S4
- 流式计算的模型是什么样?要解决哪些问题?
- S4是如何设计,如何进行分布式计算的?
- S4有哪些缺陷?
在分析海量用户搜索、广告点击行为时,这个处理数据的的需求和MapReduce生成报表类似,但是要求数据统计的反馈时间尽可能短。如果频繁使用MapReduce将不得不面对:
- 大量“额外开销”
MapReduce的额外开销不小 - 不得不让输入文件“碎片化”
GFS将文件变为64MB大小的Block,但如果每分钟都处理数据,那么输入数据就要按照分钟分割成多个小文件,分不到GFS不同节点。文件变得很小,也丧失了顺序读取大文件的性能优势。
高频执行MapReduce还有很多问题,根本原因还是:
- MapReduce 是为“高吞吐量”设计的系统,没考虑低时延的要求
- MapReduce 是一份“边界明确(bounded)”的数据,进行处理前数据已存放在存储系统上。而实时数据计算要处理的是“无边界(unbounded)”数据
流式计算逻辑模型
S4把所有计算过程变成了一个个处理元素(Processing Element)对象(PE 对象)。具体实现时,PE就是一个编程语言中的对象,其包含4个要素:
- 功能(functionality)PE类里实现的业务逻辑函数及配置
- 能够处理的事件类型(types of events)
- 能够处理的键(keyed attribute)
- 处理事件的键对应的值(value)
流式处理就是由一个个PE组成的有向无环图(DAG),起点是无键PE(Keyless PE)对象,用于接收外部发送来的事件流。外部发送来的事件流就是一条条的消息。无键PE解析消息转换为事件,然后打上三个信息:
- 事件类型(Event Type)
- 事件的 Key
- 事件的 Value
事务发出后,下游PE根据自己定义的事件类型和能处理的键接收对应消息并处理。没有对应的键的PE,系统会创建一个新PE。PE对象处理完数据后,可选择立即发送新事件出去;也可在满足一定数量或事件要求后再发送消息。在DAG的终点也有一系列PE对象,把最终计算结果发布(Publish),发布频率与其他PE发送消息类似。
