Item Pipeline即项目管道,它的调用发生在Spider产生Item之后。当Spider解析完Response,Item就会被Engine传递到Item Pipeline,被定义的Item Pipeline组件会顺次被调用,完成一连串的处理过程,比如数据清洗、存储等。
Item Pipeline的主要功能如下:
- 清洗HTML数据。
- 验证爬取数据,检查爬取字段。
- 查重并丢弃重复内容。
- 将爬取结果存储到数据库中。
一、核心方法。
我们可以自定义Item Pipeline,只需要实现指定的方法就好,其中必须实现的一个方法是:
- process_item(item, spider)
另外还有几个比较使用的方法,它们分别是:
- open_spider(spider)
- close_spider(spider)
- from_crawler(cls, crawler)
1、process_item(item, spider)
process_item是必须实现的方法,被定义的Item Pipeline会默认调用这个方法对Item进行处理,比如进行数据处理或者将数据写入数据库等操作。
(1)参数
process_item方法的参数有两个。
- item:Item对象,即被处理的Item。
- spider:Spider对象,即生成该Item的Spider。
(2)返回值
process_item方法必须返回Item类型的值或者抛出一个DropItem异常。该方法的返回类型如下:
- Item:如果返回的是Item对象,那么此Item会接着被低优先级的Item Pipeline的process_item方法处理,直到所有的方法被调用完毕。
- DropItem异常:如果抛出DropItem异常,那么此Item就会被丢弃,不再进行处理。
2、open_spider(self, spider)
open_spider方法是在Spider开启的时候被自动调用的,在这里,我们可以做一些收尾工作,如关闭数据库连接等。其中参数spider就是被开启的Spider对象。
3、close_spider(spider)
close_spider方法是在Spider关闭的时候自动调用,在这里,我们可以做一些收尾工作,如关闭数据库连接等,其中参数spider就是被关闭的Spider对象。
4、from_crawler(cls, crawler)
from_crawler方法是一个类方法,用@classmethod标识,它接受一个参数crawler。通过crawler对象,我们可以拿到Scrapy的所有核心组件,如全局配置的每个信息。然后可以在这个方法里面创建一个Pipeline实例。参数cls就是Class,最后返回一个Class实例。
