Flink实时处理入门
1、Flink框架介绍
Flink 诞生于欧洲的一个大数据研究项目 StratoSphere。它是由 3 所地处柏林的大学和欧洲其他一 些大学在 2010~2014 年共同进行的研究项目,由柏林理工大学的教授沃克尔·马尔科(Volker Markl)领衔开发。2019年1月阿里巴巴收购Flink项目,开源于apache孵化。
Flink 的官网主页地址:https://flink.apache.org/
Flink 的中文主页地址:https://flink.apache.org/zh/
Flink 的中文社区地址:https://flink-learning.org.cn/activity
阿里云Flink技术地址:https://help.aliyun.com/product/45029.html
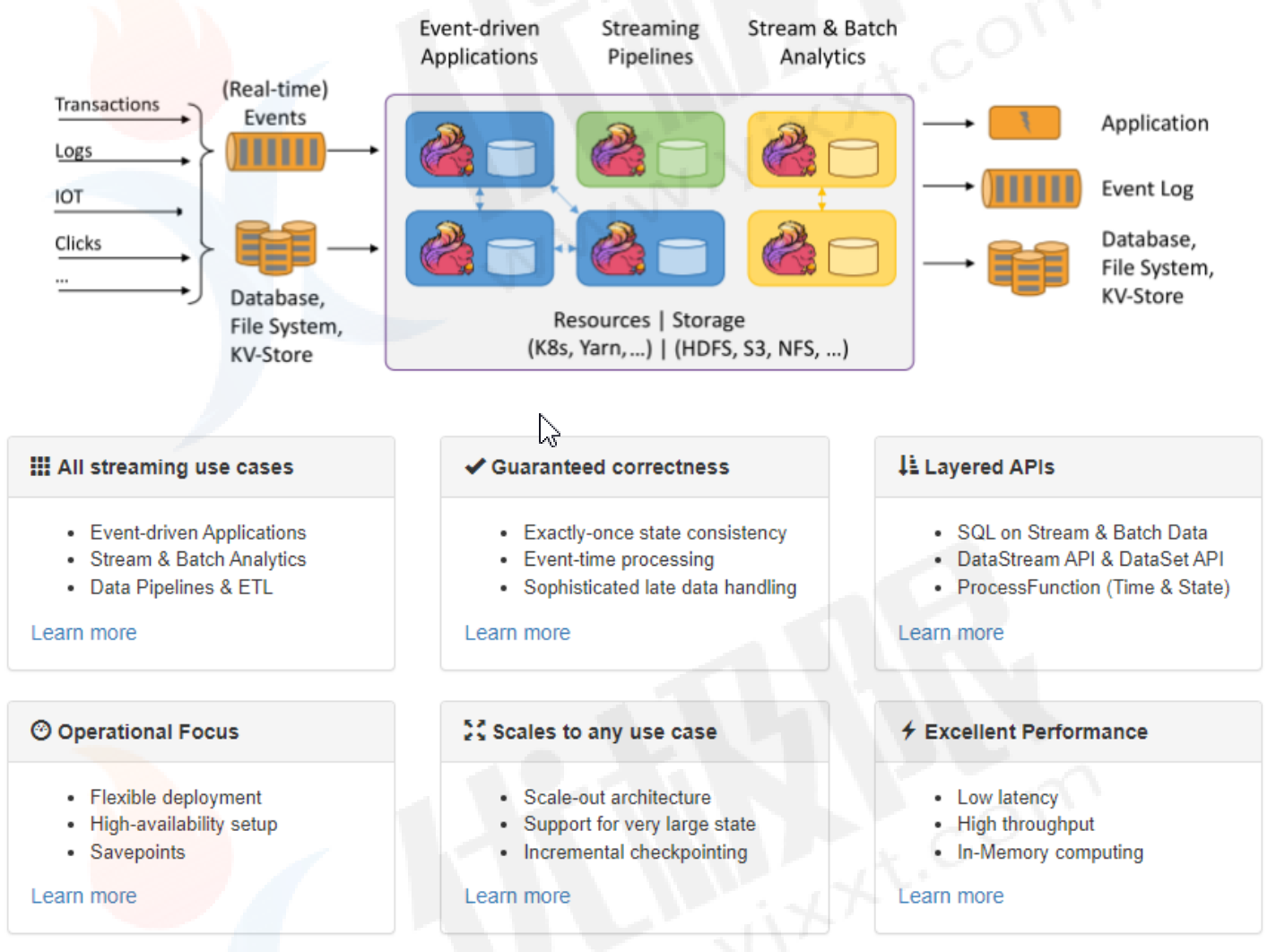
框架优势:所有流式场景、正确性保证、分层API、聚集运维、大规模运算、性能卓越
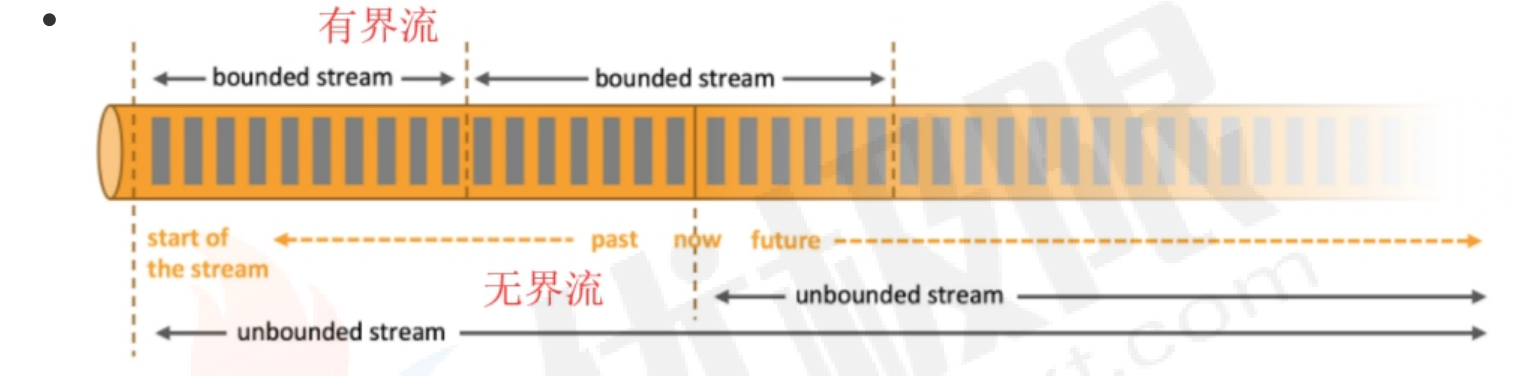
1.1、无界和有界数据
任何类型的数据都可以形成一种事件流。
数据可以分为有界流和无界流:
- 无界流:有定义流的开始,没有定义流的结束,无休止产生数据流。数据被摄取后立即处理,处理无界流要以特定顺序摄取事件。
- 有界流:有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后计算,有界流所有数据可以被排序,不需要有序摄取,有界流处理称为批处理。
flink擅长处于有界流和无界流的数据集。
2、Flink编程模型
2.1、分层API
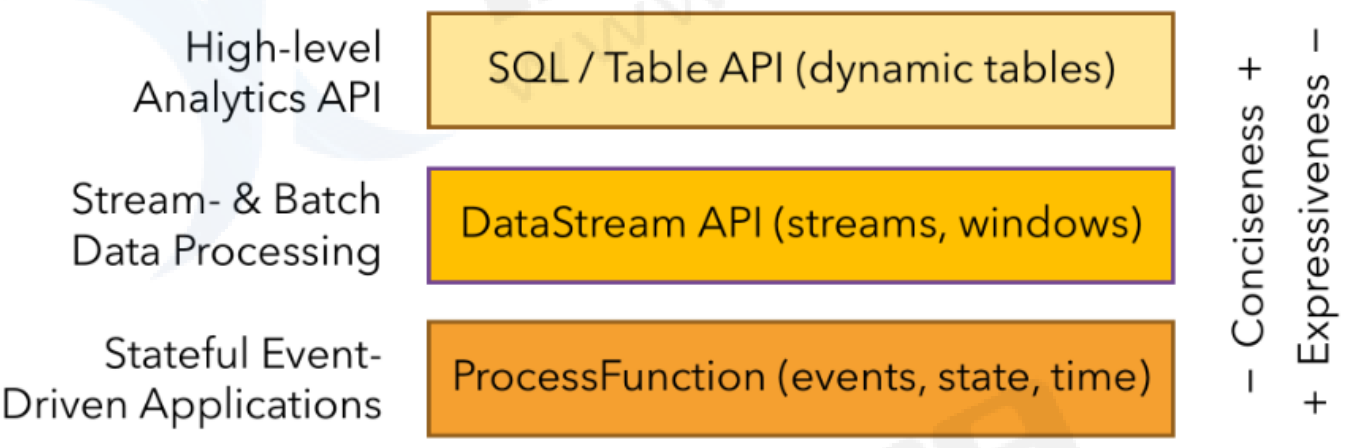
ProcessFunction:Flink最底层的APi,可以操作窗口内多个数据源和数据流,对时间和状态的细粒度控制,但是开发比较复杂,灵活性高!
DataStream API在processFunction基础上多一些算子,支持java和scala语言,预定了map()等函数;还细分为DataSet API和DataStream,其中DataSetApi是处理批数据,DataStream处理流数据。
SQL&Table API最顶层API,就是写SQL语句处理数据,适合通用性数据的解决方案,SQL构建在Table表之上的,需要构建Table环境。
2.2、编程模型
每个flink程序由source operator + transformation operator + sink operator组成

2.3、环境搭建
前置条件:必须JDK11、scala-2.12.x
- 导入依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<flink.version>1.15.2</flink.version>
<scala.version>2.12.2</scala.version>
<log4j.version>2.12.1</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!--flink客户端-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!--本地运行的webUI-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
</dependency>
<!--flink与kafka整合-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<!--状态后端-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb</artifactId>
<version>${flink.version}</version>
</dependency>
<!--日志系统-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
为了使用 Scala API,将 flink-java 的 artifact id 替换为 flink-scala_2.12 ,同时 将 flink-streaming-java 替换为 flink-streaming-scala_2.12
- 配置log4j2.properties
rootLogger.level = WARN
rootLogger.appenderRef.console.ref = ConsoleAppender
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
- 模拟目标数据(存在项目根目录路径下)
hello01 yjxxt01
hello02 yjxxt02
hello03 yjxxt03
hello04 yjxxt04
hello05 yjxxt05
hello06 yjxxt06
hello07 yjxxt07
hello08 yjxxt08
hello01 yjxxt01
hello02 yjxxt02
hello03 yjxxt03
hello04 yjxxt04
hello05 yjxxt05
hello06 yjxxt06
hello07 yjxxt07
hello08 yjxxt08
- 批处理java版本WordCount代码
package com.zwf.flinkdemo;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* @author MrZeng
* @version 1.0
* @date 2023-12-28 20:27
*/
public class Hello01WordCountByDataSetUseJava {
public static void main(String[] args) {
//创建flink环境
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
//获取数据源
DataSource<String> source = environment.readTextFile("data/data.txt");
//开始转换
FlatMapOperator<String, String> map = source.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
Arrays.stream(line.split("\\s+")).forEach(word -> collector.collect(word));
}
});
//开始计数
MapOperator<String, Tuple2<String, Integer>> map1 = map.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return Tuple2.of(s, 1);
}
});
//开始分类并统计
AggregateOperator<Tuple2<String, Integer>> sum = map1.groupBy(0).sum(1);
try {
sum.print();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
- 批处理scala版WordCount代码
package com.zwf.flinkscala
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, createTypeInformation}
/**
* @author MrZeng
* @date 2023-12-28 20:29
* @version 1.0
*/
object WordCountByDataSetUseScala {
def main(args: Array[String]): Unit = {
//flink批处理 wordcount
//加载flink环境
val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//读取文件数据
val ds: DataSet[String] = environment.readTextFile("data/data.txt")
//缺少createTypeInformation包
ds.flatMap(_.split("\\s+")).map((_,1)).groupBy(0).reduce((x,y)=>x._1->(x._2+y._2)).print()
}
}
2.4、数据流处理
先下载netcat工具:https://eternallybored.org/misc/netcat/
解压缩后把nc.exe和nc64.exe包存放C:\Windows\System32
注意:为了防止程序报毒,先关闭杀毒软件!
- 运行nc工具 在cmd窗口下
nc -lp [端口号]
- 在linux下运行
yum install -y nc
nc -l -k -p [端口]
- java代码
package com.zwf.flinkdemo;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author MrZeng
* @version 1.0
* @date 2023-12-28 22:11
*/
public class StreamingToWordCount {
public static void main(String[] args) throws Exception {
//获取流处理的环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> stream = environment.socketTextStream("localhost", 9999);
//进行mapTask操作
SingleOutputStreamOperator<String> flatMap = stream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
//先进行按空格切分
String[] words = line.split("\\s+");
//把所有的word收集
for (String w : words) {
collector.collect(w);
}
}
});
//mapTask处理
SingleOutputStreamOperator<Tuple2<String, Integer>> map = flatMap.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String w) throws Exception {
return Tuple2.of(w, 1);
}
});
//根据key进行处理
KeyedStream<Tuple2<String, Integer>, String> keyBy = map.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
});
//计算下标为1
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = keyBy.sum(1);
//打印值
sum.print();
//执行wordcount程序
environment.execute();
}
}
- scala代码
package com.zwf.flinkscala
import org.apache.flink.streaming.api.scala._
/**
* @author MrZeng
* @date 2023-12-29 8:31
* @version 1.0
*/
object StreamingWordCount {
def main(args: Array[String]): Unit = {
//创建environment环境
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//创建网络socket连接
val DStream: DataStream[String] = environment.socketTextStream("localhost", 8888)
DStream.flatMap(_.split("\\s+")).map((_,1)).keyBy(_._1).sum(1).print()
environment.execute()
}
}
注意:运行时要先使用nc工具监听端口,再启动程序!否则会报错!
在编写scala代码时,注意导入隐式转换包:import org.apache.flink.streaming.api.scala._
- java简化版代码
package com.zwf.flinkdemo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author MrZeng
* @version 1.0
* @date 2023-12-29 10:40
*/
public class SimpleFlinkJava {
public static void main(String[] args) throws Exception {
//创建flink环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//建立socket连接
DataStreamSource<String> DStream = environment.socketTextStream("localhost", 7777);
//处理流 第一种方式使用参数
DStream.flatMap((v,out)->{
String[] split = v.split("\\s+");
for (String s:split){
out.collect(s);
}
}, Types.STRING)
.map(v-> Tuple2.of(v,1),Types.TUPLE(TypeInformation.of(String.class),TypeInformation.of(Integer.class)))
.keyBy((x)->x.f0).sum(1).print();
//第二种方法 使用returns
DStream.<String>flatMap((v,out)->{
String[] split = v.split("\\s+");
for (String s:split){
out.collect(s);
}
}).returns(String.class)
.map(v-> Tuple2.of(v,1)).returns(Types.TUPLE(Types.STRING,Types.INT))
.keyBy((x)->x.f0).sum(1).print();
environment.execute();
}
}
- scala简化版代码
package com.zwf.flinkscala
import org.apache.flink.streaming.api.scala._
/**
* @author MrZeng
* @date 2023-12-29 11:08
* @version 1.0
*/
object SimpleFlinkScala {
def main(args: Array[String]): Unit = {
//创建环境
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//建立socket编程
val dataStream: DataStream[String] = environment.socketTextStream("localhost", 6666)
//处理流数据
dataStream.flatMap(_.split("\\s+")).map(_->1).keyBy(_._1).sum(1).print()
//执行流
environment.execute();
}
}
2.5、TypeInformation
由于java代码的特点,存在类型擦除,也就是泛型中有泛型会造成类型匹配失败,就需要指定数据类型,防止找不到类型。
flink使用了TypeInformation的概念来表达数据类型,针对不同数据类型产生特定序列化器、反序列化器和比较操作符。也能通过分析输入和输出数据来自动获取数据的类型信息以及序列化器和反序列化器,在一些特定环境下我们需要明确数据类型来提高程序的性能。
- 数据类型
flink支持java和scala所有原始数据类型。最常用的数据类型有以下:
- Primitives(原始数据类型)
- java和scala的元组,java元组从0开始计数位置,scala元组从1开始计数位置。Flink实现java Tuple可以有25个元素,根据元素数量不同,实现了Tuple1、Tuple2....一直到Tuple25,也可以通过public属性访问f0、f1、f2等,或者使用getFields()访问,下标从0开始。
- scala样例类和java的pojo类。
- 返回数据类型
使用scala时无需指定!
- 需要使用 SingleOutputStreamOperator 的 returns 方法来指定算子的返回数据类型。
//第二种方法 使用returns
DStream.<String>flatMap((v,out)->{
String[] split = v.split("\\s+");
for (String s:split){
out.collect(s);
}
}).returns(String.class)
.map(v-> Tuple2.of(v,1)).returns(Types.TUPLE(Types.STRING,Types.INT))
.keyBy((x)->x.f0).sum(1).print();
environment.execute();
使用TypeInformation指定返回的数据类型,也是flink类型系统的核心,是生产序列化和反序列化工具和Comparator工具类。同时它还连接schema和编程语言内部系统的桥梁。
DStream.flatMap((v,out)->{
String[] split = v.split("\\s+");
for (String s:split){
out.collect(s);
}
}, Types.STRING)
.map(v-> Tuple2.of(v,1),Types.TUPLE(TypeInformation.of(String.class),TypeInformation.of(Integer.class)))
.keyBy((x)->x.f0).sum(1).print();
为了支持泛型,Flink引入了TypeHit类
// 要使用TypeHint来指定。
Types.TUPLE(new TypeHint<Tuple2<String,Integer>>(){}.getTypeInfo());
Types对象既可以使用TypeHit指定又可以使用Types指定,序列化和反序列化以及比较器已经定义好了。
Types.POJO(String.class);
Types.TUPLE(Types.STRING,Types.INT);
Types.TUPLE(new TypeHint<Tuple2<String,Integer>>(){}.getTypeInfo());
2.6、基本概念介绍
- Stream执行环境
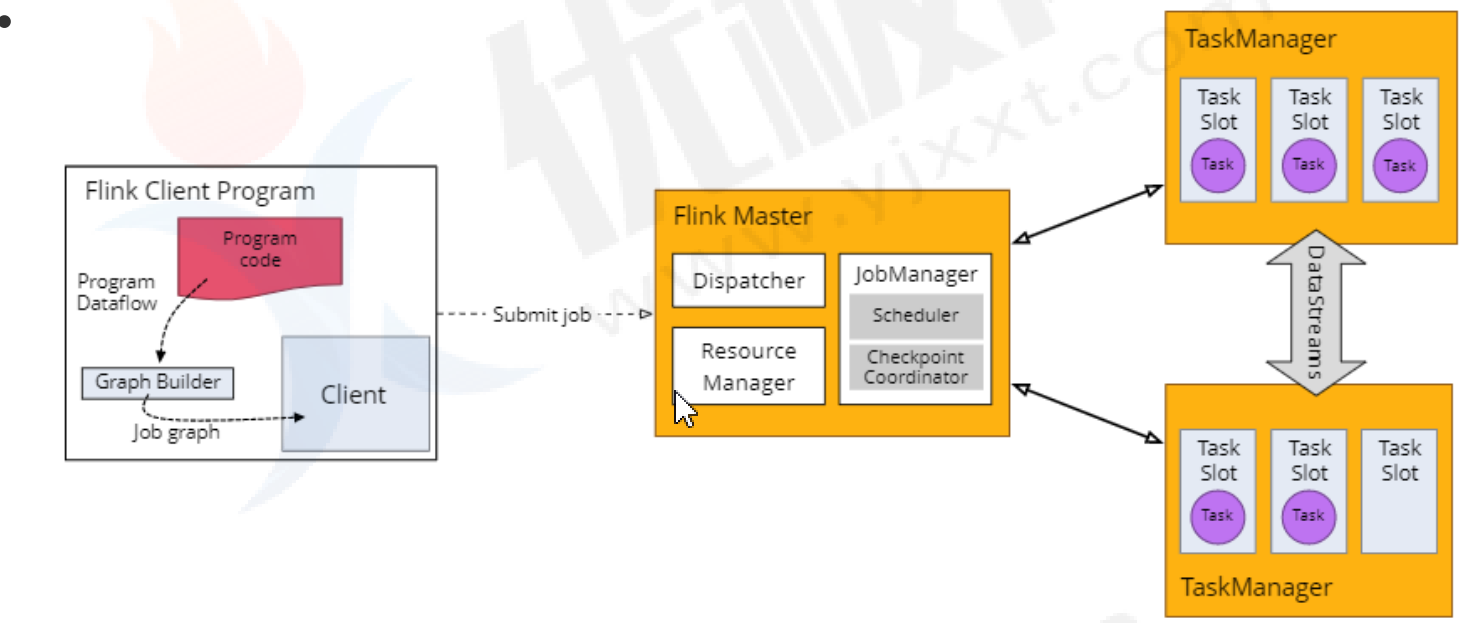
每个Flink作业都要执行环境,流式应用就需要用到StreamExecutionEnvironment。
DS API为你的作业构建一个job graph,附加到 StreamExecutionEnvironment。
调用environment.execute()时此graph打包发送到jobManager上。jobManager对作业并行处理并将其子任务分发给Task Manager来执行。
每个作业的多个并行子任务将在task slot中,如果没有调用execute()方法,应用不会执行。
- Flink运行环境由JobManagers和TaskManagers两个进程组成:
JobManagers:有时也叫Masters,主要协调分布式运行。他们调度任务,协调checkpoint,协调失败任务的恢复。一个Flink集群至少有一台JobManager节点,多台情况下就是一个leader和standby。
TaskManagers:有时也叫Workers,TaskManager主要执行dataflow中的任务tasks,缓存数据以及进行数据流的交换;TaskManager在jvm中以多线程执行任务;TaskManger提供了一定数量的插槽,控制执行任务数;每一个集群至少有一个TaskManger;一个TaskManager可以同时执行多个任务(同一个算子子任务、不同算子、不同应用程序)。
- Flink任务执行计划
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。

2.7、任务并行度
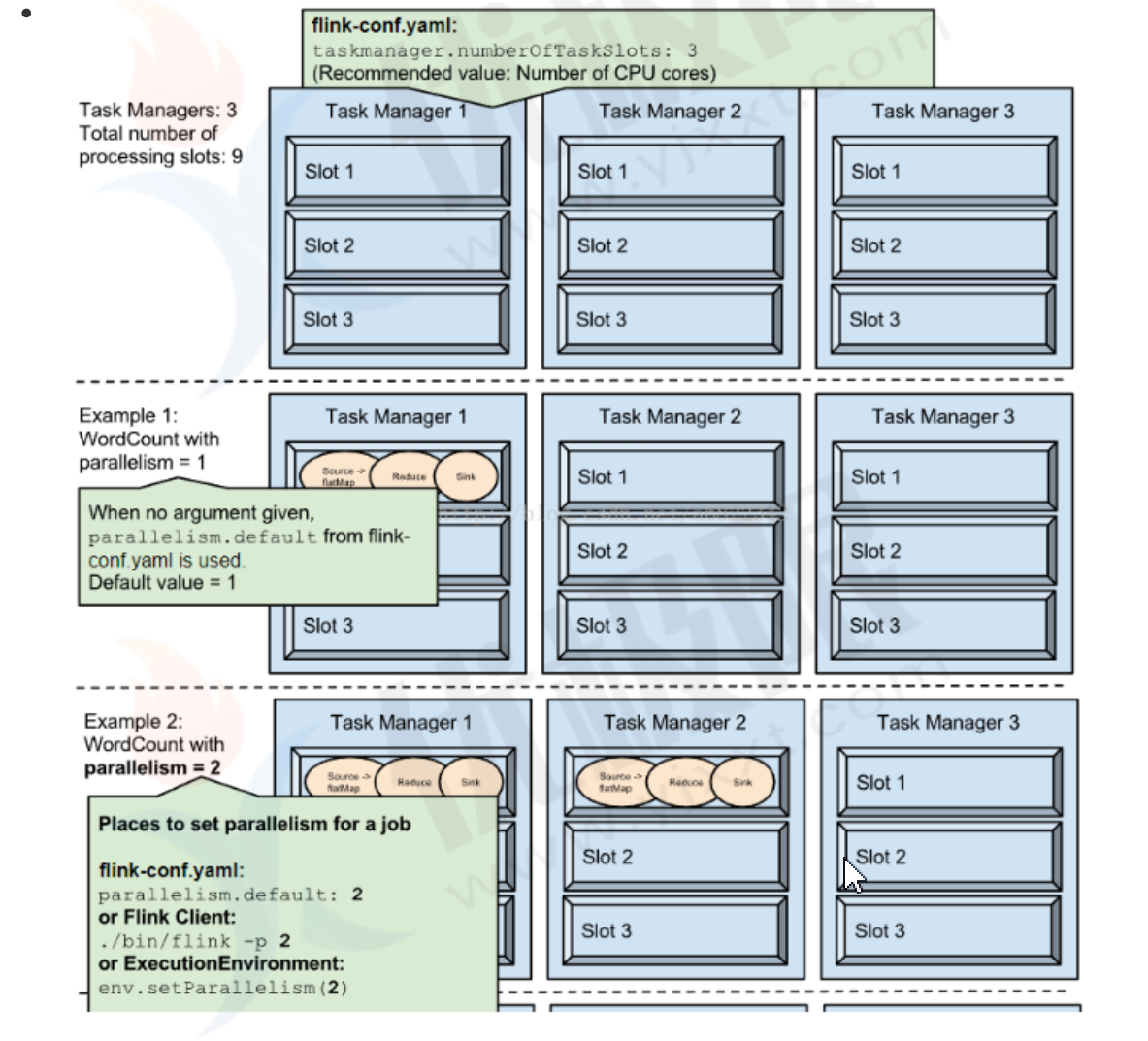
任务在TaskManager上执行占用Task slot个数决定程序的并行度;一个程序中,不同的算子可能具有不同的并行度。
为了提高任务执行效率,同一个数据源执行任务可以在不同的slot中运行。
将tasks调度到slots上,可以让多个 tasks跑在同一个TaskManager内,也就可以是的tasks之间的数据交换更高效。
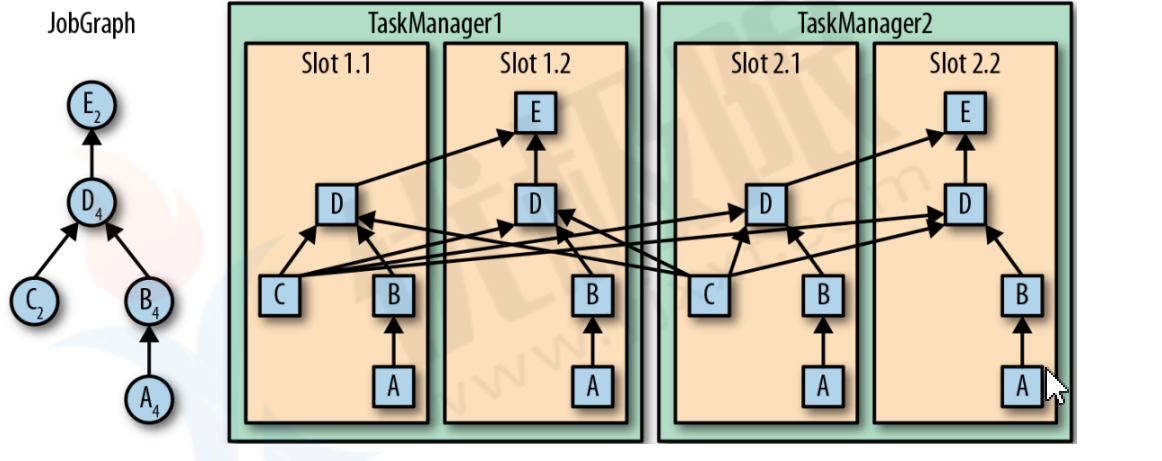
图中AC是数据源,C数据源可以再slot1.1和slot2.1并行运算,E输出数据源在slot1.2和slot2.2并行运算!
- 并行度设置
任务并行度设置分为4个等级:
- 配置文件:通过设置 ${flink_home}/conf/flink-conf.yaml 配置文件中的 parallelism.default`配置 项来定义默认并行度。
- 执行环境级别:在作业代码中设置并行度
- 算子级别:设置特定算子调用setParallelism()方法来定义单个运算符,数据源或数据接收器的并行度。
- 代码实现
public static void main(String[] args) {
//flink执行计划
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//设置执行并行度为2 在转换过程中 每个算子2个并行度运算 只有数据源有1个并行度
//这里设置的并行度是指这个作业并行度是2
//有三种设置并行度方式:1、作业范围的并行度设置 2、配置文件设置并行度,集群生效 3、指定算子设置并行度
environment.setParallelism(2);
DataStreamSource<String> stream = environment.socketTextStream("localhost", 8888);
stream.flatMap((x,coll)->{
String[] split = x.split("\\s+");
for (String s:split){
coll.collect(s);
}
//指定特定算子并行度
},Types.STRING).setParallelism(1).map((x)-> Tuple2.of(x,1), Types.TUPLE(Types.STRING,Types.INT)).keyBy((tup)->tup.f0).sum(1).print();
//默认转换过程中的所有算子都是8个并行度 数据源1个并行度
String plan = environment.getExecutionPlan();
System.out.println(plan);
}
2.8、Flink操作链
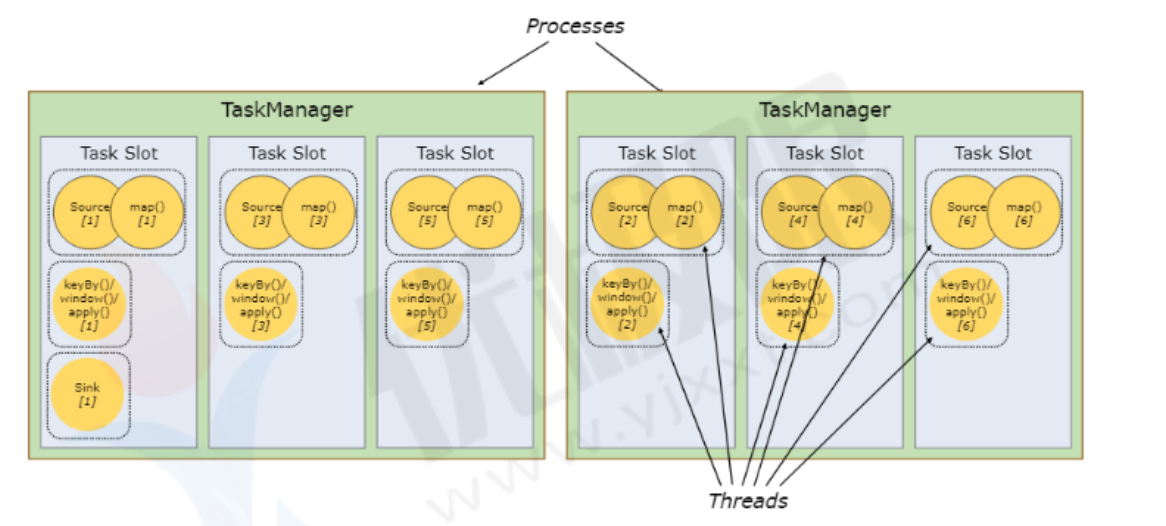
操作链是flink默认开启机制,是为了减少数据shuffle阶段IO传输,提升计算性能,减少了线程间切换和缓冲,降低时延。
条件:上下游算子实例间一对一数据传输,类似于spark中的窄依赖;上下游算子并行度相同;上下游属于槽位共享组;
链条可以在程序中关闭!默认是开启的!
// 当前环境关闭操作链..
environment.disableOperatorChaining();
//单个算子关闭操作链
Stream.disableChaining();
3、Flink三种运行环境
- 批处理运行环境
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
- 流处理运行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
- 流处理环境兼容WebUI
<!--本地运行的webUI-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>1.15.2</version>
</dependency>
StreamExecutionEnvironment ui = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
由于在本地环境,因此在浏览器访问http://localhost:8081.
4、Source类算子
4.1、通用方式
- 基于文本文件获取数据源
//基于File文件获取数据源
environment.readTextFile("data/data.txt");
- 基于socket网络获取数据源
//基于socket获取数据源
DataStreamSource<String> stream = environment.socketTextStream("localhost", 9999);
- 基于集合获取数据源
//基于Collection获取数据源
List<String> list = List.of("11", "22", "33", "44", "55");
DataStreamSource<String> streamSource = environment.fromCollection(list);
4.2、Connector方式
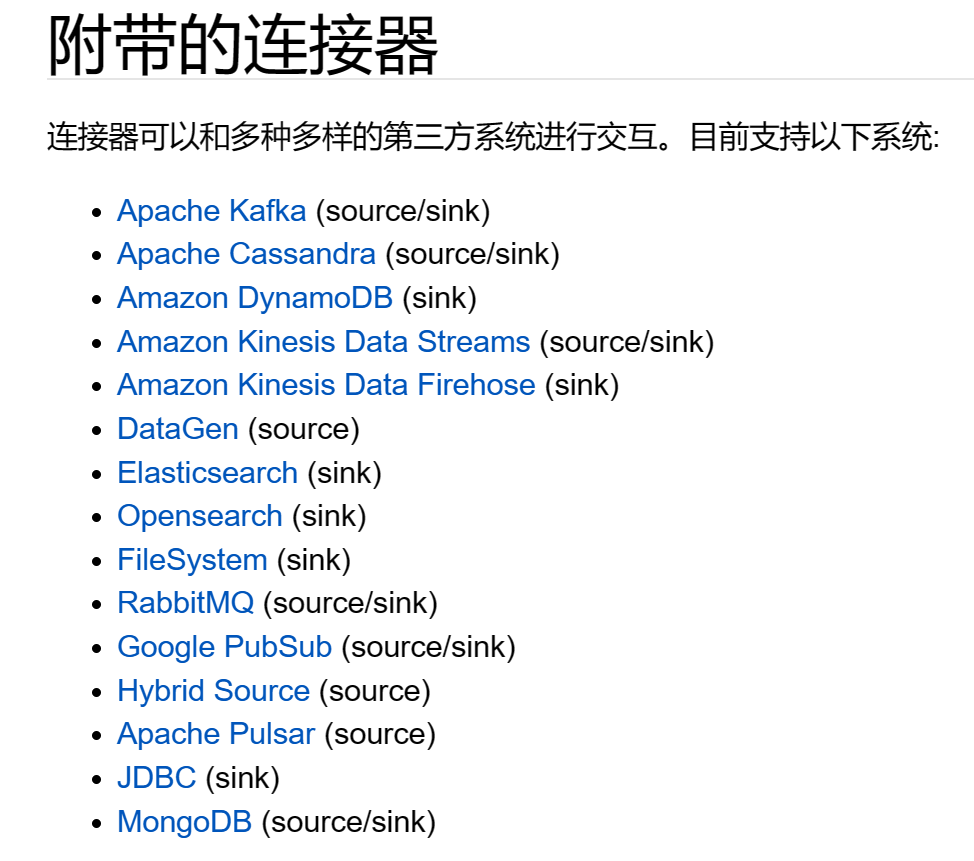
如图Flink连接器支持kafka、ElasticSearch、JDBC等数据源获取!我们通过这些第三方组件获取数据进行计算处理。官网手册:
https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/docs/connectors/datastream/overview/这里只列举从kafka获取数据源,其他的自行查找官方文档!kafka版本在0.10及以上!
注意:从kafka读取数据时,flink设置的并行度应该小于kafka分区数,否则flink在用事件时间处理时会造成数据全部迟到,因为在读取source数据源时,使用forward模式传输,读取最小时间为水位线,当读取到空的并行处理时没有水位线flink没有时间,计算线程阻塞停止。
- 导入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.15.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.15.2</version>
</dependency>
- 创建主题
kafka-topics.sh --zookeeper node1:2181,master:2181,node2:2181/kafka0110 --create --replication-factor 2 --partitions 3 --topic flink_topic
- 创建kafka连接工具类
public class KafkaUtils {
//创建kafka生产者
public static KafkaProducer<String,String> getProducer(){
Properties prop=new Properties();
prop.setProperty("bootstrap.servers","node1:9092,master:9092,node2:9092");
//设置写出数据格式
prop.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
prop.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
//应答方式
prop.put("acks","all");
//错误重试次数
prop.put("retries",2);
//批量写出 16KB为一批数据
prop.put("batch.size",1024*16);
KafkaProducer<String, String> producer = new KafkaProducer<>(prop);
return producer;
}
//创建kafka消费者
public static KafkaConsumer<String,String> getConsumer(String groupId) {
//读取配置文件
Properties properties = new Properties();
properties.put("bootstrap.servers", "node1:9092,master:9092,node2:9092");
//设置groupId
properties.put("group.id", groupId);
//zk超时时间
properties.put("zookeeper.session,timeout.ms", "1000");
//反序列化
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//当消费者第一次消费时,从最低的偏移量开始消费
properties.put("auto.offset.reset", "earliest");
//设置自动提交
properties.put("auto.commit.enable", "true");
//消费者自动提交偏移量的时间间隔 1s
properties.put("auto.commit.interval.ms", "1000");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
return consumer;
}
}
- flink消费
import com.zwf.util.KafkaUtils;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
/**
* @author MrZeng
* @version 1.0
* @date 2023-12-29 16:19
*/
public class StreamDataSource {
public static void main(String[] args) throws Exception {
//启动线程向kafka中发送数据
new Thread(()->{
KafkaProducer<String, String> producer = KafkaUtils.getProducer();
for (int i=0;i<1000;i++){
ProducerRecord<String, String> record = new ProducerRecord<>("flink_topic", "flink_" + i, "kafka_Msg_" + i);
producer.send(record);
try {
Thread.sleep(10);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
//创建环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
//flink连接kafka消费数据
KafkaSource<String> connector = KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setTopics("flink_topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
//读取kafka数据源
DataStreamSource<String> streamSource = environment.fromSource(connector, WatermarkStrategy.noWatermarks(), "kafka Source");
streamSource.map(w->w.toUpperCase()).print();
//执行kafka 流处理
environment.execute();
}
}
4.3、自定义Source数据源
自定义数据源连接器需要实现
ParallelSourceFunction接口或者继承接口实现类RichParallelSourceFunction实现接口的方式读取源数据会设置多个并行度会造成数据重复消费,就需要继承接口的实现去获取上下文环境进行控制。
- 原始方法
package com.zwf.sourceconnector;
import org.apache.commons.io.FileUtils;
import org.apache.flink.api.common.functions.IterationRuntimeContext;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.io.File;
import java.util.List;
import java.util.Objects;
/**
* @author MrZeng
* @version 1.0
* @date 2023-12-29 17:22
*/
public class CustomerConnector {
public static void main(String[] args) throws Exception {
//获取flink环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//获取自定义数据源 设置并行度为2 会重复读取消费数据
DataStreamSource<String> source = environment.addSource(new CustomerDataSource("data/data.txt")).setParallelism(2);
//数据转大写 并打印输出
source.map(x->x.concat("==道德经==")).print();
environment.execute();
}
}
//最原始自定义数据源方式
class CustomerDataSource implements ParallelSourceFunction<String>{
private String path;
public CustomerDataSource(String path) {
this.path = path;
}
@Override
public void run(SourceContext<String> ctx) throws Exception {
List<String> list = FileUtils.readLines(new File(path), "UTF-8");
for(String data:list){
ctx.collect(data);
}
}
@Override
public void cancel() {
}
}
- 获取上下文环境控制重复读取
public class CustomerConnector {
public static void main(String[] args) throws Exception {
//获取flink环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//获取自定义数据源 设置并行度为2 会重复读取消费数据
DataStreamSource<String> source = environment.addSource(new CustomerDataSource("data/data.txt")).setParallelism(2);
//数据转大写 并打印输出
source.map(x->x.concat("==道德经==")).print();
environment.execute();
}
}
//第二种法继承自定义数据源的RichParallelSourceFunction获取上下文环境
class CustomerRichParallel extends RichParallelSourceFunction<String>{
private String path;
public CustomerRichParallel(String path) {
this.path = path;
}
@Override
public void run(SourceContext<String> ctx) throws Exception {
//获取并行度数
int number = this.getRuntimeContext().getNumberOfParallelSubtasks();
//获取并行度ID
int parallelId = this.getRuntimeContext().getIndexOfThisSubtask();
List<String> list = FileUtils.readLines(new File(path), "UTF-8");
for (String v:list){
//把多个并行度相同的数据去重
if(Math.abs(Objects.hash(v)%number)==parallelId) {
ctx.collect(v);
}
}
}
@Override
public void cancel() {
}
@Override
public RuntimeContext getRuntimeContext() {
return super.getRuntimeContext();
}
@Override
public IterationRuntimeContext getIterationRuntimeContext() {
return super.getIterationRuntimeContext();
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
@Override
public void close() throws Exception {
super.close();
}
}
5、Transform算子
- map
映射算子,把集合中每个元素取出来后进行处理后,再返回!

