况。
试题说明
目前我行拥有海量大众客户(月日均金融资产为1元-10万元),其挖掘潜力巨大,但“无力管”的经营痛点依然存在,亟需运用大数据建模手段,精准识别一批最具有潜力的客户,集中力量和资源开展数字化经营,促进大众客户存款和资产提升。
一、训练数据部分
1、自然属性信息表(DZ_NATURE)
2、资产表(DZ_ASSET)
3、现金交易表(DZ_TR_CASH)
4、自助设备交易表(DZ_TR_ATM)
5、柜台交易表(DZ_TR_TERM)
6、理财交易表(DZ_TR_FNCG)
7、跨行转账表(DZ_TR_IBTF)
8、第三方支付交易表(DZ_TR_TPAY)
9、掌银行为表(DZ_MBNK_BEHAVIOR)
10、活期交易表(DZ_TR_APS)
11、目标客户列表(DZ_TARGET_TRAIN)
二、预测数据部分
预测目标是客户在未来两个月的平均月日均AUM提升一定金额,1代表提升,0代表不提升。
预测结果上传文件名:upload.csv
文件格式:utf-8
分隔符:半角逗号
内容格式:客户号,预测结果
示例:(第一行无列名)
1641456132123456,0
16145456387696314,1
三、评价指标
本题使用F1作为评价指标,具体公式如下:
F1=2*precision*recall/(precision+recall)
precision=TP/(TP+FP)
recall=TP/(TP+FN)
四、表结构介绍
自然属性信息表(DZ_NATURE)
|
英文字段名 |
中文字段名 |
|
DATA_DAT |
数据日期 |
|
CUST_NO |
客户编号 |
|
NTRL_CUST_SEX_CD |
客户性别代码 |
|
NTRL_CUST_AGE |
客户年龄 |
|
NTRL_RANK_CD |
客户等级代码 |
资产表(DZ_ASSET)
|
英文字段名 |
中文字段名 |
|
DATA_DAT |
数据日期 |
|
CUST_NO |
客户编号 |
|
AST_DAY_FA_BAL |
当日金融资产余额 |
|
AST_MAVER_FA_BAL |
月日均金融资产余额 |
|
AST_SAVER_FA_BAL |
季日均金融资产余额 |
|
AST_YAVER_FA_BAL |
年日均金融资产余额 |
|
AST_DAY_AUM_BAL |
当日AUM余额 |
|
AST_MAVER_AUM_BAL |
月日均AUM余额 |
|
AST_SAVER_AUM_BAL |
季日均AUM余额 |
|
AST_YAVER_AUM_BAL |
年日均AUM余额 |
|
AST_FA_BAL_MAX |
金融资产余额最大值 |
|
AST_AUM_BAL_MAX |
AUM余额最大值 |
|
AST_DP_BAL |
存款余额 |
|
AST_MAVER_DP_BAL |
月日均存款余额 |
|
AST_SAVER_DP_BAL |
季日均存款余额 |
|
AST_YAVER_DP_BAL |
年日均存款余额 |
|
AST_DPSA_BAL |
活期存款余额 |
|
AST_MAVER_DPSA_BAL |
月日均活期存款余额 |
|
AST_SAVER_DPSA_BAL |
季日均活期存款余额 |
|
AST_YAVER_DPSA_BAL |
年日均活期存款余额 |
|
AST_DCARD_SA_BAL |
借记卡活期余额 |
|
AST_TD_BAL |
定期存款余额 |
|
AST_PSRE_TAINO_BAL |
存单定期一本通余额 |
|
AST_DP_BAL_MAX |
存款余额最大值 |
现金交易表(DZ_TR_CASH)
|
英文字段名 |
中文字段名 |
|
DATA_DAT |
数据日期 |
|
CUST_NO |
客户编号 |
|
CASH_MOTH_TR_CNT |
月交易笔数 |
|
CASH_SEAN_TR_CNT |
季交易笔数 |
|
CASH_HYEAR_TR_CNT |
半年交易笔数 |
|
CASH_YEAR_TR_CNT |
年交易笔数 |
|
CASH_MOTH_TR_ATM |
月交易金额 |
|
CASH_SEAN_TR_ATM |
季交易金额 |
|
CASH_HYEAR_TR_ATM |
半年交易金额 |
|
CASH_YEAR_TR_ATM |
年交易金额 |
|
CASH_MOTH_NET_TR_ATM |
月净交易金额 |
|
CASH_SEAN_NET_TR_ATM |
季净交易金额 |
|
CASH_HYEAR_NET_TR_ATM |
半年净交易金额 |
|
CASH_YEAR_NET_TR_ATM |
