使用模型
复旦nlp——fnlp_bart_large_Chinese
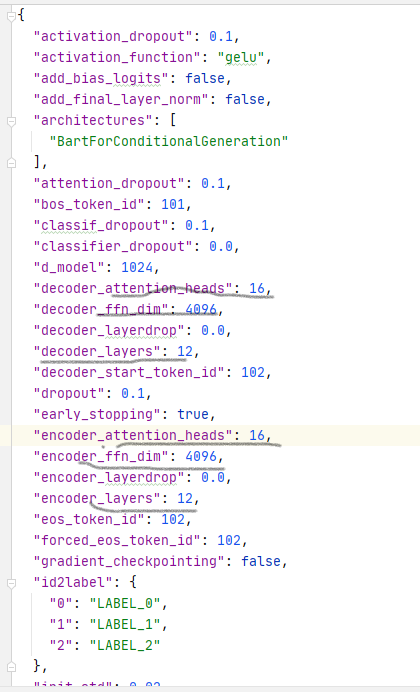
| 注意力头 | encoder/decoder层数 | 词嵌入表示 |
|---|---|---|
| 16 | 12 | 1024 |
词典使用BertTokenizer, vocab_size: 51271
在nlpcc数据集上微调模型
原fnlp_bart_large_Chinese是一个通用的文本生成任务的模型,在nlpcc数据集上微调,使之适用于摘要任务。
nlpcc数据集:

使用在nlpcc数据集上训练好的模型,评估模型性能
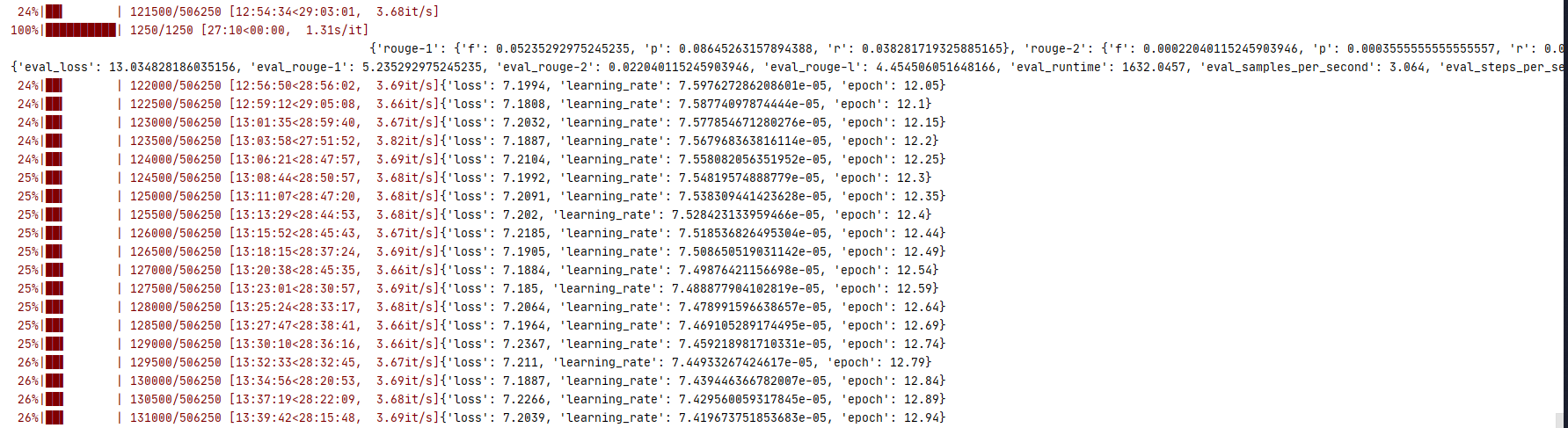
{
'rouge-1': {'f': 0.05235292975245235, 'p': 0.08645263157894388, 'r': 0.038281719325885165},
'rouge-2': {'f': 0.00022040115245903946, 'p': 0.0003555555555555557, 'r': 0.00016269035604260447},
