缓存:数据库成为瓶颈后,动态数据的查询要如何加速?
缓存可以有多层,比如上面提到的静态缓存处在负载均衡层,分布式缓存处在应用层和数据库层之间,本地缓存处在应用层。我们需要将请求尽量挡在上层,因为越往下层,对于并发的承受能力越差;
缓存命中率是我们对于缓存最重要的一个监控项,越是热点的数据,缓存的命中率就越高。
缓存的使用姿势(一):如何选择缓存的读写策略?
1.Cache Aside(旁路缓存)策略
先更新数据库,再更新缓存,会造成缓存和数据库中的数据不一致。
如何解决这个问题呢?其实,我们可以在更新数据时不更新缓存,而是删除缓存中的数据,在读取数据时,发现缓存中没了数据之后,再从数据库中读取数据,更新到缓存中。
Cache Aside 策略(也叫旁路缓存策略),这个策略数据以数据库中的数据为准,缓存中的数据是按需加载的。它可以分为读策略和写策略,其中读策略的步骤是:
- 从缓存中读取数据;
- 如果缓存命中,则直接返回数据;
- 如果缓存不命中,则从数据库中查询数据;
- 查询到数据后,将数据写入到缓存中,并且返回给用户。
写策略的步骤是:
- 更新数据库中的记录;
- 删除缓存记录。
那么像 Cache Aside 策略这样先更新数据库,后删除缓存就没有问题了吗?其实在理论上还是有缺陷的。假如某个用户数据在缓存中不存在,请求 A 读取数据时从数据库中查询到年龄为 20,在未写入缓存中时另一个请求 B 更新数据。它更新数据库中的年龄为 21,并且清空缓存。这时请求 A 把从数据库中读到的年龄为 20 的数据写入到缓存中,造成缓存和数据库数据不一致。
Cache Aside 存在的最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。如果你的业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
1. 一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