二、实例演示
本节我们的目标网站是:https://ssr1.scrape.center/,我们需要把每部电影的名称、类别、评分、简介、导演、演员的信息以及相关图片爬取下来,同时把每部电影的导演、演员的相关图片保存成一个文件夹,并将每部电影的完整数据保存到Mysql和images文件夹内。
在这里我们使用scrapy来实现这个电影数据爬虫,了解Item Pipeline的用法。
1、创建项目
我们首先创建一个项目,取名为testItemPipeline,命令如下:
- scrapy startproject testItemPipeline
进入该项目,在项目中创建一个spider,名叫movie_spider。
- scrapy genspider movie_spider https://ssr1.scrape.center/
这样我们就成功创建了一个Spider,,接下来我们来实现列表页的抓取。本站点一共有10页数据,所以我们可以新建10个初始请求。实现start_requests方法的代码如下:

在这里,修改了start_urls,使其形成单个初始url,随后,通过start_requests函数构造了十个初始url,随后返回了构造后的十个url,并通过Request的回调方法修改为了parse_index,最后我们暂时在parse_index方法里面打印输出了response对象。运行spider后结果如下:
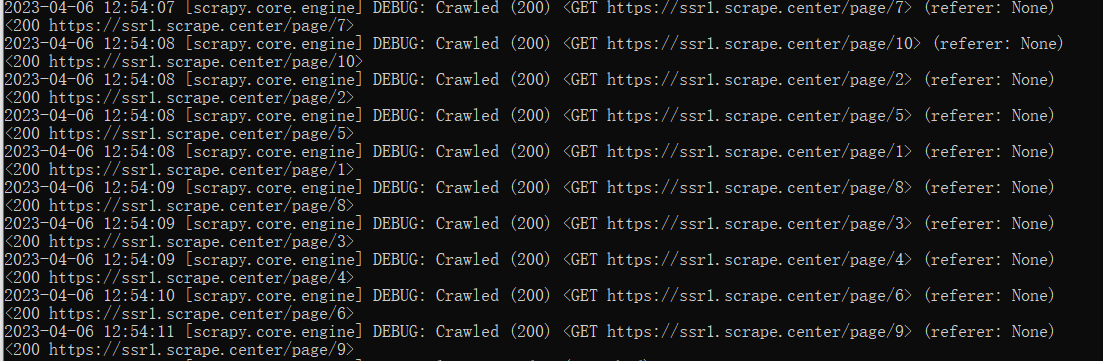
可以看到对应的列表页的数据就被爬取下来了,Response的状态码为200。
接着我们可以在parse_index方法里对response的内容进行解析,提取每部电影的详情页连接,在这里我们通过xpath进行数据的提取。提取链接之后生成详情页的Request,可以把parse_index方法改写如下: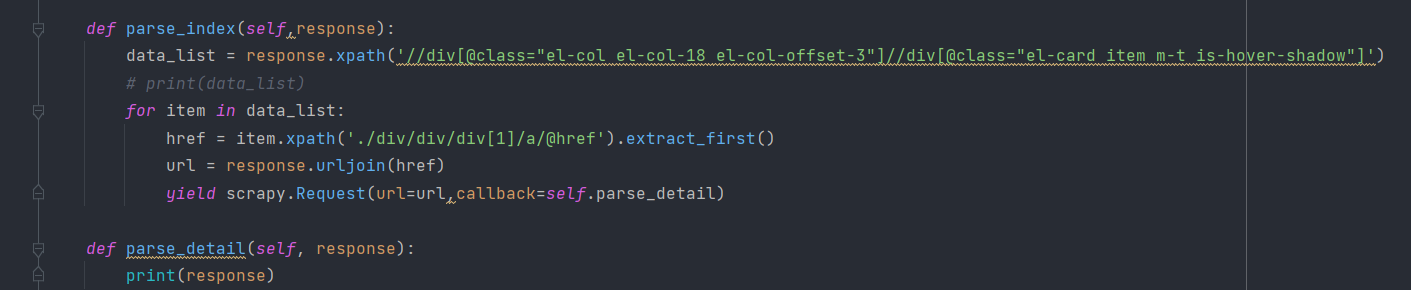
这里,我们首先筛选了每部电影所对应的节点,然后遍历这些节点,提取其中的href来提取详情页链接,接着通过response的urljoin方法拼接成完整的详情页URL,最后构造新的详情页Request,回调方法设置为parse_detail,同时在parse_detail方法里面打印输出response,重新运行,我们可以看到详情页的内容就被爬取下来了,类似下面的输出:

其实现在parse_detail里面的response就是详情页的内容了,我们可以进一步对详情页的内容进行解析,提取了每部电影的名称、类别、评分、简介、导演、演员等信息:
