一、选题背景
随着社会经济的发展和人们生活水平的提高,汽车已经成为现代化生活中不可或缺的交通工具之一。同时,环保意识的提高也给汽车产业带来了新的挑战,例如减少汽车的油耗和减少尾气排放。
在这样的背景下,通过分析不同车辆类型的城市道路油耗、高速公路油耗和二氧化碳排放量数据,可以帮助我们更好地了解不同车辆类型的能源利用情况和环境影响。这一研究方向对于环境保护和可持续发展具有重要意义。
二、大数据分析设计方案
1.本数据集的数据内容

三、数据分析步骤
1.数据源
本次课程设计的数据集来自爱数科平台
网址:http://www.idatascience.cn/dataset-detail?table_id=102045
2.数据清洗
对数据进行数据清洗,数据清洗在数据分析和建模过程中起着重要的作用。用来提高数据的质量和准确性,确保数据的可靠性和可用性:
import pandas as pd
# 读取数据
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 处理缺失值
data = data.dropna() # 删除包含缺失值的行
# 处理重复值
data = data.drop_duplicates() # 删除重复的行
#数据转换
data['Engine Size(L)'] = pd.to_numeric(data['Engine Size(L)'])
data['Cylinders'] = pd.to_numeric(data['Cylinders'])
# 查看数据前10行
print(data.head(10))
显示结果:

3.大数据分析过程及采用的算法
数据源采集: 在爱数科平台上获取城市道路油耗、高速公路油耗和二氧化碳排放量数据集。
数据清洗和预处理: 对数据集进行清洗和预处理,包括了去除重复数据、处理缺失值和异常值。
数据探索和可视化: 使用Python的数据分析库:pandas库、seaborn库、matplotlib库和numpy库对数据进行探索性分析和可视化。绘制了柱状图、箱线图、散点图来展示不同车辆类型在城市道路和高速公路上的油耗以及二氧化碳排放量的分布情况。
四.数据分析
1.各种车辆类别的城市道路油耗(升/100公里)的柱状图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据集
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 提取 'Vehicle Class' 和 'Fuel Consumption City (L/100 km)' 两列数据
df = data[['Vehicle Class', 'Fuel Consumption City (L/100 km)']]
# 按 'Vehicle Class' 分组,并计算平均值
grouped = df.groupby('Vehicle Class').mean()
# 绘制柱状图
ax = grouped.plot(kind='bar')
# 在每个柱形上添加数值标注
for p in ax.patches:
ax.annotate(f"{p.get_height():.2f}",
(p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center',
xytext=(0, 5),
textcoords='offset points')
# 设置图表标题和轴标签
plt.title('Average Fuel Consumption City by Vehicle Class')
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption City (L/100 km)')
# 显示图表
plt.show()
绘制结果:

该图形有助于比较不同车辆类型之间的平均城市燃油消耗量,通过这个图表,,从而了解它们的城市燃油消耗量水平。
2.各种车辆类别的高速公路油耗(升/100公里)的柱状图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据集
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 提取 'Vehicle Class' 和 'Fuel Consumption Hwy (L/100 km)' 两列数据
df = data[['Vehicle Class',
'Fuel Consumption Hwy (L/100 km)']]
# 按车辆类别分组计算高速公路油耗的平均值
mean_hwy_fuel_consumption = data.groupby('Vehicle Class')['Fuel Consumption Hwy (L/100 km)'].mean()
# 创建柱状图
ax = mean_hwy_fuel_consumption.plot(kind='bar')
# 为每个柱状条添加数值标注
for p in ax.patches:
ax.annotate(f"{p.get_height():.2f}", (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', xytext=(0, 5), textcoords='offset points')
# 设置图表标签和标题
plt.xlabel('Vehicle Class')
plt.ylabel('Mean Hwy Fuel Consumption (L/100 km)')
plt.title('Mean Hwy Fuel Consumption by Vehicle Class')
# 显示图表
plt.show()
绘制结果:

