备注
本文对Transformer架构的分析来源于论文 Attention is All You Need 以及部分其引用的论文,可以理解为对该论文的翻译以及相关内容的整理。本文对 Transformer 的实现基于 Pytorch,但是不直接调用 Pytorch 封装的 Transformer,而是手动实现 Encoder 和 Decoder 等;与 Transformer 本身无关的代码内容取自 pytorch 的官方教程 LANGUAGE TRANSLATION WITH NN.TRANSFORMER AND TORCHTEXT。
Transformer 产生的背景
Transformer 是在 RNN 之后提出的,解决了 RNN 的重要问题,一定程度上取代了 RNN。RNN 的问题主要在于其大量的序列化计算,它的计算量随序列数据长度线性增长。序列化计算的一大问题是占用大量资源,尤其是空间资源,所以我们在训练 RNN 时无法在一个 minibatch 中放入大批数据——原文对此的评价是“难以并行化”。
Transformer 同样有堆叠起来的序列化计算(EncoderLayers & DecoderLayers),但是堆叠的数量是常数级的,很好地支持了并行化训练。
此外,Transformer 的一大特点是完全依赖注意力机制。这一点使得它可以很好地对两个相隔很远的 token 之间的关系进行建模,原因将在后文分析。
Transformer 的架构及实现
这一部分基本上是对原文的翻译和整理。
完整架构与数据流动方向
首先对 Transformer 中数据的流动方向有一个整体的了解:
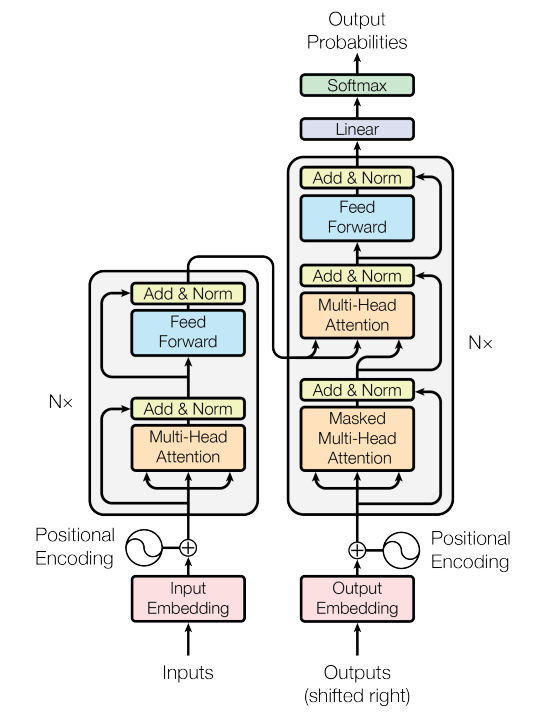
上图是经典 Transformer 架构,图所描述的是其训练过程。图中传递的数据 \(X_{input}, X_{output}\) 是若干个句子(一个batch)的词嵌入表示,具体的,\(X\) 是三维的,\(X_i\) 代表第 \(i\) 个句子的所有词的词嵌入表示,\(X_{ij}\) 是第 \(i\) 个句子的第 \(j\) 个单词的词嵌入表示,为一个向量。同一个batch中各个句子的长度可能不同,我们取所有句子的最大长度,不足最大长度的句子在末尾补充特殊单词PAD补齐,PAD有自己的词嵌入表示。下面我们具体描述数据的流动:
- Transformer 在训练时有两个输入:Inputs 和 Outputs,在自然语言翻译模型中也就是原文和译文;
- Inputs 和 Outputs 分别通过对应语言的 Embedding 得到它们的向量表示;
- Inputs 和 Outputs 分别加上一个 Position Embedding(之后会分析),所得的两个向量传入 Transformer 的主要架构 Encoder 和 Decoder;
- Encoder 包含 \(N\) 个堆叠的 EncoderLayer,Inputs 传入第一个 EncoderLayer 得到输出,上一层 EncoderLayer 的输出作为下一层 EncoderLayer 的输入,直到经过 \(N\) 个 EncoderLayer 得到 Encoder 的输出 Output_Encoder;
- Decoder 包含 \(N\) 个 DecoderLayer,每个 DecoderLayer 有两个输入:Output_Encoder 以及上一层 DecodeLayer 的输出(如果是第一层则为 Outputs),经过 \(N\) 个 DecoderLayer 得到 Decoder 的输出 Output_Decoder;
- 最后将 Output_Decoder 用线性层计算出单词的得分,然后经过 Softmax 层得到单词的概率。
Transformer 架构的层次非常清晰(在编写代码时也可以按照这个层次来划分文件):
- 最高层是 Transformer 本身,包括 Embedding, Position Embedding, Encoder, Decoder 和 softmax 分类器;
- 然后是 Encoder 和 Decoder,分别由若干 EncoderLayer 和 DecoderLayer 堆叠组成;
- 再然后是 layer 层,即上面提到的 EncoderLayer 和 DecoderLayer,由 Multi-head Attention 和 Feed-Forward Network 组成;
- 最后是 sub-layer 层,即 Multi-head Attention 和 Feed-Forward Network。
本节的下文将从底层到最高层逐步建立 Transformer 架构。
Multi-head Attention(MHA)
Transformer 开篇即阐明,它完全依靠注意力机制。可以说 Multi-head Attention 是它的关键部分。MHA 可以看作有两个输入,\(X_{key\_value}, X_{query}\),前者用于提供输出的信息,后者用于提供输入的信息,有时候可以看到 \(X_{key\_value}=X_{query}\)。
Scaled Dot-product Attention(SDA)
MHA 也是一个复合的结构,由若干个小的注意力模块堆叠而成。这里的堆叠不是顺序堆叠,而是平行堆叠,具体在下文阐释。
每个 SDA 的输入均为相同的 X_{key_value}, X_{query}$,包含三个矩阵参数 \(M_{key}, M_{value}, M_{query}\),用于将 \(X_{key\_value}\) 转化为 key 向量 \(K\) 和 value 向量 \(V\),将 \(X_{query}\) 转化为 query 向量 \(Q\)。
通俗地理解 SDA:\(X_{key,value}\) 储存了若干键值对(或者说 C++ 中的一个 map),\(X_{query}\) 储存了若干询问,我们希望找到 query 在键值对中对应的 value。但是 query 不是完美地匹配上 key,处理方法是衡量 query 和每个 key 的相似程度,将对应的 value 加权求和。通过矩阵乘法,我们从 \(X_{key\_value}\) 中提取出 key 向量 \(K\)(每一行表示一个 key 向量,\(Q,V\) 同理)和 value 向量,从 \(X_{query}\) 中提取出 query 向量。为了后面定义相似程度,我们保证 key 和 query 向量的长度相同。