首先让我们先修改一下items.py的内容,修改的Item类叫作TestitempipelineItem。
新建文件时就是以下样式:
我们只需要在里面添加几个需要爬取的字段就可以了。
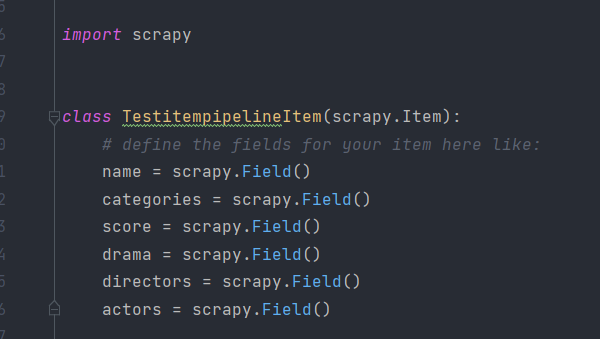
这里我们定义了几个字段name、categories、score、drama、directors、actors分别代表电影名称、类别、评分、简介、导演、演员。接下来我们就可以提取详情页了,修改parse_detail方法如下:
def parse_detail(self, response):
item = TestitempipelineItem()
item["name"] = response.xpath('//div[@class="el-card__body"]/div[@class="item el-row"]/div[@class="p-h el-col el-col-24 el-col-xs-16 el-col-sm-12"]/a/h2/text()').extract_first()
item["categories"] = ','.join(response.xpath('//div[@class="el-card__body"]/div[@class="item el-row"]/div[@class="p-h el-col el-col-24 el-col-xs-16 el-col-sm-12"]/div[@class="categories"]/button/span/text()').extract())
item["score"] = ''.join(response.xpath('//div[@class="el-card__body"]/div[@class="item el-row"]/div[@class="el-col el-col-24 el-col-xs-8 el-col-sm-4"]/p/text()').extract_first()).replace("\n","").replace(" ","")
item["drama"] = ''.join(response.xpath('//div[@class="el-card__body"]/div[@class="item el-row"]/div[@class="p-h el-col el-col-24 el-col-xs-16 el-col-sm-12"]/div[@class="drama"]/p/text()').extract_first()).replace("\n","")