这个柱状图可以帮助我们比较不同车辆类别之间的高速公路油耗平均值,从而了解它们的高速公路油耗水平。
3.各种车辆类别的综合油耗(55% 城市,45% 高速公路)的柱状图
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 提取 'Vehicle Class' 和 'Fuel Consumption Comb (L/100 km)' 两列数据
df = data[['Vehicle Class',
'Fuel Consumption Comb (L/100 km)']]
# 统计每个车辆类别的燃油消耗的均值
mean_fuel_consumption = data.groupby('Vehicle Class')['Fuel Consumption Comb (L/100 km)'].mean()
# 创建柱状图
ax = mean_fuel_consumption.plot(kind='bar')
# 添加每个柱子的数值标注
for p in ax.patches:
ax.annotate(f"{p.get_height():.2f}",
(p.get_x() + p.get_width() / 2.,
p.get_height()),
ha='center',
va='center',
xytext=(0, 5),
textcoords='offset points')
# 设置图表标签和标题
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption Comb (L/100 km)')
plt.title('Mean Fuel Consumption by Vehicle Class')
plt.show()
绘制结果:

通过这个图表,可以比较不同车辆类别之间的平均综合燃油消耗量,以便了解哪些车辆类别更为节能或者消耗更多燃油。
4.各种车辆类别的燃油消耗梳(每加仑)的柱状图
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 提取 'Vehicle Class' 和 'Fuel Consumption Comb (mpg)' 两列数据
df = data[['Vehicle Class',
'Fuel Consumption Comb (mpg)']]
# 统计每个车辆类别的燃油消耗的均值
mean_fuel_consumption = data.groupby('Vehicle Class')['Fuel Consumption Comb (mpg)'].mean()
# 绘制柱状图
ax = mean_fuel_consumption.plot(kind='bar')
# 添加每个柱子的数值标注
for p in ax.patches:
ax.annotate(f"{p.get_height():.2f}",
(p.get_x() + p.get_width() / 2,
p.get_height()),
ha='center',
va='bottom')
# 设置图表标签和标题
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption Comb (mpg)')
plt.title('Mean Fuel Consumption by Vehicle Class')
plt.show()
绘制结果:

通过这个图表,可以比较不同车辆类别之间的平均综合燃油消耗量(与上面不同的是这里的燃油消耗量单位是"mpg"(每加仑英里)),以便了解哪些车辆类别更为节能或者消耗更多燃油。
5.各种车辆类别的二氧化碳排放(克/公里)的箱线图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据集文件
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 选择'Vehicle Class'和'CO2 Emissions(g/km)'两列数据
selected_data = data[['Vehicle Class', 'CO2 Emissions(g/km)']]
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 8), dpi=80)
# 绘制箱线图
selected_data.boxplot(by='Vehicle Class', column='CO2 Emissions(g/km)', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class')
plt.xlabel('Vehicle Class')
plt.ylabel('CO2 Emissions (g/km)')
# 自动调整布局
plt.tight_layout()
# 调整坐标刻度标签的角度和大小
plt.xticks(rotation=45, fontsize=8)
# 显示图表
plt.show()
绘制结果:

通过这个图表,可以比较不同车辆类别之间的二氧化碳排放量的分布情况,以便了解哪些车辆类别的排放量较高或较低。
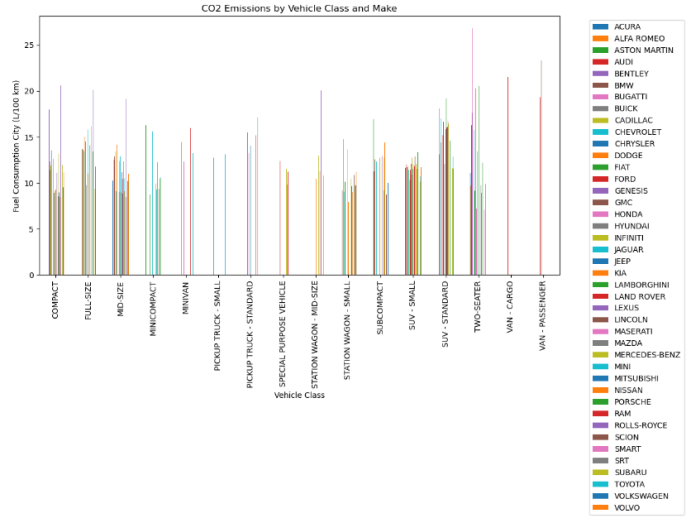
6.各个公司同一车辆类别的二氧化碳排放(克/公里)对比柱状图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据集文件
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 选择'Vehicle Class'、'Make'和'CO2 Emissions(g/km)'三列数据
selected_data = data[['Vehicle Class', 'Make', 'CO2 Emissions(g/km)']]
# 对'Vehicle Class'和'Make'进行分组,并计算每个类别的二氧化碳排放平均值
grouped_data = selected_data.groupby(['Vehicle Class', 'Make'])['CO2 Emissions(g/km)'].mean()
# 将分组后的数据重塑成透视表
pivot_table = grouped_data.unstack('Make')
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制柱状图
pivot_table.plot(kind='bar', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class and Make')
plt.xlabel('Vehicle Class')
plt.ylabel('CO2 Emissions(g/km)')
# 调整图表布局,避免图例重叠在图表上
plt.legend(bbox_to_anchor=(1.05, 1))
# 显示图表
plt.show()
绘制结果:

通过这个图表,可以比较不同车辆类别和不同制造商之间的二氧化碳排放量,以便了解哪些车辆类别和制造商的车辆在环境排放方面表现较好或较差。
7.各个公司同一车辆类别的城市道路油耗(升/100公里)对比柱状图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据集文件
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 选择'Vehicle Class'、'Make'和'Fuel Consumption City (L/100 km)'三列数据
selected_data = data[['Vehicle Class',
'Make',
'Fuel Consumption City (L/100 km)']]
# 对'Vehicle Class'和'Make'进行分组,并计算每个类别的城市道路油耗(升/100公里)平均值
grouped_data = selected_data.groupby(['Vehicle Class', 'Make'])['Fuel Consumption City (L/100 km)'].mean()
# 将分组后的数据重塑成透视表
pivot_table = grouped_data.unstack('Make')
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制柱状图
pivot_table.plot(kind='bar', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class and Make')
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption City (L/100 km)')
# 调整图表布局,避免图例重叠在图表上
plt.legend(bbox_to_anchor=(1.05, 1))
# 显示图表
plt.show()
绘制结果:
通过这个图表,可以了解哪些车辆类别和制造商的车辆在城市道路上的油耗更高或更低。
8.各个公司同一车辆类别的高速公路油耗(升/100公里)对比柱状图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据集文件
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 选择'Vehicle Class'、'Make'和'Fuel Consumption Hwy (L/100 km)'三列数据
selected_data = data[['Vehicle Class',
'Make',
'Fuel Consumption Hwy (L/100 km)']]
# 对'Vehicle Class'和'Make'进行分组,并计算每个类别的高速公路油耗(升/100公里)平均值
grouped_data = selected_data.groupby(['Vehicle Class', 'Make'])['Fuel Consumption Hwy (L/100 km)'].mean()
# 将分组后的数据重塑成透视表
pivot_table = grouped_data.unstack('Make')
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制柱状图
pivot_table.plot(kind='bar', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class and Make')
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption Hwy (L/100 km)')
# 调整图表布局,避免图例重叠在图表上
plt.legend(bbox_to_anchor=(1.05, 1))
# 显示图表
plt.show()
绘制结果:

通过这个图表,可以比较不同车辆类别和制造商之间的高速公路油耗平均值,以便了解哪些车辆类别和制造商的车辆在高速公路上的燃油消耗情况。
9.各个公司同一车辆类别的综合油耗(55% 城市,45% 高速公路)对比柱状图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据集文件
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 选择'Vehicle Class'、'Make'和'Fuel Consumption Comb (L/100 km)'三列数据
selected_data = data[['Vehicle Class',
'Make',
'Fuel Consumption Comb (L/100 km)']]
# 对'Vehicle Class'和'Make'进行分组,并计算每个类别的综合油耗(55% 城市,45% 高速公路)平均值
grouped_data = selected_data.groupby(['Vehicle Class', 'Make'])['Fuel Consumption Comb (L/100 km)'].mean()
# 将分组后的数据重塑成透视表
pivot_table = grouped_data.unstack('Make')
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制柱状图
pivot_table.plot(kind='bar', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class and Make')
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption Comb (L/100 km)')
# 调整图表布局,避免图例重叠在图表上
plt.legend(bbox_to_anchor=(1.05, 1))
# 显示图表
plt.show()
绘制结果:

通过这个图表,可以比较不同车辆类别和车辆制造商之间的综合油耗差异,以便了解哪些车辆类别和制造商的车辆在燃油消耗方面表现更好或更差。
10.各个公司同一车辆类别的燃油消耗梳(每加仑)对比柱状图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据集文件
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 选择'Vehicle Class'、'Make'和'Fuel Consumption Comb (mpg)'三列数据
selected_data = data[['Vehicle Class',
'Make',
'Fuel Consumption Comb (mpg)']]
# 对'Vehicle Class'和'Make'进行分组,并计算每个类别的燃油消耗梳(每加仑)平均值
grouped_data = selected_data.groupby(['Vehicle Class', 'Make'])['Fuel Consumption Comb (mpg)'].mean()
# 将分组后的数据重塑成透视表
pivot_table = grouped_data.unstack('Make')
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制柱状图
pivot_table.plot(kind='bar', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class and Make')
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption Comb (mpg)')
# 调整图表布局,避免图例重叠在图表上
plt.legend(bbox_to_anchor=(1.05, 1))
# 显示图表
plt.show()
绘制结果:

通过这个图表,可以比较不同车辆类别和制造商之间的平均燃油消耗量(这里的燃油消耗量单位是"mpg"(每加仑英里)),以便了解哪些车辆类别和制造商的车辆在燃油消耗方面表现更为节能。
11.绘制城市道路油耗(升/100公里)与所用发动机尺寸、气缸数、带齿轮数的变速器、使用的燃料类型的关系的散点矩阵图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 读取数据集
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 提取需要的字段
fields = ['Fuel Consumption City (L/100 km)',
'Engine Size(L)',
'Cylinders',
'Transmission',
'Fuel Type']
# 绘制散点图矩阵
scatter_matrix = sns.pairplot(data[fields], diag_kind='kde')
# 在每个散点图上添加回归线和相关系数的标注
for i, j in zip(*np.triu_indices_from(scatter_matrix.axes, 1)):
scatter_matrix.axes[i, j].annotate(
f"correlation = {data[fields[i]].corr(data[fields[j]]):.2f}",
(0.6, 0.9),
xycoords='axes fraction',
ha='center')
sns.regplot(x=data[fields[i]], y=data[fields[j]], ax=scatter_matrix.axes[i, j])
plt.show()
绘制结果:

通过这个图表,可以了解城市燃油消耗量和发动机尺寸、气缸数、带齿轮数的变速器、使用的燃料类型之间的关系。
12.绘制综合油耗(55% 城市,45% 高速公路)与所用发动机尺寸、气缸数、带齿轮数的变速器、使用的燃料类型的关系的散点矩阵图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 读取数据集
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 选择需要使用的变量
variables = ['Fuel Consumption Comb (L/100 km)',
'Engine Size(L)',
'Cylinders',
'Transmission',
'Fuel Type']
# 根据选择的变量创建子集
subset = data[variables].dropna()
# 绘制散点图矩阵
sns.set(style="ticks")
scatter_matrix = sns.pairplot(subset, diag_kind='kde')
# 添加回归线和相关系数标注
for i, j in zip(*np.triu_indices_from(scatter_matrix.axes, 1)):
scatter_matrix.axes[i, j].annotate(
f"correlation = {subset.iloc[:, i].corr(subset.iloc[:, j]):.2f}",
(0.6, 0.9),
xycoords='axes fraction',
ha='center')
sns.regplot(x=subset.columns[i], y=subset.columns[j], data=subset, ax=scatter_matrix.axes[i, j])
plt.show()
绘制结果:

通过这个图表,可以了解综合油耗和发动机尺寸、气缸数、带齿轮数的变速器、使用的燃料类型之间的关系。
13.绘制高速公路油耗(升/100公里)与所用发动机尺寸、气缸数、带齿轮数的变速器、使用的燃料类型的关系的散点矩阵图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 读取数据集
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 选择需要使用的变量
fields = ['Fuel Consumption Hwy (L/100 km)',
'Engine Size(L)',
'Cylinders',
'Transmission',
'Fuel Type']
# 绘制散点图矩阵
scatter_matrix = sns.pairplot(data[fields], diag_kind='kde')
# 在每个散点图上添加回归线和相关系数的标注
for i, j in zip(*np.triu_indices_from(scatter_matrix.axes, 1)):
scatter_matrix.axes[i, j].annotate(
f"correlation = {data[fields[i]].corr(data[fields[j]]):.2f}",
(0.6, 0.9),
xycoords='axes fraction',
ha='center')
sns.regplot(x=data[fields[i]], y=data[fields[j]], ax=scatter_matrix.axes[i, j])
plt.show()
绘制结果:

通过这个图表,可以了解高速公路燃油消耗量和发动机尺寸、气缸数、带齿轮数的变速器、使用的燃料类型之间的关系。
14.绘制二氧化碳排放(克/公里)与所用发动机尺寸、气缸数、带齿轮数的变速器、使用的燃料类型的关系的散点矩阵图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 读取数据集
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 选择需要使用的变量
variables = ['CO2 Emissions(g/km)',
'Engine Size(L)',
'Cylinders',
'Transmission',
'Fuel Type']
# 根据选择的变量创建子集
subset = data[variables]
# 绘制散点图矩阵
scatter_matrix = sns.pairplot(subset, diag_kind='kde')
# 在每个散点图上添加回归线和相关系数的标注
for i, j in zip(*np.triu_indices_from(scatter_matrix.axes, 1)):
scatter_matrix.axes[i, j].annotate(
f"correlation = {subset[variables[i]].corr(subset[variables[j]]):.2f}",
(0.6, 0.9),
xycoords='axes fraction',
ha='center')
sns.regplot(x=subset[variables[i]], y=subset[variables[j]], ax=scatter_matrix.axes[i, j])
plt.show()
绘制结果:

通过这个图表,可以了解二氧化碳排放量和发动机尺寸、气缸数、带齿轮数的变速器、使用的燃料类型之间的关系。
完整代码:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 读取数据
data = pd.read_csv('车辆二氧化碳排放量数据集.csv')
# 处理缺失值
data = data.dropna() # 删除包含缺失值的行
# 处理重复值
data = data.drop_duplicates() # 删除重复的行
#数据转换
data['Engine Size(L)'] = pd.to_numeric(data['Engine Size(L)'])
data['Cylinders'] = pd.to_numeric(data['Cylinders'])
# 查看数据前10行
print(data.head(10))
# 提取 'Vehicle Class' 和 'Fuel Consumption City (L/100 km)' 两列数据
df = data[['Vehicle Class',
'Fuel Consumption City (L/100 km)']]
# 按 'Vehicle Class' 分组,并计算平均值
grouped = df.groupby('Vehicle Class').mean()
# 绘制柱状图
ax = grouped.plot(kind='bar')
# 在每个柱形上添加数值标注
for p in ax.patches:
ax.annotate(f"{p.get_height():.2f}",
(p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center',
xytext=(0, 5),
textcoords='offset points')
# 设置图表标题和轴标签
plt.title('Average Fuel Consumption City by Vehicle Class')
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption City (L/100 km)')
# 显示图表
plt.show()
# 提取 'Vehicle Class' 和 'Fuel Consumption Hwy (L/100 km)' 两列数据
df = data[['Vehicle Class',
'Fuel Consumption Hwy (L/100 km)']]
# 按车辆类别分组计算高速公路油耗的平均值
mean_hwy_fuel_consumption = data.groupby('Vehicle Class')['Fuel Consumption Hwy (L/100 km)'].mean()
# 创建柱状图
ax = mean_hwy_fuel_consumption.plot(kind='bar')
# 为每个柱状条添加数值标注
for p in ax.patches:
ax.annotate(f"{p.get_height():.2f}",
(p.get_x() + p.get_width() / 2.,
p.get_height()),
ha='center',
va='center',
xytext=(0, 5),
textcoords='offset points')
# 设置图表标签和标题
plt.xlabel('Vehicle Class')
plt.ylabel('Mean Hwy Fuel Consumption (L/100 km)')
plt.title('Mean Hwy Fuel Consumption by Vehicle Class')
# 显示图表
plt.show()
# 提取 'Vehicle Class' 和 'Fuel Consumption Comb (L/100 km)' 两列数据
df = data[['Vehicle Class',
'Fuel Consumption Comb (L/100 km)']]
# 统计每个车辆类别的燃油消耗的均值
mean_fuel_consumption = data.groupby('Vehicle Class')['Fuel Consumption Comb (L/100 km)'].mean()
# 创建柱状图
ax = mean_fuel_consumption.plot(kind='bar')
# 添加每个柱子的数值标注
for p in ax.patches:
ax.annotate(f"{p.get_height():.2f}",
(p.get_x() + p.get_width() / 2.,
p.get_height()),
ha='center',
va='center',
xytext=(0, 5),
textcoords='offset points')
# 设置图表标签和标题
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption Comb (L/100 km)')
plt.title('Mean Fuel Consumption by Vehicle Class')
plt.show()
# 提取 'Vehicle Class' 和 'Fuel Consumption Comb (mpg)' 两列数据
df = data[['Vehicle Class',
'Fuel Consumption Comb (mpg)']]
# 统计每个车辆类别的燃油消耗的均值
mean_fuel_consumption = data.groupby('Vehicle Class')['Fuel Consumption Comb (mpg)'].mean()
# 绘制柱状图
ax = mean_fuel_consumption.plot(kind='bar')
# 添加每个柱子的数值标注
for p in ax.patches:
ax.annotate(f"{p.get_height():.2f}",
(p.get_x() + p.get_width() / 2,
p.get_height()),
ha='center',
va='bottom')
# 设置图表标签和标题
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption Comb (mpg)')
plt.title('Mean Fuel Consumption by Vehicle Class')
plt.show()
# 选择'Vehicle Class'和'CO2 Emissions(g/km)'两列数据
selected_data = data[['Vehicle Class',
'CO2 Emissions(g/km)']]
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 8), dpi=80)
# 绘制箱线图
selected_data.boxplot(by='Vehicle Class', column='CO2 Emissions(g/km)', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class')