对于某个 key 向量 \(k\) 和某个 query 向量 \(q\),我们定义点乘 \(k\cdot q\) 为 \(k,q\) 的相似程度。这个类似于用两个向量的夹角衡量相似程度,但是我们并没有对向量长度归一化,所以 key 向量的长度也会对相似程度产生影响。这里笔者的理解是数据分布本身是有 bias 的,某些 key 的占比更大,类似于简单的 Softmax 分类器中的 bias。使用矩阵表示的话即为 \(S=QK^T\),\(S_{ij}\) 表示询问 \(i\) 与键 \(j\) 的相似程度,经过 Softmax 得到询问 \(i\) 的答案中值 \(j\) 的占比。
于是我们得到最终的式子:
其中 \(d_{key}\) 是 key 向量的长度。按照原文的说法,这里除以 \(\sqrt{d_{key}}\) 是为了防止 Softmax 饱和。
MHA
我们可以堆叠 \(h\) 个 SDA 并行计算,每个 SDA 都传入 \(X_{key\_value}, X_{query}\)。对于某个询问 \(i\),第 \(j\) 个 SDA 给出的回答是 \(v_{ij}\);则最终得到的答案是把 \(v_{i1}, \dots, v_{ih}\) 首尾相接 \(\mathrm{concat}(v_{i1}, \dots, v_{ij})\)。
最后我们再把得到的答案乘上矩阵 \(W_O\),得到最终输出。这可以看作是从 value 空间(别忘了我们在 SDA 中把 \(X_{key\_value}\) 乘上 \(M_{value}\) 得到 value 向量,SDA 的输出是 value 向量的线性组合,也是 value 空间中的)到原空间中的一个映射。为什么要映射回原空间?因为 Transformer 继承了 ResNet 的 residual connection,每一层的输出是该层的输出加上该层的输入,所以输出必须和输入在同一个空间,否则没有意义。
Formally,我们可以把整个 MHA 层写作:
以及要加上 residual connection 和 LayerNorm,这个后面再说。
此外,在这里阐述一个额外参数:mask。注意到我们一开始在句末补充了PAD,PAD本身不在句中,没有实际意义,因此也不应该占用注意力。也即我们不希望 \(X_{key\_value}\) 中代表PAD的键值对在 Softmax 中分配到比例,于是我们额外传入一个参数 mask,表示我们不希望哪些键值对被分配注意力(储存形式可以理解为“不希望句子 \(i\) 的第 \(j\) 个词在第 \(k\) 个询问中分配到注意力”),在 Softmax 之前,我们手动把 \(QK^T\) 中的这些位置设置为 \(-\infty\) 即可。实际上,添加 mask 并不止是因为有 PAD,在 Decoder 一节会讲解另一个需要 mask 的原因。
Feed-Forward Networks
在笔者看来这个就是两个线性层的堆叠,中间以 ReLU 激活。不从原文的“大小为 \(1\) 的卷积核”的角度阐释,我们可以认为 FFN 就是先通过一个线性层提取出大量特征(特征向量的维度远大于输入数据的维度),然后使用 ReLU 筛选特征,最后再用线性层恢复到原特征空间。恢复到原空间的原因仍然是 residual connection。
实现就相当地简单,formally:
EncoderLayer
EncoderLayer 由 MHA 和 FFN 顺序相接组成,输入只来源于上一个 EncoderLayer 的输出,如果是第一层则为原文的词嵌入。
其中 MHA 的输入 \(X_{key\_value}, X_{query}\) 是同一个值,为上一层 EncoderLayer 的输出,若为第一层则以原文的词嵌入为输入。注意 MHA 和 FFN 的输出都要加上 residual connection 传递的输入值之后再经过 LayerNorm 归一化。
在实现时,我们还需要额外传入 Padding mask,作为 MHA 的 mask。
DecoderLayer
DecoderLayer 由两个 MHA 和一个 FNN 顺序相接组成。输入包括 Encoder 的输出和上一层 DecoderLayer 的输出,如果是第一层则为译文的词嵌入。既然有两个输入源,Encoder 的输出对应原文,DecoderLayer 的输出或者词嵌入对应译文,那么我们的 Padding mask 就既要考虑原文,也要考虑译文,记 \(mask_{in}, mask_{out}\) 分别为原文、译文的 Padding mask。
第一个 MHA 称为 masked-MHA,第二个直接称为 MHA。为什么有这种区别?顾名思义,masked-MHA 除了 Padding mask 以外还多了一个 mask。
首先确认 masked-MHA 的输入,它的 \(X_{key\_value}, X_{query}\) 也是相同的,都是上一层 DecoderLayer 的输出(如果是第一层就是译文的词嵌入)。既然键值对来自译文,那么 Padding mask 当然用 \(mask_{out}\)。首先就翻译任务而言,我们采用顺序翻译,这就有一个限制:在预测翻译出的第 \(i\) 个词时,我们只知道翻译出的前 \(i-1\) 个词,以及输入的所有词。如果只加 Padding mask,那么我们在训练时,预测第 \(i\) 个词的已知信息中就包含了 \(i\) 以及 \(i\) 之后的词的信息,就会导致问题。我们希望进行询问 \(i\) 时,\(i\) 及其之后的词不要分配注意力,这就需要 mask,记为 \(mask_{pred}\)。我们把 \(mask_{pred}\cup mask_{out}\) 作为 mask-MHA 的 mask。
第二个 MHA 的输入包含两个:\(X_{key\_value}\) 是 Encoder 的输出,来自原文,\(X_{query}\) 是上一层 DecoderLayer 的输出,来自译文。Padding mask 针对键值对,所以应该采用 \(mask_{in}\) 为 mask;而且在翻译时,我们知道原文的全部信息,因此也不需要其他的 mask。
最后经过 FFN 得到输出。
同样,两个 MHA 以及 FFN 都要在加上 residual connection 过后再过一个 LayerNorm。
