案例引入
假如你们一家已上市的电商公司,在元旦来临前夕,领导需要你模拟用户,通过接口生成10万笔新订单。你该如何处理?
方案探索
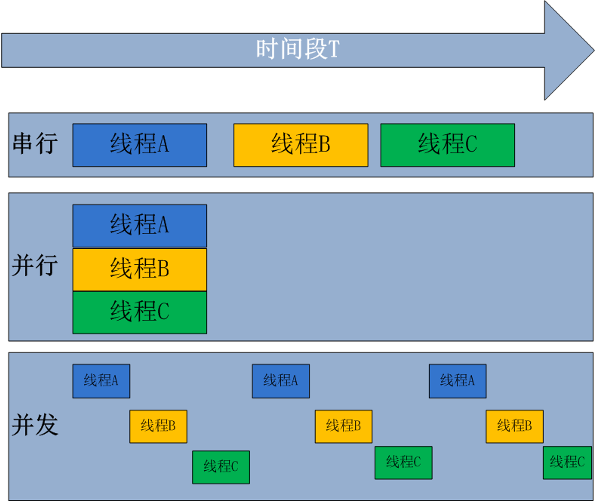
- 串行: 多个任务逐个执行的过程,上个任务执行完成前,阻塞下一个任务执行。
- 并发:多个任务交替执行的过程,这些任务可能在同一时间段内执行,但是它们的执行时间可能会重叠。
- 并行:多个任务同时执行的过程,这些任务在同一时间段内执行,它们的执行时间不会重叠。
Python中的多任务处理
- 串行
- 多线程 / 线程池
- 多进程 / 进程池
- 协程
多线程
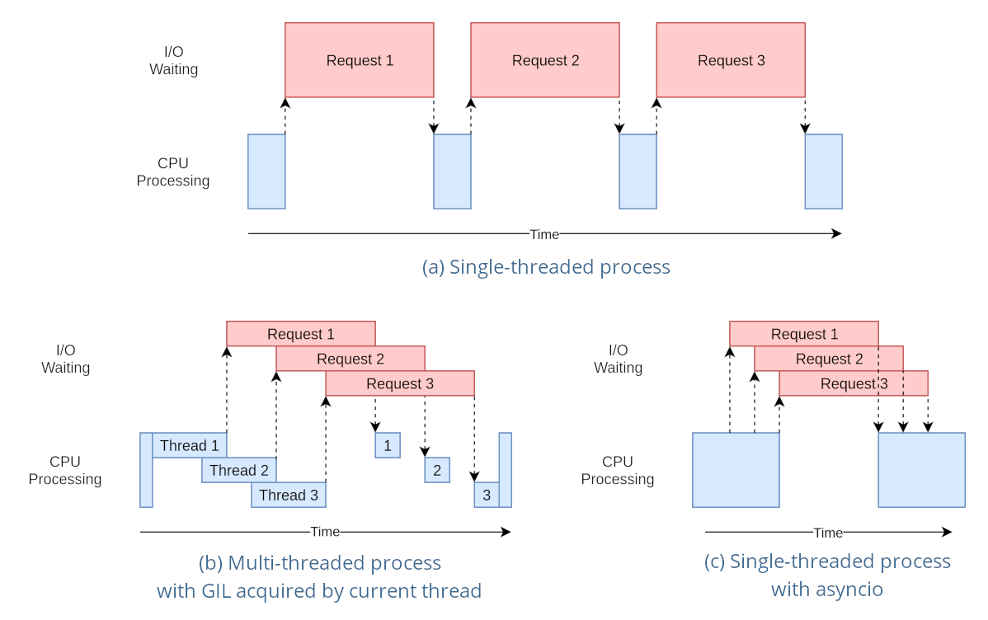
多线程是指在一个进程中并发运行多个独立的任务,每个任务称为一个线程,线程之间共享该进程中的变量、内存等资源。
多线程可以充分利用单个CPU的处理能力,提高程序的并发性和响应速度,同时也可以避免阻塞和等待的问题。
如何使用多线程
- 编写任务函数:
def get(url): pass - 创建线程对象:
t = Thread(target=get) - 启动线程:
t.start() - 连接到主线程:
t.join()
from threading import Thread
import requests
def get(url):
res = requests.get(url)
print(res.text)
return res
t = Thread(target=task, args=('https://postman-echo.com/get',))
t.start()
t.join() # 阻塞当前线程(主线程),等待t线程执行结束
threads = []
for i in range(10):
t = threading.Thread(target=task, args=(('https://postman-echo.com/get',))
threads.append(t)
t.start()
for i in range(10):
t.join()
Thread对象属性及方法
初始化参数
- group:线程组(暂无功能)。
- target:目标函数(必填)。
- name:线程名。
- args: 目标函数位置参数(元祖类型)。
- kwargs:目标函数关键字参数(字典类型)。
- daemon:是否作作为守护线程(如果主线程结束,守护线程将立即结束,布尔类型)。
线程相关方法
- start():启动一个独立的线程运行自身的run方法。
- run():根据target、args及kwargs调用目标函数。
- join():阻塞当前(主)线程,等待自身执行结束。
- is_alive():线程是否Ready状态。
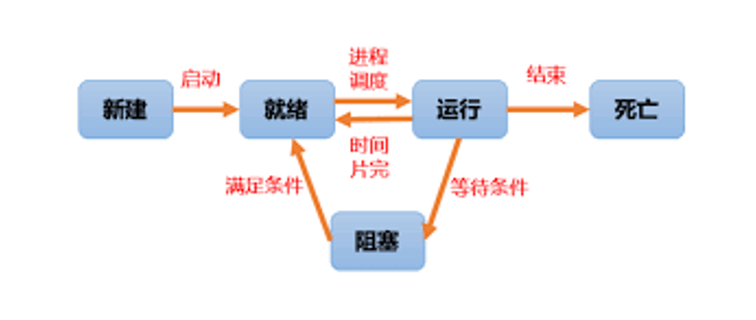
线程状态
- 新建(New):当线程对象被创建时,线程处于新建状态。
- 就绪(Ready):当线程调用start()方法后,线程处于就绪状态,等待CPU调度执行。
- 运行(Running):当线程被CPU调度执行时,线程处于运行状态。
- 阻塞(Blocked):当线程等待某个事件(如I/O操作)完成时,线程处于阻塞状态。
- 死亡(Dead):当线程执行完毕或者出现异常时,线程处于死亡状态。
线程状态
可以通过is_alive()方法来获取线程的状态,如果线程处于就绪、运行或阻塞状态,is_alive()方法返回True,否则返回False。
import time
from threading import Thread
import requests
def get(url):
res = requests.get(url)
print(res.text)
return res
thread = Thread(target=get, args=('https://postman-echo.com/get',))
print('未启动时:', thread.is_alive())
thread.start()
print('启动后:', thread.is_alive())
thread.join()
print('运行结束后:', thread.is_alive())
获取线程执行结果
from threading import Thread
class MyThread(Thread):
def __init__(self, group=None, target=None, name=None,
args=(), kwargs=None, *, daemon=None):
super(MyThread, self).__init__(group, target, name, args, kwargs, daemon=daemon)
self.result = None # 新增一个属性用于记录函数调用结果
def run(self):
try:
if self._target:
self.result = self._target(*self._args, **self._kwargs) # 记录函数调用结果
finally:
del self._target, self._args, self._kwargs
def get(url): ...