item["directors"] = ''.join(response.xpath('//div[@class="directors el-row"]/div[@class="director el-col el-col-4"]/div[@class="el-card is-hover-shadow"]/div[@class="el-card__body"]/p/text()').extract())
item["actors"] = []
ss = response.xpath('//div[@class="actors el-row"]//div[@class="actor el-col el-col-4"]')
for data in ss:
actors_image = ''.join(data.xpath('./div/div/img/@src').extract())
actors_name = ''.join(data.xpath('./div/div/p/text()').extract())
item["actors"].append({
"name":actors_name,
"actors_image":actors_image
})
yield item在这里我们首先创建了一个TestitempipelineItem对象,赋值为item,然后我们使用xpath方法提取了name、categories、score、drama、directors、actors六个字段,最后组合成了一个列表赋值给actors,其中的actors信息包括image和name两个信息,以字典的形式添加进actors里面。运行以下,结果如下:

可以看到我们这里已经成功提取了各个字段然后生成了MovieItem对象了。那么下一步就是我们的重点了,我们需要将爬取到的内容存储到MongoDB和本地文件夹中。
如果不知道MongoDB的环境怎么配置可以参考这篇博客:MongoDB - 乐之之 - 博客园 (cnblogs.com)
2、MongoDB Pipeline
那么我们需要实现一个MongoDBPipeline,将信息保存到MongoDB,在pipelines.py里添加如下类的实现:
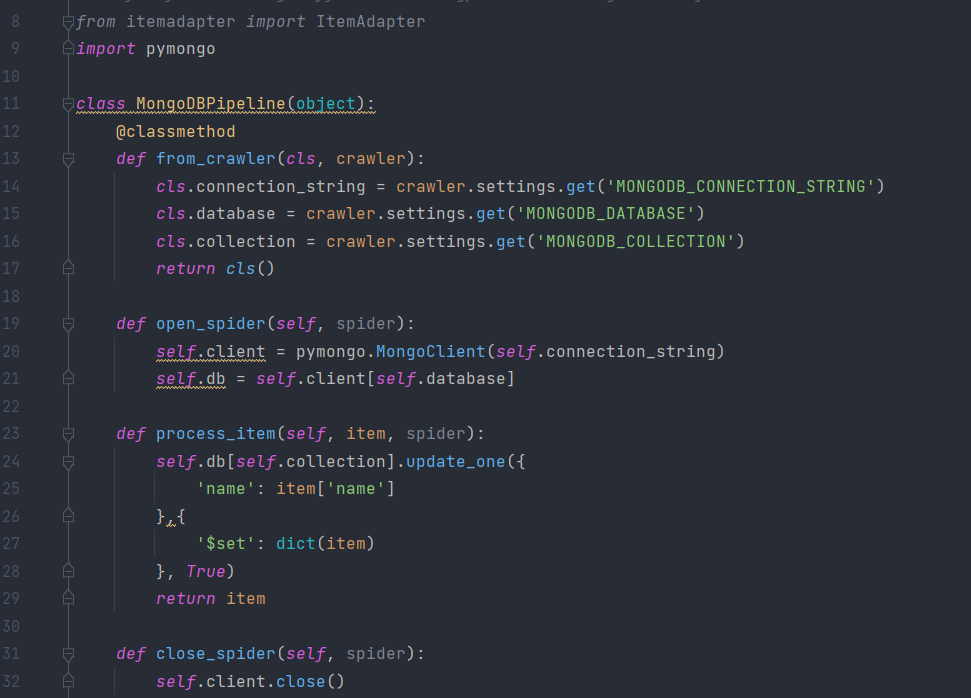
这里我们首先利用from_crawler获取了全局配置MONGODB_CONNECTION_STRING、MONGODB_DATABASE和MONGODB_COLLECTION,即MongoDB连接字符串、数据库名称、集合名词,然后将三者赋值为类属性。
