Pre
title: Randomized Quantization: A Generic Augmentation for Data Agnostic Self-supervised Learning
accepted: ICCV 2023
paper: https://arxiv.org/abs/2212.08663
code: https://github.com/microsoft/random_quantize
ref: https://mp.weixin.qq.com/s/WA_sLGfaqFtMtsqfc7mQ7g
关键词: quantization, self-supervised learning, data augmentation
阅读理由: 简单有效、通用、数据增强
Idea
一种通用的数据增强技术,可以应用于任意数据模态。以通道为单位,将其中的值根据大小映射到随机划分区间中的某一个值,如图1。
Motivation&Solution
- 自监督学习算法在概念上通用,但具体操作上却基于特定的数据模态,例如针对RGB图像的颜色抖动(color jittering)无法应用于其他数据模态。
- 已有的通用的自监督学习效果不好
Background
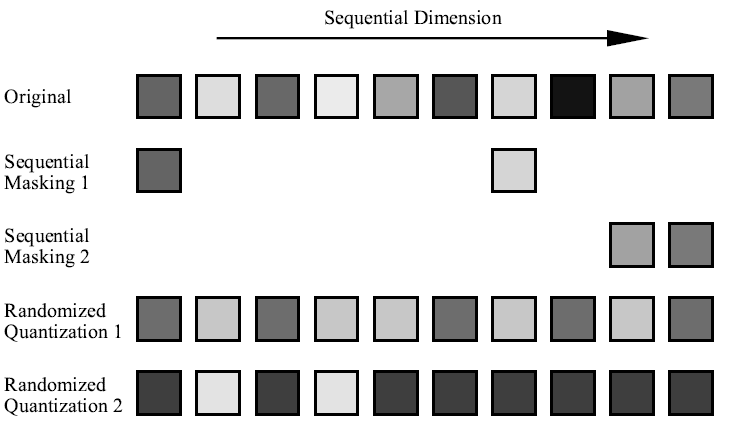
图1 将数据表示为一个矩阵,分序列维度和通道维度。masking是一个通用的数据增强方法,它通过在序列维度上扔掉一些token来实现。本文提出的随机量化则是扣留通道上的信息。这里用10个token的一维数据来表示,方块灰度值表示元素的数据值。
序列维度上的masking方法在捕获序列token间的相关性上有效
而通道维度描述了每个序列位置上的数据特征,如RGB颜色或光谱频率。
Method(Model)
Overview
量化(Quantization)指的是利用一组离散的数值表征连续数据,以便于数据的高效存储、运算以及传输。然而,一般的量化操作的目标是在不损失精确度的前提下压缩数据,因而该过程是确定性的,而且是设计为与原数据尽量接近的。这就限制了其作为增强手段的强度和输出的数据丰富程度。
随机量化(randomized quantization):每个通道中的数据通过非均匀量化器进行动态量化,量化值是从随机划分的区间中随机采样的。通过这种方式,落在同一个区间(bin)内原始输入的信息差被删除,同时不同区间(bin)数据的相对大小被保留,从而达到 masking 的效果。
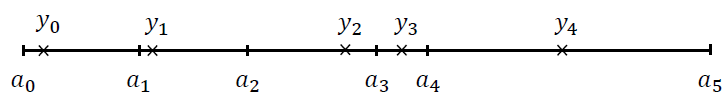
图3 非均匀量化器对5区间量化的示例。$\alpha_i$表示量化区间,$y_i$表示每个区间的再生值(reproduction value)
Randomized Quantization as Augmentation
只划分一个区间的极端情况就相当于丢弃了整个通道。均匀量化的区间和值均匀分布,非均匀则相反,可能有更好的性能,因为随机的过程带来了更加丰富的样本,同一个数据每次执行随机量化操作都可以生成不同的数据样本
随机量化表达的能力取决于:
- 区间划分的随机性
- 区间随机采样值
- 划分的区间个数n
Data-Agnostic Augmentation
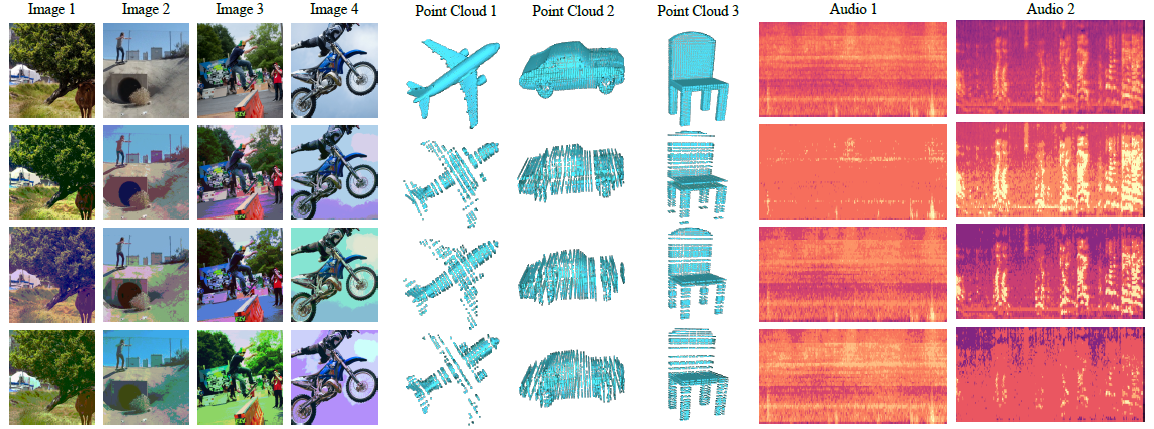
图2 随机量化增强的可视化。第一行是原始数据,后面三行都是增强后的视图。随机量化修改了图片的颜色,增强了边缘,在空间上采样点云的坐标,增强了音频的频率通道
图2里对图片去掉了高频细节,很突出了物体边界和边缘。音频倾向于增强特定的频率信号,如低频或高频声音。点云上通道维度代表了xyz坐标,倾向于下采样局部结构但突出全局形状。某些离散模态,如语言无法直接用于量化,但通过冻结数据嵌入层先映射到连续表征就好。
Siamese Representation Learning
孪生表征学习(Siamese representation learning)或对比学习很依赖增强的质量,每个训练迭代时,单独用随机量化或结合其他增强方法来采样两个数据视图。
Siamese representation learning frameworks: MoCo-v3, BYOL
Experiment
Ablation Study
Randomizing Bins.
Randomizing reproduction values.