keybySource.map(x-> Tuple2.of(1,x), Types.TUPLE(Types.INT,Types.STRING)).keyBy(x->x.f1).sum(0).print();
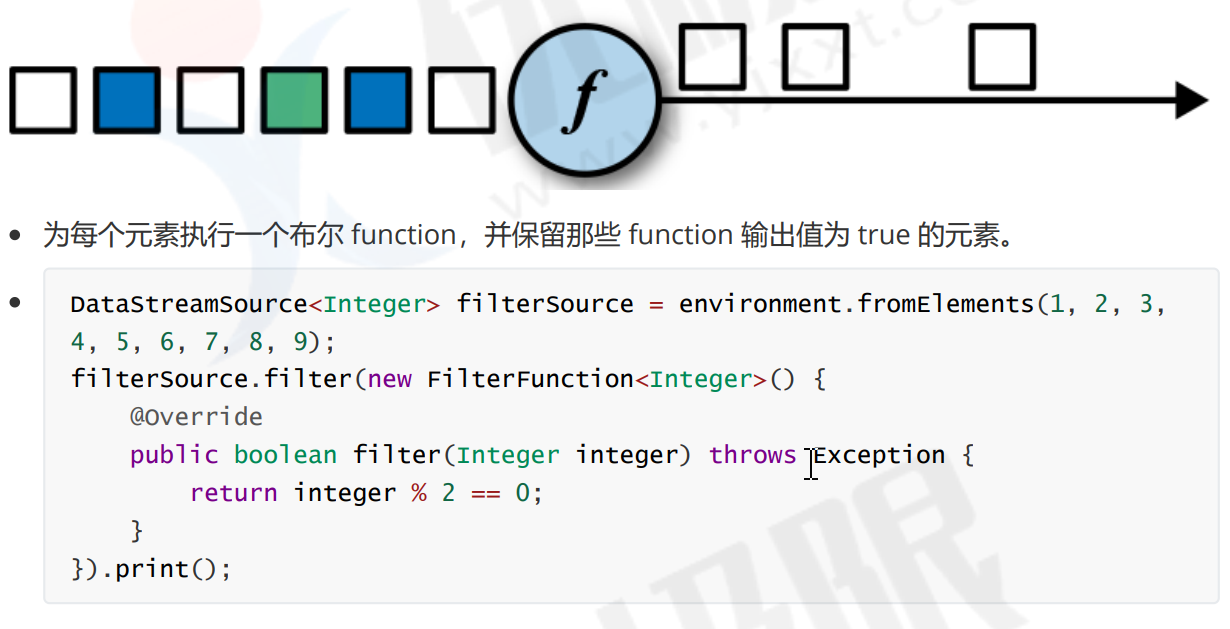
- filter
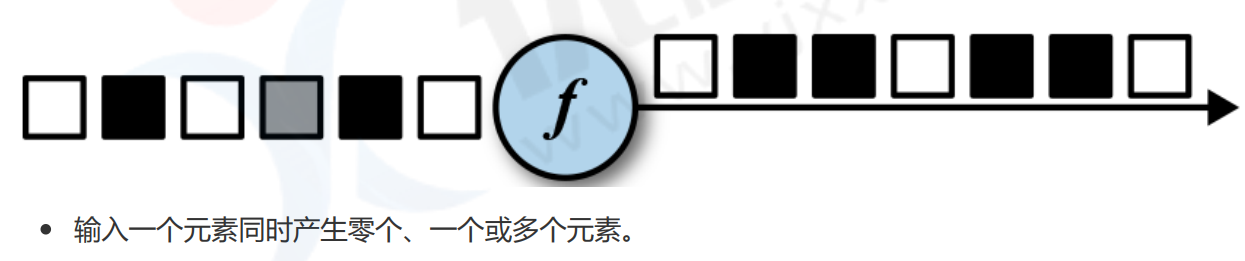
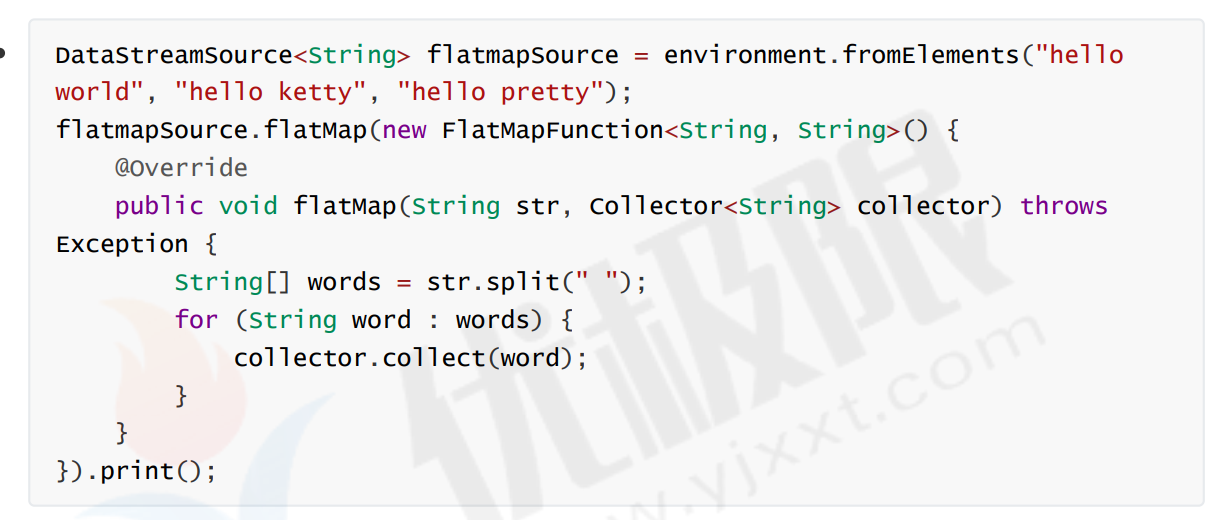
- flatMap
- keyBy
在逻辑上将流划分为不想交的分区。具有相同key的记录都分配到同一个分区。在内部,keyBy()是通过哈希分区实现的。
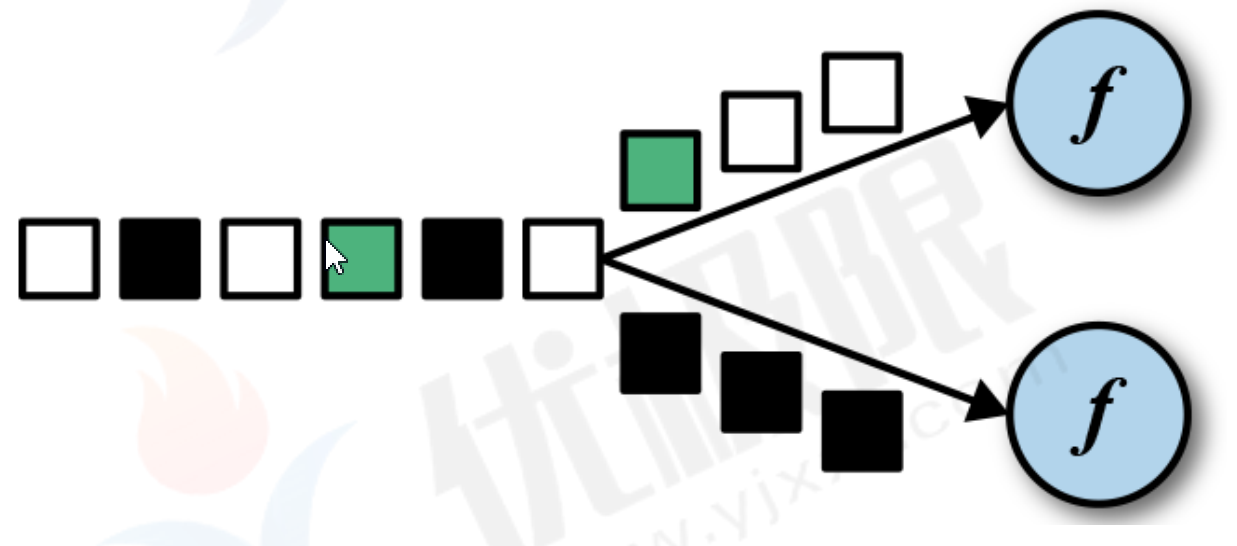
DataStreamSource<String> keybySource = environment.fromElements("aaaa", "bbb", "ccc", "aaaa", "ddd");
keybySource.map(x-> Tuple2.of(1,x), Types.TUPLE(Types.INT,Types.STRING)).keyBy(x->x.f1).sum(0).print();
- aggregation函数
滚动聚合算子由 KeyedStream 调用,并生成一个聚合以后的DataStream
滚动聚合算子是多个聚合算子的统称, 有 sum、 min、 minBy、 max、 maxBy;
常见聚合方法:
- sum():在输入流上对指定的字段做滚动相加操作。
- min():在输入流上对指定的字段求最小值。
- max():在输入流上对指定的字段求最大值。
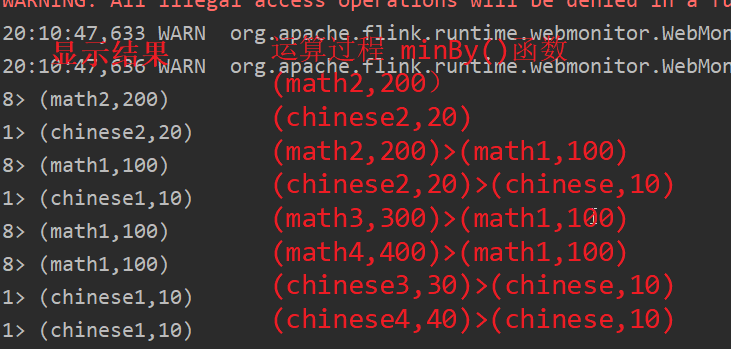
- minBy():在输入流上针对指定字段求最小值,并返回最小值字段所在的那条数据。
- maxBy():在输入流上针对指定字段求最大值,并返回最大值字段所在的那条数据。
- sum()使用
//创建flink环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
List<Tuple2<String, Integer>> list = new ArrayList<>();
list.add(new Tuple2<>("math2", 200));
list.add(new Tuple2<>("chinese2", 20));
list.add(new Tuple2<>("math1", 100));
list.add(new Tuple2<>("chinese1", 10));
list.add(new Tuple2<>("math4", 400));
list.add(new Tuple2<>("chinese4", 40));
list.add(new Tuple2<>("math3", 300));
list.add(new Tuple2<>("chinese3", 30));
DataStreamSource<Tuple2<String, Integer>> source = environment.fromCollection(list);
source.keyBy(x -> x.f0.length()).sum(1).print();
environment.execute();
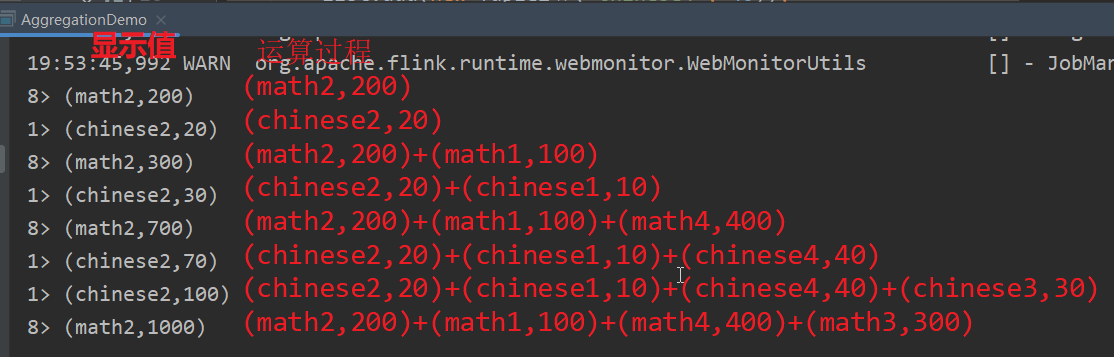
- min()使用 max()同理
source.keyBy(x -> x.f0.length()).min(1).print();
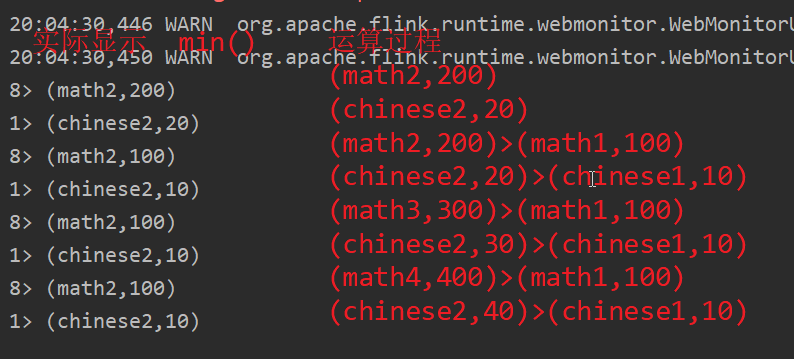
- minBy()使用,maxBy()同理
source.keyBy(x -> x.f0.length()).minBy(1).print();
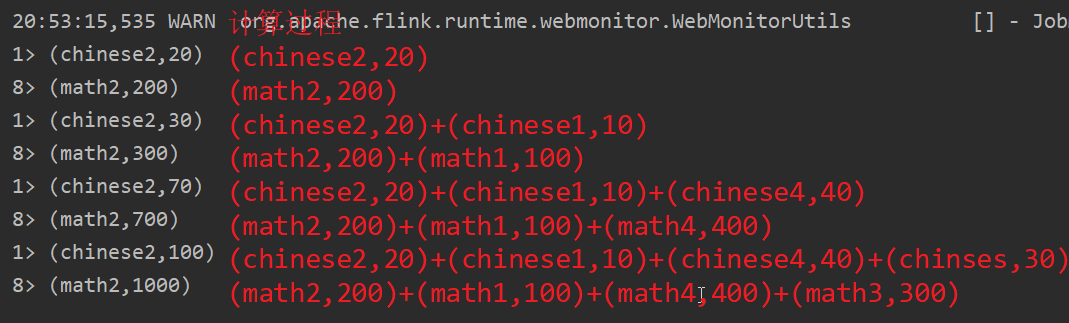
- reduce()
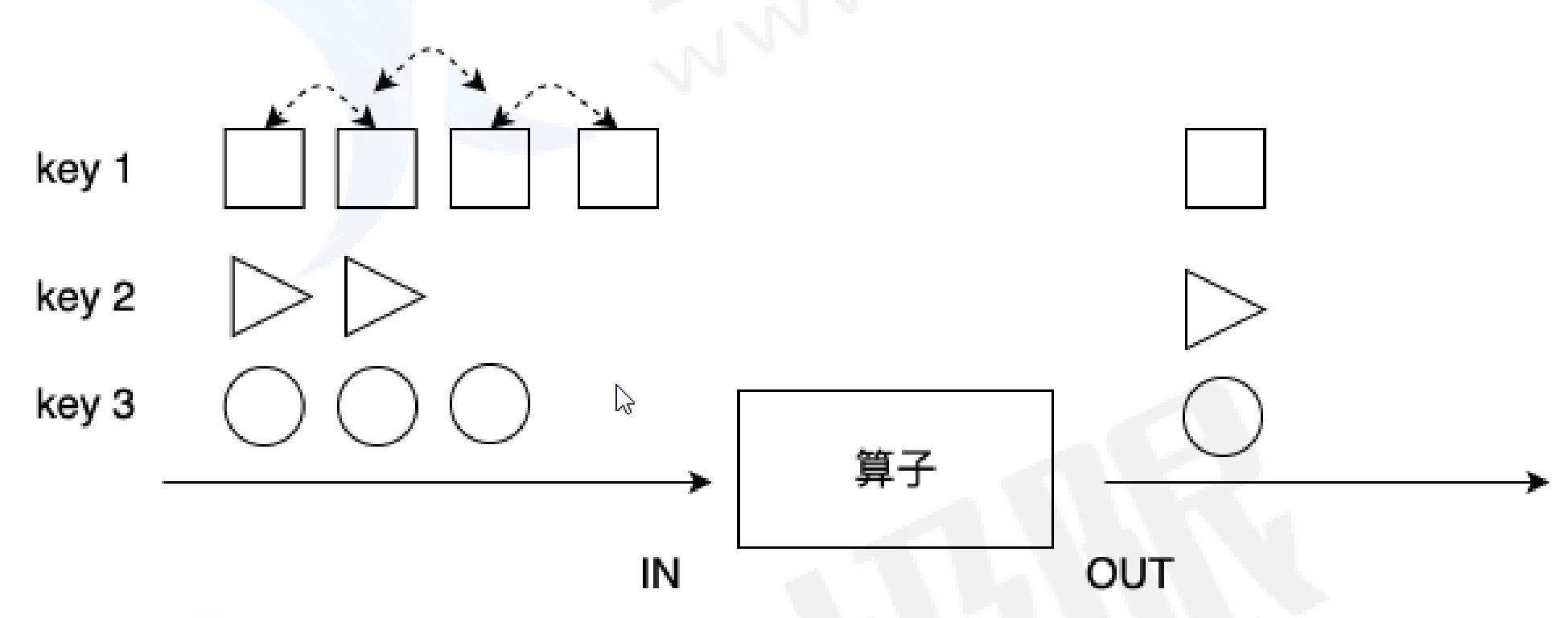
在相同key 的数据流上“滚动”执行 reduce。将当前元素与最后一次 reduce 得到的值组合然后输出新值。
//创建flink环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
List<Tuple2<String, Integer>> list = new ArrayList<>();
list.add(new Tuple2<>("math2", 200));
list.add(new Tuple2<>("chinese2", 20));
list.add(new Tuple2<>("math1", 100));
list.add(new Tuple2<>("chinese1", 10));
list.add(new Tuple2<>("math4", 400));
list.add(new Tuple2<>("chinese4", 40));
list.add(new Tuple2<>("math3", 300));
list.add(new Tuple2<>("chinese3", 30));
DataStreamSource<Tuple2<String, Integer>> source = environment.fromCollection(list);
source.keyBy(x -> x.f0.length()).reduce((x,y)-> new Tuple2<>(x.f0,(x.f1+y.f1))).print();
environment.execute();
- Iterate函数算子

//Iterate 迭代器使用 用于循环处理数据流
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
//数据源
DataStream<String> source = environment.fromElements("苹果,101", "桃子,51", "葡萄,202");
IterativeStream<Tuple3<String, Integer, Integer>> iterateStream = source.map((x) -> {
String[] split = x.split(",");
return Tuple3.of(split[0], Integer.parseInt(split[1]), 0);
}, Types.TUPLE(Types.STRING, Types.INT, Types.INT)).iterate();
//迭代体
SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> iterativeBody = iterateStream.map((x) -> {
x.f1 -= 10;
x.f2++;
return x;
}, Types.TUPLE(Types.STRING, Types.INT, Types.INT));
//迭代条件
SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> filter = iterativeBody.filter(x -> x.f1 > 10);
iterateStream.closeWith(filter);
//不满足迭代条件的
SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> output = iterativeBody.filter(x -> x.f1 <= 10);
output.print("不满足条件的数据:");
//运行环境
environment.execute();
- connect()函数,可以将两组数据类型不一样,元素个数不一样的数据联合一起。
- union()函数,可以将两组数据类型一样,元素个数一样的数据联合一起,并且不会去重。
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> data1 = environment.fromElements("Yes", "Yes", "Yes", "No", "No");
DataStreamSource<Double> data2 = environment.fromElements(40.3D, 20.6D, 25D, 32.3D, 37.6D);
ConnectedStreams<String,Double> connect = data1.connect(data2);
connect.map(new CoMapFunction<String, Double, String>() {
@Override
public String map1(String value) throws Exception {
if(value.equals("Yes")){
return "报警器安全!";
}
return "报警器危险!";
}
@Override
public String map2(Double value) throws Exception {
if(value.doubleValue()>30.0){
return "温度感应器危险!";
}
return "温度感应器安全!";
}
}).print();
environment.execute();
6、Flink Sink类算子
把计算好的结果写入哪个设备,普通组件:File、Console、Socket(套节字);Connector:kafka、jdbc等。
- 写入txt/csv/文件中或者控制台中,socket套接字!一般用于测试环境。
//文本字符传入文本文件中
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//默认是8个并行度 会出现生成8个文本文件,但是可能会出现有的文本文件没有字符!
//防止重复设置一个并行度
environment.setParallelism(1);
List<Tuple2<String, String>> lists = new ArrayList<>();
lists.add(new Tuple2<>("赵欣", "18"));
lists.add(new Tuple2<>("李四", "22"));
lists.add(new Tuple2<>("王五", "23"));
lists.add(new Tuple2<>("赵六", "18"));
lists.add(new Tuple2<>("田七", "16"));
lists.add(new Tuple2<>("朱八", "14"));
lists.add(new Tuple2<>("甜甜", "13"));
DataStreamSource<Tuple2<String, String>> source = environment.fromCollection(lists);
//存为csv文件必须是Tuple类型 否则会报错!
source.map(x->x,Types.TUPLE(Types.STRING,Types.STRING)).writeAsCsv("data/new"+System.currentTimeMillis()+".csv");
// 保存文本文件 可以不用是Tuple类型
// source.writeAsText("data/new.txt");
//打印控制台
source.print();
environment.execute();
- 使用套接字上传到服务器
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//默认是8个并行度 会出现生成8个文本文件,但是可能会出现有的文本文件没有字符!
//防止重复设置一个并行度
environment.setParallelism(1);
List<Tuple2<String, String>> lists = new ArrayList<>();
lists.add(new Tuple2<>("赵欣", "18"));
lists.add(new Tuple2<>("李四", "22"));
lists.add(new Tuple2<>("王五", "23"));
lists.add(new Tuple2<>("赵六", "18"));
lists.add(new Tuple2<>("田七", "16"));
lists.add(new Tuple2<>("朱八", "14"));
lists.add(new Tuple2<>("甜甜", "13"));
DataStreamSource<Tuple2<String, String>> source = environment.fromCollection(lists);
//输出道服务器中
source.writeToSocket("localhost", 23641, new SerializationSchema<Tuple2<String, String>>() {
@Override
public byte[] serialize(Tuple2<String, String> element) {
try {
return element.toString().getBytes("GBK");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException(e);
}
}
});
environment.execute();
使用nc模拟测试
把数据写入Connector中,包括jdbc、kafka等。
<!--flink与kafka整合-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.15.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.15.2</version>
</dependency>
- CMD监听socket端口写数据
//把数据写入kafka
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
DataStreamSource<String> streamSource = environment.socketTextStream("localhost", 6379);
//设置kafka写出配置
KafkaSink<String> build = KafkaSink.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("flink_topic")
.setKeySerializationSchema(new SimpleStringSchema())
.setValueSerializationSchema(new SimpleStringSchema())
.build()
).setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
streamSource.sinkTo(build);
environment.execute();
}
- 把计算数据写入JDBC连接器
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>1.15.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
- Jdbc建表语句
create table if not exists scott.Books(
id varchar(50),
title varchar(50),
author varchar(50),
price double,
qty Int
)
package com.zwf.sink;
import org.apache.commons.lang3.RandomStringUtils;
import org.apache.commons.lang3.RandomUtils;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.UUID;
/**
* @author MrZeng
* @version 1.0
* @date 2023-12-30 21:10
*/
class Book{
private String id;
private String title;
private String author;
private Double price;
private Integer qty;
public Book(String id, String title, String author, Double price, Integer qty) {
this.id = id;
this.title = title;
this.author = author;
this.price = price;
this.qty = qty;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
public Integer getQty() {
return qty;
}
public void setQty(Integer qty) {
this.qty = qty;
}
@Override
public String toString() {
return "Book{" +
"id=" + id +
", title='" + title + '\'' +
", author='" + author + '\'' +
", price=" + price +
", qty=" + qty +
'}';
}
}
public class JdbcSinkDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Book> source = environment.fromElements(
new Book(RandomStringUtils.randomAlphabetic(8), "<<java从入门到精通>>", "詹姆斯.高斯林", 19.26D, 11)
, new Book(RandomStringUtils.randomAlphabetic(8), "<<python从入门到精通>>", "詹姆斯.高斯林", 23.12D, 20)
, new Book(RandomStringUtils.randomAlphabetic(8), "<<c++从入门到精通>>", "詹姆斯.高斯林", 63.56D, 26)
, new Book(RandomStringUtils.randomAlphabetic(8), "<<scala从入门到精通>>", "詹姆斯.高斯林", 58.3D, 18));
source.addSink(JdbcSink.sink("insert into Books (id, title, author, price, qty) values (?,?,?,?,?)",(ps, t)->{
ps.setString(1,t.getId());
ps.setString(2,t.getTitle());
ps.setString(3,t.getAuthor());
ps.setDouble(4,t.getPrice());
ps.setInt(5,t.getQty());
//批数据为1条就提交 默认是5000条 否则数据不会立即插入数据库 要挤攒到5000条
//才能把数据插入数据库
},new JdbcExecutionOptions.Builder().withBatchSize(1).build()
,new JdbcConnectionOptions
.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://master:3306/scott?useUnicode=true&characterEncoding=UTF-8&serverTimeZone=UTC")
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUsername("root")
.withPassword("Root@123456.")
.build()));
environment.execute();
}
}
自定义Sink函数
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>5.3.21</version>
</dependency>
- java代码
package com.zwf.sink;
import org.apache.commons.io.FileUtils;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.springframework.util.DigestUtils;
import java.io.File;
import java.util.ArrayList;
/**
* @author MrZeng
* @version 1.0
* @date 2023-12-30 22:17
*/
public class CustomSinkDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment =
StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(2);
//操作数据
ArrayList<String> list = new ArrayList<>();
list.add("君子周而不比,小人比而不周");
list.add("君子喻于义,小人喻于利");
list.add("君子怀德,小人怀土;君子怀刑,小人怀惠");
list.add("君子欲讷于言而敏于行");
list.add("君子坦荡荡,小人长戚戚");
DataStreamSource<String> source =
environment.fromCollection(list);
source.addSink(new CustomSinkFunction("data/" +
System.currentTimeMillis()+".txt"));
environment.execute();
}
}
class CustomSinkFunction implements SinkFunction<String> {
private File file;
public CustomSinkFunction(String path) {
file = new File(path);
}
@Override
public void invoke(String value, Context context) throws Exception {
//写出数据
String s = DigestUtils.md5DigestAsHex(value.getBytes("UTF-8"))+"\t\n";
FileUtils.writeStringToFile(file,s,"UTF-8",true);
}
}
7、分区类算子
- 分区算子:用于指定上游 task 的各并行 subtask 与下游 task 的 subtask 之间如何传输数据。
Global(): 分区器会将上游所有元素都发送到下游的第一个算子实例上(SubTask Id=0)。
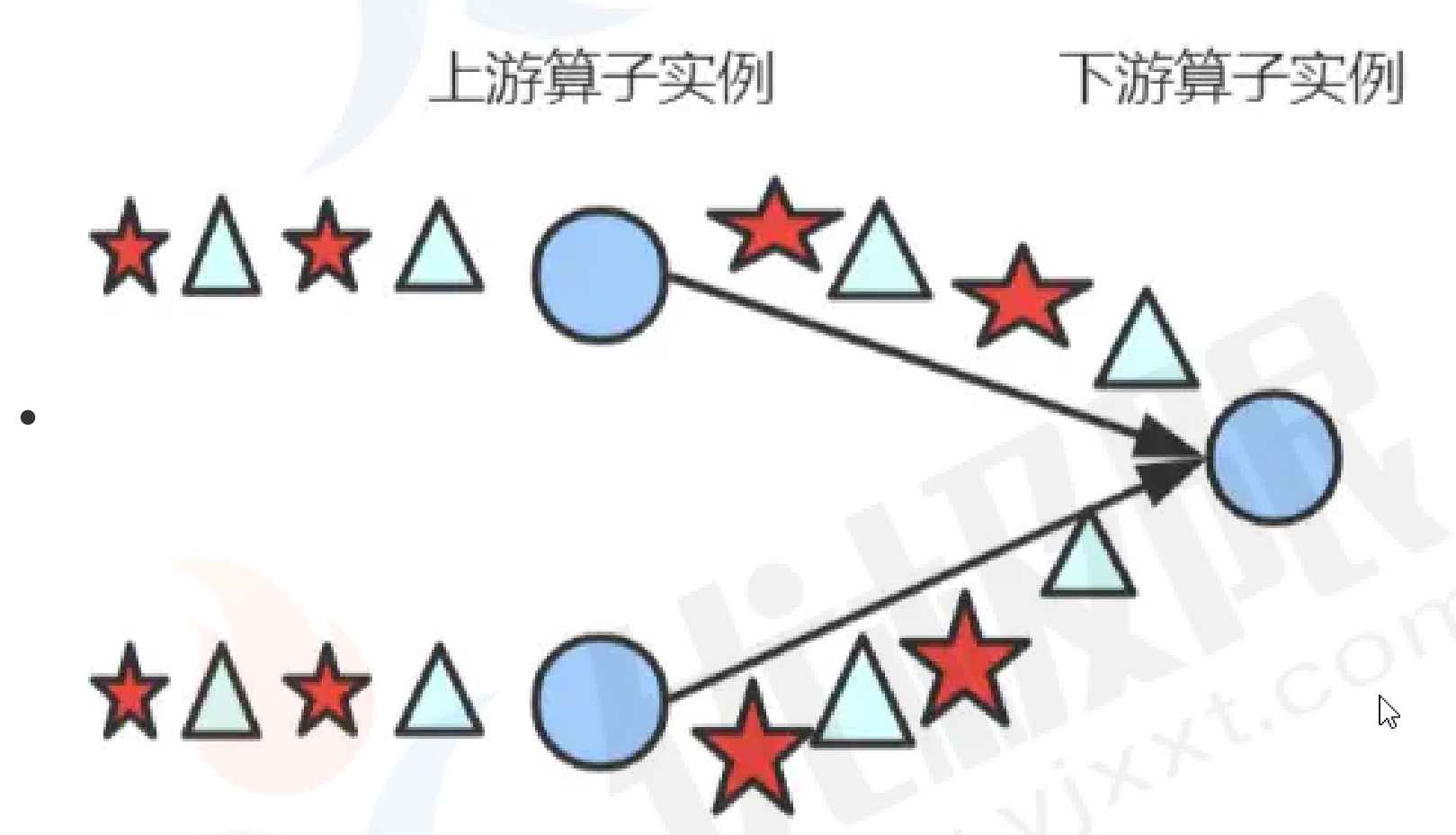
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(2);
DataStreamSource<String> source = environment.readTextFile("data/data.txt").setParallelism(1);
//把所有的数据拉取到第一个并行度上
source.global().print("globalFunction");
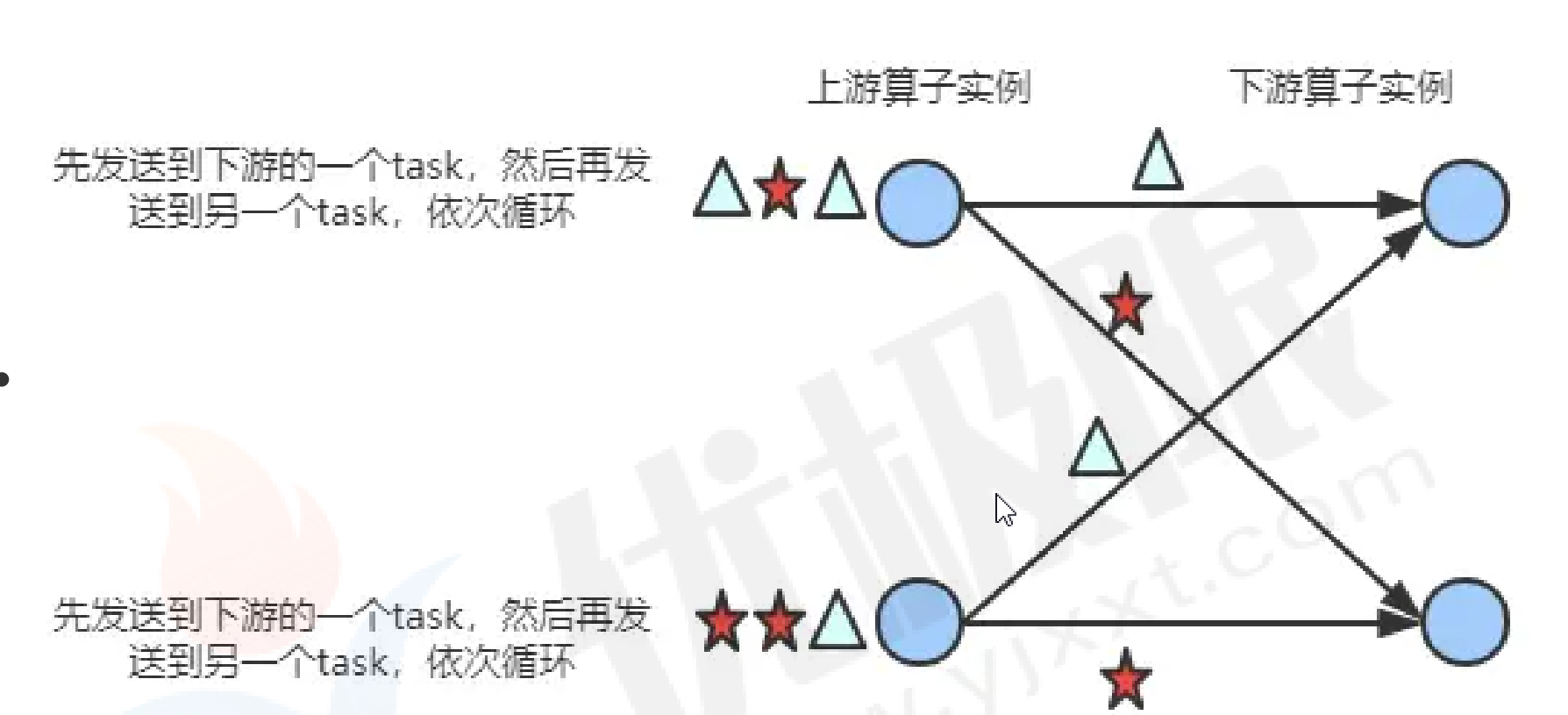
reblance():上游轮询把数据分发给下游!
source.rebalance().print("rebalance").setParallelism(4);
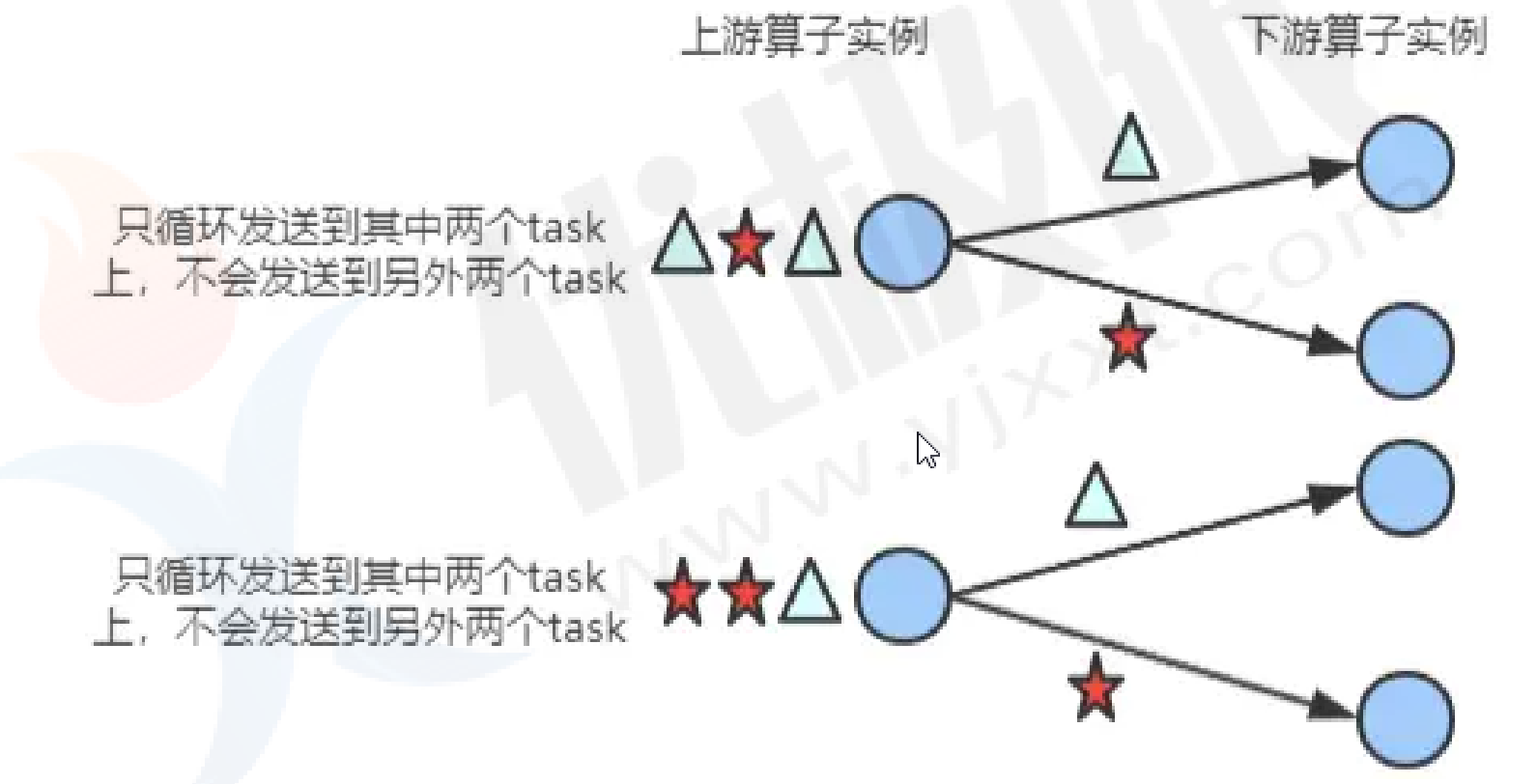
rescale():上游按照比例把数据发送给下游
- 若上游并行度是2,下游是4,则上游一个并行度以循环的方式将记录输出到下游的两个并行 度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。
source.rescale().print("rescale").setParallelism(2);
shuffle():上游取出一个数据后随机分发给下游
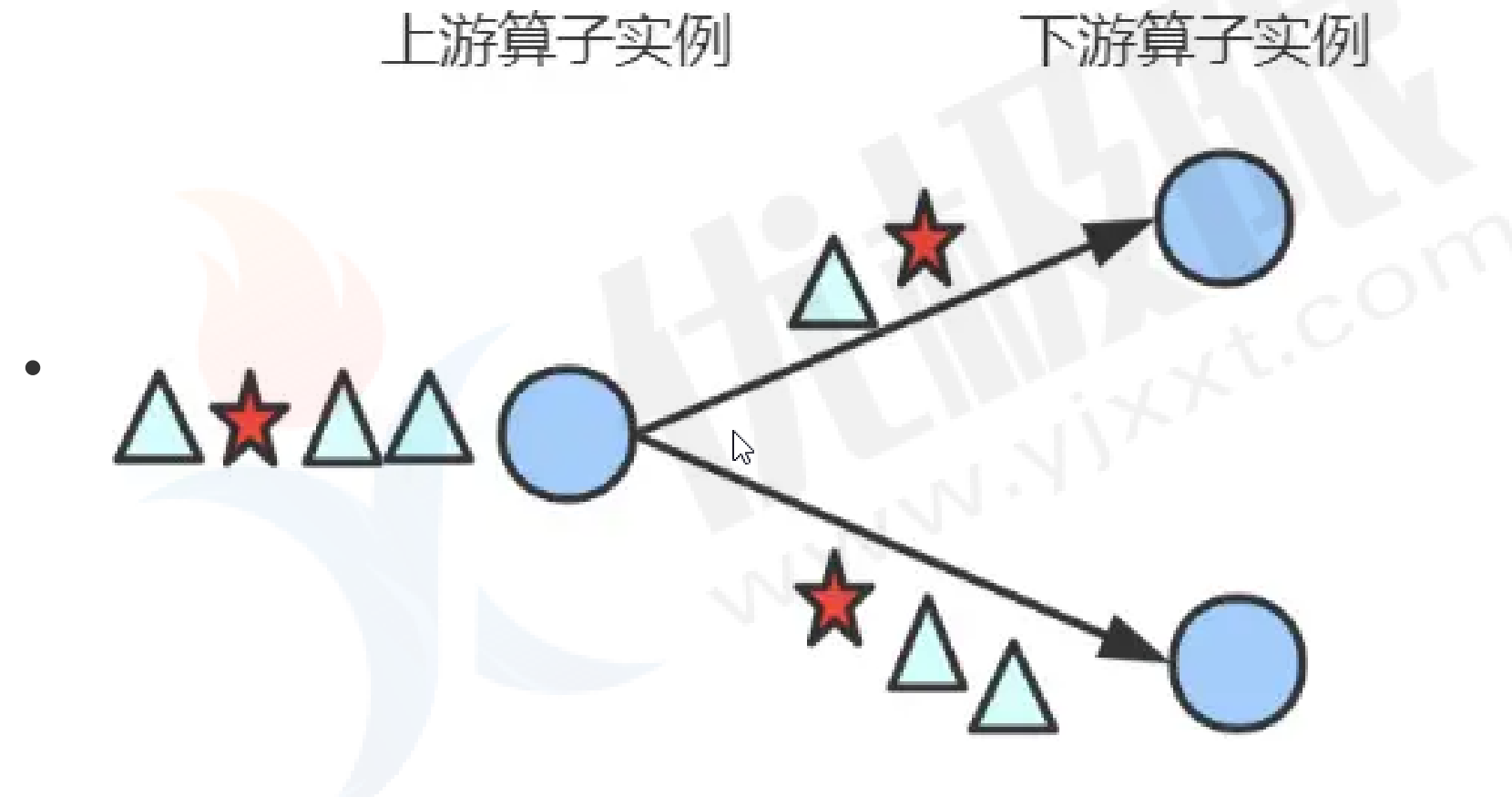
source.shuffle().print("shuffle").setParallelism(2);
broadcast():上游所有数据广播给下游所有分区,也就是说下游每个分区都可以获取上游的全量数据,一般用于大小表join操作!
