此篇Survey是A Systematic Mapping Study in AIOps的后续研究
对于AIOPS中占比较高的Failure Management进行进一步的研究

Compared to traditional approaches, AIOps is:
• fast, because it reacts independently and automatically to real-time problems, without re- quiring long manual debugging and analysis sessions;
• efficient, because it takes advantage of the monitoring infrastructure holistically, removing data silos and improving issue visibility. By forecasting workload requirements and modeling request patterns, AIOps improves resource utilization, identifies performance bottlenecks, and reduces wastages. By relieving IT operators from investigation and repair burdens, AIOps enables in-house personnel to concentrate more effort on other tasks;
• effective, because it allocates computer resources proactively and can offer a large set of actionable insights for root-cause diagnosis, failure prevention, fault localization, recovery, and other O&M activities.
The term AIOps was originally coined by Gartner in 2017 [74], for which “AIOps platforms utilize big data, modern Machine Learning and other advanced analytics technolo- gies to directly and indirectly enhance IT operations.”
All these definitions share two common objectives: (1) enhance IT services for customers and (2) provide full visibility and understanding into the operational state of IT systems.
The most cited AIOps problems are anomaly detection [36, 75, 107, 129], root-cause analysis [17, 75, 96, 116], resource provisioning [36, 107, 116, 129], failure remediation [17, 96, 116], and failure prediction and prevention [17, 75, 79].
AIOPS相关综述,

论文总结出,对于算法评价标准度量的各种方法,
Mean-squared Error (MSE) 均方误差,最直观
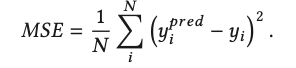
后续的度量方法基于这张表,

accuracy,准确性。所有Pre中,判断正确的比例
![]()
pricision,recall,精确度,召回率。判阳中,判断准确比例;所有阳中,被判断出的比例

false-positive rate (FPR, also called false alarm date) 假阳率。所有阴中,被误判成阳的比例

true-negative rate (TNR, or specificity) 真阴率。所有阴中,被正确判定为阴的比例
![]()
单纯的看P, R都有偏面,所以综合
F1-score (or F- score/F-measure)
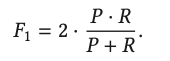
这里思路很清晰,FM分为主动avoidence和被动tolerance
主动avoidence,意味着在failure未发生前,分为predicting和preventive
被动tolerance,意味着在failure发生后,detection,RCA,remediation
当前主要的研究方向偏向被动,偏向发现问题分析问题,解决问题和闭环的研究比较少
Failure Management (FM) is the study of techniques deployed to minimize the appearance and impact of failures.
We differentiate between proactive (failure avoidance) and reactive (failure tolerance) approaches
Failure avoidance comprises any approach aiming to address failures in anticipation of their occurrence, either by predicting the appearance of errors based on the system state or by taking preventive actions to minimize their future incidence.
Failure avoidance is divided into failure prevention (Section 4.1) and online failure prediction (Section 4.2).
Failure tolerance techniques, however, deal with errors after their appearance to assist humans and improve mean-time-to-recovery (MTTR).
Failure tolerance includes failure detection (Section 4.3), root-cause analysis (Section 4.4), and remediation (Section 4.5).
The FM area with the highest number of contributions is failure detection (226, 33.7%), followed by root-cause analysis (179, 26.7%) and online failure prediction (177, 26.4%).
Failure prevention
目的是降低失败发生的概率和影响,分为静态(源码分析)和动态
Failure prevention mechanisms, tend to minimize the occurrence and impact of failures, by analyzing the configuration of the system, both in static aspects (like the source code) and dynamic aspects (e.g., the availability of computing resources in physical hosts).

