2023数据采集与融合技术实践作业2
作业 ① :
- 要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
代码:
import requests
import urllib.error
from bs4 import BeautifulSoup
import pymysql
db = pymysql.connect(host='localhost', user='root', password='qazqaz123',autocommit=True,auth_plugin_map='mysql_native_password')
cursor = db.cursor()
cursor.execute('create database if not exists data')
cursor.execute('use data')
url = 'http://www.weather.com.cn/weather/101020100.shtml'
html = ''
try:
html = requests.get(url)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
html = html.content
bs = BeautifulSoup(html, "html.parser")
soup = bs.find_all('ul',attrs={'class':'t clearfix'})
name = soup[0].text.split('\n')
for i in range(0,6):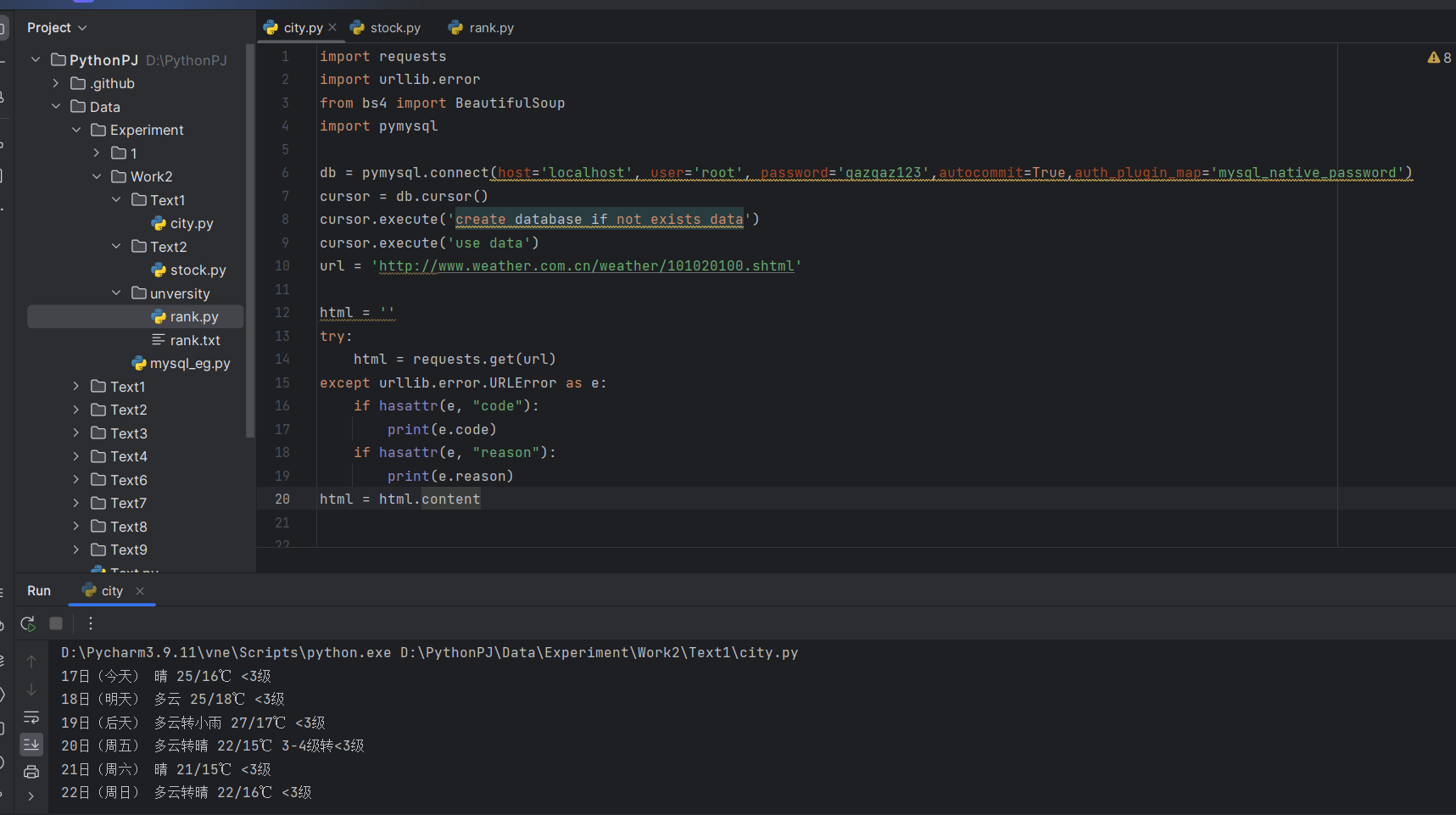
print(name[2+i*17] + ' ' + name[5+i*17] + ' ' + name[7+i*17] + ' ' + name[14+i*17])
