Http:超文本传输协议
Https:安全的http
首先引入request库:pip install requests
先F12打开页面检查,在network(网络)里面,然后刷新页面,会发先有个请求文档,点击并观察它:
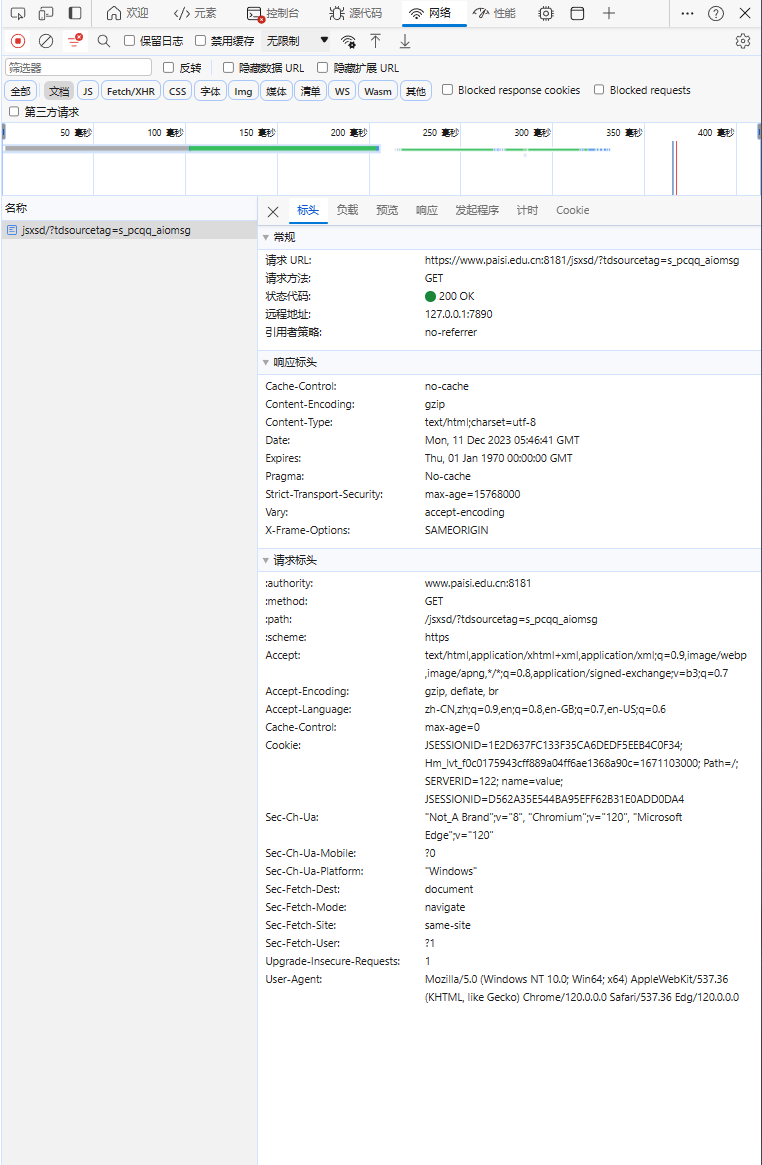
在常规里面可以看到请求地址为https://www.paisi.edu.cn:8181/jsxsd/?tdsourcetag=s_pcqq_aiomsg,将它复制到新页面确实https://www.paisi.edu.cn:8181/jsxsd,我们需要的url就是这个去掉?后面的,还观察到请求方法为GET。
再观察请求标头(header),前面带 : 的和Sec开头的可以忽略这里用不到,将从Accept到Cache-Control的和Upgrade-Insecure-Requests,User-Agent的内容全部复制,然后在python里新建一个字典:
header = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*,"
"q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip,deflate,br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Cache-Control": "max-age=0",
"Content-Length": "106",
"Content-Type": "application/x-www-form-urlencoded",
"Upgrade-Insecure-Requests": "1",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}然后得到url和header我们就可以去获取cookies,直接写一个获取cookies的方法:
import requests
ses=requests.session()
def get_login_cookies():
url= 'https://www.paisi.edu.cn:8181/jsxsd/'
ses.get(url=url,headers=headers)
cookies =ses.cookies.get_dict()
cookies = str(cookies).replace("{", '').replace("'", '').replace(":", '=').replace('}', '').replace(",", ";")
cookies = cookies.replace(" ", '')
return cookies然后就可以去模拟登录账号了
但是登录你得先有一个账号来获取登录的信息。这里我就随便拿一个账号举例了,先在网页里面登录,然后在网络检查找到登录的文档:
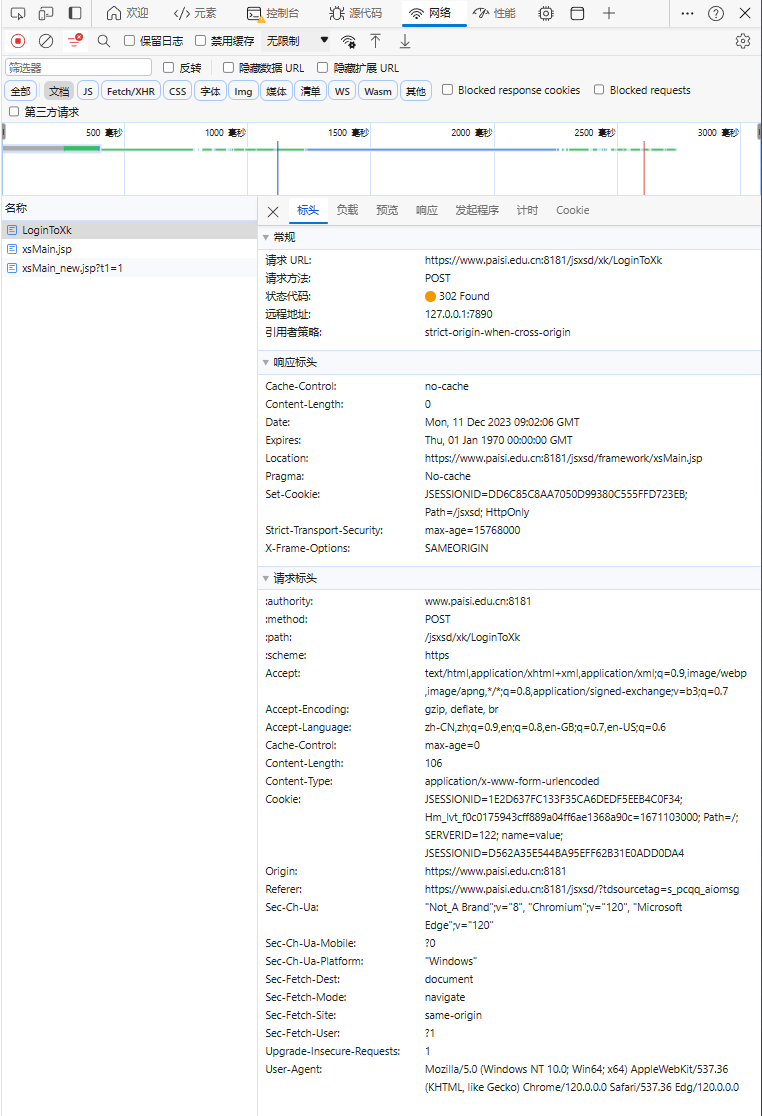

这里需要查看负载的内容,将负载的所有内容复制并定义一个字典(注意:这里的userPassword我隐藏了,网页也隐藏了,编写的时候也要写):