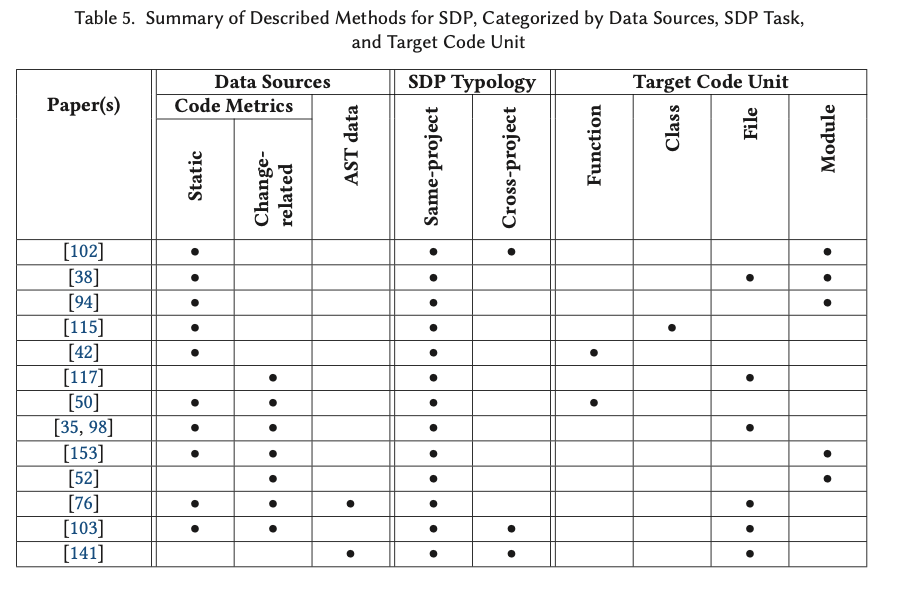
Software Defect Prediction.
计算代码存在bug的概率
SDP determines the probability of running into a software bug (or defect) within a functional unit of code (i.e., a function, a class, a file, or a module).
传统的方法,基于code metrics来构建defect predictor。
所以前期的研究主要在于用哪些metrics,基本是一些从源码手工构建的features,比如基于模块的图复杂度,读复杂度,基于OO的CK metrics,模块间的耦合度,甚至LOC
A traditional method to identify fault-prone(易于出错) software consists in constructing defect predictors from code metrics.
Code metrics are handcrafted features obtained directly from source code, which potentially have the power to predict fault proneness in software.
Over the last decades, different groups of code metrics have been proposed:
the original module-level metrics, designed during the 1970s for procedural languages, describing graph complexity (McCabe metrics [90]) and reading complexity (Halstead metrics [53]);
Chidamber and Kemerer [28] later defined a suite of metrics for object-oriented software on a class level, usually referred to as “CK metrics” (from the authors’ initials);
Briand et al. [16] have introduced coupling metrics as a measure of interconnection between software modules;
finally, the Lines-of-Code (LOC) metric is widely adopted across the research community.
研究方向后续又转换到,使用怎样的方法来构建defect-prone,defect-free的分类器
有基于SVM加高斯核的研究,有基于BN贝叶斯网络的研究
Attention is moved from the choice of metrics to the choice of learners: by applying decision trees and Naïve Bayes models, software modules are classified as defect-prone or defect-free.
研究提出,源码的变化也是软件faults的一个主要原因
所以有学者提出,要分成product measures和process measures,来量化the change history of a software project
A potential indication of the presence of software faults may also come from the change history of source code.
In particular, the code age and the number of previous defects can be indicative to estimate the presence of new bugs.
Graves et al. [52] divide software quality predictors into product measures (like code metrics) and process measures, which quantitatively describe the change history of a software project, advocating for the latter category (product measures are considered inconclusive from a correlation analysis).
In addition to introducing the benchmark SDP dataset AEEEM, D’Ambros et al. [35] compute several change-related metrics, such as the number of revisions, refactorings, and bug fixes per file, which are correlated with the number of future defects.
学者提出,传统的code metrics过于简单和依赖人工,提出使用源码的AST作为新的metrics。
A critique of traditional code metrics is that they are too handcrafted and simplistic. An alternative is to directly parse the source code using Abstract Syntax Trees (AST).
In their work, after parsing the code with ASTs, a Deep Belief Network (DBN) is trained to learn semantic features in an unsupervised fashion via stochastic first-order optimization.
