1.算法仿真效果
matlab2022a仿真结果如下:



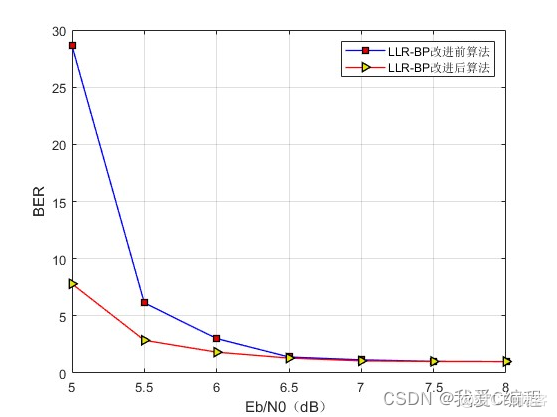
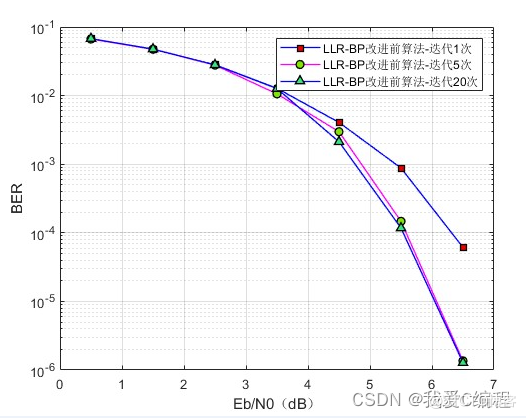
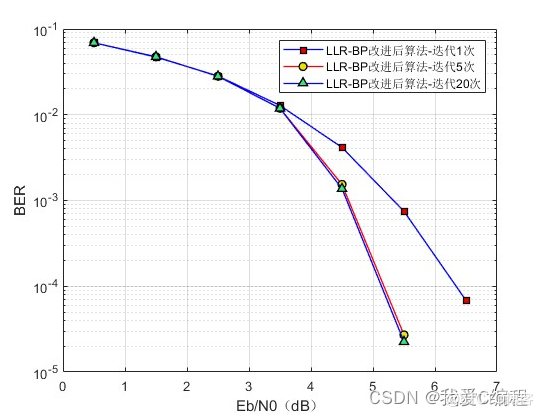
2.算法涉及理论知识概要
LDPC码是麻省理工学院Robert Gallager于1963年在博士论文中提出的一种具有稀疏校验矩阵的分组纠错码。几乎适用于所有的信道,因此成为编码界近年来的研究热点。它的性能逼近香农极限,且描述和实现简单,易于进行理论分析和研究,译码简单且可实行并行操作,适合硬件实现。
LDPC ( Low-density Parity-check,低密度奇偶校验)码是由 Gallager 在1963 年提出的一类具有稀疏校验矩阵的线性分组码 (linear block codes),然而在接下来的 30 年来由于计算能力的不足,它一直被人们忽视。1996年,D MacKay、M Neal 等人对它重新进行了研究,发现 LDPC 码具有逼近香农极限的优异性能。并且具有译码复杂度低、可并行译码以及译码错误的可检测性等特点,从而成为了信道编码理论新的研究热点。Mckay ,Luby 提出的非正则 LDPC 码将 LDPC 码的概念推广。非正则LDPC码 的性能不仅优于正则 LDPC 码,甚至还优于 Turbo 码的性能,是目前己知的最接近香农限的码。Richardson 和 Urbank 也为 LDPC 码的发展做出了巨大的贡献。首先,他们提出了一种新的编码算法,在很大程度上减轻了随机构造的 LDPC 码在编码上的巨大运算量需求和存储量需求。其次,他们发明了密度演进理论,能够有效的分析出一大类 LDPC 译码算法的译码门限。仿真结果表明,这是一个紧致的译码门限。最后,密度演进理论还可以用于指导非正则 LDPC码 的设计,以获得尽可能优秀的性能。
在 LDPC 码的 Tanner 图中,从一个顶点出发,经过不同顶点后回到同一个顶点的一些“边”组成的回路称为“环”。经过的边的个数称为环的长度。所有环中周长最小的环称为 LDPC码的围长(girth) 。Tanner 图中的环不可避免的会对译码结果造成非常大的干扰。由于迭代概率译码会使信息在节点间交互传递,若存在环,从环的某一个节点出发的信息会沿着环上的节点不断传递并最终重新回到这个节点本身,从而使得节点自身信息不断累加,进而使得译码的最终结果失败的概率变大。显然,环长越小,信息传递回本身所需走的路径就越短,译码失败的概率就变得越高。Tanner 图形成一个环至少需要 4 个节点组成4 条相连的边,即环长最小为4,这类短环对码字的译码结果干扰最大。定义 LDPC码的行列(RC)约束为:两行或两列中不存在元素 1 的位置有 1 个以上相同的情况。显然,满足 RC 约束的 LDPC 码最低就是 6 环,去除了4 环的干扰。由于4环的检测以及避免最为简单并且必要,因此绝大部分构造方法都会满足 RC 约束。而构造大圈长的码字则需要精确的设计。
LDPC仿真系统图LDPC 码的奇偶校验矩阵H是一个稀疏矩阵,相对于行与列的长度,校验矩阵每行、列中非零元素的数目(我们习惯称作行重、列重)非常小,这也是LDPC码之所以称为低密度码的原因。由于校验矩阵H的稀疏性以及构造时所使用的不同规则,使得不同LDPC码的编码二分图(Taner图)具有不同的闭合环路分布。而二分图中闭合环路是影响LDPC码性能的重要因素,它使得LDPC码在类似可信度传播(Belief ProPagation)算法的一类迭代译码算法下,表现出完全不同的译码性能。
当H的行重和列重保持不变或尽可能的保持均匀时,我们称这样的LDPC码为正则LDPC码,反之如果列、行重变化差异较大时,称为非正则的LDPC码。研究结果表明正确设计的非正则LDPC码的性能要优于正则LDPC。根据校验矩阵H中的元素是属于GF(2)还是GF(q)(q=2p),我们还可以将LDPC码分为二元域或多元域的LDPC码。研究表明多元域LDPC码的性能要比二元域的好。
在LDPC编码中,会用到一个叫做H矩阵的校验矩阵(Parity Check Matrix),比如,我们来看一个简单的H矩阵:

LLRBP算法较为复杂,因此,我们考虑改进算法的复杂度,加快算法仿真速度。具体方法如下所示:
这里,在改进算法复杂度方面,主要从tanh方面入手,因为tanh计算在硬件实现方面非常复杂,所以这里通过泰勒展开式,并近似的选择泰勒展开式的前几项作为近似计算公式进行计算,从而降低复杂度。。

这个地方改进的含义是计算信道传递给变量节点的初始概率似然比信息。
传统的LLRBP算法,其计算是通过这个似然比得到的,
而改进后的算法,通过似然比和变量节点信息的差作为校验节点信息的输入。
另外一方面,在校验节点计算过程中,根据变量节点传递给校验节点的信息的值,选择不同的校验节点信息的计算公式:具体如下所示:
首先取
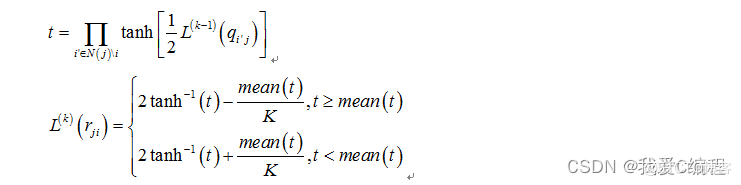
通过这么处理,可以有效减小变量节点之间信息的相关性,提高译码性能。
3.MATLAB核心程序
Times = [5000,3000,1000,400,200,50,30];
EbN0_dB = [0.5:1:5.5];
max_iter = 15;
load GH.mat
[N,M] = size(H);
R = 1-N/M;
disp('Start......');
for i=1:length(EbN0_dB)
Bit_err(i) = 0;
Num_err = 0;
Numbers = 0; %误码率累加器
EbN0 = 10^(EbN0_dB(i)/10); % 比特信噪比,十进制表示
sigma = 1/sqrt(2*EbN0); % 求出方差值
while Num_err <= Times(i);
Num_err
fprintf('Eb/N0 = %f\n', EbN0_dB(i));
Trans_data = round(rand(1,M-N)); %产生需要发送的随机数
ldpc_code = mod(Trans_data*G,2); %LDPC编码
Trans_BPSK = 2*ldpc_code-1; %BPSK
%通过高斯信道
Rec_BPSK = Trans_BPSK + sigma*randn(size(Trans_BPSK));
z_hat = func_LLRBP(Rec_BPSK,sigma,H,max_iter) ;
x_hat = z_hat(size(G,2)+1-size(G,1):size(G,2));
[nberr,rat] = biterr(x_hat,Trans_data);
Num_err = Num_err+nberr;
Numbers = Numbers+1;
end
Bit_err(i)=Num_err/(length(Trans_data)*Numbers);
end
figure;
semilogy(EbN0_dB,Bit_err,'b-o');
xlabel('Eb/N0(dB)');
ylabel('BER');
grid on;
% save R1.mat EbN0 Bit_err