在多线程编程中,一个著名的问题是生产者-消费者问题 (Producer Consumer Problem, PC Problem)。
对于这类问题,通过信号量加锁 (https://www.cnblogs.com/sinkinben/p/14087750.html) 来设计 RingBuffer 是十分容易实现的,但欠缺性能。
考虑一个特殊的场景,生产者和消费者均只有一个 (Single Producer Single Consumer, SPSC),在这种情况下,我们可以设计一个无锁队列来解决 PC 问题。
0. Background
考虑以下场景:在一个计算密集型 (Computing Intensive) 和延迟敏感的 for 循环当中,每次循环结束,需要打印当前的迭代次数以及计算结果。
void matrix_compute()
{
for (i = 0 to n)
{
// code of computing
...
// print i and result of computing
std::cout << ...
}
}
在这种情况下,如果使用简单的 std::cout 输出,由于 I/O 的性质,将会造成严重的延迟 (Latency)。
一个直观的解决办法是:将 Log 封装为一个字符串,传递给其他线程,让其他线程打印该字符串,实现异步的 Logging 。
1. Lock-free SPSC Queue
此处使用一个 RingBuffer 来实现队列。
由于是 SPSC 型的队列,队列头部 head 只会被 Consumer 写入,队列尾部 tail 只会被 Producer 写入,所以 SPSC Queue 可以是无锁的,但需要保证写入的原子性。
template <class T> class spsc_queue
{
private:
std::vector<T> m_buffer;
std::atomic<size_t> m_head;
std::atomic<size_t> m_tail;
public:
spsc_queue(size_t capacity) : m_buffer(capacity + 1), m_head(0), m_tail(0) {}
inline bool enqueue(const T &item);
inline bool dequeue(T &item);
};
对于一个 RingBuffer 而言,判空与判满的方法如下:
- Empty 的条件:
head == tail - Full 的条件:
(tail + 1) % N == head
因此,enqueue 和 dequeue 可以是以下的实现:
inline bool enqueue(const T &item)
{
const size_t tail = m_tail.load(std::memory_order_relaxed);
const size_t next = (tail + 1) % m_buffer.size();
if (next == m_head.load(std::memory_order_acquire))
return false;
m_buffer[tail] = item;
m_tail.store(next, std::memory_order_release);
return true;
}
inline bool dequeue(T &item)
{
const size_t head = m_head.load(std::memory_order_relaxed);
if (head == m_tail.load(std::memory_order_acquire))
return false;
item = m_buffer[head];
const size_t next = (head + 1) % m_buffer.size();
m_head.store(next, std::memory_order_release);
return true;
}
std::memory_order 的使用说明:https://en.cppreference.com/w/cpp/atomic/memory_order
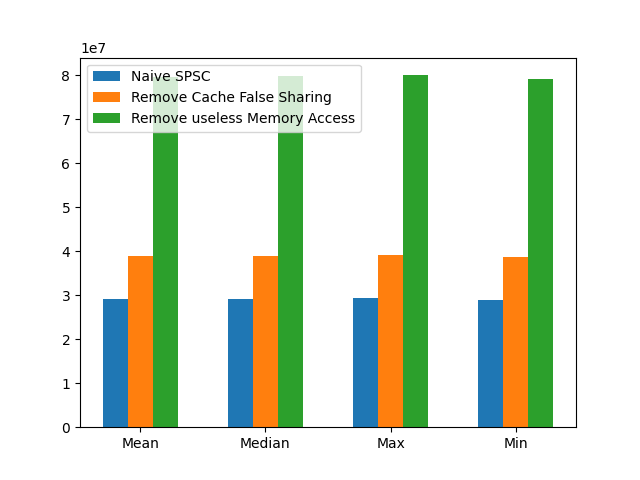
Benchmark 计算 SPSC Queue 的吞吐量:
Mean: 29,158,897.200000 elements/s
Median: 29,178,822.000000 elements/s
Max: 29,315,199 elements/s
Min: 28,995,515 elements/s
Benchmark 的计算方法为:
- Producer 和 Consumer 分别执行
1e8次enqueue和dequeue,计算队列为空所耗费的总时间t,1e8 / t即为吞吐量。 - 上述过程执行 10 次,最终计算
mean, median, min, max的值。
2. Remove cache false sharing
什么是 Cache False Sharing? 参考 Architecture of Modern CPU 的 Exercise 一节。
int *a = new int[1024];
void worker(int idx)
{
for (int j = 0; j < 1e9; j++)
a[idx] = a[idx] + 1;
}
考虑以下程序:
- P1: 开启 2 线程,执行
worker(0), worker(1) - P2: 开启 2 线程,执行
worker(0), worker(16)