年净交易金额 |
自助设备交易表(DZ_TR_ATM)
|
英文字段名 |
中文字段名 |
|
DATA_DAT |
数据日期 |
|
CUST_NO |
客户编号 |
|
ATM_YEAR_TR_CNT_IN |
年流入交易笔数 |
|
ATM_YEAR_TR_CNT_OUT |
年流出交易笔数 |
|
ATM_YEAR_TR_AMT_IN |
年流入交易金额 |
|
ATM_YEAR_TR_AMT_OUT |
年流出交易金额 |
柜台设备交易表(DZ_TR_TERM)
|
英文字段名 |
中文字段名 |
|
DATA_DAT |
数据日期 |
|
CUST_NO |
客户编号 |
|
TERM_YEAR_TR_CNT_IN |
年流入交易笔数 |
|
TERM_YEAR_TR_CNT_OUT |
年流出交易笔数 |
|
TERM_YEAR_TR_AMT_IN |
年流入交易金额 |
|
TERM_YEAR_TR_AMT_OUT |
年流出交易金额 |
理财交易表(DZ_TR_FNCG)
|
英文字段名 |
中文字段名 |
|
DATA_DAT |
数据日期 |
|
CUST_NO |
客户编号 |
|
FNCG_MOTH_TR_CNT_IN |
年流入交易笔数 |
|
FNCG_MOTH_TR_CNT_OUT |
年流出交易笔数 |
|
FNCG_MOTH_TR_AMT_IN |
年流入交易金额 |
|
FNCG_MOTH_TR_AMT_OUT |
年流出交易金额 |
跨行转账表(DZ_TR_IBFT)
|
英文字段名 |
中文字段名 |
|
DATA_DAT |
数据日期 |
|
CUST_NO |
客户编号 |
|
IBFT_MOTH_TR_AMT |
月交易金额 |
|
IBFT_YEAR_TR_AMT |
年交易金额 |
|
IBFT_MOTH_NET_TR_AMT |
月净交易金额 |
|
IBFT_YEAR_NET_TR_AMT |
年净交易金额 |
|
IBFT_MOTH_TR_AMT_IN |
月流入金额 |
|
IBFT_YEAR_TR_AMT_IN |
年流入金额 |
|
IBFT_MOTH_TR_CNT |
月交易笔数 |
|
IBFT_YEAR_TR_CNT |
年交易笔数 |
|
IBFT_MOTH_TR_CNT_IN |
月流入交易笔数 |
|
IBFT_YEAR_TR_CNT_OUT |
年流入交易笔数 |
第三方支付交易表(DZ_TR_TPAY)
|
英文字段名 |
中文字段名 |
|
DATA_DAT |
数据日期 |
|
CUST_NO |
客户编号 |
|
TPAY_MOTH_TR_AMT |
月交易金额 |
|
TPAY_SEAN_TR_AMT |
季交易金额 |
|
TPAY_MOTH_NET_TR_AMT |
月净交易金额 |
|
TPAY_SEAN_NET_TR_AMT |
季净交易金额 |
|
TPAY_MOTH_TR_CNT |
月交易笔数 |
|
TPAY_YEAR_TR_CNT |
季交易笔数 |
掌银行为表(DZ_MBNK_BEHAVIOR)
|
英文字段名 |
中文字段名 |
|
pid |
客户编号 |
|
DeviceId |
设备ID |
|
UserId |
用户Id |
|
OperationPage |
当前操作页面 |
|
addfielddate |
有效日期 |
活期交易表(DZ_TR_APS)
|
英文字段名 |
中文字段名 |
|
apsdtrdat |
交易日期 |
|
apsdcusno |
客户编号 |
|
apsdtrcod |
交易码 |
|
apsdtramt |
交易金额 |
|
apsdabs |
摘要 |
|
apsdtrchl |
交易渠道 |
目标客户表(DZ_TAGGET_TRAIN)
|
英文字段名 |
中文字段名 |
|
DATA_DAT |
数据日期 |
|
CUST_NO |
客户编号 |
|
flag |
正负样本标识 |
下面,就让我来一步一步说明我的竞赛解题思路。
第一步,通读全文,初步筛选特征,就是从逻辑上确定哪些数据用来做预测,哪些数据变换成可计算数字特征。
先打开我使用的机器学习建模软件-Anaconde,如下图

点击JUPYTER,开室进行数据分析。
新建一个python文件,导入需要的资源包
import os #用于操作系统,文件
import time #用于操作时间
import string
# 数据读取与计算
import math
import pandas as pd
import numpy as np