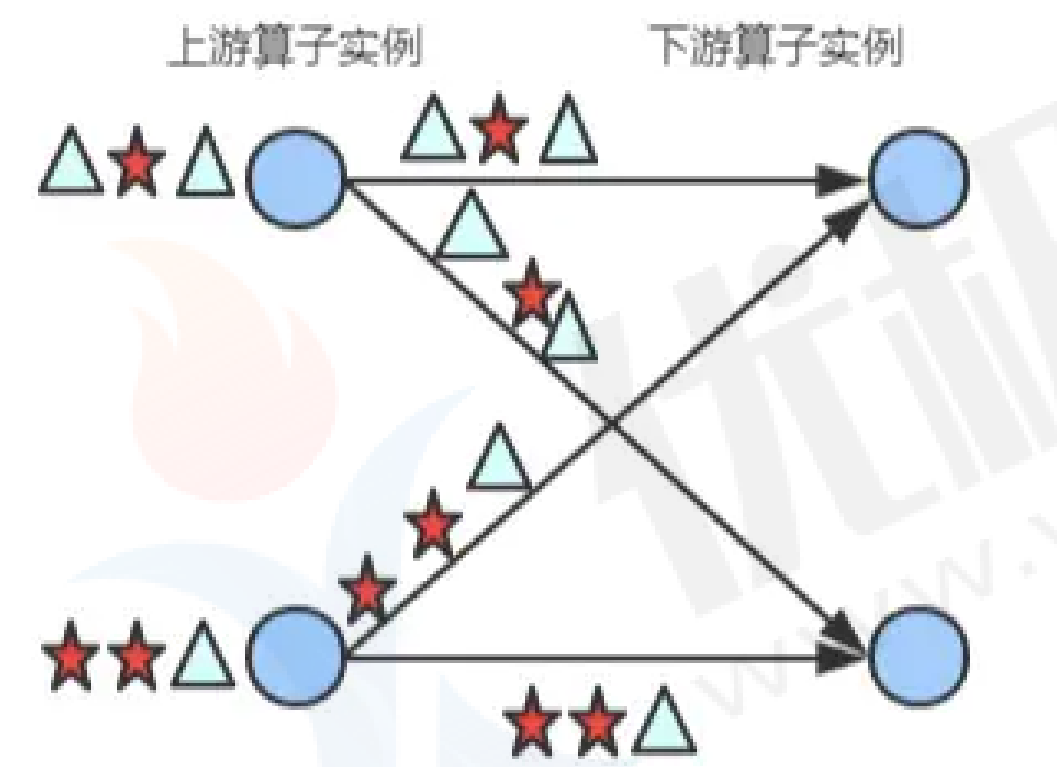
source.broadcast().print("broadcast==>").setParallelism(4);
forward():上游数据分发给下游每个分区,必须要求上下游分区数一致,当两个数据可以组成操作链时,默认使用操作链方式进行发送!
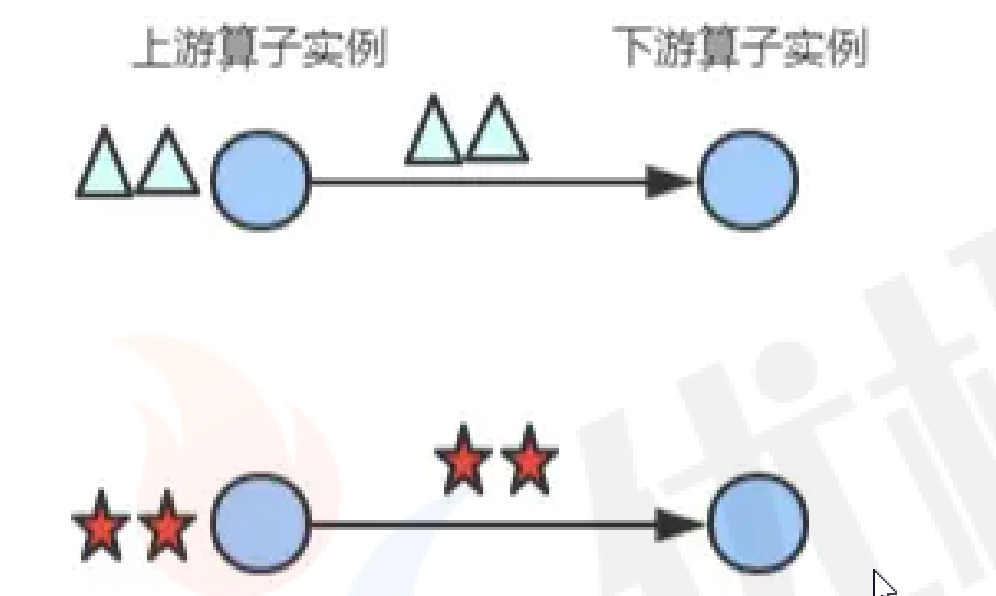
keyby(): 按照key值的hash值对分区数取余进行分发给下游分区。
source.keyBy(x->x).print("keyBy分区器:").setParallelism(4);
partitionCustom():自定义分区器,自定义设置分区器分发规则。
source.partitionCustom(new Partitioner<String>() {
@Override
public int partition(String key, int numPartitions) {
return Math.abs(key.hashCode())%numPartitions;
}
}, new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
return value;
}
}).print("自定义分区器").setParallelism(4);
8、Flink Process Function
转换算子是无法访问事件的时间戳信息和水位线信息的,而这在一些应用场景下,极为重要。
ProcessFunction 函数是低阶流处理算子,可以访问流应用程序所有(非循环)基本构建块:事件(数据元素)、状态(容错和一致性)、定时器(事件时间和处理时间)
- 函数分类
Flink提供了8个不同的处理函数:
- ProcessFunction:最基本的处理函数,基于 DataStream 直接调用.process()时作为参数传入。
- KeyedProcessFunction:对流按键分区后的处理函数,基于 KeyedStream 调用.process()时作为参数传入。要想使用 定时器,比如基于 KeyedStream。
- ProcessWindowFunction:开窗之后的处理函数,也是全窗口函数的代表。基于 WindowedStream 调用.process()时作 为参数传入。
- ProcessAllWindowFunction:同样是开窗之后的处理函数,基于 AllWindowedStream 调用.process()时作为参数传入。
- CoProcessFunction:合并(connect)两条流之后的处理函数,基于 ConnectedStreams 调用.process()时作为参 数传入。关于流的连接合并操作。
- ProcessJoinFunction:间隔连接(interval join)两条流之后的处理函数,基于 IntervalJoined 调用.process()时作 为参数传入。
- BroadcastProcessFunction:广播连接流处理函数,基于 BroadcastConnectedStream 调用.process()时作为参数传入。 这里的“广播连接流”BroadcastConnectedStream,是一个未 keyBy 的普通 DataStream 与 一个广播流(BroadcastStream)做连接(conncet)之后的产物。
- KeyedBroadcastProcessFunction:按键分区的广播连接流处理函数,同样是基于 BroadcastConnectedStream 调用.process() 时作为参数传入。与 BroadcastProcessFunction 不同的是,这时的广播连接流,是一个 KeyedStream与广播流(BroadcastStream)做连接之后的产物。
- WordCount案例
package com.zwf.processFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
/**
* @author MrZeng
* @version 1.0
* @date 2024-01-02 11:13
*/
public class WordCount {
public static void main(String[] args) throws Exception {
//使用flink最底层API开发 wordcount案例代码
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.readTextFile("data/data.txt");
environment.setParallelism(1);
//处理数据
source.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String line, ProcessFunction<String, String>.Context ctx, Collector<String> out) throws Exception {
String[] split = line.split("\\s+");
for(String s:split) {
out.collect(s);
}
}
}).process(new ProcessFunction<String, Tuple2<String,Integer>>() {
@Override
public void processElement(String word, ProcessFunction<String, Tuple2<String, Integer>>.Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
out.collect(Tuple2.of(word,1));
}
}).keyBy(w->w, Types.TUPLE(Types.STRING,Types.INT)).process(new KeyedProcessFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>>() {
private ValueState<Integer> valueState;
@Override
public void open(Configuration parameters) throws Exception{
//设置状态初始值
valueState= getRuntimeContext().getState(new ValueStateDescriptor<Integer>("word-count",Integer.class,0));
}
@Override
public void processElement(Tuple2<String, Integer> value, KeyedProcessFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>>.Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
//获取初始值
Integer countV = valueState.value();
//把同一个key的值进行累加 并更新状态初始值
countV += value.f1;
valueState.update(countV);
//输出数据
out.collect(Tuple2.of(value.f0, countV));
}
}).print();
environment.execute();
}
}
- 侧输出
process function可以通过Context对象发射一个事件到一个或者多个side outputs。
一个side output可以定义为OutputTag[X]对象,X是输出流的数据类型。
process function的side outputs功能可以产生多条流,并且这些流的数据类型可以不一样。
package com.zwf.processFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
/**
* @author MrZeng
* @version 1.0
* @date 2024-01-02 11:13
*/
public class WordCount {
public static void main(String[] args) throws Exception {
//使用flink最底层API开发 wordcount案例代码
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.readTextFile("data/data.txt");
environment.setParallelism(1);
//创建侧输出流标签
OutputTag<String> tag1 = new OutputTag<>("sideOutput1"){};
OutputTag<Integer> tag2 = new OutputTag<>("sideOutput2"){};
//处理数据
SingleOutputStreamOperator<Tuple2<String, Integer>> process = source.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String line, ProcessFunction<String, String>.Context ctx, Collector<String> out) throws Exception {
String[] split = line.split("\\s+");
for (String s : split) {
out.collect(s);
}
}
}).process(new ProcessFunction<String, Tuple2<String, Integer>>() {
@Override
public void processElement(String word, ProcessFunction<String, Tuple2<String, Integer>>.Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
//侧输出流
ctx.output(tag1, word);
out.collect(Tuple2.of(word, 1));
}
}).keyBy(w -> w, Types.TUPLE(Types.STRING, Types.INT)).process(new KeyedProcessFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>>() {
private ValueState<Integer> valueState;
@Override
public void open(Configuration parameters) throws Exception {
//设置状态初始值
valueState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("word-count", Integer.class, 0));
}
@Override
public void processElement(Tuple2<String, Integer> value, KeyedProcessFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple2<String, Integer>>.Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
//获取初始值
Integer countV = valueState.value();
//把同一个key的值进行累加 并更新状态初始值
countV += value.f1;
valueState.update(countV);
ctx.output(tag2, countV);
//输出数据
out.collect(Tuple2.of(value.f0, countV));
}
});
//获取侧输出流数据
process.getSideOutput(tag1).print("sideOutput1");
process.getSideOutput(tag2).print("sideOutput1");
//主通道输出
process.print();
environment.execute();
}
}
9、时间语义
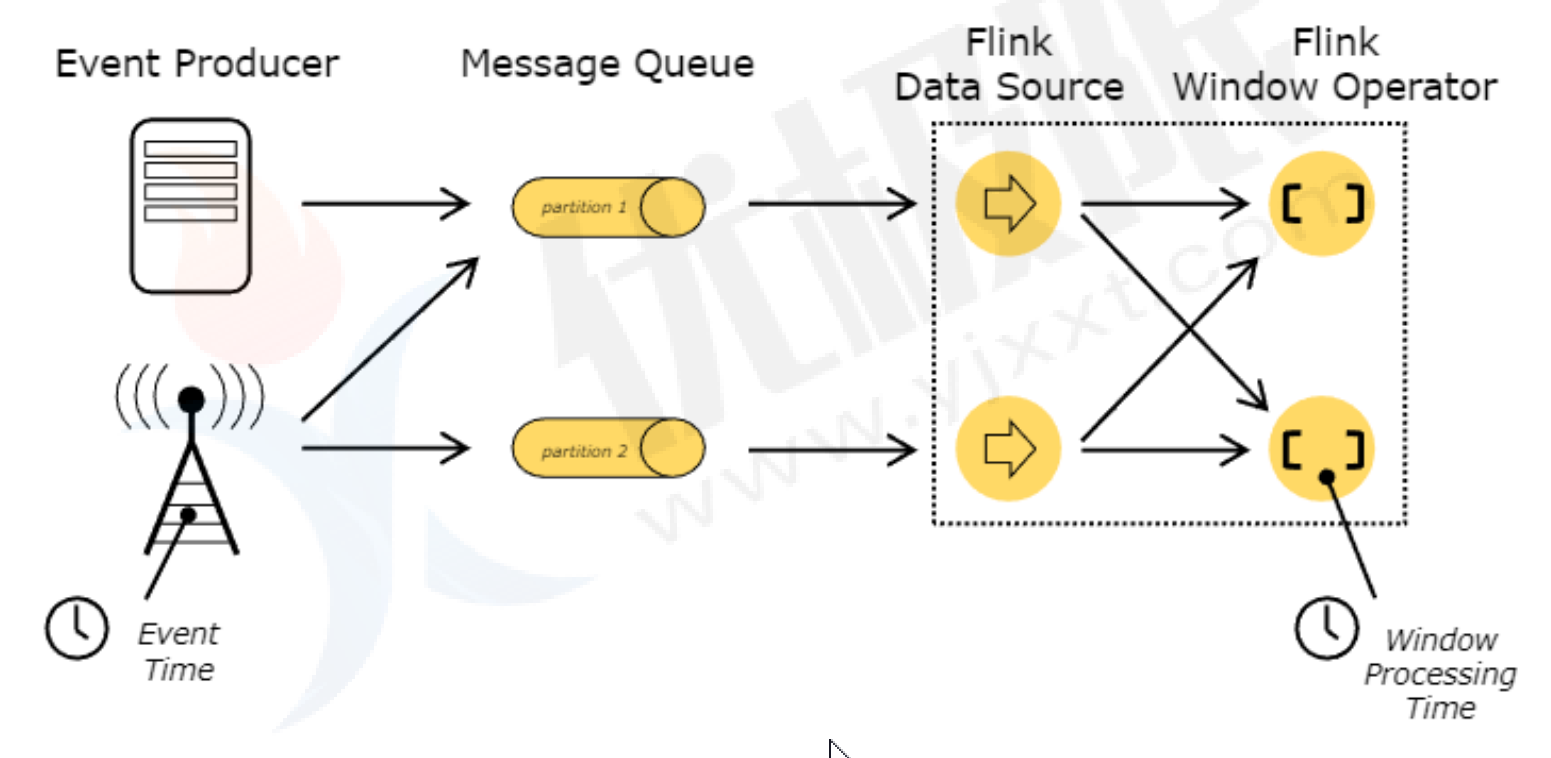
- Event Time(事件时间)
事件时间就是每个事件在其生产设备发生的时间。这个时间通常记录在进入Flink之前嵌入在记录中,并且可以从每个记录中提取事件时间戳!指的是数据本身携带的时间,这个时间是在事件产生时的时间,对于乱序、延时、或者数据重放情况,都能给出正确的结果。
例如:充值数据
- Ingestion time(摄入时间)
摄入时间指的是数据进入flink的时间。
- processing time(处理时间)
处理时间指正在执行相应操作的机器系统时间,当流式程序在基于时间运行时,所有的时间的操作都使用运行相应机器系统时钟。处理时间容易受流和机器之间传输的影响具有不确定性,但是提供了最佳的性能和最低的延迟。
例如:秒杀数据
- 代码实现
时间语义要为窗口计算服务,flink1.12以前,默认以处理时间作为默认时间语义,可以在环境上设置所想要的时间语义,但是新版本已经过时
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.fromElements("hadoop", "spark", "flink", "clickhouse");
//1.12老版本写法 以事件时间为默认时间
environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//设置摄入时间
environment.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
//以处理时间当做时间标准
environment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
flink1.12以后,flink默认以事件时间作为默认的时间语义。
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.fromElements("hadoop", "spark", "flink", "clickhouse");
//1.12版本以后写法 以处理时间为默认时间
source.keyBy(x->x).window(SlidingEventTimeWindows.of(Time.seconds(5),Time.seconds(1)));
source.keyBy(x->x).window(SlidingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(1)));
source.keyBy(x->x).window(TumblingEventTimeWindows.of(Time.seconds(5),Time.seconds(1)));
environment.execute();
10、Flink窗口函数
- 基本概念
在流处理应用中,数据是连续不断的,如果我们需要对数据进行聚合处理,就需要设置一个窗口,并对这个窗口内的数据进行计算。例如:在过去1min内有多少用户点击了我们的网页等。
Windows是flink处理无限流的核心,Windows将流拆分为有限大小的”桶“,可以在其应用上进行计算。Flink认为Batch是Streaming的一个特例,所以需要在一个窗口内对数据进行计算。而窗口(window)就是从 Streaming 到 Batch 的一个桥梁。Flink 提供了 非常完善的窗口机制。
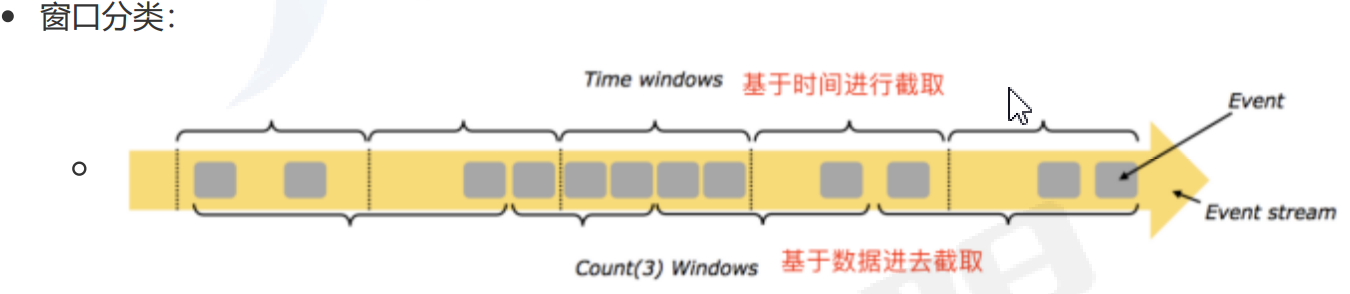
基于时间划分驱动,例如:每30s
基于数据数量驱动,例如:每一百个元素,与时间无关。
- Keyed&non-keyed
Flink 窗口在 keyed streams 和 non-keyed streams 上使用的基本结构:
- keyed streams 要调用 keyBy(...) 后再调用 window(...) 。
- non-keyed streams 直接调用 windowAll(...) 。
- 区别:一个计算每个分区内数据,一个计算全量数据。
定义窗口前确定的是你的Stream是keyed还是non-keyed:对于keyed stream,其中数据的任何属性都可以作为key。属于同一个key的元素会被发送到同一个task,使用keyed stream允许你的窗口计算由多个task并行,每个逻辑上的keyed stream都可以单独被处理。


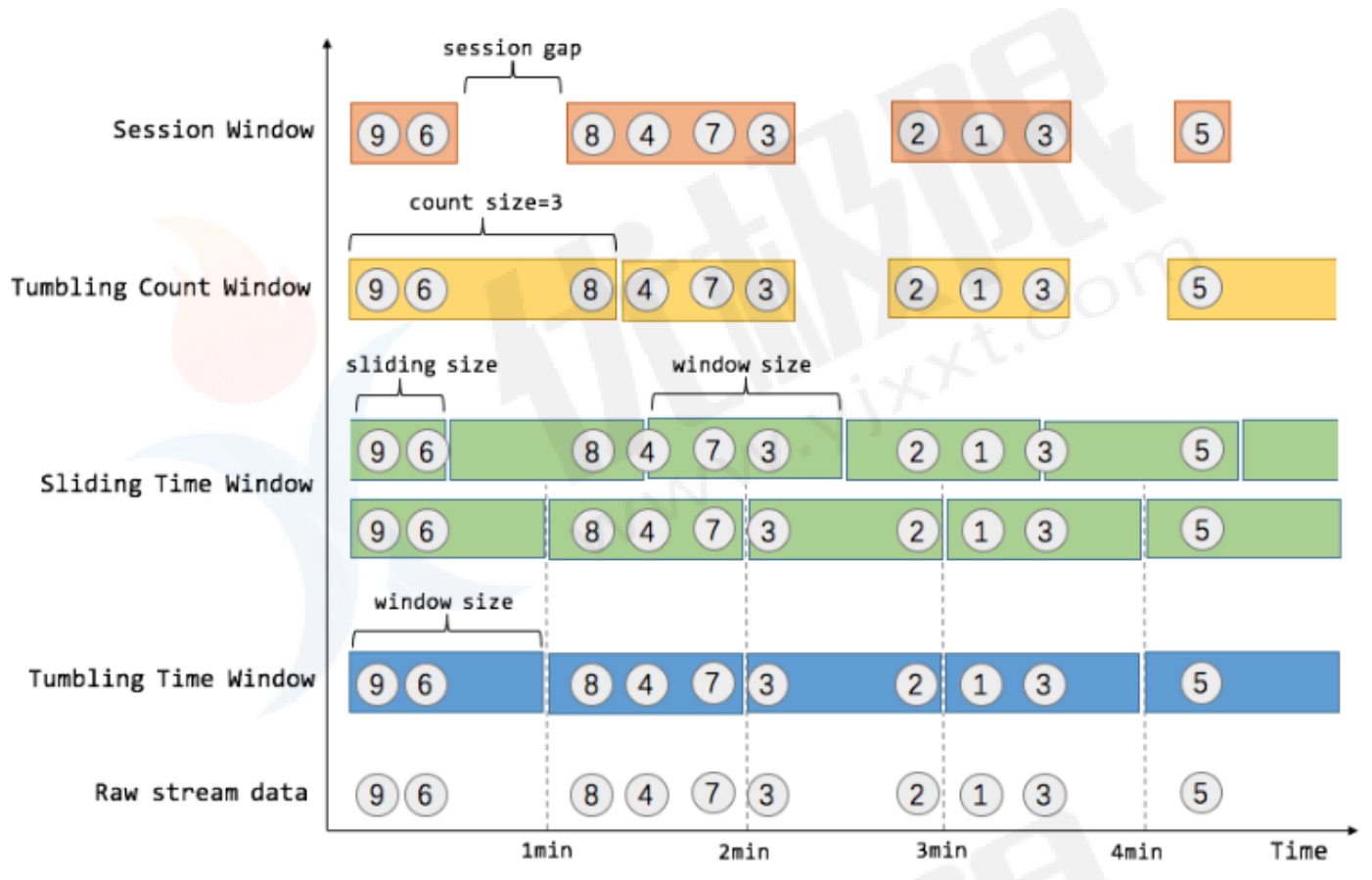
- count window
分区后计数窗口基于元素的个数来截取数据,每个分区中相同key达到固定个数就触发计算并关闭窗口。相当于座位有限,”人满就发车“,是否发车与时间无关,每个窗口截取数据的个数就是窗口大小。
//countWindows(3)相当于滚动3个数据为一个窗口 countWindows(3,2)相当于在窗口大小为3个数据滑动2个数据进行计算
source.map(x-> Tuple2.of(x,1), Types.TUPLE(Types.STRING,Types.INT)).keyBy(x->x.f0,Types.STRING).countWindow(3,2).sum(1).print("3个数据为一个窗口计算一次");
- Window All
不分区计算窗口基于元素个数来截取数据,达到固定个数就触发计算并关闭窗口,通俗点就是要数据个数达到设置的个数据就进行计算!
package com.zwf.windowFunction;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author MrZeng
* @version 1.0
* @date 2024-01-02 20:03
*/
public class CountWindowAllDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.socketTextStream("localhost", 9999);
//countWindowAll不能加keyBy()
source.map(x->{
String[] values = x.split(":");
return Tuple2.of(values[0],Integer.parseInt(values[1]));
//countWindowAll(3) 相当于窗口大小等于滑动窗口大小变成窗口滚动(tumbling)
//countWindowAll(3,2) 在窗口大小为3的窗口内滑动2个数据进行计算关闭窗口(sliding) 。
}, Types.TUPLE(Types.STRING,Types.INT)).countWindowAll(3,2).reduce((x1,x2)->{
x1.f1+=x2.f1;
return x1;
}).print("window all");
environment.execute();
}
}
总结:countwindow分为keyed和no-keyed,keyed是在指定同key的数据达到固定个数进行计算,而no-keyed只要数据个数达到固定个数就进行计算。
缺陷:如果上游数据个数不稳定,就会造成处理时间不确定!
- TimeWindow
为了弥补CountWindow()的缺失,flink又推出了时间窗口函数,时间窗口是最常用的窗口函数,可以分为滚动、滑动和会话三种。
- 翻滚窗口(Tumbling Window,无重叠)
- 滑动窗口(Sliding Window,有重叠)
- 会话窗口(Session Window,活动间隙)
除了Flink自定义的,还可以继承WindowAssigner类来实现自定义Window Assigner
所有内置的window assigner(除了global window)都是基于时间分发数据的,process time或event time均可。
- Tumbling Window
滚动窗口的assigner分发元素到指定大小的窗口;滚动窗口大小是固定的,各自范围之间不重叠;如果你指定了窗口大小为5分钟,每5分钟就有一个窗口被计算,新窗口被创建。
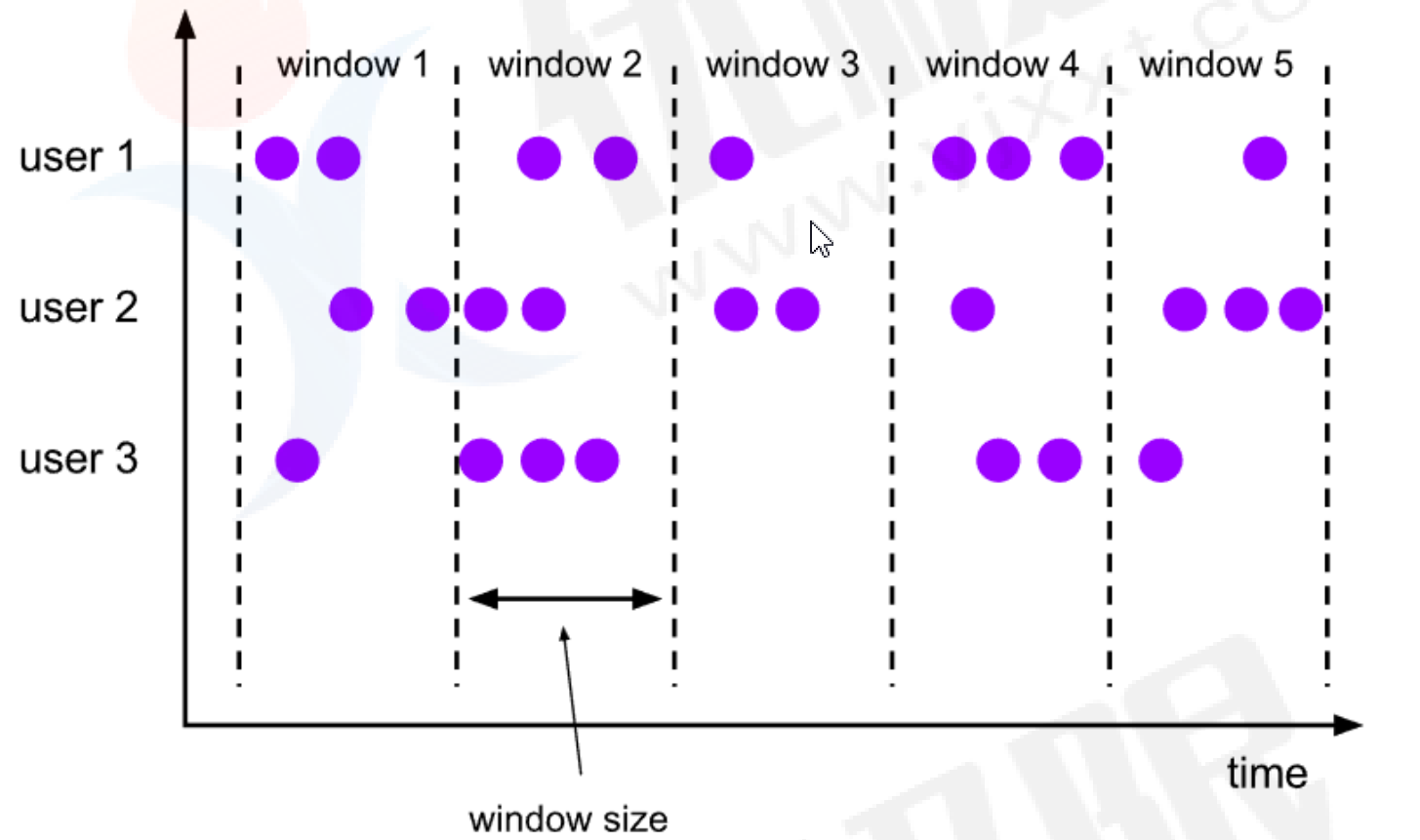
- 案例(keyed 滚动窗口案例)
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.socketTextStream("localhost", 6379);
source.map(x->{
String[] values = x.split(":");
return Tuple2.of(values[0],Integer.valueOf(values[1]));
}, Types.TUPLE(Types.STRING,Types.INT)).keyBy(x->x.f0).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).reduce((x1, x2)->{
x1.f1+=x2.f1;
return x1;
//处理时间要放在下游
}).map(y-> {
y.f0=LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy年MM月dd日HH 时mm分ss秒SSS毫秒"))+"[处理时间:]"+y.f0;
return y;
},Types.TUPLE(Types.STRING,Types.INT)).print("时间窗口聚合").setParallelism(1);
environment.execute();
- Sliding Window
滑动窗口的 assigner 分发元素到指定大小的窗口,窗口大小通过 window size 参数设置。
滑动窗口需要一个额外的滑动距离(window slide)参数来控制生成新窗口的频率。
如果滑动窗口时间大小等于窗口时间大小,窗口元素滚动!(只设置窗口大小,不设置滑动间隔)
如果滑动窗口时间大小小于窗口时间大小,数据有重叠!
如果滑动窗口时间大小大于窗口时间大小,数据集有丢失!
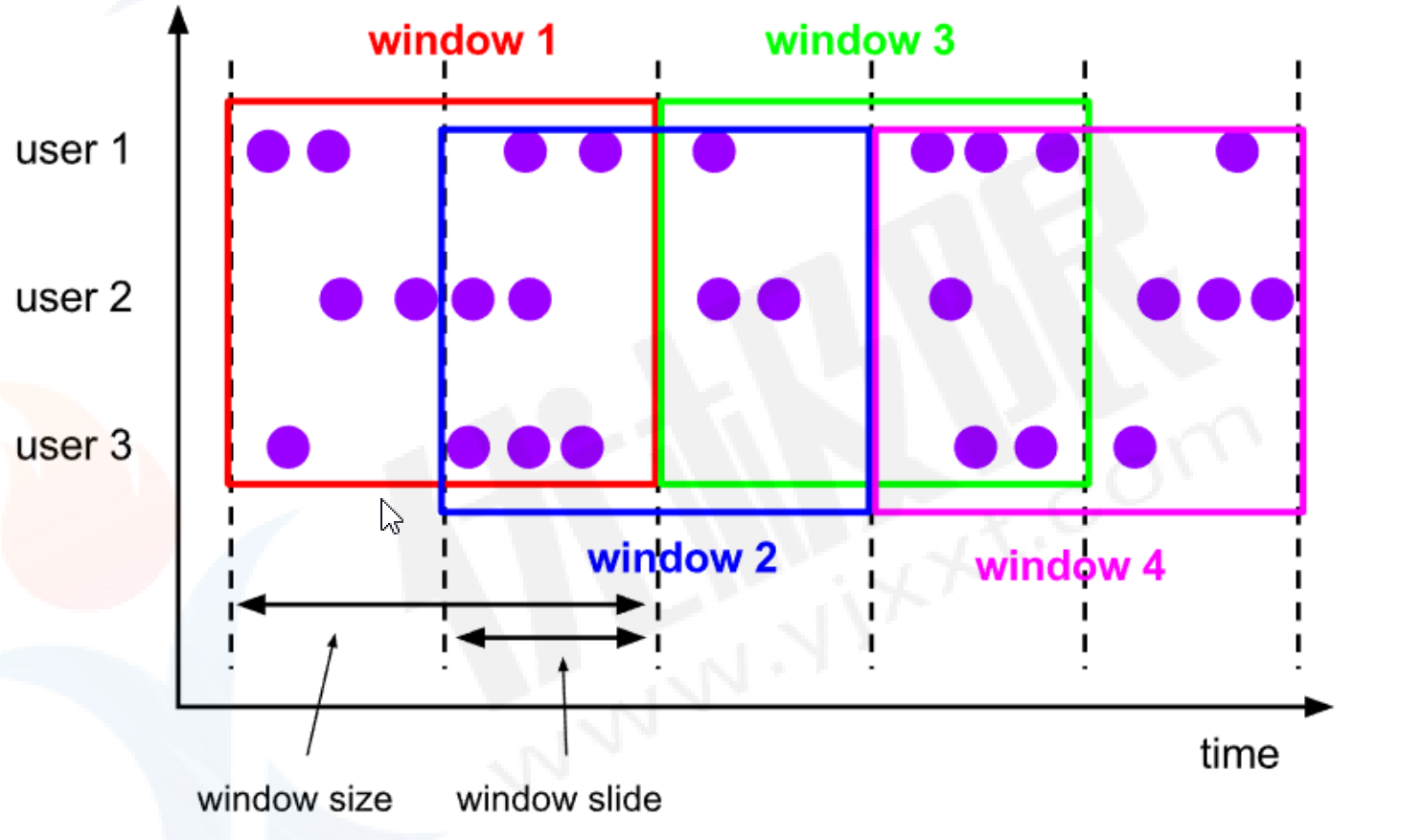
- 案例(no-keyed滑动窗口案例)
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.socketTextStream("localhost", 9999);
source.map((x)-> {
String[] split = x.split(":");
return Tuple2.of(split[0],Integer.valueOf(split[1]));
}, Types.TUPLE(Types.STRING,Types.INT)).windowAll(SlidingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(2))).reduce((y1,y2)-> {
y1.f1 +=y2.f1;
return y1;
}).map(x->{
x.f0+="[处理时间:]"+ LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy年MM月dd日HH 时mm分ss秒SSS毫秒"));
return x;
},Types.TUPLE(Types.STRING,Types.INT)).print().setParallelism(1);
environment.execute();
- Session Windown
会话窗口的 assigner 会把数据按活跃的会话分组。与滚动时间和滑动窗口不同的是会话窗口不会相互重叠,没有固定开始和结束时间。会话窗口设置固定的会话间隔或者用会话间隔函数动态定义时间算作不活跃。超出不活跃时间段,会话就关闭,接下来的数据发到新会话窗口。
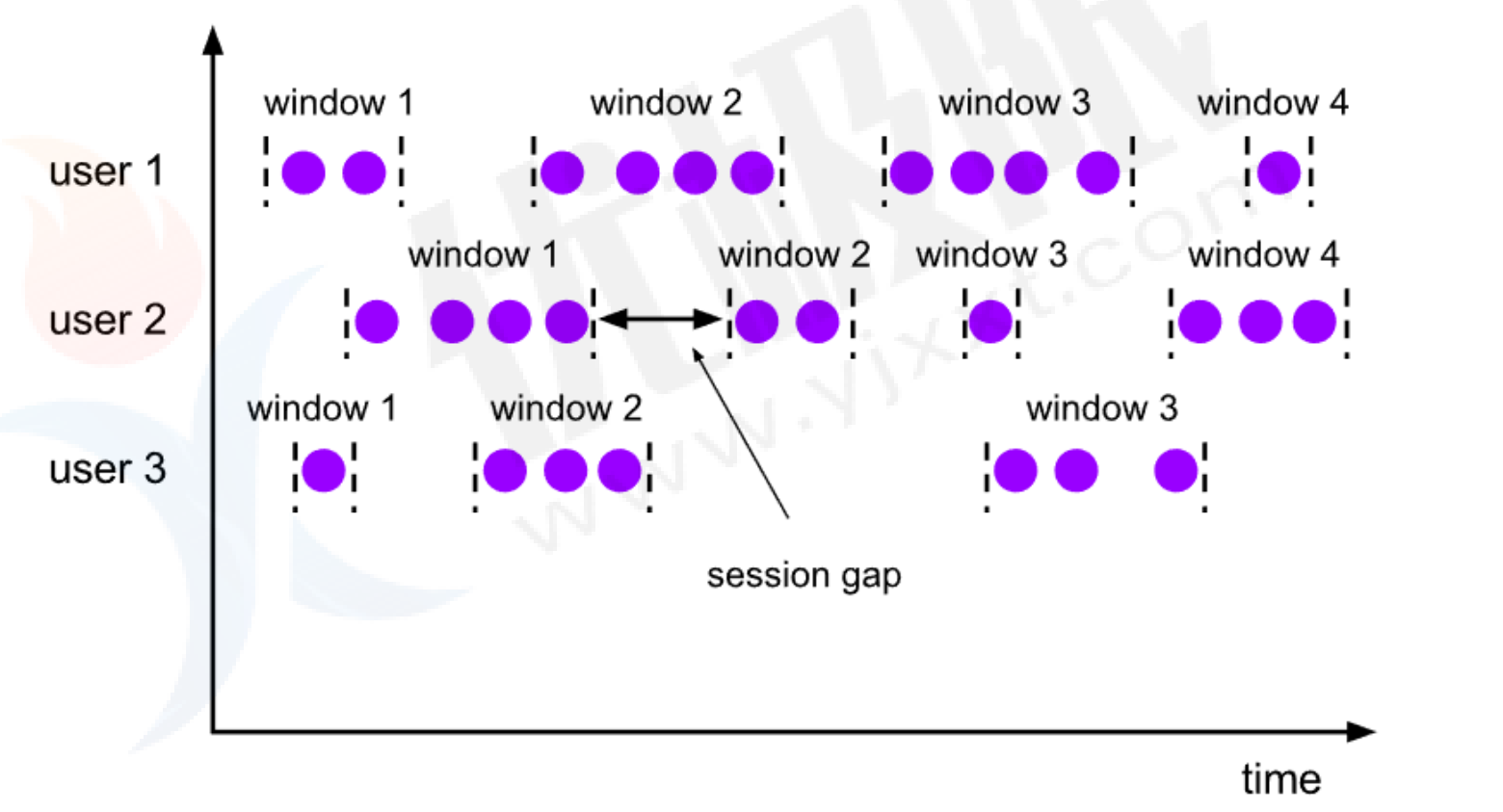
- 案例
//session会话 只要在会话间隔时间内有数据输入就不会计算 超过会话间隔输入/不输入数据都会计算!