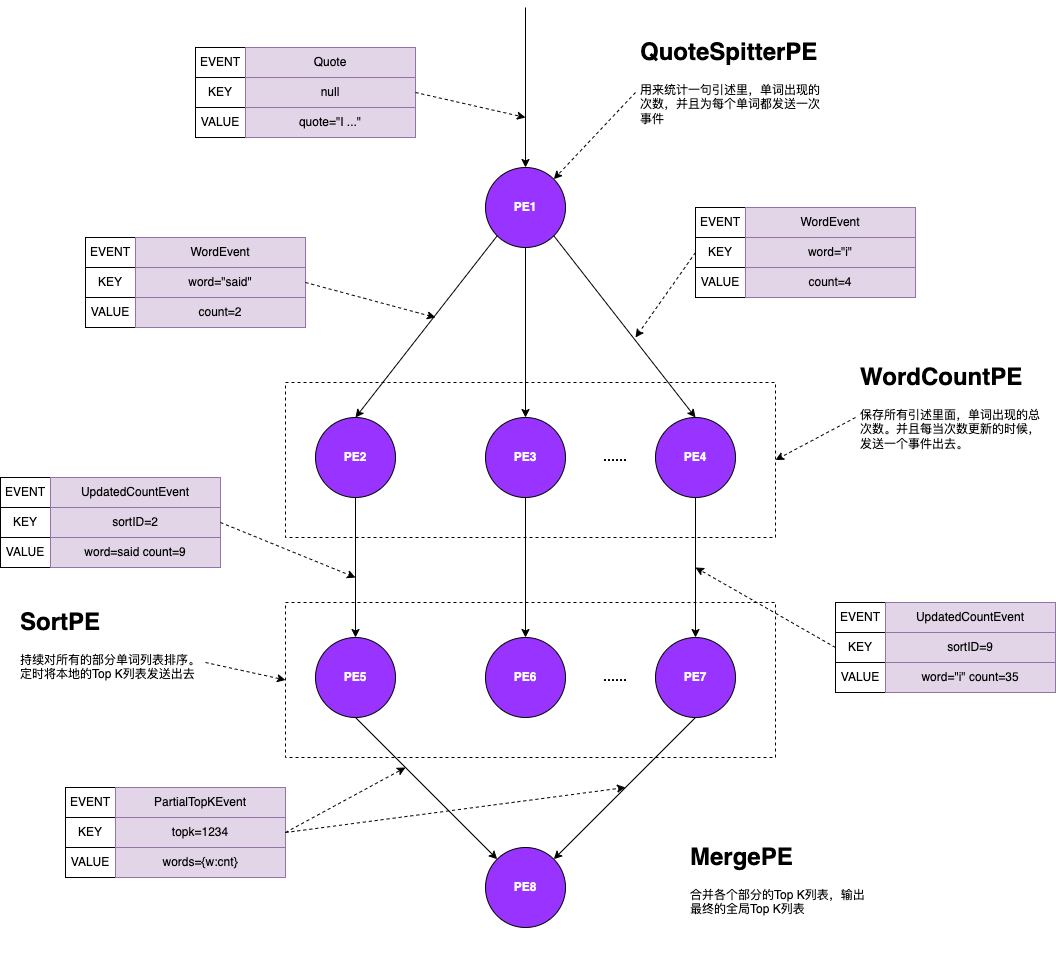
图中是TopK单词的例子:
- 起始节点是 QuoteSplitterPE,也是无键PE
- 接收外部传来的句子,分割成单词并统计单词出现次数
- 将每个单词出现次数作为 WordEvent 发送出去,对应 Event 的 Key 就是(Word,具体单词)的组合(Tuple),对应 Event 的值就是(Count,出现次数)的组合(Tuple)
- 一系列 WordCountPE 对象,声明只接受 WordEvent,每个不同单词对应一个PE对象,系统中有海量PE对象
- 上游PE将相同单词 WordEvent 发送到同一个PE,这个PE就可以统计单词出现的总次数
- 收到一个事件单词的出现次数就会更新,向下游发送一个 UpdatedCountEvent,也就是更新单词计数的事件
- 这个事件中对应的Key是(Sort,N)这样的组合,每个PE对象里的N都是随机的,但是固定不变的。
这个组合为了一层的负载均衡,可设定N,越大下游的PE对象越多,数据就会到更多不同对象中计算。对应的值包括对应的单词是什么及对应的单词出现次数。也就是((Word,具体单词),(Count,出现次数))这么一个组合。
- 一系列 SortPE 对象,用于接收上游不同单词出现次数,在内部排序。最后输出TopK给下游。它相当于所有单词的某个分区的数据,这个分区包含了一部分单词的所有数据。前面设定了N是几,就会有几个SortPE对象
- 给下游的事件为 PartialTopkEvent,是一个部分数据的TopK
- 所有 SortPE 的对象输出消息的 Key 都是相同的。为了获得全局排序,要发送到同一个PE对象。这个Key被固定为(topk,1234).而Value则是K个(单词,出现次数)的集合
- 整个 DAG 的终点,是唯一一个 MergePE,用于接收 PartialTopkEvent,然后内部归并,选出全局 TopK。最终把对应数据写入到其他存储系统供其他应用读取