threads = [MyThread(target=get, args=('...',)) for i in range(10)]
[t.start() for t in threads]
[t.join() for t in threads]
results = [t.result for t in threads] # 获取所有线程结果
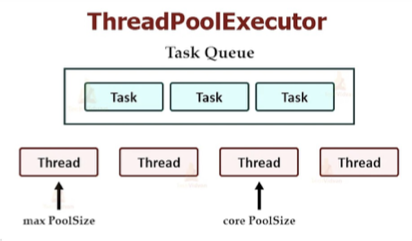
线程池
在Python中,使用线程池可以预先创建一定数量的线程,并将任务分配给这些线程执行,从而避免了线程创建和销毁的开销,提高了程序的响应速度。
from concurrent.futures import ThreadPoolExecutor, as_completed
pool = ThreadPoolExecutor(max_workers=5) # 新建线程池执行器
tasks = []
for i in range(10):
task = pool.submit(task) # 提交任务
tasks.append(task)
for task in as_completed(tasks): # 等待全部结束
print(task.result())
pool.shutdown() # 关闭线程池
线程锁
不带锁
在使用多线程并发修改共享资源时,可能存在数据被覆盖或丢失的问题。
from threading import Thread
class Counter:
def __init__(self):
self.value = 0
def increase(self):
self.value += 1
def worker(counter):
for i in range(100000):
counter.increase()
counter = Counter()
threads = []
for i in range(10):
t = Thread(target=worker, args=(counter,))
threads.append(t)
t.start()
for t in threads:
t.join()
print(counter.value)
带锁
在涉及并发修改的多线程编程中,一般需要使用锁等机制来保护共享资源,以避免并发访问导致的问题。
from threading import Thread, Lock
class Counter:
def __init__(self):
self.value = 0
self.lock = Lock() # 新建一个同步锁
def increase(self):
self.lock.acquire() # 请求锁
self.value += 1
self.lock.release() # 释放锁
常用线程锁
在Python的threading模块中,有多种线程锁可以用来保证线程安全。
- Lock:同步锁,可以用来保证同一时间只有一个线程可以访问共享资源。当一个线程获取到锁时,其他线程必须等待该线程释放锁后才能获取锁。
- RLock:可重入锁(递归锁),可以被同一个线程多次获取,避免死锁。当一个线程获取到锁时,可以多次获取锁,但必须释放相同次数的锁才能释放锁。
- vSemaphore**:信号量,可以用来控制同时访问共享资源的线程数量。当信号量的值为1时,只有一个线程可以访问共享资源,当信号量的值大于1时,多个线程可以同时访问共享资源。
- Event:事件锁,可以用来实现线程间的通信。当一个线程等待事件时,它会被阻塞,直到另一个线程设置了该事件。
- Condition:条件锁,可以用来实现线程间的协调。当一个线程等待条件变量时,它会被阻塞,直到另一个线程通知了该条件变量。
重入锁
当同一线程需要多次操作不同的修改时,使用RLock可以避免重复获取锁。
from threading import Thread, RLock
class Counter:
def __init__(self):
self.value = 0
self.lock = RLock() # 新建一个同步锁
def increase(self):
with self.lock:
self.value += 1
def decrease(self):
with self.lock:
self.value -= 1
def worker(counter):
for i in range(100000):
counter.increase()
counter.decrease()
counter = Counter()
threads = []
for i in range(10):
t = Thread(target=worker, args=(counter,))
threads.append(t)
t.start()
for t in threads:
t.join()
print(counter.value)
信号量
信号量Semaphore的常见作用是控制并发量(同时运行的线程数)。
from threading import Thread, Semaphore
import requests
def get(url, semaphore):
semaphore.acquire()
res = requests.get(url)
print(res.text)
semaphore.release()
return res
semaphore = Semaphore(5) # 创建Semaphore对象,初始并发5
threads = []
for i in range(10):
t = Thread(target=get, args=('https://postman-echo.com/get', semaphore))
threads.append(t)
t.start()
for t in threads:
t.join()
事件锁
当线程中需要等待一些资源,或者需要设置集合点时,可以用Event进行触发。
import threading
import requests
def get(url, event):
event.wait() # 等待事件
res = requests.get(url)
print(res.text)
return res
event = threading.Event()
threads = []
for i in range(10):
t = threading.Thread(target=get, args=('https://postman-echo.com/get', event))
threads.append(t)
t.start()
print('现在开始')
event.set() # 发送事件
for t in threads:
t.join()
条件锁
当线程中需要更加复杂的一些条件时,可以使用Condition条件锁。在线程的操作影响到条件时,可以使用notify()来通知等待该条件的线程,来检查是否条件已达到。
from threading import Thread, Lock, Condition, current_thread
class Counter:
def __init__(self):
self._value = 0
self._lock = Lock()
self._condition = Condition(self._lock)
def increment(self):
with self._lock:
self._value += 1
self._condition.notify()
def wait_until(self, target):
with self._condition:
while self._value < target:
self._condition.wait()
def value(self):
with self._lock:
return self._value
def worker(counter):
for i in range(10):
counter.increment()
print(f"Worker {current_thread().name} incremented counter to {counter.value()}")
counter.wait_until(20)
print(f"Worker {current_thread().name} reached target")
counter = Counter()
threads = []
for i in range(2):
