爬虫request网站
Python错误:requests请求设置verify=False时日志中有warning信息
问题描述: 在requests做请求的时候,为了避免ssl认证,可以将verify=False,但是这么设置会带来一个问题,日志中会有大量的warning信息, 如下面: D:\Program Files\Python\lib\site-packages\urllib3\connectionpool ......
几种在线数据透视表网站
1、 Tableau免费版本 注意数据源导入只显示100行 可以处理excel 表格 网站地址 https://public.tableau.com/newWorkbook/af886a65-13bd-495c-a9c2-7c8b61e117c1#1 2、redash 免费版本支持数据库,excel ......
【python爬虫案例】用python爬豆瓣读书TOP250排行榜!
[toc] # 一、爬虫对象-豆瓣读书TOP250 今天我们分享一期python爬虫案例讲解。爬取对象是,豆瓣读书TOP250排行榜数据: https://book.douban.com/top250 : public class Hello { @Autowired HttpServletRequest request; //这里可以获取到request } 2.在web.xml中配置一个监听: <listener> <listener-class> org.sp ......
哪个爬虫库用的最多?
在Python中,最常用的爬虫库是requests和BeautifulSoup。requests库用于发送HTTP请求和处理响应,而BeautifulSoup库用于解析HTML文档。这两个库通常结合使用,用于爬取网页内容并提取所需的数据。其他常用的爬虫库还包括Scrapy、Selenium等。 常用 ......
盘点一个Python网络爬虫的问题
大家好,我是皮皮。 ### 一、前言 前几天在Python白银群【大侠】问了一个`Python`网络爬虫的问题,这里拿出来给大家分享下。 
django网站自带CSRF校验,所以jmeter直接请求时会出现校验不通过的情况 ### 一、CSRF校验 CSRF是指跨站请求伪造,CSRF攻击的流程大概是我们登录网站A后存在本地的cookie,之后打开了另一个危险网站B,这个网站B使用本地cookie向网站A发起请求(该请求不是用户主动发起, ......
2023.6.28 - 关于网站的字体引入
在字体使用之前导入样式 ```css @font-face { font-family: 'YouSheBiaoTiHei'; src: url('@/assets/font/YouSheBiaoTiHei.woff2') format('woff2'); } ``` 其中`format('woff ......
代理软件打开后,不能访问国内网站的解决方案,例如不能访问百度,解决方案:关掉系统代理
代理软件打开后,不能访问国内网站的解决方案,例如不能访问百度,解决方案:关掉系统代理 按win键 输入 代理 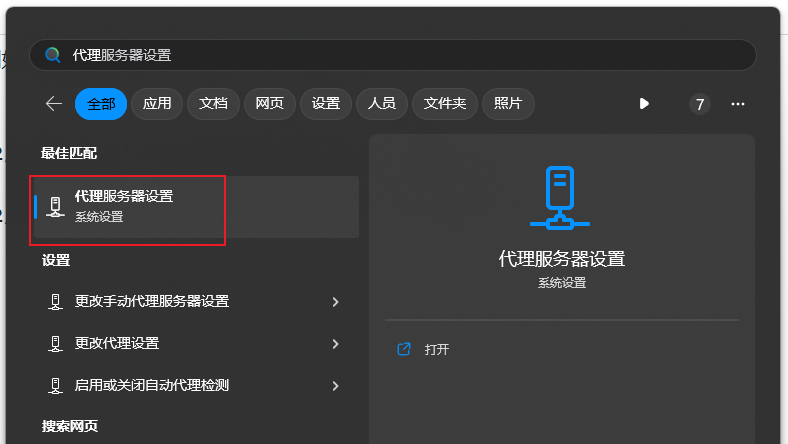  retries = Retry(total=3, backoff_factor=1) ses ......
科普 涨知识类 网站合集大汇总!【暑期熊孩子必备】
科普 涨知识类 网站合集大汇总!【暑期熊孩子必备】【暑期熊孩子必备】各类有趣又能涨知识的站点,希望大家可以在这个信息泛滥的时代学到一点属于自己的东西,也可以给自己的孩子用啊。知识科普微科普 https://www.wkepu.com/知道日报https://zhidao.baidu.com/生物谷h ......