# 绘图
import matplotlib.pyplot as plt
# 模型数据集划分
from sklearn.model_selection import train_test_split, KFold
# 模型流水线整合器
from sklearn.pipeline import Pipeline
# 模型数据预处理
from sklearn.preprocessing import PowerTransformer, StandardScaler, PolynomialFeatures
# 模型
from sklearn.linear_model import LassoCV
import xgboost as xgb
# 加载回归模型的评价指标
from sklearn.metrics import mean_absolute_error
# 保存模型模块
#from sklearn.externals import joblib
# 屏蔽warnings
import warnings
from sklearn.cluster import KMeans
Dir = ''
pd.set_option('display.max_columns', None)
#对年龄分布进行分析
DZ_NATURE=pd.read_csv(Dir +'DZ_NATURE.csv')
df_DZ_NATURE= pd.DataFrame(pd.read_csv(Dir +'DZ_NATURE.csv')) #把自然属性信息表(DZ_NATURE)数据读取出来进行分析
df_DZ_NATURE.info
df_DZ_NATURE['NTRL_CUST_AGE'].describe()
count 50161.000000
mean 44.288511
std 12.461690
min 8.000000
25% 35.000000
50% 43.000000
75% 53.000000
max 124.000000
Name: NTRL_CUST_AGE, dtype: float64
plt.figure(figsize=(9,8))
sns.set()
sns.distplot((df_DZ_NATURE['NTRL_CUST_AGE']),color='g',bins=100)
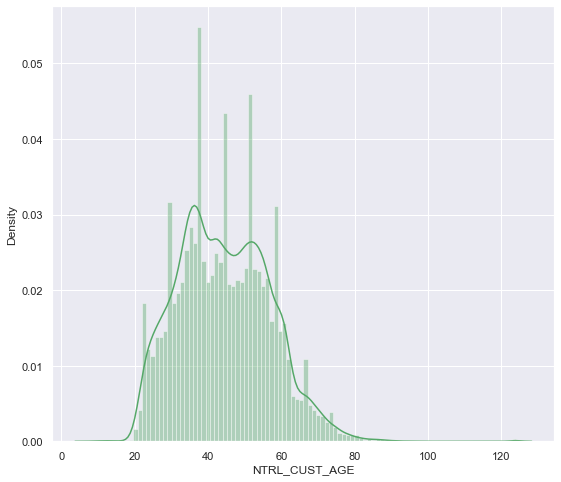
直观上看,客户年龄分布近似于正太分布,考虑对空值取年龄28,
进一步查看其它数据分布:
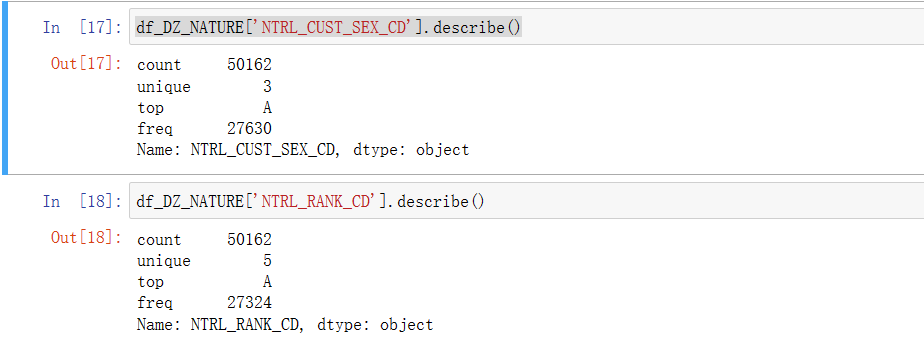
可以看到性别包括A,B和缺失3种分类,客户等级包括ABCDE等级,对这三个特征进行数据化。
df_DZ_NATURE['NTRL_CUST_AGE']=df_DZ_NATURE['NTRL_CUST_AGE'].fillna(28)
#对年龄做区间化,取消年龄的数字特性(也可考虑不拆分或取对数(因为满足正态分布))
df_DZ_NATURE['AGE_CLASS']=np.NAN
df_DZ_NATURE.loc[df_DZ_NATURE.NTRL_CUST_AGE < 20,'AGE_CLASS']='Class1'
df_DZ_NATURE.loc[(df_DZ_NATURE.NTRL_CUST_AGE>=20) & (df_DZ_NATURE.NTRL_CUST_AGE<30),'AGE_CLASS']='Class2'
df_DZ_NATURE.loc[(df_DZ_NATURE.NTRL_CUST_AGE>=30) & (df_DZ_NATURE.NTRL_CUST_AGE<40),'AGE_CLASS']='Class3'
df_DZ_NATURE.loc[(df_DZ_NATURE.NTRL_CUST_AGE>=40) & (df_DZ_NATURE.NTRL_CUST_AGE<50),'AGE_CLASS']='Class4'
df_DZ_NATURE.loc[(df_DZ_NATURE.NTRL_CUST_AGE>=50) & (df_DZ_NATURE.NTRL_CUST_AGE<60),'AGE_CLASS']='Class5'
df_DZ_NATURE.loc[(df_DZ_NATURE.NTRL_CUST_AGE>=60) & (df_DZ_NATURE.NTRL_CUST_AGE<70),'AGE_CLASS']='Class6'
df_DZ_NATURE.loc[(df_DZ_NATURE.NTRL_CUST_AGE>=70) & (df_DZ_NATURE.NTRL_CUST_AGE<80),'AGE_CLASS']='Class7'