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.socketTextStream("localhost", 6666);
source.map(x->{
String[] split = x.split(":");
return Tuple2.of(split[0],Integer.valueOf(split[1]));
}, Types.TUPLE(Types.STRING,Types.INT)).keyBy(x->x.f0).window(ProcessingTimeSessionWindows.withGap(Time.seconds(3))).reduce((y1,y2)->{
y1.f1+= y2.f1;
return y1;
}).map(x->{
x.f0+="[时间间隔]"+ LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy年MM月dd日HH 时mm分ss秒SSS毫秒"));
return x;
},Types.TUPLE(Types.STRING,Types.INT)).print();
environment.execute();
- global windows
GlobalWindows作为一个全局的窗口分配器,它不像TimeWindow或CountWindow那样通过元素 个数来划分成一个个窗口,而是把分区内所有的元素分配到同一个窗口,所以说如果没有定义触发器,那么整个subTask中就只有一个窗口,且一直存在,不会触发计算。(自定义触发计算逻辑)
窗口模式仅在你指定了自定义的[trigger]时有用。 否则,计算不会发生,因为全局窗口没有天然的终点去触发其中积累的数据。
window和windowAll区别:
- window只能在已经分区的 KeyedStream 上定义,通过KeyedStream转化为 WindowedStream执行具体的开窗操作。
- windowAll只能在未分区的DataStream上定义,调用windowAll方法后,会把DataStream转 化为AllWindowedStream,并得到全局统计结果。也就是说WindowAll并行度只能1,且不可设置并行度。

- 案例(自定义globalwindowfunction函数)
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.socketTextStream("localhost", 8888);
source.map(x->{
String[] split = x.split(":");
return Tuple2.of(split[0],Integer.valueOf(split[1]));
//自定义同一个key 5个数据计算一次 通过触发器设置
}, Types.TUPLE(Types.STRING,Types.INT)).keyBy(x->x.f0).window(GlobalWindows.create()).trigger(PurgingTrigger.of(CountTrigger.of(5))).reduce((y1, y2)->{
y1.f1+=y2.f1;
return y1;
}).map(x->{
x.f0+="[处理时间]"+ LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy年MM月dd日HH 时mm分ss秒SSS毫秒"));
return x;
},Types.TUPLE(Types.STRING,Types.INT)).print("global window function");
environment.execute();
- 案例(no-keyed 自定义globalwindowfunction函数)
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.socketTextStream("localhost", 8888);
source.map(x->{
String[] split = x.split(":");
return Tuple2.of(split[0],Integer.valueOf(split[1]));
//自定义全量数据 5个数据计算一次
}, Types.TUPLE(Types.STRING,Types.INT)).windowAll(GlobalWindows.create()).trigger(CountTrigger.of(5)).reduce((y1, y2)->{
y1.f0+="_"+y2.f0;
y1.f1+=y2.f1;
return y1;
}).map(x->{
x.f0+="[处理时间]"+ LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy年MM月dd日HH 时mm分ss秒SSS毫秒"));
return x;
},Types.TUPLE(Types.STRING,Types.INT)).print("global window function");
environment.execute();
11、增量聚合函数
增量聚合函数有ReduceFunction和AggregateFunction两种,其中reduceFunction必须要求进出数据类型必须以一致,因此我们传入数据时,必须把数据转为输入时的数据格式再输出!
AggregateFunction可以看做是ReduceFunction的通用版本,可以不要求输入和输出数据一致,里面有四个实现方法:
- createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。
- add():传入新的value值和累加器的值,对新的数据进一步聚合过程,返回一个新的累加器值。每条数据到来之后都会调用这个方法。
- getResult():这个方法只在窗口要输出结果时调用。
- merge():合并两个累加器,并将合并后的状态作为一个累加器返回。这个方法只在需要合并窗口 的场景下才会被调用;常见的合并窗口就是会话窗口(Session Windows)
总结:来一条加一条数据,达到特定的触发条件输出计算结果!
- 案例(reduce案例)
//增量函数
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.socketTextStream("localhost", 9999);
source.map(w->{
String[] split = w.split(":");
return Tuple2.of(split[0],Integer.valueOf(split[1]));
}, Types.TUPLE(Types.STRING,Types.INT)).keyBy(x->x.f0).countWindow(3).reduce((t1,t2)->{
System.out.println("窗口增量计算函数来一条算一条.main["+t1+"]["+t2+"]");
t1.f0=t1.f0+"_"+t2.f0;
t1.f1=t1.f1+t2.f1;
return t1;
}).print("count--Tumbling").setParallelism(1);
environment.execute();
- 案例( Aggregate案例 求平均数)
//自定义聚合函数
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.socketTextStream("localhost", 9999);
source.map(x->{
String[] split = x.split(":");
return Tuple2.of(split[0],Integer.valueOf(split[1]));
//3行同一个key值数据计算一次 滚动计算
}, Types.TUPLE(Types.STRING,Types.INT)).keyBy(x->x.f0).countWindow(3).aggregate(
//三个泛型 输入数据类型 中间累加数据类型 输出数据类型
new AggregateFunction<Tuple2<String, Integer>, Tuple3<String,Integer, Integer>, Tuple2<String,Double>>() {
@Override
public Tuple3<String, Integer, Integer> createAccumulator() {
return Tuple3.of(null, 0, 0);
}
@Override
public Tuple3<String, Integer, Integer> add(Tuple2<String, Integer> value, Tuple3<String, Integer, Integer> accumulator) {
accumulator.f1 = value.f1 + accumulator.f1;
accumulator.f0 = value.f0;
accumulator.f2++;
return accumulator;
}
@Override
public Tuple2<String, Double> getResult(Tuple3<String, Integer, Integer> accumulator) {
Double avg = accumulator.f1 * 1.0 / accumulator.f2;
return Tuple2.of(accumulator.f0, avg);
}
@Override
public Tuple3<String, Integer, Integer> merge(Tuple3<String, Integer, Integer> a, Tuple3<String, Integer, Integer> b) {
return null;
}
}).print();
environment.execute();
12、全量聚合函数
全量聚合函数在一个窗口触发特定条件时,只计算一次并输出结果,没有触发特定条件过程中,不会进行计算!
常见的全量窗口函数:
- apply(windowFunction<>())
- process(processFunction<>())
- 案例
//全量数据聚合
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = environment.socketTextStream("localhost", 8888);
//使用name:数字
source.map(x->{
String[] value = x.split(":");
return Tuple2.of(value[0],Integer.parseInt(value[1]));
/**
* Tuple2<String, Integer>:输入参数
* Tuple3<String,Integer,String>:输出参数:key,值,窗口信息
*/
}, Types.TUPLE(Types.STRING,Types.INT)).keyBy(k->k.f0).window(SlidingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(3))).apply(new WindowFunction<Tuple2<String, Integer>, Tuple3<String,Integer,String>, String, TimeWindow>() {
/**
* @param s key值
* @param window 有GlobalWindow和TimeWindow.
* @param input 输入的数据集合 迭代输入
* @param out 输出参数
- *
*/
@Override
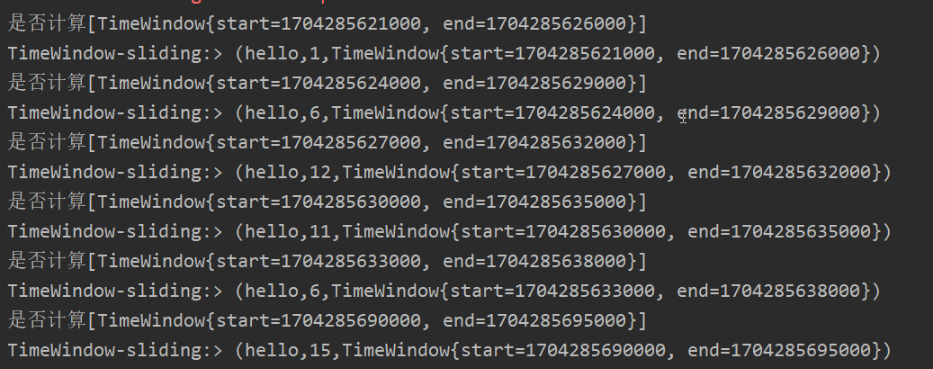
public void apply(String s, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<Tuple3<String, Integer, String>> out) throws Exception {
System.out.println("是否计算"+"["+window+"]");
//结果变量
int sum=0;
for (Tuple2<String, Integer> integerTuple2 : input) {
sum+=integerTuple2.f1;
}
out.collect(Tuple3.of(s,sum,window.toString()));
}
}).print("TimeWindow-sliding:").setParallelism(1);
environment.execute();
13、WaterMark
“水位线”就是用来度量事件时间。程序使用事件时间就需要水位线,水位线设置是为了解决"迟到数据",所谓”迟到数据“就是在先产生的数据(时间戳小)没有在后产生的数据(时间戳大)前面进行计算消费,也是为了统一flink系统时间,解决数据在网络延迟、IO传输过程中造成事件时间乱序问题。
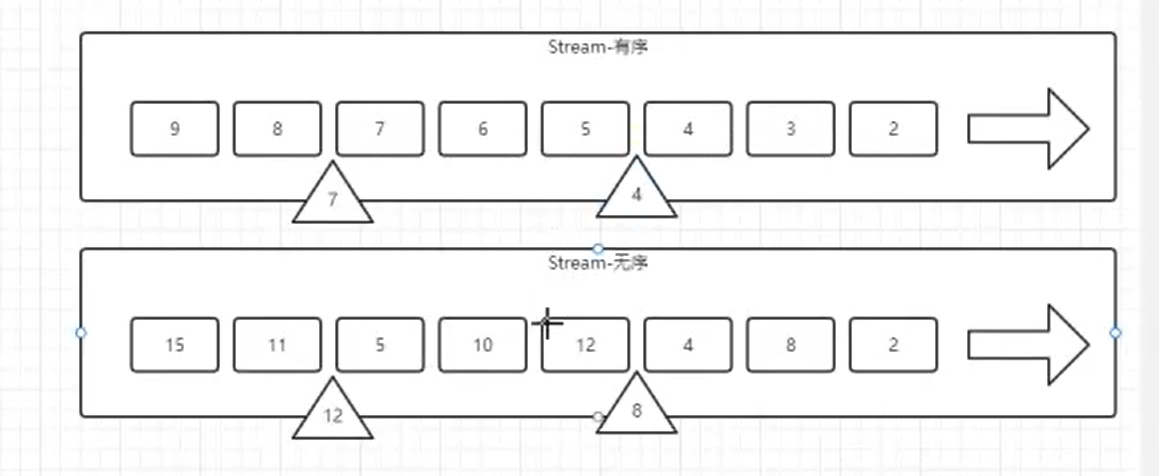

"时间所剩不多了"-------->快迟到了! 先到先处理,先到时间戳越小!正常时间戳随着时间流逝,时间戳不断增加!
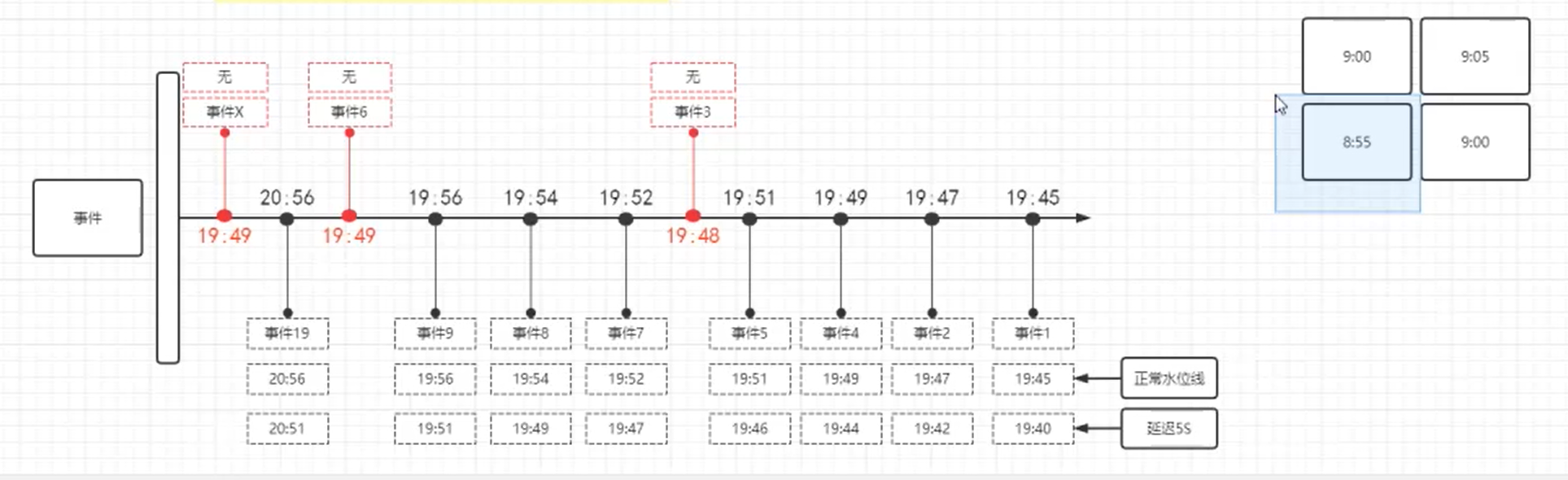
图中每个事件时间戳是距离处理时间(水位线)的毫秒数,事件数据从左往右时间戳越来越小,时间戳越小数据生成越早越先被处理,时间戳越大表示数据生成越晚处理越晚,意味着最理想状态是在最大时间戳事件前处理完所有小时间戳数据。比如:到了8:20进行数据计算处理,但是8:10事件数据还没到,为了等待8:10事件数据,设置水位线为8:30,也就是8:30再进行处理,把时间戳拉长(晚一点处理)。
如果事件时间戳小于水位线并且比水位线时间戳还要晚处理就会造成数据迟到,此时需要设置水位线延迟时间(时间戳变小),把迟到的数据纳入窗口进行计算,如果迟到数据时间戳还是比延迟时间戳小并且在延迟时间后面处理,那么数据抛弃或者再设置允许迟到时间!
公式:事件时间 - 延迟时间 >= 窗口最大时间 + 允许迟到时间 (事件时间-延迟时间也是水位线时间)
单并行度下,使用全量窗口函数等事件时间超过每个窗口的水位线时间才触发计算,每个窗口下水位线是窗口内事件最大时间戳(就是窗口内最晚的数据)。
多并行度下,多个并行度传输数据,会以最小时间戳并行度时间广播到下游窗口中设置为水位线。
- 案例(数据有序设置水位线案例)
对于有序流,主要特点就是时间戳单调增长(Monotonously Increasing Timestamps),所以永远不会出现迟到数据的问题。
直接调用WatermarkStrategy.forMonotonousTimestamps()方法就可以实现。
直接拿当前最大的时间戳作为水位线就可以了。
public static void main(String[] args) throws Exception {
//事件时间读取 代码没加水位线 无法计算
new Thread(()->{
//生成随机值发送到kafka中
for(int i=0;i<200;i++) {
String randDigest = RandomStringUtils.randomAlphabetic(8).toLowerCase(Locale.ROOT);
KafkaProducer<String, String> producer = KafkaUtils.getProducer();
//插入有序数据
String s = String.valueOf(System.currentTimeMillis());
ProducerRecord<String, String> record = new ProducerRecord<String, String>("event_data","eventData"+i,randDigest+i%2+":"+i+":"+s);
producer.send(record);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
//从kafka中读取数据
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(2);
KafkaSource<String> kafkaSource= KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setTopics("event_data")
.setGroupId("event-group")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> source = environment.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka_source");
source.map(word -> {
String[] split = word.split(":");
return Tuple3.of(split[0], Integer.parseInt(split[1]),Long.parseLong(split[2]));
}, Types.TUPLE(Types.STRING, Types.INT,
//在滑动窗口前设置水位线 有序数据使用 forMonotonousTimestamps
//WatermarkStrategy 水位线策略
Types.LONG)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String,Integer,Long>>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, Integer, Long>>() {
//把事件时间戳作为水位线
@Override
public long extractTimestamp(Tuple3<String, Integer, Long> element, long recordTimestamp) {
return element.f2;
}
}))
.keyBy(t -> t.f0).window(SlidingEventTimeWindows.of(Time.seconds(5),Time.seconds(2))).apply(new WindowFunction<Tuple3<String, Integer, Long>, Tuple2<String,Integer>, String, TimeWindow>() {
@Override
public void apply(String s, TimeWindow window, Iterable<Tuple3<String, Integer, Long>> input, Collector<Tuple2<String, Integer>> out) throws Exception {
int sum=0;
StringBuffer key=new StringBuffer();
key.append(s).append("[窗口信息]:").append(window.toString());
for (Tuple3<String, Integer, Long> item : input) {
sum+=item.f1;
key.append("[事件时间]:"+String.valueOf(item.f2));
}
out.collect(Tuple2.of(key.toString(),sum));
}
}).print("[WaterMark------>TimeWindows]");
environment.execute();
}
- 无序流
由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定量的延迟时间(Fixed Amount of Lateness)。
调用 WatermarkStrategy. forBoundedOutOfOrderness()方法就可以实现。
这个方法需要传入一个 maxOutOfOrderness 参数,表示“最大乱序程度”。(延迟时间)
Tips:
当程序开始时,WaterMark会被设置为Long的最小值,以保证它不会丢数据。
当程序关闭时,WaterMark会被设置为Long的最大值,以保证它大到足以关闭所有已经开启的窗口。
- 案例(无序流处理)
//事件时间读取 代码没加水位线 无法计算
new Thread(()->{
//生成随机值发送到kafka中
String randDigest = RandomStringUtils.randomAlphabetic(8).toLowerCase(Locale.ROOT);
for(int i=200;i<400;i++) {
KafkaProducer<String, String> producer = KafkaUtils.getProducer();
//插入有序数据
if(i%5!=0) {
ProducerRecord<String, String> record = new ProducerRecord<String, String>("OutInOrder", "eventData" + i, randDigest + i % 2 + ":" + i + ":" + System.currentTimeMillis());
producer.send(record);
//能被5整除的迟到数据 迟到1到10s [0,10)s
}else {
ProducerRecord<String, String> record = new ProducerRecord<String, String>("OutInOrder", "eventData" + i, randDigest + i % 2 + ":" + i + ":" + (System.currentTimeMillis()-(long)(Math.random()*10000)));
producer.send(record);
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
//从kafka中读取数据
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
KafkaSource<String> kafkaSource= KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setTopics("OutInOrder")
.setGroupId("event-group")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
//读取数据进行消费
DataStreamSource<String> source = environment.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafka_source");
//处理数据
source.map(x->{
String[] v = x.split(":");
Tuple3<String, String, Long> tuple3 = Tuple3.of(v[0], v[1], Long.parseLong(v[2]));
return tuple3;
},Types.TUPLE(Types.STRING,Types.STRING,Types.LONG))
//标记水位线 注意泛型 设置延迟时间为8s
.assignTimestampsAndWatermarks(WatermarkStrategy. <Tuple3<String,String,Long>>forBoundedOutOfOrderness(Duration.ofSeconds(8)).withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String,String,Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long recordTimestamp) {
return element.f2;
}
//滑动事件时间
})).keyBy(t3->t3.f0).window(SlidingEventTimeWindows.of(Time.seconds(5),Time.seconds(2)))
.apply(new WindowFunction<Tuple3<String, String, Long>, String, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow window, Iterable<Tuple3<String, String, Long>> input, Collector<String> out) throws Exception {
StringBuffer buffer=new StringBuffer();
buffer.append("[计算结果:]");
for (Tuple3<String, String, Long> vas : input) {
buffer.append(vas.f1).append("_");
}
buffer.append("[时间窗口]").append(window.toString());
out.collect(buffer.toString());
}
}).print("[水位线]---->[乱序流]");
environment.execute();
- 自定义水位线
自定义水位线有两种:
- 周期性(periodic):周期性调用的方法中发出水位线。
- 实现Periodic Generator接口生成实现类定义
- 通过onEvent()观察判断输入的事件,在OnPeriodicEmit()发出水位线。
- 定点式(Punctuated):在事件方法中发出水位线。
- 实现Punctuated Generator接口生成实现类定义
- 定点生成器不停检测onEvent()中事件,发现带有水位线信息的特殊事件就会立即发出
- 案例(周期性水位线 无序流)
package com.zwf.windowFunction;
import com.zwf.util.KafkaUtils;
import org.apache.commons.lang3.RandomStringUtils;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.swing.plaf.basic.BasicSliderUI;
import java.util.Locale;
/**
* @author MrZeng
* @version 1.0
* @date 2024-01-04 10:38
*/
public class eventTimeWaterMark {
public static void main(String[] args) throws Exception {
new Thread(()->{
KafkaProducer<String, String> producer = KafkaUtils.getProducer();
String lowerCase = RandomStringUtils.randomAlphabetic(4).toLowerCase(Locale.ROOT);
for (int i=100;i<2000;i++){
if(i%5!=0) {
ProducerRecord<String, String> record = new ProducerRecord<String, String>("customer_watermark", lowerCase, lowerCase+i%2 + ":" + i + ":" + System.currentTimeMillis());
producer.send(record);
}else {
//模拟数据迟到0到10s
ProducerRecord<String, String> record = new ProducerRecord<String, String>("customer_watermark", lowerCase, lowerCase+i%2+ ":" + i + ":" + (System.currentTimeMillis()-(long)Math.random()*10000));
producer.send(record);
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
KafkaSource<String> kafkaSource= KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setTopics("customer_watermark")
.setGroupId("event-group-id")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
//连接kafka
DataStreamSource<String> source = environment.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource");
//处理kafka数据源
source.map(x->{
String[] val = x.split(":");
return Tuple3.of(val[0],val[1],Long.parseLong(val[2]));
}, Types.TUPLE(Types.STRING,Types.STRING, Types.LONG)).assignTimestampsAndWatermarks(new CustomerWaterMark()).keyBy(x->x.f0).window(SlidingEventTimeWindows.of(Time.seconds(5),Time.seconds(3)))
.apply(new WindowFunction<Tuple3<String, String, Long>, String, String, TimeWindow>() {
@Override
public void apply(String s, TimeWindow window, Iterable<Tuple3<String, String, Long>> input, Collector<String> out) throws Exception {
StringBuffer buffer=new StringBuffer();
buffer.append("[数据计算]:");
for (Tuple3<String, String, Long> vals : input) {
buffer.append(vals.f1).append("_").append("[事件时间]:").append(vals.f2).append(",");
}
buffer.append("[窗口信息]:").append(window);
out.collect(buffer.toString());
}
}).print("自定义无序流周期性水位线:");
environment.execute();
}
}
//自定义水位线策略
class CustomerWaterMark implements WatermarkStrategy<Tuple3<String,String,Long>> {
@Override
public WatermarkGenerator<Tuple3<String,String,Long>> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new PeriodicWaterMark();
}
//设置参考时间戳时间
@Override
public TimestampAssigner<Tuple3<String, String, Long>> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long recordTimestamp) {
return element.f2;
}
};
}
}
//自定义周期水位线生成器
class PeriodicWaterMark implements WatermarkGenerator<Tuple3<String,String,Long>>{
//初始化水位线
Long maxTimeStamp=Long.MIN_VALUE;
//设置延迟时间 防止丢失迟到数据
Long lateTime=8000L;
/**
*
* @param event 输入事件数据对象
* @param eventTimestamp 事件时间戳
* @param output 输出对象
*/
@Override
public void onEvent(Tuple3<String, String, Long> event, long eventTimestamp, WatermarkOutput output) {
//设置水位线
maxTimeStamp = Math.max(maxTimeStamp,event.f2);
}
//周期性发送
@Override
public void onPeriodicEmit(WatermarkOutput output) {
//周期性发送水位线 到一个事件就发射一个水位线
output.emitWatermark(new Watermark(maxTimeStamp-lateTime-1L));
}
}
- 案例(定点水位线)
package com.zwf.windowFunction;
import com.zwf.util.KafkaUtils;
import org.apache.commons.lang3.RandomStringUtils;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Locale;
/**
* @author MrZeng
* @version 1.0
* @date 2024-01-04 14:20
*/
