一、选题课程背景
在当前的房地产市场中,二手房交易一直是一个备受关注的话题。通过对二手房市场的数据进行分析可以帮助我们了解房地产市场的发展趋势、价格变动、供需关系等重要信息。这种数据分析能够为政府制定相关政策、投资者做出决策、购房者选择合适房产等提供有价值的参考。
二、选题意义
在房地产市场中,二手房数据是非常重要的市场参考指标。通过对二手房数据的分析,可以了解各区域房价的趋势、热门小区、房型偏好等信息,对于购房者、房地产开发商和政府部门都具有重要的指导意义。因此,通过爬取贝壳或链家网站上的二手房数据,并对这些数据进行预处理和分析,可以为相关人员提供有价值的信息支持。
本案例旨在通过Python编程语言,结合网络爬虫技术,实现对北京市东城区、海淀区、通州区、怀柔区的在售二手房数据的获取和分析。
通过本案例,可以深入了解北京市不同区域的二手房市场情况,为购房者提供决策支持,为房地产开发商提供市场调研参考,也可以为政府部门提供房地产市场监测数据,具有重要的实际应用意义。同时,通过Python程序设计,可以锻炼数据处理和分析的能力,提高对Python编程语言和数据处理工具的熟练程度。
三、数据集简介
此数据集是爬取的是链家网("http://bj.lianjia.com")北京市地区的二手房源销售信息数据,这些数据可以帮助我们了解二手房市场的交易情况,例如成交价格、成交时间、户型、面积等等。通过分析这些数据,我们可以对二手房市场进行深入研究,包括市场趋势、价格走势、购房者的行为习惯等等。
四、数据准备
4.1获取数据集
使用 Python 爬虫从贝壳或链家网站中获取北京市东城区、海淀区、通州区、怀柔区的在售二手房数据,并将其保存为.csv格式进行存储数据。
(1)观察网页源代码
发现与房子相关的信息主要在div标签中class为houseInfo、positionInfo、totalPrice、unitPrice及tag中出现,故将其提取出来
import requests
from bs4 import BeautifulSoup
import csv
def extract_house_info(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
house_info = []
position_info = []
prices = []
tags = []
# 寻找houseInfo标签
house_info_divs = soup.find_all('div', class_='houseInfo')
for div in house_info_divs:
house_info.append(div.text.strip())
# 寻找positionInfo标签
position_info_divs = soup.find_all('div', class_='positionInfo')
for div in position_info_divs:
position_info.append(div.text.strip())
# 寻找totalPrice和unitPrice标签
price_divs = soup.find_all('div', class_='totalPrice') + soup.find_all('div', class_='unitPrice')
for div in price_divs:
prices.append(div.text.strip())
# 寻找tag标签
tag_divs = soup.find_all('div', class_='tag')
for div in tag_divs:
tags.append(div.text.strip())
# 将提取的信息写入CSV文件
with open('house_bj.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["House Info", "Position Info", "Price", "Tags"]) # 写入表头
for info, pos, price, tag in zip(house_info, position_info, prices, tags):
writer.writerow([info, pos, price, tag]) # 写入数据行
# 使用函数提取信息
url = "http://bj.lianjia.com/xiaoqu/1111027377435/"
extract_house_info(url)特别的是,在tag中,出现的是房子的特色信息,在这里仅将特定类“taxfree”和“subway”提取出来处理
(2)观察url格式
由于我们需要大量的数据,共需要3000条以上,故需要循环迭代读入每一页的内容,经观察发现,链家二手房北京地区的url格式为:https://bj.lianjia.com/ershoufang/(区名)/(页号)故采用双层循环格式,最外层循环为四地区,内层循环为页号,代码如下:
#for j in np.arange(1,int(total_page)+1):
page_url=url+'pg'+str(j)
print (page_url)
page_html=urlopen(page_url)
page_bsObj=BeautifulSoup(page_html,features="lxml")
info=page_bsObj.findAll("div",{"class":"houseInfo"})#提取对应文本信息
position_info=page_bsObj.findAll("div",{"class":"positionInfo"})
totalprice=page_bsObj.findAll("div",{"class":"totalPrice"})
unitprice=page_bsObj.findAll("div",{"class":"unitPrice"})
tagList=page_bsObj.findAll("div",{"class":"tag"})