P2 的执行速度会比 P1 快,现代 CPU 的 Cache Line 大小一般为 64 字节,由于 a[0], a[1] 位于同一个 CPU Core 的同一个 Cache Line,每次写入都会带来数据竞争 (Data Race) ,触发缓存和内存的同步(参考 MESI 协议),而 a[0], a[16] 之间相差了 64 字节,不在同一个 Cache Line,所以避免了这个问题。
所以,对于上述的 SPSC Queue,可以进行以下改进:
template <class T>
class spsc_queue
{
private:
std::vector<T> m_buffer;
alignas(64) std::atomic<size_t> m_head;
alignas(64) std::atomic<size_t> m_tail;
};
这里的 alignas(64) 实际上改为 std::hardware_constructive_interference_size 更加合理,因为 Cache Line 的大小取决于具体 CPU 硬件的实现,并不总是为 64 字节。
#ifdef __cpp_lib_hardware_interference_size
using std::hardware_constructive_interference_size;
using std::hardware_destructive_interference_size;
#else
// 64 bytes on x86-64 │ L1_CACHE_BYTES │ L1_CACHE_SHIFT │ __cacheline_aligned │ ...
constexpr std::size_t hardware_constructive_interference_size = 64;
constexpr std::size_t hardware_destructive_interference_size = 64;
#endif
Benchmark 结果:
Mean: 38,993,940.400000 elements/s
Median: 39,027,123.000000 elements/s
Max: 39,253,946 elements/s
Min: 38,624,197 elements/s
3. Remove useless memory access
在使用 spsc_queue 的时候,通常会有以下形式的代码:
spsc_queue sq(1024);
// Producer keep spinning
int x = 233;
while (!sq.enqueue(x)) {}
而在 dequeue/enqueue 中,存在判空/判满的代码:
inline bool enqueue(const T &item)
{
const size_t tail = m_tail.load(std::memory_order_relaxed);
const size_t next = (tail + 1) % m_buffer.size();
if (next == m_head.load(std::memory_order_acquire))
return false;
// ...
}
每次执行 m_head.load,Producer 线程的 CPU 都会访问一次 m_head 所在的内存,但实际上触发该条件的概率较小(因为在实际的场景下, Producer/Consumer 都是计算密集型,否则根本不需要无锁的数据结构)。在判空/判满的时候,可以去 “离 CPU 更近” 的 Cache 去获取 m_head 的值。
template <class T>
class spsc_queue
{
private:
std::vector<T> m_buffer;
alignas(hardware_constructive_interference_size) std::atomic<size_t> m_head;
alignas(hardware_constructive_interference_size) std::atomic<size_t> m_tail;
alignas(hardware_constructive_interference_size) size_t cached_head;
alignas(hardware_constructive_interference_size) size_t cached_tail;
};
inline bool enqueue(const T &item)
{
const size_t tail = m_tail.load(std::memory_order_relaxed);
const size_t next = (tail + 1) % m_buffer.size();
if (next == cached_head)
{
cached_head = m_head.load(std::memory_order_acquire);
if (next == cached_head)
return false;
}
// ...
}
Benchmark 结果:
Mean: 79,740,671.300000 elements/s
Median: 79,838,314.000000 elements/s
Max: 80,044,793 elements/s
Min: 79,241,180 elements/s
4. Summary
Github: https://github.com/sinkinben/lock-free-queue
3 个版本的 spsc_queue 的吞吐量比较(均值,中位数,最大值,最小值)。在优化 Cache False Sharing 和优先从 Cache 读取 head, tail 之后,可得到 x2 的提升。