来自NUS&NVIDIA
文章地址:[2204.12451] Understanding The Robustness in Vision Transformers (arxiv.org)
项目地址:https://github.com/NVlabs/FAN
一、Motivation
CNN使用滑动窗的策略来处理输入,ViT将输入划分成一系列的补丁,随后使用自注意力层来聚合补丁并产生他们的表示,ViT的强大鲁棒性部分归因于他们的自注意设计,self-attention结合了非局部关系的建模,但这一假设最近受到新兴研究ConvNeXt的挑战。这就提出了一个有趣的问题,即自注意在鲁棒泛化性中的实际作用。
在本文中,作者旨在找到上述问题的答案,在图像分类过程中,ViT中自然会出现有意义的对象分割。这促使我们想知道,自我关注是否通过视觉分组促进了中级表征的改进(从而提高了鲁棒性)(视觉分组指的是视觉系统将离散的刺激组织成更大整体的趋势,他是确定视觉场景的哪些区域和部分作为高阶感知单元(如物体或图案)的一部分的过程)——这一假设与早期计算机视觉的奥德赛(加州大学伯克利分校)相呼应。作为进一步的研究,我们使用光谱聚类分析了每个ViT层的输出令牌,其中亲和矩阵的显著特征值对应于主要的聚类成分。我们的研究表明显著特征值的数量与输入损坏的扰动之间存在有趣的相关性:两者在中层上都显著减少,这表明在这些层上分组和鲁棒性的共生关系。
为了理解分组现象的深层原因,我们从信息瓶颈(IB)的角度来解释SA ,这是一种压缩过程,通过最小化潜在特征表示和目标类标签之间的互信息,同时最大化潜在特征和输入原始数据之间的互信息,“挤出”不重要的信息。我们表明,在温和的假设下,自我关注可以写成IB目标的迭代优化步骤。这在一定程度上解释了新出现的分组现象,因为已知IB可以促进聚类代码。
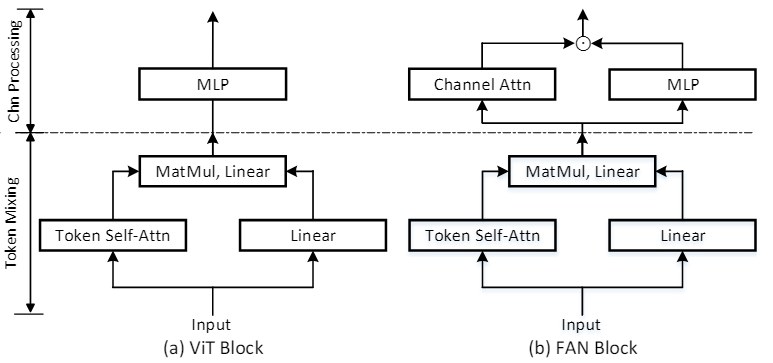
(a)展示了ViT Block的基本结构,ViT采用多头注意力机制,然后是MLP来聚合来自多个头部的信息,因为不同的头部聚焦于对象的不同部分,所以muti-head attention设计本质上组成了一个信息
瓶颈的混合,所以,如何聚合来自不同头部的信息很重要。
本文的目标是提出一种聚合设计,以加强分组和鲁棒性的共生。如(b) 所示,提出了一种新颖的注意力通道处理设计,它通过重新加权来促进通道选择。与 MLP 块中的静态卷积操作不同,注意力设计是动态的和内容相关的,会产生更具组合性和鲁棒性的表示。本文所提出的模块产生了一系列新的 Transformer 主干,在其设计之后创造了完全注意力网络 (FAN)。
二、Contribution
1.这项工作没有侧重于实证研究,而是提供了一个解释框架。将视觉传递中的分组、信息瓶颈和稳健泛化三位一体统一起来。
2.提出的全注意力设计既高效又有效,以边际额外成本带来系统改进的鲁棒性。与ConvNeXt等最先进的结构相比,FAN模型在干净和鲁棒的图像分类精度方面都表现出了良好的性能。
三、Fully Attention Network
FAN的设计主要有两方面驱动:1)为了促进更多的组合特征,引入通道加权是可取的,因为一部分头部伙同搭配确实比其他的通道捕获更多有用的信息;2)重新加权机制应该包含更多空间上的每个通道整体考虑,来利用提升的分组信息,而不是做出非常局部的通道聚合决策。
