emr-hive openldap hive emr
hive-拉链表
**工作中的拉链表是使用spark程序开发的,因为一些业务需求单纯使用sql解决不了,以下是使用纯sql写的拉链表**拉链表是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史。**记录一个事物从开始,一直到当前状态的所有变化的信息。**下面就是一张拉链表,存储的是用户的最 ......
Flink-读Kafka写Hive表
1. 目标 使用Flink读取Kafka数据并实时写入Hive表。 2. 环境配置 EMR环境:Hadoop 3.3.3, Hive 3.1.3, Flink 1.16.0 根据官网描述: https://nightlies.apache.org/flink/flink-docs-release-1 ......
Hive LAG函数分析
含义:LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值 第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL) https://blog.csdn.net/weixin_43291055/arti ......
hive-四种排序
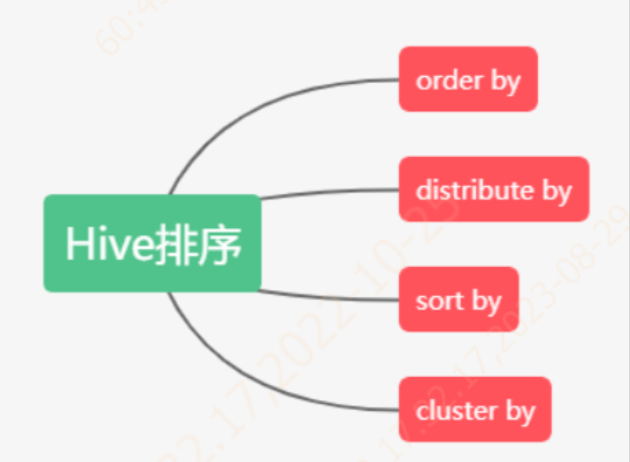 #### 数据准备 ```plsql 2008 32.0 2008 21.0 2008 31.5 2008 17. ......
hive-表的操作
### 创建表 create table语句遵从sql语法习惯,只不过Hive的语法更灵活。例如,可以定义表的数据文件存储位置,使用的存储格式等。 ```plsql create table if not exists test.user1( name string comment 'name', ......
hive-同比环比
HIVE-同比环比 定义 详情: (1)同比:本期与同期做对比。(2)环比:本期与上期做对比。 同比:通常是指今年第n月与去年第n月比。同比发展速度主要是为了消除季节变动的影响,用以说明本期发展水平与去年同期发展水平对比而达到的相对发展速度。常用于分析数据的长期趋势。环比:通常是指表示连续2个单位周 ......
hive函数
运算函数 1、取整函数: round 语法: round(double a) 返回值: BIGINT 说明: 返回double类型的整数值部分 (遵循四舍五入) hive> select round(3.1415926) from iteblog; 3 hive> select round(3.5) ......
技术实践|Hive数据迁移干货分享
导语 Hive是基于Hadoop构建的一套数据仓库分析系统,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能。它的优点是可以通过类SQL语句快速实现简单的MapReduce统计,不用再开发专门的MapReduce应用程序,从而降低学习成本,十分适合对数据仓库进行统计分析。 近几年 ......
Spring Boot集成Mybatis-plus+hive
运行环境 jdk1.8 springboot:2.7.15 1.在pom.xml文件中加入 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version ......
hive SQL案例
上个月用户连续n天登录天数 用户登录记录表user_login,包括用户id(user_id)、日期(login_date) user_id login_date 12333256 2021-01-03 84272916 2021-01-03 94038271 2021-01-02 20193401 ......
Hive 刷题——银行可以支付监测
场景说明 有一个支付流水表,关键字段:用户,交易时间,交易金额,现在规定:两个小时内交易此时大于2且交易总结金大于100000的用户为可疑用户,现在需要使用HiveSQL 进行监测 数据准备 CREATE TABLE transfer_log ( log_id INTEGER, log_ts TIM ......
Hive服务部署相关步骤
# 一、hiveserver2服务部署 # 1、配置hadoop下面的core-site.xml文件 进入到相应的目录下: ``` cd /root/software/hadoop-3.0.0/etc/hadoop ``` 编辑core-site.xml文件,将下面的语句补充到里面: ``` had ......
spingboot集成hive
因为开学要考就是把数据库换成hive那些做个web网站,所有提前做个小demo测试下。 首先呢就是pom文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns ......
hive整个服务启动流程
首先是 start-all.sh 然后打开历史服务器: mapred --daemon start historyserver 最后首先启动metastore服务,然后启动hiveserver2服务 nohup bin/hive --service metastore >> logs/metasto ......
org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!问题的解决
# 问题描述 上次还是初始化很快,这次直接出错,我觉得可能是已经初始化一次的原因;  # 问题解决 进入到mysql ......
Hive执行计划详解
## 什么是Hive SQL执行计划 Hive SQL执行计划描绘了SQL实际执行的整体轮廓,即**SQL转化为对应计算引擎的执行逻辑**;毫无疑问,这一块对于Hive SQL的优化是非常重要的。 Hive SQL早期是基于规则的方式生成执行计划,在Hive 0.14及之后,集成了Apache Ca ......
基于Hive数仓实现需求开发
# 1、建库建表与加载数据  上传到HDFS,即加载数据,可以使用命令行进行上传,还可以直接在网页里面进行上传; 在D ......
Hive相关学习
# 1、服务启动  ,得到最近一次价格的涨幅情况,并按照涨幅升序排序。 结果如下: sku_id<string>(商品id)price_change<decimal(16,2)>(涨幅) 8 -200.00 9 -100.00 2 -70. ......
8.14-8.20学习总结博客五:Hive进阶与复杂查询
博客题目:学习总结五:Hive进阶与复杂查询实践内容概要:学习Hive进阶的使用方法,包括复杂查询、数据转换和性能优化等方面的知识。学习资源:推荐的Hive进阶教程、实践案例和性能优化技巧。实践内容:通过编写复杂的Hive查询语句,探索Hive的高级功能和性能优化方法,并分享实践中的挑战和解决方案。 ......
MYSQL与Hive配置的相关步骤
# 1、配置元数据到MYSQL #### 1、新建Hive元数据库 登录Mysql: ``` mysql -uroot -p //不加分号 ```  使用Hive处理数据的好处: 中查询在相同时刻,多地登陆(ip_address不同)的用户 题目需求 从登录明细表(user_login_detail)中查询在相同时刻,多地登陆(ip_address不同)的用户 期望结果如下: user_id<string>(用户id ......
HIVE带中括号的列名取数
某次取数,某表中有奇怪的字段名:pointchange_ygz_[yyyy],带了个中插号,用简单查询出错 select pointchange_ygz_[yyyy] as p from t 出错信息: Error while compiling statement: FAILED: Semanti ......
Amazon EMR Hudi 性能调优——Clustering
随着数据体量的日益增长,人们对 Hudi 的查询性能也提出更多要求,除了 Parquet 存储格式本来的性能优势之外,还希望 Hudi 能够提供更多的性能优化的技术途径,尤其当对 Hudi 表进行高并发的写入,产生了大量的小文件之后,又需要使用 Presto/Trino 对 Hudi 表进行高吞吐的 ......
Hive SQL 的 ntile 分组切片函数
Hive SQL 的 ntile 函数用于将分组数据按照顺序切分成n组,并返回当前切片值。如果切片不均匀,默认增加第一个切片的分布。它把有序的数据集合「平均分配」到指定的数量(n)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差 1。 语法 Hi ......
[42000][3] Error while processing statement: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask.
[42000][3] Error while processing statement: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job fai ......