t = Thread(target=worker, args=(counter,))
threads.append(t)
t.start()
for t in threads:
t.join()
print(counter.value())
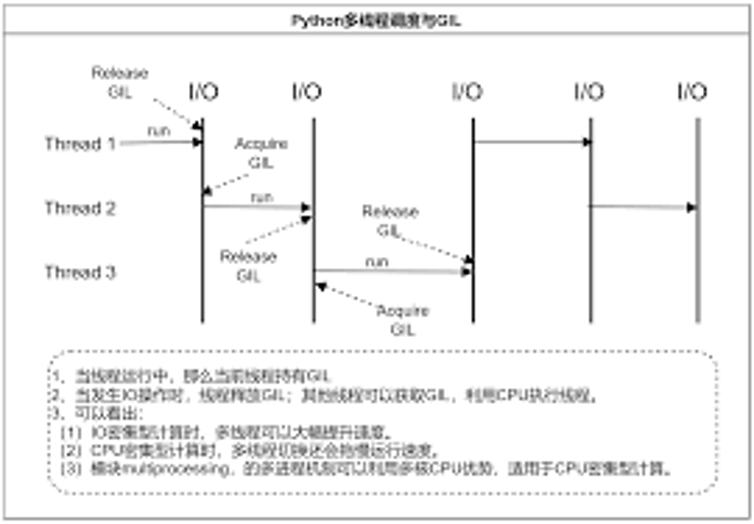
Python全局GIL锁
GIL(全局解释器锁)是Python解释器中的一种机制,它可以保证同一时间只有一个线程可以执行Python字节码。
GIL锁的存在是为了保证Python解释器的线程安全,避免多个线程同时访问共享资源导致的数据竞争和锁竞争。
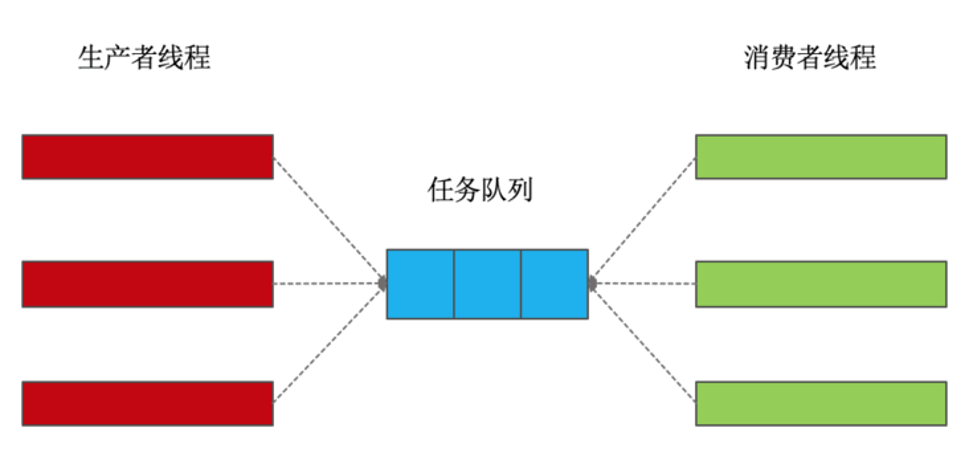
生产者/消费者模式
生产者-消费者模式是一种常用的并发编程模式,它可以将一个程序分成多个生产者和消费者,并通过一个共享的缓冲区来实现它们之间的通信。
- queue.Queue(),可以用来创建一个线程安全的队列,多个线程可以同时访问这个队列。
- put()方法:添加元素,当队列已满时,put方法会阻塞线程,直到队列中有空间可供添加元素。
- get()方法,获取元素。当队列为空时,get方法会阻塞线程,直到队列中有元素可供获取。
生产者-消费者模式示例
import queue
import threading
import time
def producer(queue):
for i in range(5):
print(f'Producing {i}')
queue.put(i)
time.sleep(1)
def consumer(queue):
while True:
item = queue.get()
if item is None:
break
print(f'Consuming {item}')
time.sleep(2)
if __name__ == '__main__':
q = queue.Queue(maxsize=3)
p = threading.Thread(target=producer, args=(q,))
c = threading.Thread(target=consumer, args=(q,))
p.start()
c.start()
p.join()
q.put(None)
c.join()
多进程
进程是程序运行的基本单位,每个进程都享有独立的地址空间和系统资源。
多进程是指将一个程序分成多个进程并行执行,从而提高程序的性能和效率。多进程可以充分利用多核CPU的性能。
如何使用多进程
在Python中,可以使用multiprocessing模块来创建和管理多进程。
multiprocessing模块提供了多种创建和管理进程的方法,包括Process类、Pool类、Queue类等。
其中,Process类可以用来创建单个进程,Pool类可以用来创建进程池,Queue类可以用来实现进程间的通信。
from multiprocessing import Process
import requests
def get(url):
res = requests.get(url)
print(res.text)
return res
def main():
processes = []
for i in range(10):
p = Process(target=get, args=('http://postman-echo.com/get',))
processes.append(p)
p.start()
for p in processes:
p.join()
if __name__ == '__main__':
main()
进程和线程的区别
- 资源占用:进程是系统分配资源的基本单位,包括内存、文件、网络等资源,每个进程都有独立的地址空间和系统资源。而线程是进程中的执行单元,共享进程的地址空间和系统资源,但是每个线程有独立的栈空间和程序计数器。
- 切换开销:进程切换的开销比线程切换的开销大,因为进程切换需要保存和恢复整个进程的状态,包括内存、寄存器、文件等。而线程切换只需要保存和恢复线程的栈空间和程序计数器。
- 通信方式:进程之间的通信需要使用进程间通信(IPC)机制,如管道、消息队列、共享内存等。而线程之间的通信可以直接访问共享变量或使用线程同步原语,如锁、信号量、条件变量等。
- 安全性:由于进程之间有独立的地址空间和系统资源,因此进程之间的数据不会相互影响,具有较高的安全性。而线程之间共享进程的地址空间和系统资源,因此线程之间的数据可能会相互影响,需要使用线程同步原语来保证数据的一致性和安全性。
- 创建和销毁:创建和销毁进程的开销比创建和销毁线程的开销大,因为进程需要分配和释放独立的地址空间和系统资源。而线程的创建和销毁比较轻量级,只需要分配和释放线程的栈空间和程序计数器。
多进程还是多线程
- CPU密集型任务:如果应用程序需要进行大量的计算和处理,可以选择使用多进程。因为多进程可以充分利用多核CPU的性能,避免GIL(全局解释器锁)的限制,提高计算效率。
- I/O密集型任务:如果应用程序需要进行大量的I/O操作,如读写文件、网络通信等,可以选择使用多线程。因为多线程可以避免I/O操作的阻塞,提高响应速度和吞吐量。
- 数据共享和协调任务:如果应用程序需要共享数据和协调任务,可以选择使用多线程或多进程。但是,多线程之间共享数据需要使用线程同步原语,如锁、信号量、条件变量等,以保证数据的一致性和安全性。而多进程之间共享数据需要使用进程间通信(IPC)机制,如管道、消息队列、共享内存等。
- 可移植性:如果应用程序需要在不同的操作系统上运行,可以选择使用多线程。因为多线程是基于操作系统的线程实现的,可以在不同的操作系统上运行。而多进程需要使用操作系统提供的进程间通信(IPC)机制,不同的操作系统可能有不同的实现方式和限制。
- 安全性和稳定性:如果应用程序需要更高的安全性和稳定性,可以选择使用多进程。因为每个进程都有独立的地址空间和系统资源,可以避免资源竞争和数据不一致的问题。而多线程共享进程的地址空间和系统资源,可能会导致数据不一致和安全性问题。
- 资源占用:如果应用程序需要占用大量的内存、文件、网络等系统资源,可以选择使用多进程。因为每个进程都有独立的地址空间和系统资源,可以避免资源竞争和数据不一致的问题。而多线程共享进程的地址空间和系统资源,可能会导致数据不一致和安全性问题。
- 可维护性:如果应用程序需要更好的可维护性和可扩展性,可以选择使用多线程。因为多线程可以共享代码和数据,减少代码冗余和维护成本。而多进程需要使用进程间通信(IPC)机制,增加了代码复杂度和维护成本。
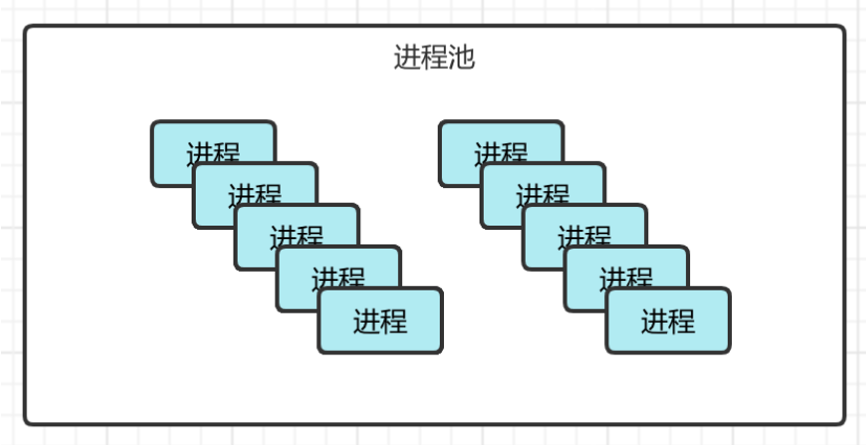
进程池
在Python中,进程池是一种常用的并发编程技术,它可以预先创建一定数量的进程,并将任务分配给这些进程执行,从而避免了进程创建和销毁的开销,提高了程序的响应速度。
multiprocessing模块中的Pool类提供了apply方法、apply_async方法、map方法和map_async方法等,可以用来提交任务和批量提交任务。其中,apply方法和apply_async方法用于提交单个任务,map方法和map_async方法用于批量提交任务。
进程池示例
相较与多线程或线程池,多进程或进程池的开销仍然相对较大,在处理I/O密集型任务(如网络请求)时性能并不太占优势。
from multiprocessing import Pool
import requests
def get(url):
res = requests.get(url)
print(res.text)
return res
def main():
results = []
pool = Pool(processes=5)
for i in range(10):
result = pool.apply(get, args=('http://postman-echo.com/get',))
results.append(result)
print('Results:', results)
if __name__ == '__main__':
main()
多进程通信
在Python中,可以使用多种方式实现进程间通信,包括:
- 管道(Pipe):管道是一种双向通道,可以在两个进程之间传递数据。
- 多进程队列(Queue):队列是一种多进程安全的数据结构,可以在多个进程之间传递数据
- 共享内存(Value和Array):共享内存是一种多进程共享数据的方式,可以在多个进程之间共享同一块内存区域。
- 数据管理器(Manager):数据管理器是一种多进程共享数据的方式,可以在多个进程之间共享同一整套数据。