比较有意思的是提出用CNN来对于AST进行抽象,学习出encoder,可以将AST转换成中间表示,再结合传统的code metrics进行整体的预测
Li et al. [76] explore Convolutional Neural Networks (CNN) for SDP.
During the parsing step, a subset of AST nodes corresponding to different types of semantic operations is extracted.
These tokens are mapped to numerical features using embeddings and fed into a 1D convolutional architecture,
which is used to learn intermediate representations of the input code, and later integrated with handcrafted features for the final prediction.
Fault Injection.
故意引入faults,来评估系统的fault tolerance水平
Fault injection is the deliberate introduction of faults into a target working system [5] to evaluate the level of fault tolerance reached.
Important definitions in fault injection are the set of injected faults or faultload (F);
the set of activations of faults in the system (A);
the set (R) of readouts from the system and the set (M) of measured values.
F and A model the injection procedure from the input, R and M from the output [5].
这种技术在分布式系统上用处更加明显,比如Netflix的Chaos Monkey
In a distributed computing environment, fault injection can also be applied at the cluster or datacenter scale,
for example, to randomly terminate operations at the instance level and stress test the resiliency of the distributed service under investigation.
This is the case with software tools such as Chaos Monkey and Kong by Netflix [13] or Facebook’s Project Storm [69].
Finally, fault injection techniques can be applied at the network level based on principles that are similar to the hardware and software level previously cited.
Software Aging and Rejuvenation.
老化,随着程序运行,逐渐累积的错误,比如内存泄露,数据碎片,锁未释放等
研究基本就是通过,拟合,回归的方法去预测系统风险
Software aging describes the process of accumulation of errors during the execution of a program that eventually results in terminal failures, such as hangs, crashes, or heavy performance degradations [49].
Known causes of software aging include memory leaks and bloats, unreleased file locks, data fragmentation, and numerical error accumulation [21].
Several Machine Learning techniques have been applied to predict the exhaustion of resources preemptively.
Garg et al. [49] estimate time-to-exhaustion of system resources, such as free memory, file and process table sizes, and used swap space, using instrumentation tools available under the UNIX operating system.
年轻化,清除内部的状态,比如GC
Software aging can be contrasted with software rejuvenation [57], a corrective measure where the execution of a piece of software is temporarily suspended to clean its internal state.
Software rejuvenation can be performed at the software and OS level. Common cleaning operations include garbage collection, flushing kernel tables, reinitializing internal data structures [136].
To this end, authors distinguish between periodic (or synchronous) and prediction-based (or asynchronous) rejuvenation policies, where the latter requires a prediction model for future software failures.
Checkpointing.
用算法选择不同的CP策略和CP调度问题
A concept linked to software rejuvenation is checkpointing, i.e., the continuous and preemptive process of saving the system state before the occurrence of a failure.
Similar to software rejuvenation, checkpointing tolerates failures by occasionally interrupting the execution of a program to take precautionary actions.
Different from software rejuvenation, during checkpointing the interruption period is used to save the internal state of the system to persistent storage.
In case a fatal failure occurs, the created checkpoint file can be used to resume the program and reduce failure overhead.
AI is used to model a faulty execution workload under different checkpointing strategies and select the most suitable strategy according to different objectives.
Again, checkpointing can be static or dynamic depending on the scheduling of checkpoints.
Online Failure Prediction
A prediction of failures on-the-fly allows one to be aware of future failures but also to know in advance the remaining useful to recovery, vital to timely deploy recovery and failover mechanisms.

Hardware Failure Prediction.
这个领域中,大部分的研究集中在硬盘的Failure Prediction,94年硬盘厂商就提出SMART技术,在实际的研究中,发现SMART features充分非必要,大量的硬盘fail前不一定有明显的SMART error signal
在后续的研究中,部分方向是如何补充SMART features,部分是如何基于SMART,使用不同的学习和分类方法。
In large-scale computing infrastructures, hardware reliability represents one of the most relevant practices to achieve service availability goals in distributed services.
Hard drives are the most replaced components inside large cloud computing systems (78%) and one of the dominant reasons for server failure [138].
Machines with a higher number of disks are also more prone to experience additional faults in a fixed time period.
