爬虫request网站
爬虫学习02 requests高级用法
## 1 requests高级用法 ### 1.0 自动携带cookie 的session对象 ```python # session对象 》已经模拟登录上了一些网站 》单独把cookie 取出来 -res.cookies 是cookiejar对象,里面有get_dict()方法转换成字典 -转成字 ......
7.10 requests的高级使用
1. 自动携带cookie和session对象 header={ 'Referer': 'http://www.aa7a.cn/user.php?&ref=http%3A%2F%2Fwww.aa7a.cn%2F', 'User-Agent': 'Mozilla/5.0 (Windows NT 10. ......
爬虫使用
### 爬取新闻 ```python import re import requests from bs4 import BeautifulSoup import pymysql # 建立数据库链接 conn = pymysql.connect( user='root', password="123 ......
爬虫学习01
## 1 扫码登录功能 ```python # 前端 1 前端进入扫码登录页面 》向后端发送请求 》后端生成二维码图片 》显示在前端,暂存key 2 掏出手机,打开对应的app 》扫描二维码 》app端提示是否登录 》当你点登录 》app能解析出这个地址 》取出你当前app登录的token 》向这个 ......
如何为odoo15网站应用添加域名以及邮箱设置
odoo在服务器上安装好后,是通过IP地址加端口的方式访问的(例如:http://43.159.48.232:8069/)。实际应用的时候,IP地址和端口不好记。同时网站的功能也得需要一个网站地址。这篇文章主要介绍步骤就是通过安装Nginx, 启用SSL并设置80端口自动转向odoo的默认端口806... ......
2023-07-10 记录使用chrome浏览器点击内容搜索时跳转到了一个叫www.ibaixia.com的网站然后才跳转到www.baidu.com的异常
前言:猜测是chrome中毒了,或者就是网页被劫持了,每次搜索会跳转到www.ibaixia.com,然后在一瞬间又跳转到了百度搜索页。 解决方案:在 chrome 打开chrome://settings/searchEngines,也就是打开设置,找到【网站搜索】一栏,在该栏中找到百度字样,然后打 ......
一次网站部署的各种问题
一、安装基本环境 Java 下载jdk8的deb文件,用指令安装即可 MySQL 注意,只能安装mysql8。虽然我自认为安装的就是mysql8,但是负责部署的人说安装的实际上是5.7,从而导致后续java项目无法启动。 Redis apt安装即可 Nginx apt直接安装nginx即可 二、其他 ......
使用IPv6后一些网站无法访问,有时能访问有时无法访问问题解决
# 使用IPv6后一些网站无法访问,有时能访问有时无法访问问题解决 遇到这个问题有几天了,虽然有时候可以访问,况且也不是一定要快速访问,但是这样半死不活、并且让人不明就里的状态就很烦,所以开始着手解决这个问题。 把光猫分别配置了只用ipv4和ipv4&ipv6两种情况,发现的确只有在ipv6生效的时 ......
使用WARP,加速网站访问
https://hostloc.com/thread-1024969-1-1.html 1.使用全局模式代理 2.直接下载使用 3.利用优选工具 可以使IPv4直接支持访问ipv6的能力 数据库设计
# 1. 确定功能和需求 - 用户可以浏览产品列表,并查看每个产品的详细信息。 - 用户可以将产品添加到购物车,并在购物车中修改产品数量或删除产品。 - 用户可以生成订单,并提供送货地址和付款信息。 - 管理员可以管理产品信息、订单和用户。 # 2. 设计数据库架构 Products (产品表) ` ......
从零用python flask框架写一个简易的网站
要用Python写一个网站,你可以使用Python的Web框架来开发。常见的Python Web框架包括Django、Flask、Bottle等。以下是一个简单的使用Flask框架开发的示例。 ### 1. 安装Flask 在开始开发之前,你需要安装Flask框架。你可以使用以下命令来安装: ``` ......