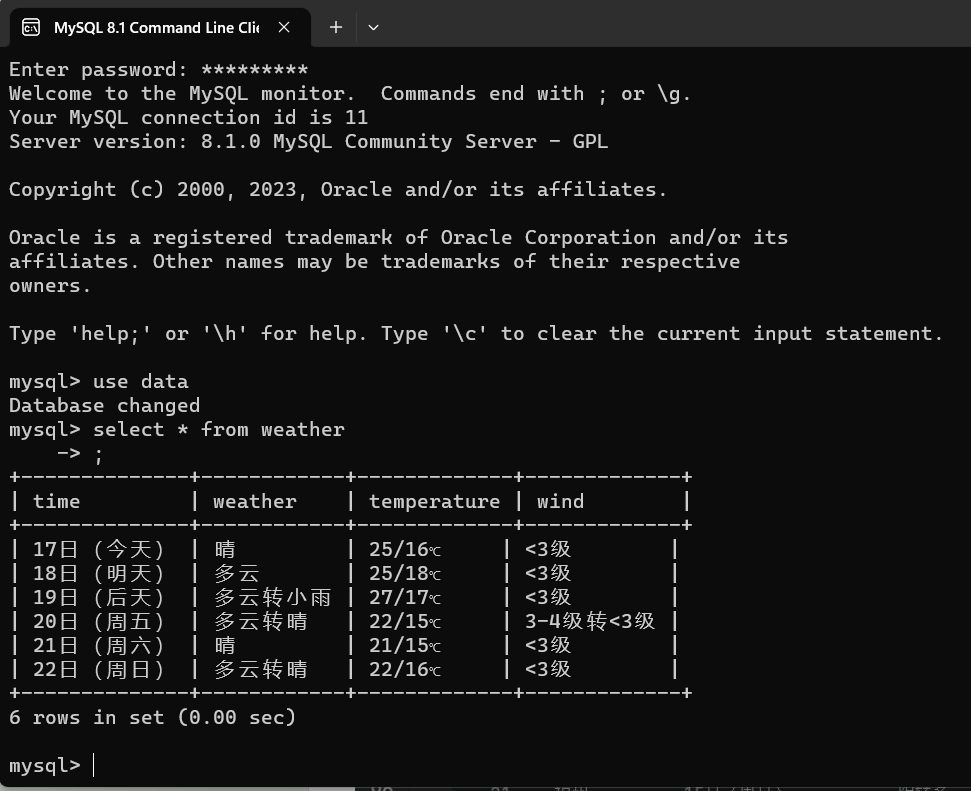
cursor.execute('create table if not exists weather(time varchar(20),weather varchar(20),temperature varchar(20),wind varchar(20))')
cursor.execute('truncate table weather')
for i in range(0,6):
cursor.execute('insert into weather values(%s,%s,%s,%s)',(name[2+i*17],name[5+i*17],name[7+i*17],name[14+i*17]))
db.close()
运行结果截图:

数据库显示:
心得体会
爬取数据使用了较为简陋的方式,没有寻求更好的筛选方法。对于城市也没有寻找各自的数字代码使得可以实现搜索的功能,程序可提升空间大
作业②
- 要求:用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
代码:
import requests
import re
import urllib.error
import math
import pymysql
db = pymysql.connect(host='localhost', user='root', password='qazqaz123',autocommit=True,auth_plugin_map='mysql_native_password')
cursor = db.cursor()
cursor.execute('create database if not exists data')
cursor.execute('use data')
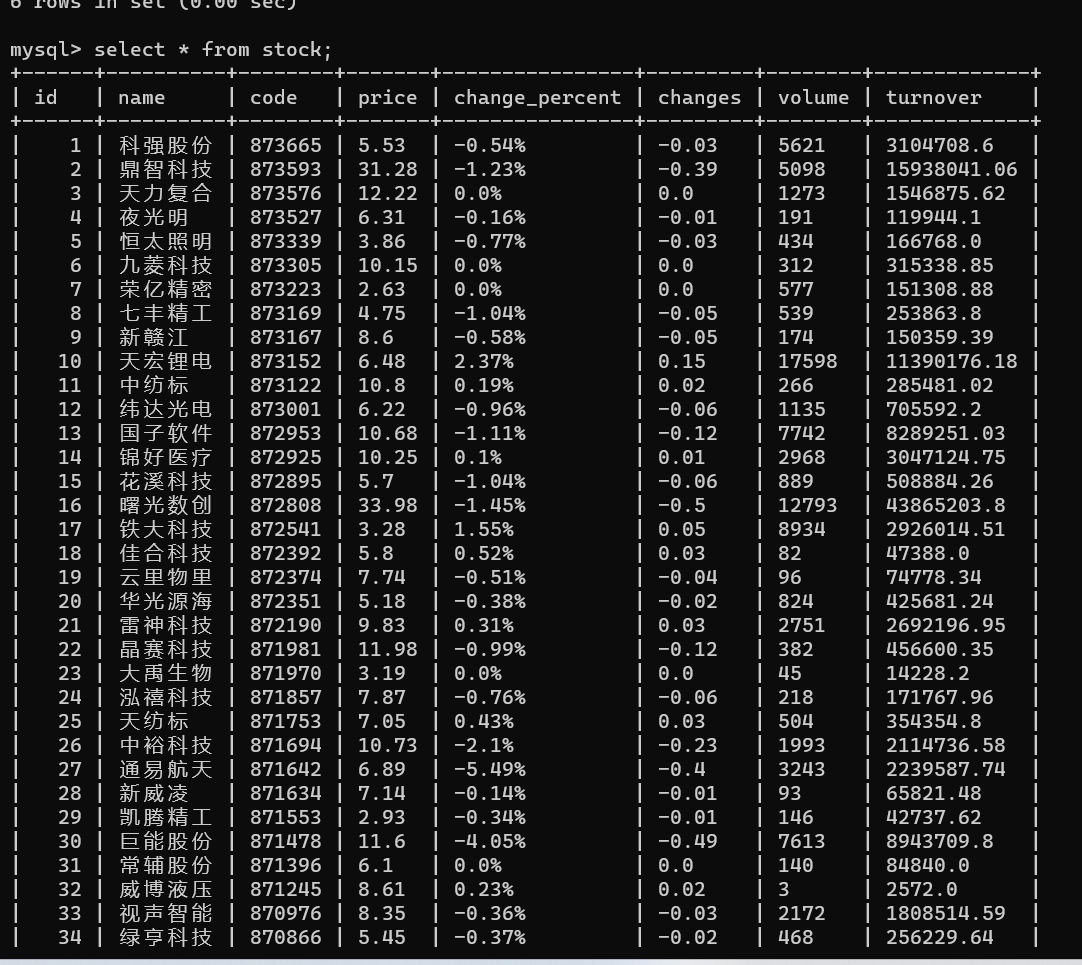