This fact has led hard-drive manufacturers to adopt common self-monitoring technologies (such as Self-monitoring Analysis and Reporting Technology (SMART)) in their storage products since 1994 [100].
However, some SMART features were shown to correlate well with a higher failure rate.
However, SMART metrics were also shown to be likely insufficient for single-disk predictions, as the majority of failed drives did not manifest any SMART error signal before faults.
一个不同的思路将SMART数据作为事件序列,强调时间信息的重要性,这样的差异是可以使用隐马尔可夫,半马尔科夫来进行建模
Different from previous works [54, 101], Zhao et al. [164] treat SMART data as a time series, arguing for the importance of temporal information.
Their approach employs Hidden Markov and Semi-Markov Models (HMM/HSMM) to estimate the sequence of likely events from the disk metric observations, which are obtained from a dataset of approximately 300 disks .
基于滑动时间窗口的方法
Murray et al. [101] test the applicability of several Machine Learning methods using a sliding window approach, where the last n samples constitute the observation for predicting an imminent(迫在眉睫) failure.
基于RNN的方法,这个是之前基于马尔科夫方法的延续,
The same SMART dataset is used by Xu et al. in a paper [149] that introduces Recurrent Neural Networks (RNN) to hard drive failure prediction.
Similar to Reference [164], the method can analyze sequences directly and to model the long-term relationships takes advantage of the temporal dimension of the problem.
|Differently from previous approaches that apply binary classification, the model is trained to predict the health status of the disk, providing additional information on the remaining useful life of disks.
上面的方法都是离线训练,这里提出的方法可以动态的根据新的数据更新模型
To this end, Xiao et al. [148] propose the use of Online Random Forests, a model able to evolve and behave adaptively to the change in the data distribution via online labeling.
除了硬盘,也有基于其他设备的相关研究
其中对于用RNN预估系统主件剩余的使用周期的研究可以关注
Although most of the scientific interest is concentrated around disk failures, a minor group of contributions, focusing on failure prediction for other components, is present. Ma et al. [88] elevate the discussion on storage reliability to the level of RAID groups.
Costa et al. [33] investigate the occurrence of main-memory errors for HPC applications. They propose and evaluate methods for temporal and spatial correlation among memory failures.
Zhang et al. [161] deal with the problems of failure prediction and diagnosis in network switches.
Their method, based on system log history, proposes to extract templates from logs and correlate them with faulty behavior.
Zheng et al. [165] propose a method based on RNN to estimate the Remaining Useful Life of system components.
They argue that the temporal nature of sensor data justifies the use of long short-term memory (LSTM)-based RNNs, due to their ability to model long term-dependencies.
System Failure Prediction.
System失败是在软件层面的,基于log,metrices等作为输入
Instead of investigating the occurrence of physical component failures, future system availability can also be estimated through symptomatic evidence and dependency modeling assumptions at the software level.
Past approaches for system failure prediction are mostly based on the observation of logs, which constitute the most frequent data source, KPIs and hardware metrics, which are typically used in shorter prediction windows and are more frequently associated with the failure detection problem as well.
利用贝叶斯网络建模各种observed variables的关联性,从而detect SLO violations
Cohen et al. [31] investigate an approach based on Tree-augmented Bayesian Networks (TANs) to associate observed variables with abstract service states, forecast and detect SLO violations and failures in three-tiered Web services. The system is based on the observation of system metrics, such CPU time, disk reads, swap space, and KPI-related measures, like the number of served requests, all interdependently modeled (in addition to the dependent variable, the predicted state).
基于错误日志的事件序列来在线预测failures,这个有点意思
Salfner et al. [123] train HSMM for online prediction of failures in event sequences collected from error logs. One HSMM is trained on failing sequences, a second one on non-failing sequences.
基于自回归和ARIMA进行时序预测
Chalermarrewong et al. [23] propose a system availability prediction framework for datacenters, based on autoregressive models and fault-tree analysis.
Their autoregressive integrated moving average (ARIMA) model works on time series of workload and hardware metrics,
where thresholds are fixed to detect component-level symptoms (such as high CPU temperature, bad disk sectors, memory exhaustion), which also constitute the leaves of the fault tree.