- 套接字(Socket):多个进程绑定不同的端口,基于TCP/UDP协议进行通信,甚至分布式跨主机通信。
管道
管道Pipe常用于两个进程之间一对一传递数据。
from multiprocessing import Process, Pipe
def worker(conn):
conn.send('Hello')
data = conn.recv()
print('Received:', data)
conn.close()
def main():
parent_conn, child_conn = Pipe()
p = Process(target=worker, args=(child_conn,))
p.start()
data = parent_conn.recv()
print('Received:', data)
parent_conn.send('World')
p.join()
if __name__ == '__main__':
main()
多进程队列
进程队列multiprocessing.Queue可以在多个进程对多个进程之间传递数据。
多进程队列和普通队列区别如下:
- queue.Queue: 基于锁及条件锁实现,常用于多线程通信。
- multiprocessing.Queue基于共享内存和进程锁实现,用于多个进程之间通信。
from multiprocessing import Process, Queue
def worker(queue):
queue.put('Hello')
data = queue.get()
print('Received:', data)
def main():
queue = Queue()
p = Process(target=worker, args=(queue,))
p.start()
data = queue.get()
print('Received:', data)
queue.put('World')
p.join()
if __name__ == '__main__':
main()
共享内存
multiprocessing模块中的Value和Array对象和在多个进程之间共享单个变量或一组变量。
from multiprocessing import Process, Value, Array
def worker(num, value, array):
value.value = num
array[num] = num * 2
def main():
value = Value('i', 0)
array = Array('i', range(5))
processes = [Process(target=worker, args=(i, value, array)) for i in range(5)]
for p in processes:
p.start()
for p in processes:
p.join()
print('Value:', value.value)
print('Array:', list(array))
if __name__ == '__main__':
main()
数据管理器
multiprocessing模块的Manager类来实现进程间共享数据。Manager类提供了一个进程间共享的命名空间,可以在多个进程之间共享数据。
from multiprocessing import Process, Manager, current_process
def worker(d):
d["count"] += 1
print(f"Worker {current_process().name} updated count to {d['count']}")
def main():
manager = Manager()
d = manager.dict({"count": 0})
processes = []
for i in range(5):
p = Process(target=worker, args=(d,))
processes.append(p)
p.start()
for p in processes:
p.join()
print(f"Final count: {d['count']}")
if __name__ == "__main__":
main()
套接字
multiprocessing模块的Manager类来实现进程间共享数据。Manager类提供了一个进程间共享的命名空间,可以在多个进程之间共享数据。
import socket
from multiprocessing import Process
def server():
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('localhost', 6000))
s.listen(1)
conn, addr = s.accept()
data = conn.recv(1024)
print('Received:', data.decode())
conn.sendall(b'World')
conn.close()
def client():
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('localhost', 6000))
s.sendall(b'Hello')
data = s.recv(1024)
print('Received:', data.decode())
s.close()
if __name__ == '__main__':
p1 = Process(target=server)
p2 = Process(target=client)
p1.start()
p2.start()
p1.join()
p2.join()
Master-Worker模式
Master-Worker模式是一种常用的并行计算模式,它可以将一个大任务分解成多个小任务,并将这些小任务分配给多个Worker节点并行执行,最后将结果汇总得到最终结果。
在Python中,可以使用multiprocessing模块来实现Master-Worker模式。
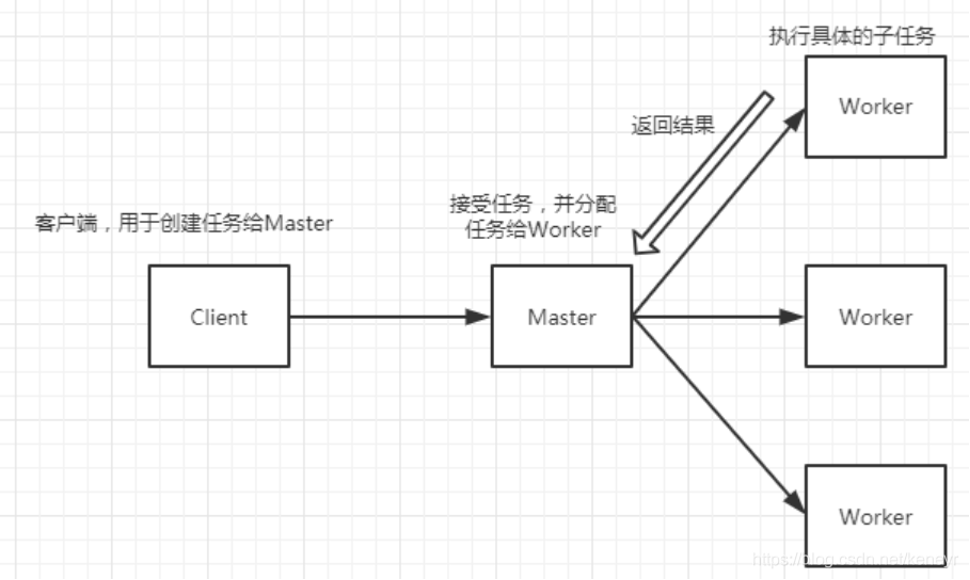
Master-Worker模式示例
在Master-Worker模式中,Master节点负责将任务分解成多个小任务,并将这些小任务分配给多个Worker节点执行。
Worker节点负责接收任务,执行任务,并将结果返回给Master节点。
Master节点收集所有Worker节点的结果,并将它们汇总得到最终结果。
from multiprocessing import Process, Queue, cpu_count
def worker(task_queue, result_queue):
while True:
task = task_queue.get()
if task is None:
break
result = task * 2
result_queue.put(result)
def master():
tasks = [1, 2, 3, 4, 5]
task_queue = Queue()
result_queue = Queue()
for task in tasks:
task_queue.put(task)
num_workers = cpu_count()
workers = [Process(target=worker, args=(task_queue, result_queue)) for i in range(num_workers)]
for w in workers:
w.start()
for w in workers:
task_queue.put(None)
for w in workers:
w.join()
results = []
while not result_queue.empty():
result = result_queue.get()
results.append(result)
print('Results:', results)
if __name__ == '__main__':
master()
协程
协程(Coroutine)是一种轻量级的线程,也称为用户级线程或绿色线程。协程是一种特殊的函数,可以在执行过程中暂停并保存当前状态,然后在需要的时候恢复执行。协程可以在单线程中实现并发,可以提高程序的效率和响应速度。
如何使用协程