cursor.execute('create table if not exists stock(id INTEGER, name varchar(20), code varchar(20), price varchar(20), change_percent varchar(20), changes varchar(20), volume varchar(20), turnover varchar(20))')
cursor.execute('truncate table stock')
def get(k):
n = (k-1)*20
url =('https://18.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112407434943956153934_1696659291141&pn='+ str(k) +
'&pz=20&po=1&np=1'
'&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f12&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,'
'm:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f12,f14&_=1696659291147')
html = ''
try:
html = requests.get(url)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
html = html.text
info = []
for i in range(2, 7):
r = r'f' + str(i) + '":(.*?),'
info.append(re.findall(r, html))
info.append(re.findall(r'f12":"(.*?)",', html))
info.append(re.findall(r'f14":"(.*?)"', html))
for i in range(0, len(info[0])):
print(str(n + i + 1) + ' ' + info[6][i] + ' ' + info[5][i] + ' ' + info[0][i] + ' ' + info[1][i] + '% ' + info[2][
i] + '% ' + info[3][i] + ' ' + info[4][i])
return info
def insert(info,k):
n = (k - 1) * 20
for i in range(0, len(info[0])):
sql = 'insert into stock(id, name, code, price, change_percent, changes, volume, turnover) values(%s, %s, %s, %s, %s, %s, %s, %s)'
cursor.execute(sql, (n+i+1, info[6][i], info[5][i], info[0][i], info[1][i] + '%', info[2][i], info[3][i], info[4][i]))
def main():
k = input('请输入你要查询的股票数:')
print('序号' + ' ' + '名称' + ' ' + '代码' + ' ' + '最新价' + ' ' + '涨跌幅' + ' ' + '涨跌额' + ' ' + '成交量' + ' ' + '成交额')
k= math.floor(int(k)/20)
for i in range(k+1):
info = get(i)
insert(info,i)
if __name__ == '__main__':
main()
运行结果:

数据库显示:
心得体会