S4将整个数据处理流程变成一个有向无环图的设计,后续流式系统都采用的方法。所有数据变成事件流,开发人员只需要:
- 设计整个 DAG 应该是什么样子
- 实现其中每个节点的业务逻辑代码
来自 MaprReduce 的设计理念
S4 和 MP 都是抽象的概念,但是S4选择了一个无中心的、完全对称的架构。S4没有Master节点,但是依赖ZooKeeper。所有服务器作为一个处理节点(ProcessingNode),简称PN,注册在zk上。集体的分配负载由各个节点协商决定,而不是由一个中心化的Master统一分配。
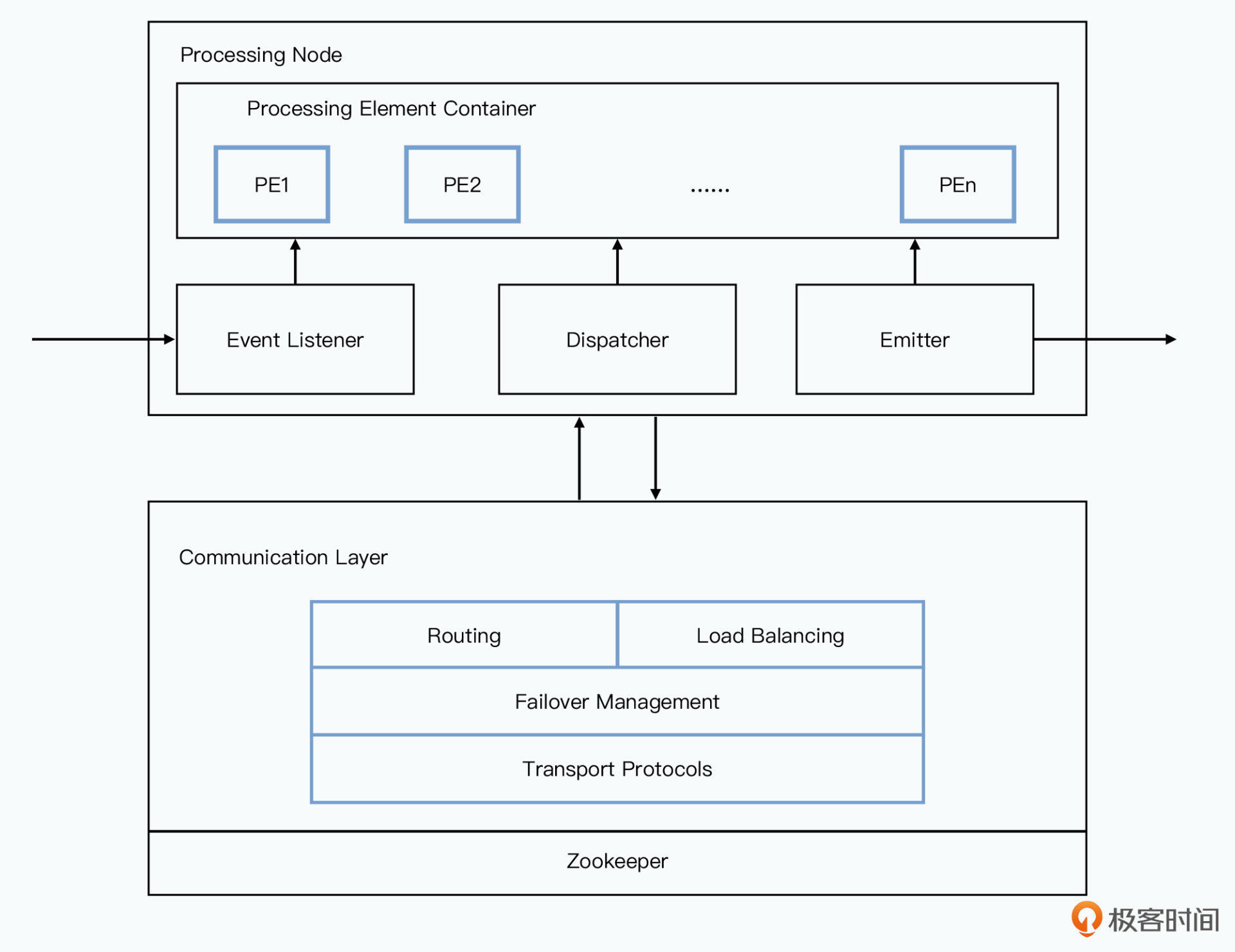
每个处理节点都是由上下两部分组成的:
上面,实际的业务处理逻辑模块
- 通过 Event Listener,监听外部发送过来的消息,转发给对应PE对象
- PE对象所有输出结果都发送给 Dispatcher,让 Dispatcher 确定应该发送给哪些 PE 里
- 实际消息发送由 Dispatcher 交给 Emitter,对外发送出去
业务处理模块只确定对应的消息发送,应该发送给哪个逻辑上的PE。具体发送由下层的通信层模块决定
下面,通信层模块
- 具体的路由,就是Event要去的某个逻辑PE到底在哪台物理服务器
- 负载均衡,不同单词更新频率可能不同,所以根据节点的负载判断新PE该放到哪个节点上
- 容错恢复机制,有特定节点挂掉时,要在其他节点上恢复原先这个节点被分配的PE
- 传输协议,S4是一个“插件式”架构,底层传输协议可以切换的。可使用TCP确保消息能发送成功;也可用UDP支持更大吞吐量
这与 MapReduce 类似,开发者只要关注业务逻辑,具体通信无需关心
“过时”的伸缩和容错能力
看起来S4的DAG上要有海量的对象,可能是数万级别。S4的设计很粗糙,有很多问题:
- 海量对象。每个Key都是一个对象,即使只出现一次也占用内存。S4的解决办法是设定TTL,定期清理
- 没有时间窗口。实时处理时常常要统计“过去一分钟热搜”或“过去一小时热搜”这种有时间范围的数据
