实验06 Pandas缺失值处理
实验学时:2学时
实验类型:验证
实验要求:必修
一、实验目的
- 掌握判断缺失值、过滤缺失值、填充缺失缺失值等缺失值处理
- 解决实际数据中的缺失值问题
二、实验要求
使用常见的缺失值处理函数(如:isnull()、notnull()、fillna()、dropna()函数)等知识在PyCharm中编写程序,解决实际数据中的缺失值处理问题。
三、实验内容
任务1.用分组的均值来填充缺失值,用Python编写程序实现。
类别 产地 名称 单价
0 文具 晋江 文具盒 15.0
1 文具 厦门 钢笔 NaN
2 文具 厦门 订书机 18.0
3 服装 厦门 上衣 50.0
4 服装 晋江 裤子 35.0
5 鞋袜 晋江 棉袜 NaN
6 鞋袜 晋江 丝袜 12.0
类别 产地 名称 单价
产地
厦门
1 文具 厦门 钢笔 34.000000
2 文具 厦门 订书机 18.000000
3 服装 厦门 上衣 50.000000
晋江
0 文具 晋江 文具盒 15.000000
4 服装 晋江 裤子 35.000000
5 鞋袜 晋江 棉袜 20.666667
6 鞋袜 晋江 丝袜 12.000000
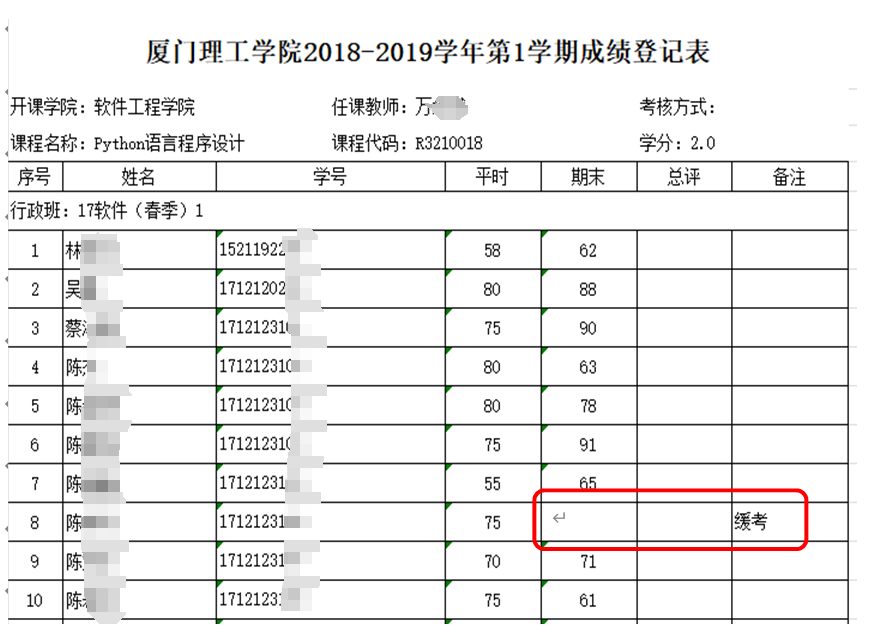
任务2. 有一个名为python1.xls的文件,内容如下图,现将表中的缓考、缺考的期末值用同姓所有同学的平均分填充。用Python编写程序实现。
任务3. 有一个名为python2.xlsx的文件,内容如下图,现将表中的数据做如下处理:
(1)读取数据,删除空行和空列;
(2)将分数列值为NAN(空值)的值填充为0分;
(3)将姓名的缺失值用“张生”进行填充。
(4)将处理好的数据保存在exepython2.xlsx中。
用Python编写程序实现。
test6.py
import numpy as np
import pandas as pd
import openpyxl as opx
from openpyxl.styles import Font, Alignment, Color, Border, Side
pd.set_option("display.unicode.east_asian_width", True)
pd.set_option("display.max_rows", None)
def task1():
data = {
'类别': ['文具', '文具', '文具', '服装', '服装', '鞋袜', '鞋袜'],
'产地': ['厦门', '晋江', '晋江', '晋江', '厦门', '厦门', '厦门'],
'类名称': ['文具盒', '钢笔', '订书机', '上衣', '裤子', '棉袜', '丝袜'],
'单价': [15.0, None, 18.0, 50.0, 35, None, 12.0],
}
df = pd.DataFrame(data)
print("原数据\n", df)
df1 = df.groupby(['产地']).mean(numeric_only=True)
print(df1)
df2 = pd.DataFrame(df.values.T)
df2 = df2.fillna({1: df1['单价'][0], 5: df1['单价'][1]})
df = pd.DataFrame(df2.values.T)
print("填充后\n", df)
def task2():
data = pd.read_excel("./python1.xlsx", skiprows=4, usecols=(1, 5), skipfooter=12)
data.columns = ['姓名', '期末']
print('初始数据'.center(65, '-'), '\n', data)
d = data.groupby(data['姓名'].str[0]).mean(numeric_only=True)
print('分组后的数据'.center(65, '-'), '\n', d)
print('陈姓同学的期末成绩平均值'.center(65, '-'), '\n', d['期末'].get('陈'))
workbook = opx.load_workbook("./python1.xlsx")
worksheet = workbook["sheet1"]
worksheet['F13'] = d['期末'].get('陈')
l_side = Side(style='dashDot', color=Color(indexed=10))
r_side = Side(style='thin', color=Color(indexed=59))
t_side = Side(style='thin', color=Color(indexed=59))
b_side = Side(style='thin', color=Color(indexed=59))
for i in range(4, 63):
worksheet['D' + str(i)].border = Border(top=t_side, bottom=b_side)
worksheet['I' + str(i)].border = Border(top=t_side, bottom=b_side, right=r_side)
for i in range(55, 63):
worksheet['B' + str(i)].border = Border(top=t_side, bottom=b_side)
worksheet['E' + str(i)].border = Border(top=t_side, bottom=b_side)
worksheet['F' + str(i)].border = Border(top=t_side, bottom=b_side)
worksheet['H' + str(i)].border = Border(top=t_side, bottom=b_side)
workbook.save('python1.xlsx')
def task3():
data = pd.read_excel("./python2.xlsx", skiprows=1, usecols=(0, 1, 2, 4, 6, 7))
data.columns = ['姓名', '高等数学', '大学英语', '操作系统', 'Python语言', '计算机组成原理']
print('初始数据'.center(65, '-'), '\n', data)
data = data.dropna(axis=0, how='all', subset=None, inplace=False)
print('删除空行后的数据'.center(65, '-'), '\n', data)
data = data.fillna({'高等数学': 0, '大学英语': 0, '操作系统': 0, 'Python语言': 0, '计算机组成原理': 0})
print('填充分数为0后的数据'.center(65, '-'), '\n', data)
data = data.fillna({'姓名': '张生'})
print('姓名缺省值用张生填充'.center(65, '-'), '\n', data)
data.replace({'缺考': 0}, inplace=True)
data.to_excel('exepython2.xlsx', index=False)
if __name__ == '__main__':
task1()
task2()
task3()