学会了抓取网页加载的js的url链接,根据分析url的结构以及根据自己的需求可以对其进行修改来获取指定信息。在抓取信息后发现股票信息是以json的形式存储,可采用将获取的html文本进行数据预处理,获取其json格式的数据,然后在将其加载在python内,最后再经过循环进行数据的提取。但是通过观察html文本发现其json的键只对应股票信息,所以也可以用re提取各个键来进行数据的提取

作业 ③ :
- 要求:爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。
获取js
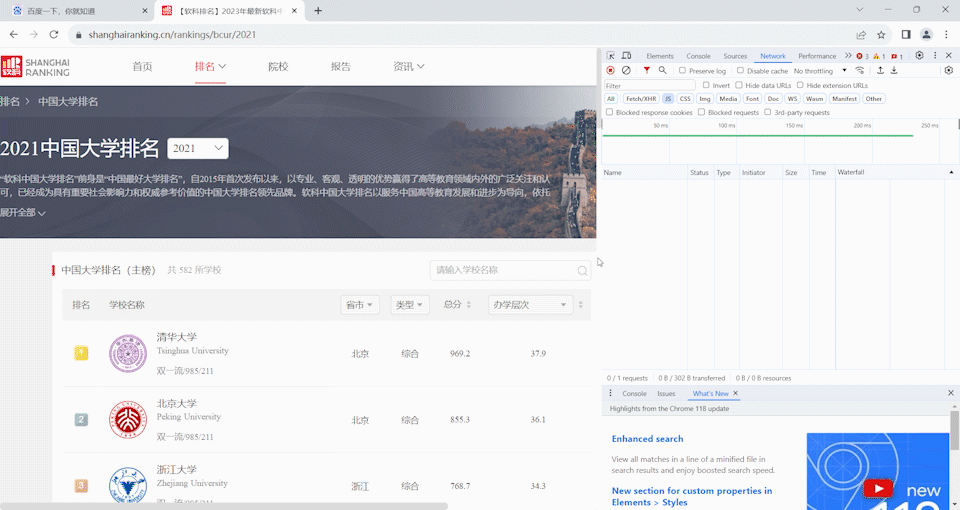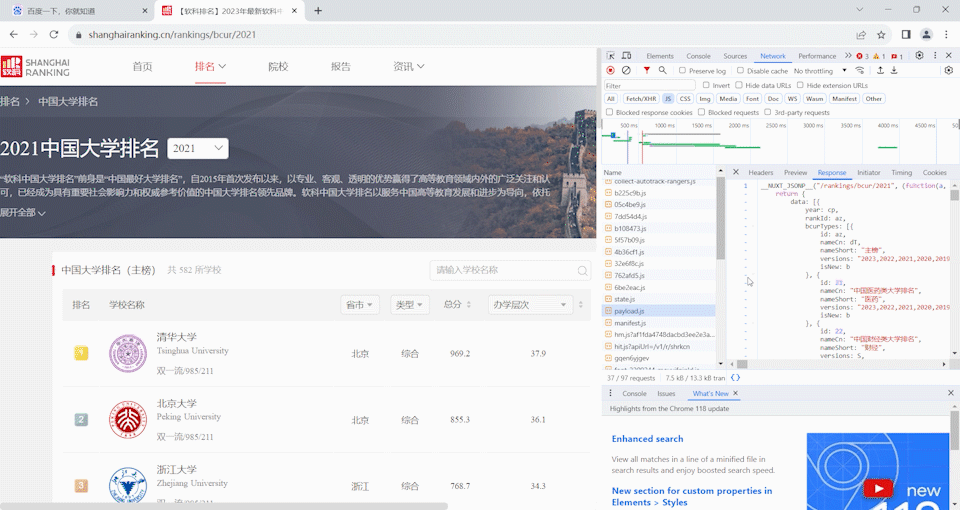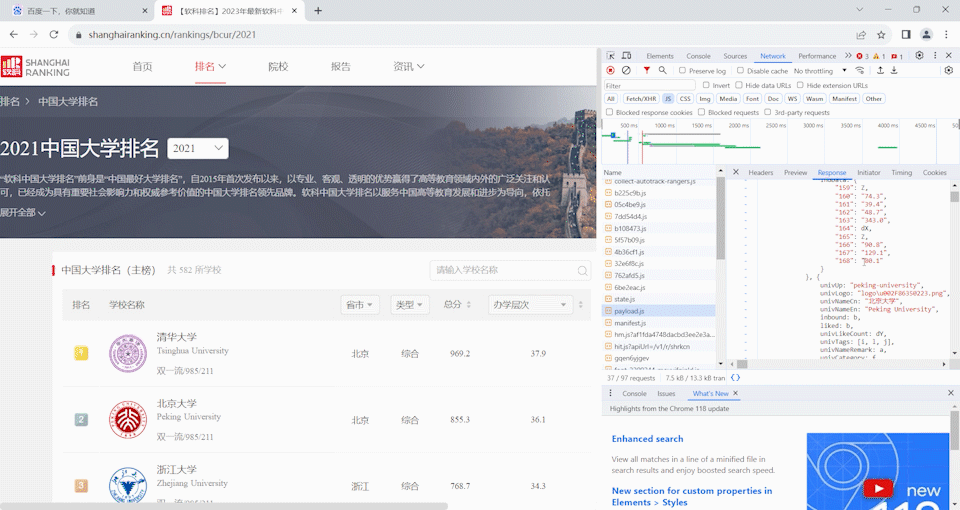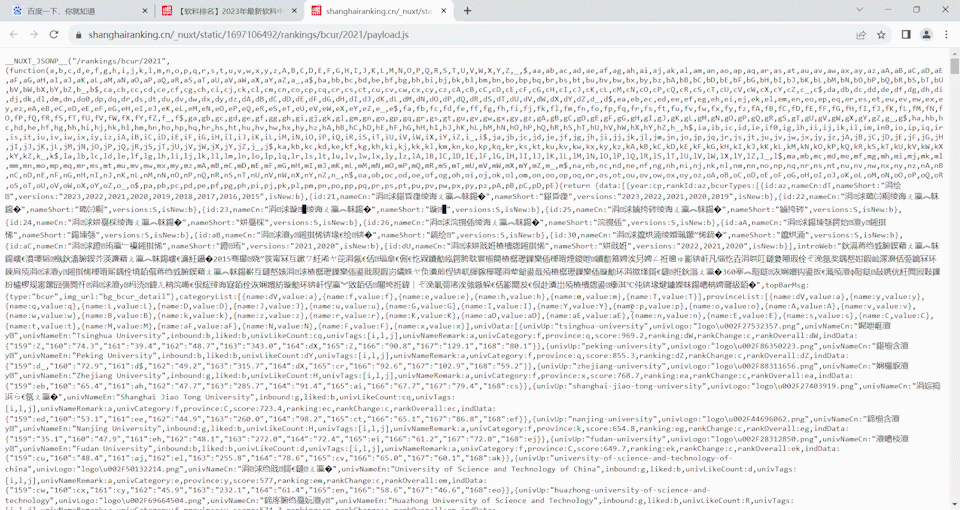
代码
import requests
import urllib.error
import re
import pymysql
url = 'https://www.shanghairanking.cn/_nuxt/static/1697106492/rankings/bcur/202111/payload.js'
province_map = {
'q': '青海','x': '西藏','C': '上海', 'k': '江苏', 'o': '河南','q': '北京',
'p': '河北','n': '山东','r': '辽宁','s': '陕西','t': '四川','u': '广东',
'v': '湖北','w': '湖南','x': '浙江','y': '安徽','z': '江西','A': '黑龙江',
'B': '吉林','D': '福建','E': '山西','F': '云南','G': '广西','I': '贵州',
'J': '甘肃','K': '内蒙古','L': '重庆','M': '天津','N': '新疆','Y': '海南',