#print(tagList[0].get_text())
#print(position_info[0].get_text())
For i_info,i_pinfo,i_tp,i_up,i_tag in zip(info,position_info,totalprice,unitprice,tagList):
#在houseInfo中,0是大小,n室n厅,1是面积,2是房屋开向,3是房屋装修程度,4是房屋高度,5是房屋年份,6是房屋类型其中,info,position_info,totalPrice,unitPrice,tag为信息所在的类
(3)观察类内数据格式
可以看出,houseInfo内数据都由“|”号隔开,故提取每一格内数据,且通过进一步观察发现,最多只会有6个|,故将此作为数据提取的限定条件
house_type=i_info.get_text().replace(' ','').split('|')[0]#房屋种类
house_area=i_info.get_text().replace(' ','').split('|')[1]#面积
house_direction=i_info.get_text().split('|')[2].replace(' ','')#朝向
house_decorating=i_info.get_text().split('|')[3]#装修
house_floor=i_info.get_text().split('|')[4]#层数
house_year=i_info.get_text().split('|')[5]#年份
house_build_type=i_info.get_text().split('|')[6]#楼种
#位置相关信息
house_loc=(i_pinfo.get_text().replace(' ','').split('-')[0])#小区
house_position=(i_pinfo.get_text().replace(' ','').split('-')[1])#街道
#价格相关信息
t_price=i_tp.span.string#总价
u_price=re.sub('\D','',i_up.get_text())#单价
#tag相关信息
temp=i_tag.find("span", {"class": "subway"})
if temp is not None:
isSubway=temp.get_text()#是否近地铁
else:
isSubway="None"
temp=i_tag.find("span", {"class": "taxfree"})
if temp is not None:Tag标签内相对比较特殊的是,subway和taxfree标签不是每次都有的,若有,只需提取标签内内容即可[对于subway,有内容则设为yes],没有则设为缺省值[“NONE”/“NO”]
- 提取出来的数据总览:
字段属性:共14类
house_data = house_data.append({
u'城区': chengqu[cq],
u'小区名称': house_loc,
u'房型': house_type,
u'面积': house_area,
u'朝向': house_direction,
u'装修': house_decorating,
u'楼种类': house_build_type,
u'楼层': house_floor,
u'建造年份': house_year,
u'位置': house_position,
u'总价': t_price,
u'单价': u_price,
u'距离地铁':isSubway,
u'房本是否满五年':isfangben
}, ignore_index=True)数据条数查看: ,数据未预处理前,有6101条数据,
,数据未预处理前,有6101条数据,
结果保存:
将结果写入”house_bj.csv”文件中
# 将数据保存到CSV中
house_data.to_csv('house_bj.csv', encoding='utf-8', index=None)4.2数据预处理
重复值处理
删除完全相同的重复行,并保留最后一个出现的行:
df=df.drop_duplicates( keep= ' last' )
print(df.shape[e])print(df.shape[e])
经过检查发现没有重复行
缺失值处理
删除有缺失值的行
print(df.isnu11().sum())#检查缺失值
df = df.dropna()#删除所有有缺失值的行对于每列的特殊处理
在数据处理中,很重要的一步就是统一数据类型/格式,尤其是同一列的数据类型/格式,这在后面的建模中会进行进一步处理
先检查所有列的数据类型,进行进一步的判断:

对房本是否满五年列进行处理
从上一步爬虫中可以得知,在此列我们的变量有两种取值“yes”和“no”,将其转换为“0”/“1”变量,方便以后处理
print(df.dtypes)#查看数据类型
df['房本是否满五年']=df['房本是否满五年'].replace('yes', '1')#房本满五年列转为整型,方便后续处理
df['房本是否满五年']=df['房本是否满五年'].replace('no','0')
df['房本是否满五年']=df['房本是否满五年'].astype('float')#转为浮点型对于距离地铁列进行处理
从上一步爬虫中可以得知,在此列我们的变量有两种取值“近地铁”和“None”,将其转换为“0”/“1”变量,方便以后处理
df['距离地铁']=df['距离地铁'].replace('None','0')
df['距离地铁']=df['距离地铁'].replace('近地铁','1')
df['距离地铁']=df['距离地铁'].astype('float')#转为浮点型对于单价列进行处理
将其转换为与总价列相同的浮点型
df['单价']=df['单价'].astype('float')#转为浮点型对于楼层列进行处理