plt.xlabel('Vehicle Class')
plt.ylabel('CO2 Emissions (g/km)')
# 自动调整布局
plt.tight_layout()
# 调整坐标刻度标签的角度和大小
plt.xticks(rotation=45, fontsize=8)
# 显示图表
plt.show()
# 选择'Vehicle Class'、'Make'和'CO2 Emissions(g/km)'三列数据
selected_data = data[['Vehicle Class',
'Make',
'CO2 Emissions(g/km)']]
# 对'Vehicle Class'和'Make'进行分组,并计算每个类别的二氧化碳排放平均值
grouped_data = selected_data.groupby(['Vehicle Class', 'Make'])['CO2 Emissions(g/km)'].mean()
# 将分组后的数据重塑成透视表
pivot_table = grouped_data.unstack('Make')
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制柱状图
pivot_table.plot(kind='bar', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class and Make')
plt.xlabel('Vehicle Class')
plt.ylabel('CO2 Emissions(g/km)')
# 调整图表布局,避免图例重叠在图表上
plt.legend(bbox_to_anchor=(1.05, 1))
# 显示图表
plt.show()
# 选择'Vehicle Class'、'Make'和'Fuel Consumption City (L/100 km)'三列数据
selected_data = data[['Vehicle Class',
'Make',
'Fuel Consumption City (L/100 km)']]
# 对'Vehicle Class'和'Make'进行分组,并计算每个类别的城市道路油耗(升/100公里)平均值
grouped_data = selected_data.groupby(['Vehicle Class', 'Make'])['Fuel Consumption City (L/100 km)'].mean()
# 将分组后的数据重塑成透视表
pivot_table = grouped_data.unstack('Make')
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制柱状图
pivot_table.plot(kind='bar', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class and Make')
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption City (L/100 km)')
# 调整图表布局,避免图例重叠在图表上
plt.legend(bbox_to_anchor=(1.05, 1))
# 显示图表
plt.show()
# 选择'Vehicle Class'、'Make'和'Fuel Consumption Hwy (L/100 km)'三列数据
selected_data = data[['Vehicle Class',
'Make',
'Fuel Consumption Hwy (L/100 km)']]
# 对'Vehicle Class'和'Make'进行分组,并计算每个类别的高速公路油耗(升/100公里)平均值
grouped_data = selected_data.groupby(['Vehicle Class', 'Make'])['Fuel Consumption Hwy (L/100 km)'].mean()
# 将分组后的数据重塑成透视表
pivot_table = grouped_data.unstack('Make')
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制柱状图
pivot_table.plot(kind='bar', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class and Make')
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption Hwy (L/100 km)')
# 调整图表布局,避免图例重叠在图表上
plt.legend(bbox_to_anchor=(1.05, 1))
# 显示图表
plt.show()
# 选择'Vehicle Class'、'Make'和'Fuel Consumption Comb (L/100 km)'三列数据
selected_data = data[['Vehicle Class',
'Make',
'Fuel Consumption Comb (L/100 km)']]
# 对'Vehicle Class'和'Make'进行分组,并计算每个类别的综合油耗(55% 城市,45% 高速公路)平均值
grouped_data = selected_data.groupby(['Vehicle Class', 'Make'])['Fuel Consumption Comb (L/100 km)'].mean()
# 将分组后的数据重塑成透视表
pivot_table = grouped_data.unstack('Make')
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制柱状图
pivot_table.plot(kind='bar', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class and Make')
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption Comb (L/100 km)')
# 调整图表布局,避免图例重叠在图表上
plt.legend(bbox_to_anchor=(1.05, 1))
# 显示图表
plt.show()
# 选择'Vehicle Class'、'Make'和'Fuel Consumption Comb (mpg)'三列数据
selected_data = data[['Vehicle Class',
'Make',
'Fuel Consumption Comb (mpg)']]