df_DZ_NATURE.loc[df_DZ_NATURE.NTRL_CUST_AGE>=80,'AGE_CLASS']='Class8'
Count_A=df_DZ_NATURE.loc[df_DZ_NATURE.NTRL_CUST_SEX_CD=='A'].count()
Count_B=df_DZ_NATURE.loc[df_DZ_NATURE.NTRL_CUST_SEX_CD=='B'].count()
from collections import Counter
SexKeys = df_DZ_NATURE['NTRL_CUST_SEX_CD']
c = Counter(SexKeys)
''' OneHot 性别 ,显示性别组成
print('---------------------')
print (dict(c))
print('---------------------')
'''
if c['A']<c['B']:
df_DZ_NATURE.loc[(df_DZ_NATURE.NTRL_CUST_SEX_CD!='A') & (df_DZ_NATURE.NTRL_CUST_SEX_CD!='B')]='B'
else:
df_DZ_NATURE.loc[(df_DZ_NATURE.NTRL_CUST_SEX_CD!='A') & (df_DZ_NATURE.NTRL_CUST_SEX_CD!='B')]='A'
Sex_OneHot=pd.get_dummies(df_DZ_NATURE['NTRL_CUST_SEX_CD'],prefix='SexKey',prefix_sep='_')
Train=df_DZ_NATURE.drop(['NTRL_CUST_SEX_CD'],axis=1)
Train=pd.concat([Train,Sex_OneHot],axis=1)
#处理性别特征完毕
'''
处理客户等级
对客户等级进行OneHot,注意未处理客户等级缺失的数据,因样本中没有包含此类数据
'''
Sex_OneHot=pd.get_dummies(Train['NTRL_RANK_CD'],prefix='RANK',prefix_sep='_')
Train=Train.drop(['NTRL_RANK_CD'],axis=1)
Train=pd.concat([Train,Sex_OneHot],axis=1)
#处理客户等级特征完毕
#先对年龄缺失值进行处理,这里先按28岁填充
#处理客户年龄,因为年龄基本服从正态分布,初步考虑分为0-20,20-30,30-40,40-50,50-60,70-80,80-100
#分别标记为 age_class1,......,age_class8
Train['NTRL_CUST_AGE']=Train['NTRL_CUST_AGE'].fillna(28)
Sex_OneHot=pd.get_dummies(Train['AGE_CLASS'],prefix='AGES',prefix_sep='_')
Sex_OneHot=Sex_OneHot.drop(['AGES_A'],axis=1)
Train=Train.drop(['AGE_CLASS'],axis=1)
Train=Train.drop(['NTRL_CUST_AGE'],axis=1)
Train=Train.merge(Sex_OneHot,on='CUST_NO',how='outer')
Train=Train.merge(df_DZ_ASSET,on='CUST_NO',how='outer')
Train=Train.merge(df_DZ_TR_ATM,on='CUST_NO',how='outer')
Train=Train.merge(df_DZ_TR_CASH,on='CUST_NO',how='outer')
Train=Train.merge(df_DZ_TR_FNCG,on='CUST_NO',how='outer')
Train=Train.merge(df_DZ_TR_IBTF,on='CUST_NO',how='outer')
Train=Train.merge(df_DZ_TR_TERM,on='CUST_NO',how='outer')
Train=Train.merge(df_DZ_TR_TPAY,on='CUST_NO',how='outer')
到这里,第一组数据提取完成。这是一个50162个大众客户的基本信息。