'rouge-l': {'f': 0.04454506051648166, 'p': 0.07328421052631329, 'r': 0.032644400904541925}}
{'eval_loss': 13.034828186035156, 'eval_rouge-1': 5.235292975245235, 'eval_rouge-2': 0.022040115245903946, 'eval_rouge-l': 4.454506051648166, 'eval_runtime': 1632.0457, 'eval_samples_per_second': 3.064, 'eval_steps_per_second': 0.766, 'epoch': 12.0}
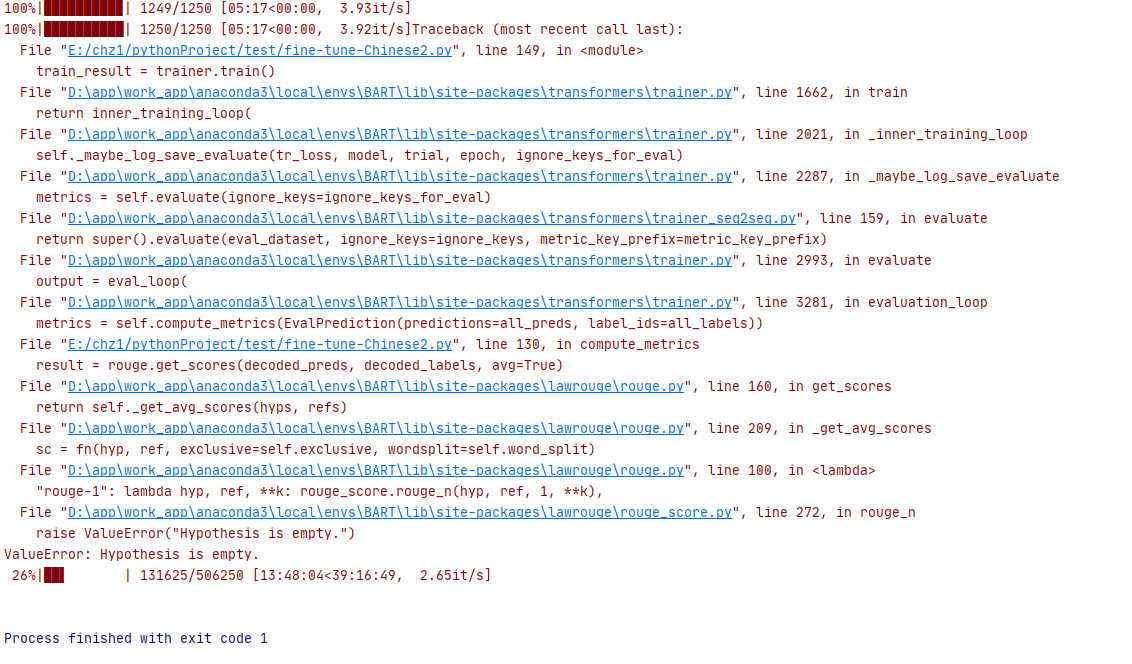
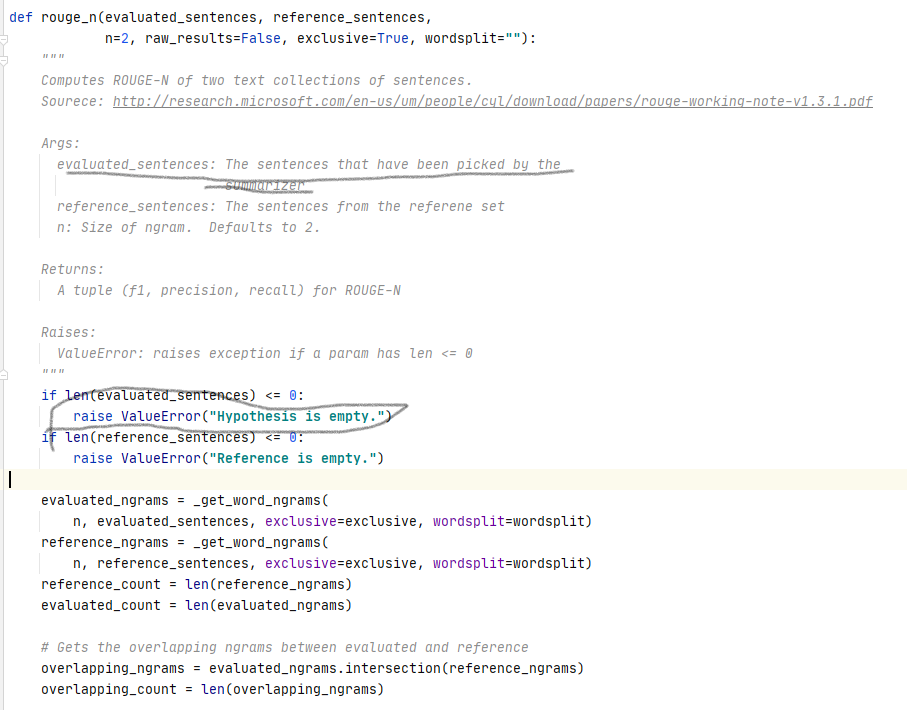
训练12个小时后,出错退出。原因:训练某个句子时输出摘要为空
使用现有关于中文摘要的BART
IDEA-CCNL/Randeng-BART-139M-SUMMARY模型
