二三、编译器
1、One Definition Rule
1)转化单元
我们写好的每个源文件(.cpp,.c)将其所包含的头文件(#include <xxx.h>)合并后,称为一个转化单元。
编译器单独的将每一个转化单元生成为对应的对象文件(.obj),对象文件包含了转化单元的机器码和转化单元的引用信息(不在转化单元中定义的对象)。
最后链接器将各个转化单元的对象文件链接起来,生成我们的目标程序。
比如在对象文件A中包含了定义在其它转化单元的引用,那么就去其它转化单元的对象文件中寻找这个引用的定义来建立链接,如果在所有的对象文件中都找不到这个定义,那么就会生成一个链接错误。
2)未定义行为
在编写代码中,C++标准未做规定的行为,称为未定义行为,未定义行为的结果是不确定的,具体不同的编译器下会有不同的效果,比如
c=2*a++ + ++a*6;
这里先算a++还是先算++a就是一个未定义行为,比如
int x = -25602;
x= x>>2;
x的结果在不同的编译器下是不确定的,因为这也属于未定义行为
3)One Definition Rule(ODR)
ODR是一系列规则,而不是一个规则,程序中定义的每个对象都应有着自己的规则;但是基本上来讲任何的变量、函数、类、枚举、模板、概念(C++20)在每个转化单元中都只允许有一个定义;
在整个程序中,非inline的函数或变量(C++17),有且仅能有一个定义
const声明的变量或函数只在当前的源文件中有效,可以在一个项目的不同源文件定义相同的const变量
4)名称的链接属性
程序中的变量、函数、结构等都有着自己的名字,这些名字具有不同的链接属性,链接器就是根据这些链接属性来把各个对象文件链接起来的。链接属性分为以下三种
①内部链接属性:该名称仅仅在本转化单元中有效,如static、const声明的变量、函数
②外部链接属性:该名称在其它转化单元中也有效。通过extern关键字可以定义外部链接属性
③无链接属性:该名称仅仅能够用于该名称的作用域内访问
注:static变量或函数在自己的转化单元有着自己的内存空间,而inline定义的变量只有一个内存地址
2、#define
1)用法一
#define A B //将标识符A定义为B的别名
#define 整数 int //将整数替换为int
整数 a{};
//#define实际用法
#include <iostream>
#define _HHHH_ int a //将_HHHH_ 替换为int a
#define VERSION "V2.0"
int main()
{
_HHHH_ { 250 };
std::cout << a << std::endl;
std::cout << VERSION<<std::endl;
}
2)C++中定义常量的方式
//C++定义常量的方法
const int width{1080};
//C语言中经常通常#define来定义常量
#define width 1080
#define的方式来定义常量存在一个问题,有时候并不安全
3)#define其它写法
#define H //定义一个标识符H ,代码中的H将会被删除掉
int H a 相当于 int a;
//实际场景应用
#define _in_ //没有实际意义
#define _out_
int ave(_in_ int a,_out_ int& b)
{
return a+b
}
4)取消宏的定义
//语法
#undef H //
//应用场景
#define _H_
#undef _H_ //删除宏_H_的定义,后面的代码不能使用
注:执行顺序为代码编译的顺序(从上到下),而不是函数调用的顺序
5)定义复杂表达式宏
#define SUM(X,Y) X+Y //使用X+Y替换SUM(X,Y)
#define AVE(X,Y) (X+Y)/2 //使用(X+Y)/2替换AVE(X,Y)
#define BIGGER(X,Y) ((X)>(Y)?(X):(Y))
SUM(100,200);
AVE(100,200);
BIGGER(100,200);
//实际应用场景
#define RELEASE(x) delete[] x;x=nullptr
int main()
{
int* a = new int[50];
RELEASE(a);
}
6)定义复杂表达式宏
// #可以将一个标识符参数字符串化
#define SHOW(X) std::cout<<#X //通过#将X处理成了字符串
SHOW(1234fg); //相当于std::cout<<"12345fg"
// ##可以连接两个标识符
#define T1(X,Y) void X##Y(){std::cout<<#Y;}
T1(test, 22);
3、namespace
有时候为了方便管理,把相关的函数、变量、结构体等会附加到一个命名空间中
//声明命名空间
namespace t
{
int value;
}
//访问这个命名空间的变量
t::value
//直接使用命名空间,不推荐
using namespace t;
vlaue=255;
2)全局命名空间
虽有具有链接属性的对象,只要没有定义命名空间,就默认定义在全局命令空间中,全局命名空间中成员的访问不用显示的指定,当局部名称覆盖了全局名称时才需要显示的指定全局命令空间
int a;
::a=250;
3)命名空间的扩展
//第二个htd属于对htd命名空间的扩展,weight和heigth同属于一个命名空间
namespace htd
{
int weigth{1980};
}
namespace htd
{
int heigth{1080};
}
4)命名空间的声明
//htd.h
namespace std
{
extern int height; //变量声明
void test(); //函数声明
}
//htd.cpp
#include <iostream>
#include "htd.h"
int htd::heigth{250}; //变量定义
void htd::test() //函数定义
{
std::cout<<htd::height;
}
5)命名空间的嵌套
//htd.h
namespace htd
{
namespace hack //命名空间的嵌套
{
void hackServer();
}
}
//htd.cpp
void htd::hack::hackServer()
{
...