- 容错处理很简单。S4中某个节点挂了就重启一个,但原先PE维护的信息都丢失了。不知道目前统计信息是什么,也不知目前处理到哪些事件
- 不支持动态扩容。负载上升过快时,S4随机丢弃一些数据,本质是对数据进行采样,而不能通过简单的堆硬件解决问题
小结
S4内部将业务逻辑层、网络协议、数据路由、负载均衡拆分开,做成了可插拔(Pluggable)的系统架构。整个流式处理框架里,S4采用了典型的Actor模式。DAG中每个点都是一个处理元素,每条边都是一条消息传递的路径,每个处理元素的会被托管在某个处理节点里。计算结果保持在内存,并定期发布到外部存储。
S4很粗糙,但是设计了一个完全对称、没中心节点的分布式架构。没有单点故障问题,但也放弃了动态扩容,在突发流量时选择服务降级。
业务层,也只考虑了“计算节点”层面的容错。只是重启挂掉的节点,但历史数据都已丢失。节点间的数据传输也没有全链路的传输保障。
Storm
- Storm 架构什么样?对比S4有哪些优点?
- 如何对消息容错处理?为什么Storm可追踪消息的整个生命周期,但又不过度影响集群性能
S4中使用了无中心的PE逻辑单元,整个系统没有master,是完全对称架构。Storm采用了DAG逻辑模型,但是在系统架构上采用了经典的 Master + Worker 的分布式架构,并将传送的消息和对应消息的处理逻辑做了分离。
基于 Topology 的逻辑模型
Storm的DAG叫Topology即拓扑图,包含元素如下:
- Spouts 数据源。
Storm没有将一切定义为PE,Spout负责去读取或收集数据,对应S4的 Keyless PE - Tuple 元组
就是Topology中传输的最小粒度的数据单元,是一个带命名的值的列表,可看作一个个KV对。但Key只在定义Tuple时出现,数据传输时只要传输对应的值。类似Thrift中字段名称定义在外部,传输时只要序号、类型、值。对应S4中事件(Event) - Streams 数据流
一个流包含了无限多个 Tuple 序列,会被系统分布式地并行处理 - Bolts 进行计算逻辑处理的地方