基于log的方案
Fronza et al. [44] describe a failure prediction approach based on text-analysis of system logs and SVMs.
First, log files are parsed and encoded using a technique called Random Indexing, where for each operation inside a log line, index vectors are assigned to obtain a latent representation of the text.
Similarly, in Reference [160] RNNs are applied for failure prediction from logs.
The approach is composed of a clustering algorithm used to group similar logs, a pattern matcher used to identify common templates inside similar logs, a log feature extractor based on natural language process- ing, and a sequential neural network architecture based on LSTM cells, used to predict the failure status within the predictive period.
Failure Detection
开始讨论reactive(被动)failure management技术

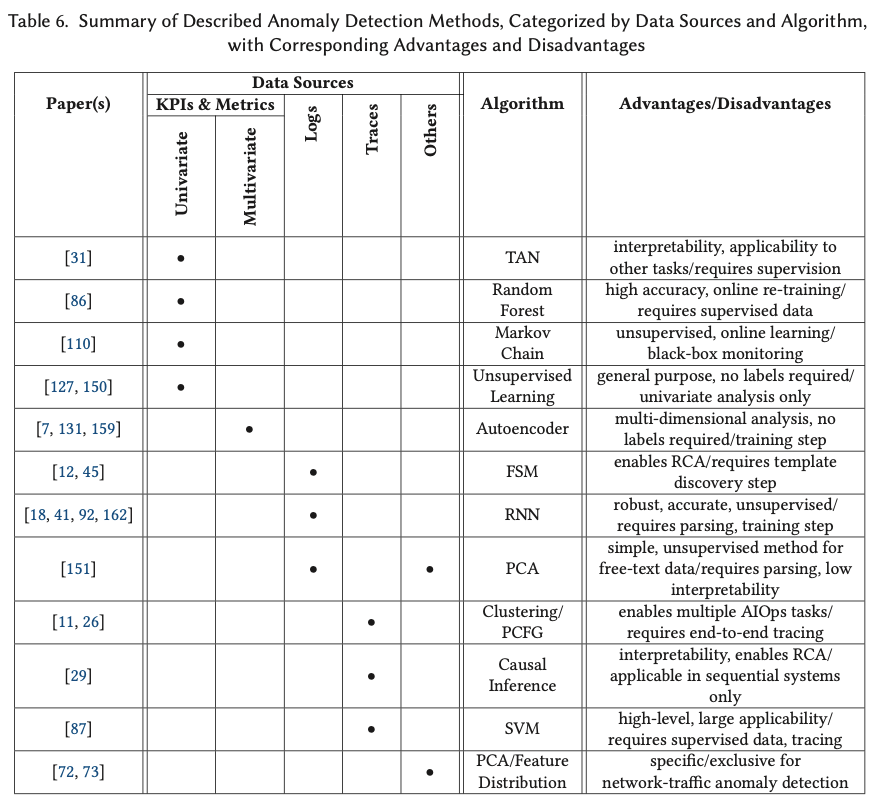
Anomaly Detection.
AD可以实现的前提假设
Anomaly Detection is applied in the AIOps context under the assumption that failures generate irregular behavior in IT systems (errors) across a set of measurable entities (or symptoms), such as KPIs, metrics, logs, or execution traces.
由于训练集很难收集,当前研究的方法都是无监督的,主要是聚类,降维,自编码
Because obtaining labeled examples is time-consuming, anomaly detection systems typically rely on unsupervised learning.
Three are the most prominent techniques used in such context: clustering [11, 127], dimensionality reduction [72, 151] and neural network autoencoders [7, 131, 150, 159].
At the network level, Lakhina et al. [72] monitor network links via SNMP data to detect and diagnose anomalies in network traffic.
The apply PCA on link flow measurements collected over time to separate traffic in normal and anomalous subspaces.
Several approaches apply unsupervised learning on univariate time series constructed from KPI and metric observations [127, 150]. The paper proposes to collect a variety of measures at the VM and physical machine level, including resource utilization, operating system variables, and application performance metrics. The paper then proposes three different unsupervised Machine Learning approaches for anomaly detection: k-nearest neighbors (k-NN), HMMs, and k-means clustering.