从上一步爬虫所得的csv文件中观察,发现此列有两种类型,一种是标明具体楼层和高中低的,一种是只写了高中低的,还有一种只写了具体楼层的,统一格式,将其中的具体楼层提取出来,若没有具体楼层,则用下列函数所定义的规则填补
 (未处理之前此列数据)
(未处理之前此列数据)
ef extract_floor_number(x):
floors = re.findall(r'\d+', x)
if len(floors) > 0:
return int(floors[0])
else:
if x[0]=="高":
return int(15)
elif x[0]=="顶":
return int(20)
elif x[0]=="中":
return int(8)
else:
return int(3)若当前楼层为高楼层,则认为是15,若为顶楼,则认为是20,若为中楼,则认定为8,若为低楼/底楼,则认为是3
对于面积列进行处理
将面积的数字提取出来,并转换为浮点型(在函数内已处理)
df['面积']=df['面积'].apply(extract_mian_number)#将面积提取出来对于装修列/楼种类列进行处理
对于装修/楼种类类的处理方法类似,由于之前爬虫的时候没有删除空格,在这一步,去除其前面的空格;
df['装修'] = df['装修'].apply(lambda x: x.strip())
df['楼种类']=df['楼种类'].apply(lambda x: x.strip())对于楼种类,删除暂无数据的异常值,先替换为缺省值,待一会处理
对于建造年份列进行处理
将年份字符提取出来,对于无法提取的异常值,则替换为缺省值,待一会统一处理
def extract_year_number(text):
pattern = r"\d+"
match = re.search(pattern, text)
if match:
return int(match.group())
else:
return None删除缺省值
print(df.dtypes)#查看处理后数据结果
print(df.isnull().sum()) #检查缺失值
df = df.dropna()#删除所有有缺失值的行被删除的数据:

查看处理完后数据条数:

查看处理完后数据类型:
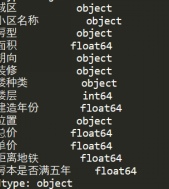
将结果保存为”house_bj_new.csv”文件
df.to_csv('house_bj_new.csv', encoding='utf-8', index=None)4.3数据清理
import pandas as pd
# 读取数据集
data = pd.read_csv('house_bj.csv')
# 数据清洗
# 删除houseInfo和positionInfo中的空值
data = data.dropna(subset=['houseInfo', 'positionInfo'])
# 将totalPrice和unitPrice转换为浮点数
data['totalPrice'] = data['totalPrice'].astype(float)
data['unitPrice'] = data['unitPrice'].astype(float)
# 删除tag中的重复值
data = data.drop_duplicates(subset='tag')
# 保存清洗后的数据集
data.to_csv('house_bj.csv', index=False)一、大数据实验分析
5.1基于 Matplotlib 的数据可视化分析
5.1.1分析四城区总价的特点
图题:

分析
由图可以看出,越靠近市中心的区【东城区和海淀区】,总房价越高;从图中看,房价平均最高的地区是东城区,其次是海淀区,然后是通州区和怀柔区;从数据的波动水平来看,怀柔区和通州区的数据波动程度比海淀区和东城区要小;海淀区和东城区的数据变化程度要高于另外两区;北京市这四区的房价都偏高,大部分都高于500万元
代码展示:
def drawBoxByAll(df):# 绘制各城区房屋的总价箱线图
df.boxplot(column='总价', by='城区')
plt.title('四城区总价箱线图')
plt.xlabel('四区')
plt.ylabel('总价/万元')
plt.show()以总价为纵坐标,城区为横坐标绘制箱线图
5.1.2分析四城区单价的特点:
图题:
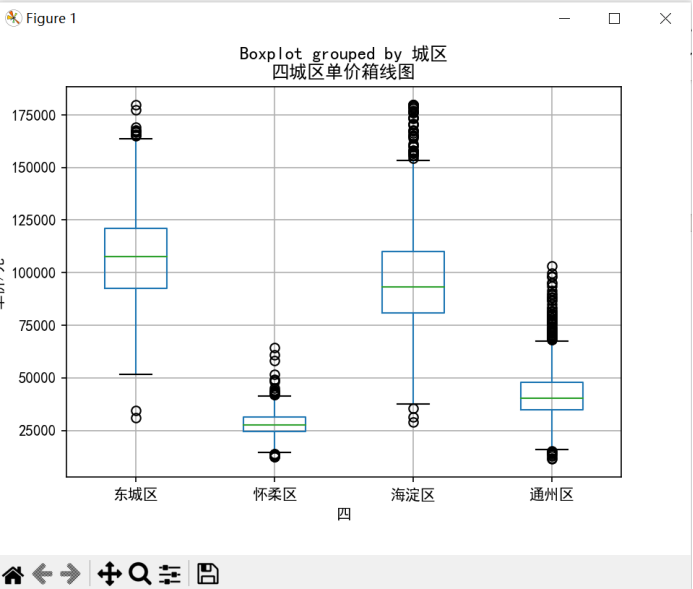
分析:
由图可以看出,四城区中,东城区和海淀区的房价偏高,50%的房子单价都在80000元/平米以上,通州区和怀柔区的房价偏低,怀柔区房价中位数大概在26000元/平米,通州区中位数大概在40000元/平米;东城区和海淀区的数据波动程度较大,通州区其次,怀柔的数据较为稳定
代码展示:
def drawBoxByAll(df):# 绘制各城区房屋的总价箱线图
df.boxplot(column='总价', by='城区')
plt.title('四城区总价箱线图')
plt.xlabel('四区')
plt.ylabel('总价/万元')
plt.show()
def drawBoxByOne(df):# 绘制各城区房屋的单价箱线图
df.boxplot(column='单价', by='城区')
plt.title('四城区单价箱线图')
plt.xlabel('四')
plt.ylabel('单价/元')
plt.show()以总价为纵坐标,四区为横坐标绘制箱线图
5.1.3分析四城区距离地铁远近的特点
图题:

分析:
可以看出,除了通州区,其他三区距离地铁不近的房子数量差不多,但是从比例上看,通州区和怀柔区大部分房子都距离地铁不近,怀柔区甚至没有一个标明离地铁近的房子,海淀区和东城区与其相反,60%左右的房子都距离地铁近,猜测大概是由于位于市中心的原因,地铁线路分布较为密集
代码展示:
def drawisNearSubway(df):#绘制堆叠柱状图