处理任意多输入流,产生任意多输出流。也负责将结果写入到外部DB。看起来像S4中PE,但Bolts与PE完全不同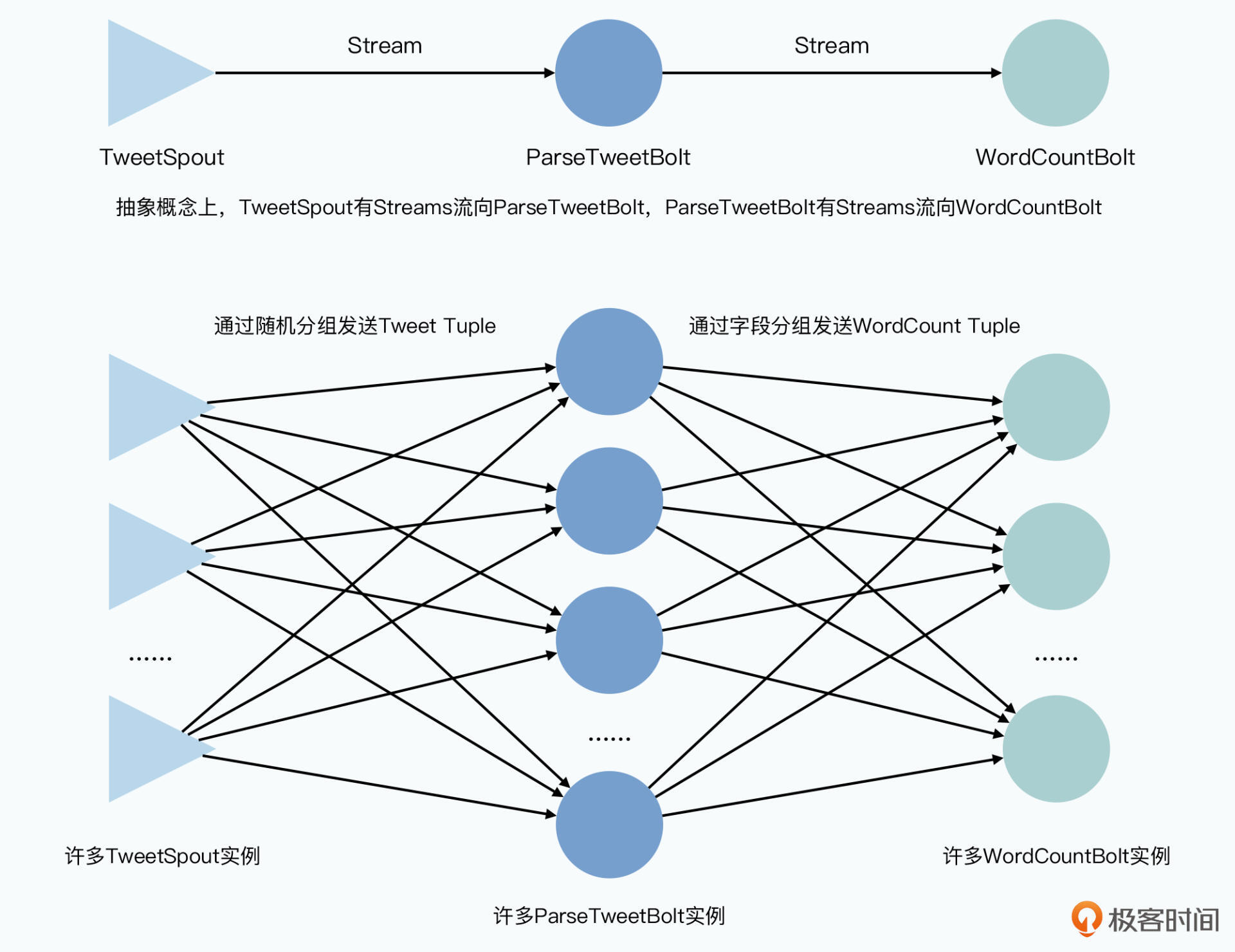
Storm 的 Bolt 只是逻辑处理单元,而不是每个Key就有一个Bolt对象,对于数据分发则通过Tuple的Grouping进行的,所以系统并行度可以设置,而不是与PE对象数量相关。
S4的PE不仅仅是功能逻辑单元,也是一个KV对的数据,同样类型事件下所有相同Key的数据会聚合到同一个PE下。这使得系统有大量PE对象,也导致S4的整个系统有几个显著设计问题:
- 内存占用和GC开销
开发者只能控制单个PE对象,而PE的数量是又S4框架控制的。在内存不足时可通过应用层更灵活的操作,如更频繁地把数据输出到外部KV数据库,释放掉内存,但S4框架下做不到 - 业务逻辑代码里混入控制分布式数据分发的逻辑
S4中将输出地Key变成(SortID,N)这种组合,也就是靠PE里逻辑代码设置拓扑图地并行度看,这使得分布式地分发逻辑和数据处理逻辑混合。如果数据量增加想增加并行度,不能仅仅修改参数,还要修改代码重新部署。而且历史上处理了(SortID,N)组合的PE在重新部署后可能要处理完全不同的数据,因为N已经变了
Storm中Bolt更类似MapReduce中的Map或Reduce。在Topology中可设置Bolt的并行度、数据流如何分组。但每个Bolt输出的Tuple本身无需通过生成一个类似(SortID,N)的特殊Key来定义下一层Bolt的并行度。Storm中数据流的分组:
- 随机分组(Shuffle Grouping)
每个Bolt随机发送,下层每个Bolt接收的数量都接近 - 字段分组(Fields Grouping)
选定Tuple中某个字段进行分组。如对于词频TopK排序,有Tuple (word,count),可指定对word字段分组,相应单词的Tuple分发到相同的Bolt去 - 全部分组(All Grouping)