Encoder
实现了 EncoderLayer 过后,实现 Encoder 就只需要把 \(N\) 个 EncoderLayer 顺序相接就行了。其中 \(N\) 是超参数。第一个 EncoderLayer 的输入是原文词嵌入,最后一个 EncoderLayer 的输出作为 Encoder 的输出。
Decoder
Decoder 同样是由 \(N\) 个 DecoderLayer 顺序相接而成的。在 Transformer 中,Encoder 和 Decoder 是顺序关系而不是并行关系,因为 Decoder 的输入包含 Encoder 的输出。
Position Embedding
上文经常提及“词嵌入”,原文的词嵌入是 Encoder 的输入,译文的词嵌入是 Decoder 的输入之一。我们可以用 pytorch 很方便地实现普通的词嵌入,但是这里的词嵌入还包含 Position Embedding。
首先翻译是与词的相对位置紧密相关的,尽管我们在 \(X_{input}, X_{output}\) 中将句子中的词按顺序排列,但实际上做矩阵乘法时,这种“顺序”是直接被忽略掉的,在参数看来,这些词就是无序的。我们必须 explicitly 在词嵌入的数值上体现相对位置。
于是我们考虑给第 \(i\) 个词的词嵌入向量(记其长度为 \(l\))加上向量 \(PE_i\),其中
\(PE\) 就称为 Position Embedding。
这里只从相对位置的角度分析选取这种 \(PE\) 的原因,实际上有很多原因导致最终选取三角函数形式的 \(PE\)。考虑一个固定的相对距离 \(k\),观察 \(PE_{i,j}\) 和 \(PE_{(i+k),j}\),不妨设 \(j\) 是偶数:
这里 \(C_1,C_2\) 都是常数。也即 \(PE_{i+k}\) 可以用 \(PE_{i}\) 的项线性表出。原作者认为这种线性关系很容易训练得到。
补充:LayerNorm
Transformer 里没有用 BatchNorm 而是用的 LayerNorm,笔者暂时没有弄清楚原因。按理来说 BatchNorm 只是在 RNN 这类序列化计算的模型上存在理论问题,在 Transformer 中,序列计算的序列长度是常数 \(N\),不应该是这个原因。不论如何,先阐释 LayerNorm 是什么。
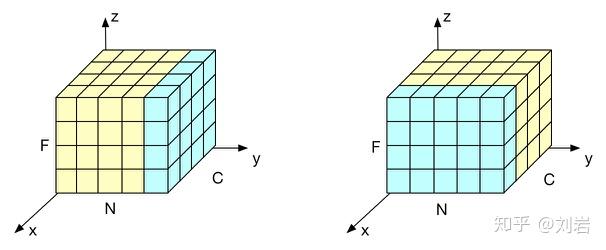
在一个 batch 的数据中,每个 sample 的数据包含若干个特征向量。在 BatchNorm 中,我们是对所有 sample 中的同一个特征向量归一化。而在 LayerNorm 中,我们是对一个 sample 中的所有特征向量归一化。模型优化之Layer Normalization(知乎)中的这张图片非常清晰地表明了这一区别,其中 \(N\) 维度代表不同 sample,\(C\) 维度代表不同特征向量,每个特征向量有 \(F\) 维。左图是 LayerNorm,右图是 BatchNorm。
Transformer的pytorch实现
这里的实现很大程度上参考了 LANGUAGE TRANSLATION WITH NN.TRANSFORMER AND TORCHTEXT,主要是与 Transformer 无关的部分。
笔者认为重要的部分已经写了注释,其他问题可以在评论区提出。
embed.py,包括封装的pytorch自带的词嵌入以及PositionEmbedding
import torch
import torch.nn as nn
import math
class TokenEmbedding(nn.Module):
"""
利用Pytorch生成指定长度的原始词嵌入
"""
def __init__(self, vocab_size, embed_size):
super(TokenEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.embed_size = embed_size
def forward(self, x):
return self.embedding(x.long()) * math.sqrt(self.embed_size)
class PositionEmbedding(nn.Module):
"""
生成至多包含max_num_words个词的Position Embedding
"""
def __init__(self, d_model, max_num_words=1000, p_drop=0.1):
super(PositionEmbedding, self).__init__()
# 计算Position Embedding,储存在 self.additive中
temp:torch.Tensor = torch.arange(d_model) // 2 * 2 / d_model
temp = torch.pow(10000, -temp)
additive = torch.arange(max_num_words).view(-1, 1)
additive = additive.repeat(1, d_model)
additive = additive / temp
additive[:, 0::2] = torch.sin(additive[:, 0::2])
additive[:, 1::2] = torch.sin(additive[:, 1::2])
self.additive = nn.Parameter(additive, requires_grad=False)
self.dropout = nn.Dropout(p_drop)
def forward(self, x):
len_x = x.size()[1]
# 截取所需长度的Position Embedding,并通过Dropout
return self.dropout(self.additive[:len_x] + x)
attention.py,实现了SDA
import torch
import torch.nn as nn
import math
NEG_INF = float("-inf")
class ScaledDotProductAttention(nn.Module):