Linux系统怎么添加一个桌面快捷方式链接到网站
Linux系统需要添加一个桌面快捷方式链接到网站可以编辑在桌面编辑文档 > 注意:文件需要以desktop为后缀 index.desktop 内容如下 ``` [Desktop Entry] Encoding=UTF-8 Name=OutLook Type=Application Icon=/hom ......
如何看待低级爬虫与高级爬虫?
爬虫之所以分为高级和低级,主要是基于其功能、复杂性和灵活性的差异。根据我总结大概有下面几点原因: 功能和复杂性:高级爬虫通常提供更多功能和扩展性,包括处理复杂页面结构、模拟用户操作、解析和清洗数据等。它们解决了开发者在处理复杂任务时遇到的挑战。低级爬虫则更简单,包含基础的爬取功能,适用于简单任务和入 ......
拥有完整产品栈的界面组件 Telerik,将种子实验室网站研发时长缩短 40%!
SoDak实验室研发工程师 Baszler: “我们的实验室主要是从事农业种子检测的,主要为北美知名的种子生产公司服务。除了主营的农业种子测试外,我们还经常需要邀请客户或者潜在客户进行线上交流,所以这就要求能有一个稳定的平台,帮助实验室员工高效完成更多的操作,客户还能全程参与提问回答等。” 该实验室 ......
会网络爬虫能干什么?
网络爬虫是一种自动化程序,用于浏览互联网并从网页中获取数据。它可以执行以下任务: 数据采集:网络爬虫可以访问网站,并从中提取所需的数据,例如新闻文章、产品信息、用户评论等。这些数据可以用于各种目的,如市场调研、数据分析、内容聚合等。 搜索引擎索引:搜索引擎使用爬虫来抓取网页,并将其加入搜索引擎的索引 ......
[scrapy]一个简单的scrapy爬虫demo
# 一个简单的scrapy爬虫demo ## 爬取豆瓣top250的电影名称+电影口号 使用到持久化流程: * 爬虫文件爬取到数据后,需要将数据封装到items对象中。 * 使用yield关键字将items对象提交给pipelines管道进行持久化操作。 * settings.py配置文件中开启管道 ......
AI绘画关键词Prompt:分享一些质量比较高的StableDiffusion(SD)关键词网站
**今天向大家推荐一些SD(StableDiffusion)高质量的** **关键词** **网站。这些网站的质量可靠,能为大家在创建** **AI** **绘画时提供有效的参考。以下是六个推荐的网站,优缺点分析。** **有几个质量还算是挺高的。大家可以参考一下结合使用~** 1. 网站链接:ht ......
has been blocked by CORS policy: The request client is not a secure context and the resource is ...
该报错原因为:Chrome浏览器禁止外部请求访问本地,被CORS策略阻止解决方案:1、打开chrome的设置: chrome://flags/#block-insecure-private-network-requests2、将 Block insecure private network requ ......
elementUI中upload自定义上传行为 http-request属性
需求是上传一个xlsx后台处理完再返回xlsx流upload 请求需要添加responseType: 'blob' 属性所有要扩展一下 若依项目扩展elementUI中upload自定义上传行为 http-request属性 ``` 将文件拖到此处,或点击上传 仅允许导入xls、xlsx格式文件。 ......
网站配置https后在win7系统 IE浏览器中无法打开问题处理
主要配置文件: ``` server { listen 443 ssl; server_name www.example.com; ssl_certificate /usr/local/nginx_server/ssl_key/example.com.pem; ssl_certificate_key ......
解决python中requests请求时报错:UnicodeEncodeError: ‘latin-1‘ codec can‘t encode character
当request请求中,带有中文,可能引发报错:  UnicodeEncodeError: 'latin-1' c ......
Python爬虫笔记
爬虫分为四个步骤,首先获取数据,然后解析数据,再提取数据,最后是存储数据 ```python import requests #首先引入requests库 res=requests.get('URL')#向服务器发送了一个请求,把服务器响应结果赋给res,为response对象 res.encodi ......