elevator_counts = df.groupby('城区')['距离地铁'].value_counts().unstack()
elevator_counts.plot(kind='bar', stacked=True)
plt.title('四城区距离地铁远近')
plt.text(0.25, 0.95,"1--地铁近\n0--距地铁不近", ha='right', va='top', transform=plt.gca().transAxes)
plt.xlabel('四城区')
plt.ylabel('远近')
plt.show()以城区为组,分别计算距离地铁列中不同取值的个数,绘制堆叠柱状图
5.1.4分析四城区房子种类的特点
图题:
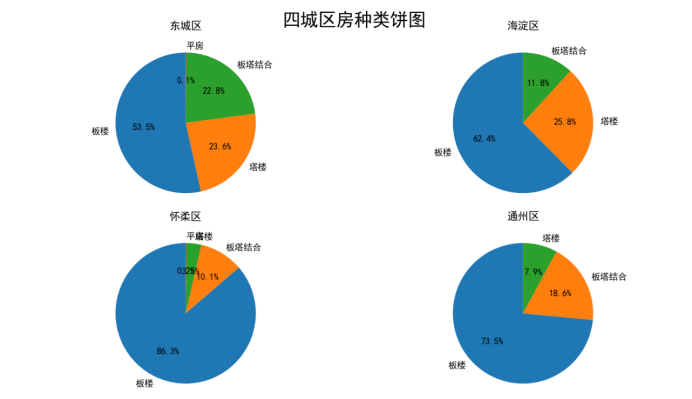
分析:
可以看出,北京这四城区的在售二手房大多都是板楼;东城区和海淀区剩下两个占比较大的部分是塔楼,板塔结合;而怀柔区和通州区剩下两个比较大的部分分别是板塔结合和塔楼,和之前提到两区相反;四区的在售二手房中,平房只占极少的部分,甚至没有平房二手房在售
代码展示:
def drawHouseType(df):#绘制四城区二手房种类饼状图
# 获取所有区域的列表
districts = df['城区'].unique()
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(20, 10), subplot_kw=dict(aspect='equal'))
for ax, district in zip(axes.flatten(), districts):
data = df.loc[df['城区'] == district, '楼种类'].value_counts()
ax.pie(data, labels=data.index, autopct='%1.1f%%', startangle=90)
ax.set_title(district)
fig.suptitle('四城区房种类饼图', fontsize=20)
fig.tight_layout()
plt.show()对于每个城区,分别计算其装修列中不同取值的个数,绘制饼图子图,最后再放置于同一画布中
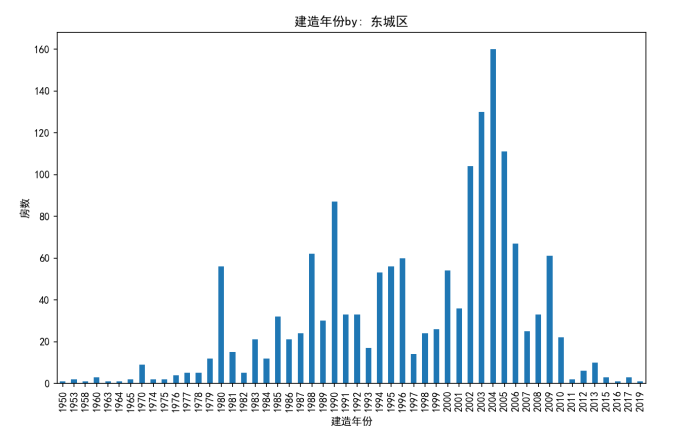
5.1.5分析四城区住房年份的特点
图题
由于各城区的房子年份分布较为复杂,故对每一个城区都分别绘制了住房年份图
东城区住房年份图:
海淀区住房年份图:

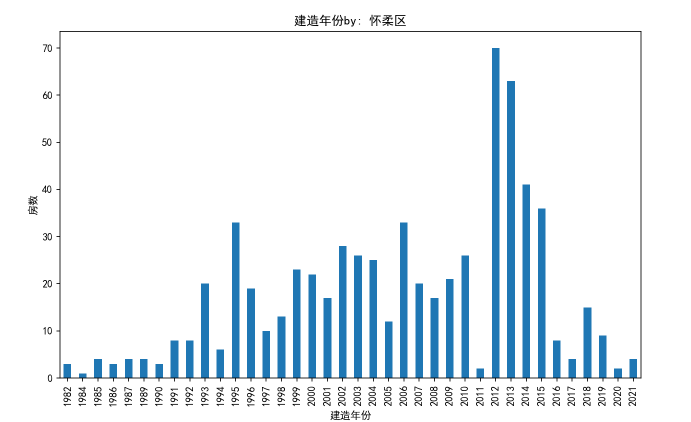
怀柔区住房年份图:
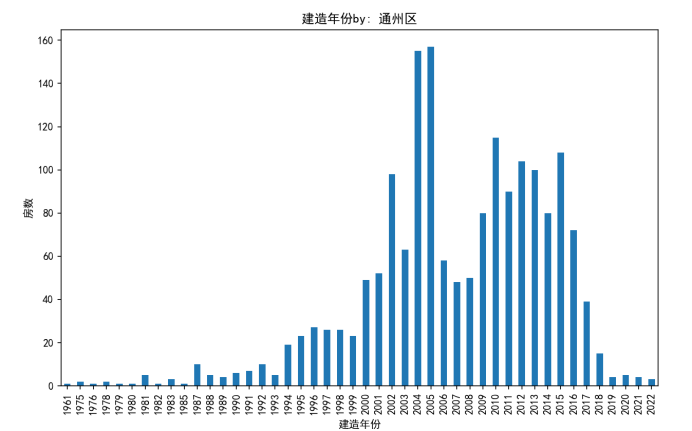
通州区住房年份图:
分析:
可以看出,四城区在售二手房,在二十世纪末二十一世纪末初建的较多,怀柔区相较于其他三区,在售的二手房都较新,最古老的房子只在1980年左右,其他三区的在售房年份跨度都较大,最早的都可以追溯到上世纪中期,这可以体现出北京是一个历史悠久的城市,越靠近市中心的区越有年份较早的房子在售
代码展示:
def drawfindYear(df):#为每个城区分别绘制年份柱状图
districts = df['城区'].unique()
# 遍历每个城区
for district in districts:
data = df[df['城区'] == district]#筛选城区对应数据
plt.figure(figsize=(10, 6))#设置图片大小
data['建造年份'].value_counts().sort_index().plot(kind='bar')#绘制柱状图
plt.title(f"建造年份by: {district}")
plt.xlabel('建造年份')
plt.ylabel('房数')
plt.show()对于每个城区都计算建造年份列中不同取值的个数,然后分别绘制四城区年份柱状图
5.1.6分析四城区装修的特点
图题
柱状图:
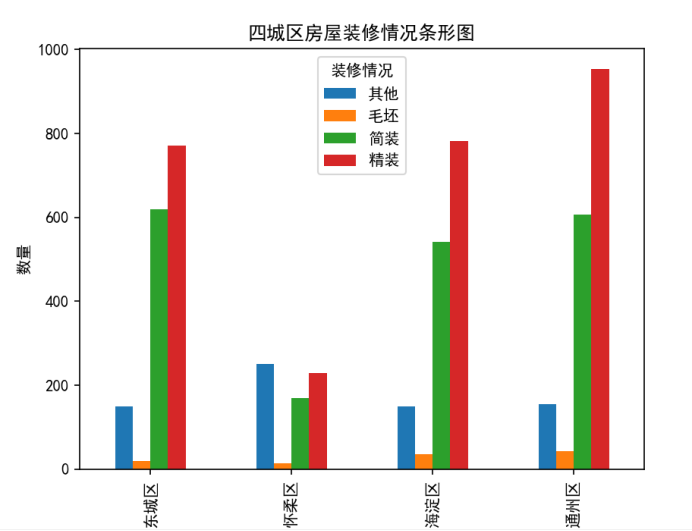
饼状图:
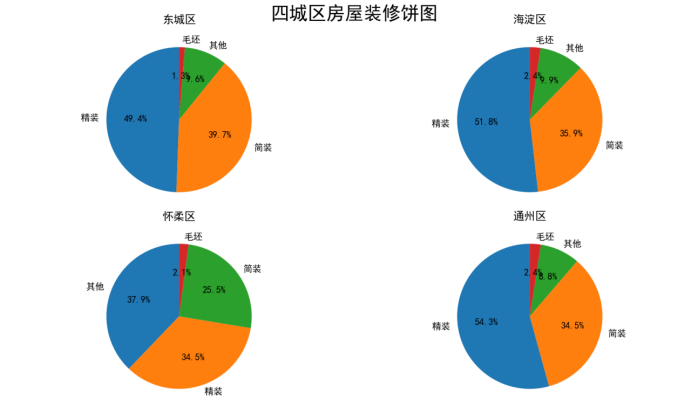
分析:
在上述图中,可以看出,四区在售二手房最多的是精装房,除了怀柔区以外,第二多的就是简装房,怀柔区第二多则是其他类型的装修方式;四城区在售二手房最少的房子装修都是毛坯房;基本在售二手房都是已经装修过的,精装的比简装的多(除怀柔区)这其实可以看出二手房销售的一种特点,基本都是已经装修过的房,而不是买来就是为了炒房的
代码展示:
def drawDecorationByP(df):#使用饼状图绘制四城区的房屋装修情况
districts = df['城区'].unique()
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(20, 10), subplot_kw=dict(aspect='equal'))
for ax, district in zip(axes.flatten(), districts):
data = df.loc[df['城区'] == district, '装修'].value_counts()
ax.pie(data, labels=data.index, autopct='%1.1f%%', startangle=90)
ax.set_title(district)
fig.suptitle('四城区房屋装修饼图', fontsize=20)
fig.tight_layout()
plt.show() 对每个城区都分别计算对应装修列中各取值的个数,并绘制饼图的子图,最后放置于同一画布中
def drawDecorationByC(df):#使用柱状图绘制四城区的房屋装修情况
year_counts = df.groupby('城区')['装修'].value_counts().unstack()#统计不同城区房屋装修情况
year_counts.plot(kind='bar', stacked=False)