public class CustomPointWaterMark {
//自定义定点水位线
public static void main(String[] args) throws Exception {
new Thread(()->{
KafkaProducer<String, String> producer = KafkaUtils.getProducer();
String ranStr = RandomStringUtils.randomAlphabetic(5).toLowerCase(Locale.ROOT);
for (int i=1000;i<2000;i++) {
ProducerRecord<String, String> record = new ProducerRecord<>("customer_watermark", ranStr+i, ranStr+i%2+":"+i+":"+System.currentTimeMillis());
producer.send(record);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
//读取kafka数据源
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setGroupId("kafka_group")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setTopics("customer_watermark")
.setStartingOffsets(OffsetsInitializer.latest())
.build();
environment.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka_source")
.assignTimestampsAndWatermarks(new CusWaterMark()).keyBy(x -> x.split(":")[0]).window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new WindowFunction<String, String, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow window, Iterable<String> input, Collector<String> out) throws Exception {
StringBuffer buffer=new StringBuffer();
buffer.append("[计算结果]:");
for (String s : input) {
buffer.append(s.split(":")[1]).append("_").append(s.split(":")[2]);
}
buffer.append("[窗口信息]:").append(window);
out.collect(buffer.toString());
}
}).print();
environment.execute();
}
}
class CusWaterMark implements WatermarkStrategy<String>{
@Override
public WatermarkGenerator<String> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new CusWaterMarkDemo();
}
@Override
public TimestampAssigner<String> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new SerializableTimestampAssigner<String>() {
@Override
public long extractTimestamp(String element, long recordTimestamp) {
return Long.parseLong(element.split(":")[2]);
}
} ;
}
}
class CusWaterMarkDemo implements WatermarkGenerator<String>{
//循环到整百数时 发送水位线 定点发送水位线
@Override
public void onEvent(String event, long eventTimestamp, WatermarkOutput output) {
if(Integer.parseInt(event.split(":")[1])%100==0){
output.emitWatermark(new Watermark(Long.parseLong(event.split(":")[2])-1L));
}
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
}
}
14、迟到数据
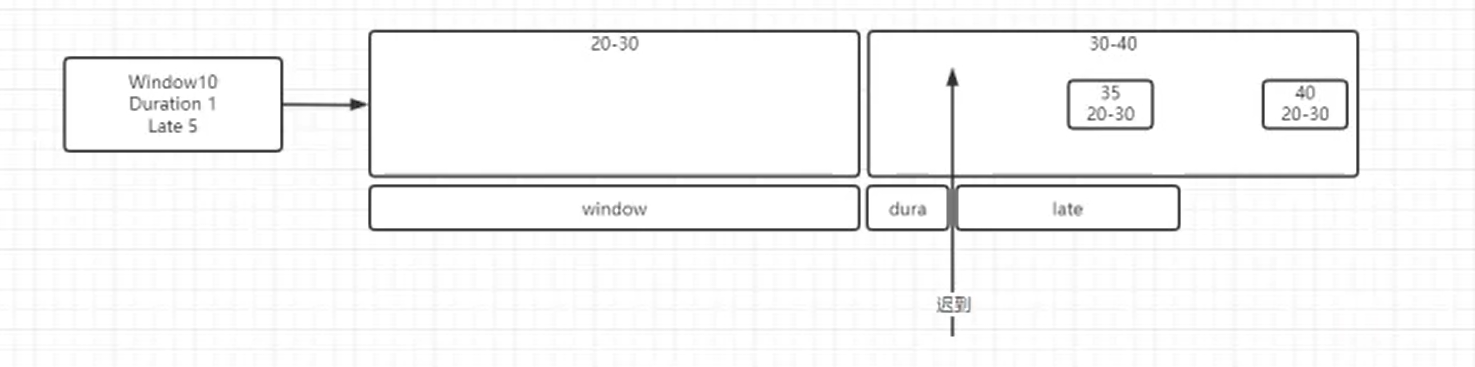
迟到数据指:在设置延迟后未在延迟时间之前被处理的数据。
解决方案:
- 等待迟到数据,通过WindowedStream.allowedLateness()方法来设定窗口的允许延迟。
- 侧输出迟到数据:这是保底方案,就是在超过等待时间数据还没到,就通过侧输出收集起来,数据延迟严重可以保证数据不丢失。
- 延迟的数据通过outputTag输出,必须要事件时间大于watermark + allowed lateness,数据才会存储在outputTag(侧输出数据)中。
- 案例(处理迟到数据)
package com.zwf.windowFunction;
import com.zwf.util.KafkaUtils;
import org.apache.commons.lang3.RandomStringUtils;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.OutputTag;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.time.Duration;
import java.util.Locale;
/**
* @author MrZeng
* @version 1.0
* @date 2024-01-04 15:26
*/
public class LateDataProcessFunction {
public static void main(String[] args) throws Exception {
//模拟迟到数据处理
new Thread(()->{
KafkaProducer<String, String> producer = KafkaUtils.getProducer();
String s = RandomStringUtils.randomAlphabetic(5).toLowerCase(Locale.ROOT);
for (int i=100;i<300;i++){
//10倍数位置生产的数据 时间迟到13s
if(i%10==0){
ProducerRecord<String, String> record = new ProducerRecord<String, String>("late_data_topic",s+(i%2),s+i%2+":"+i+":"+(System.currentTimeMillis()-13000));
producer.send(record);
//5倍数位置的生产 时间迟到8s
}else if(i%5==0){
ProducerRecord<String, String> record = new ProducerRecord<String, String>("late_data_topic",s+(i%2),s+i%2+":"+i+":"+(System.currentTimeMillis()-8000));
producer.send(record);
}else {
ProducerRecord<String, String> record = new ProducerRecord<String, String>("late_data_topic",s+(i%2),s+i%2+":"+i+":"+System.currentTimeMillis());
producer.send(record);
}
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
//设置kafka连接信息
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setGroupId("kafka_group")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setTopics("late_data_topic")
.setStartingOffsets(OffsetsInitializer.latest())
.build();
//设置侧输出标签
OutputTag<String> outputTag=new OutputTag<>("latedata"){ };
DataStreamSource<String> ds = environment.fromSource(source, WatermarkStrategy.noWatermarks(), "kafkaSource");
SingleOutputStreamOperator<String> reduceStream =
// 设置延迟时间1s
ds.assignTimestampsAndWatermarks(WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(1)).withTimestampAssigner(new SerializableTimestampAssigner<String>() {
@Override
public long extractTimestamp(String element, long recordTimestamp) {
return Long.parseLong(element.split(":")[2]);
}
//等待迟到数据两秒
})).keyBy(s -> s.split(":")[0]).window(TumblingEventTimeWindows.of(Time.seconds(5))).allowedLateness(Time.seconds(2)) //超出2s还没处理 就侧输出到数据库中再处理。
.sideOutputLateData(outputTag).reduce((y1, y2) -> y1 + "[" + y2.split(":")[1] + "," + y2.split(":")[2] + "]");
//延迟1s
reduceStream.map(t -> "[" + System.currentTimeMillis() + "][" + t + "]", Types.STRING).print("main:");
//获取侧输出
reduceStream.getSideOutput(outputTag).print("output:");
environment.execute();
}
}
15、Triggers&Evictor
- 触发器(trigger)
trigger决定一个窗口何时被窗口函数处理,每个窗口函数都有一个默认你的触发器。如果默认 trigger 无法满足你的需要,你可以在 trigger(...) 调用中指定自定义的 trigger。
Trigger接口提供5个抽象方法:
- onElement() 方法在每个元素被加入窗口时调用。
- onEventTime() 方法在注册的 event-time timer 触发时调用。
- onProcessingTime()方法在注册的 processing-time timer 触发时调用。
- onMerge() 方法与有状态的 trigger 相关。该方法会在两个窗口合并时, 将窗口对应 trigger 的状态进行合并,比如使用会话窗口时。
- clear() 方法处理在对应窗口被移除时所需的逻辑。
前三个方法通过返回 TriggerResult 来决定 trigger 如何应对到达窗口的事件。应对方案有:
- CONTINUE : 什么也不做
- FIRE : 触发计算
- PURGE : 清空窗口内的元素
- FIRE_AND_PURGE : 触发计算,计算结束后清空窗口内的元素
- 清除器/驱逐器(Evictor)
Flink 窗口模式允许特别的算子Evictor(驱逐器),应用在WindowAssigner和trigger之间。通过evictor()方法使用。
Evictor驱逐器能够在element进入Window窗口聚合之前进行移除数据或者在进入Window窗口聚合后,Trigger触发计算操作之前移除数据。
Evictor的2个方法:
evictBefore():移除窗口元素,在Window Function之前调用。
evictAfter():移除窗口元素,在Window Function之后调用。
source.map(x->{
String[] split = x.split(":");
return Tuple2.of(split[0],Integer.valueOf(split[1]));
//自定义同一个key 5个数据计算一次 在进入聚合前清除5个数据
}, Types.TUPLE(Types.STRING,Types.INT)).keyBy(x->x.f0).window(GlobalWindows.create()).trigger(PurgingTrigger.of(CountTrigger.of(5))).evictor(CountEvictor.of(5)).reduce((y1, y2)->{
y1.f1+=y2.f1;
return y1;
}).map(x->{
x.f0+="[处理时间]"+ LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy年MM月dd日HH 时mm分ss秒SSS毫秒"));
return x;
},Types.TUPLE(Types.STRING,Types.INT)).print("global window function");
16、状态(State)
flink分为有状态和无状态:
- 不需要借助历史数据进行计算的算子称为无状态算子。比如:map、flatmap、filter等。

- 需要借助历史数据进行计算的算子叫有状态算子。比如:reduce、sum等。
离线计算不需要状态,离线任务失败了,重启任务重读一遍输入数据,最后把昨天数据重新计算一遍即可。
实时任务失败重新计算一遍就不可以,实时任务第一就是时效性,重新计算违背了时效性原则。
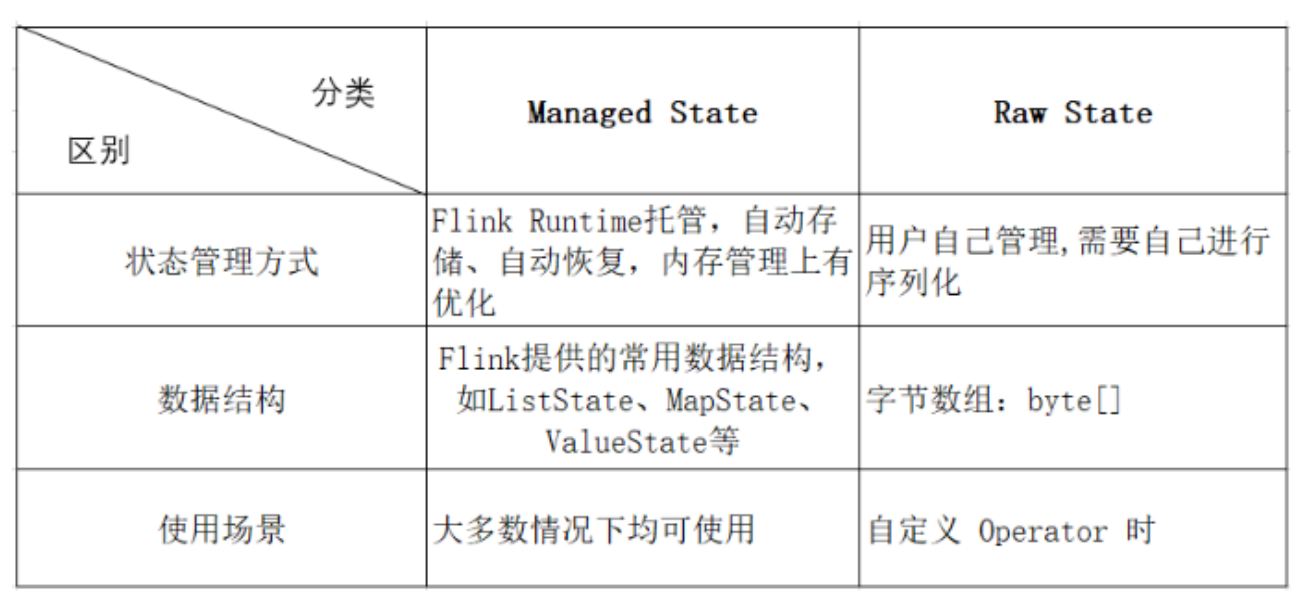
- 原始状态
原始状态则是自定义的,相当于就是开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复;用字节数组来存储,一般情况下不推荐使用。
- 托管状态(推荐使用)
托管状态就是由Flink统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由Flink实 现,我们只要调接口就可以;
托管状态是由Flink的运行时(Runtime)来托管的;在配置容错机制后,状态会自动持久化保 存,并在发生故障时自动恢复。
Flink提供了值状态(ValueState)、列表状态(ListState)、映射状态(MapState)、聚合状态 (AggregateState)等多种结构,内部支持各种数据类型。
- 状态类型
Flink中,一个算子任务会按照并行度分为多个并行子任务执行,而不同的子任务会占据不同的任务槽(slot)由于slot在计算资源上是物理隔离的,因此flink管理的并行任务间是无法共享的只对当前子任务有效。
而聚合、窗口都是要先做keyBy进行按键分区,按键分区之后计算只针对key有效,状态也按key值彼此进行隔离,状态的访问方式可以共享。
因此可以将托管状态分为:算子状态和按键分区状态两类。
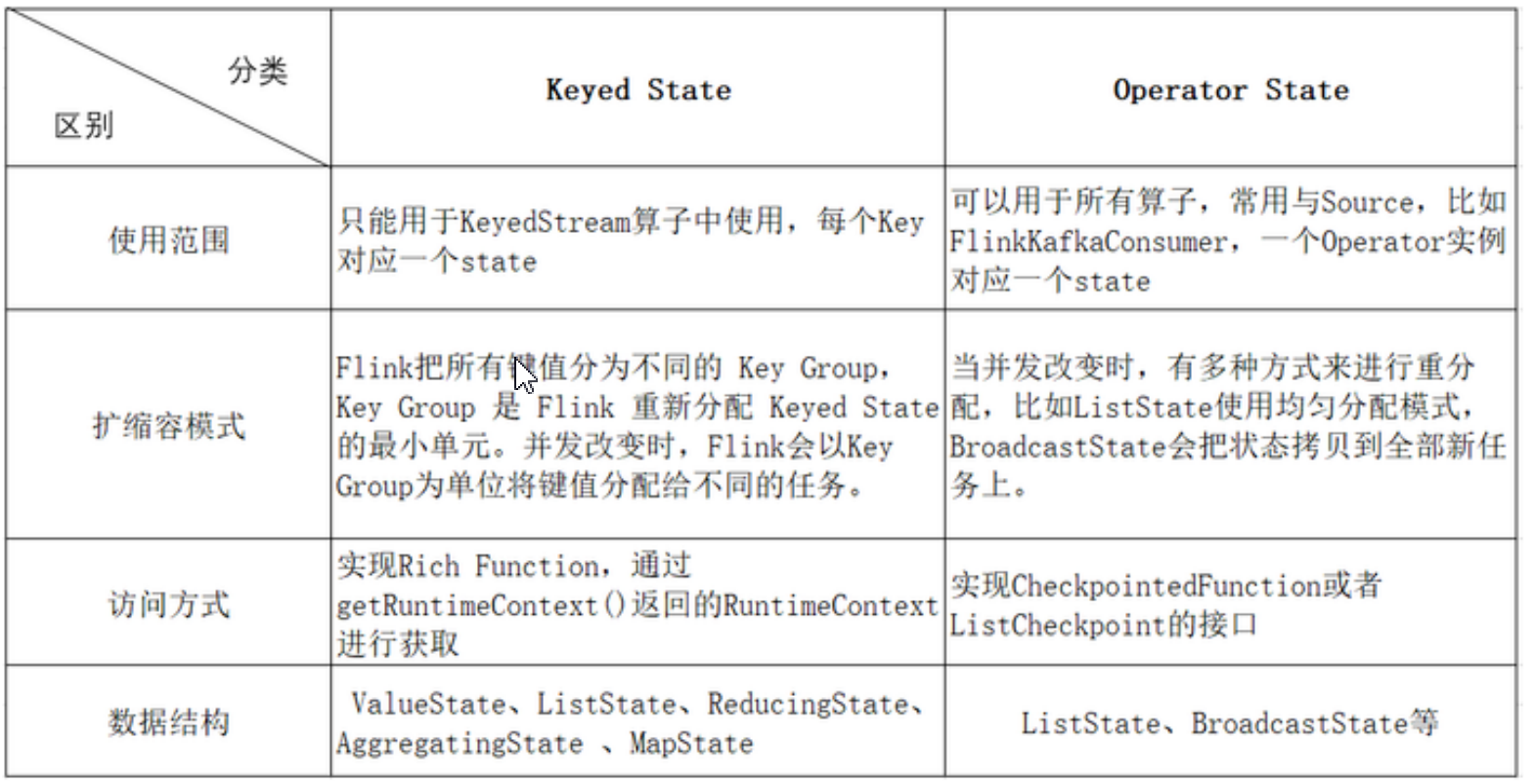
- 算子状态
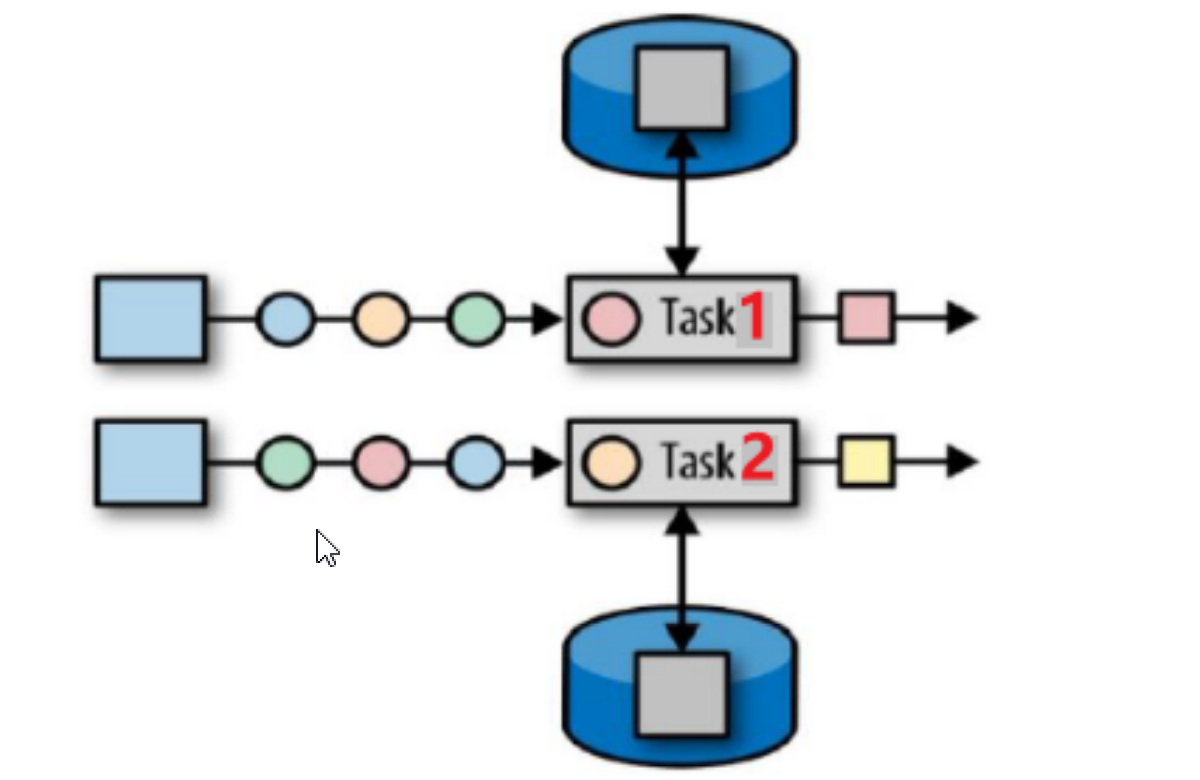
算子状态对于当前算子任务实例,只对当前并行子任务有效。意味着对于一个并行子任务,占据一个分区,它所处理的数据都会访问到相同的状态,对于同一任务而言状态是共享的。
算子状态可以用在所有算子上,使用时相当于一个本地变量,我们可以进一步实现checkpointFunction接口把状态数据进行保存。
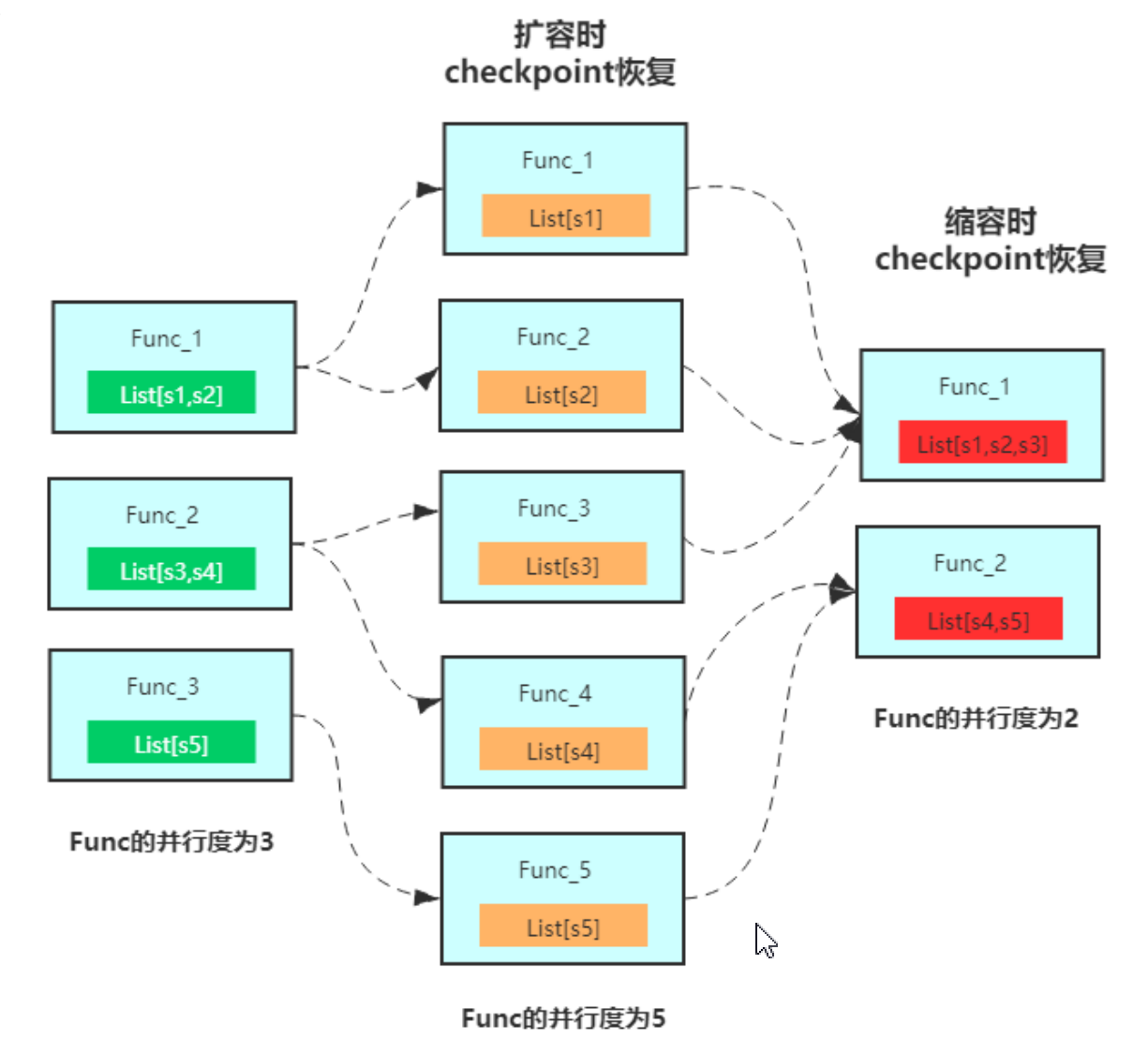
算子状态案例
public static void main(String[] args) throws Exception {
//默认物理状态隔离
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(2);
//5s保存一次
environment.enableCheckpointing(5000);
//把状态数据保存到项目根目录中 以文件形式保存
environment.getCheckpointConfig().setCheckpointStorage("file:///"+System.getProperty("user.dir")+ File.separator+"ckpt");
DataStreamSource<String> source = environment.socketTextStream("localhost", 6379);
source.map(new CusMapFunc()).print("使用listState保存状态");
environment.execute();
}
}
/**
* MapFunction 处理数据
* CheckpointedFunction 保存状态数据持久化
*/
class CusMapFunc implements MapFunction<String,String>, CheckpointedFunction{
private int count=0;
private ListState<Integer> listState;
@Override
public String map(String value) throws Exception {
return value.toUpperCase()+"[计数:]"+count++;
}
//初始化函数
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Integer> descriptor = new ListStateDescriptor<>("CountListState", Types.INT);
this.listState=context.getOperatorStateStore().getListState(descriptor);
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
this.listState.clear();
this.listState.add(count);
}
}
- 键分区状态(keyBy)
状态是根据输入流中定义的键(key)来维护和访问的,所以只能定义在按键分区流 (KeyedStream)中,也就keyBy之后才可以使用 聚合算子必须在keyBy之后才能使用,就是因为聚合的结果是以Keyed State的形式保存的。
常用的内置对象:
- ValueState
: 保存一个可以更新和检索的值。 - ListState
:保存一个元素的列表,可以在列表中添加数据和检索数据。 - ReduceState
:保存一个单值,表示添加到状态的所有值的聚合,相当于使用ListState添加数据,再使用reduceFunction对列表数据进行聚合。 - AggregatingState<IN,OUT>:保存一个单值,表示对所添加状态值聚合,但是与ReduceState不同的时,AggregatingState聚合类型和添加类型可能不同,其他一样。
- MapState<UK,UV>:维护一个映射列表。添加键值对保存数据,可以通过entries()进行检索迭代,使用isEmpty()来判断是否包含任何键值对。
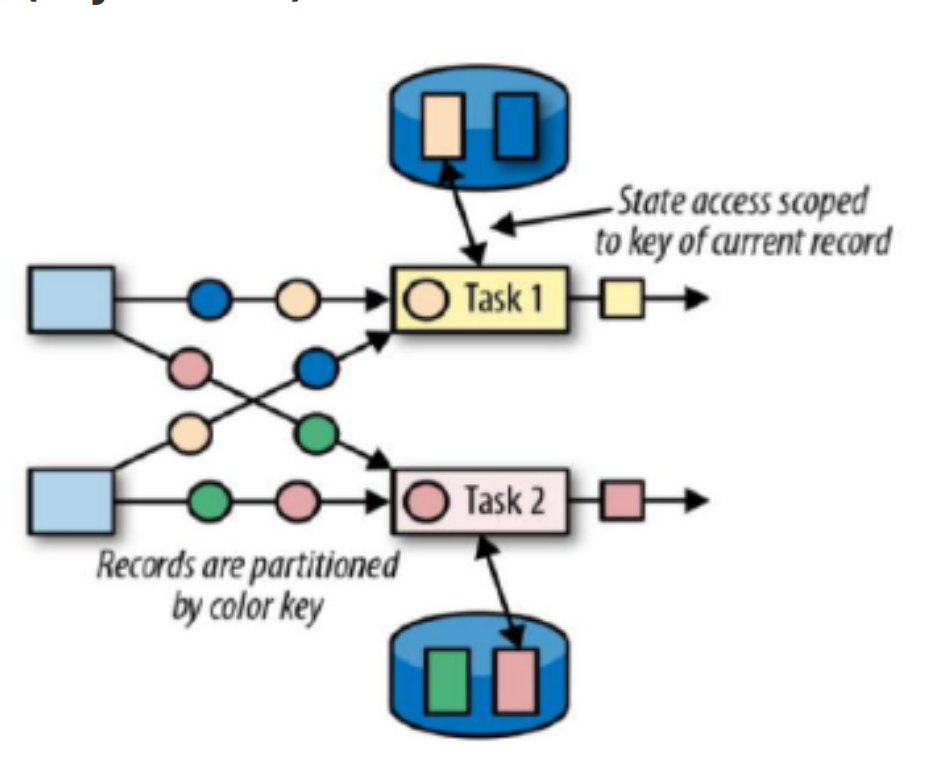
- 案例(keyby后的状态,案例使用了ValueState内置对象)
public static void main(String[] args) throws Exception {
//创建环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
//5s 保存一次
environment.enableCheckpointing(5000);
environment.getCheckpointConfig().setCheckpointStorage("file:///"+System.getProperty("user.dir")+ File.separator+"chk");
DataStreamSource<String> source = environment.socketTextStream("localhost", 19523);
source.map(x->{
String[] split = x.split(":");
return Tuple2.of(split[0],Integer.parseInt(split[1]));
},Types.TUPLE(Types.STRING,Types.INT)).keyBy(x->x.f0).reduce(new ReduceFun()).print("聚合函数:");
environment.execute();
}
}
/**
* MapFunction: 处理数据
* CheckpointedFunction: 保存状态数据持久化
* RichReduceFunction: ReduceFunction接口下的抽象实现类
*/
class ReduceFun extends RichReduceFunction<Tuple2<String,Integer>> {
//声明一个状态对象
private ValueState<Tuple2<String,Integer>> valueState;
/**
* @param parameters 环境
* @throws Exception 抛出异常类型
* 类的初始化方法
*/
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<Tuple2<String, Integer>> stateDescriptor = new ValueStateDescriptor<Tuple2<String, Integer>>("valueState", Types.TUPLE(Types.STRING, Types.INT));
this.valueState=getRuntimeContext().getState(stateDescriptor);
}
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
value1.f1+=value2.f1;
valueState.update(value1);
return value1;
}
17、状态后端
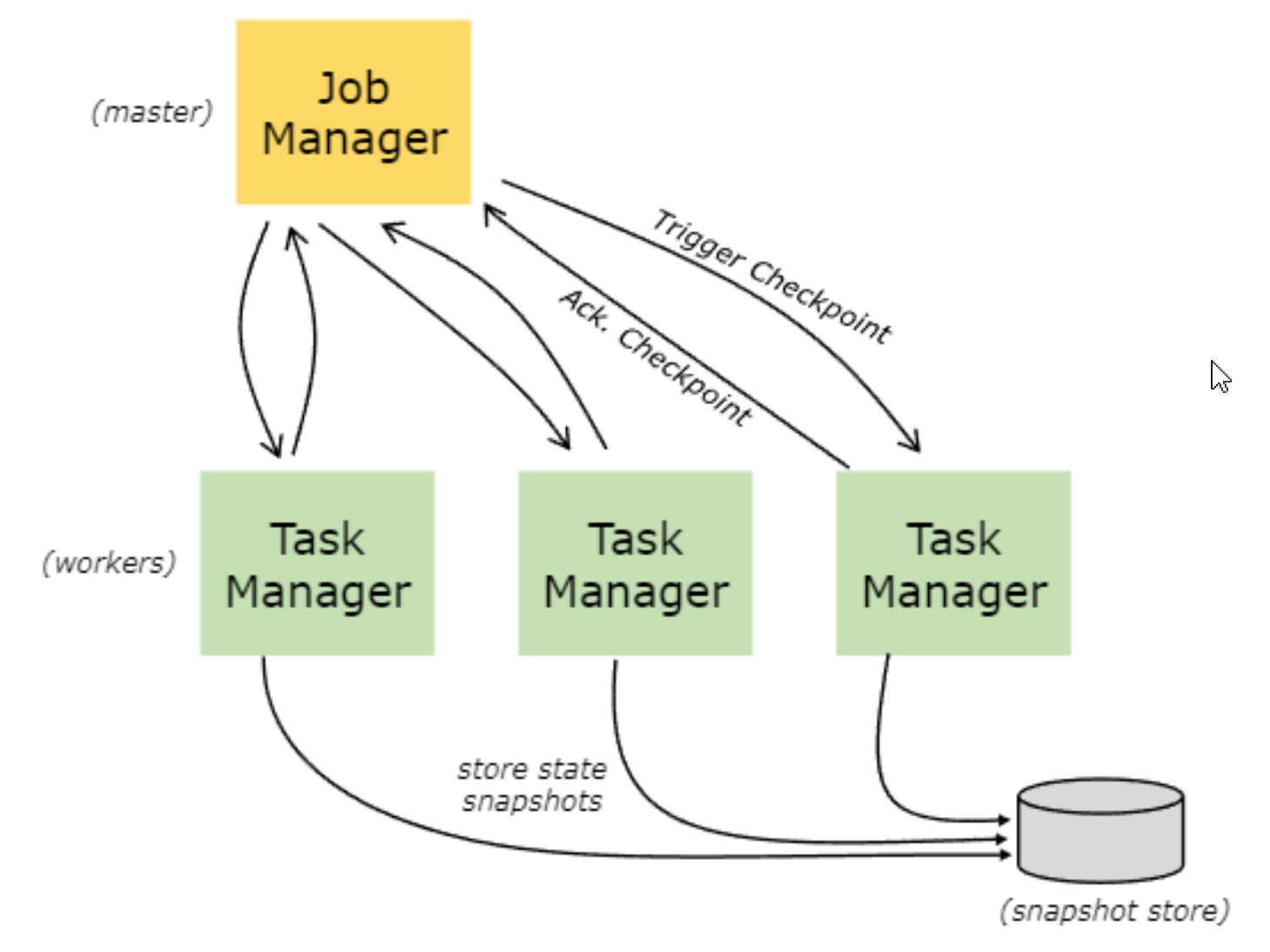
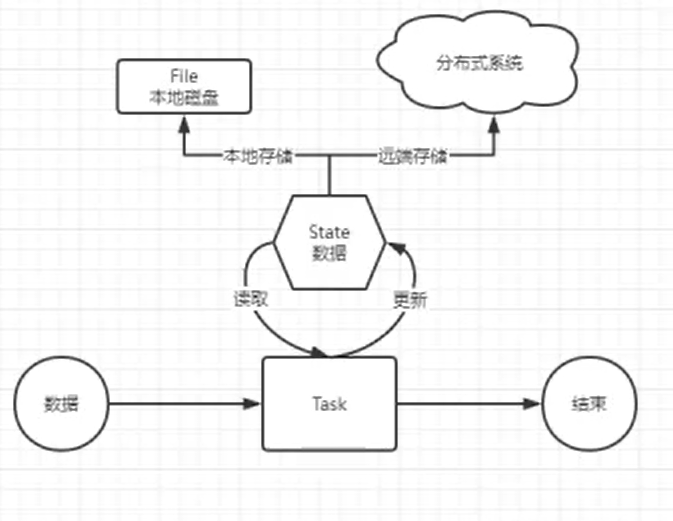
State Backends作用就是用来维护State的。有状态的流计算是Flink一大特点,状态本质是数据,数据需要维护的,数据库就是维护数据的一种方案。
状态后端负责两件事:Local State Management(本地状态管理) 和 Remote State Checkpointing(远程状态备份):
- 本地状态管理:主要任务确保状态的更新和访问,将State以对象的形式存储到JVM堆上(本地内存)或者将State以序列化后存储到RocksDB中(本地磁盘)。如果对访问速度不敏感的建议存储在RocksDB上,特别是数据比较大的情况下。
- 远程状态备份:Flink程序是分布式运行的,各个State都是存储到各个节点上,一旦TaskManager节点出现问题,就会导致State丢失,可以通过checkpointing将本地状态信息备份到存储介质上,可以是分布式的存储系统(HDFS)和数据库(Mysql、Oracle)。
- 存储方式
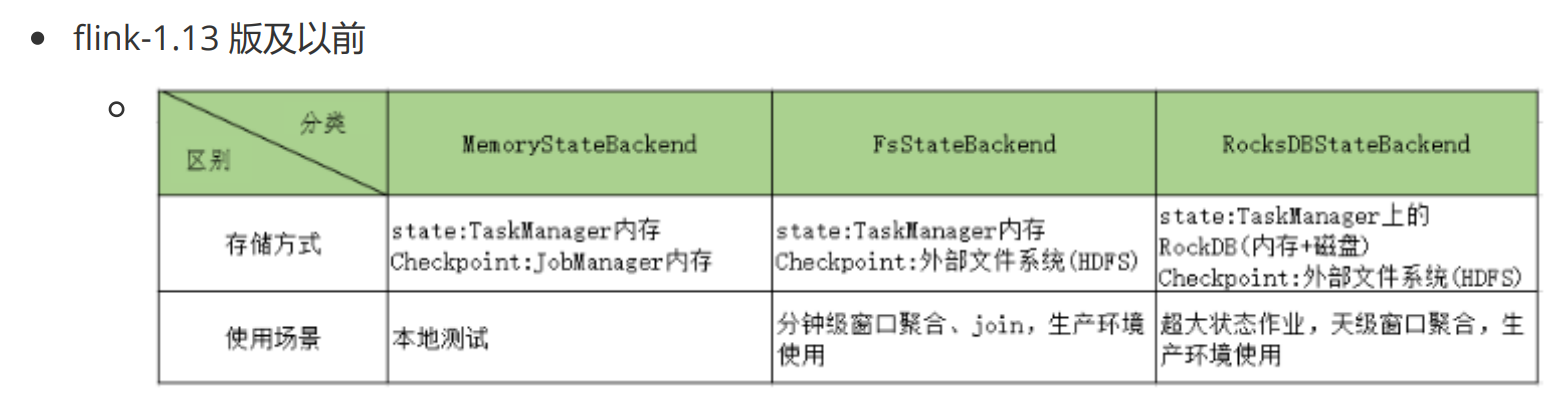
Flink1.13以前存储state有三种方式:内存存储、文件系统存储、RocksDB数据库存储
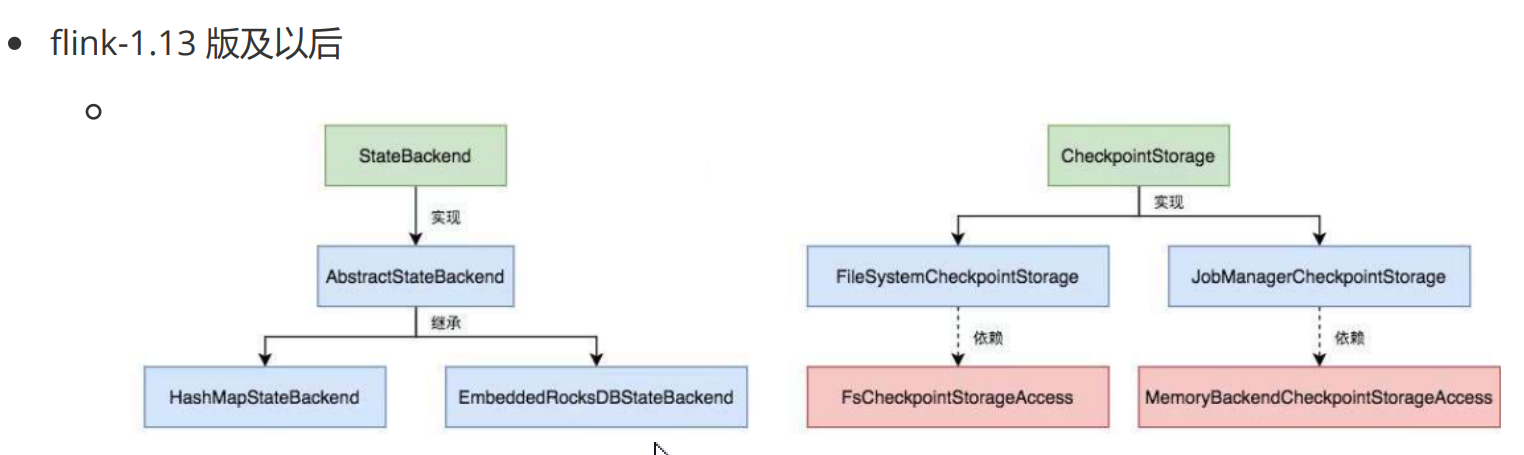
Flink1.13以后,把接口实现类划为两大类:HashMapStateBackend、EmbededRocksDBStateBackend。其中HashMapStateBackend包括了文件系统存储和内存存储,EmbededRocksDBStateBackend包括RocksDb数据库存储。
HashMapStateBackend:存储管理状态类似于管理一个java堆中的对象,key/value的状态和窗口操作都会在一个 hashtable中进行存储状态。默认内存存储大小是5MB,超过内存大小就会溢写到磁盘,读写性能会下降。
EmbededRocksDBStateBackend:该状态后端存储管理状态在RocksDB数据库中,该状态存储在本地taskManager的磁盘目录。RocksDB 的每个 key 和 value 的最大大小为 2^31 字节。这是因为 RocksDB 的 JNI API 是基于 byte[] 的。有内存缓存的部分,也有磁盘文件的部分.RocksDB磁盘文件数据读写速度相对比较快,也支持大规模状态数据。(推荐使用)
- 方式选择
性能维度:HashMap状态后端基于内存存储计算,性能比较强。
扩展维度:EmbededRocksDB状态后端基于数据库本地磁盘计算,利于扩展,直接加数据库!
- 案例(状态后端)
- 加入hadoop相关文件
- 导入依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<flink.version>1.15.2</flink.version>
<scala.version>2.12.2</scala.version>
<log4j.version>2.12.1</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!--flink客户端-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!--本地运行的webUI-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
</dependency>
<!--flink与kafka整合-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<!--状态后端-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb</artifactId>
<version>${flink.version}</version>
</dependency>
<!--日志系统-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>5.3.21</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
</dependencies>
- 编码
public class StateBackendTypes {
//状态后端
public static void main(String[] args) throws Exception {
//运行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(2);
environment.enableCheckpointing(5000);
//本地存储
environment.setStateBackend(new EmbeddedRocksDBStateBackend());
//远程存储备份
environment.getCheckpointConfig().setCheckpointStorage("hdfs://master:8020/flink/checkpoints");
DataStreamSource<String> source = environment.socketTextStream("localhost", 6379);
source.map(new MapFunctionDemo()).print();
environment.execute();
}
}
//不能使用RichMapFunction抽象类作为状态后端去保存状态
class MapFunctionDemo implements MapFunction<String,String>, CheckpointedFunction{
//由于使用是算子状态所有只能使用ListState和BroadcastState
private ListState<Integer> vState;
//计数
private int count=0;
@Override
public String map(String value) throws Exception {
count++;
return value+"[计数:]"+count;
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
vState.clear();
vState.add(count);
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
//初始化状态
ListStateDescriptor<Integer> countState = new ListStateDescriptor<>("countState", Types.INT);
this.vState=context.getOperatorStateStore().getListState(countState);
}
}
18、状态TTL
状态文件的有效期(Time To Live)进行存活时长管理,即”新陈代谢“;
淘汰的机制主要是基于存活时间;存活时长的计时器可以在数据被读、写时重置;TTL存活管理粒度是元素级(如:liststate中的每个元素,mapState中的每个entry)。
//设置TTL 60s
StateTtlConfig.newBuilder(Time.seconds(60))
// 当插入、更新时候,该数据的ttl计时重置
.updateTtlOnCreateAndWrite()
// 当读取、更新时候,该数据的ttl计时重置
.updateTtlOnReadAndWrite()
// 不允许返回已经过期但是还没清理的数据
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
// 允许返回已经过期但是还没清理的数据
.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
// ttl的时间语义:设置为处理时间
.setTtlTimeCharacteristic(StateTtlConfig.TtlTimeCharacteristic.ProcessingTime)
// ttl的时间语义:设置为处理时间
.useProcessingTime()
// 增量清理(每一条状态数据被访问,会驱动过期检查以及清除)
.cleanupIncrementally(1000,true)
// 全量快照清理策略(ck时候,保存到快照文件的值包含未过期的状态数据,并不会清理算子状态数据)
.cleanupFullSnapshot()
// compact 过程中清理过期的状态数据
.cleanupInRocksdbCompactFilter(1000)
// 禁用默认后台清理策略
.disableCleanupInBackground()
.build();
19、窗口联结
- Join(inner join)
Join都是利用window的机制,按照指定字段和窗口进行inner join。先将数据缓存在Window State中,触发窗口时执行join(内连接)计算。
按照窗口类型操作分为:Tumbling Window Join、Sliding Window Join、Session Window Join
- Tumbling Window Join
执行窗口时间滚动时,具有公共键和公共翻滚窗口的所有元素成对组合联接,一个流中元素在其滚动窗口中没有来自另一个流的元素,因此不会被发射。
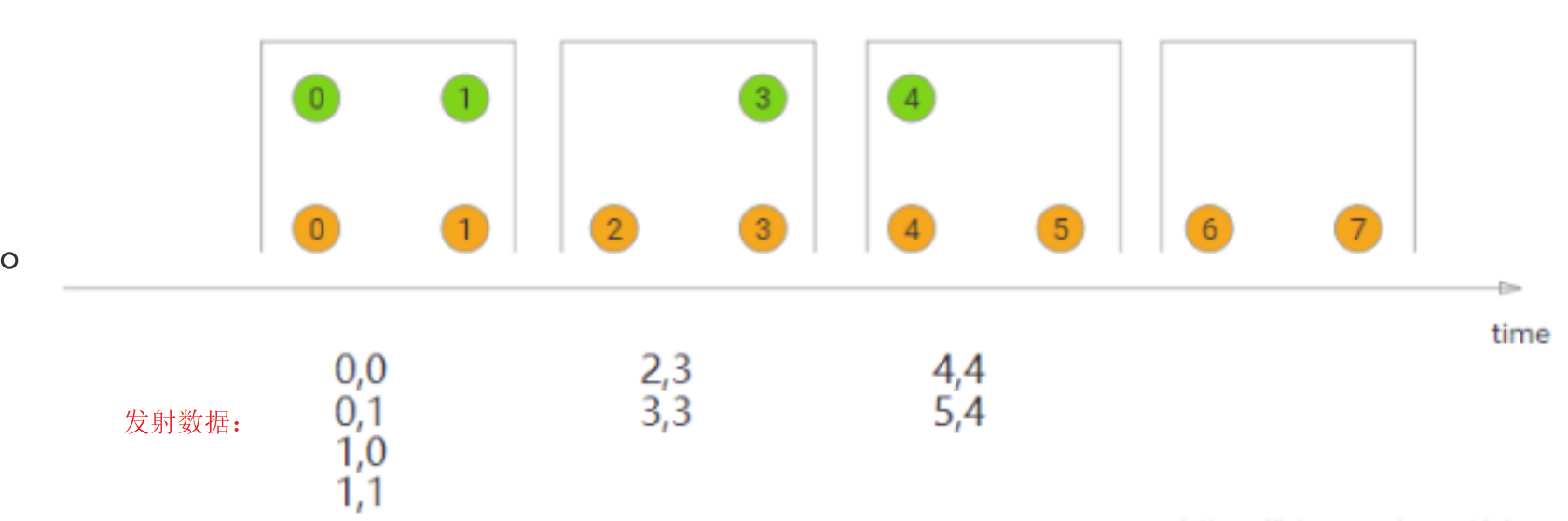
- Sliding Window Join
在执行滑动窗口联接时,具有公共键和公共滑动窗口的所有元素将作为成对组合联接,传递给JoinFunction或FlatJoinFunction。在当前滑动窗口中,一个流的元素没有来自另一个流的元素不会发射。
某些情下,元素会连接到一个滑动窗口中,但不会连接到另一个滑动窗口中。

x轴下方的连接元素是传递给每个滑动窗口的JoinFunction的元素。在这里,您还可以看到, 例如,在窗口[2,3]中,橙色②与绿色③连接,但在窗口[1,2]中没有与任何对象连接。(特殊情况)
- Session Window Join
在执行会话窗口联接时,具有相同键(当“组合”时满足会话条件)的所有元素以成对组合方式联 接,并传递给JoinFunction或FlatJoinFunction。 同样,这执行一个内部连接,所以如果有一个会话窗口只包含来自一个流的元素,则不会发出任何 输出!