基于Randeng-BART-139M,在收集的1个中文领域的文本摘要数据集(LCSTS)上微调了它,得到了summary版本。
测试数据:nlpcc数据集
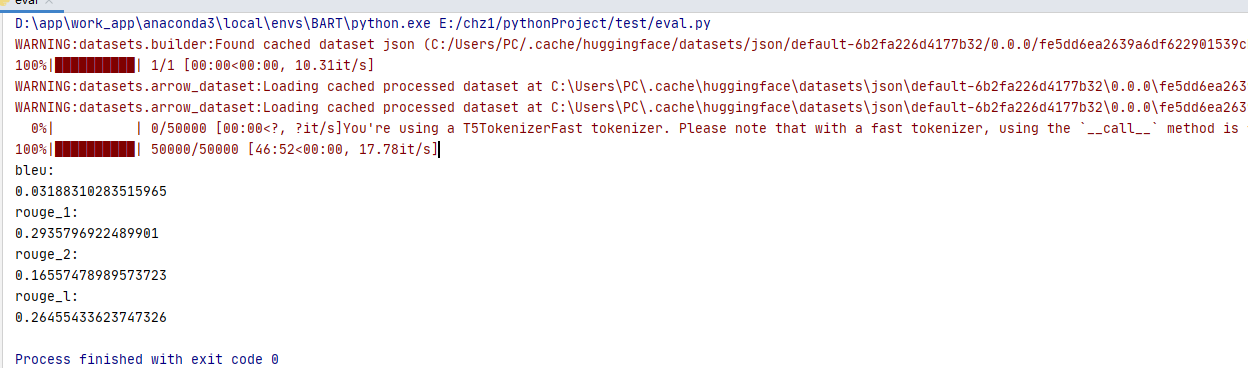

IDEA-CCNL/Randeng-Pegasus-238M-Summary-Chinese
基于Randeng-Pegasus-238M-Chinese,我们在收集的7个中文领域的文本摘要数据集(约4M个样本)上微调了它,得到了summary版本。这7个数据集为:education, new2016zh, nlpcc, shence, sohu, thucnews和weibo。
测试数据:nlpcc数据集


fnlp/bart-large-chinese
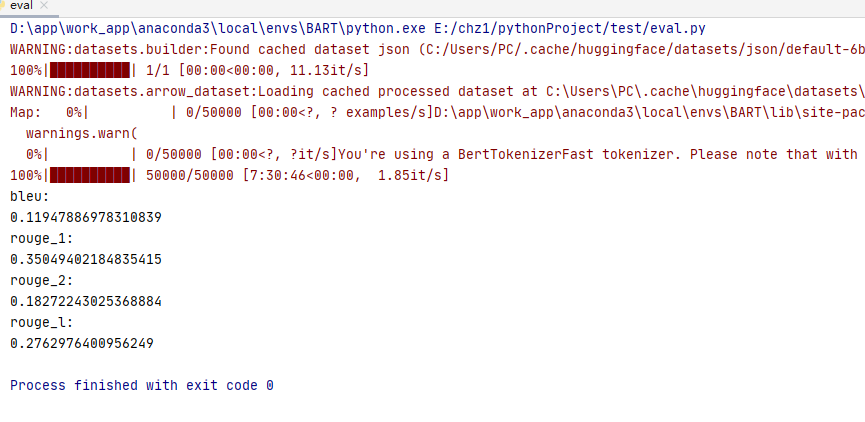

参考:
Distributed Training: Train BART/T5 for Summarization using ? Transformers and Amazon SageMaker