plt.title('四城区房屋装修情况条形图')
plt.xlabel('四城区')
plt.ylabel('数量')
plt.legend(title='装修情况')#添加图例
plt.show()对每个城区都分别计算对应装修列中各取值的个数,以城区作为横坐标,城区列中有装修列,数量作为纵坐标绘制图像
总结
在北京市这四区中,房价都偏高,越靠近市中心的区(海淀区/东城区)房价越高;靠近市中心的区销售的二手房靠近地铁的比例较大,反之则较小;当前销售的二手房大多都是在二十世纪末二十一世纪初建造的二手房;当前销售的二手房大多都是已经精装或者简装的(一般来说精装比例略高于简装)当前销售的二手房房子大多都是板楼,少部分为板塔结合,平房和塔楼占比较少
5.2房价与其影响因素分析
5.2.1分析住房面积对二手房总价的影响
图题:
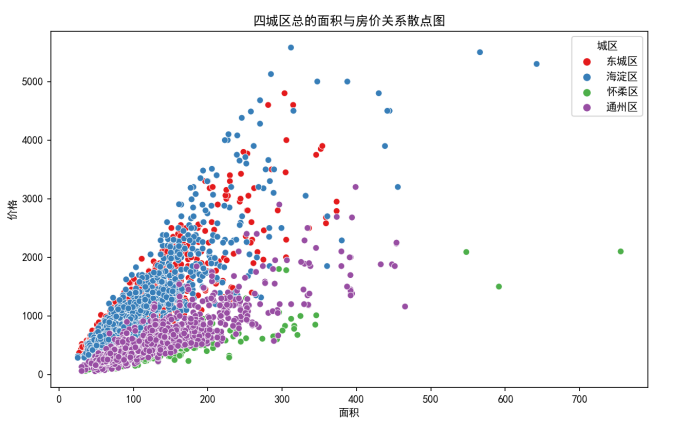
四城区总的面积与总价散点图:
四城区住房面积与房价分别的散点图:

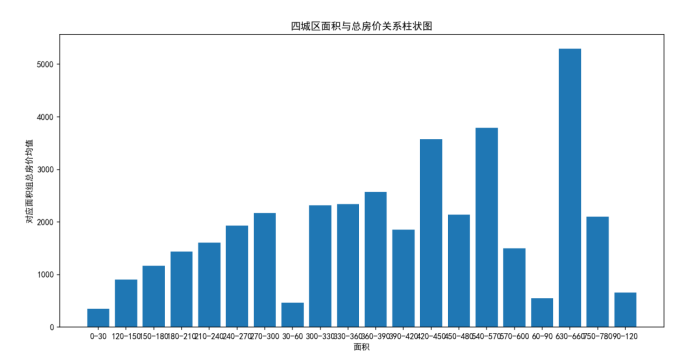
住房平均面积和总价关系图:
分析:
从图上可以看出,住房面积和总价呈正相关的关系,且海淀区和东城区随着面积的增大,二手房房价上升的幅度较高,而怀柔区和通州区相较于这两区,上升的幅度较不高,从柱状图中更可以明显的看出随着面积的增加,四城区房价是在增加的
代码展示:
def draw_p_vs_area_byALL(df):#绘制四城区面积与二手房总价关系散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(data=df, x='面积', y='总价', hue='城区', palette='Set1')
plt.title('四城区总的面积与房价关系散点图')
plt.xlabel('面积')
plt.ylabel('价格')
plt.show()以总价作为纵坐标,横坐标为面积,以城区取值作为点的种类绘制散点图
def draw_p_vs_area_byOne(df):#绘制每一城区房价与面积分别散点图
districts = df['城区'].unique()
fig, axs = plt.subplots(len(districts), figsize=(8, 5 * len(districts)))
for i, district in enumerate(districts):
axs[i].scatter(df[df['城区'] == district]['面积'],
df[df['城区'] == district]['总价'])
axs[i].set_xlabel('面积')
axs[i].set_ylabel('价格')
plt.tight_layout()
plt.title("四城区房价与面积分别的散点图")
plt.show()对每一城区,横坐标为城区对应面积,纵坐标为城区对应房价,分别绘制散点图的子图,最后加入同一画布中
def draw_p_vs_area_byALLbyC(df):#绘制四城区面积与二手房总价关系柱状图
df['平均面积'] = df['面积'].apply(lambda x: str(math.floor(x / 30) * 30) + '-' + str(math.floor(x / 30 + 1) * 30))
average_price = df.groupby('平均面积')['总价'].mean()
plt.bar(average_price.index, average_price.values)
# 设置图表标题和坐标轴标签
plt.title("四城区面积与总房价关系柱状图")
plt.xlabel("面积")
plt.ylabel("对应面积组总房价均值")
# 显示图表
plt.show()对于面积,将面积以30划分为一组(例:0-30,30-60,60-90……),分别计算此范围面积对应的二手房的平均房价,以房价为纵坐标,面积为横坐标,绘制四城区面积与总房价关系柱状图
5.2.2分析住房装修对二手房总价的影响
图题:
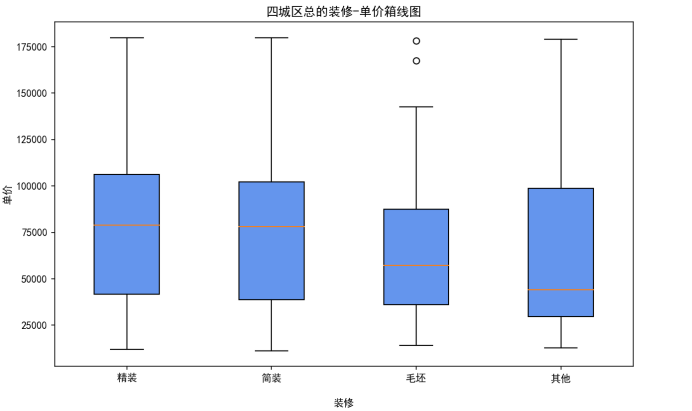
四城区总的装修-总价箱线图:
四城区单位房价-装修折线图:

分析:可以看出,四城区在装修方面,价格的波动程度都较大,四种装修50%左右的单价都在50000~100000/平方米之间,精装和简装的价格稍高于另外两种;从单价和装修的关系来看,可以较为明显的看出精装装修的单位房价较高,其次到简装,毛坯,其他,符合物价规律,精美的价格高
代码展示:
def draw_p_vs_de_byALLbyBox(df):#绘制四城区总的装修种类与二手房单价箱线图
zhuangxiu = [list(df[df['装修'] =="精装" ]["单价"]),
list(df[df['装修'] =="简装" ]["单价"]),
list(df[df['装修'] =="毛坯" ]["单价"]),
list(df[df['装修'] =="其他" ]["单价"])]
plt.figure(figsize=(10,6))
plt.title("四城区总的装修-单价箱线图")
plt.boxplot(zhuangxiu, labels = ['精装', '简装', '毛坯','其他'],patch_artist=True,boxprops={'facecolor':'cornflowerblue'})
plt.xlabel("\n装修")
plt.ylabel('单价')
plt.show()划分四个列表,其中每一列表都存储对应不同种类装修所对应的单价,以装修种类为label,单价为纵坐标绘制箱线图
def draw_p_vs_de_byALLbyLine(df):#绘制四城区总的装修种类及其对应的单位平均房价折线图
mean=[]
zhong=df['装修'].unique()
for i in range (len(zhong)):
per_data = df[ df['装修'] == zhong[i] ]