我们定义了一个会话窗口连接,其中每个会话被至少1ms的间隔分割。
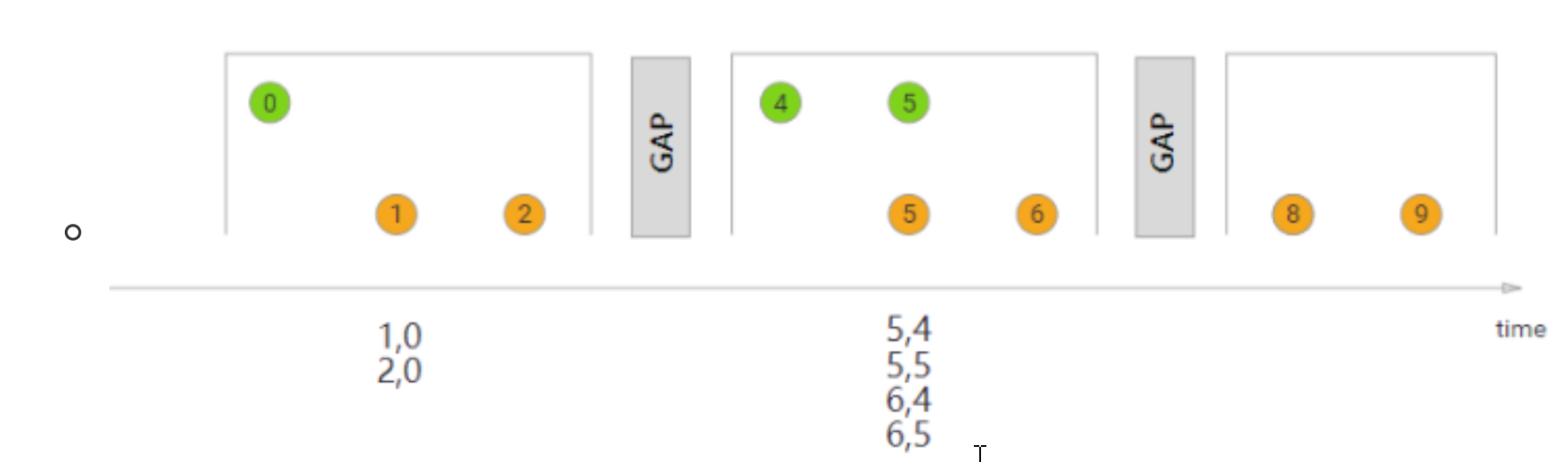
- 代码(滑动窗口join案例)
//窗口联接 所谓的窗口联接就是 在一个窗口中 有两种流进行join 就计算出结果
//如果窗口中只有一种流 那么就不会计算发射出结果!
public static void main(String[] args) throws Exception {
new Thread(()->{
KafkaProducer<String, String> producer = KafkaUtils.getProducer();
for (int i=0;i<300;i++){
String joinKey = RandomStringUtils.randomAlphabetic(8).toUpperCase();
ProducerRecord<String,String> record1=new ProducerRecord<>("goods_infor",joinKey+i,joinKey+":infor+"+i+":"+System.currentTimeMillis());
producer.send(record1);
ProducerRecord<String,String> record2=new ProducerRecord<>("goods_price",joinKey+i,joinKey+":price+"+i+":"+(System.currentTimeMillis()-5000L));
producer.send(record2);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(3);
KafkaSource<String> goodsInfor = KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setTopics("goods_infor")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> goodsIn = environment.fromSource(goodsInfor, WatermarkStrategy.noWatermarks(), "goodsInfor");
//设置水位线整理数据格式
SingleOutputStreamOperator<Tuple3<String, String, Long>> goodsInfoOperator = goodsIn.map(x -> {
String[] split = x.split(":");
return Tuple3.of(split[0], split[1], Long.parseLong(split[2]));
}, Types.TUPLE(Types.STRING, Types.STRING, Types.LONG)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(
new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long recordTimestamp) {
return element.f2;
}
}
));
KafkaSource<String> goodsPrice = KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setTopics("goods_price")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> goodsPri= environment.fromSource(goodsPrice, WatermarkStrategy.noWatermarks(), "goodsPrice");
SingleOutputStreamOperator<Tuple3<String, String, Long>> goodsPriceOperator = goodsPri.map(x -> {
String[] split = x.split(":");
return Tuple3.of(split[0], split[1], Long.parseLong(split[2]));
}, Types.TUPLE(Types.STRING, Types.STRING, Types.LONG)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(
new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long recordTimestamp) {
return element.f2;
}
}
));
//进行流与流之间的联接 窗口联接前先设置水位线
goodsPriceOperator.join(goodsInfoOperator)
.where(p -> p.f0)
//如果是滚动窗口join 使用TumblingEventTimeWindows 会话窗口使用EventTimeSessionWindow
.equalTo(i -> i.f0).window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(3)))
.apply(new JoinFunction<Tuple3<String, String, Long>, Tuple3<String, String, Long>, String>() {
@Override
public String join(Tuple3<String, String, Long> first, Tuple3<String, String, Long> second) throws Exception {
return "["+first+"]["+second+"]";
}
}).print("slidingEventInnerJoin--");
environment.execute();
}
- CoGroup
相当于Outer join,除了输出匹配元素外,未能匹配的元素也会输出。
用于DataStream时返回是CoGroupedStreams,用于DataSet时返回是CoGroupOperatorSets
//窗口联接 CoGroup所谓的窗口联接就是 在一个窗口中 有两种流进行join 就计算出结果
//如果窗口中只有一种流 也会发射
public static void main(String[] args) throws Exception {
new Thread(() -> {
KafkaProducer<String, String> producer = KafkaUtils.getProducer();
for (int i = 0; i < 300; i++) {
String joinKey = RandomStringUtils.randomAlphabetic(8).toUpperCase();
ProducerRecord<String, String> record1 = new ProducerRecord<>("goods_infor", joinKey + i, joinKey + ":infor+" + i + ":" + System.currentTimeMillis());
producer.send(record1);
ProducerRecord<String, String> record2 = new ProducerRecord<>("goods_price", joinKey + i, joinKey + ":price+" + i + ":" + (System.currentTimeMillis() - 5000L));
producer.send(record2);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(3);
KafkaSource<String> goodsInfor = KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setTopics("goods_infor")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> goodsIn = environment.fromSource(goodsInfor, WatermarkStrategy.noWatermarks(), "goodsInfor");
//设置水位线整理数据格式
SingleOutputStreamOperator<Tuple3<String, String, Long>> goodsInfoOperator = goodsIn.map(x -> {
String[] split = x.split(":");
return Tuple3.of(split[0], split[1], Long.parseLong(split[2]));
}, Types.TUPLE(Types.STRING, Types.STRING, Types.LONG)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(
new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long recordTimestamp) {
return element.f2;
}
}
));
KafkaSource<String> goodsPrice = KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setTopics("goods_price")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> goodsPri = environment.fromSource(goodsPrice, WatermarkStrategy.noWatermarks(), "goodsPrice");
SingleOutputStreamOperator<Tuple3<String, String, Long>> goodsPriceOperator = goodsPri.map(x -> {
String[] split = x.split(":");
return Tuple3.of(split[0], split[1], Long.parseLong(split[2]));
}, Types.TUPLE(Types.STRING, Types.STRING, Types.LONG)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(
new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long recordTimestamp) {
return element.f2;
}
}
));
//进行流与流之间的联接
goodsPriceOperator.coGroup(goodsInfoOperator)
.where(p -> p.f0).equalTo(i -> i.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.apply(new CoGroupFunction<Tuple3<String, String, Long>, Tuple3<String, String, Long>, String>() {
@Override
public void coGroup(Iterable<Tuple3<String, String, Long>> first, Iterable<Tuple3<String, String, Long>> second, Collector<String> out) throws Exception {
String s = RandomStringUtils.randomAlphabetic(8);
for (Tuple3<String, String, Long> f : first) {
out.collect(s + "------>" + f);
}
for (Tuple3<String, String, Long> v : second) {
out.collect(s + "------>" + v);
}
}
}).print("coGroupWin:");
environment.execute();
}
- Interval Join
在有些场景下,我们要处理的时间间隔可能并不是固定的。
比如,在交易系统中,需要实时地对每一笔交易进行核验,保证两个账户转入转出数额相 等,也就是所谓的“实时对账”。
为了应对基于时间的窗口联结已经无能为力的需求,Flink提供了一种叫作“间隔联结”(interval join)的合流操作。
间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否 有来自另一条流的数据匹配。
间隔联结的两条流A和B,也必须基于相同的key;下界lowerBound应该小于等于上界 upperBound,两者都可正可负;间隔联结目前只支持事件时间语义。
间隔联结在代码中,是基于KeyedStream的联结(join)操作。
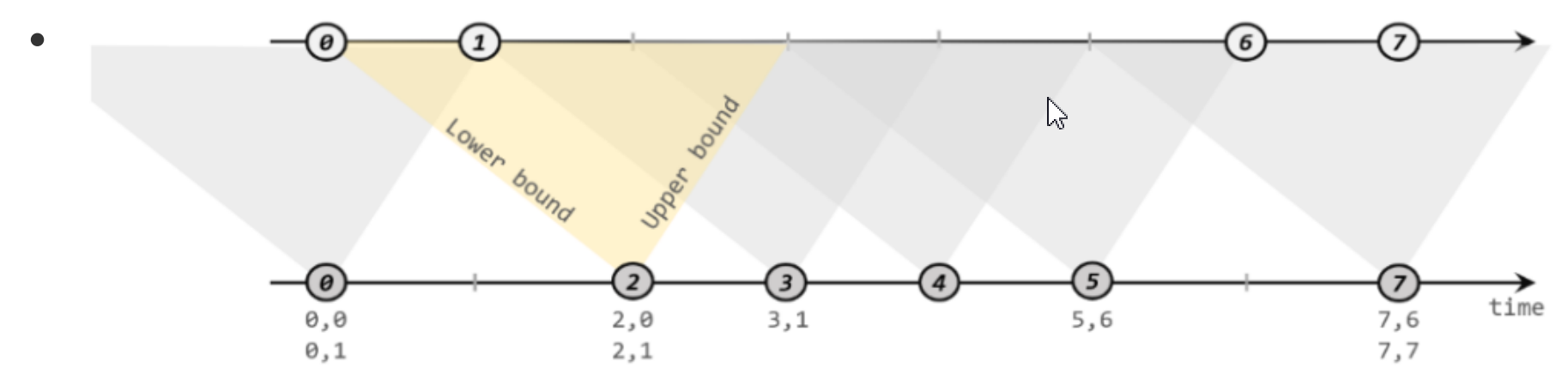
- 案例(interval join案例)
/**
*
* @param args interval join 在短时间内对数据安全性要求较高时,为了防止时间延迟丢失数据
* 在需要操作的数据前后扩充时间范围 在时间范围内能够进行联接操作
* 比如转账操作 转账数据和入账数据为了保证实时 必须在时间内进行联接操作并且数据不能丢失!
* @throws Exception
*/
public static void main(String[] args) throws Exception {
new Thread(()->{
KafkaProducer<String, String> producer = KafkaUtils.getProducer();
for (int i=0;i<300;i++){
String joinKey = RandomStringUtils.randomAlphabetic(8).toUpperCase();
ProducerRecord<String,String> record1=new ProducerRecord<>("goods_infor",joinKey+i,joinKey+":infor+"+i+":"+System.currentTimeMillis());
producer.send(record1);
ProducerRecord<String,String> record2=new ProducerRecord<>("goods_price",joinKey+i,joinKey+":price+"+i+":"+(System.currentTimeMillis()-5000L));
producer.send(record2);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}).start();
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(3);
KafkaSource<String> goodsInfor = KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setTopics("goods_infor")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> goodsIn = environment.fromSource(goodsInfor, WatermarkStrategy.noWatermarks(), "goodsInfor");
//设置水位线整理数据格式
SingleOutputStreamOperator<Tuple3<String, String, Long>> goodsInfoOperator = goodsIn.map(x -> {
String[] split = x.split(":");
return Tuple3.of(split[0], split[1], Long.parseLong(split[2]));
}, Types.TUPLE(Types.STRING, Types.STRING, Types.LONG)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(
new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long recordTimestamp) {
return element.f2;
}
}
));
KafkaSource<String> goodsPrice = KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setTopics("goods_price")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> goodsPri= environment.fromSource(goodsPrice, WatermarkStrategy.noWatermarks(), "goodsPrice");
SingleOutputStreamOperator<Tuple3<String, String, Long>> goodsPriceOperator = goodsPri.map(x -> {
String[] split = x.split(":");
return Tuple3.of(split[0], split[1], Long.parseLong(split[2]));
}, Types.TUPLE(Types.STRING, Types.STRING, Types.LONG)).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner(
new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long recordTimestamp) {
return element.f2;
}
}
));
//进行流与流之间的联接 使用interval join window
//设置在当前时间前后5s 可以在一段范围内 对顺序要求性较高的数据 进行聚合操作!
goodsPriceOperator.keyBy(x->x.f0)
.intervalJoin(goodsInfoOperator.keyBy(y->y.f0))
.between(Time.seconds(-5),Time.seconds(5))
.process(new ProcessJoinFunction<Tuple3<String, String, Long>, Tuple3<String, String, Long>, String>() {
@Override
public void processElement(Tuple3<String, String, Long> left, Tuple3<String, String, Long> right, ProcessJoinFunction<Tuple3<String, String, Long>, Tuple3<String, String, Long>, String>.Context ctx, Collector<String> out) throws Exception {
out.collect("["+left+"]["+right+"]");
}
}).print("intervalJoin--");
environment.execute();
}
20、Flink 容错机制
批数据处理时,如果在处理过程中出现系统崩溃,我们重启系统后可以重新计算。
流数据处理,本身数据源源不断的产生,一旦系统处理过程中崩溃了,必须恢复出崩溃前的状态才能进行数据的继续处理,因此需要一种机制能对系统内各种状态进行持久化容错。
Fink-EOS:Exactly-Once Semantics指端到端一致性,从数据读取、引擎计算、写入外部存储的整个过程中,即使机器或软件出现故障,都确保数据仅处理一次,不会重复、也不会丢失,一批数据从注入到输出结果整个过程,每个环节都处理成功,要么失败回滚。
- 数据处理语义
对于流处理,数据流本身是动态的,即使可以replay buffer部分数据,但default-tolerant做起来会复杂的多。流处理引擎通常为应用程序提供三种数据处理语义:最多一次、至少一次和精确一次。
一致性:At Most Once< At Least Once<Exactly once<End to End Exactly Once
- At Most Once
本质有可能会数据丢失,这本质是简单的恢复方式,直接从失败处的下个数据开始恢复程序,之前的失败数据处理就不管了,这种方式可能丢失数据出现少消费。
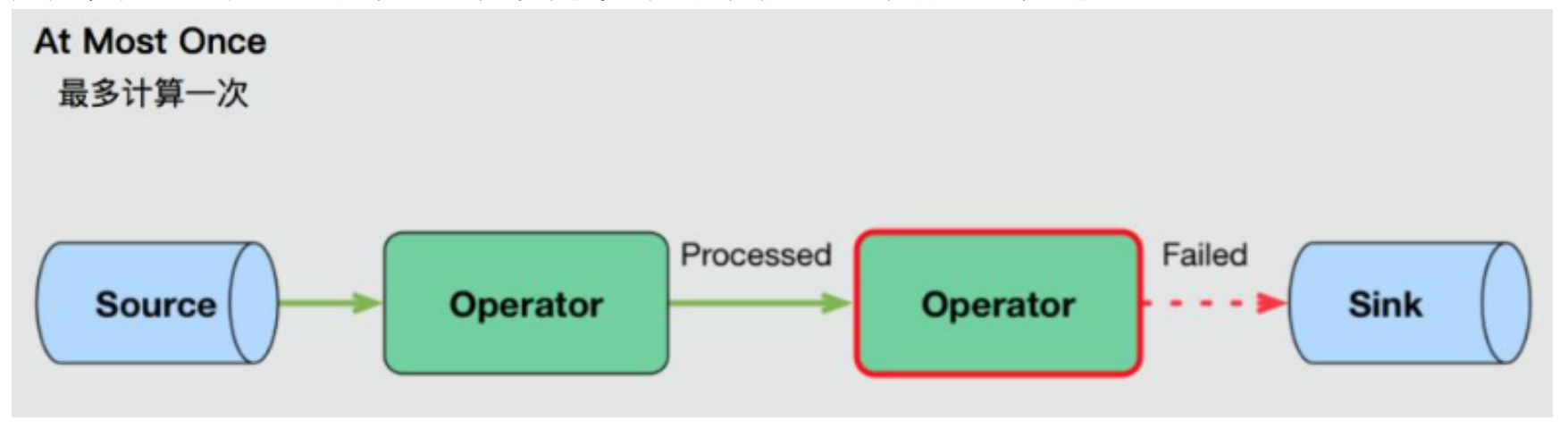
- At Least Once
应用程序在所有算子都保证数据或事件被处理一次。意味如果事件在流应用程序完全处理之前丢失,则将从源头或重新传输事件,因此有可能重新处理数据。
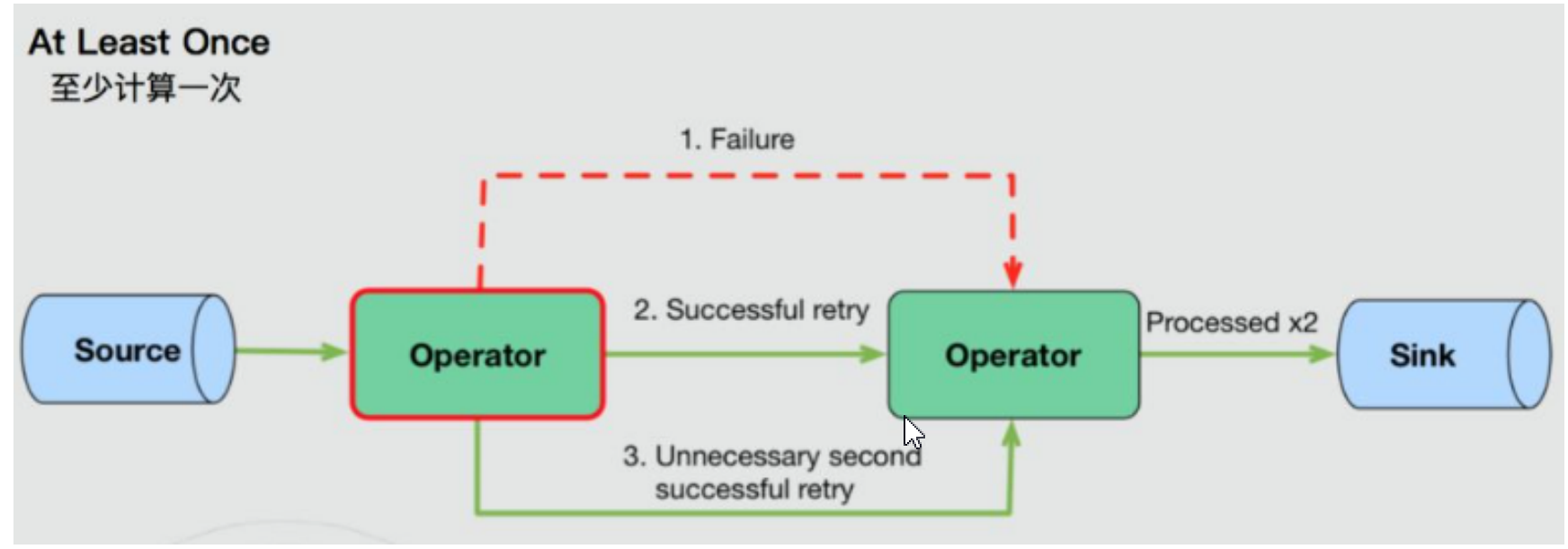
- Exactly-once
每一条信息只能被流处理一次,即使在各种故障下,流应用中所有算子都保证事件只会被精确一次的处理,Flink实现『精确一次』的分布式快照/状态检查点方法受到 Chandy-Lamport 分布式快照算法的启发。
分布式快照算法:应用程序中每个算子定期做checkpoint保存状态,如果系统中任何地方发生失败,每个算子回滚到最新的全局一致checkpoint,在回滚期间暂停所有处理,源重置与最近checkponit相对应正确的偏移量,整个流应用程序基本上是回到最近一次一致状态,程序从最近一次状态重新启动。
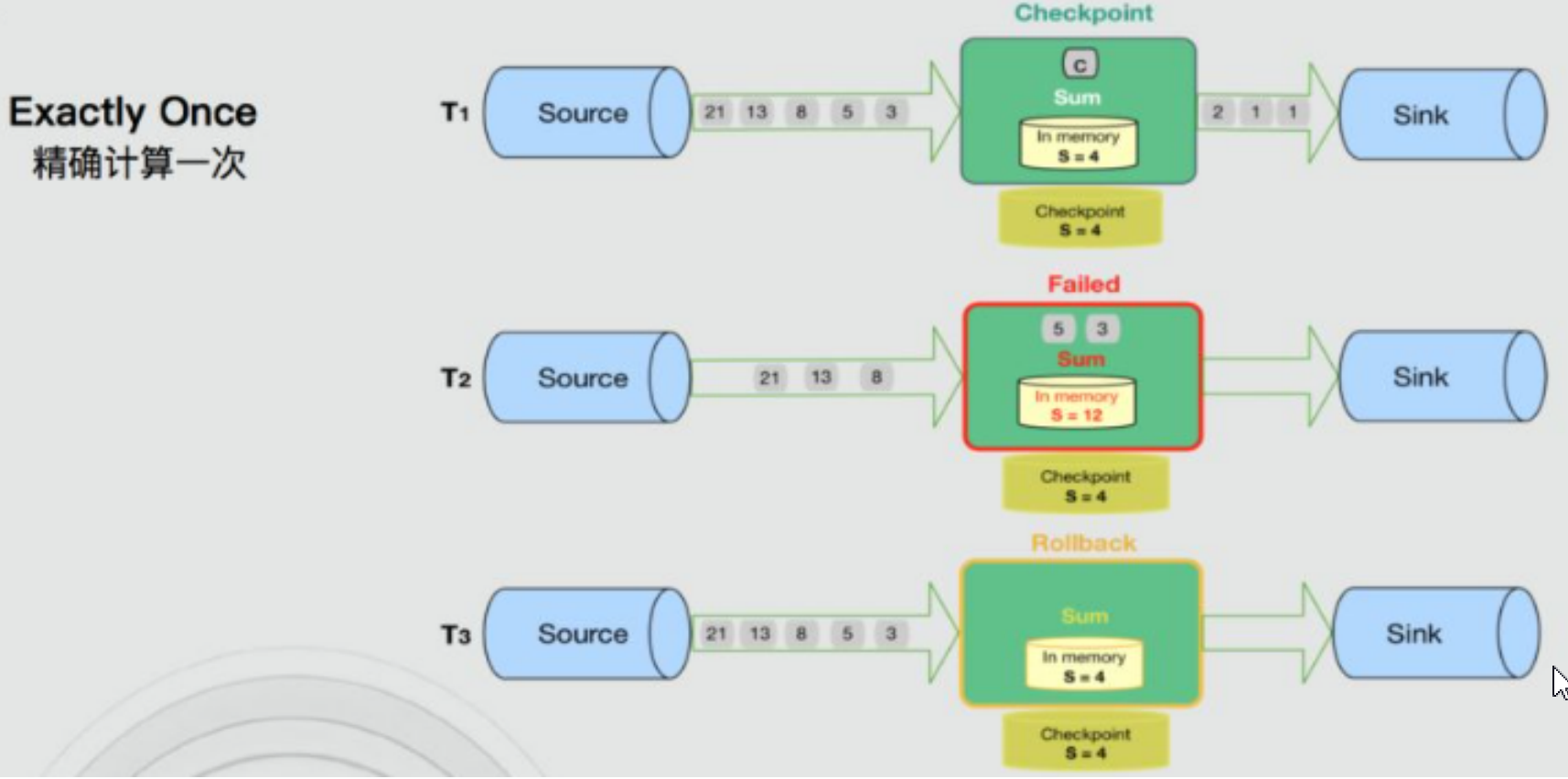
- End-to-End Exactly-Once
Flink 应用从 Source 端开始到 Sink 端结束,数据必须经过的起始点和结束点,每个环节都精确到一次
End-to-End Exactly-Once保证所有记录仅影响内部和外部状态一次。
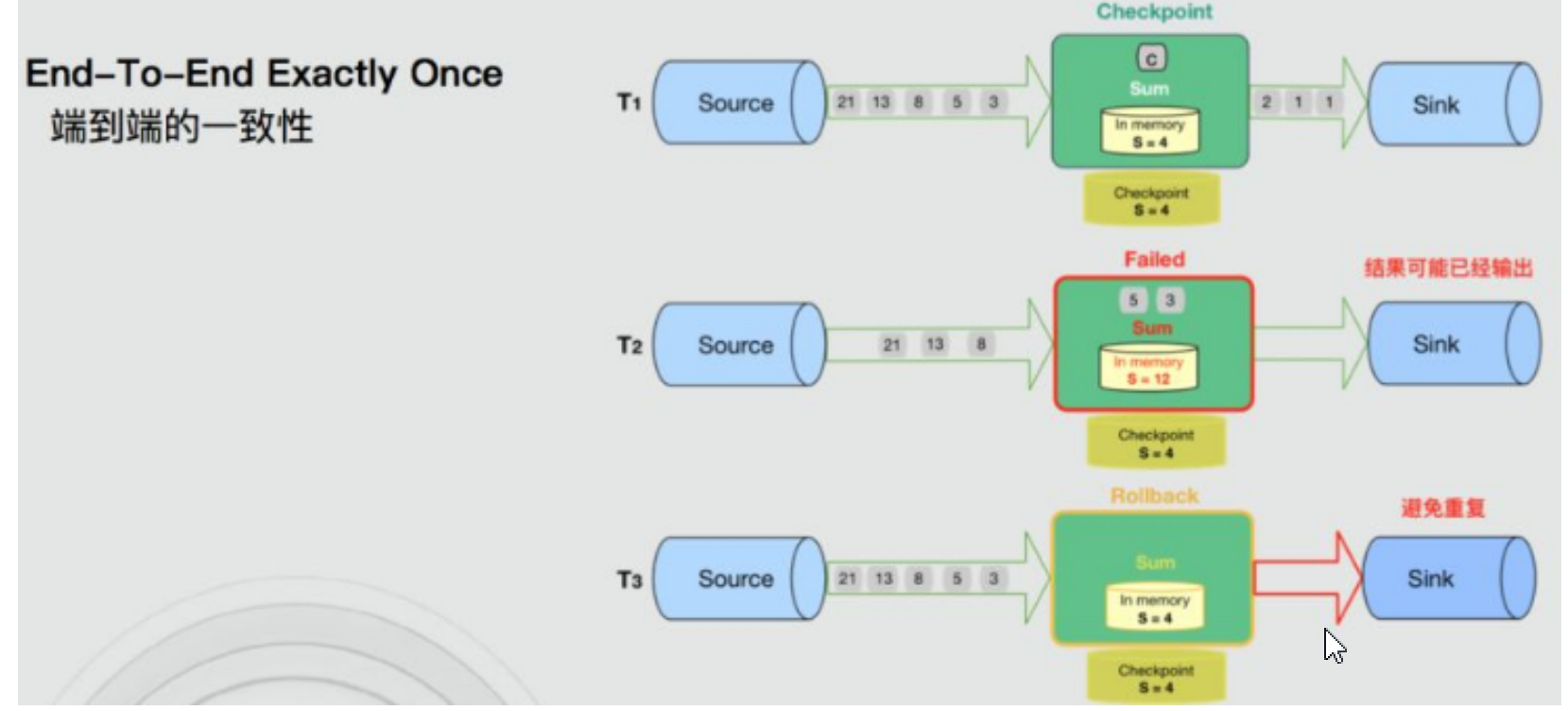
- checkPoint
checkPonit是flink中的一种容错机制,使得任务失败的时候可以进行重启而不丢失之前的一些信息,需要数据源支持重发机制。
- Chandy-Lamport(分布式快照算法)
特定时间点记录下来的分布式系统的全局状态。主要用途:故障恢复(检查点)、死锁检测、垃圾收集等。
数据模型
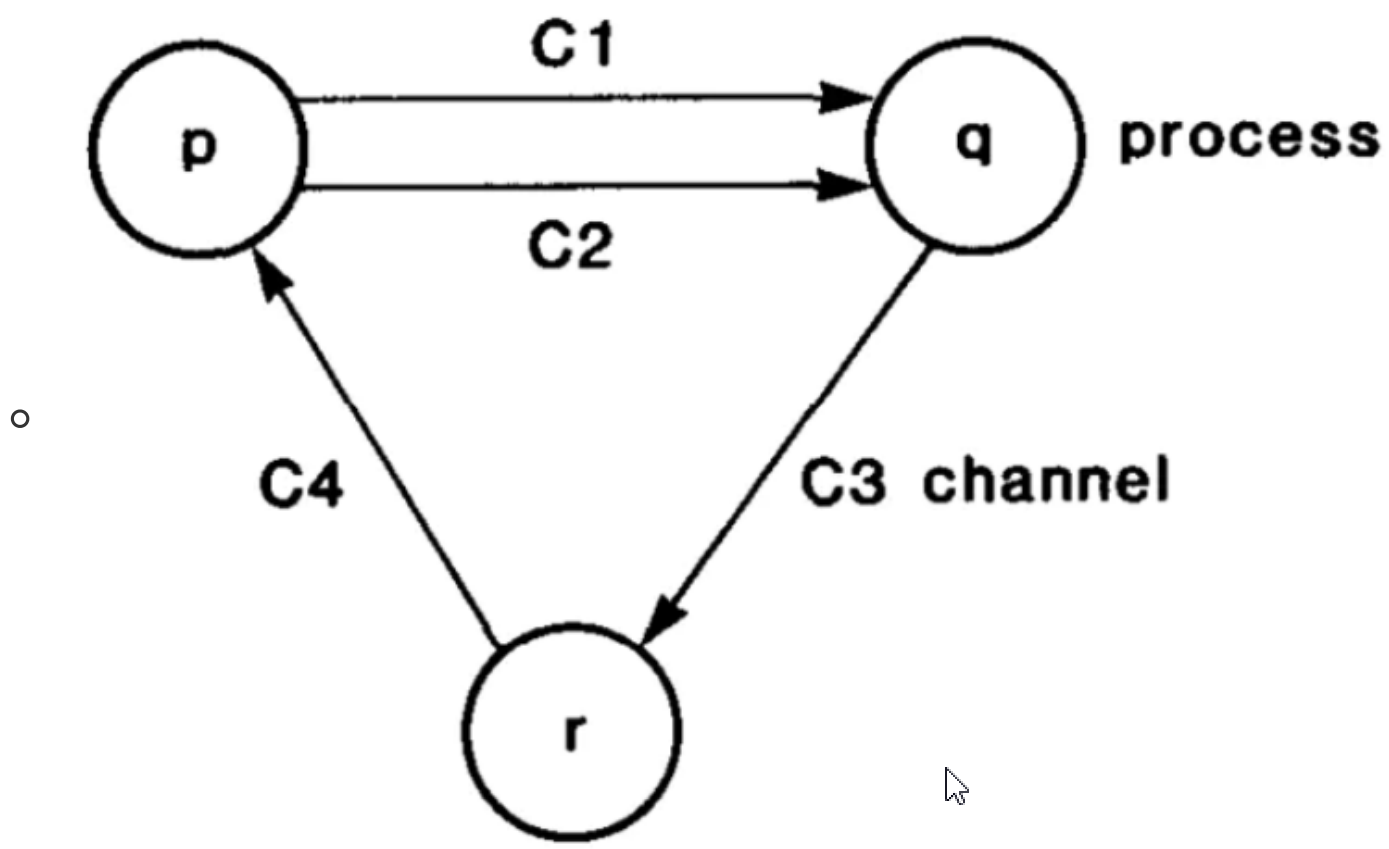
分布式系统全局状态,我们将分布式系统简化成有限个进程和进程之间的channel组成,也就是有向图,其中节点是进程,单箭头表示channel,进程运行在不同的物理机上,分布式快照算法就是为全局状态下分布式系统节点(Node)和channel中状态(Message)拍摄快照,全局状态包括多有进程的状态以及所有channel的状态。
- Flink中应用的CL算法
由于Flink中在计算流数据时,形成一个有向无环图,因此在为每个算子拍摄快照的时候,不需要暂停计算,只需要发送一个Marker标记,发送CheckPoint指令时,从source开始Marker就像水位线一样,Marker到哪个算子,哪个算子开始拍摄快照,直到Sink写出其他组件,而且拍摄的时候不影响上下游继续发送数据。将来恢复数据时,先从每个算子保存的状态恢复,然后从拍摄节点后一个数据重新发送数据重新计算。
- 数据屏障(barrier)
Flink分布式快照里面有一个核心的元素就是流屏障(Stream Barrier)屏障会被插入到数据流中,屏障不包含数据,有一个唯一ID,相当于kafka分区中的最后一条记录的偏移量,如果数据接入多个流就会有多个屏障。数据屏障把不同流数据切割开来,分为快照数据前后,快照数据前表示已经保存的快照,快照数据后表示新的一批计算流数据。
- 屏障对齐(aligned Checkpoint flink1.1版本后新特性)

数据流屏障到达哪个算子,哪个算子就开始保存快照,,整个过程上游分区通过广播模式传输数据给每个算子,等上游所有的子分区的barrier都到齐了,才去保存当前的任务状态。
缺点:如果不是同一个输入源的数据流先到达某个分区,而当前计算输入源后到达,就会把先达到分区的数据流存储到算子缓存中等待当前计算输入源计算完成才计算缓存中的数据,这样容易导致数据积压(背压)。
- 屏障对不齐(Unaligned Checkpoint)
为了解决数据在输入源缓存中积压问题,第一个barrier在到input buffer队列最前端开始触发checkpoint操作,然后barrier立即向下游的output buffers队列最前端传输,等barrier标记发到下游以后,需要做一个短暂的暂停,暂停的时候把算子的state和input buffers、output buffers中的数据打标记(checkpoint)持久化保存,直到下一个屏障到达operator时,数据标记结束,后期可以通过恢复快照把状态数据和buffers中数据进行恢复重新计算,恢复性能受限于 Checkpoint 间隔时间,间隔时间越长恢复越慢。
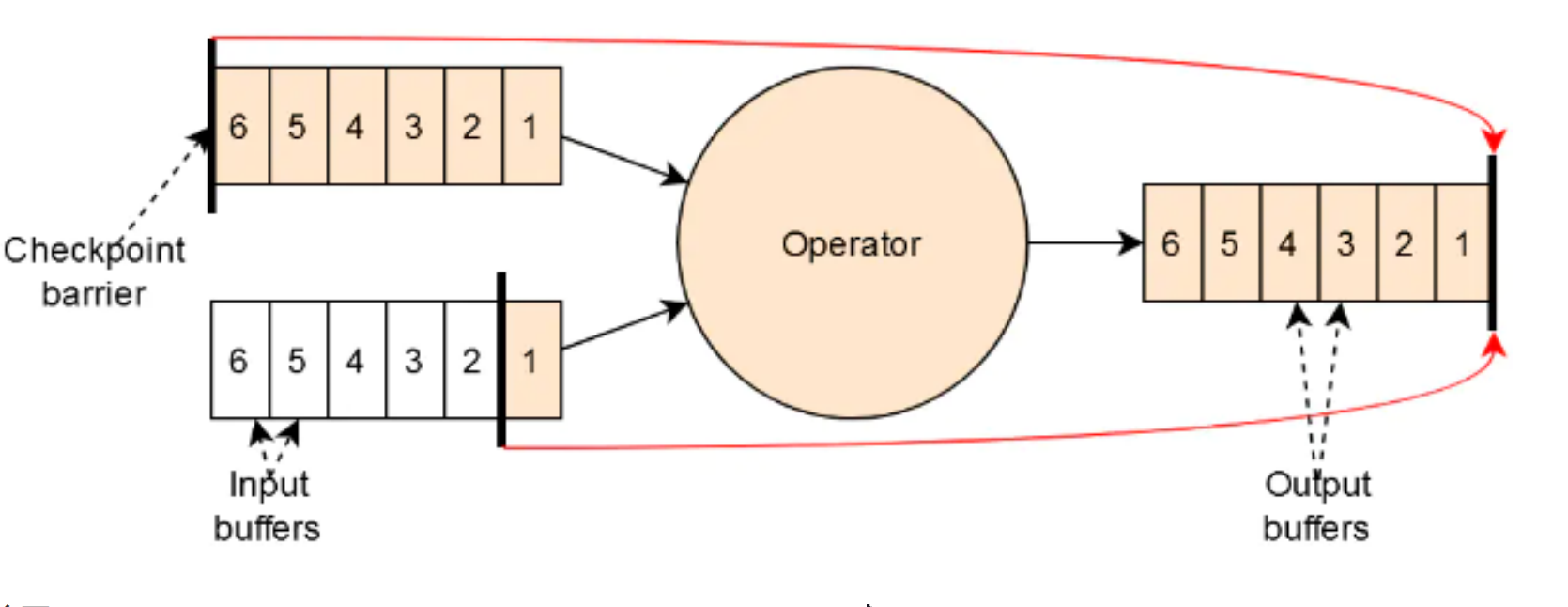
- SavePoint
savePoint保存点和checkpoint功能一样,只不过SavePoint是手动保存状态,CheckPoint是flink自动保存状态数据,savaPoint作为实时任务的全局镜像,底层代码和CheckPoint的代码是一样的。
Checkpoint 的主要目的是为意外失败的作业提供恢复机制(如 tm/jm 进程挂了)。 Checkpoint 的生命周期由 Flink 管理,即 Flink 创建,管理和删除 Checkpoint - 无需用户交 互。
Savepoint 由用户创建,拥有和删除。 他们的用例是计划的,手动备份和恢复。 Savepoint 应用场景,升级 Flink 版本,调整用户逻辑,改变并行度,以及进行红蓝部署等。Savepoint 更多地关注可移植。
- 触发SavePoint方式
使用 flink savepoint 命令触发 Savepoint,其是在程序运行期间触发 savepoint。
使用 flink cancel -s 命令,取消作业时,并触发 Savepoint。
使用 Rest API 触发 Savepoint,格式为:*/jobs/:jobid /savepoints*
注意:由于SavePoint是程序的全局状态,对于过大的实时任务,不要频繁触发savepoint;我们在进行SavePoint恢复时,先检查SavePoint文件是否可用,可能存在你上次触发的SavePoint没有成功,任务会启动不起来。
- 容错策略
当Task发生故障时,Flink需要重启出错的Task以及其他受到影响的Task,使作业恢复到正常执行状态;Flink通过重启策略和故障恢复来控制Task重启:
- 重启策略决定是否可以重启以及重启间隔。
- 故障恢复策略决定哪些task需要重启。
Flink作业没有定义重启策略,就会默认加载集群重启策略,如果flink作业有重启策略,优先以flink作业重启策略为主。
可以通过flink集群配置文件flink-conf.yaml来设置默认的重启策略,配置restart-strategy定义策略:
如果没有启用checkpoint,就采用不重启策略。
如果启动checkpoint没有配置重启策略,采用固定延时重启策略,最大尝试重启次数是Integer.MAX_VALUE参数设置。
一、固定延迟重启策略:如果超过重启次数,作业失败。
//配置文件 restart-strategy: fixed-delay 10分钟重启一次 重启3次
ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, // 尝试重启的次数
Time.of(10, TimeUnit.SECONDS) // 延时
));
二、故障率重启策略:故障发生后之后重启策略,也就是当每个时间间隔发生故障的次数超过设定的限制时,作业最终失败!
//配置文件restart-strategy: failure-rate
ExecutionEnvironment env =
ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个时间间隔的最大故障次数
Time.of(5, TimeUnit.MINUTES), // 测量故障率的时间间隔 5分钟内不能超过3次故障 否则任务失败
Time.of(10, TimeUnit.SECONDS) // 下一次重启相隔的时间 10s重启一次
));
三、不重启策略:作业直接失败,不重启
//配置文件restart-strategy: none
ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
四、备用重启策略: 使用集群定义的重启策略!
ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fallbackRestart());
- 恢复策略
Flink 支持多种不同的故障恢复策略,该策略需要通过 Flink 配置文件flink-conf.yaml中的 jobmanager.execution.failover-strategy配置项进行配置:
- full恢复:在全图重启故障恢复策略下,task发生故障时会重启作业中所有Task进行恢复。
- Region恢复:相比于全局重启故障恢复策略,这种策略在一些场景下的故障恢复需要重启的 Task 会更少。 此处 Region 指以 Pipelined 形式进行数据交换的 Task 集合。
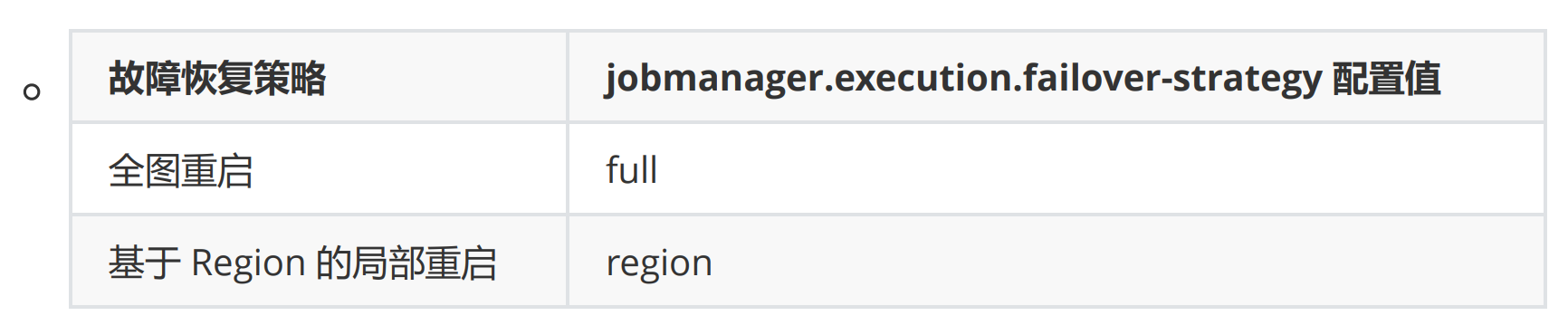
- 如何保证EOS(Exactly-Once Semantics)?
