一、 第五章 定时器及时钟服务
1、并行计算
是一种计算方案,它尝试使用多个执行并行算法的处理器更快速的解决问题
顺序算法与并行算法

并行性与并发性
并行算法只识别可并行执行的任务。CPU系统中,并发性是通过多任务处理来实现的
2、线程
线程的原理:某进程同一地址空间上的独立执行单元
线程的优点
线程创建和切换速度更快
线程的响应速度更快
线程更适合并行运算
线程的缺点
线程需要来自用户的明确同步
库函数不安全
单CPU系统中,线程解决问题实际上要比使用顺序程序慢
3、线程操作
线程可在内核模式或用户模式下执行
其中涉及Linux下的pthread并发编程
线程管理函数
创建线程
pthread_create()
int pthread_create(pthread_t *pthread_id,pthread_attr_t *attr,void *(*func)(void*),void *arg)
其中:
1、pthread_id是指向pthread_t类型变量的指针
2、attr如果是NULL,将使用默认属性创建线程
线程ID
int pthread_equal(pthread_t t1,pthread_t t2);
不同的线程,返回0,否则返回非0
线程终止
int pthread_exit(void *status);
线程连接
int pthread_join(pthread_t thread,void **status_ptr)
线程同步
竞态条件:修改结果取决于线程执行顺序
互斥量
在pthread中,锁被称为互斥量
pthread_mutex_lock(&m);
access shared data object;
pthread_mutex_unlock(&m);
死锁预防
死锁是一个状态,在这种状态下,许多执行实体相互等待,无法继续进行下去
条件变量
条件变量可以通过两种方法进行初始化:静态方法,动态方法
生产者-消费者问题
共享全局变量
int buf[NBUF];
int head,tail;
int data;
4.信号量
信号量是进程同步的一般机制
信号量和条件变量
屏障
线程连接操作允许某线程等待其他线程终止
在pthread中可以采用的机制是屏障以及一系列屏障函数
Linux中的线程
进程和线程都是由clone()系统调用创建的具有以下原型
int clone(int (*fn)(void*),void *child_stack,int flags,void *arg)
信号量与条件变量的区别:
条件变量、互斥锁——主要用于线程间通信
pthread_cond_wait()
pthread_cond_wait(&m_cond,&m_mutex); 指的是等待条件变量,总和一个互斥锁结合使用。
pthread_cond_wait() 函数执行时先自动释放指定的互斥锁,然后等待条件变量的变化;在函数调用返回之前(即wait成功获得cond条件的时候),会自动将指定的互斥量重新锁住(即在“等待的条件变量满足条件时,会重新锁住指定的锁”)。
二、代码实践
1、利用线程计算矩阵的和
代码
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define ROWS 3
#define COLS 3
#define THREADS_NUM 3
int matrix[ROWS][COLS] = {{1, 2, 3}, {4, 5, 6}, {7, 8, 9}};
int sum[THREADS_NUM] = {0};
pthread_t threads[THREADS_NUM];
void *thread_func(void *arg) {
int tid = *(int *)arg;
int start = tid * ROWS / THREADS_NUM;
int end = (tid + 1) * ROWS / THREADS_NUM;
for (int i = start; i < end; i++) {
for (int j = 0; j < COLS; j++) {
sum[tid] += matrix[i][j];
}
}
pthread_exit(NULL);
}
int main() {
int thread_args[THREADS_NUM];
for (int i = 0; i < THREADS_NUM; i++) {
thread_args[i] = i;
pthread_create(&threads[i], NULL, thread_func, &thread_args[i]);
}
for (int i = 0; i < THREADS_NUM; i++) {
pthread_join(threads[i], NULL);
}
int total_sum = 0;
for (int i = 0; i < THREADS_NUM; i++) {
total_sum += sum[i];
}
printf("The sum of the matrix is %d\n", total_sum);
return 0;
}
代码分析:
该代码中,我们首先定义了一个 3x3 的矩阵和 3 个线程。每个线程计算矩阵的一部分,并将结果存储在 sum 数组中。最后,我们将所有线程计算出的结果相加,得到矩阵的总和。