}
void htd::sendSms()
{
...
}
6)未命名的命名空间
不给命名空间指定名称,将会声明一个未命名的命名空间。未命名的命名空间中声明的内容一律为内部链接属性,包括extern声明的内容,未命名的命名空间仅仅在本转化单元中有效
//t.cpp
void THack()
{
}
//x.cpp
namespace
{
void THack()
{
}
}
int main()
{
THack();
}
//
7)命名空间的别名
namespace htd
{
void sendSms();
namespace hack
{
void hackServer();
}
}
namespace hServer=htd::hack;
hServer::hackServer();
4、预处理指令逻辑
所有#开头的代码都是和编译器进行打交道
1)#ifdef
#define _HEIGHT_ 1080 //#ifdef和#endif成对出现
#ifdef _HIGHT_
#else
#endif
//hc.h
#ifdef _HC_ //如果定义了宏_HC_,就执行XXXX里面的代码。如果没有定义,则执行YYYYY
XXXX
#else
YYYYY
#endif
//常见用法
#ifndef _HC_ //如果没有定义了宏_HC_
#define _HC_ //则定义了宏_HC_
#else
#endif
//实际应用场景
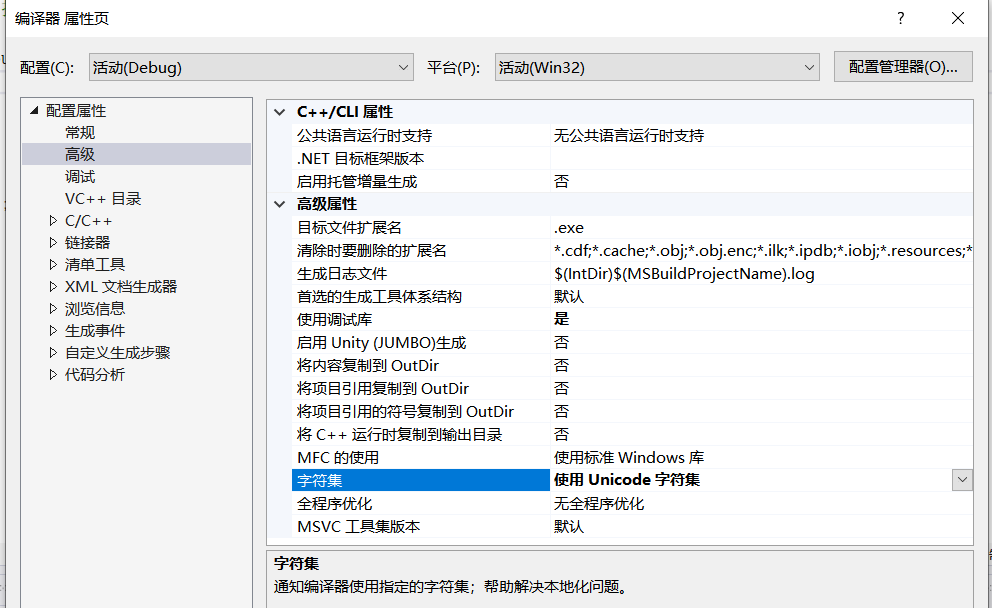
#ifdef UNICODE //如果使用了UNICODE字符集,则使用wchar_t定义变量
wchar_t a;
#else
char a;
#endif
//通过预处理指令进行版本控制
#define VERSION 101
#if VERSION==100 //当VERSION为100时,执行如下逻辑,否则执行else中的逻辑
void SendSms()
{
}
#else
void SendSms()
{
}
#endif
2)#elif
//#elif语法
#define _HEIGHT_ 2080
#if _HEIGHT_ == 1080 //针对每一个分辨率执行不同的逻辑
...