类似数据广播,每个Bolt输出的Tuple要想下游每个Bolt都发一份 - 全局分组(Global Grouping)
所有上游Bolt都发送到某个唯一的Bolt,其拥有全局信息 - 无分组(None Grouping)
不关心分组,即随机分组 - 指向分组(Direct Grouping)
上游Bolt指定下游Bolt接收对应Tuple - 本地或随机分组(Local or Shuffle Grouping)
当下游Bolt有“任务”(Tasks)和上游Bolt在同一个worker进程,那么Tuple分发到这个进程的任务里,若没有则使用随机分组的方式发送Tuple。主要为了性能考虑。

S4中WordCountPE的输出只会给一个SortPE
Storm里 WordCountBolt 的输出会发送给多个不同的 SortCountBolt,因为同一个Bolt会包含多个不同单词
Master + Worker 系统架构
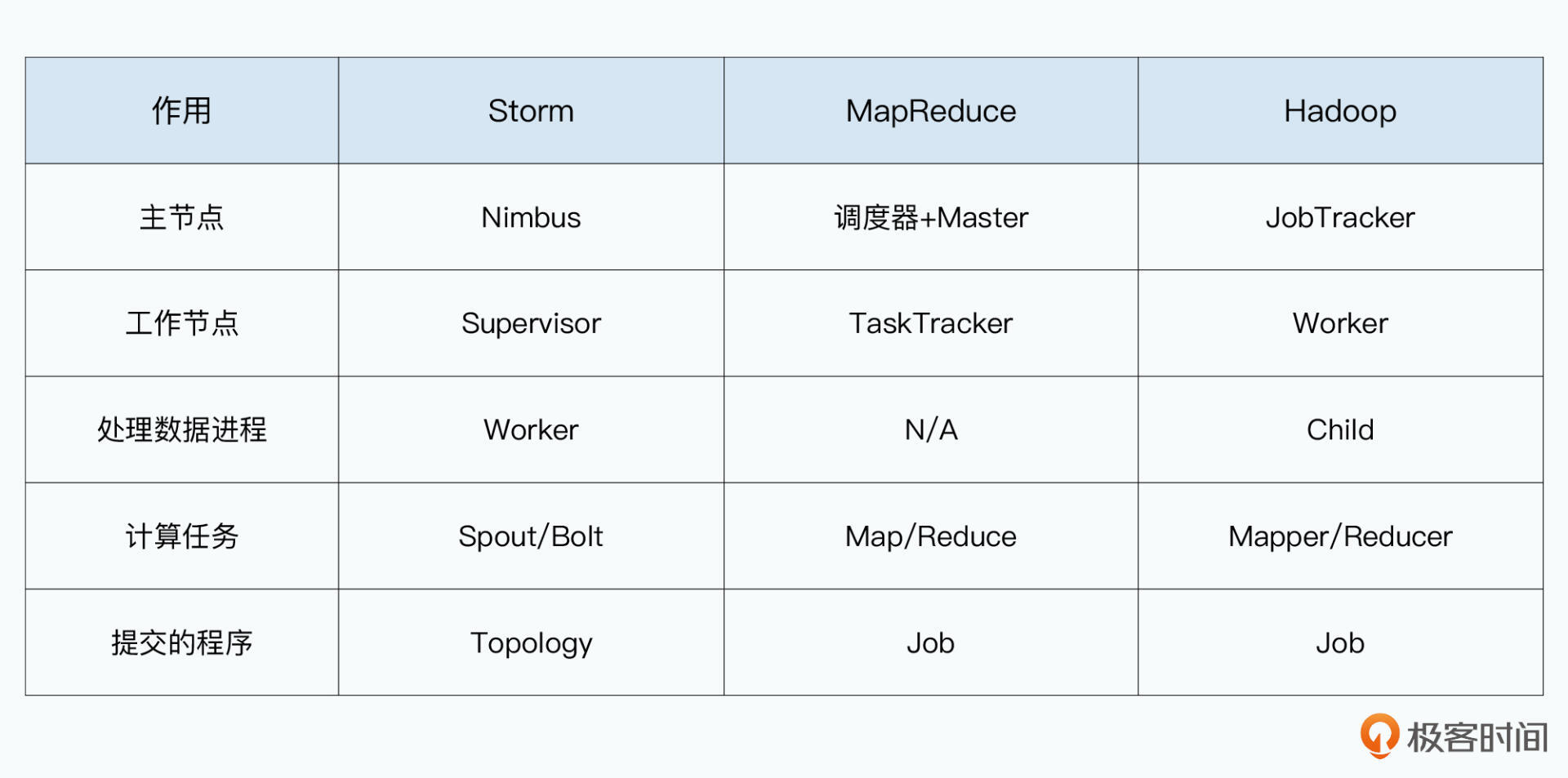
Storm 架构和 MapReduce 相似。Storm 集群中由 Nimbus + Supervisor + Worker 三类进程组成,容错能力也增加
- Nimbus 进程
Storm的Master,类似Hadoop的 JobTracker 或 MapReduce 的 Scheduler+Master,负责资源分配和任务调度。
开发者提交一个Topology给它。这个DAG实际上是一个编译好的程序和配置 - Supervisor 进程
类似Hadoop的TaskTracker,也就是MapReduce的Worker。每个服务器上都有一个。不负责执行任务,但负责接收Nimbus分配的任务,然后管理本地的Worker进程,让Worker进程执行 - Worker 进程
一台服务器有多个Worker进程,通过JVM的Executor维护一个线程池。实际线程池里有多个 Spout/Bolt 任务。线程池中Spout和Bolt会复用同样的线程
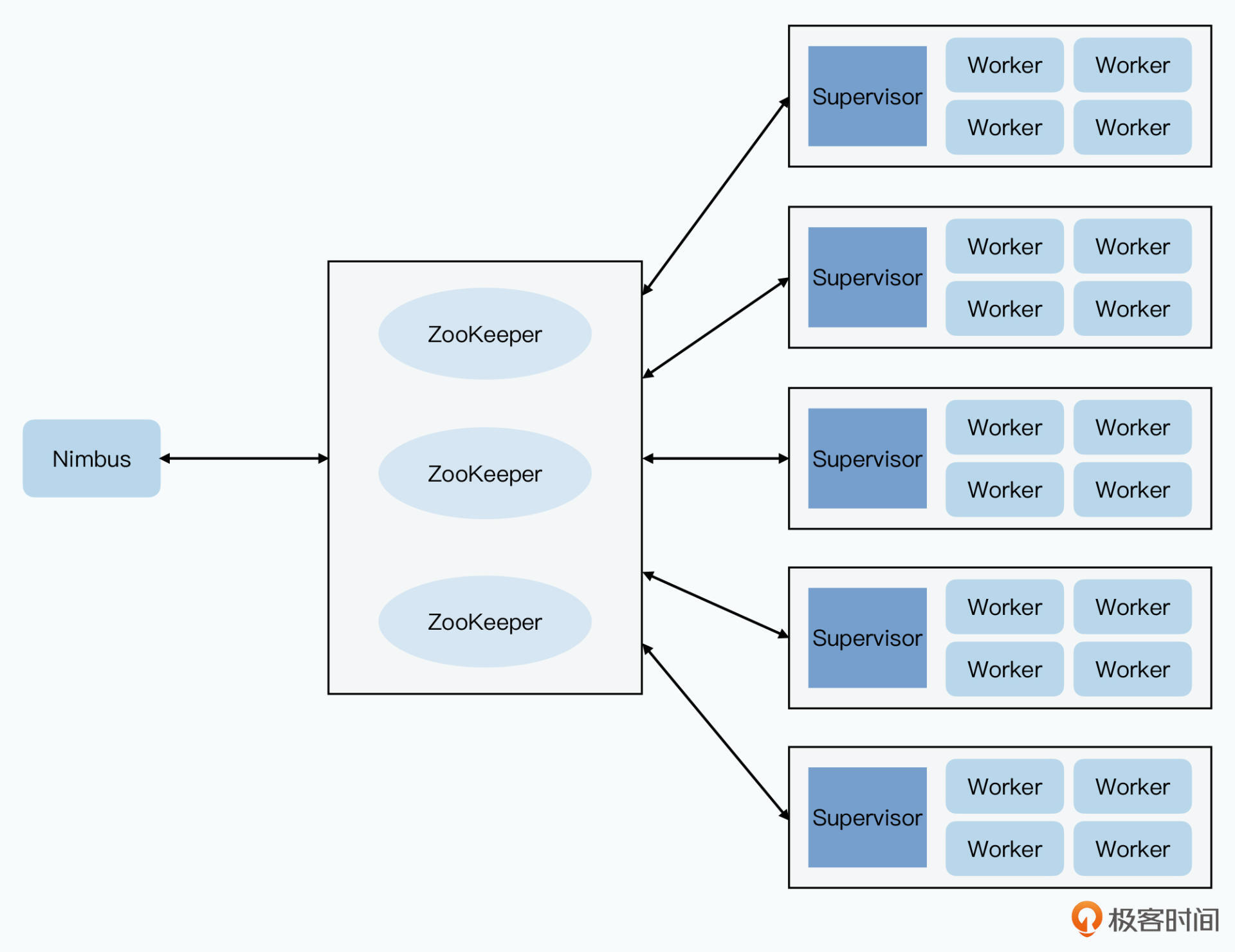