data = {
'userAccount': "2022126002", #学号
'userPassword': passoword, #密码
'encoded': encoded, #算法加密内容
'pwdstr1': '',
'pwdstr2': ''
}不同的网站需求都不一样
当我们再次检查请求标头的时候发现大多数跟刚刚登录网页的一样,所以直接用刚刚的请求头再加两个参数Orign和Referer就行,在定义一个方法为模拟登录账号,该方法需要携带刚刚获取的cookie参数:
def login(cookie):
url = 'https://www.paisi.edu.cn:8181/jsxsd/xk/LoginToXk'
header["Origin"] = "https://www.paisi.edu.cn:8181"
header["Referer"]= "https://www.paisi.edu.cn:8181/jsxs"
header["Cookie"]= cookie
msg = ses.post(url, headers=header, data=data, timeout=1000).text # 这个跳转
# print("cookies验证:"+str(msg))
return str(msg)现在我们的cookie就会被认为是已经登陆了的了。
然后就是获取课表了,在网页先查询下课表,然后像刚刚那样检查页面的网络信息,点击新增的查询课表文档:
跟刚刚的方法分析参数信息就行:(cookies为第一步登录网页获取的cookies,我只是将返回的数据定义下来了)
def get_class():
url="https://www.paisi.edu.cn:8181/jsxsd/xskb/xskb_list.do"
header["Referer"] = "https://www.paisi.edu.cn:8181/jsxsd/framework/xsMain.jsp"
header["Cookie"] = cookies
msg = ses.get(url=url,headers=header)
# print(str(msg))
# print(msg.text)
return msg.text这样就可以返回课表的html源码了。
但是如果我们想要的是课程的各项数据,可以使用BeauitifulSoup这个库。以我这个举例:
soup = BeautifulSoup(text,'html.parser')
all_classes = soup.findAll("div",attrs={"class": "kbcontent"})
for i in all_classes:
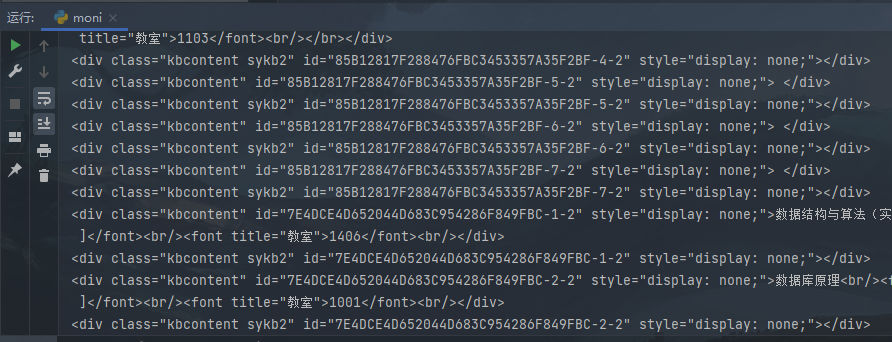
print(i)这里的意思就是先定义一个BeautifulSoup的参数,让他解析类型为html的,第二步则是获取html中标签为div的且class名为kbcontent的内容。运行出来就是这样:
还有种方法就是使用etree库也可以获取数据,这里就不介绍了。