在Python中,可以使用asyncio模块来实现协程。
asyncio模块提供了async和await关键字,可以用来定义协程函数和协程对象。
协程函数是一种特殊的函数,它可以在执行过程中暂停并等待其他协程执行完毕后再继续执行。
协程对象是一种特殊的对象,它可以被调度器调度并执行。
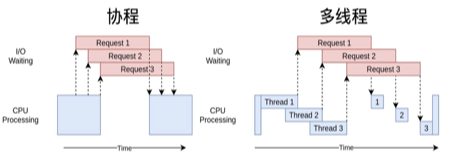
编写协程步骤:
- 定义任务(异步)函数:
async def get(url): ... - 定义主(异步)函数:
async def main(): ... - 使用await等待并自动切换执行函数。
- 使用
asyncio.run()运行主(异步)函数。
示例-不收集结果
import aiohttp # 需要pip install aiohttp
import asyncio
async def get(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as res:
body = await res.text()
print(body)
return body
async def main():
for i in range(10):
await get('https://postman-echo.com/get')
if __name__ == '__main__':
asyncio.run(main())
示例-搜集结果
import aiohttp # 需要pip install aiohttp
import asyncio
async def get(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as res:
body = await res.text()
print(body)
return body
async def main():
tasks = [get('https://postman-echo.com/get') for _ in range(10)]
results = await asyncio.gather(*tasks)
print('Results:', results)
if __name__ == '__main__':
asyncio.run(main())
协程并发量控制
协程的优势在于可以避免线程切换的开销,从而提高程序的性能。但是,如果协程数量过多,也会导致程序的性能下降。因此,需要控制协程的并发量,以充分利用系统资源,同时避免资源浪费。可以使用asyncio.Semaphore或asyncio.Queue来控制协程并发量。
import aiohttp # 需要pip install aiohttp
import asyncio
async def get(url, semaphore):
async with semaphore:
async with aiohttp.ClientSession() as session:
async with session.get(url) as res:
body = await res.text()
print(body)
return body
async def main():
semaphore = asyncio.Semaphore(5)
tasks = [get('https://postman-echo.com/get', semaphore) for _ in range(10)]
results = await asyncio.gather(*tasks)
print('Results:', results)
if __name__ == '__main__':
asyncio.run(main())
Python网络编程
Python提供了丰富的库和模块,用于进行网络编程。
常用的Python网络编程库和模块:
- socket:底层的网络接口(套接字)。
- sl: 为socket提供TLS/SSL加密。
- socketserver : 基于socket的TCP服务器及UDP服务器。
- urllib:URL处理及发送HTTP请求的功能。
- http: 简单的HTTP服务端及客户端。
- ftplib: FTP协议客户端。
- poplib: POP3协议客户端。
- imaplib: IMAP协议客户端。
- smtplib:SMTP协议客户端。
- xmlrpc: XML-RPC服务端及客户端。
Python TCP及UDP协议
在Python中,可以使用socket模块发送TCP和UDP协议
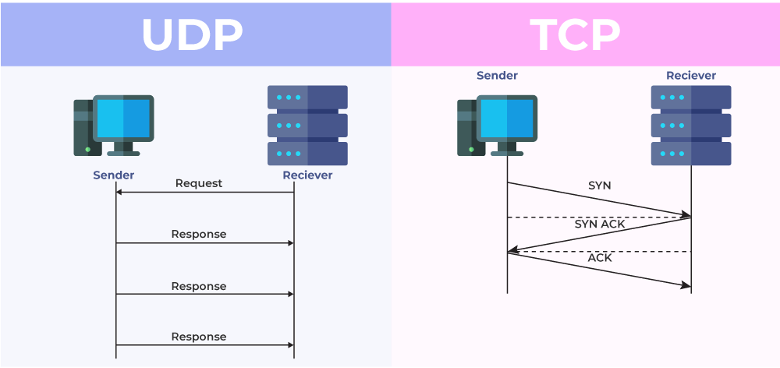
sock = socket.socket(<family>, <type>)
family类型:
- socket.AF_UNIX: sock文件
- socket.AF_INET: IPv4
- socket. AF_INET6: IPv6
type类型
- socket. SOCK_STREAM: TCP连接
- socket. SOCK_DGRAM: UDP连接
TCP服务端及客户端
使用socket
TCP服务端及客户端socket常用的方法:
- bind(): 服务端绑定服务地址
- accept() : TCP服务端接收消息,收到的是一个客户端socket链接和客户端地址
- send(): TCP服务端使用客户端socket发送消息
- recv(): TCP客户端接收消息
- close(): 关闭socket
# TCP服务端
import socket
IPv4, TCP = socket.AF_INET, socket.SOCK_STREAM
SERVER_ADDR = ('127.0.0.1', 9999) # 服务端地址
with socket.socket(IPv4, TCP) as s:
s.bind(SERVER_ADDR) # 绑定服务地址
s.listen(5) # 设置监听数量
while True: # 循环接收消息
client_socket, addr = s.accept() # 接收消息
print(f'连接的客户端地址: {addr}')
msg = '欢迎客户端 {addr}'
client_socket.send(msg.encode())
client_socket.close()
# TCP客户端
import socket
IPv4, TCP = socket.AF_INET, socket.SOCK_STREAM
SERVER_ADDR = ('127.0.0.1', 9999) # 服务端地址
with socket.socket(IPv4, TCP) as s:
s.connect(SERVER_ADDR) # 连接服务端
msg = s.recv(1024) # 客户端接收消息
s.close()
print(msg.decode())
使用socketserver
也可以使用socketserver中的TCPServer来实现TCP服务端。不同的是你通过实现一个请求处理类(Handler)来处理请求,这个请求处理类应继承BaseRequestHandler,并实现handle方法。
Handler类中常用方法如下:
- self.request.recv():接收客户端数据
- self.client_address:客户端地址及端口号
- self.request.sendall():发送数据给所有连接的客户端
# TCP服务端2
from socketserver import TCPServer, BaseRequestHandler
SERVER_ADDR = ('127.0.0.1', 9991) # 服务端地址
class MyTCPHandler(BaseRequestHandler):
def handle(self):
print(f'连接的客户端地址: {self.client_address}')
msg = '你好客户端'
self.request.sendall(msg.encode())
with TCPServer(SERVER_ADDR, MyTCPHandler) as server:
server.serve_forever()
# TCP客户端
import socket
IPv4, TCP = socket.AF_INET, socket.SOCK_STREAM
SERVER_ADDR = ('127.0.0.1', 9999) # 服务端地址
with socket.socket(IPv4, TCP) as s:
s.connect(SERVER_ADDR) # 连接服务端
msg = s.recv(1024) # 客户端接收消息
s.close()
print(msg.decode())
UDP服务端及客户端
使用socket
UDP服务端及客户端socket常用的方法:
- bind():服务端绑定服务地址
- recvfrom() :UDP服务端/客户端接收消息,收到的数据及另一端地址
- sendto():UDP服务端发送消息给客户端
- recv():客户端接收消息
- close():关闭socket
# UDP服务端
import socket
IPv4, UDP = socket.AF_INET, socket.SOCK_DGRAM
SERVER_ADDRESS = ("127.0.0.1", 9998)
with socket.socket(IPv4, UDP) as s:
s.bind(SERVER_ADDRESS) # 绑定服务地址
while True:
data, client_addr = s.recvfrom(1024) # 接收数据和客户端地址
print(f"收到客户端消息 {client_addr}: {data.decode()}")
msg = "客户端你好"
s.sendto(msg.encode(), client_addr) # 发送响应数据给客户端
# UDP客户端
import socket
IPv4, UDP = socket.AF_INET, socket.SOCK_DGRAM
SERVER_ADDRESS = ("127.0.0.1", 9998)
with socket.socket(IPv4, UDP) as s:
msg = "你好服务端"
s.sendto(msg.encode(), SERVER_ADDRESS) # 发送数据给服务器
data, server_addr = s.recvfrom(1024) # 接收服务器消息
print(f"收到服务端消息 {server_addr}: {data.decode()}")
使用socketserver
同样可以使用socketserver的UDPServer来实现UDP服务端。同样你需要继承BaseRequestHandler并通过handle
方法来处理请求数据, Handler类中常用的属性及方法如下:
- data, client_socket = self.request: 获取客户端请求数据及客户端socket连接
- sendto(): UDP服务端使用客户端socket发送消息给客户端
# UDP服务端2
from socketserver import UDPServer, BaseRequestHandler
SERVER_ADDRESS = ("127.0.0.1", 9998)
class MyUDPHandler(BaseRequestHandler):
def handle(self):
data, client_socket = self.request
print(f"收到客户端消息 {self.client_address} {data.decode()}")
msg = "客户端你好"
client_socket.sendto(msg.encode(), self.client_address)
with UDPServer(SERVER_ADDRESS, MyUDPHandler) as server:
server.serve_forever()
# UDP客户端
import socket
IPv4, UDP = socket.AF_INET, socket.SOCK_DGRAM
SERVER_ADDRESS = ("127.0.0.1", 9998)
with socket.socket(IPv4, UDP) as s:
msg = "你好服务端"
s.sendto(msg.encode(), SERVER_ADDRESS) # 发送数据给服务器
data, server_addr = s.recvfrom(1024) # 接收服务器消息
print(f"收到服务端消息 {server_addr}: {data.decode()}")
HTTP协议
http库
Python中内置了http模块包含http.server、http.client、http.cookies、http.cookiejar及HTTPStatus等。
- http.server:基于TCPServer的一个简单的HTTP服务器(静态文件服务器)。
- http.client:一个低层级的 HTTP 协议客户端,对于高层级的 URL 访问请使用 urllib.request。
from http.server import SimpleHTTPRequestHandler
from socketserver import TCPServer
SERVER_ADDRESS = ("127.0.0.1", 8000)
with TCPServer(SERVER_ADDRESS, SimpleHTTPRequestHandler) as httpd:
httpd.serve_forever()
from http.client import HTTPSConnection
conn = HTTPSConnection("postman-echo.com")
conn.request("GET", "/get")
res = conn.getresponse()
print('状态码', res.status,'状态码说明', res.reason)
print('响应数据', res.read().decode())
conn.close()
urllib库
Python中urllib库提供了urllib.request(发送http请求)、urllib.parse(URL解析)等相关的模块
- urllib.request常用方法如下:
- urlopen:打开(请求)指定URL,并返回响应数据。
- urllib.parse常用方法如下:
- urlparse:解析URL,得到各个部分。
- quote:将字符串格式数据进行URL编码
- unquote: 将URL编码字符串进行URL解码
- urlencode: 将字典格式数据进行URL编码,返回编码后的字符串。
from urllib import request, parse
query = parse.urlencode({'a': 1, 'b': 2})
url = "http://postman-echo.com/get?%s" % query
with request.urlopen(url) as f:
print('响应数据', f.read().decode())
from urllib.parse import quote, unquote, urlencode
url = 'http://postman-echo.com/get?name=%E4%B8%B4%E6%B8%8A&age=21'
print('URL解码:', unquote(url))
print('URL解码字符串:', quote('name=临渊&age=21'))
print('URL解码字典数据:', urlencode({'name': '临渊', 'age': 21}))
使用Flask/FastAPI搭建HTTP服务
Flask是Python三方的微型的Web服务框架,使用其编写接口非常简单。
FastAPI是一款高性能的异步Web服务框架,风格和Flask有点类似,并自带接口文档。
# 文件名: flask_app.py
#需要安装: pip install flask
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/', methods=['GET'])
def home():
return jsonify({'msg': 'hello flask'})
# 启动服务: 命令行运行 flask --app flask_app run –port 5000
# 文件名: fastapi_app.py
# 需要安装: pip install fast-api uvicorn
from fastapi import FastAPI
app = FastAPI()
@app.get('/')
async def home():
return {'msg': 'hello fast-api'}