Flink其实很难保证端到端精确一次的时间语义,用户代码被部分存在的可能性永远存在的,我们可以通过有效一次(effectively once)的时间语义保证flink数据的正确性。
实现策略:至少一次+去重 最少一次+幂等性 分布式快照算法
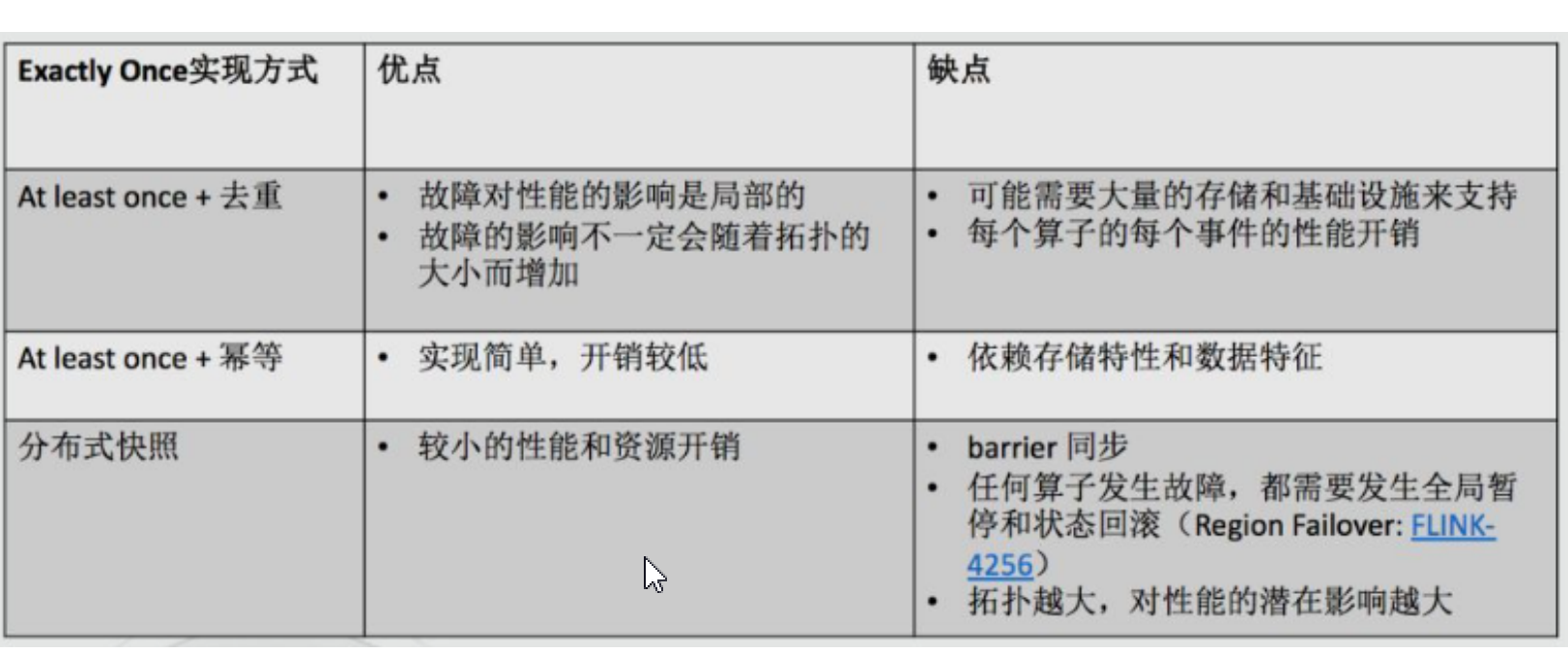
- Flink Source
Flink 的很多 source 算子都能为 EOS 提供保障,如 kafka Source :记录偏移量、重放数据、偏移量记录在state与下游其他算子state一起,经由checkpoint机制实现状态数据的快照统一(把数据计算的整个过程拍摄快照保存)。
- Flink Operator
flink使用分布式快照算法实现了整个数据流中各种算子状态数据快照统一,如果这条(批)数据在中间任何过程失败,则重启恢复后,所有算子的 state 数据都能回到 这条数据从未处理过时的状态。flink的快照备份精确到算子级别,也可以对全局数据做快照。Spark 仅仅是针对Driver 的故障恢复 Checkpoint。
- Flink Sink
Sink面临的问题是作业失败重启,写入重复数据。
Sink中处理有效一次语义分为:
- 幂等性写入方式
- 任意多次向一个系统中写入数据,只对目标系统产生一次结果影响,如:重复向HashMap中插入同一个key值数据二元对,最终数据还是插入时的数据,这就是一个幂等操作。此外redis、Hbase等也支持。幂等操作可能会出现暂时数据不一致,不过当数据的重放逐渐超过发生故障的点的时候,最终的结果还是一致 的。
- 采用WAL预写日志提交方式(不支持事务的sink组件)
- 在计算一个时间间隔内的数据,在整个过程先到sink数据先写入WAL日志保存到外部存储设备中,等整个过程完成计算成功保存了checkpoint,完成数据一致性的时候,再把WAL日志中的数据进行日志回放提交数据。
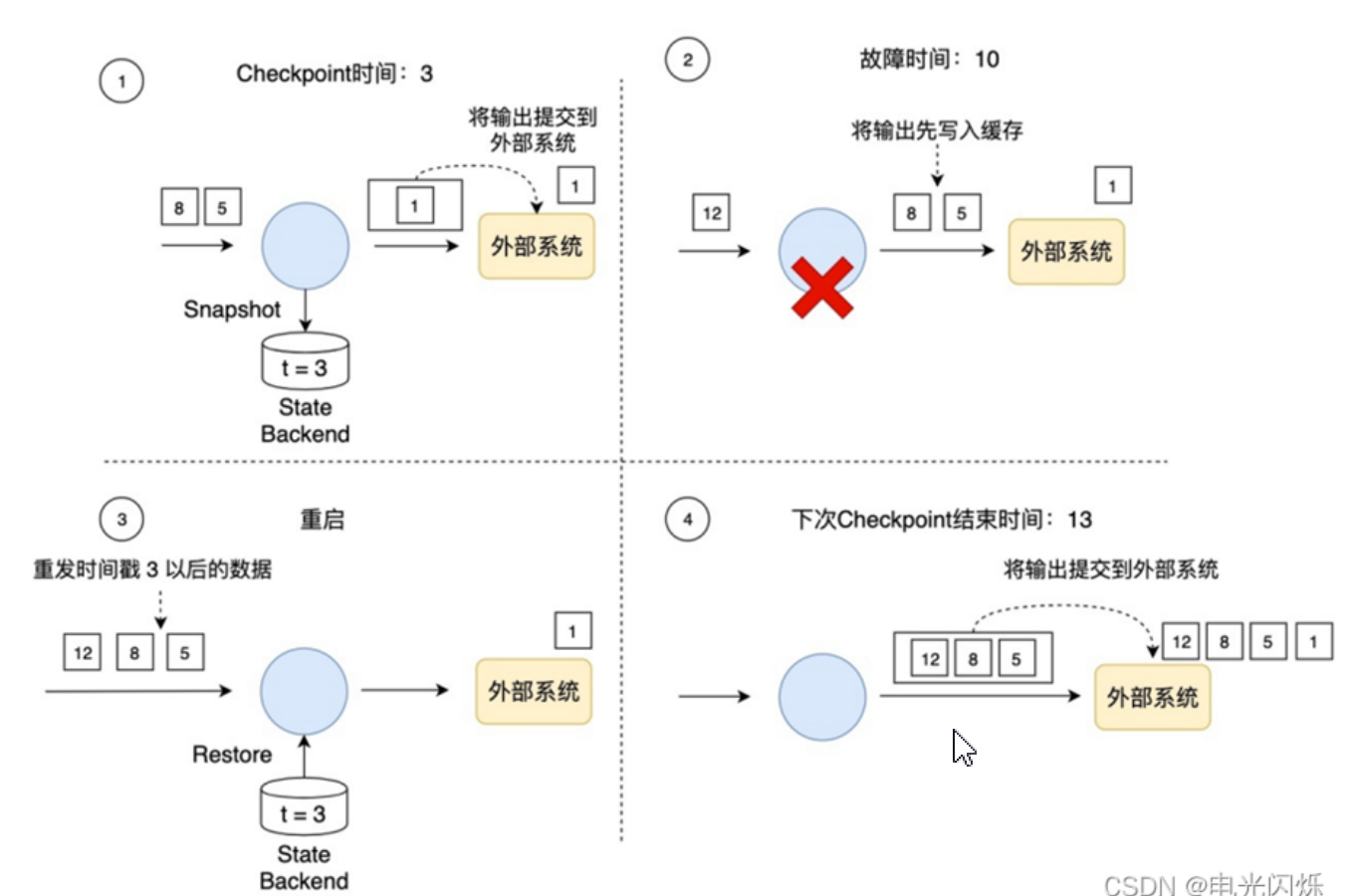
- 二阶段提交方式(事务提交)
- 二阶段提交保证事务的ACID原则(原子性 一致性 隔离性 可持久化),一个目的两个角色和三个条件。
- 一目的两角色三条件:
- 目的:分布式系统架构下所有节点在进行事务提交时保持一致性(要么全成功要么全失败!)
- 两角色:协调者,负责下达命令工作;参与者,负责认真干活并响应协调者的命令。
- 三条件:分布式中必须存在一个协调者和多个参与者,所有节点之间可以相互通信;所有节点都采用预写日志方式,且日志可靠保存;所有节点不会永久损坏,允许可恢复的短暂损坏。
- 二阶段过程:
- 预提交阶段:协调者向所有参与者发起请求,询问可以执行提交操作,开始等待所有参与者的响应。所有参与者响应请求,将undo和redo信息写入日志持久化。所有参与者响应协调者发起的询问,对于每个参与者节点,如果事务操作执行成功返回同意,反之返回终止。
- 正式提交阶段:如果协调者接收到所有参与者响应的成功信息,协调者就会向所有参与者发送正式提交请求,所有参与者释放事务期间占用的资源;
- 如果协调者收到一个参与者响应的成功信息或者协调者询问时间超时,协调者就会向所有参与者发送事务回滚请求,所有参与者就会对undo redo日志进行事务回滚操作并释放整个事务期间占用的资源。
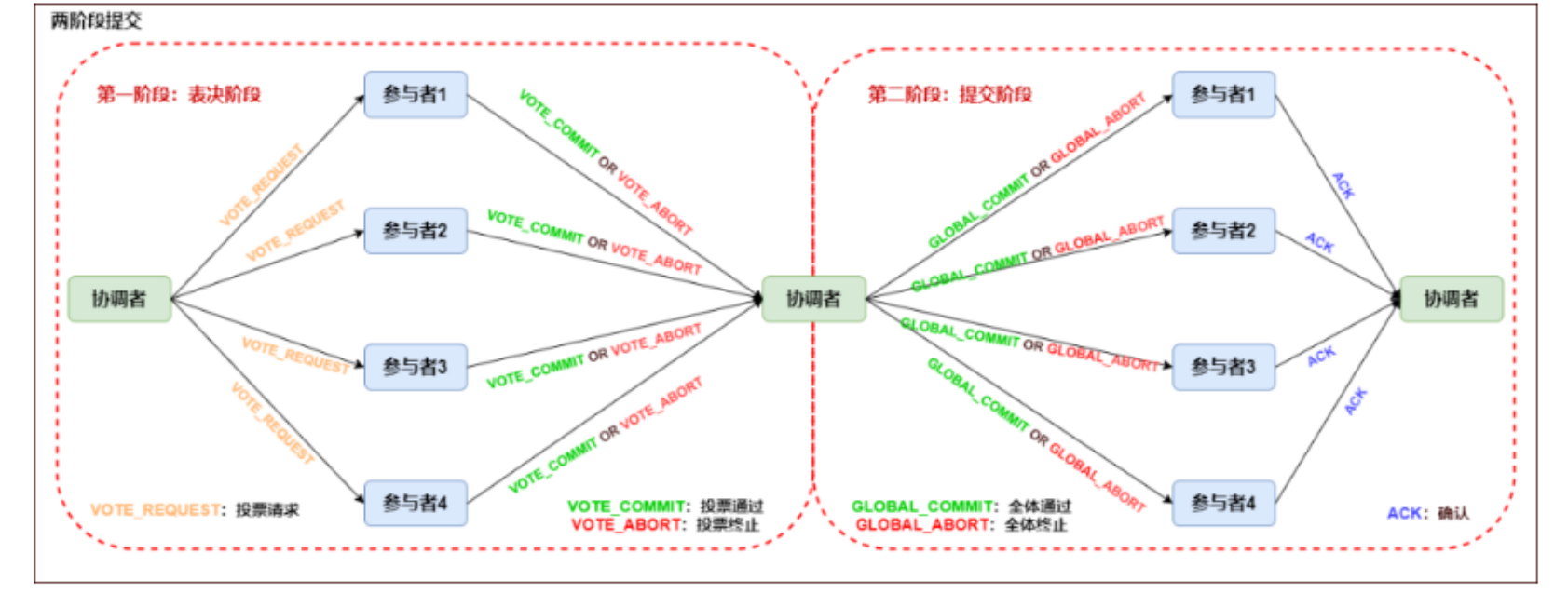
- kafka Sink二阶段提交(Flink应用)
Flink由JobManager协调各个TaskManager进行checkpoint存储,CheckPoint保存在状态后端中。默认状态后端是内存级,Flink消费消息后会开启一个事务,正常写入kafka分区日志标记但未提交,等待所有operator完成各自的预提交,有一个失败operator操作,flink就会回滚到最近的checkpoint。
当所有的operator完成任务时,sink端就会收到checkpoint barrier(检查点分界线),Sink保存当前状态,存入ck中,通知jobManager,并提交外部事务,用于提交外部检查点的数据,JobManager收到所有的确认信息,并发出确定信息给kafka sink,表示ck已经完成,kafka sink收到jobManager发来的确认信息就正式提交数据,kafka sink关闭事务,提交的数据就可以消费。
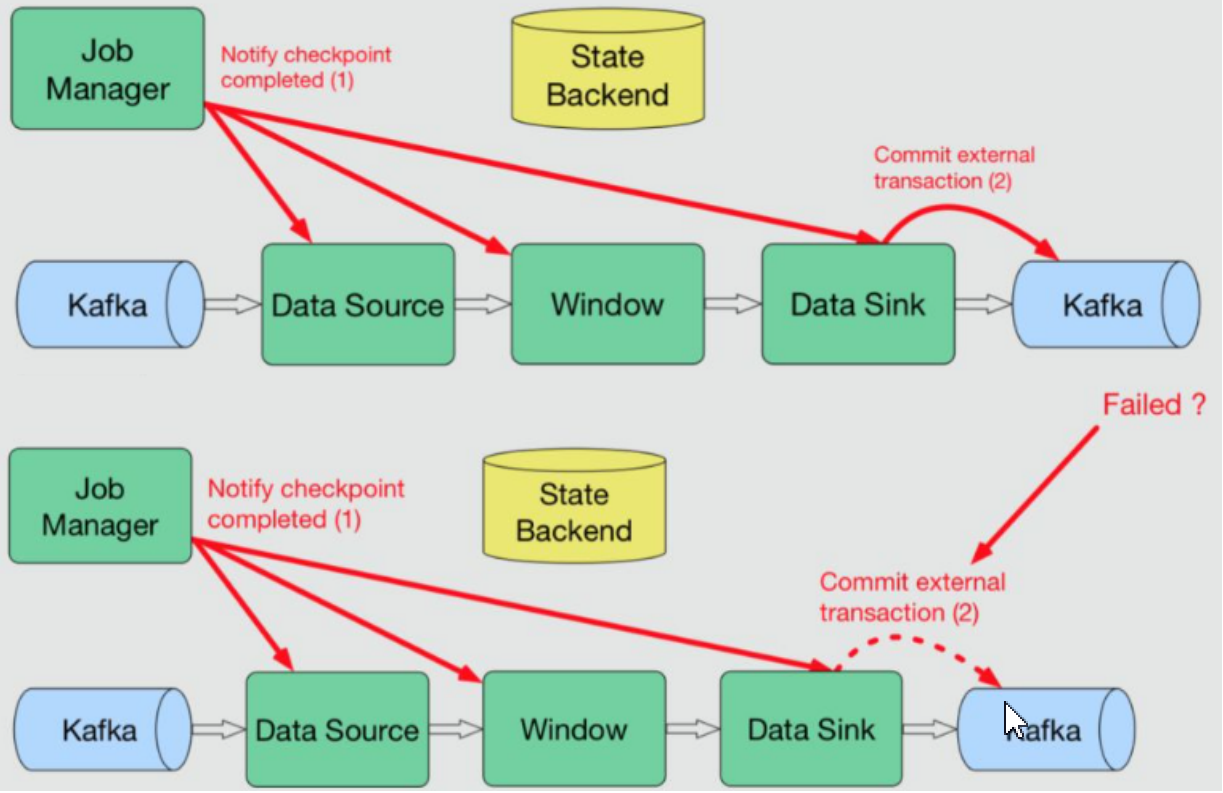
- kafka End To End (案例)
版本说明:Flink1.4版本之前支持精确一次时间语义,仅限应用内部;Flink1.4版本之后,通过两阶段提交支持端到端精确一次时间语义;
kafka要求0.11+,0.11开始添加可kafka事务处理!
- 代码
/**
* 本次代码模拟kafka端到端数据传输
* flink通过二阶段提交(事务)实现了有效一次提交语义
* 版本要求:flink 1.4+ kafka 0.11+
* flink默认事务超时时间是15分钟 而kafka生成者事务超时时间是1小时 注意调整kafkaSink transaction Timeout小于15分钟 否则写入失败!
*/
public class EOSDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度为2
environment.setParallelism(2);
//开启checkpoint保存状态 5s开启一次ck 设置状态后端
environment.enableCheckpointing(5000);
//设置本地存储 保存到RocksDB中
environment.setStateBackend(new EmbeddedRocksDBStateBackend());
//设置远程存储备份 保存到HDFS上
environment.getCheckpointConfig().setCheckpointStorage("hdfs://node1:8020/flink/checkpoints");
//开启最小间隔数 1s保存一次ck
environment.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);
//错误容忍次数 0次
environment.getCheckpointConfig().setTolerableCheckpointFailureNumber(0);
//设置精确一次保存的语义
environment.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//超过30s保存ck就失败
environment.getCheckpointConfig().setCheckpointTimeout(30000);
//ck并行度
environment.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//重试恢复次数3次 每隔10s重试一次 重试超过3次任务失败
environment.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.of(10, TimeUnit.SECONDS)));
//获取kafka数据源
KafkaSource<String> kafkaSource= KafkaSource.<String>builder()
.setBootstrapServers("node1:9092,master:9092,node2:9092")
.setTopics("OutInOrder")
.setGroupId("event-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> source = environment.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource");
SingleOutputStreamOperator<String> transformation = source.map(x -> Tuple3.of(x.split(":")[0], x.split(":")[1], x.split(":")[2]), Types.TUPLE(Types.STRING, Types.STRING, Types.STRING))
.keyBy(x -> x.f0).map(new RichMapFunction<Tuple3<String, String, String>, String>() {
private ValueState<Integer> countState;
private Integer count = 0;
@Override
public String map(Tuple3<String, String, String> value) throws Exception {
count++;
countState.update(count);
return "[key:]" + value.f0 + "[value:]" + value.f1 + "[timestamp:]" + value.f2 + "[次数:]" + countState.value();
}
@Override
public void open(Configuration parameters) throws Exception {
//初始化valueState
ValueStateDescriptor<Integer> descriptor = new ValueStateDescriptor<>("计数", Types.INT);
this.countState = this.getRuntimeContext().getState(descriptor);
}
});
//flink默认事务超时时间是15分钟 而kafka生成者事务超时时间是1小时 注意调整生成者小于15分钟
Properties properties = new Properties();
properties.setProperty("transaction.timeout.ms", "300000");
KafkaSink<String> kafkaSink = KafkaSink.<String>builder().setBootstrapServers("node1:9092,master:9092,node2:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic("KafkaSink")
.setValueSerializationSchema(new SimpleStringSchema()).build())
.setKafkaProducerConfig(properties)
//支持只有一次时间语义应答模式
.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
transformation.sinkTo(kafkaSink);
environment.execute();
}
21、Flink集群部署
Flink的部署有三种模式,分别是Local,Standalone Cluster和Yarn Cluster
前提:Hadoop3.X、kafka0.11+ 、JDK11
flink1.15.2下载网站:
https://www.apache.org/dyn/closer.lua/flink/flink-1.15.2/flink-1.15.2-bin-scala_2.12.tgzJDK11下载网站:
https://www.oracle.com/cn/java/technologies/javase/jdk11-archive-downloads.htmlhadoop-shaded-hadoop-9-***.jar下载地址:
https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.9.0-173-9.0/flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
- standalone环境搭建
安装jdk环境到服务器,安装步骤与jdk1.8一致,安装前如果有jdk1.8版本,应该先删除1.8版本后再安装!
下载包flink1.15.2包并上传到服务器并解压到特定目录下
tar -zxvf flink1.15.2-hadoop3-XXX.tar.gz -C /usr/local/flink
修改${FLINK_HOME}/conf/flink-conf.yaml配置文件(node1节点)
jobmanager.rpc.address: node1
jobmanager.bind-host: 0.0.0.0
taskmanager.bind-host: 0.0.0.0
## taskmanager.host 配置文件在哪个节点上就配置哪个节点
taskmanager.host: node1
taskmanager.numberOfTaskSlots: 2
parallelism.default: 2
rest.address: node1
rest.bind-address: 0.0.0.0
修改${FLINK_HOME}/conf/master文件
node1:8081
修改${FLINK_HOME}/conf/workers
node1
master
node2
再把配置好的flink拷贝到其他节点上(master node2)
rsync -av /usr/local/flink/link1.15.2 root@master:`pwd`
rsync -av /usr/local/flink/link1.15.2 root@node2:`pwd`
修改各自节点的flink-conf.yaml配置文件信息
## taskmanager.host 配置文件在哪个节点上就配置哪个节点
taskmanager.host: master
## taskmanager.host 配置文件在哪个节点上就配置哪个节点
taskmanager.host: node2
配置/etc/profile环境变量
export FLINK_HOME=/usr/local/flink/flink-1.15.2
export PATH=${FLINK_HOME}/bin:$PATH
source /etc/profile 环境生效
- 启动集群
start-cluster.sh
访问UI页面
http://node1:8081
- flink通用系统架构
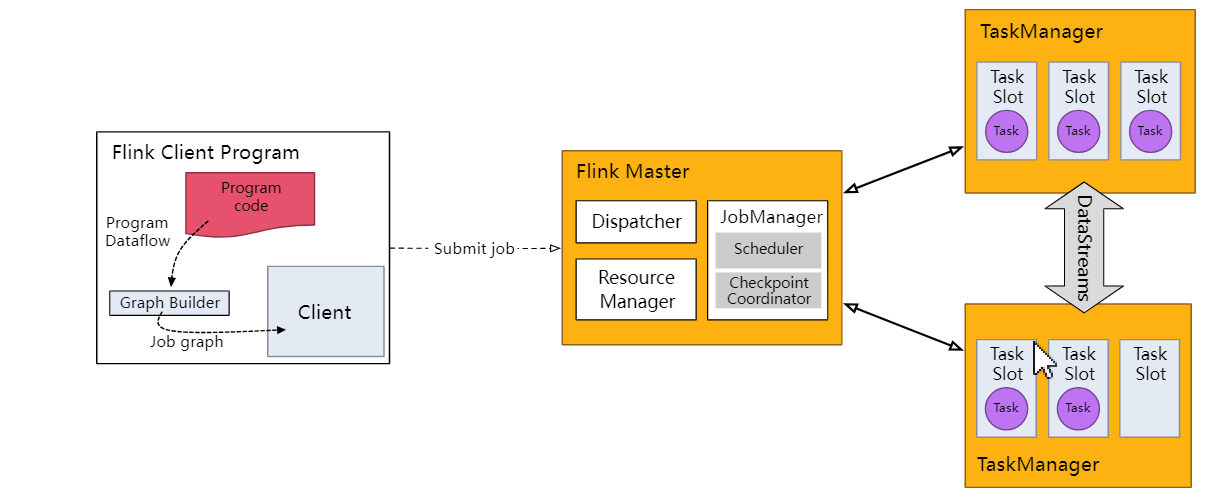
StandAlone不考虑高并发情况下,只有一个FlinkMaster和多个TaskManager,其中JobManager是集群管理者,负责管理调度,而TaskManager是真正执行任务的节点。
客户端提交job作业调用main方法,将代码转化为数据流图(Dataflow Graph),并最终生成作业图(JobGraph),一并发送给JobManager。
Flink Master内部有三个组件:JobManager、ResourceManager、Dispatcher。
- JobManager是jobManager最核心的组件,负责处理单独的作业,一个Job对应一个JobManager,多个Job运行在一个集群中,作业提交时,JobManager接收jar包、数据流图(dataFlow graph)、作业图(jobGraph),JobManager把作业图转为物理层面的执行图,其中包含并发任务。JobManager会向ResouceManager发送请求,申请任务必要的资源,然后把执行图运行到TaskManager上。
- ResourceManager负责资源的分配和管理,所谓的资源就是一组cpu和内存,每一个task任务都需要分配到一个slot上执行。在单机模式下,由于TaskManager是单独启动的·,资源管理器只能分配给可用的TaskManger中得到slot,不会启动新的TaskManager。在Yarn、Mesos等架构下,资源管理器会将空闲的slot分配给JobManager,如果没有足够的slot,资源管理器会发起会话,请求提供TaskManager进程的容器,资源管理器还负责释放TaskManager和计算资源。
- Dispatcher:负责Rest接口,用来提交应用,为每一个提交的作业启动新的JobManager组件。Dispatcher也会启动一个WebUI监控作业执行情况,Dispatcher不是必须的,在不同的部署模式下可能会被忽略。
TaskManager是Flink的工作进程,也称Worker,集群中至少有一个TaskManager,如果是分布式计算,可能有多个TaskManager运行,每个TaskManager都包含一定数量的slot,slot是资源调度的最小单位,限制了并行处理的任务数量。启动后,TaskManager会向资源管理器注册它的slots,ResourceManger收到指令后,TaskManager会将申请的slots提供jobMaster进行调用,JobManager就可以分配任务来执行,执行过程中,TaskManager可以缓冲数据,可以跟运行同一job的TaskManager交换数据。
- Standalone模式
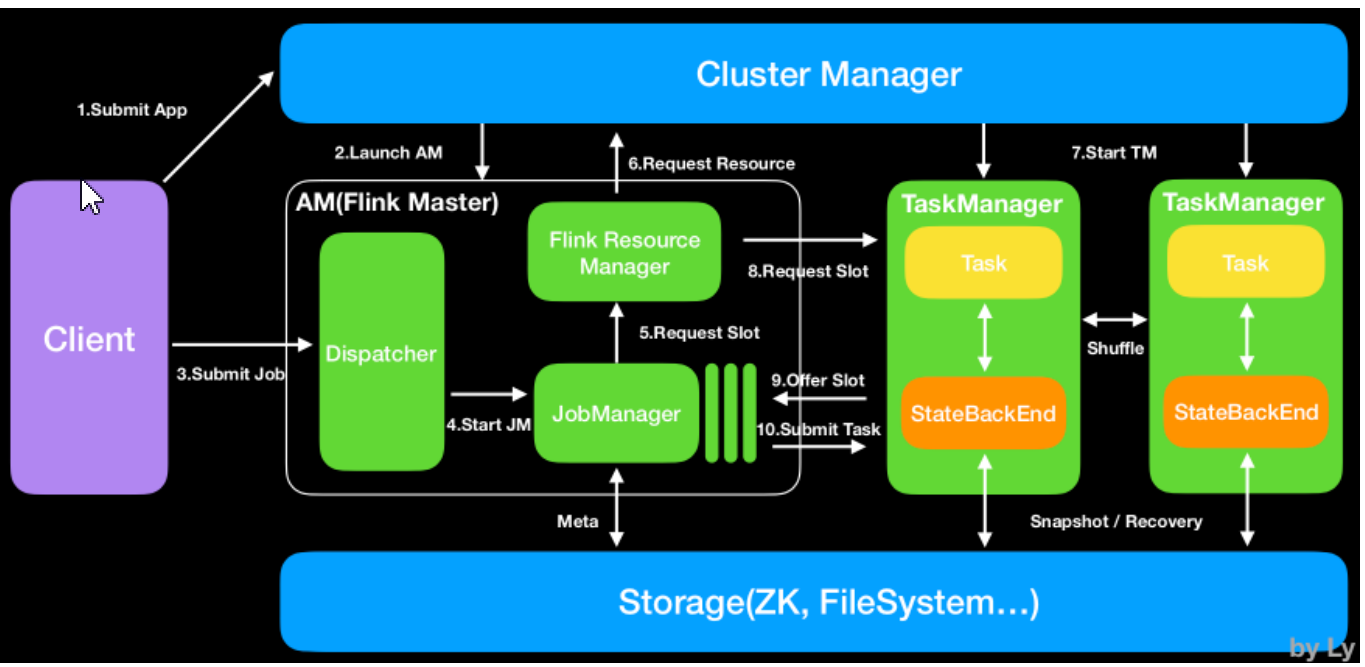
客户端提交job作业到flink的FlinkMaster,FlinkMaster中的JobManager接收到作业,把数据流图转换为工作图,并最终转化为物理层面的执行图,客户端的任务就结束了,只有一个TaskManager向Flink Master中的ResourceManager注册slots任务槽,ResourceManager接收到请求后提供任务槽给JobManager使用,JobManager把执行图分发到TaskManager中可用的slot任务槽中运行,最终返回结果通过Netty连接网络传输返回计算结果给上游客户端。
JobManager、client、TaskManager三者是独立的JVM进程,jobManager除了管理Job还协助Task做checkpoint。Task在启动时就设置好了任务槽数据,不会被回收,使用时开启session直接调用,多个job共有slots任务槽。
缺点:
资源利用弹性不够,job任务结束后不会回收资源;
资源隔离度不够,多个job共享群资源;
所有job共有一个JobManager。
-
StandAlone模式下操作方式
- WebUI提交
- command提交
- -c 指定的main方法的类
- -C 为每个用户代码添加URL,URL需要指定文件的schema(如file://)
- -d 在后台运行
- -p job需要指定Env并行度
- -q 禁止logging输出作为标准输出
- -s 基于savePoint保存下来的路径
- -sae 如果前台方式提交中断,集群执行job任务也会关机。
## 先在node1上安装nc yum localinstall -y netcat-0.7.1-1.i386.rpm ## 先启动端口监听 nc -lp 9999 ## 在node1上提交job任务 flink run -c com.zwf.flinkdemo.StreamingToWordCount -p 2 /root/flinkProject-1.0-SNAPSHOT.jar -
Yarn模式
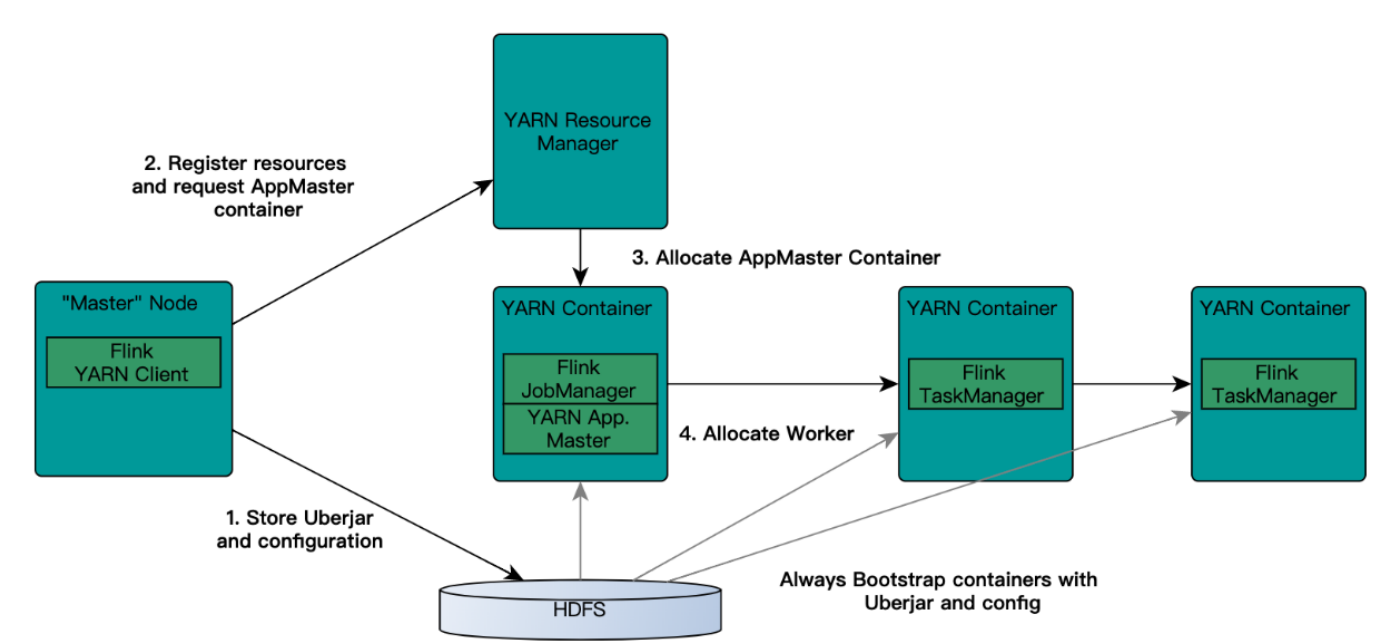
当启动一个新的Yarn会话,client会检查所有请求资源(容器/内存)是否可用,之后上传flink配置文件和jar到HDFS上,client请求一个容器运行applicationMaster进程,ResourceManager选一台NodeManager机器启动AM。
在启动AM过程中,client将配置文件和jar包作为容器资源注册,NodeManager会负责准备一些初始化工作,初始化工作完成了applicationMaster就启动了,并且JobManager与AM运行在同一容器,一旦成功启动,AM可以获取JobManager地址,为TaskManager生成一个新的Flink配置文件,该文件同样上传到HDFS上,AM容器也为Flink提供WebUI。
之后applicationMaster为TaskManager分配Container并在对应的nodemanager上启动taskmanager,工作初始化完成后,从HDFS上下载jar包和修改后的flink配置文件,最终Flink安装完成后接受任务计算。
- Yarn集成环境安装
前提是已经安装Hadoop3.X版本集群、java环境是JDK11.