表1 消融随机区间和随机值
Number of quantization bins.
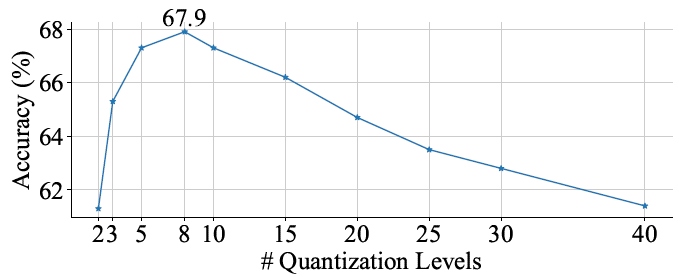
图5 量化区间数量的消融。区间越多增强效果越弱

图4 不同区间量化图片的可视化。这些图片都是均匀量化器量化的,一定数量的区间(5-10)适合图像增强
Training epochs.
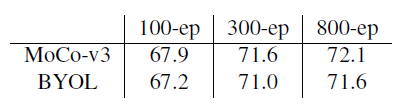
表2 随机量化增强能受益于更多的训练epoch,不会有early saturation
Experiments on Various Modalities
Images
Comparisons with domain-agnostic augmentations. 近来的域无关增强大多由Mixup改进而来,如i-Mix对输入数据进行线性插值,相应虚拟标签由当前batch产生。DACL插值输入,但将其用作对原始数据的加噪。
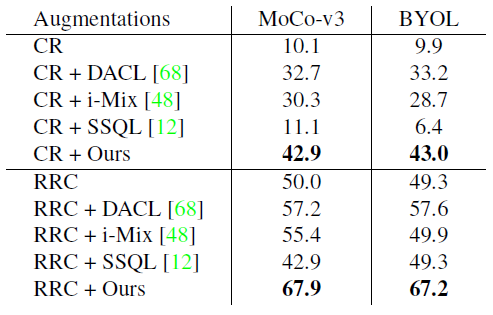
表3 ImageNet上与其他域无关增强技术比较。CR: center crop, RRC: random resized crop
Comparisons with domain-specific augmentations.
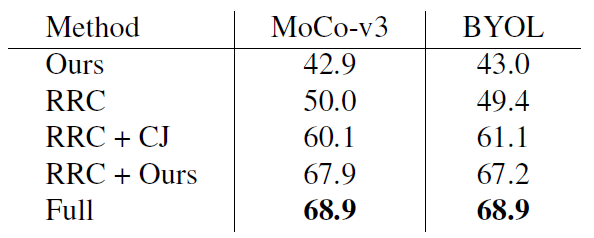
表4 ImageNet上与其他图片特定的增强技术比较。CJ: color jittering Full: random resized crop, color jittering, grayscaling, Gaussian blurring, solarization 随机量化比CJ强多了,也只落后完整handcrafted增强1%