Nimbus 和 Supervisor 不直接通信,防止单点故障,而是使用Zookeeper进行任务分配持久化,由Paxos协议保障容错能力。Supervisor 从 Zookeeper 里读取对应的任务分配。
Nimbus 和 Supervisor 职责非常简单,Nimbus 只要进行 Topology 的解析和任务调度,而 Supervisor 只要接收任务并监控 Worker 进程是否存活。它们本身不处理数据也不在内存保持数据,挂掉后只要重启进程即可。与Megastore中协同服务器类似,只要让特定节点足够简单,即使称为单点,它们的稳定性也为处理复杂逻辑的进程要高。
各类分布式系统设计思路都是类似的,尤其是 Master + Worker 组合,Master负责调度,Worker负责执行。为了高可用引入分布式锁,确保分布式分配的数据不依赖Master。为了让整个系统更稳定,拆分调度任务的进程和直接执行任务的进程,让每个进程都只有单一的职责。
Storm 容错机制
S4没详细说明如何通信,在Storm中通过ZeroMQ完成Worker间通信。MQ的优势是异步、高性能。但是上游无法知道下游是否正确接收并处理了这条消息。分布式系统中错误是难免的。且流式计算中不可能只有一层链路。
论文中例子:统计Tweet里单词数量,先从一个TweetSpout中读取数据流里的Tweet,随机发送给一个ParseTweetBolt,这个Bolt解析Tweet成一个个单词,再发送给下游WordCountBolt。不同单词发给不同WordCountBolt,任何一个 WordCountBolt 没被成功处理就意味着面临“错误”。

Storm解决方案:从Spout发起的第一个Tuple作为树的根,下游所有衍生出来发送的Tuple都是树的一部分,任何Tuple处理失败或超时,就从Spout重发消息。
为此,Storm要引入AckerBolt,Spout发送出的消息要同时告知AckerBolt。Bolt完成根Tuple相关消息也通知Acker两个消息:告知已处理完Tuple,向下游发送了哪些衍生的Tuple。等最后一个Bolt告知后面没有新的Tuple时,AckerBolt就有了从Spout开始的整棵树的信息。
