1. 导读
前面我们回顾了AlexNet,AlexNet的作者指出模型的深度很重要,而VGG最大的贡献就在于对网络模型深度的研究。
VGG原论文:《Very Deep Convolutional Networks for Large-Scale Image Recognition》
VGG模型是2014年ILSVRC竞赛的第二名,第一名是GoogLeNet。但是VGG其规律的设计、简洁可堆叠的卷积块,且在其他数据集上都有着很好的表现,从而被人们广泛应用,同时在多个迁移学习任务中的表现要优于googLeNet。而且,从图像中提取CNN特征,VGG模型是首选算法。
2. 网络结构
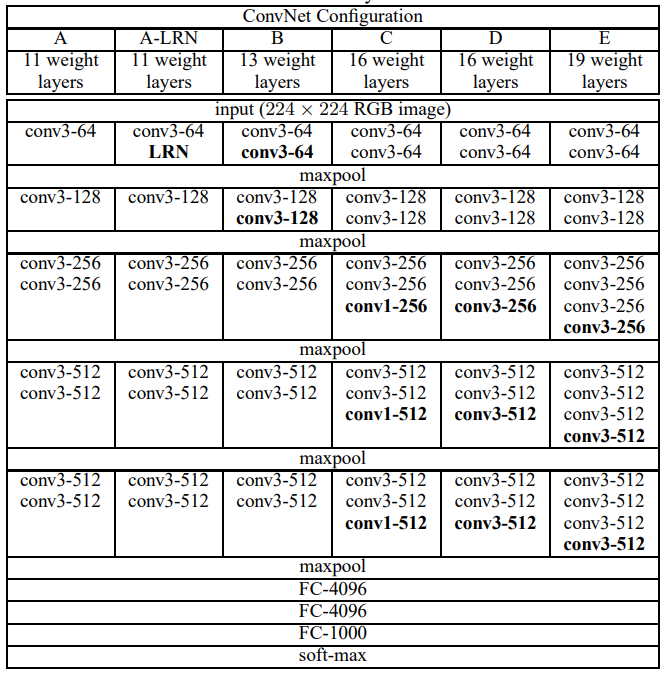
这是论文中作者给出的VGG的6种不同网络结构:
VGG-16示意图如下,整体来说整个网络可分为5个block,每个block由卷积+池化组成,然后进入3个全连接层再接softmax实现分类:

我们以VGG-16为例来解读其网络结构:
- VGG-Block内的卷积层都是相同的结构,其中都是统一通过size为3×3的kernel size + stride1 + padding(same)实现,意味着输入和输出的尺寸一样,且卷积层可以堆叠复用。
- MaxPool层统一的pool size=2,stride=2,起到的作用是将前面的卷积层的特征缩减一半,从224-112-56-28-14-7.
- 输入层: 输入为224×224×3 三通道的图像。
- Block1: 输入为224×224×3,2个卷积层分别经过64个kernel size为3x3×3的filter,stride = 1,padding=same卷积后得到shape为224×224×64;再经Max-pooling层:pool size=2,stride=2的减半池化后得到尺寸为112×112×64的池化层。
- Block2:输入尺寸为112×112×64,2个卷积层分别经128个3×3×64的filter,stride = 1,padding=same卷积后得到shape为112×112×128;再经Max-pooling层:pool size=2,stride=2的减半池化后得到尺寸为56×56×128的池化层。
- Block3:输入尺寸为56×56×128,3个卷积层分别经256个3×3×128的filter,stride = 1,padding=same卷积后得到shape为56×56×256;再经Max-pooling层:pool size=2,stride=2的减半池化后得到尺寸为28×28×256的池化层。
- Block4:输入尺寸为28×28×256,3个卷积层分别经512个3×3×256的filter,stride = 1,padding=same卷积后得到shape为28×28×512;再经Max-pooling层:pool size=2,stride=2的减半池化后得到尺寸为14×14×512的池化层。
- Block5:输入尺寸为14×14×512,3个卷积层分别经512个3×3×512的filter,stride = 1,padding=same卷积后得到shape为14×14×512;再经Max-pooling层:pool size=2,stride=2的减半池化后得到尺寸为7×7×512的池化层,该层后面还隐藏了flatten操作,通过展平得到7×7×512=25088个参数后与之后的全连接层相连。
- FC:经过3个全连接层,神经元个数分别为4096,4096,1000。其中前两层在使用relu后还使用了Dropout对神经元随机失活,最后一层全连接层用softmax输出1000个分类。
3. 论文总结
-
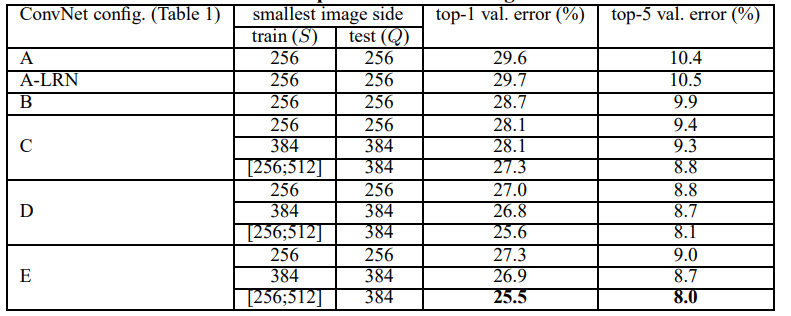
网络深度对模型分类性能有提高:作者做了实验,网络从11层19层,网络深度增加对top1和top5的错误率下降很明显。最佳模型:VGG-16
-
多个小卷积核比单个大卷积核好:相较与AlexNet,VGG最大的改进或者说区别就是用小size的Filter代替大size的Filter。2个3x3的卷积层连接,就达到了5x5的效果,3个3x3的卷积层连接,就达到了7x7的效果;多个小卷积比单个大卷积好在两个方面:1:可以减少参数,例如使用3个3x3卷积参数个数:3(3x3xCxC),单个7x7卷积层参数个数,后者参数量大81%:7x7xCxC;2:这样做相当于进行了更多的非线性映射,可以增加网络的拟合和表达能力。
-
删除了AlexNet中的LRN层:没有使用AlexNet中的LRN技术。这是因为后面的实验(如上图中的A和A-LRN)中证明了使用LRN对性能并没有提升作用,反而增加内存和时间消耗。
-
图像预处理:在模型训练期间,作者所做的唯一预处理就是将输入的224×224×3通道的像素值,减去平均RGB值,为了增加数据集,和AlexNet一样,这里也采用了随机水平翻转和随机RGB色差进行数据扩增。对经过重新缩放的图片随机排序并进行随机剪裁得到固定尺寸大小为224×224的训练图像。
4. 代码实现
为了加深对VGG网络的理解,我基于pytorch框架使用了与我上一篇AlexNet博客中同样的数据集去对VGG16进行测试,其demo你可以点击这里在github上访问;