# 对'Vehicle Class'和'Make'进行分组,并计算每个类别的燃油消耗梳(每加仑)平均值
grouped_data = selected_data.groupby(['Vehicle Class', 'Make'])['Fuel Consumption Comb (mpg)'].mean()
# 将分组后的数据重塑成透视表
pivot_table = grouped_data.unstack('Make')
# 设置图表布局
fig, ax = plt.subplots(figsize=(12, 6))
# 绘制柱状图
pivot_table.plot(kind='bar', ax=ax)
# 添加标题和标签
plt.title('CO2 Emissions by Vehicle Class and Make')
plt.xlabel('Vehicle Class')
plt.ylabel('Fuel Consumption Comb (mpg)')
# 调整图表布局,避免图例重叠在图表上
plt.legend(bbox_to_anchor=(1.05, 1))
# 显示图表
plt.show()
# 提取需要的字段
fields = ['Fuel Consumption City (L/100 km)',
'Engine Size(L)',
'Cylinders',
'Transmission',
'Fuel Type']
# 绘制散点图矩阵
scatter_matrix = sns.pairplot(data[fields], diag_kind='kde')
# 在每个散点图上添加回归线和相关系数的标注
for i, j in zip(*np.triu_indices_from(scatter_matrix.axes, 1)):
scatter_matrix.axes[i, j].annotate(
f"correlation = {data[fields[i]].corr(data[fields[j]]):.2f}",
(0.6, 0.9),
xycoords='axes fraction',
ha='center')
sns.regplot(x=data[fields[i]], y=data[fields[j]], ax=scatter_matrix.axes[i, j])
plt.show()
# 选择需要使用的变量
variables = ['Fuel Consumption Comb (L/100 km)',
'Engine Size(L)',
'Cylinders',
'Transmission',
'Fuel Type']
# 根据选择的变量创建子集
subset = data[variables].dropna()
# 绘制散点图矩阵
sns.set(style="ticks")
scatter_matrix = sns.pairplot(subset, diag_kind='kde')
# 添加回归线和相关系数标注
for i, j in zip(*np.triu_indices_from(scatter_matrix.axes, 1)):
scatter_matrix.axes[i, j].annotate(
f"correlation = {subset.iloc[:, i].corr(subset.iloc[:, j]):.2f}",
(0.6, 0.9),
xycoords='axes fraction',
ha='center')
sns.regplot(x=subset.columns[i], y=subset.columns[j], data=subset, ax=scatter_matrix.axes[i, j])
plt.show()
# 选择需要使用的变量
fields = ['Fuel Consumption Hwy (L/100 km)',
'Engine Size(L)',
'Cylinders',
'Transmission',
'Fuel Type']
# 绘制散点图矩阵
scatter_matrix = sns.pairplot(data[fields], diag_kind='kde')
# 在每个散点图上添加回归线和相关系数的标注
for i, j in zip(*np.triu_indices_from(scatter_matrix.axes, 1)):
scatter_matrix.axes[i, j].annotate(
f"correlation = {data[fields[i]].corr(data[fields[j]]):.2f}",
(0.6, 0.9),
xycoords='axes fraction',
ha='center')
sns.regplot(x=data[fields[i]], y=data[fields[j]], ax=scatter_matrix.axes[i, j])
plt.show()
# 选择需要使用的变量
variables = ['CO2 Emissions(g/km)',
'Engine Size(L)',
'Cylinders',
'Transmission',
'Fuel Type']
# 根据选择的变量创建子集
subset = data[variables]
# 绘制散点图矩阵
scatter_matrix = sns.pairplot(subset, diag_kind='kde')
# 在每个散点图上添加回归线和相关系数的标注
for i, j in zip(*np.triu_indices_from(scatter_matrix.axes, 1)):
scatter_matrix.axes[i, j].annotate(
f"correlation = {subset[variables[i]].corr(subset[variables[j]]):.2f}",
(0.6, 0.9),
xycoords='axes fraction',
ha='center')
sns.regplot(x=subset[variables[i]], y=subset[variables[j]], ax=scatter_matrix.axes[i, j])
plt.show()
五.总结
1.通过对数据分析和挖掘,我们得到了不同车辆类型在城市道路和高速公路上的油耗以及二氧化碳排放量数据。这些数据提供有益了的结论和见解,包括以下方面:
根据不同车辆类型的油耗数据,可以比较不同类型车辆在城市道路和高速公路上的燃油效率,找到相对节能的车辆类型。
通过比较不同车辆类型的二氧化碳排放量,可以了解哪些车辆类型对环境的影响程度较高,从而指导环保政策的制定。
我的目标是分析不同车辆类型的油耗和二氧化碳排放量数据,通过这个课程设计,我达到了预期的目标。
2.在完成这个设计过程中,我获得了以下收获:
通过这个设计,我有机会实践数据清洗和分析技术,提升了数据分析的能力。
通过分析不同车辆类型的油耗和二氧化碳排放量数据,我对车辆的燃油效率和环境影响有了更深入的认识。
对于改进建议,我考虑以下方面:
确保采集的数据完整且准确,以提高分析的可信度。
除了城市道路和高速公路油耗和二氧化碳排放量,可以考虑分析其他方面的数据,例如不同车辆类型的排放标准、动力性能等,以获得更全面的结论。
通过改进图表的设计和使用更丰富的图表类型,可以更清晰地呈现数据分析的结果。