def __init__(self,
d_model: int,
d_query_key: int,
d_value: int):
"""
:param d_model: 输入的特征向量的长度
:param d_query_key: 键以及询问的向量表示的长度
:param d_value: 值的向量表示的长度
"""
super(ScaledDotProductAttention, self).__init__()
self.wk = nn.Parameter(torch.zeros((d_model, d_query_key)))
self.wq = nn.Parameter(torch.zeros((d_model, d_query_key)))
self.wv = nn.Parameter(torch.zeros((d_model, d_value)))
self.div = math.sqrt(d_query_key) # 储存以加速
self.softmax = nn.Softmax(dim=2)
def forward(self,
mask: torch.Tensor,
x_key_value: torch.Tensor,
x_query: torch.Tensor=None):
"""
:param mask: 一个 bool Tensor,与博客中不同的是它为 true 的地方是表示允许分配注意力,而为 false 的地方是不允许分配注意力。
:param x_key_value: 键值对
:param x_query: 询问
:return: 询问中每个词询问的结果,是value向量的加权和
"""
if x_query == None:
x_query = x_key_value
k = x_key_value @ self.wk
q = x_query @ self.wq
v = x_key_value @ self.wv
mat = torch.einsum("nik, njk -> nij", q, k) / self.div
mat = torch.where(mask, mat, NEG_INF) # 这里 true 是通过,false 的地方设为 -inf 则在 softmax 后为 0
portion = self.softmax(mat)
return torch.einsum("nij, njk -> nik", portion, v)
sublayers.py,包括上文提及的sub-layer:FFN, MDA
"""
sublayers.py 实现了 FFN 和 MDA。
由于所有的 sub-layer 都需要先加上 residual connection 然后再经过 LayerNorm,在这里就直接把这两个过程实现了。
"""
import torch
import torch.nn as nn
from model.attention import ScaledDotProductAttention
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model: int, d_ffn: int, p_drop: float=0.1):
"""
:param d_model: 在这里是上一层 MHA 输出的value向量的长度
:param d_ffn: 中间层的长度
:param p_drop: Dropout参数
"""
super(PositionWiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ffn)
self.linear2 = nn.Linear(d_ffn, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p_drop)
def forward(self, x: torch.Tensor):
# Linear
additive = self.linear2(torch.relu(self.linear1(x)))
# Dropout
additive = self.dropout(additive)
# Residual Connection
x = x + additive
# Layer Normalization
return torch.layer_norm(x, normalized_shape=x.size()[1:])
class MultiHeadAttention(nn.Module):
def __init__(self,
num_heads: int,
d_model: int,
p_drop: float=0.1):
"""
:param num_heads: 博客以及原文中的 h,堆叠的 SDA 的数量
:param d_model: 输入的特征向量长度,实际上由于 residual connection,这就是词\
嵌入的长度
:param p_drop: Dropout参数
"""
super(MultiHeadAttention, self).__init__()
self.attentions = nn.ModuleList(
ScaledDotProductAttention(d_model,
d_model // num_heads,
d_model // num_heads)
for _ in range(num_heads)
) # 直接创建 h 个 SDA
self.wo = nn.Parameter(torch.zeros((d_model, d_model)))
self.dropout = nn.Dropout(p_drop)
def forward(self,
mask: torch.Tensor,
x_key_value: torch.Tensor,
x_query: torch.Tensor=None):
# h x SDAs
res = torch.concatenate([func(mask, x_key_value, x_query)
for func in self.attentions], dim=2)
# Dropout & Residual Connection
# 对于 Encoder,只有一个输入,而 Decoder 有两个输入,residual connection 使用
# 来自 Decoder 的输入
res = self.dropout(res @ self.wo) \