接着我们实现了open_spider方法,该方法就是利用from_crawler赋值的connection_string创建一个MongoDB连接对象,然后声明数据库操作对象,close_spider则是在Spider运行结束时关闭MongoDB连接。
接着最重要的就是process_item方法了,这个方法接收的参数item就是从Spider生成的Item对象,该方法需要将此Item存储到MongoDB中,这里我们使用update_one方法实现了存在即更新。不存在则插入的功能。
接下来我们需要在settngs.py里面添加MONGODB_CONNECTION_STRING、MONGODB_DATABASE和MONGODB_COLLECTION这三个变量,相关代码如下:
MONGODB_CONNECTION_STRING = os.getenv('MONGODB_CONNECTION_STRING')
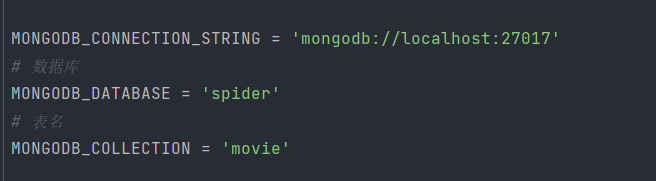
# 数据库
MONGODB_DATABASE = 'spider'
# 表名
MONGODB_COLLECTION = 'movies'这里可以将MONGODB_CONNECTION_STRING设置为从环境变量中读取,而不用将明文、密码等信息写到代码里。
如果是本地无密码的MongoDB,直接写为如下内容即可:
MONGODB_CONNECTION_STRING = 'mongodb://localhost:27017'如下所示:
这样,一个保存到MongoDB的Pipeline就创建好了,利用process_item方法我们即可完成数据插入到MongoDB的操作,最后会返回Item对象。
3、image Pipeline
Scrapy 提供了专门处理下载的 Pipeline,包括文件下载和图片下载。下载文件和图片的原理与抓取页面的原理一样,因此下载过程支持异步和多线程,十分高效。下面我们来看看具体的实现过程。
官方文档地址为:https://doc.scrapy.org/en/latest/topics/media-pipeline.html。
首先定义存储文件的路径,需要定义一个IMAGES_STORE 变量,在settingspy 中添加如下代码:
IMAGES_STORE='./images'
在这里我们将路径定义为当前路径下的images子文件夹,即下载的图片都会保存到本项目的images文件夹中。
内置的 ImagesPipeline 会默认读取Item 的 image_urls 字段,并认为它是列表形式,接着遍历该字段后取出每个URL进行图片下载。