'aD':'香港','aE': '澳门','aF': '台湾','aG': '南海诸岛', 'aH': '钓鱼岛',
'aD':'宁夏'
}
category_map = {
'f': '综合','e': '理工','h': '师范','m': '农业','T': '林业',
}
db = pymysql.connect(host='localhost', user='root', password='qazqaz123',autocommit=True,auth_plugin_map='mysql_native_password')
cursor = db.cursor()
cursor.execute('create database if not exists data')
cursor.execute('use data')
cursor.execute('create table if not exists university(ranks int,name varchar(20),location varchar(20),type varchar(20),point varchar(20))')
cursor.execute('truncate table university')
def get(url):
html = ''
try:
html = requests.get(url)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
html = html.text
info = []
name = re.findall(r'univNameCn:"(.*?)"',html)
score = re.findall(r'score:(.*?),',html)
province = re.findall(r'province:(.*?),',html)
univCategory = re.findall(r'univCategory:(.*?),',html)
return name,score,province,univCategory
def insert(name,score,province,univCategory):
for i in range(0, len(name)):
s = re.findall(r'\d', score[i])
if(s==[]):
score[i] = score[i-1]
cursor.execute('insert into university values(%s,%s,%s,%s,%s)',
(i + 1, name[i], province_map[province[i]], category_map[univCategory[i]], score[i]))
def main():
name,score,province,univCategory = get(url)
score.append('0')
insert(name,score,province,univCategory)
for i in range(0, len(name)):
s = re.findall(r'\d', score[i])
if(s==[]):
score[i] = score[i-1]
print(i+1, name[i], province_map[province[i]], category_map[univCategory[i]], score[i])
if __name__ == '__main__':
main()
运行结果
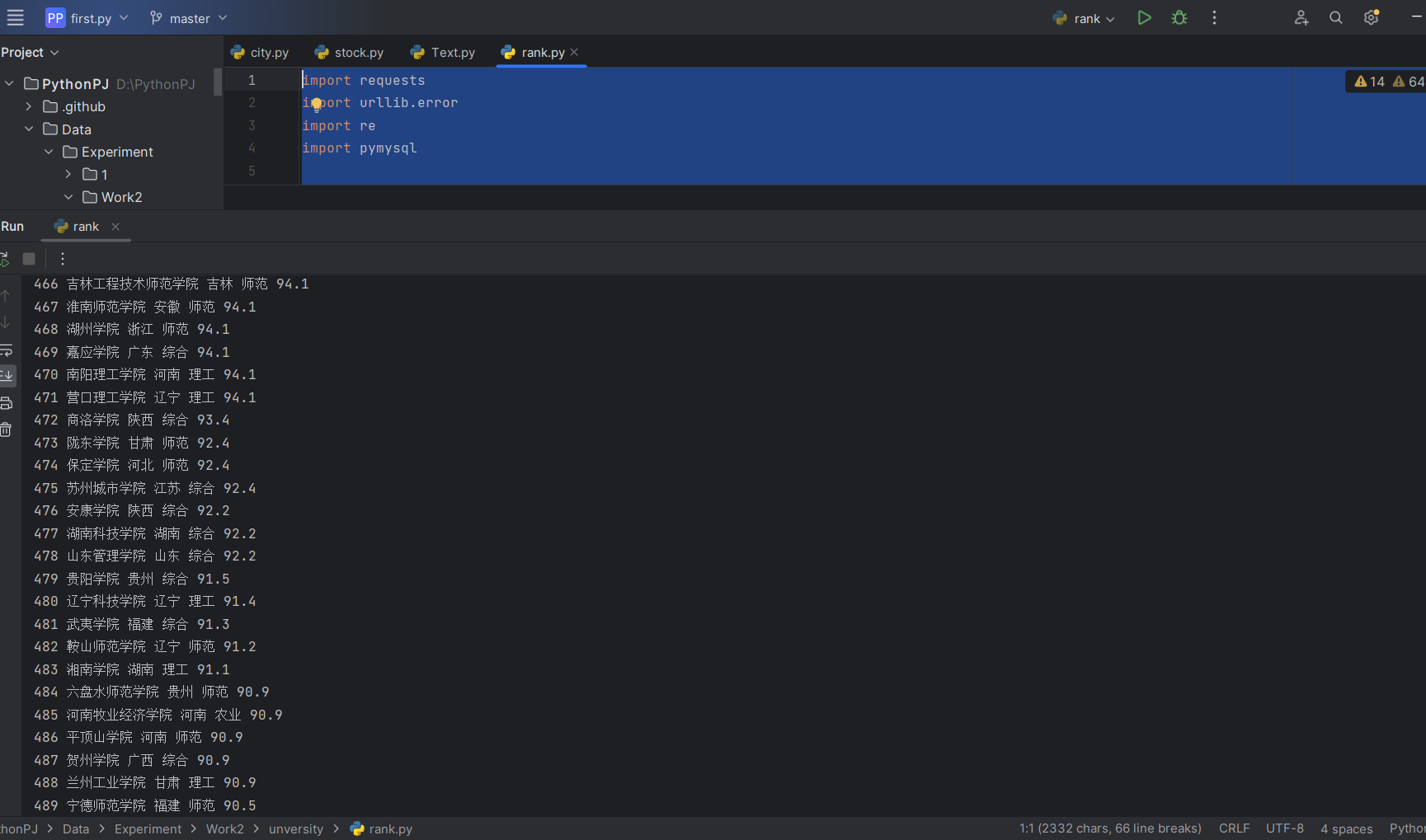
数据库显示

心得体会
处理与股票类似,但是该网站的json对应的数据进行了一定的隐藏,需要我们在提取数据后进行转码得到精确的键值,再者是其在分数事项时对相同的分数会进行字母化处理,需要我们进行处理