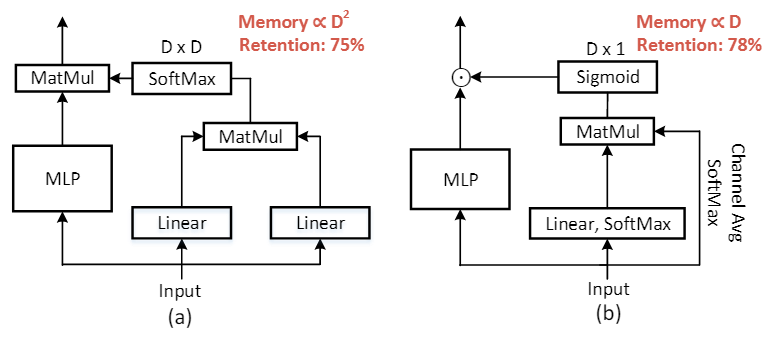
上述目标的一个起点是引入类似于XCiT的通道自我注意机制,如(a)所示,通道注意(CA)模块采用自注意设计,将MLP块移动到自注意块中,然后与来自通道注意分支的D×D通道注意矩阵进行矩阵相乘。
3.1 注意特征转换
FAN引入以下通道注意(CA)进行特征变换:
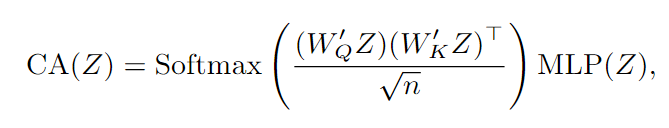
与SA不同的是,CA沿着通道维度而不是token维度计算注意矩阵,它利用特征协方差(经过线性变换W ' Q, W ' K)进行特征变换。对相关值较大的强相关特征通道进行聚合,对相关值较低的异常特征通道进行隔离。这有助于模型过滤掉不相关的信息。在CA的帮助下,该模型可以过滤不相关的特征,从而对前景和背景标记形成更精确的标记聚类。
3.2 高效的通道自注意力
在通道维度应用传统的自我注意力计算机制有以下两个限制:1)计算开销,方程中的引入的CA的计算量与维度的二次方成正比,对于现在的金字塔模型,通道尺寸在顶部变得越来越大,所以直接应用CA会导致比较大的计算开销;2)参数效率低。在传统的SA模块中,注意权重的注意分布是通过Softmax操作来锐化的。因此,只有部分通道有助于表征学习,因为大多数通道通过与小注意权重相乘而减少。
为了克服上述问题,文章提出了一个一种新型的类自注意机制,它具有高计算效率和参数效率,主要改动有以下两点:首先,我们不是在计算token特征之间的相关性矩阵,首先通过计算通道维度的平均值来生成token原型Z,Z中聚合了由token位置表示的所有空间位置的通道信息,因此,在token特征和token原型之间计算相关矩阵是信息丰富的。其次,FAN并未使用softmax函数,而是使用了sigmoid函数进行权重的规范化。然后将其与token特征相乘,而不是使用MatMul来聚合通道信息。直观地说,我们不会强迫通道只选择几个“重要”的令牌特征,而是根据空间相关关系重新加权每个通道。实际上,通道特征通常被认为是独立的。一个价值大的渠道不应该限制其他渠道的重要性。通过结合这两个设计概念,我们提出了一种新的自关注通道,并通过公式计算:\
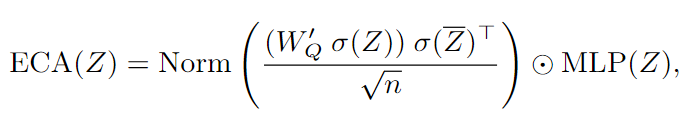
其中,σ表示沿令牌维度的Softmax操作,Z表示令牌原型。我们用s形作为Norm
四、Code
等我用完看看效果⭐
- Understanding Transformers Robustness Vision ICMLunderstanding transformers robustness vision vision-language understanding enhancing advanced convolutions transformers introducing vision transformers replacing softmax vision efficientformer transformers vision icml robustness robustness-enhanced translation augmentation robustness improving robustness similarity improving attention