配置/etc/profile文件追加配置
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop/
source /etc/profile
如果之前安装的是JDK1.8版本,记得修改${HADOOP_HOME}/etc/hadoop/hadoop-env.sh文件
还要修改${ZOOKEEPER_HOME}/bin/zkServer.sh 配置中JAVA_HOME的变量值。
export JAVA_HOME=/usr/local/java/jdk-11.0.16.1
把Flink1.15.x压缩包解压分发到不同节点上
tar -zxvf flink1.15.2-hadoop3-XXX.tar.gz -C /usr/local/flink
rsync -av /usr/local/flink/link1.15.2 root@master:/usr/local/flink/
rsync -av /usr/local/flink/link1.15.2 root@node2:/usr/local/flink/
把commons-cli-1.5.0.jar(apache-commons-cli)、flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar两个jar包放进flink根目录的lib下(三个节点都要放)
从
https://mvnrepository.com/中下载以上两个包。
- 配置UI页面访问端口号,修改${HADOOP_HOME}/conf/Flink-conf.yaml。 (如果不配置就会随机生成UI页面端口)。
rest.port: 8081
- 启动flink-yarn架构
start-all.sh
## 启动yarn-session并分配的资源:
yarn-session.sh -n 3 -jm 1024 -tm 1024
- -n 指明container容器个数,即 taskmanager的进程个数。
- -jm 指明jobmanager进程的内存大小。
- -tm 指明每个taskmanager的进程内存大小。
访问UI页面:
http://node2:40770
- flink可以通过以下三种模式启动
in Application Mode
in a Per-Job Mode
in Session Mode
区别:集群生命周期和资源隔离保护。 应用程序main方法是在客户端执行还是在集群上执行。
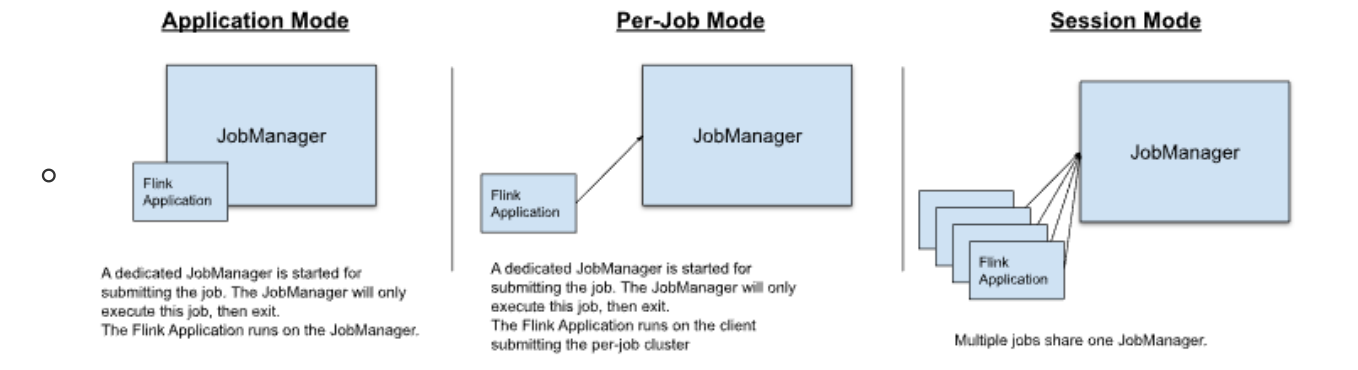
- Session Mode
多个Job共享同一个集群,Job退出集群也不会退出,提交任务的main方法在client端运行,申请的资源不会在job完成后关闭回收。
适用于提交大量小job的场景,因为没提交一次新的job,不需要向yarn注册应用
- Command
yarn-session.sh -n 3 -jm 1024 -tm 1024
## application_id从yarn UI页面上查看
yarn application -kill [application_id]
-
-n 指明container容器个数,即 taskmanager的进程个数。
-
-jm 指明jobmanager进程的内存大小。
-
-tm 指明每个taskmanager的进程内存大小。
-
Per-Job Mode
每个Job独自运行在一个集群中,用户main方法在client端运行,比较适合大Job,运行时长很长,因为每起一个Job,就要向Yarn申请JobManager和TaskManager。一个任务对应一个Job,任务的失败情况不会影响其他任务运行,运行完以后就会立即释放资源。
- Command
flink run -m yarn-cluster -yjm 1024 -ytm 1024 -c com.zwf.flinkdemo.StreamingToWordCount -p 2 /root/flinkProject-1.0-SNAPSHOT.jar
-
-m: 后面接着yarn-cluster,不需要指明地址。由于single job模式每次提交任务会新建flink集群,jobManager是不固定的。
-
-yn: 指明taskManager个数。
-
-c:指明main方法的主类
-
-yjm:指明yarn jobmanager的空间大小。
-
-ytm:指明yarn taskmanager的空间大小。
-
-p:并行度大小
-
Application Mode
与Per-Job Mode 比较用户程序的 main 方法在集群中运行,而不是在客户端运行。每提交一个应用程序就会创建一个集群,该集群可以看作是特定应用程序作业之间共享会话集群,在应用程序完成时终止。这种模式下不同应用之间提供资源隔离和资源负载平衡。
用户可以先上传jar到hdfs上,以后递交作业的时候不需要上传jar了,只需要执行hafs的jar包地址即可。
- command
## 提交任务 jar上传本地 注意:上传的jar要包含hadoop依赖环境 否则无法运行
flink run-application -t yarn-application /root/flink060106_util.jar
#列出集群上正在运行的作业,列出jobId、jobName application_id通过yarn WEBUI查看 YARN UI端口8088
flink list -t yarn-application -Dyarn.application.id=[application_id]
#取消任务: jobId【请注意,取消应用程序集群上的作业将停止该集群。】
flink cancel -t yarn-application -Dyarn.application.id=application_1666689812613_0003
## jar包上传HDFS上再使用以下命令运行 并指明主类 注意:上传的jar要包含hadoop依赖环境 否则无法运行
flink run-application -t yarn-application -p 2 hdfs://hdfs-zwf/flinkProject.jar
22、Flink CEP
- 概念
CEP是复杂事件处理,是Flink上层实现复杂事件处理库,市场上有多种CEP解决方案,例如Spark、Samza、Bean等没有专门的library支持。Flink提供了专门的CEP library。
特征:从目标到输入再到处理最后到输出整个过程的复杂处理。
- Sample 案例
- 测试数据:
{"empno":7369,"ename":"SMITH","job":"CLERK","mgr":7902,"hiredate":345830400000,"sal":800.0,"comm":null,"deptno":20}
{"empno":7499,"ename":"ALLEN","job":"SALESMAN","mgr":7698,"hiredate":351446400000,"sal":1600.0,"comm":300.0,"deptno":30}
{"empno":7521,"ename":"WARD","job":"SALESMAN","mgr":7698,"hiredate":351619200000,"sal":1250.0,"comm":500.0,"deptno":30}
{"empno":7566,"ename":"JONES","job":"MANAGER","mgr":7839,"hiredate":354988800000,"sal":2975.0,"comm":null,"deptno":20}
{"empno":7654,"ename":"MARTIN","job":"SALESMAN","mgr":7698,"hiredate":370454400000,"sal":1250.0,"comm":1400.0,"deptno":30}
{"empno":7698,"ename":"BLAKE","job":"MANAGER","mgr":7839,"hiredate":357494400000,"sal":2850.0,"comm":null,"deptno":30}
{"empno":7782,"ename":"CLARK","job":"MANAGER","mgr":7839,"hiredate":360864000000,"sal":2450.0,"comm":null,"deptno":10}
{"empno":7788,"ename":"SCOTT","job":"ANALYST","mgr":7566,"hiredate":553100400000,"sal":3000.0,"comm":null,"deptno":20}
{"empno":7839,"ename":"KING","job":"PRESIDENT","mgr":null,"hiredate":374774400000,"sal":5000.0,"comm":null,"deptno":10}
{"empno":7844,"ename":"TURNER","job":"SALESMAN","mgr":7698,"hiredate":368726400000,"sal":1500.0,"comm":0.0,"deptno":30}
{"empno":7876,"ename":"ADAMS","job":"CLERK","mgr":7788,"hiredate":553100400000,"sal":1100.0,"comm":null,"deptno":20}
{"empno":7900,"ename":"JAMES","job":"CLERK","mgr":7698,"hiredate":376156800000,"sal":950.0,"comm":null,"deptno":30}
{"empno":7902,"ename":"FORD","job":"ANALYST","mgr":7566,"hiredate":376156800000,"sal":3000.0,"comm":null,"deptno":20}
{"empno":7934,"ename":"MILLER","job":"CLERK","mgr":7782,"hiredate":380563200000,"sal":1300.0,"comm":null,"deptno":10}
- 环境依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep</artifactId>
<version>1.15.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.15.2</version>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.41</version>
</dependency>
- 代码
//案例
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
DataStreamSource<String> source = environment.readTextFile("data/emp.txt");
//获取DataStream对象
DataStream<Emp> map = source.map(line -> JSONObject.parseObject(line, Emp.class));
//构建匹配模式
Pattern<Emp, Emp> cep = Pattern.<Emp>begin("start").where(
new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(10);
}
}
);
//处理时间匹配
PatternStream<Emp> pattern = CEP.pattern(map, cep).inProcessingTime();
//处理函数进行处理
pattern.process(new PatternProcessFunction<Emp,Emp>() {
@Override
public void processMatch(Map<String, List<Emp>> map, Context context, Collector<Emp> collector) throws Exception {
Set<Map.Entry<String, List<Emp>>> entries = map.entrySet();
for (Map.Entry<String, List<Emp>> entry : entries) {
entry.getValue().forEach(collector::collect);
}
}
}).print();
environment.execute();
- CEP模式
模式APi可以让用户定义想从输入流中抽取复杂模式序列,数据流最终寻找出来的序列称为模式序列,你可以把模式序列看作是模式构成的图,这样模式基于用户指定条件从一个转换到另一个。一个匹配是输入事件的序列。
注意:每个模式必须有一个独一无二的名字,可以在后面使用它识别匹配事件。模式的名字不能包含
:。
- 单模式
默认情况下CEP都是单模式。单模式只接受一个事件,循环模式可以接受多个事件。
例如:a b+ c? d,如果不组合一起单个来看a、d、c?都是单模式,而b+是循环模式。
在Flink CEP中循环模式:
pattern.oneOrMore()表示一次或多次,与以上提到的b+意义一致。
pattern.times(#ofTimes)表示特定的次数。
pattern.times(#fromTimes, #toTimes)表示从n次到m次
pattern.greedy()循环模式变贪婪。
pattern.optional()循环模式可选,不管存在与否都是显示不报错。
//案例
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
DataStreamSource<String> source = environment.readTextFile("data/emp.txt");
//获取DataStream对象
DataStream<Emp> map = source.map(line -> JSONObject.parseObject(line, Emp.class));
//构建匹配模式
Pattern<Emp, Emp> cep = Pattern.<Emp>begin("start").where(
new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(10);
}
}
).times(1,3);
//处理时间匹配
PatternStream<Emp> pattern = CEP.pattern(map, cep).inProcessingTime();
//处理函数进行处理
pattern.process(new PatternProcessFunction<Emp,Emp>() {
@Override
public void processMatch(Map<String, List<Emp>> map, Context context, Collector<Emp> collector) throws Exception {
Set<Map.Entry<String, List<Emp>>> entries = map.entrySet();
for (Map.Entry<String, List<Emp>> entry : entries) {
System.out.println(entry);
}
}
});
environment.execute();
-----------------------------------------------------------------------------------------
//常见案例 start就是模式名
// 期望出现4次
start.times(4);
// 期望出现0或者4次
start.times(4).optional();
// 期望出现2、3或者4次
start.times(2, 4);
// 期望出现2、3或者4次,并且尽可能的重复次数多
start.times(2, 4).greedy();
// 期望出现0、2、3或者4次
start.times(2, 4).optional();
// 期望出现0、2、3或者4次,并且尽可能的重复次数多
start.times(2, 4).optional().greedy();
// 期望出现1到多次
start.oneOrMore();
// 期望出现1到多次,并且尽可能的重复次数多
start.oneOrMore().greedy();
// 期望出现0到多次
start.oneOrMore().optional();
// 期望出现0到多次,并且尽可能的重复次数多
start.oneOrMore().optional().greedy();
// 期望出现2到多次
start.timesOrMore(2);
// 期望出现2到多次,并且尽可能的重复次数多
start.timesOrMore(2).greedy();
// 期望出现0、2或多次
start.timesOrMore(2).optional();
// 期望出现0、2或多次,并且尽可能的重复次数多
start.timesOrMore(2).optional().greedy();
- 条件
简单条件:这种类型的条件扩展了前面提到的 IterativeCondition 类,它决定是否接受一个事件 只取决于事件自身的属性。
迭代条件:这是最普通条件类型。使用它可以指定一个基于前面已经被接受的事件属性或者它们的一个子集统计数据。
组合条件:你可以把 subtype 条件和其他的条件结合起来使用。这适用于任何条件,你可以通过依 次调用 where() 来组合条件。 最终的结果是每个单一条件的结果的逻辑AND。如果想 使用OR来组合条件,你可以像下面这样使用 or() 方法。
停止条件:如果指定循环模式(OneOrMore() and OneOrMore().optional())你可以指定一个停止条件,例如,接受事件的值大于5直到值小于50,循环条件停止。
- 具体代码实现
where(condition):为了匹配这个模式,一个事件必须满足某些条件。多个连续where()语句取与组成判断条件
or(condition):一个事件满足至少一个判断条件就匹配到模式。
until(condition):为循环模式指定一个停止条件。满足了给定条件事件出现后,就不会再有事件被接受进入模式。只适用于和OneOrMore()同时使用。
subtype(subClass):为当前模式一个子类型条件。一个事件只有这个子类型的时候才能匹配模式。
oneOrMore():指定模式期望匹配到的事件至少出现一次。
timesOrMore(#times) 指定模式期望匹配到的事件至少出现#times次。
times(#ofTimes):指定模式期望匹配到的事件出现次数在#fromTimes和#toTimes之间。
optional():指定这个模式是可选的,也就是说,它可能根本不出现。这对所有之前提到的量词都适用。
greedy():指定这个模式是贪心的,也就是说,它会重复尽可能多的次数。
- 案例代码
//案例
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
DataStreamSource<String> source = environment.readTextFile("data/emp.txt");
//获取DataStream对象
DataStream<Emp> map = source.map(line -> JSONObject.parseObject(line, Emp.class));
//构建匹配模式
Pattern<Emp, Emp> cep = Pattern.<Emp>begin("start").where(
new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(10);
}
}
//过滤出deotno=10或者deptno=30的数据
).or(new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(30);
}
});
//处理时间匹配
PatternStream<Emp> pattern = CEP.pattern(map, cep).inProcessingTime();
//处理函数进行处理
pattern.process(new PatternProcessFunction<Emp,Emp>() {
@Override
public void processMatch(Map<String, List<Emp>> map, Context context, Collector<Emp> collector) throws Exception {
Set<Map.Entry<String, List<Emp>>> entries = map.entrySet();
for (Map.Entry<String, List<Emp>> entry : entries) {
System.out.println(entry);
}
}
});
environment.execute();
- 组合模式
- 模式序列由一个初始模式作为开头:Pattern start = Pattern.
begin("start"); - 模式序列分类:严格连续 松散连续 不确定的松散连续
- 代码实现:
- next(): 指定严格连续
- followedBy():指定松散连续
- followedByAny():指定不确定松散连续。
- notNext(): 如果不想后面直接连接着一个特定事件
- notFollowedBy(): 如果不想一个特定事件发生在两个事件之间的任何地方。
- 注意
- 一个模式序列只能有一个时间限制。如果限制了多个时间在不同的单个模式上,会使用 最小的那个时间限制。使用
next.within(Time.seconds(10))设置。- 模式序列不能以 notFollowedBy() 结尾。
- 一个 NOT 模式前面不能是可选的模式。
- 代码
//案例
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
DataStreamSource<String> source = environment.readTextFile("data/emp.txt");
//获取DataStream对象
DataStream<Emp> map = source.map(line -> JSONObject.parseObject(line, Emp.class));
//构建匹配模式 deptno=10下一行数据是deptno=30 显示这两行数据。 (严格模式)
Pattern<Emp, Emp> cep = Pattern.<Emp>begin("start").where(
new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(10);
}
}
).next("middle").where(new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(30);
}
});
=========================================================================================
//构建匹配模式 最前面deptno=10下不管隔几行数据是deptno=30,显示这些数据 必须符合deptno=10后面接deptno=30的数据。 (松散模式)
Pattern<Emp, Emp> cep = Pattern.<Emp>begin("start").where(
new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(10);
}
}
).followedBy("middle").where(new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(30);
}
});
=========================================================================================
//构建匹配模式 所有的deptno=10开头只要下面有数据是deptno=30 显示这两行数据。
//第二行数据可能有重复 (不确定松散模式)
Pattern<Emp, Emp> cep = Pattern.<Emp>begin("start").where(
new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(10);
}
}
).followedByAny("middle").where(new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(30);
}
});
=========================================================================================
environment.execute();

- 模式组
可以定义一个模式序列作为 begin , followedBy , followedByAny 和 next 的条件。
这个模式序列在逻辑上会被当作匹配的条件, 并且返回一个 GroupPattern ,可以在 GroupPattern 上使用oneOrMore() , times(#ofTimes) , times(#fromTimes, #toTimes) , optional() , consecutive() , allowCombinations() 。

//案例
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
DataStreamSource<String> source = environment.readTextFile("data/emp.txt");
//获取DataStream对象
DataStream<Emp> map = source.map(line -> JSONObject.parseObject(line, Emp.class));
//构建匹配模式 匹配符合middle模式中1个或多个值都可以。 返回一个模式组
Pattern<Emp, Emp> cep = Pattern.<Emp>begin("start").where(
new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(10);
}
}
).followedByAny("middle").where(new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(30);
}
}).oneOrMore();
//处理时间匹配
PatternStream<Emp> pattern = CEP.pattern(map, cep).inProcessingTime();
//处理函数进行处理
pattern.process(new PatternProcessFunction<Emp,Emp>() {
@Override
public void processMatch(Map<String, List<Emp>> map, Context context, Collector<Emp> collector) throws Exception {
Set<Map.Entry<String, List<Emp>>> entries = map.entrySet();
for (Map.Entry<String, List<Emp>> entry : entries) {
System.out.println(entry);
}
}
});
- 匹配跳过策略
对于一个给定的模式,同一个事件可能会分配到多个成功的匹配上。
为了控制一个事件会分配到多少个匹配上,你需要指定跳过策略
AfterMatchSkipStrategy有五种跳过策略:
- NO_SKIP:每个成功的匹配都会被输出。
- SKIP_TO_NEXT: 丢弃以相同事件开始的所有部分匹配。
- SKIP_PAST_LAST_EVENT:丢弃起始在这个匹配的开始和结束之间所有部分匹配。
- SKIP_TO_FIRST:丢弃起始在这个匹配的开始和第一个出现的名称为PatternName事件之间的 所有部分匹配。
- SKIP_TO_LAST: 丢弃起始在这个匹配的开始和最后一个出现的名称为PatternName事件之间 的所有部分匹配。
案例01:给定一个模式 b+ c 和一个数据流 b1 b2 b3 c ,不同跳过策略之间的不同如下:
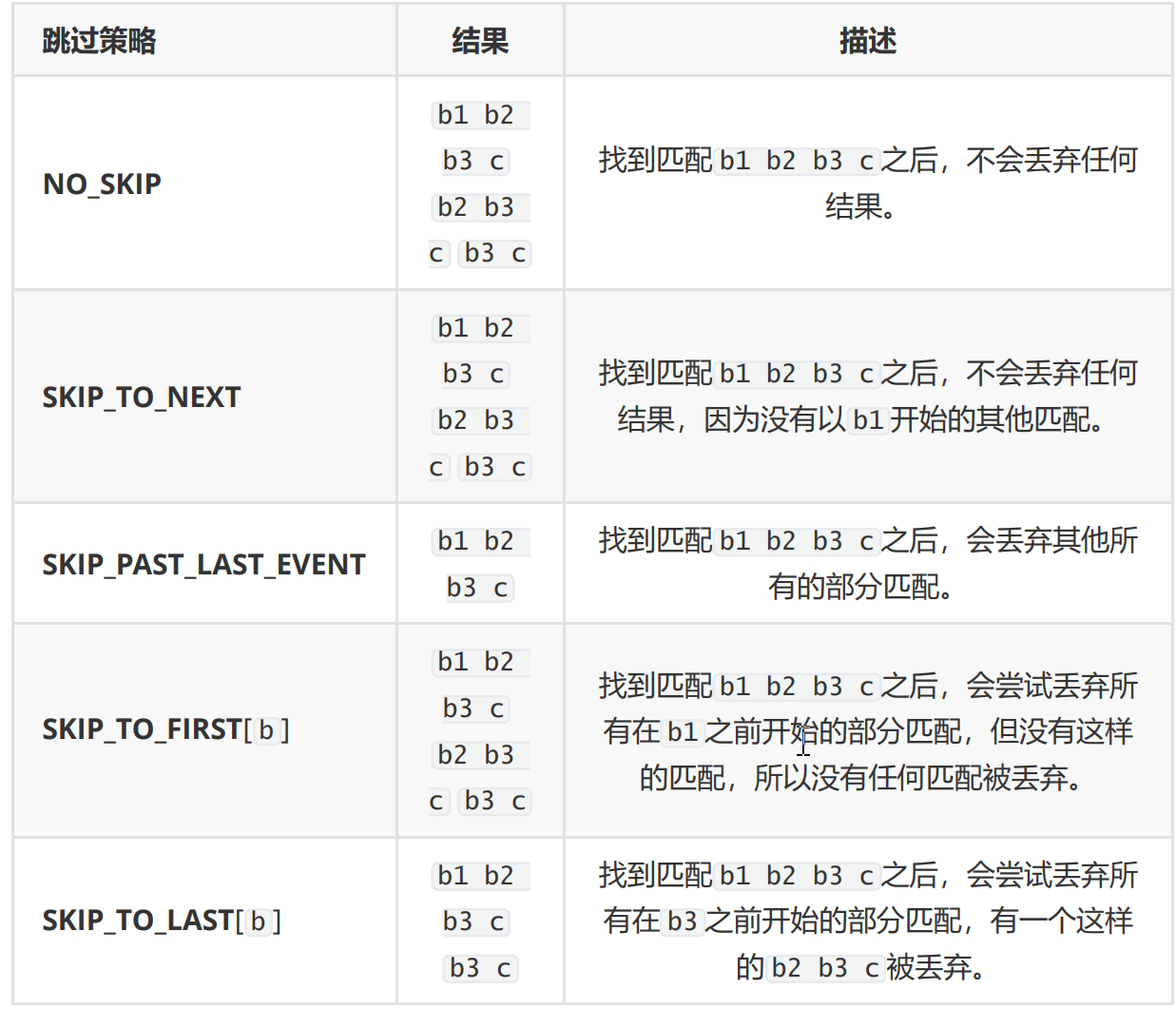
- 案例
Pattern<Emp, Emp> cep = Pattern.<Emp>begin("start",
//在这里设置策略
AfterMatchSkipStrategy.skipToNext()).where(
new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(10);
}
}
).followedByAny("middle").where(new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(30);
}
}).oneOrMore();
- 时间处理
在 CEP 中,事件的处理顺序很重要。在使用事件时间时,为了保证事件按照正确的顺序被处理, 一个事件到来后会先被放到一个缓冲区中, 在缓冲区里事件都按照时间戳从小到大排序,当水位线到达后,缓冲区中所有小于水位线的事件被处理。这意味着水位线之间的数据都按照时间戳被顺序处理。
如果在水位线到达后,时间戳比水位线时间戳小,这属于迟到数据,迟到数据不会被处理,一般被侧输出。
- 案例
//案例
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
DataStreamSource<String> source = environment.readTextFile("data/emp.txt");
//获取DataStream对象
// 数据处理流设置时间窗口处理
SingleOutputStreamOperator<Emp> process = source.map(line -> JSONObject.parseObject(line, Emp.class)).windowAll(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))).process(new ProcessAllWindowFunction<Emp, Emp, TimeWindow>() {
@Override
public void process(ProcessAllWindowFunction<Emp, Emp, TimeWindow>.Context context, Iterable<Emp> elements, Collector<Emp> out) throws Exception {
Iterator<Emp> iterator = elements.iterator();
while (iterator.hasNext()) {
out.collect(iterator.next());
}
}
});
OutputTag<Emp> lateDataOutputTag = new OutputTag("late_event_time"){};
//构建匹配模式 匹配符合middle模式中1个或多个值都可以。
Pattern<Emp, Emp> cep = Pattern.<Emp>begin("start", AfterMatchSkipStrategy.skipToNext()).where(
new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(10);
}
}
).followedByAny("middle").where(new SimpleCondition<Emp>() {
@Override
public boolean filter(Emp value) throws Exception {
return value.getDeptno().equals(30);
}
}).oneOrMore();
//处理时间匹配
PatternStream<Emp> pattern = CEP.pattern(process, cep);
//处理迟到数据
pattern.sideOutputLateData(lateDataOutputTag).select(new PatternSelectFunction<Emp, Object>() {
@Override
public Object select(Map<String, List<Emp>> map) throws Exception {
return null;
}
});
//处理函数进行处理
SingleOutputStreamOperator<Emp> operator = pattern.process(new PatternProcessFunction<Emp, Emp>() {
@Override
public void processMatch(Map<String, List<Emp>> map, Context context, Collector<Emp> collector) throws Exception {
Set<Map.Entry<String, List<Emp>>> entries = map.entrySet();
for (Map.Entry<String, List<Emp>> entry : entries) {
System.out.println(entry);
}
}
});
DataStream<Emp> sideOutput = operator.getSideOutput(lateDataOutputTag);
sideOutput.print();
environment.execute();
23、Flink 指标
通过flink指标可以通过可视化界面获取到任务运行状态,避免任务运行处于黑盒状态,分析这些指标,可以更好调整任务的资源,对任务进行监控。
Flink Metrics两大作用:
- 实时采集监控数据。在Flink UI页面上,用于可以看到自己提交的任务状态、时延、监控信息等。
- 对外提供数据。用于将整个flink集群的监控数据主动上报至第三方监控系统。如:promethus等。
编写代码打成jar包后在服务器上运行,然后打开webUI界面,观察你设置的任务指标图!
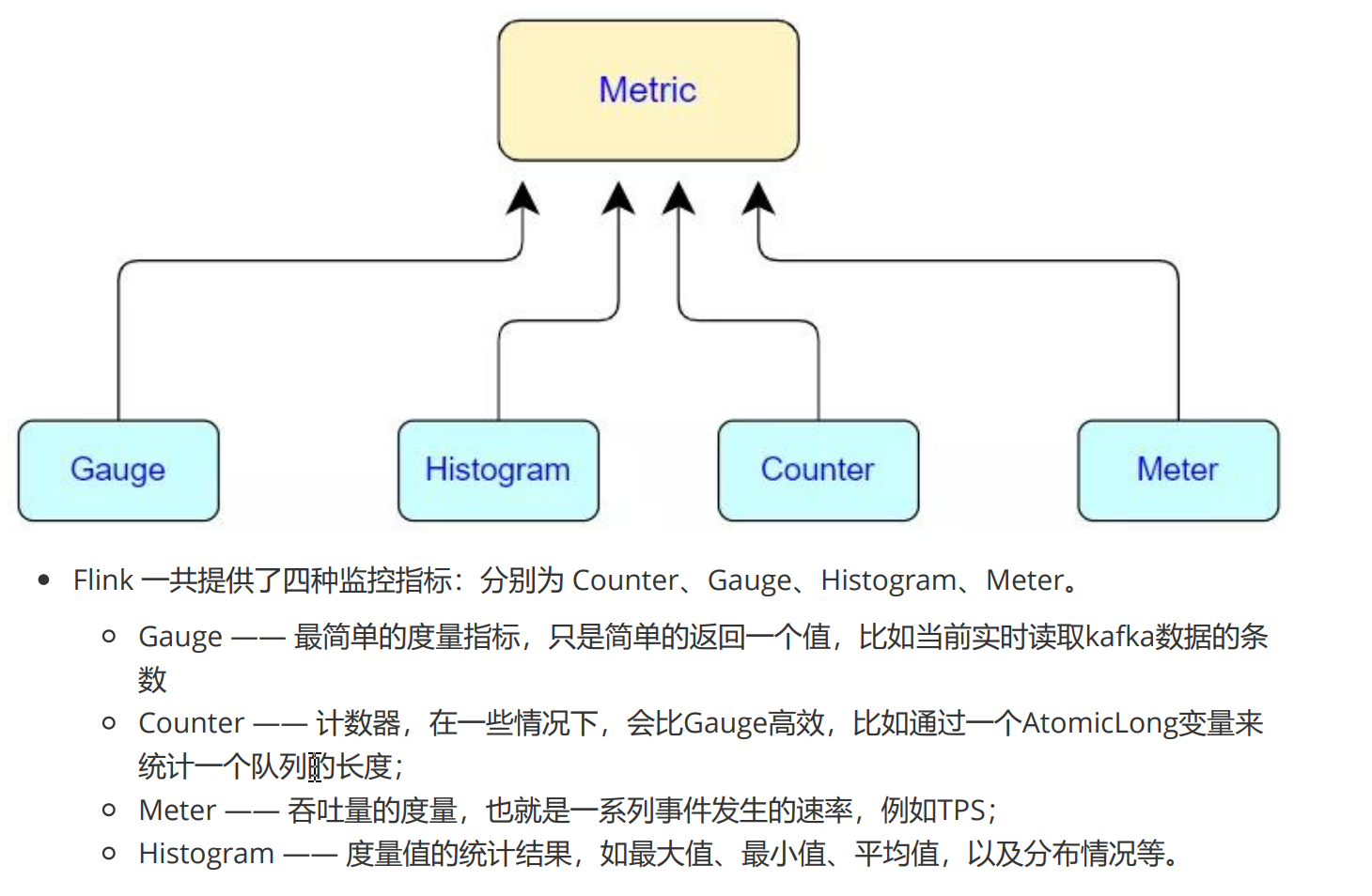
- Count 计数器样例代码
public class MyMapper extends RichMapFunction<String, String> {
private transient Counter counter;
@Override
public void open(Configuration config) {
this.counter = getRuntimeContext()
.getMetricGroup()
.counter("myCustomCounter", new CustomCounter());
}
@Override
public String map(String value) throws Exception {
this.counter.inc();
return value;
}
}
- Gauge 指标瞬时值
public class MyMapper extends RichMapFunction<String, String> {
private transient int valueToExpose = 0;
@Override
public void open(Configuration config) {
getRuntimeContext()
.getMetricGroup()
.gauge("MyGauge", new Gauge<Integer>() {
@Override
public Integer getValue() {
return valueToExpose;
}
});
}
@Override
public String map(String value) throws Exception {
valueToExpose++;
return value;
}
}
- Meter 平均值
public class MyMapper extends RichMapFunction<Long, Long> {
private transient Meter meter;
@Override
public void open(Configuration config) {
this.meter = getRuntimeContext()
.getMetricGroup()
.meter("myMeter", new MyMeter());
}
@Override
public Long map(Long value) throws Exception {
this.meter.markEvent();
return value;
}
}
public class MyMeter implements Meter {
int cnt = 0;
int sum = 0;
@Override
public void markEvent() {
sum += RandomUtils.nextInt(100, 200);
cnt++;
}
@Override
public void markEvent(long l) {
sum += l;
cnt++;
}
@Override
public double getRate() {
return sum / cnt;
}
@Override
public long getCount() {
return cnt;
}
}
- Histogram 直方图
public class MyMapper extends RichMapFunction<Long, Long> {
private transient Histogram histogram;
@Override
public void open(Configuration config) {
this.histogram = getRuntimeContext()
.getMetricGroup()
.histogram("myHistogram", new MyHistogram());
}
@Override
public Long map(Long value) throws Exception {
this.histogram.update(value);
return value;
}
}
其他参考02Flink完整文档!
24、Flink Backpressure
数据反压机制(背压):
如果你看到一个task发生反压警告,意味着它生产速率比下游task消费数据速率要快。
在工作流中数据记录是从上游向下游流动。
反压沿着相反的方向传 播,沿着数据流向上游传播。
Task的每个并行实例都可以用三个一组的指标评价:
backPressureTimeMsPerSecond ,subtask 被反压的时间
idleTimeMsPerSecond ,subtask 等待某类处理的时间
busyTimeMsPerSecond ,subtask 实际工作时间 在任何时间点,这三个指标相加都约等于 1000ms。
在内部,反压根据输出 buffers 的可用性来进行判断的。如果一个 task 没有可用的输出 buffers,那么这个 task 就被认定是在被反压。 相反,如果有可用的输入,则可认定为闲置。闲置的task为蓝色,完全反压的为黑色,完全繁忙的tasks为红色。中间的所有值表示这三种颜色的过渡色。
反压原因:反压影响两项指标==》checkpoint时长和state大小
前者因为barrier不会越过数据,数据处理阻塞导致barrier流经整个数据管道时间变长,checkpoint总体时间变长。
为了保证EOS,对于有两个以上输入管道的Opaerator,barrier需要对齐,接受到较快输入管道Operator,barrier需要对齐,接受输入管道barrier后,数据会被缓存起来不处理,直到较慢输入管理的barrier到达,数据会被存放state里,导致checkpoint变大。
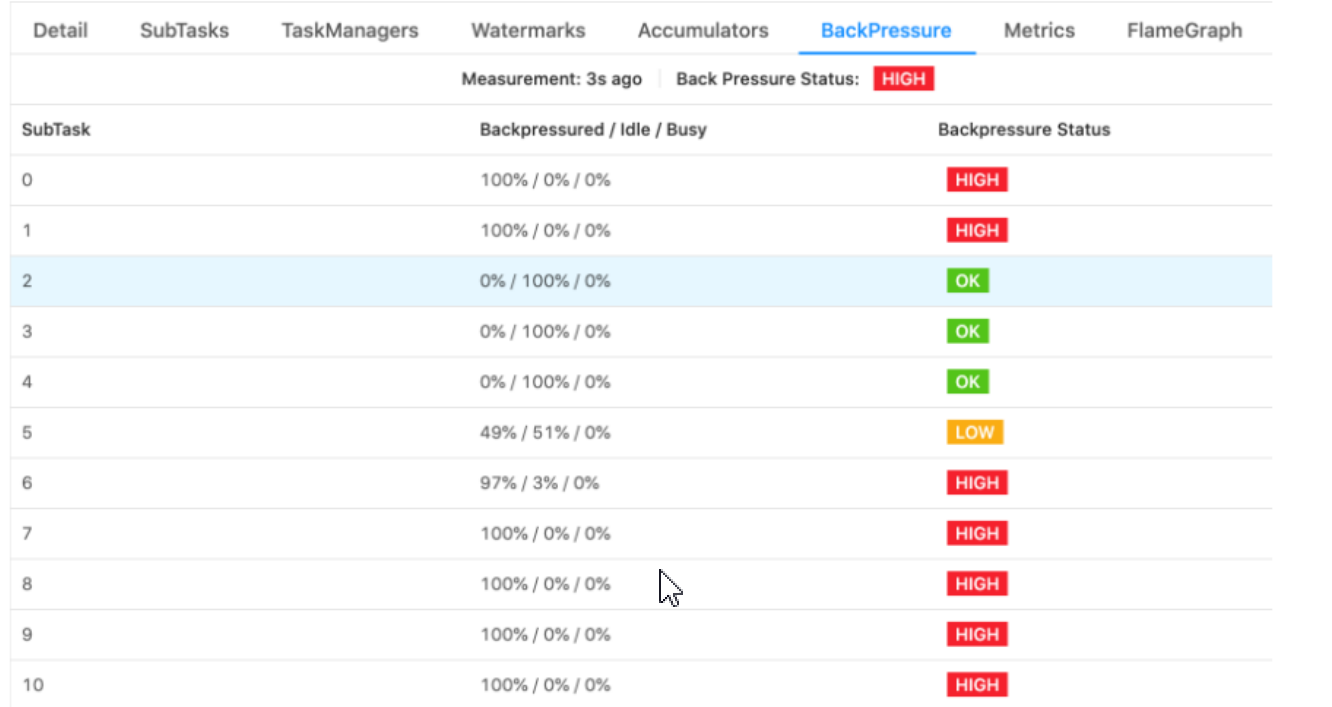
- 网络监控
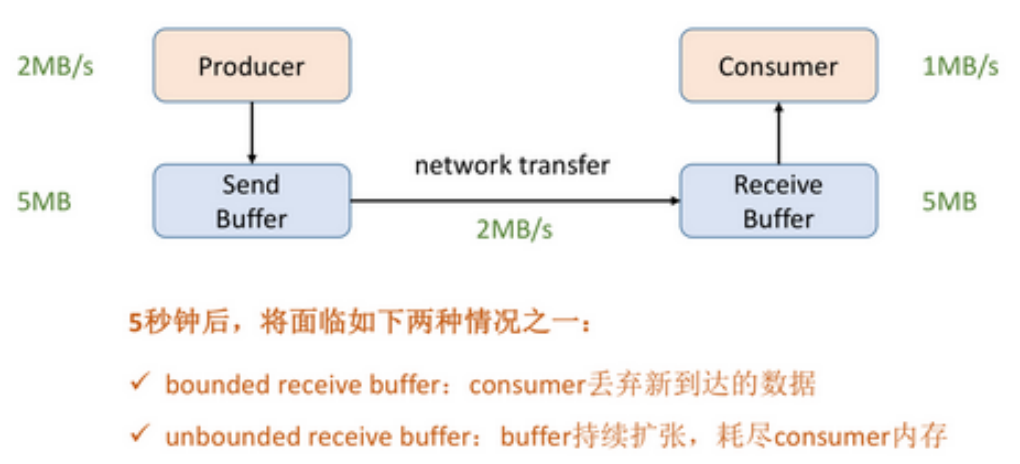
由于Producer的传输速度是2MB/s,而Consumer是1MB/s,导致Producer生产速度大于Consumer消费速度1MB/s,5s后会导致Receive Buffer持续扩张最终占满cousumer内存,而Consumer丢弃新到达的数据。
- 解决方案:
- 静态限流,通过载producer和send buffer之间加上一个rate limiter速率限流器,让生产速度控制在1MB,这样上下游速度就能一致。但是事先无法预估consumer承载多大的速率,cousumer承受能力会动态波动。(老版本)
- 动态反馈机制consumer消费完以后,动态反馈consumer承受的压力给producer,动态反馈分为两种:
- 负反馈:接收速度小于发生速率时,告知producer降低发送速率。
- 正反馈:发送速率小于接收速率时,告知producer把速率提升上来。
- 反压流程
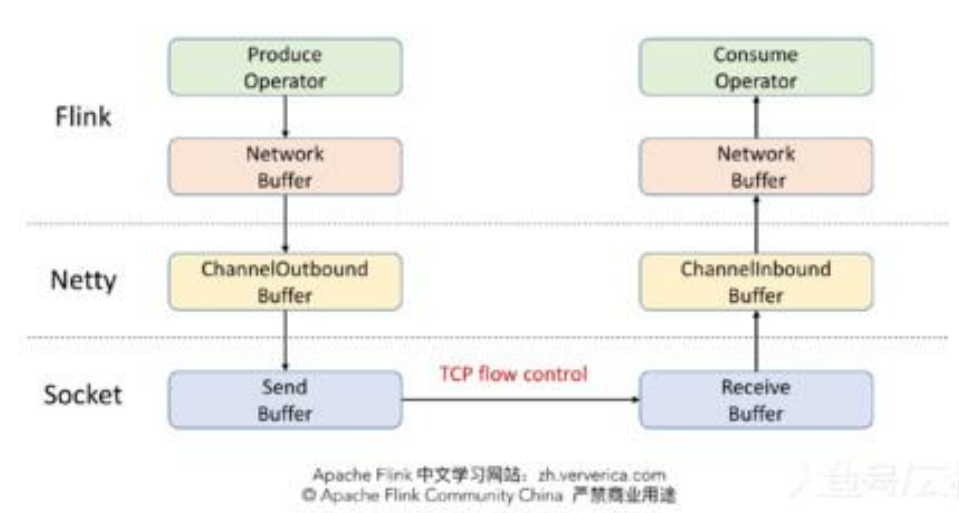
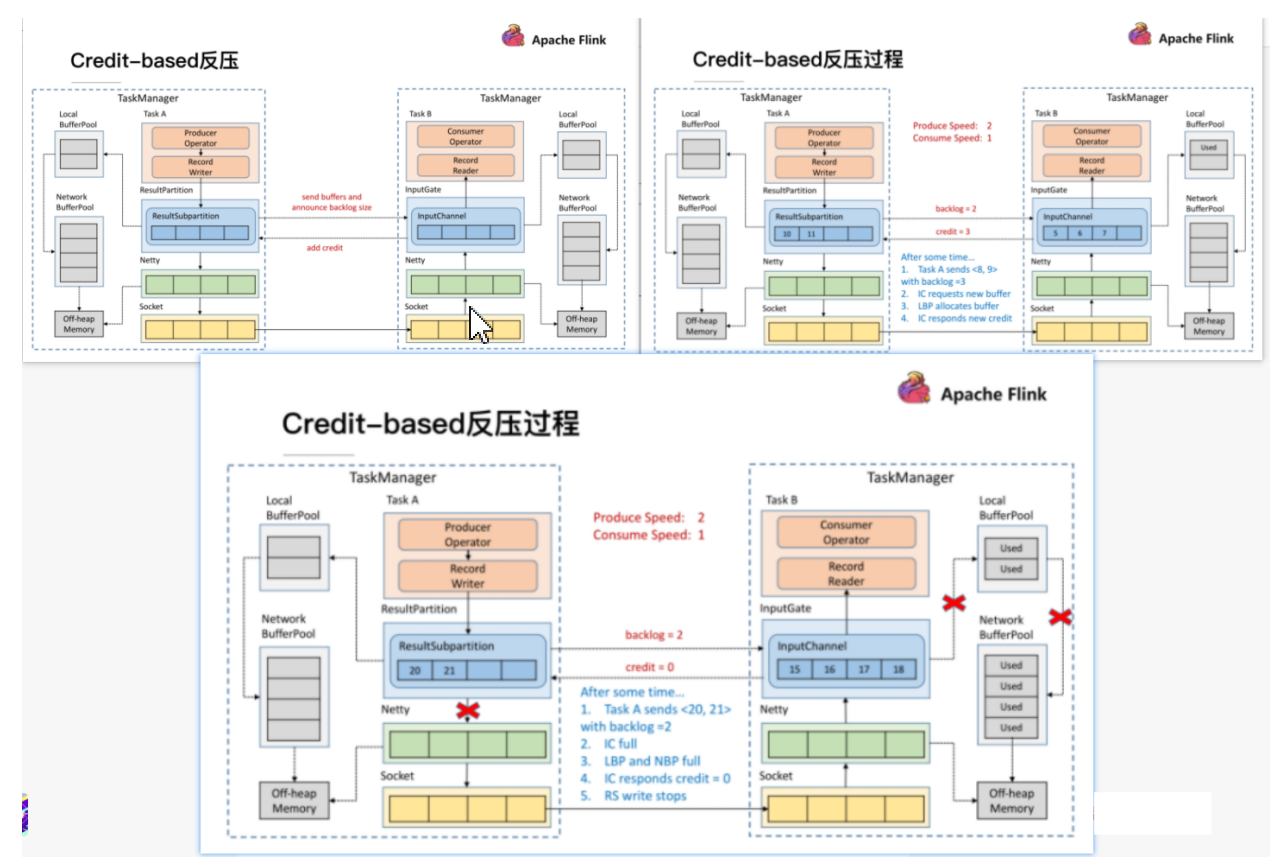
Flink1.5之前通过TCP流控机制实现速率反馈,依赖最底层的TCP流控,导致反压传播路径太长了,生效延迟比较大,容易造成checkpoint和state空间越来越大。
Flink1.5以后通过 Credit-based 反压机制,每一次 ResultSubPartition 向 InputChannel 发送消息的时候都 会发送一个 backlog size 告诉下游准备发送多少消息,下游就会去计算有多少的 Buffer 去接收消 息,算完之后如果有充足的 Buffer 就会返还给上游一个 Credit 告知他可以发送消息,不用通过 Socket 和 Netty 一层层地向上反馈,降低了反 压生效的延迟。同时也不会将 Socket 去阻塞,解决了由于一个 Task 反压导致 TaskManager 和 TaskManager 之间的 Socket 阻塞的问题。
- 反压原因
系统资源负载过高 、垃圾回收(GC)、CPU/线程瓶颈 、 线程争用、负载不均