但是现在生成的Item的图片链接字段并不是 image_urls 字段表示的,我们是想下载directors和actors的每张图片。所以为了实现下载,我们需要重新定义下载的部分逻辑,即自定义ImagePipeline继承内置的ImagesPipeline,重写几个方法。
我们定义的ImagePipeline代码如下:
class ImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for director in item['directors']:
director_name= director['name']
director_image =director['image']
yield Request(director_image, meta={
'name': director_name,
'type':'director',
'movie':item['name']
})
for actor in item['actors']:
actor_name = actor['name']
actor_image = actor['image']
yield Request(actor_image,meta= {
'name': actor_name,
'type': 'actor',
'movie': item['name']
})
def file_path(self, request, response=None, info=None):
movie = request.meta['movie']
print(f"movie:<{movie}>")
type = request.meta['type']
print(f"type:<{type}>")
name = request.meta['name']
print(f"name:<{name}>")
file_name = f'{movie}/{type}/{name}.jpg'.replace(" ","")
print(f"file_name:<{file_name}>")
return file_name
def item_completed(self, results,item, info):
print("item:",f'<{item}>')
image_paths=[x['path'] for ok,x in results if ok]
if not image_paths:
raise DropItem('Image Downloaded Failed')
return item在这里我们实现了 ImagePipeline,继承Scrapy内置的ImagesPipeline,重写下面几个方法。