+ x_key_value if x_query is None else x_query
# Layer Normalization
return torch.layer_norm(res, normalized_shape=res.size()[1:])
layers.py,包括EncoderLayer和DecoderLayer
from model.sublayers import *
import torch.nn as nn
class EncoderLayer(nn.Module):
def __init__(self,
num_heads: int,
d_model: int,
d_ffn: int,
p_drop: float=0.1):
"""
:param num_heads: MHA中的并行SDA数量
:param d_model: 输入特征向量的长度,实际上就是词嵌入的长度
:param d_ffn: FFN的隐层的维数
:param p_drop: Dropout参数
"""
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(num_heads, d_model, p_drop)
self.feed_forward = PositionWiseFeedForward(d_model, d_ffn, p_drop)
def forward(self,
mask: torch.Tensor,
x: torch.Tensor):
"""
:param mask: 原文的Padding mask
:param x: 上一层EncoderLayer的输出/原文词嵌入
"""
x = self.attention(mask, x)
return self.feed_forward(x)
class DecoderLayer(nn.Module):
def __init__(self,
num_heads: int,
d_model: int,
d_ffn: int,
p_drop: float=0.1):
"""
:param num_heads: MHA中的并行SDA数量
:param d_model: 输入特征向量的长度,实际上就是词嵌入的长度
:param d_ffn: FFN的隐层的维数
:param p_drop: Dropout参数
"""
super(DecoderLayer, self).__init__()
self.masked_attention = MultiHeadAttention(num_heads, d_model, p_drop)
self.attention = MultiHeadAttention(num_heads, d_model, p_drop)
self.feed_forward = PositionWiseFeedForward(d_model, d_ffn, p_drop)
def forward(self,
padding_mask: torch.Tensor,
mask: torch.Tensor,
x_decoder: torch.Tensor,
x_encoder: torch.Tensor):
"""
:param padding_mask: 第二个MHA的mask,针对x_encoder,所以应该传入\
mask_input
:param mask: 第二个MHA,即mask-MHA的mask,针对 x_decoder,包含了\
mask_output和mask_pred
:param x_decoder: 上一层DecoderLayer的输出/译文词嵌入
:param x_encoder: 来自Encoder的输入
"""
x_decoder = self.masked_attention(mask, x_decoder)
x_decoder = self.attention(padding_mask, x_encoder, x_decoder)
return self.feed_forward(x_decoder)
transformer.py,包括Encoder,Decoder和完整封装的Transformer
from model.layers import *
from model.embed import *
class Encoder(nn.Module):
def __init__(self,
num_layers: int,
num_heads: int,
d_model: int,
d_ffn: int,
p_drop: float=0.1):
super(Encoder, self).__init__()
self.layers = nn.ModuleList(
EncoderLayer(num_heads, d_model, d_ffn, p_drop)
for _ in range(num_layers)
)
def forward(self,
padding_mask: torch.Tensor,
src: torch.Tensor):
for layer in self.layers:
src = layer(padding_mask, src)
return src
class Decoder(nn.Module):
def __init__(self,
num_layers: int,
num_heads: int,
d_model: int,
d_ffn: int,
p_drop: float=0.1):
super(Decoder, self).__init__()
self.layers = nn.ModuleList(
DecoderLayer(num_heads, d_model, d_ffn, p_drop)
for _ in range(num_layers)
)
def forward(self,
padding_mask: torch.Tensor,
mask: torch.Tensor,
tgt: torch.Tensor,
encoder_out: torch.Tensor):
for layer in self.layers:
tgt = layer(padding_mask, mask, tgt, encoder_out)
return tgt