#elif _HEIGHT_ == 720
...
#else
...
#endif
//预处理指令可以进行简单的计算//当VERSION为100时,执行如下逻辑,否则执行else中的逻辑
void SendSms()
{
}
5、预定义宏
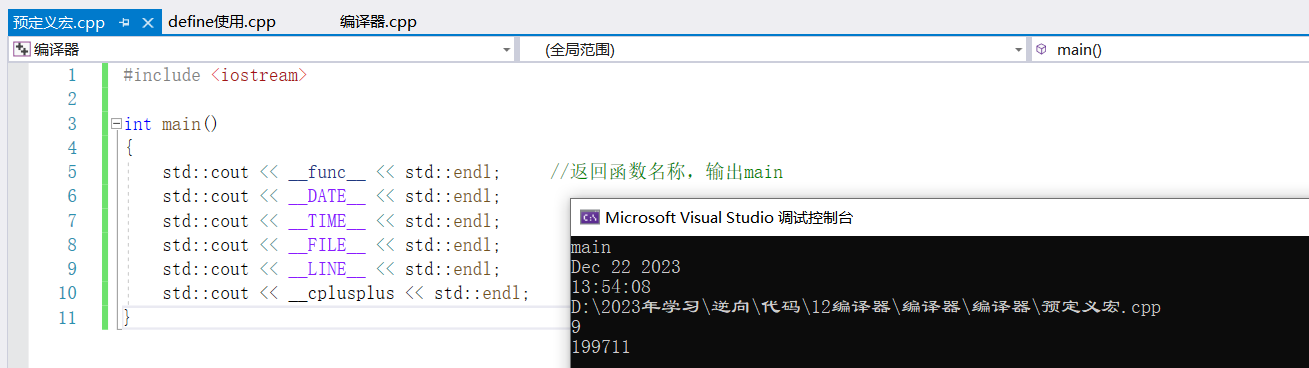
1)标准预定义标识符_fun_
编译器支持ISO C99和ISO C++ 11,即可使用该预定义标识符。用于返回函数的名称
__func__ //返回函数的名称
//用法示例
#include <iostream>
int main()
{
std::cout << __func__ << std::endl; //返回函数名称,输出main
}
2)标准预定义宏
编译器支持ISO C99和ISO C++17标准,即可使用以下预定义宏
| 宏 | 说明 |
|---|---|
| _DATE_ | 返回源文件的编译日期 |
| _TIME_ | 返回当前转化单元的转化时间(可理解为代码修改的时间) |
| _FILE_ | 返回源文件的名称 |
| _LINE_ | 返回当前的行 |
| __cplusplus | 当当前单元为C++时(即.cpp文件时),__cplusplus定义为一个整数,否则不是c++文件 |
#include <iostream>
int main()
{
std::cout << __func__ << std::endl; //返回函数名称,输出main
std::cout << __DATE__ << std::endl;
std::cout << __TIME__ << std::endl;
std::cout << __FILE__ << std::endl;
std::cout << __LINE__ << std::endl;
std::cout << __cplusplus << std::endl;
}
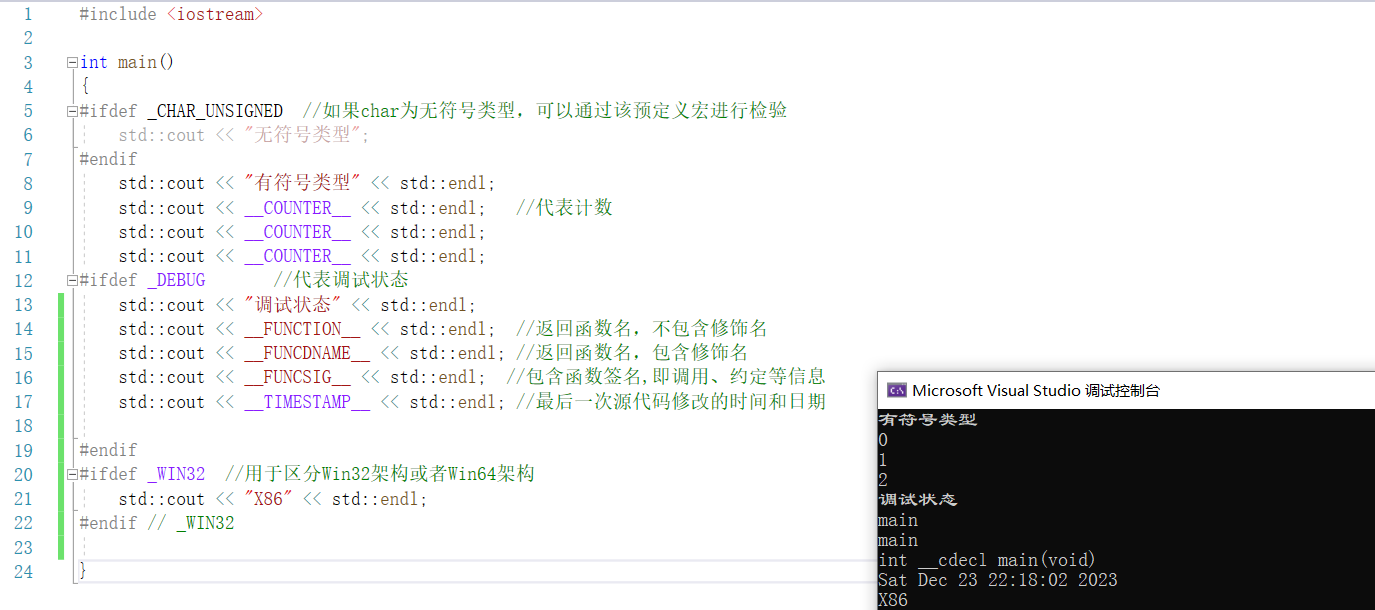
3)MSVC的预定义宏(可理解为微软的VC编译器中,预定义的一些宏)
| 宏 | 说明 |
|---|---|