Donut [150] performs anomaly detection on seasonal KPI time series using deep Variational Autoencoders (VAE) and window sampling.
The most recent time-series approaches focus on multivariate anomaly detection using autoencoders [7, 131, 159].
虽然labeled 训练集不多,但是可以基于日志,对于系统执行模型和行为模型进行建模,帮助进行异常探测。
Although in the majority of cases real labeled samples are not available, it may be possible to obtain behavioral set of rules or an execution model for the system.
The model information becomes also very relevant when failures need to be diagnosed (see Section 4.4.2).
With the use of a behavioral model, different pattern-matching approaches can be developed.
For example, having access to a probabilistic context-free grammar (PCFG), which defines the likelihood of event chains to occur in sequential input, allows an anomaly detection algorithm to single out unlikely structures and detect anomalies.
More often, a behavioral model of the system is inferred from the past execution history, often expressed in the form of logs. An example of such a model is constituted by Finite State Machines (FSM) [12, 45].
RNN在基于日志的异常检测
基于日志的上下文,去预测后续的日志,和语言模型相同的思路
In recent years, RNN have been applied for log-based anomaly detection [18, 41, 92, 162]. Du et al.’s DeepLog [41] uses RNNs based on LSTM layers to learn patterns from logs and detect anomalies.
As in Fu et al. [45], log entries are initially mapped to corresponding log keys. Then, DeepLog predicts the probability distribution of the next log key from the observation of previous log keys, similar to a natural language model that predicts the next token from the observation of the rest of the sentence.
Brown et al. [18] also work on log-based anomaly detection, presenting an word-token RNN language model for raw logs based on five attention mechanisms (reaching AUCROC ≥ 0.963). The paper also proposes to analyze attention weights to provide statistical insights, un- derstand global behavior and improve decision making.
Internet Traffic Classification (ITC).
A task connected to network failure detection is Internet Traffic Classification (ITC).
ITC allows categorizing packets exchanged by a network system to identify network problems, to optimize resource provisioning and improve Quality-of- Service [43, 97].
Log Enhancement.
Another task connected to failure detection is log enhancement.
Its goal is to improve the quality and expressiveness of system logs, which are frequently used for detection and diagnosis tasks by IT operators and AIOps algorithms.
将是否要放置logging snippets转换成一个二元分类问题,基于信息增益的决策树
Zhu et al. [168] propose a logging suggestion tool, called LogAdvisor, to learn practical logging suggestions from existing log instances.
In code snippets, several structural, syntactical, and textual features are extracted and filtered based on information gain, from which a decision tree is later trained to suggest logging of snippets as a binary classification problem.
通过信息entropy来自动打日志,选择日志级别,提升日志效率
In Reference [163], an approach for automated placement of log printing statements (Log20) based on information theory is proposed. First, entropy is shown to be an informative measure for the placement of printing statements. Then, a greedy dynamic programming algorithm for placing printing statements is implemented.
Root-cause Analysis (RCA)
Failure detection is the process of collection of symptoms(症状), i.e., observations that are indicative of failures.
Root-cause analysis is, instead, the process of inferring the set of faults that generated a given set of symptoms [130].