AckerBolt的开销岂不是非常大?需要将所有的还在处理中的Tuple存储下来。
Storm采用了位运算中的异或(XOR),Storm给每个发送的Tupe分配一个64位 message id。消息从Spout发送时AckerBolt接收到一个message-id,开始追踪此Tuple树。Acker会维护 message-id 到校验码(checksum)的映射关系。初始状态,校验码是用0和message-id异或一下。下游每个新发送的Tuple都要带上根Tuple的message-id,新Tuple发送后Bolt通知AckerBolt,内容就是根message-id到校验码的映射。
这个校验码就是当前对外发送的所有消息的message-id和已处理完的消息的message-id做异或,AckerBolt收到这个消息会把收到的校验码和本地校验码做异或,生成新的。我们发送和接受一条消息各一次,最后结果一定是0。只要Tuple没被acking,校验码就不是0;所有Tuple都被acking后校验码一定是0。

所有Bolt通知Acker最新执行内容只要发送 16byte 的 message-id 和校验码。即不必发送Tuple原始内容,也不必为下游每个Tuple单独发送消息。但是,这个机制只能保障Spout发送的Tuple至少处理一次(At Least Once),避免不了 Tuple 被重复处理。AckerBolt不适用所有场景,需要按需启用。关闭acking机制就实现了 At Most Once。Storm没有实现 Exactly Once。
小结
Storm 使用 Nimbus 这个主节点进行任务调度,通过 Zookeeper 存储所有元数据,通过把工作节点拆分为 Supervisor 和 Worker 提升系统稳定性。
相比S4仅仅在高压下实现降级,Storm 利用异或操作实现了追踪Tuple的整个生命周期,实现“At Least Once”保障。