class Transformer(nn.Module):
def __init__(self,
num_encoder_layers: int,
num_decoder_layers: int,
num_heads: int,
src_vocab_size: int,
tgt_vocab_size: int,
d_model: int,
d_ffn: int,
p_drop: float=0.1,
max_num_words: int=None):
"""
:param num_encoder_layers: EncoderLayer的数量
:param num_decoder_layers: DecoderLayer的数量,理论上可以和EncoderLayer不同
:param num_heads: MHA中的并行SDA数量
:param src_vocab_size: 原文的单词库大小,用于构建pytorch自带的Embedding
:param tgt_vocab_size: 译文的单词库大小,用于构建pytorch自带的Embedding
:param d_model: 词嵌入的维数,由于residual connection的存在,这一维数是整个\
transformer中大多数特征向量的维数
:param d_ffn: FFN隐层的维数
:param p_drop: Dropout参数,一般取0.1
:param max_num_words: 最大允许的单个sample包含的token数量,用于初始化\
Position Embedding
"""
super(Transformer, self).__init__()
self.src_tok_embed = TokenEmbedding(src_vocab_size, d_model)
self.tgt_tok_embed = TokenEmbedding(tgt_vocab_size, d_model)
if max_num_words is None:
self.pos_embed = PositionEmbedding(d_model, p_drop=p_drop)
else:
self.pos_embed = PositionEmbedding(d_model, max_num_words, p_drop)
# 这里是原文的一个设计:并行的SDA中的特征向量(key,value,query)的维度都设计为
# d_model/num_heads,从而降低计算量
assert d_model % num_heads == 0
self.encoder = Encoder(num_encoder_layers, num_heads, d_model, d_ffn,
p_drop)
self.decoder = Decoder(num_decoder_layers, num_heads, d_model, d_ffn,
p_drop)
self.linear = nn.Linear(d_model, tgt_vocab_size)
def forward(self,
src_padding_mask: torch.Tensor,
tgt_padding_mask: torch.Tensor,
src: torch.Tensor,
tgt: torch.Tensor):
"""
:param src_padding_mask: 原文的Padding mask
:param tgt_padding_mask: 译文的Padding mask
:param src: 原文(经过tokenize)
:param tgt: 译文(经过tokenize)
:return: 对于译文下一个词的预测scores
"""
src_embed = self.pos_embed(self.src_tok_embed(src))
tgt_embed = self.pos_embed(self.tgt_tok_embed(tgt))
encoder_padding_mask = src_padding_mask.expand(-1, src.size()[1], -1)
encoder_out = self.encoder(encoder_padding_mask, src_embed)
decoder_mask = torch.tril(tgt_padding_mask.expand(-1, tgt.size()[1], -1))
decoder_padding_mask = src_padding_mask.expand(-1, tgt.size()[1], -1)
decoder_out = self.decoder(decoder_padding_mask, decoder_mask,
tgt_embed, encoder_out)
return self.linear(decoder_out)
最后附上训练的代码,这一部分的前面是抄的,具体细节可以不管……可能是笔者没有精细调参的原因(原文采用了“warm step”的调参方法,但是考虑到笔者并没有采用太大的数据集,就没有实现这种方法),loss卡在 \(4\) 附近下不去了,希望大家能把自己的训练结果以及调参方法分享一下。
main.py,训练代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn.utils.rnn import pad_sequence
from torch.utils.data import DataLoader
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from torchtext.datasets import multi30k, Multi30k
from typing import Iterable, List
from model.transformer import Transformer
import pickle
import os
"""
Initializations and Definitions
"""
multi30k.URL["train"] = "https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/training.tar.gz"