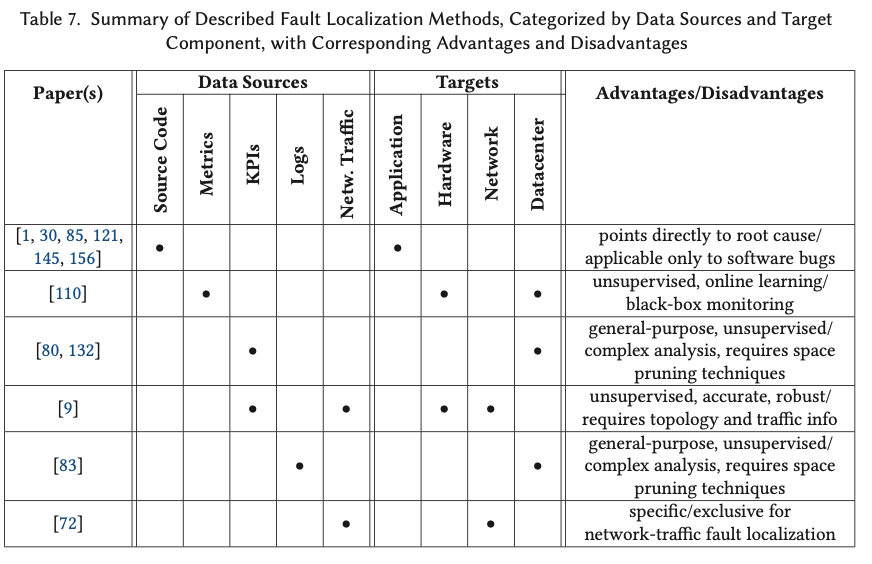
Fault Localization.
Fault localization is about identifying the set of components (devices, network links, hosts, software modules, etc.) interested by a fault that caused a specific failure.
基于指标组合关联关系的异常变化来定位
Several approaches [80, 83, 132] address fault localization by correlating abnormal changes in KPI values to particular combinations of attributes (representing, e.g., geographical regions, ISPs, hosts, buckets, etc.).
Hotspot [132] applies Monte Carlo Tree Search and hierarchical pruning to efficiently examine attribute combinations and measure how they relate to sudden changes in the Page View metric.
With Sherlock [9], Bahl et al. localize sources of performance problems in enterprise networks by constructing probabilistic inference graphs from the observation of packets exchanged in the network infrastructure.
Software Fault Localization (SFL) is fault localization in software components through source code analysis.
An SFL system typically returns a report containing a list of suspicious statements or components.
Zeller et al. [156] propose Delta Debugging, an algorithm for the determination of state variables causing a change in the outcome of execution runs.
Root-cause Diagnosis.
Root-cause diagnosis identifies the causes of behavior leading to failures, by recognizing the primary form of fault.
For this reason, it is typically treated as a classification problem.
Due to the inherent complexity and inter-dependency between components in software systems, it is considered a challenging task [6].
Kandula et al. [64] develop Shrink, a failure diagnosis tool designed for optical links in IP networks, but certainly extendable to other networking scenarios (the authors mention, for example, the diagnosis of routers and servers).
SherLog [154] performs post-mortem analysis of logs and source code to diagnose software faults (such as code bugs and configuration errors).
Samir et al. [124] utilize Hierarchical Hidden Markov Models (HHMM) to associate resource anomalies to root causes in clustered resource environments, on the different levels of container, node, and cluster.
Other Tools Supporting RCA.
Aguilera et al. [3] describe several approaches to identify performance problems in distributed systems by analyzing causal path dependencies between black-box components.
Podgurski et al. [120] propose to use Machine Learning algorithms to classify and group soft- ware failures to facilitate error prioritization and diagnosis.
Remediation

Incident Triage.
Incident triage(事件分流) is the step in problem resolution dealing with categorizing a reported problem.
The purpose of triage is often the assignment to the correct expert resolution group [126, 158].
Solution Recommendation.
The approaches here described provide implementations for recommending solutions to occurring problems.
Most solutions are based on past incident history and rely on the annotation of solutions in a previous resolution window.
Zhou et al. [166] propose similarity-based algorithms to suggest the resolution of repeating problems from incident tickets.
The basic approach consists in retrieving k ticket resolution suggestions using a k-NN approach.
Wang et al. [140] propose a cognitive framework based on the use of ontologies to construct domain-specific knowledge and suggest recovery actions for tickets in IT service management.
Recovery.
We define as recovery approaches those methods taking direct and independent actions toward the resolution of a diagnosed problem.
CONCLUSION

- Management Methods Failure Survey 论文management methods failure survey language survey models论文 survey comprehensive compiler learning survey reconstruction learning natural survey meta-learning learning survey meta readpaper-pulsar readpaper pulsar survey a_survey_on_space-air-ground-sea_ integrated_network_security_in basedautonomous language笔记survey diversification recommendation techniques survey