Nginx配置https网站访问第三方节点的http资源
https网站无法直接下载http网站的文件。解决思路有以下几种情况:1.两个网站都同时改为http或https。2.通过nginx转发。3.通过后端java代码获取对方网站的文件流然后把流返回给前端 本文介绍如果通过nginx转发访问http网站 配置规则一: location /asset/ { ......
requests 请求网页乱码
一般情况下,每个网页有自己的编码,在使用 requests 请求对应网页时,如果遇到中文编码的问题,大多数情况下直接显式指定 encoding 就可以了,但是今天遇到一个网站,还真是怎么指定都不行:https://www.medchemexpress.cn/ 以下所列的参考文档可能能解决编码问题,所 ......
爬虫:爬到的数据存到mysql中、爬虫和下载中间件、加代理,cookie、header、加入selenium、集成selenium、==去重规则源码分析(布隆过滤器)、布隆过滤器、scrapy-redis实现分布式爬虫
[toc] ### 爬到的数据存到mysql中 ```python class FirstscrapyMySqlPipeline: def open_spider(self, spider): print('我开了') self.conn = pymysql.connect( user='root' ......
爬虫:scrapy架构介绍、scrapy解析数据、settings相关配置,提高爬取效率、持久化方案、全站爬取cnblogs文章
[toc] ### scrapy架构介绍 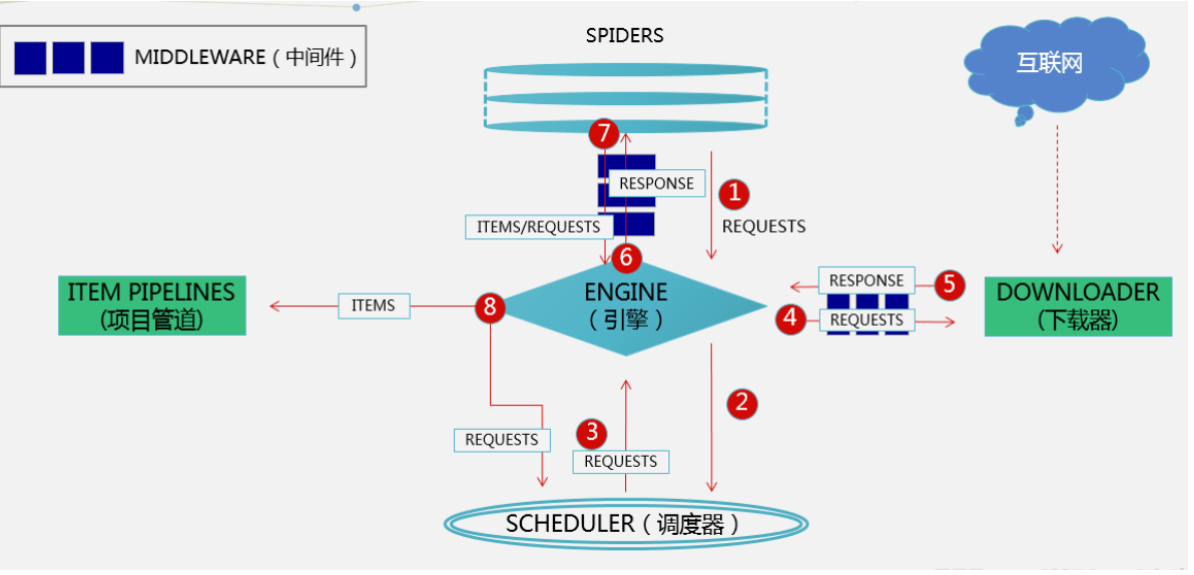 ```python # 引擎(EGINE) 引擎负责控制系统所 ......
如何利用python做爬虫?
Python爬虫在许多情况下是非常有用的,爬虫可以帮助自动化地从互联网上获取大量数据。这些数据可以是产品信息、新闻文章、社交媒体内容、股票数据等通过爬虫可以减少人工收集和整理数据的工作量,提高效率。在软件开发中,可以使用爬虫来进行自动化的功能测试、性能测试或页面链接检查等。 正常做爬虫都是有一定的模 ......