mean.append(round(per_data['单价'].mean(),2))
plt.figure(figsize=(10,6))
plt.title("四城区单位房价与装修折线图")
plt.plot(range(len(zhong)), mean, '--^', label="单位价格")
plt.xticks(range(len(zhong)), labels =zhong)
plt.legend()
plt.show()分别计算每种装修所对应的二手房单价的平均值,以单价为纵坐标,装修种类为横坐标绘制折线图
总结
从整体来看,面积越大,房价越高,装修越精美,房价越高;靠近市中心的房价随面积的涨幅比距离市中心较远的区大
5.3二手房价格的地理分布特征分析
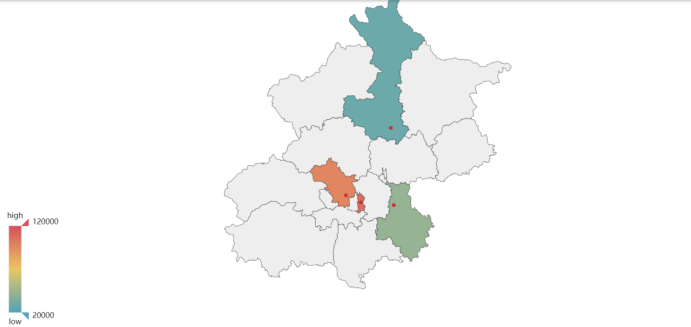
在地图上绘制这四个城区中在售二手房单位面积价格平均值的热力图和在售二手房总金额的热力图,分析二手房价格的地理分布特征。
图题:
在售二手房单位面积价格平均值的热力图:
在售二手房总金额的热力图:
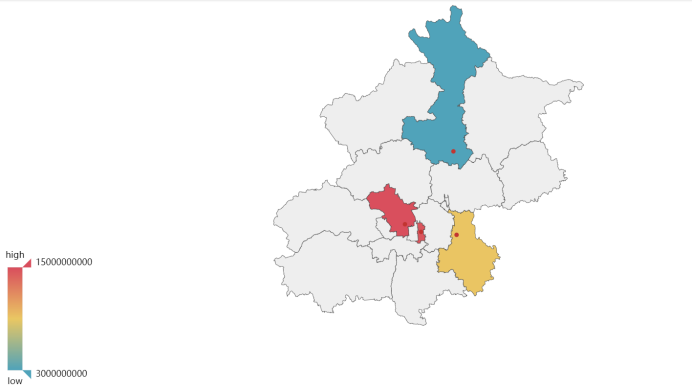
分析:
可以看出,距离市中心越近的区,在售二手房总金额越高,单位面积价格的平均值也越高,因此,东城区房价>/≈海淀区房价>通州区房价>怀柔区房价
代码展示:
绘制在售二手房单位面积平均价格的热力图:
df=pd.read_csv('house_bj_new.csv')
mean=[]
zhong=df['城区'].unique()#四城区名字
for i in range (len(zhong)):
per_data = df[ df['城区'] == zhong[i] ]
mean.append(round(per_data['单价'].mean(),2))#分别获取各城区平均值
map2 = Map("北京地图", '北京', width=1200, height=600)#获取地图
map2.add('北京', zhong, mean, visual_range=[20000,120000], maptype='北京', is_visualmap=True, visual_text_color='#000')#将数据加入,绘制热力图
map2.render(path="在售二手房单位面积价格平均值热力图.html")
先求出每个城区对应二手房的平均面积,指定x轴为北京四区,y轴为二手房平均价格,热力图颜色的取值范围为[12000,120000]绘制在售二手房总金额的热力图:
total_price=[]
zhong=df['城区'].unique()#四城区名字
for i in range (len(zhong)):
per_data = df[ df['城区'] == zhong[i] ]
total_price.append(10000*(round(per_data['总价'].sum(),2)))#分别获取各城区总价值
map1 = Map("北京地图", '北京', width=1200, height=600)#获取地图
map1.add('北京', zhong, total_price, visual_range=[3000000000,15000000000], maptype='北京', is_visualmap=True, visual_text_color='#000')#将数据加入,绘制热力图
map1.render(path="在售二手房总金额热力图.html")
先求出每个城区对应二手房的总金额,指定x轴为北京四区,y轴为二手房总金额,热力图颜色的取值范围[3000000000,15000000000]5.4预测房价
对数据进行处理,将非数值型数据替换为数值型
将楼种类和装修用对应数字替换
newdata[ '楼种类" ]=newdata['楼种类" ].replace('板楼' , 'e')#房本满五年列转为整型,方便后续处理newdata[ '楼种类' ]=newdata['楼种类' ].replace('平房''1')
newdata['楼种类']=newdata[ '楼种类' ].replace('塔楼','2')newdata['楼种类']=newdata['楼种类'j.replace('板塔结合','3')newdata[装修"]=newdata['装修'].replace('其他', 'e')
newdata['装修"]=newdata['装修'j.replace('简装,'1')newdata['装修"]=newdata['装修'j.replace('精装','2')newdata['装修']=newdata['装修'j.replace('毛坯','3')newdata[ '城区']=newdata['城区'j.replace('海淀区','0')newdata['城区'j=newdata['城区'j.replace('东城区,'1')newdata['城区']=newdata['城区'j.replace('通州区','2')newdata['城区'j=newdata'城区'j.replace('怀柔区''3')
newdata['楼种类']=newdata[ '楼种类' ].replace('塔楼','2')newdata['楼种类']=newdata['楼种类'j.replace('板塔结合','3')newdata[装修"]=newdata['装修'].replace('其他', 'e')
newdata[ '楼种类" ]=newdata['楼种类" ].replace('板楼' , 'e')#房本满五年列转为整型,方便后续处理newdata[ '楼种类' ]=newdata['楼种类' ].replace('平房''1')
newdata['楼种类']=newdata[ '楼种类' ].replace('塔楼','2')newdata['楼种类']=newdata['楼种类'j.replace('板塔结合','3')newdata[装修"]=newdata['装修'].replace('其他', 'e')