- get _media requests:第一个参数item是爬取生成的Item 对象、我们要下载的图片链接保存在Item的directors和actors每个元素的image字段中。所以我们将URL逐个取出,然后构造 Request 发起下载请求。同时我们指定了 meta信息,方便构造图片的存储路径,以便在下载完成时使用。
- file_path:第一个参数request就是当前下载对应的Request对象。这个方法用来返回保存的文件名,在这里我们获取了刚才生成的 Request 的 meta 信息,包括 movie (电影名称)、type(电影类型)和name(导演或演员姓名),最终三者拼合为 file name作为最终的图片路径。
- item_completed:单个Item完成下载时的处理方法。因为并不是每张图片都会下载成功,所以我们需要分析下载结果并剔除下载失败的图片。如果某张图片下载失败,那么我们就不需将此Item保存到数据库。item_ompleted方法的第一个参数results就是该Item对应的下载结果它是一个列表,列表的每个元素是一个元组,其中包含了下载成功或失败的信息。这里我们遍历下载结果,找出所有成功的下载列表。如果列表为空,那么该 Item 对应的图片下载失败,随即抛出DropItem异常,忽略该Item;否则返回该Item,说明此Item有效。
现在为止,2个Item Pipeline 的定义就完成了。最后只需要启用就可以了,修改settings.py,设置ITEMPIPELINES的代码如下所示:
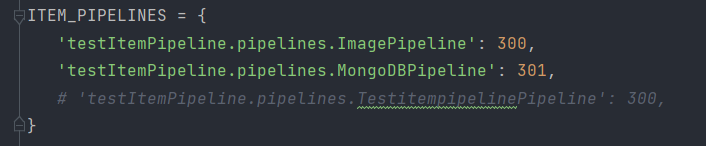
这里要注意调用的顺序。我们需要优先调用ImagePipeline对Item做下载后的筛选,下载失败的Item就直接忽略,它们不会保存到 MongoDB和MySQL里。随后再调用其他两个存储的 Pipeline,这样就能确保存人数据库的图片都是下载成功的。
接下来运行程序,命令如下:
- scrapy crawl movie_spider
爬虫一边爬取一遍爬取,速度非常快。
接下来,我们来查看一下本地images文件夹,发现图片都已经下载成功,如下图所示:
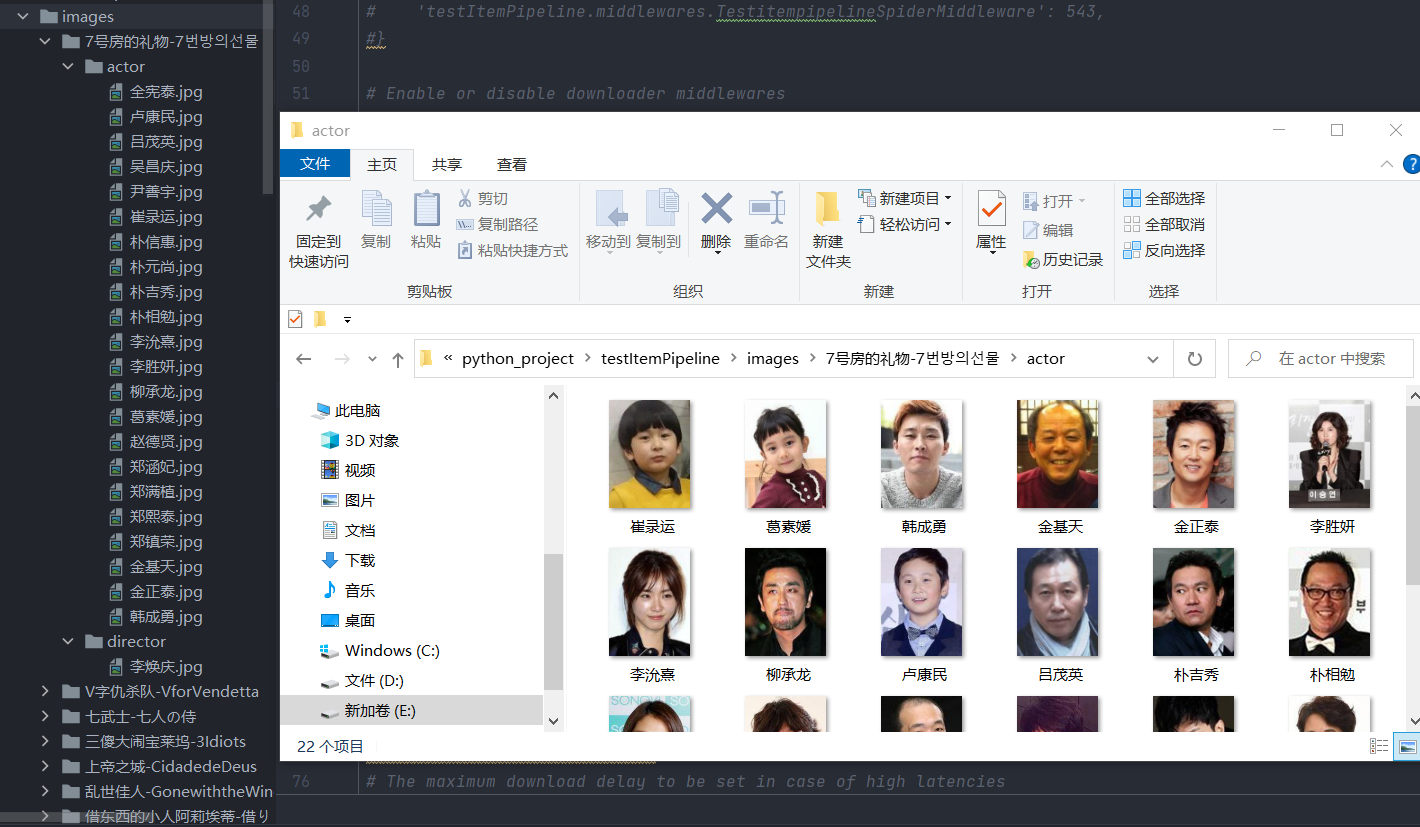
可以看到图片已经分路径存储了,一部电影一个文件夹,演员和导演分二级文件夹,图片名直接以演员和导演名命名。
然后我们再来查看一下MongoDB,下载成功的图片信息同样已经成功保存,如下图所示
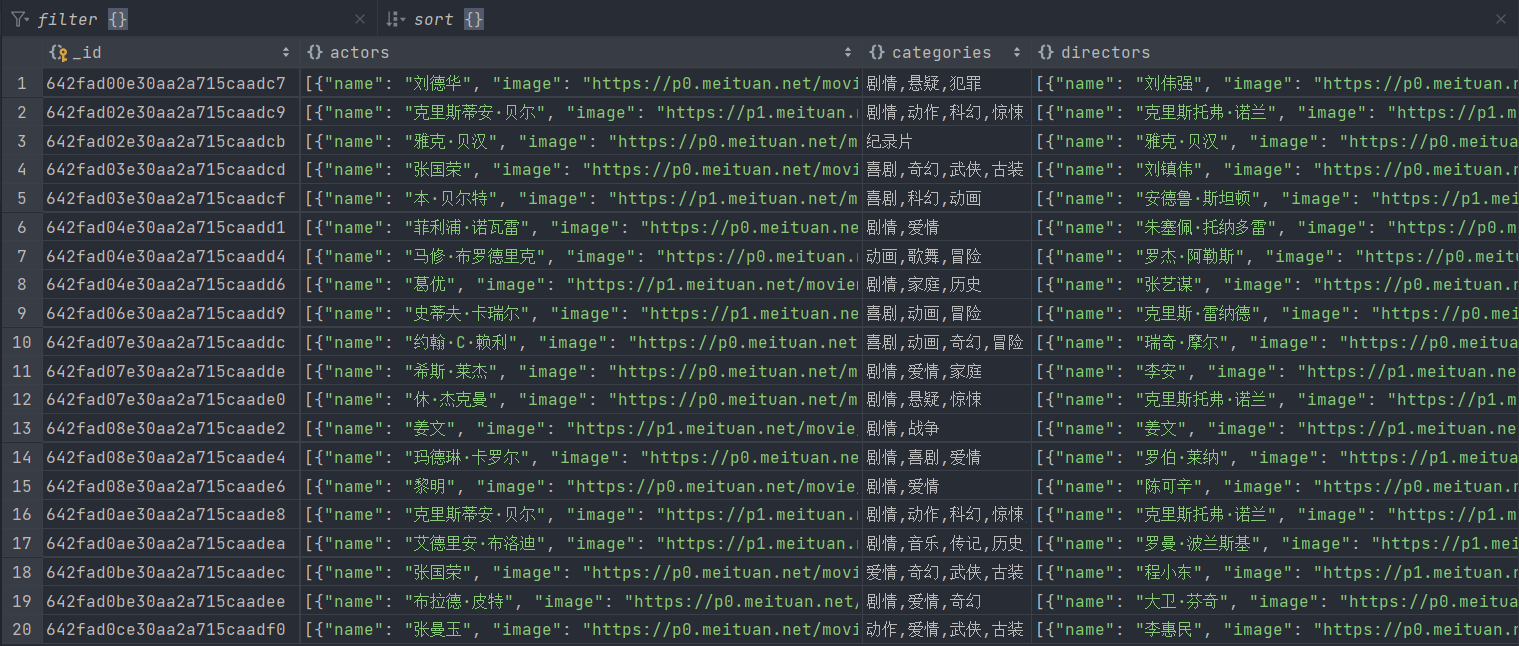
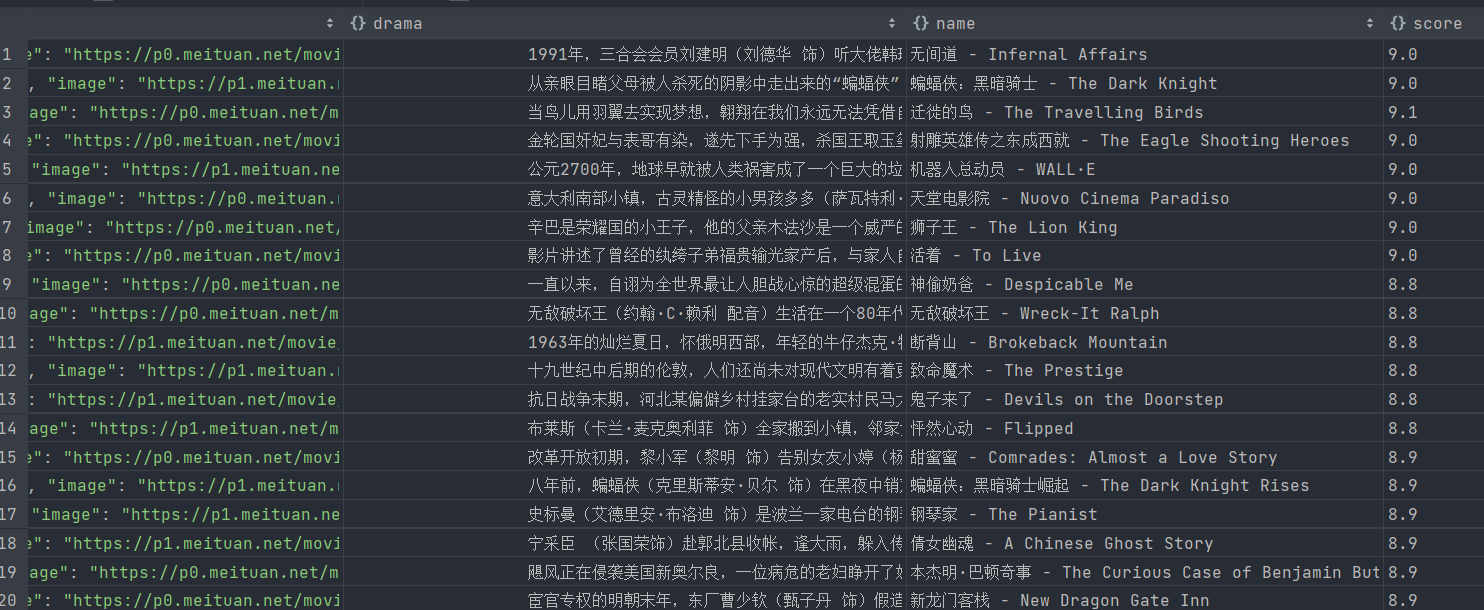
这样我们就成功的实现图片的下载并把图片的信息存入数据库里了。