Wordpress:如何更改Elementor绑定的网站?
在使用Wordpress做网站的过程中,需要用到Elementor付费版进行优化网站,一般是绑定一个网站后,要想新建另一个网站,基础版不支持多个绑定,那么如何进行改绑呢? 1.进入Elementor后台,选择Subscriptions >>> 选择已绑定的项,点击右下角 Manage This su ......
实战|如何在Linux 系统上免费托管网站
动动发财的小手,点个赞吧! Web 服务器可用于指代硬件和软件,或者两者一起工作。出于本指南的目的,我们将重点关注软件方面,并了解如何在 Linux 机器上托管网站。 Web 服务器是一种通过 HTTP/HTTPS 协议接收并响应客户端请求的软件程序。其主要目的是显示网站内容,这些内容通常采用文本、 ......
[学习笔记]python爬虫初体验
同学吹水,提到了爬虫,于是金工实习回来晚上看了看爬虫 (话说为啥所有爬虫教程前面都是一大串python基础教程啊) ```python import urllib.request #1、定义一个网址url url='http://www.baidu.com' #2、模拟浏览器向服务器发送请求 res ......
requests高级用法 代理池搭建 爬取某视频网站
[toc] ```python # 1 扫码登录 前端 -1 前端进入扫码登录页面 》向后端发送请求,获取一个验证码图片,显示在前端 -把key:1234567暂存 -2 掏出手机扫码 》用自己的app 》扫码 》app端提示是否登录 》当你点登录 》向二维码链接地址发送请求 》http://192 ......
http 和 https区别,自动携带cookie的session对象,响应response,下载图片视频到本地,编码问题,解析json,ssl认证,使用代理,超时设置,异常处理,上传文件,代理池搭建,爬取某视频网站
# 1.1 自动携带cookie 的session对象 ```python # session对象 》已经模拟登录上了一些网站 》单独把cookie 取出来 -res.cookies -转成字典 res.cookies.get_dict() #请求头和数据 import requests heade ......
,软件运行监听地址 ,扫码登录,爬虫介绍,requests模块介绍和快速使用,get请求携带参数,编码和解码,携带请求头,发送post请求携带数据,携带cookie两种方式
# 补充 ```python # 软件运行,监听地址 127.0.0.1 只能访问 127.0.0.1 localhost 不能用本机ip地址访问,外部所有人都不能 访问你 0.0.0.0 127.0.0.1 localhost 本机ip地址访问 同一个局域网内,都可以通过ip地址访问 # 本地ho ......
爬虫第一天基础
[toc] ## 1 前戏 ``` #介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3) #注意:requests库发送请求将网页内容下载下来以后,并不会执行js代码,这需要我们自己分析目标站点然后发起新的 ......
requests返回数据的处理
关于编码: resp.encoding = 'utf-8' resp.encoding = 'gbk' 关于内容三种方法: 一、etree.HTML(resp.text).xpath(): 1、参考网站未整理: https://www.jianshu.com/p/4d3c9cae5470https: ......
腻子网站的JS布局
腻子是一种施工材料,用于修补或平整墙面、天花板、地面等。它的主要作用是填补裂缝、平整不平的表面,并增加光滑度和美观性。在建筑和装饰行业中,腻子被广泛使用,成为了常见的施工工艺之一。 腻子的历史可以追溯到古代文明时期。早在古埃及时期,人们就开始使用类似腻子的材料进行墙面修补和装饰。而在中国古代,也有使 ......
413 Request Entity Too Large
1、client_max_body_size client_max_body_size 是一个Nginx配置指令,用于设置客户端请求体的最大大小限制。 在Nginx中,client_max_body_size指令的默认值是1m(即1兆字节)。这个指令用于限制客户端向服务器发送的请求体的最大大小。当客 ......