| _CHAR_UNSIGNED | 如果char类型为无符号,该宏定义为1,否则为未定义 |
| _COUNTER_ | 用于计数,从0开始,每使用一次都会递增1 |
| _DEBUG | 如果设置了_DEBUG宏,代表当前为调试状态/lDd /mDd /mTd该宏定义为1,否则为未定义 |
| _FUNCTION_ | 返回函数名称 ,但是不包含修饰名 |
| _FUNCDNAME_ | 函数名称 包含修饰名 |
| _FUNCSIG_ | 包含了函数签名的函数名 |
| _WIN32 | 当编译为32位ARM,64位ARM,X68或X64定义为1,否则未定义 |
| _WIN64 | 当编译为64位ARM或x64定义为1,否则未定义。用于区别 |
| _TIMESTAMP_ | 最后一次源代码修改的时间和日期 |
#include <iostream>
int main()
{
#ifdef _CHAR_UNSIGNED //如果char为无符号类型,可以通过该预定义宏进行检验
std::cout << "无符号类型";
#endif
std::cout << "有符号类型" << std::endl;
std::cout << __COUNTER__ << std::endl; //代表计数
std::cout << __COUNTER__ << std::endl;
std::cout << __COUNTER__ << std::endl;
#ifdef _DEBUG //代表调试状态
std::cout << "调试状态" << std::endl;
std::cout << __FUNCTION__ << std::endl; //返回函数名,不包含修饰名
std::cout << __FUNCDNAME__ << std::endl; //返回函数名,包含修饰名
std::cout << __FUNCSIG__ << std::endl; //包含函数签名,即调用、约定等信息
std::cout << __TIMESTAMP__ << std::endl; //最后一次源代码修改的时间和日期
#endif
#ifdef _WIN32 //用于区分Win32架构或者Win64架构
std::cout << "X86" << std::endl;