multi30k.URL["valid"] = "https://raw.githubusercontent.com/neychev/small_DL_repo/master/datasets/Multi30k/validation.tar.gz"
torch.manual_seed(0)
SRC_LANGUAGE = "de"
TGT_LANGUAGE = "en"
UNK_IDX, PAD_IDX, BOS_IDX, EOS_IDX = 0, 1, 2, 3
special_symbols = ['<unk>', '<pad>', '<bos>', '<eos>']
token_transform = {}
vocab_transform = {}
text_transform = {}
def yield_tokens(data_iter: Iterable, language: str) -> List[str]:
language_index = {SRC_LANGUAGE: 0, TGT_LANGUAGE: 1}
for data_sample in data_iter:
yield token_transform[language](data_sample[language_index[language]])
def sequential_transforms(*transforms):
def func(text):
for transform in transforms:
text = transform(text)
return text
return func
def tensor_transform(token_ids: List):
return torch.cat([torch.Tensor([BOS_IDX]),
torch.Tensor(token_ids),
torch.Tensor([EOS_IDX])])
def collate_fn(batch):
src_batch, tgt_batch = [], []
for src_sample, tgt_sample in batch:
src_batch.append(text_transform[SRC_LANGUAGE](src_sample.rstrip('\n')))
tgt_batch.append(text_transform[TGT_LANGUAGE](tgt_sample.rstrip('\n')))
src_batch = pad_sequence(src_batch, padding_value=PAD_IDX)
tgt_batch = pad_sequence(tgt_batch, padding_value=PAD_IDX)
return src_batch, tgt_batch
if not os.path.exists(r".\token_transforms.pkl"):
token_transform[SRC_LANGUAGE] = get_tokenizer("spacy",
language="de_core_news_sm")
token_transform[TGT_LANGUAGE] = get_tokenizer("spacy",
language="en_core_web_sm")
train_iter = Multi30k(split="train",
language_pair=(SRC_LANGUAGE, TGT_LANGUAGE))
vocab_transform[SRC_LANGUAGE] = build_vocab_from_iterator(
yield_tokens(train_iter, SRC_LANGUAGE),
min_freq=1,
specials=special_symbols,
special_first=True
)
vocab_transform[TGT_LANGUAGE] = build_vocab_from_iterator(
yield_tokens(train_iter, TGT_LANGUAGE),
min_freq=1,
specials=special_symbols,
special_first=True
)
vocab_transform[SRC_LANGUAGE].set_default_index(UNK_IDX)
vocab_transform[TGT_LANGUAGE].set_default_index(UNK_IDX)
with open(r".\token_transforms.pkl", "wb") as f:
pickle.dump((token_transform, vocab_transform), f)
else:
with open(r".\token_transforms.pkl", "rb") as f:
token_transform, vocab_transform = pickle.load(f)
for ln in [SRC_LANGUAGE, TGT_LANGUAGE]:
# So that the words not contained in the dictionary will be indexed as UNK
text_transform[ln] = sequential_transforms(token_transform[ln],
vocab_transform[ln],
tensor_transform)
def calc_padding_mask(batch: torch.Tensor):
padding_mask = torch.unsqueeze(batch != PAD_IDX, dim=1)
return padding_mask
"""
Hyper-parameters
"""
SRC_VOCAB_SIZE = len(vocab_transform[SRC_LANGUAGE])
TGT_VOCAB_SIZE = len(vocab_transform[TGT_LANGUAGE])
D_MODEL = 512
D_FNN = 512
NUM_HEADS = 8
NUM_ENCODER_LAYERS = 3
NUM_DECODER_LAYERS = 3
BATCH_SIZE = 128
DEVICE = "cuda"
"""
Training
"""
print("Begin training.")
