spark-hive spark hive
技术实践|Hive数据迁移干货分享
导语 Hive是基于Hadoop构建的一套数据仓库分析系统,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能。它的优点是可以通过类SQL语句快速实现简单的MapReduce统计,不用再开发专门的MapReduce应用程序,从而降低学习成本,十分适合对数据仓库进行统计分析。 近几年 ......
Spring Boot集成Mybatis-plus+hive
运行环境 jdk1.8 springboot:2.7.15 1.在pom.xml文件中加入 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version ......
hive SQL案例
上个月用户连续n天登录天数 用户登录记录表user_login,包括用户id(user_id)、日期(login_date) user_id login_date 12333256 2021-01-03 84272916 2021-01-03 94038271 2021-01-02 20193401 ......
8.21-8.27学习总结博客七:Spark机器学习与实时处理
博客题目:学习总结七:Spark机器学习与实时处理入门内容概要:学习使用Spark进行机器学习和实时数据处理的基本知识,了解Spark的机器学习库和实时处理框架。学习资源:推荐的Spark机器学习和实时处理教程、案例和学习资源。实践内容:通过编写Spark应用程序,实践使用Spark进行机器学习和实 ......
Spark任务提交到Yarn状态一直是Accepted
## 现象 今天提交 Spark 任务到 Yarn 集群,但是任务状态一直是 Accepted: ``` 23/08/25 14:59:55 INFO Client: Application report for application_1692971614101_0018 (state: ACCE ......
Hadoop 和 Spark 简介
# Hadoop 和 Spark 简介 Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop 过去一直是大数据的经典解决方案,它包含两个部分:Hadoop HDFS 和 Ha ......
Hive 刷题——银行可以支付监测
场景说明 有一个支付流水表,关键字段:用户,交易时间,交易金额,现在规定:两个小时内交易此时大于2且交易总结金大于100000的用户为可疑用户,现在需要使用HiveSQL 进行监测 数据准备 CREATE TABLE transfer_log ( log_id INTEGER, log_ts TIM ......
Hive服务部署相关步骤
# 一、hiveserver2服务部署 # 1、配置hadoop下面的core-site.xml文件 进入到相应的目录下: ``` cd /root/software/hadoop-3.0.0/etc/hadoop ``` 编辑core-site.xml文件,将下面的语句补充到里面: ``` had ......
spingboot集成hive
因为开学要考就是把数据库换成hive那些做个web网站,所有提前做个小demo测试下。 首先呢就是pom文件 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns ......
hive整个服务启动流程
首先是 start-all.sh 然后打开历史服务器: mapred --daemon start historyserver 最后首先启动metastore服务,然后启动hiveserver2服务 nohup bin/hive --service metastore >> logs/metasto ......
org.apache.hadoop.hive.metastore.HiveMetaException: Schema initialization FAILED! Metastore state would be inconsistent !!问题的解决
# 问题描述 上次还是初始化很快,这次直接出错,我觉得可能是已经初始化一次的原因; 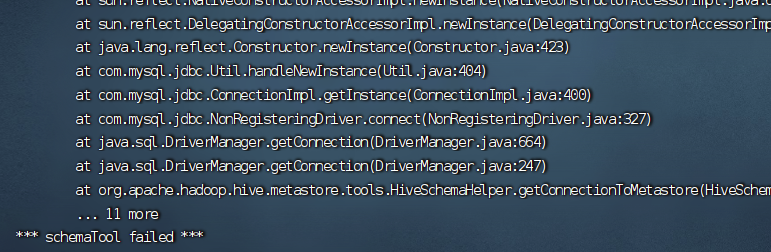 # 问题解决 进入到mysql ......
apache spark connect 试用
spark connect 3.4 开始就支持了connect 模式,3.4.1 比较稳定了 connect server 启动 实际上就是一个spark 引用,通过spark_submit 提交到spark 环境中 启动 ./sbin/start-connect-server.sh --packa ......
Spark RDD惰性计算的自主优化
原创/朱季谦 RDD(弹性分布式数据集)中的数据就如final定义一般,只可读而无法修改,若要对RDD进行转换或操作,那就需要创建一个新的RDD来保存结果。故而就需要用到转换和行动的算子。 Spark运行是惰性的,在RDD转换阶段,只会记录该转换逻辑而不会执行,只有在遇到行动算子时,才会触发真正的运 ......
Hive执行计划详解
## 什么是Hive SQL执行计划 Hive SQL执行计划描绘了SQL实际执行的整体轮廓,即**SQL转化为对应计算引擎的执行逻辑**;毫无疑问,这一块对于Hive SQL的优化是非常重要的。 Hive SQL早期是基于规则的方式生成执行计划,在Hive 0.14及之后,集成了Apache Ca ......
基于Hive数仓实现需求开发
# 1、建库建表与加载数据  上传到HDFS,即加载数据,可以使用命令行进行上传,还可以直接在网页里面进行上传; 在D ......
spark on k8s 开发部署简单实践
实际上就是一个简单的实践,方便参考,对于开发以及运行,集成ci/cd 以及dophinscheduler 任务调度为了方便开发的spark 应用共享以及使用基于s3 进行文件存储(当然dophinscheduler 也是支持自己的资源库的) 参考图 玩法说明 基于gitlab 进行代码管理,通过ci ......
Hive相关学习
# 1、服务启动  叫做弹性分布式数据集,是 Spark 中最基本的数据 处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行 计算的集合。 ### 一、RDD的两种创建方式 1. ......
Spark安装的配置相关步骤
# 1、Spark下载地址:https://archive.apache.org/dist/spark/ 选择自己适合的版本:  S ......
Hive 刷题——查看每件商品的售价涨幅情况
题目描述 从商品价格变更明细表(sku_price_modify_detail),得到最近一次价格的涨幅情况,并按照涨幅升序排序。 结果如下: sku_id<string>(商品id)price_change<decimal(16,2)>(涨幅) 8 -200.00 9 -100.00 2 -70. ......
8.14-8.20学习总结博客五:Hive进阶与复杂查询
博客题目:学习总结五:Hive进阶与复杂查询实践内容概要:学习Hive进阶的使用方法,包括复杂查询、数据转换和性能优化等方面的知识。学习资源:推荐的Hive进阶教程、实践案例和性能优化技巧。实践内容:通过编写复杂的Hive查询语句,探索Hive的高级功能和性能优化方法,并分享实践中的挑战和解决方案。 ......
MYSQL与Hive配置的相关步骤
# 1、配置元数据到MYSQL #### 1、新建Hive元数据库 登录Mysql: ``` mysql -uroot -p //不加分号 ```  使用Hive处理数据的好处: ,这些内置解析器不支持递 ......
spark中decode函数
decode函数 decode(bin, charset) - 使用第二个参数字符集解码第一个参数。 decode(expr, search, result [, search, result ] ... [, default]) - 解码比较 expr 对每个搜索值一一进行。如果 expr 等于搜 ......
HIve 刷题——同一时刻异地登录问题
题目描述 从登录明细表(user_login_detail)中查询在相同时刻,多地登陆(ip_address不同)的用户 题目需求 从登录明细表(user_login_detail)中查询在相同时刻,多地登陆(ip_address不同)的用户 期望结果如下: user_id<string>(用户id ......