主函数中:为每个线程创建一个参数数组 thread_args,然后创建 THREADS_NUM 个线程,并将线程 ID 和参数数组传递给线程函数 thread_func。
线程函数中:根据线程 ID 计算出该线程要处理的矩阵部分,然后计算该部分的和并存储在 sum 数组中。
主函数等待所有线程执行完毕后,将 sum 数组中的所有元素相加,得到矩阵的总和,并输出结果。
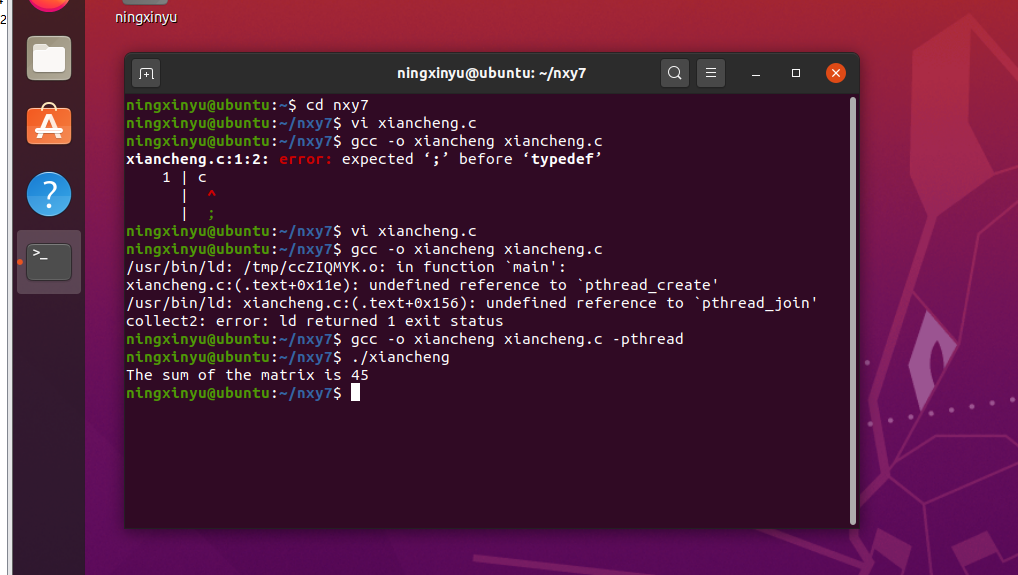
遇到的问题:
缺少相关的库
2、生产者·消费者问题
代码
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#define BUFFER_SIZE 5
#define NUM_ITEMS 10
int buffer[BUFFER_SIZE];
int count = 0;
int in = 0;
int out = 0;
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t full = PTHREAD_COND_INITIALIZER;
pthread_cond_t empty = PTHREAD_COND_INITIALIZER;
void *producer(void *arg) {
for (int i = 0; i < NUM_ITEMS; i++) {
pthread_mutex_lock(&mutex);
while (count == BUFFER_SIZE) {
pthread_cond_wait(&full, &mutex);
}
buffer[in] = i;
in = (in + 1) % BUFFER_SIZE;
count++;
printf("Produced item: %d\n", i);
pthread_cond_signal(&empty);
pthread_mutex_unlock(&mutex);
}
pthread_exit(NULL);
}
void *consumer(void *arg) {
for (int i = 0; i < NUM_ITEMS; i++) {
pthread_mutex_lock(&mutex);
while (count == 0) {
pthread_cond_wait(&empty, &mutex);
}
int item = buffer[out];
out = (out + 1) % BUFFER_SIZE;
count--;
printf("Consumed item: %d\n", item);
pthread_cond_signal(&full);
pthread_mutex_unlock(&mutex);
}
pthread_exit(NULL);
}
int main() {
pthread_t producer_thread, consumer_thread;
pthread_create(&producer_thread, NULL, producer, NULL);
pthread_create(&consumer_thread, NULL, consumer, NULL);
pthread_join(producer_thread, NULL);
pthread_join(consumer_thread, NULL);
return 0;
}
代码分析
使用一个大小为 BUFFER_SIZE 的缓冲区来模拟生产者和消费者之间的共享数据。生产者线程负责向缓冲区中生产数据,消费者线程负责从缓冲区中消费数据。
生产者线程在每次生产完一个数据项后,会先获取互斥锁 mutex,然后检查缓冲区是否已满(count == BUFFER_SIZE)。如果缓冲区已满,则调用 pthread_cond_wait 函数等待消费者线程发出的非空信号(empty)。一旦收到非空信号,生产者线程将数据写入缓冲区,并更新相关变量。最后,生产者线程发出缓冲区已满的信号(full),释放互斥锁 mutex。
消费者线程的逻辑类似,它在每次消费一个数据项后,会先获取互斥锁 mutex,然后检查缓冲区是否为空(count == 0)。如果缓冲区为空,则调用 pthread_cond_wait 函数等待生产者线程发出的非满信号(full)。一旦收到非满信号,消费者线程从缓冲区中读取数据,并更新相关变量。最后,消费者线程发出缓冲区已空的信号(empty),释放互斥锁 mutex。
在主函数中,我们创建一个生产者线程和一个消费者线程,并使用 pthread_join 函数等待它们的结束。这样,生产者和消费者就可以并发地执行。
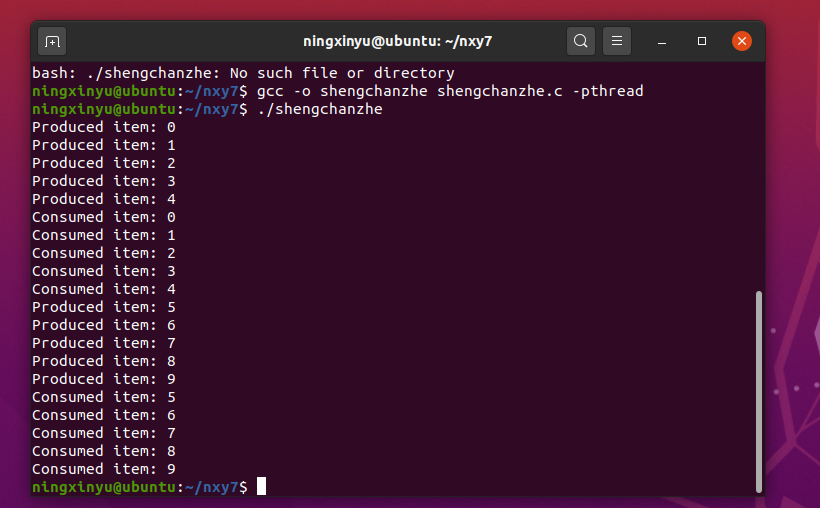
显然,输出结果符合预期。生产者线程生产了 10 个数据项,消费者线程消费了这些数据项,并且生产者和消费者交替进行,以避免缓冲区溢出或下溢。
需要注意的是,由于线程的并发执行,生产者和消费者的输出顺序可能会不同,但每个数据项的生产和消费都是正确的。
由于缓冲区大小为 5,因此在生产者和消费者之间存在一定的同步和竞争关系,这也体现了线程间通信和同步的重要性。
三、苏格拉底问答




