发表时间:2020 (NeurIPS 2020)
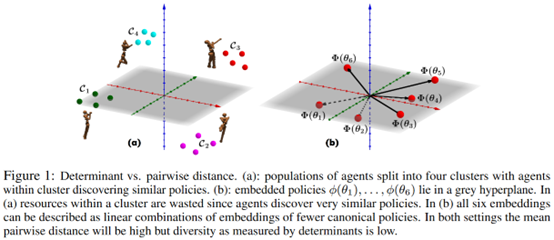
文章要点:这篇文章提出了Diversity via Determinants (DvD)算法来提升种群里的多样性。之前的方法通常都考虑的两两之间的距离,然后设计一些指标或者加权来增加种群多样性,这种方式容易出现cycling,也就是类似石头剪刀布的循环克制的关系,造成训练不上去,或者冗余的策略。作者提出的DvD是基于行列式的,在优化的时候同时考虑种群里的所有策略,这就比两两比较距离有更好的效果。
具体的,先定义一个策略表征向量来表示一个策略

然后用核函数来计算各个策略的相似度

有了这个之后,就可以构建整个种群相似度的行列式

有了这个之后就用强化的方式更新就好了

这里就相当于在通常的强化上面再加了一个population diversity的正则项,比如文章用的TD3。
文章还介绍了一种基于进化算法的学习方式,这里不提了。
总结:挺有意思的文章。
疑问:之前想看看这个文章能不能用到experience replay上面,来sample更加diverse的样本,看起来好像不是很适用。
- Population-Based Reinforcement Population Effective Diversitypopulation-based reinforcement population effective population-based diversity population information evaluation diversity retrieval generative functional landscapes diversity diversity preference-aware recommendations evaluating population sequencing文献sentieon effective reinforcement