视频直播网站源码,Android 获取屏幕像素(宽高)
视频直播网站源码,Android 获取屏幕像素(宽高) Resources resources = this.getResources();DisplayMetrics dm = resources.getDisplayMetrics();int screenWidth = dm.widthPixe ......
直播网站源码,Android获取屏幕高宽
直播网站源码,Android获取屏幕高宽 The first:通过WindowManager来获取,个人建议使用 import android.content.Context;import android.util.DisplayMetrics;import android.view.WindowM ......
python爬虫scrapy入门教程
import scrapy class BlogSpider(scrapy.Spider): name = 'blogspider' start_urls = ['https://www.zyte.com/blog/'] def parse(self, response): for title in ......
【慢慢买嗅探神器】基于scrapy+pyqt的电商数据爬虫系统
### 项目预览 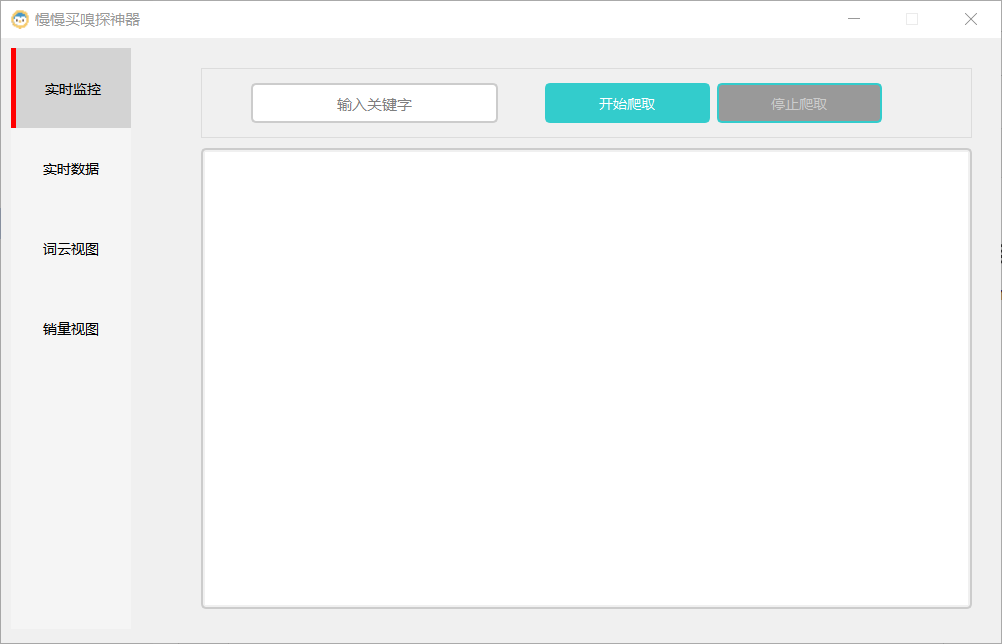 ![image](https://img2023.cnblogs.com/blog/ ......
移动端爬虫
移动端爬虫介绍 爬虫除了 Web 网页,也可以抓取 App 的数据。 为什么要学习移动APP的爬虫? 公司需求 随机互联网的发展,数据不仅仅只是存在于PC端。移动端的数据在这几年的占比以及势头发展趋势呈现几何倍数的增长。对于做数据分析、用户画像、市场调研来说仅仅参考PC端的数据是远远不够的。 有时w ......
7.6 爬虫基础知识学习 requests的使用
1. requests的快速使用 /1 爬虫定义:可见即可爬 /2 安装resquests模块 正确路径下输入 pip install requests /3 用requests发送get请求 import requests # res是响应对象 就是http响应 python包装成了对象(响应头 ......
bootstrap参考网站总结
# bootstrap参考网站总结 # 【一】官方文档 > 总官网:https://www.bootcss.com/ > Bootstrap v3:https://v3.bootcss.com/ # 【二】图标样式 > https://fontawesome.com.cn/ # 【三】弹框样式 > ......