2. 另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快过期,对业务的影响也是可以接受。
2.Read/Write Through(读穿 / 写穿)策略
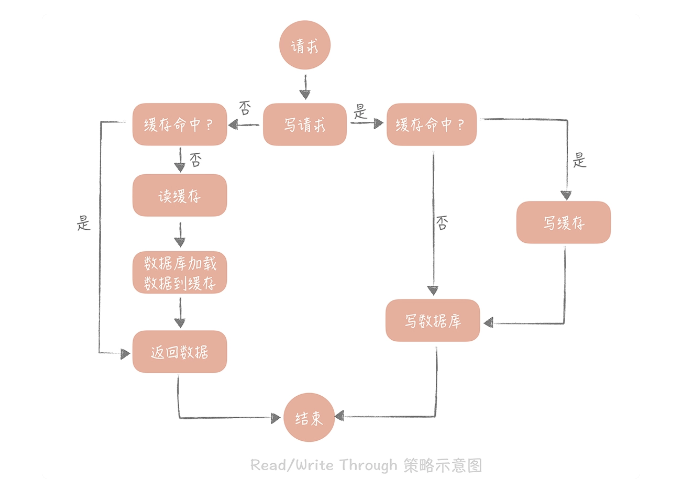
Read Through/Write Through 策略的特点是由缓存节点而非用户来和数据库打交道,在我们开发过程中相比 Cache Aside 策略要少见一些,原因是我们经常使用的分布式缓存组件,无论是 Memcached 还是 Redis 都不提供写入数据库,或者自动加载数据库中的数据的功能。而我们在使用本地缓存的时候可以考虑使用这种策略,比如说在上一节中提到的本地缓存 Guava Cache 中的 Loading Cache 就有 Read Through 策略的影子。
我们看到 Write Through 策略中写数据库是同步的,这对于性能来说会有比较大的影响,因为相比于写缓存,同步写数据库的延迟就要高很多了。那么我们可否异步地更新数据库?这就是我们接下来要提到的“Write Back”策略。
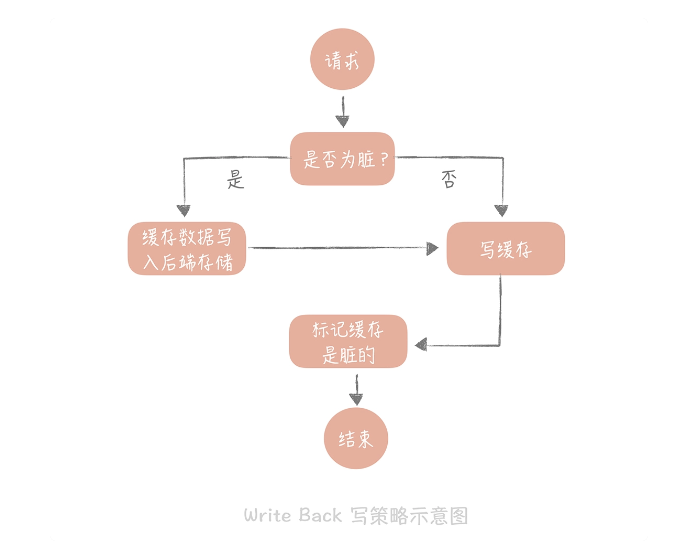
3.Write Back(写回)策略
这个策略的核心思想是在写入数据时只写入缓存,并且把缓存块儿标记为“脏”的。而脏块儿只有被再次使用时才会将其中的数据写入到后端存储中。
如果使用 Write Back 策略的话,读的策略也有一些变化了。我们在读取缓存时如果发现缓存命中则直接返回缓存数据。如果缓存不命中则寻找一个可用的缓存块儿,如果这个缓存块儿是“脏”的,就把缓存块儿中之前的数据写入到后端存储中,并且从后端存储加载数据到缓存块儿,如果不是脏的,则由缓存组件将后端存储中的数据加载到缓存中,最后我们将缓存设置为不是脏的,返回数据就好了。
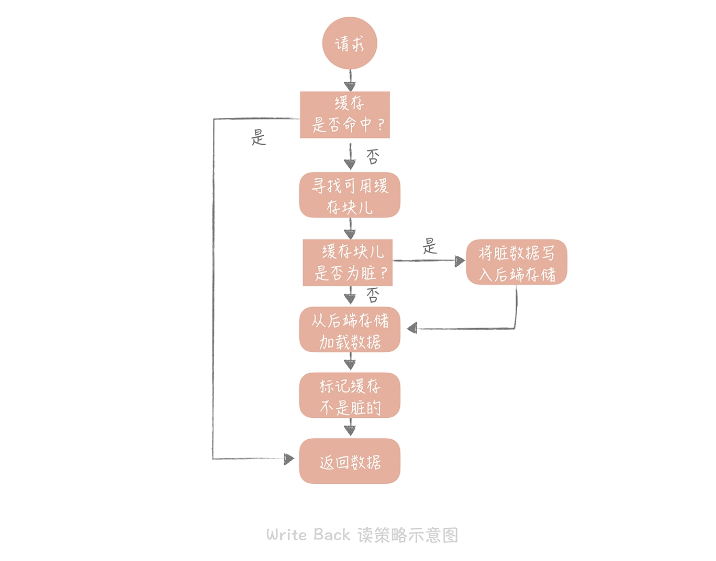
因为这个策略在性能上的优势毋庸置疑,它避免了直接写磁盘造成的随机写问题,毕竟写内存和写磁盘的随机 I/O 的延迟相差了几个数量级呢。
缓存的使用姿势(二):缓存如何做到高可用?