newdata['装修"]=newdata['装修'j.replace('简装,'1')newdata['装修"]=newdata['装修'j.replace('精装','2')newdata['装修']=newdata['装修'j.replace('毛坯','3')newdata[ '城区']=newdata['城区'j.replace('海淀区','0')newdata['城区'j=newdata['城区'j.replace('东城区,'1')newdata['城区']=newdata['城区'j.replace('通州区','2')newdata['城区'j=newdata'城区'j.replace('怀柔区''3')将房型中的N室M厅提取出来,作为新列room和office出现
#分解房型
def apart_room(x):
room = x.split('室')[O]return int(room)
def apart_hall(x):
hall = x.split(厅')[e].split('室')[1]return int(hal1)删除不必要列
newdata.drop(coLumns=['小区名称','位置','单价','朝向','房型'"], inplace=True)5.5绘制相关系数热力图
通过绘制相关系数热力图,我们可以发现,房型(room和office)与面积,和总价之间的相关系数超过0.6,故选取这三种作为特(选取这三特征原因)
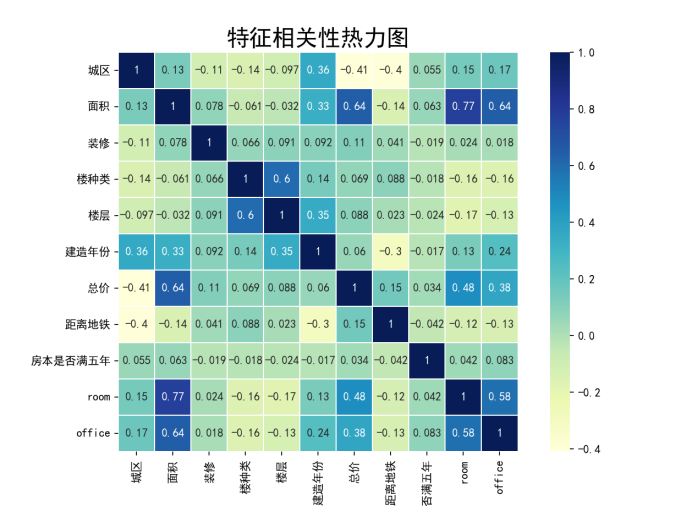
使用决策树模型进行预测,决策树库内置的score结果作为测试集得分:
dt=dt.fit(x_train,y train)
print(f'测试集得分︰{round(dt.score(x_test,y_test),5)}')
六、总结
6.1课程总结
通过python编写网络爬虫程序可以得出在北京市这四区中,房价都偏高,越靠近市中心的区(海淀区/东城区)房价越高;靠近市中心的区销售的二手房靠近地铁的比例较大,反之则较小;当前销售的二手房大多都是在二十世纪末二十一世纪初建造的二手房;当前销售的二手房大多都是已经精装或者简装的(一般来说精装比例略高于简装);当前销售的二手房房子大多都是板楼,少部分为板塔结合,平房和塔楼占比较少。
我个人认为此次课程案例可以帮助消费者对于北京市各城区的二手房选择。
6.2个人总结
在本次课程学习中,通过老师和同学的帮助,我学会了如何使用python进行数据分析,学会了如何对数据进行预处理,对数据可视化,画出各种统计图使实验结果更加清晰明了,更容易理解。提高了自己思维能力和解决问题的能力。
源代码如下:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import re
chengqu={'dongcheng':'东城区'
,'haidian':'海淀区','huairou':'怀柔区',
'tongzhou':'通州区'
}
house_data = pd.DataFrame() # 创建空的DataFrame用于存储数据
for cq in chengqu.keys():#对每一城区分别进行处理
url='https://bj.lianjia.com/ershoufang/'+cq+'/'
html=urlopen(url)
bsObj=BeautifulSoup(html)
total_page=re.sub('\D','',bsObj.find('div','page-box fr').contents[0].attrs['page-data'])[:-1]
print ('total_page',total_page)
for j in np.arange(1,int(total_page)+1):#对每一城区的每一页进行处理
#for j in np.arange(1,int(total_page)+1):
page_url=url+'pg'+str(j)
print (page_url)
page_html=urlopen(page_url)
page_bsObj=BeautifulSoup(page_html,features="lxml")
info=page_bsObj.findAll("div",{"class":"houseInfo"})#提取对应文本信息
position_info=page_bsObj.findAll("div",{"class":"positionInfo"})
totalprice=page_bsObj.findAll("div",{"class":"totalPrice"})
unitprice=page_bsObj.findAll("div",{"class":"unitPrice"})
tagList=page_bsObj.findAll("div",{"class":"tag"})
#print(tagList[0].get_text())
#print(position_info[0].get_text())
for i_info,i_pinfo,i_tp,i_up,i_tag in zip(info,position_info,totalprice,unitprice,tagList):
#在houseInfo中,0是大小,n室n厅,1是面积,2是房屋开向,3是房屋装修程度,4是房屋高度,5是房屋年份,6是房屋类型?
if len(i_info.get_text().split('|'))==7:
#print(i_info.get_text().split('|'))
house_type=i_info.get_text().replace(' ','').split('|')[0]#房屋种类
house_area=i_info.get_text().replace(' ','').split('|')[1]#面积