model = Transformer(NUM_ENCODER_LAYERS,
NUM_DECODER_LAYERS,
NUM_HEADS,
SRC_VOCAB_SIZE,
TGT_VOCAB_SIZE,
D_MODEL,
D_FNN)
for p in model.parameters():
if p.dim() > 1:
torch.nn.init.xavier_uniform_(p)
model = model.to(DEVICE)
loss_fn = nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimizer = optim.Adam(model.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
def train_epoch(model, optimizer, output_per_batch=None):
model.to(DEVICE)
model.train()
train_iter = Multi30k(split="train",
language_pair=(SRC_LANGUAGE, TGT_LANGUAGE))
train_dataloader = DataLoader(train_iter, batch_size=BATCH_SIZE,
collate_fn=collate_fn)
total_loss = 0
total_batch = 0
for batch_id, (src, tgt) in enumerate(train_dataloader):
total_batch += 1
optimizer.zero_grad()
src = src.T.to(DEVICE)
tgt = tgt.T.to(DEVICE)
tgt_input = tgt[:, :-1]
tgt_output = tgt[:, 1:]
src_padding_mask = calc_padding_mask(src)
tgt_padding_mask = calc_padding_mask(tgt_input)
scores = model(src_padding_mask, tgt_padding_mask, src, tgt_input)
num_candidates = scores.size()[-1]
loss = loss_fn(scores.reshape(-1, num_candidates),
tgt_output.long().reshape(-1))
loss.backward()
optimizer.step()
total_loss = total_loss + loss.item()
if output_per_batch is not None and batch_id % output_per_batch == 0:
print(f"Batch {batch_id}: loss = {loss.item()}"
f" avg_loss = {total_loss / (total_batch)}")
return total_loss / total_batch
def evaluate(model: Transformer):
model.eval()
val_iter = Multi30k(split="valid",
language_pair=(SRC_LANGUAGE, TGT_LANGUAGE))
val_dataloader = DataLoader(val_iter, batch_size=BATCH_SIZE,
collate_fn=collate_fn)
total_loss = 0
total_batch = 0
for src, tgt in val_dataloader:
total_batch += 1
optimizer.zero_grad()
src = src.T.to(DEVICE)
tgt = tgt.T.to(DEVICE)
tgt_input = tgt[:, :-1] # 删去最后一个词作为输入
tgt_output = tgt[:, 1:] # 删去第一个词作为输出
src_padding_mask = calc_padding_mask(src)
tgt_padding_mask = calc_padding_mask(tgt_input)
scores = model(src_padding_mask, tgt_padding_mask, src, tgt_input)
num_candidates = scores.size()[-1]
loss = loss_fn(scores.reshape(-1, num_candidates),
tgt_output.long().reshape(-1))
loss.backward()
optimizer.step()
total_loss = total_loss + loss.item()
return total_loss / total_batch
total_epoch = 10
for epoch in range(total_epoch):
print(f"Epoch {epoch + 1} / {total_epoch}:")
avg_loss = train_epoch(model, optimizer, 1)
optimizer.param_groups[0]["lr"] /= 10
print(f"Epoch {epoch + 1} done, avg_loss = {avg_loss}")
THE END
- Transformer 架构 pytorchtransformer架构pytorch transformer架构pytorch mamba ai_pytorch_transformer pytorch-vanilla transformer pytorch vanilla ai_pytorch_transformer transformer pytorch ai transformer tensorflow pytorch gpt transformer模型 研究生pytorch transformer深度pytorch 10.7 transformer架构 总体 transformer pytorch代码11.2