#endif // _WIN32
}
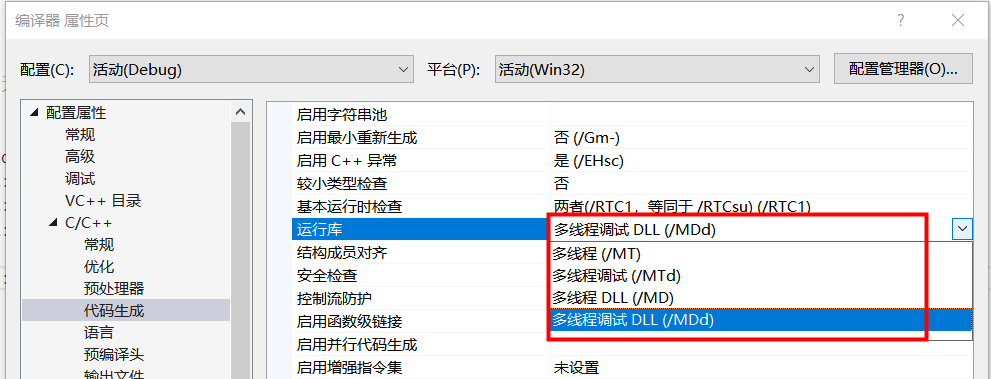
只要【项目属性】-【C/C++】-【代码生成】-【运行库】,选择了调试,则_DEBUG就会显示
注:上述宏只在微软的VS编辑器才可以使用,其它的编译器无法使用
6、调试
我们编写好程序以后,可能存在一些bug和错误,对于语法上错误,编译器能够直接给出提示,而对于逻辑上的错误,编译器不能够直接发现,调试就是一个找错误和改错误的过程
1)调试建议:为了方便调试,在编程风格上提出如下建议
①功能能模块化就模块化
②使用能够体现出具体意义的函数名和变量名
③使用正常的缩进和代码块
④良好的注释习惯
2)利用集成调试器调调试程序
VS2019继承了一个调试器,可以利用断点、流程跟踪等方式来调试自己的程序
断点就是当程序执行到断点位置,程序就会停下来
3)利用其它调试器
OllyDbg
X96Dbg
WinDbg
4)利用预处理指令来输出调试信息
#define _dbg_i //先定义一个宏
#ifdef _dbg_i //如果宏存在,则执行下面的代码块
std::cout<<"调试信息";
#endif
7、assert
assert宏需要头文件cassert
1)assert语法
//assert语法
assert(bool表达式); //如果括号内的bool表达式为false,则会调用std::abort()函数,弹出下面的对话框,
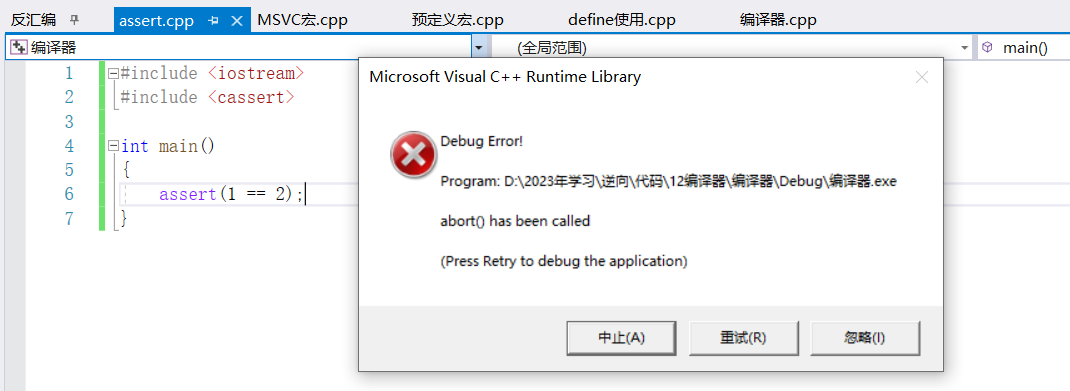
2)关闭assert
//关闭assert
#define NDEBUG //可以在当前转化单元关闭assert,但是这个定义必须放在#include <cassert>之前
3)static_assert(静态断言)
//static_assert用于编译时检查条件
static_assert(bool表达式,"Error information"); //先检查表达式,若表达式为假,则输出后面的错误信息。如果表达式为0,则程序是不进行编译的,此处二点bool表达式只能用于常量
//C++17新语法
static_assert(bool表达式);