图6 color jittering 和 随机量化的视觉比较,随机量化对图片改动更大,边缘增强更多
Comparison with weakly-augmented SSL baselines. MSF隐含地利用最近邻作为一种增强形式。
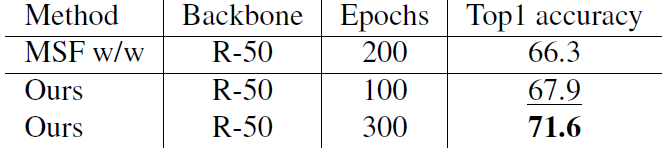
表5 与弱增强SSL基线MSF的比较
3D Point Clouds
backbone: Octree-based Sparse CNN
baseline: MID-Net
不像图片和音频,对点云坐标量化会使数据质量退化,区间设置为30来保持更多信息
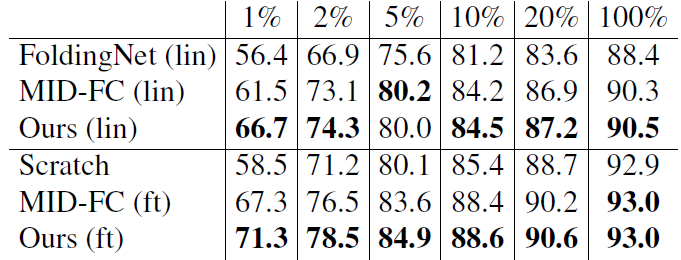
表6 ModelNet40数据集上形状分类任务的线性探测(lin)和微调(ft)结果。用ShapeNet数据集预训练。本文增强改进了分类精度,尤其在非常极限的数据上(1%的数据上也能有大提升)
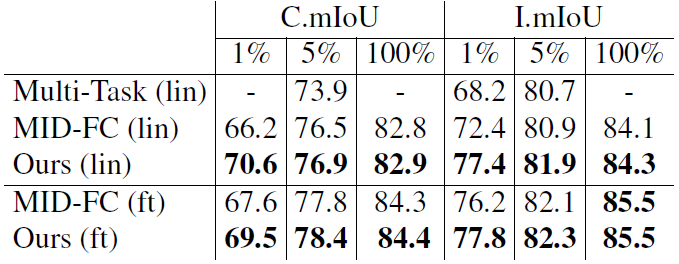
表7 ShapeNet Part数据集上形状分割任务的线性探测(lin)和微调(ft)结果。用ShapeNet数据集预训练。
Audio

表8 用于音频表征学习的下游数据集细节
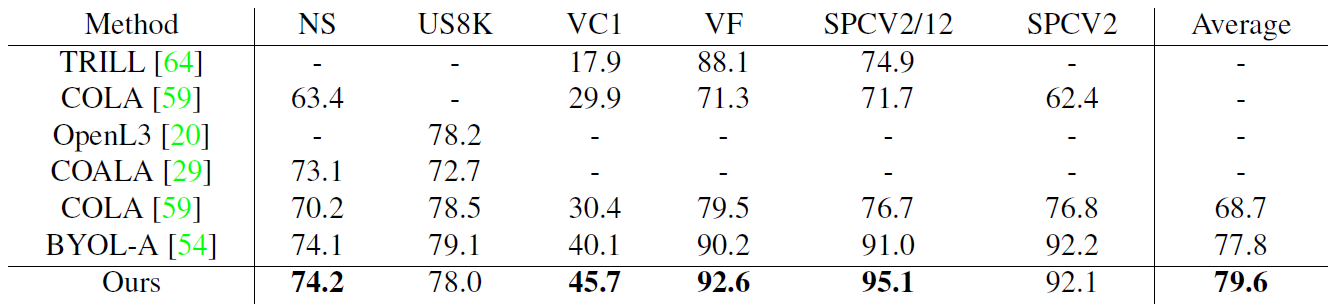
表9 音频表征学习在6个下游数据集上的线性探测结果。以AudioSet数据集预训练。
DABS
DABS是一个公开的benchmark,用于研究域无关的自监督表征学习,由于其中某些域天然就是离散的(如语言),先嵌入再增强。包含六种模态:自然RGB图片,多通道传感器数据,英语文本,音频,胸部X光照片,字幕图像(captioned images)
随机量化应用在Transformer前的token嵌入上,由于量化函数梯度为0,随机初始化token嵌入模块而不更新它,STE技巧(straight-through estimator)可能有用但不是本文的重点。

图10 用DABS benchmark评估6个模态的表征性能。每种模态的性能都是下游数据集结果的平均值。
Conclusion
提出了一种新的自监督数据增强工具:随机量化,可用于任意数据的通道维度,无需领域特定的知识,大幅超出现有的基于Mixup的域无关增强方法,比起视觉领域中域特定的增强方法也不错。它或许能用于masked建模框架,其中原始图片通过量化值重建,该方向将来会探索。
Critique
实验好多,方法简单,似乎合理且有效。试了一下,直观上来说能保持图片结构基本不变,只是色调有所变化,但用于具体任务的代码没给出来,也不知道用于其他任务最合适的区间数量怎么设置,总之按照(c,h,w)的形式塞进去,文本序列建模,掉点明显。
- Self-supervised Quantization Augmentation Randomized supervisedself-supervised quantization augmentation randomized self-supervised self-supervised exploration generative supervised self-supervised transformers lightweight supervised self-supervised interpretable adversarial generative self-supervised bidirectional supervised learning self-supervised transformers supervised empirical language-guided self-supervised segmentation self-supervised recommendation session-based self-supervised recommendation convolutional