# 启动服务: 命令行运行 uvicorn –port 5001 fastapi_app:app
# 访问 http://127.0.0.1:5001/docs 可以查看接口文档
使用Django搭建HTTP服务
Django是Python一款全栈的Web框架,使用pip install django进行安装,新建一个项目及应用:
$ django-admin startproject django_app
$ cd django_app
$ python manage.py startapp app
然后需要将”app”注册到django_app/setttings.py文件的INSTALLED_APPS中,
在app/views.py中编写接口,在app/url.py中挂载接口,
然后运行python3 manage.py runserver 5002启动服务。
# app/views.py
from django.http.response import JsonResponse
def home(request):
return JsonResponse({'msg': 'hello django'})
# django_app/url.py
from django.contrib import admin
from django.urls import path
from app.views import home
urlpatterns = [
path('admin/', admin.site.urls),
path('', home),
]
使用requests发送HTTP请求
requests是Python一个非常易用的三方HTTP请求库。安装方法pip install requests。缺点是不支持异步和HTTP/2。
详细使用可参考:https://www.cnblogs.com/superhin/p/12249847.html。
import requests
# 发送GET请求-携带query参数及自定义请求头
res = requests.get("https://postman-echo.com/get",
params={'name': '临渊', 'age':21},
headers={'token': 'abc123'})
print(res.text)
# 发送POST表单请求
res = requests.get("https://postman-echo.com/post",
data={'name': '临渊', 'age':21})
print(res.text)
# 发送POST JSON格式请求
res = requests.get("https://postman-echo.com/post",
json={'name': '临渊', 'age':21})
# 不支持HTTP/2
res = requests.get("https://http2.pro/api/v1")
print(res.text)
使用hyper发送HTTP/2请求
hyper是一个支持多种协议的HTTP请求库,安装方法pip install hyper。
简单使用示例如下,详细使用可以参考: https://hyper.readthedocs.io/en/latest/
import hyper
# 创建HTTP/2连接
conn = hyper.HTTP20Connection("http2.pro")
# 发送GET请求
conn.request("GET", "/api/v1")
# 获取响应
resp = conn.get_response()
# 打印响应状态码和响应头
print(f"Status: {resp.status}")
print(f"Headers: {resp.headers}")
# 打印响应体
print(resp.read())
使用aiohttp发送异步HTTP请求
aiohttp是异步高性能的HTTP请求库,安装方法pip install aiohttp。一般需要配合协程使用。
简单使用示例如下,详细使用可以参考:https://docs.aiohttp.org/en/stable/。
import aiohttp
import asyncio
async def main():
async with aiohttp.ClientSession() as session:
async with session.get('http://postmain-echo.com/get') as response:
print("状态码:", response.status)
print("响应内容类型:", response.headers['content-type'])
body = await response.text()
print("响应数据:", body)
asyncio.run(main())
使用PycURL发送HTTP请求
PycURL是一个Python库,用于发送和接收HTTP请求和数据。它是基于Curl库的Python封装,提供了与Curl库相似的API和功能,支持多种协议,如HTTP、HTTPS、FTP、SMTP等。安装方法pip install pycurl。
注意:MacOS上安装需要使用以下命令:
export PYCURL_SSL_LIBRARY=openssl
export LDFLAGS=-L/usr/local/opt/openssl/lib
export CPPFLAGS=-I/usr/local/opt/openssl/include
pip install pycurl --compile --no-cache-dir
import pycurl
c = pycurl.Curl()
c.setopt(pycurl.URL, 'http://postman-echo.com/get') # 设置URL
c.perform() # 发送请求(默认输出响应到控制台)
print('')
print('状态码', c.getinfo(pycurl.HTTP_CODE))
print('域名解析时间', c.getinfo(pycurl.NAMELOOKUP_TIME))
print('远程服务器连接时间', c.getinfo(pycurl.CONNECT_TIME))
print('连接上后到开始传输时的时间', c.getinfo(pycurl.PRETRANSFER_TIME))
print('接收到第一个字节的时间', c.getinfo(pycurl.STARTTRANSFER_TIME))
print('请求总的时间', c.getinfo(pycurl.TOTAL_TIME))
使用requestz发送HTTP请求
Requestz是作者基于PycURL封装的一款类Requests的库,使用方式和requests库类似,支持HTTP/2和响应数据统计。安装方法pip install requestz。
import requestz
res = requestz.get('https://http2.pro/api/v1')
print(res.text)
print(res.stats)
WebSocket协议
WebSocket是一种在Web浏览器和服务器之间进行双向通信的协议。它允许服务器主动向客户端发送消息,而不需要客户端发起请求。WebSocket协议是基于TCP协议的,它使用HTTP协议进行握手,然后在建立连接后,使用自定义的协议进行通信。 ws:// 或 wss://
WebSocket协议的优点包括:
- 实时性:Websockets协议可以实现实时通信,可以在服务器端有新消息时立即向客户端推送,而不需要客户端发起请求。
- 双向通信:Websockets协议允许服务器和客户端之间进行双向通信,可以在客户端和服务器之间传递任意类型的数据。
- 高效性:Websockets协议使用TCP协议进行通信,可以保证数据传输的可靠性和高效性。
Python中建立WebSocket服务端或发送WebSocket请求可以使用三方库websockets实现。
安装方法为pip install websockets。常见操作如下:
- serve():服务端启动服务
- connect():服务端建立连接
- send():发送消息
- recv():接收消息
# 服务端Server
import asyncio
import websockets
async def hello(websocket, path):
name = await websocket.recv()
print(f"< {name}")
greeting = f"Hello {name}!"