- 客户端方案就是在客户端配置多个缓存的节点,通过缓存写入和读取算法策略来实现分布式,从而提高缓存的可用性。
- 中间代理层方案是在应用代码和缓存节点之间增加代理层,客户端所有的写入和读取的请求都通过代理层,而代理层中会内置高可用策略,帮助提升缓存系统的高可用。
- 服务端方案就是 Redis 2.4 版本后提出的 Redis Sentinel 方案。
1.客户端方案
一致性 Hash、主从机制、多副本
一致性 Hash 算法的脏数据问题。为什么会产生脏数据呢?比方说,在集群中有两个节点 A 和 B,客户端初始写入一个 Key 为 k,值为 3 的缓存数据到 Cache A 中。这时如果要更新 k 的值为 4,但是缓存 A 恰好和客户端连接出现了问题,那这次写入请求会写入到 Cache B 中。接下来缓存 A 和客户端的连接恢复,当客户端要获取 k 的值时,就会获取到存在 Cache A 中的脏数据 3,而不是 Cache B 中的 4。
所以,在使用一致性 Hash 算法时一定要设置缓存的过期时间,这样当发生漂移时,之前存储的脏数据可能已经过期,就可以减少存在脏数据的几率。
2.中间代理层方案
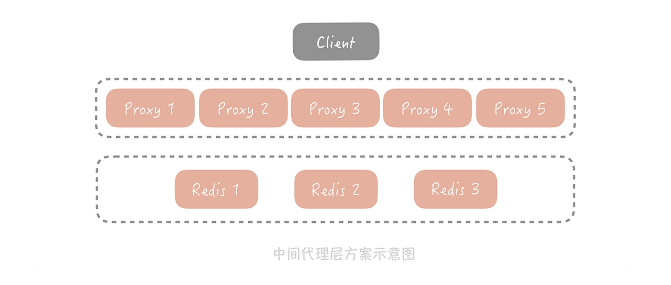
所有缓存的读写请求都是经过代理层完成的。代理层是无状态的,主要负责读写请求的路由功能,并且在其中内置了一些高可用的逻辑,不同的开源中间代理层方案中使用的高可用策略各有不同。比如在 Twemproxy 中,Proxy 保证在某一个 Redis 节点挂掉之后会把它从集群中移除,后续的请求将由其他节点来完成;而 Codis 的实现略复杂,它提供了一个叫 Codis Ha 的工具来实现自动从节点提主节点,在 3.2 版本之后换做了 Redis Sentinel 方式,从而实现 Redis 节点的高可用。
3.服务端方案
Redis Sentinel 也是集群部署的,这样可以避免 Sentinel 节点挂掉造成无法自动故障恢复的问题,每一个 Sentinel 节点都是无状态的。在 Sentinel 中会配置 Master 的地址,Sentinel 会时刻监控 Master 的状态,当发现 Master 在配置的时间间隔内无响应,就认为 Master 已经挂了,Sentinel 会从从节点中选取一个提升为主节点,并且把所有其他的从节点作为新主的从节点。Sentinel 集群内部在仲裁的时候,会根据配置的值来决定当有几个 Sentinel 节点认为主挂掉可以做主从切换的操作,也就是集群内部需要对缓存节点的状态达成一致才行。
Redis Sentinel 不属于代理层模式,因为对于缓存的写入和读取请求不会经过 Sentinel 节点。Sentinel 节点在架构上和主从是平级的,是作为管理者存在的,所以可以认为是在服务端提供的一种高可用方案。
缓存的使用姿势(三):缓存穿透了怎么办?
回种空值以及使用布隆过滤器
布隆过滤器缺陷
1. 它在判断元素是否在集合中时是有一定错误几率的,比如它会把不是集合中的元素判断为处在集合中;
2. 不支持删除元素。
总的来说,回种空值和布隆过滤器是解决缓存穿透问题的两种最主要的解决方案,但是它们也有各自的适用场景,并不能解决所有问题。
比方说当有一个极热点的缓存项,它一旦失效会有大量请求穿透到数据库,这会对数据库造成瞬时极大的压力,我们把这个场景叫做“dog-pile effect”(狗桩效应)
- 在代码中控制在某一个热点缓存项失效之后启动一个后台线程,穿透到数据库,将数据加载到缓存中,在缓存未加载之前,所有访问这个缓存的请求都不再穿透而直接返回。
- 通过在 Memcached 或者 Redis 中设置分布式锁,只有获取到锁的请求才能够穿透到数据库。
CDN:静态资源如何加速?
静态资源访问的关键点是就近访问,即北京用户访问北京的数据,杭州用户访问杭州的数据,这样才可以达到性能的最优。
CDN(Content Delivery Network/Content Distribution Network,内容分发网络)。简单来说,CDN 就是将静态的资源分发到位于多个地理位置机房中的服务器上,因此它能很好地解决数据就近访问的问题,也就加快了静态资源的访问速度。
引入DNS,查询域名的问题,但是分级查询会导致整个 DNS 的解析的时间有可能会到秒级别。
一个解决的思路是:在 APP 启动时对需要解析的域名做预先解析,然后把解析的结果缓存到本地的一个 LRU 缓存里面。这样当我们要使用这个域名的时候,只需要从缓存中直接拿到所需要的 IP 地址就好了,如果缓存中不存在才会走整个 DNS 查询的过程。同时为了避免 DNS 解析结果的变更造成缓存内数据失效,我们可以启动一个定时器定期地更新缓存中的数据。
GSLB 可以给用户返回一个离着他更近的节点,加快静态资源的访问速度。