await websocket.send(greeting)
print(f"> {greeting}")
async def main():
async with websockets.serve(hello, "localhost", 8900):
await asyncio.Future()
asyncio.run(main())
# 客户端Client
import asyncio
import websockets
async def hello():
async with websockets.connect("ws://localhost:8900") as websocket:
name = input("What's your name? ")
await websocket.send(name)
print(f"> {name}")
greeting = await websocket.recv()
print(f"< {greeting}")
asyncio.run(hello())
WebDriver协议-基于HTTP通过中介控制浏览器
WebDriver协议是一种用于自动化Web浏览器的协议,它定义了一组API,用于控制Web浏览器的行为。
WebDriver协议可以与多种编程语言和测试框架集成,例如Python、Java、C#和Selenium等。
WebDriver协议的主要功能包括:
- 控制浏览器:WebDriver协议可以控制Web浏览器的行为,例如打开网页、点击链接、填写表单等。
- 获取元素:WebDriver协议可以获取Web页面中的元素,例如文本框、按钮、下拉框等。
- 操作元素:WebDriver协议可以对Web页面中的元素进行操作,例如输入文本、点击按钮、选择下拉框等。
- 执行JavaScript:WebDriver协议可以执行JavaScript代码,例如修改页面元素、获取页面属性等。
- 截图:WebDriver协议可以对Web页面进行截图,用于测试和调试。
WebDriver协议的使用步骤如下:
- 创建WebDriver实例:使用编程语言和测试框架创建WebDriver实例,用于控制Web浏览器。
- 打开网页:使用WebDriver实例打开指定的网页。
- 查找元素:使用WebDriver实例查找Web页面中的元素。
- 操作元素:使用WebDriver实例对Web页面中的元素进行操作。
- 执行JavaScript:使用WebDriver实例执行JavaScript代码。
- 截图:使用WebDriver实例对Web页面进行截图。
CDP协议-基于WebSocket-Pyppteer / Playwright
Chrome DevTools Protocol(CDP)是一种用于与Chrome浏览器通信的协议,它允许开发人员通过HTTP协议与Chrome浏览器进行通信,并控制浏览器的行为。
CDP协议提供了一组API,用于获取浏览器的状态信息、控制浏览器的行为、调试JavaScript代码等。
CDP协议的主要功能包括:
- 获取浏览器状态:CDP协议可以获取浏览器的状态信息,例如浏览器版本、页面加载状态、网络请求等。
- 控制浏览器行为:CDP协议可以控制浏览器的行为,例如打开网页、点击链接、填写表单等。
- 调试JavaScript代码:CDP协议可以调试JavaScript代码,例如设置断点、单步执行、查看变量等。
- 获取页面信息:CDP协议可以获取Web页面的信息,例如页面元素、CSS样式、DOM结构等。
- 截图:CDP协议可以对Web页面进行截图,用于测试和调试。
CDP协议的使用步骤如下:
- 连接Chrome浏览器:使用HTTP协议连接到Chrome浏览器,获取浏览器的状态信息。
- 控制浏览器:使用CDP协议控制浏览器的行为,例如打开网页、点击链接、填写表单等。
- 调试JavaScript代码:使用CDP协议调试JavaScript代码,例如设置断点、单步执行、查看变量等。
- 获取页面信息:使用CDP协议获取Web页面的信息,例如页面元素、CSS样式、DOM结构等。
- 截图:使用CDP协议对Web页面进行截图。
Python发送邮件
在Python中,可以使用smtplib模块实现SMTP协议(发送邮件),使用imaplib模块实现IMAP协议(接收邮件) ,使用poplib模块实现POP3协议(接收邮件)。以下是使用smtplib和email模块发送邮件到示例:
import smtplib # 用于建立smtp连接
from email.mime.text import MIMEText # 邮件需要专门的MIME格式
# 1. 编写邮件内容(Email邮件需要专门的MIME格式)
msg = MIMEText('this is a test email', 'plain', 'utf-8') # plain指普通文本格式邮件内容
# 2. 组装Email头(发件人,收件人,主题)
msg['From'] = '你的邮箱地址' # 发件人
msg['To'] = '收件人邮箱地址' # 收件人
msg['Subject'] = '邮件主题' # 邮件主题
# 3. 连接smtp服务器并发送邮件
smtp = smtplib.SMTP_SSL('smtp.qq.com') # smtp服务器地址 使用SSL模式
smtp.login('你的邮箱地址', '邮箱授权密码') # 用户名和密码
smtp.sendmail("你的邮箱地址", "收件人邮箱地址", msg.as_string())
smtp.quit()
使用Exchange邮箱发送邮件
Exchange是微软开发的,企业邮箱服务协议,Python中可以使用三方库exchangelib来连接企业邮箱并发送邮件,安装方法:pip install exchangelib,使用示例如下:
from exchangelib import Account, Credentials, Message, HTMLBody, Mailbox, FileAttachment
account = Account('***@***', # 企业邮箱exchange服务地址
credentials=Credentials(username='***@***', password='***'), # 你的邮箱及密码
autodiscover=True)
email = Message(
account=account,
subject='测试带附件下',
body=HTMLBody('<h2>hello with attachment</h2>'),
to_recipients=[Mailbox(email_address='superhin@126.com')]
)
# 携带附件
email.attach(FileAttachment(name='test.html', content=open('/result/test.html', 'rb').read()))
email.send()
Python SSH/SFTP协议
在Python中,可以使用三方包paramiko模块实现SSH协议。
安装方法:pip install paramiko。简单使用示例如下:
import paramiko
# SSH服务器地址、端口、用户名和密码
SSH_ADDRESS = “example.com”
SSH_PORT = 22
SSH_USERNAME = “username”
SSH_PASSWORD = “password”
ssh_client = paramiko.SSHClient() # 创建SSH客户端
ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 自动添加SSH主机密钥
ssh_client.connect(SSH_ADDRESS, SSH_PORT, SSH_USERNAME, SSH_PASSWORD) # 连接SSH服务器
stdin, stdout, stderr = ssh_client.exec_command(“ls -l”) # 执行命令
print(stdout.read().decode()) # 打印输出
sftp_client = ssh_client.open_sftp() # 创建SFTP客户端
sftp_client.put("local_file.txt", "remote_file.txt") # 上传文件
sftp_client.get("remote_file.txt", "local_file.txt") # 下载文件
sftp_client.close() # 关闭SFTP客户端
ssh_client.close() # 关闭SSH连接