house_direction=i_info.get_text().split('|')[2].replace(' ','')#朝向
house_decorating=i_info.get_text().split('|')[3]#装修
house_floor=i_info.get_text().split('|')[4]#层数
house_year=i_info.get_text().split('|')[5]#年份
house_build_type=i_info.get_text().split('|')[6]#楼种
#位置相关信息
house_loc=(i_pinfo.get_text().replace(' ','').split('-')[0])#小区
house_position=(i_pinfo.get_text().replace(' ','').split('-')[1])#街道
#价格相关信息
t_price=i_tp.span.string#总价
u_price=re.sub('\D','',i_up.get_text())#单价
#tag相关信息
temp=i_tag.find("span", {"class": "subway"})
if temp is not None:
isSubway=temp.get_text()#是否近地铁
else:
isSubway="None"
temp=i_tag.find("span", {"class": "taxfree"})
if temp is not None:
isfangben="yes"#房本满五年
else:
isfangben="no"
house_data = house_data.append({
u'城区': chengqu[cq],
u'小区名称': house_loc,
u'房型': house_type,
u'面积': house_area,
u'朝向': house_direction,
u'装修': house_decorating,
u'楼种类': house_build_type,
u'楼层': house_floor,
u'建造年份': house_year,
u'位置': house_position,
u'总价': t_price,
u'单价': u_price,
u'距离地铁':isSubway,
u'房本是否满五年':isfangben
}, ignore_index=True)
#print("hhhhhh")
# 将数据保存到CSV中
house_data.to_csv('house_bj.csv', encoding='utf-8', index=None)
from pyecharts import Map
import pandas as pd
df=pd.read_csv('house_bj_new.csv')
mean=[]
zhong=df['城区'].unique()#四城区名字
for i in range (len(zhong)):
per_data = df[ df['城区'] == zhong[i] ]
mean.append(round(per_data['单价'].mean(),2))#分别获取各城区平均值
map2 = Map("北京地图", '北京', width=1200, height=600)#获取地图
map2.add('北京', zhong, mean, visual_range=[20000,120000], maptype='北京', is_visualmap=True, visual_text_color='#000')#将数据加入,绘制热力图
map2.render(path="在售二手房单位面积价格平均值热力图.html")
total_price=[]
zhong=df['城区'].unique()#四城区名字
for i in range (len(zhong)):
per_data = df[ df['城区'] == zhong[i] ]
total_price.append(10000*(round(per_data['总价'].sum(),2)))#分别获取各城区总价值
map1 = Map("北京地图", '北京', width=1200, height=600)#获取地图
map1.add('北京', zhong, total_price, visual_range=[3000000000,15000000000], maptype='北京', is_visualmap=True, visual_text_color='#000')#将数据加入,绘制热力图
map1.render(path="在售二手房总金额热力图.html")
import pandas as pd
import numpy as np
import re
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import math
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体为 SimHei
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
def drawBoxByAll(df):# 绘制各城区房屋的总价箱线图
df.boxplot(column='总价', by='城区')
plt.title('四城区总价箱线图')
plt.xlabel('四区')
plt.ylabel('总价/万元')
plt.show()
def drawBoxByOne(df):# 绘制各城区房屋的单价箱线图
df.boxplot(column='单价', by='城区')
plt.title('四城区单价箱线图')
plt.xlabel('四')
plt.ylabel('单价/元')
plt.show()
def drawisNearSubway(df):#绘制堆叠柱状图
elevator_counts = df.groupby('城区')['距离地铁'].value_counts().unstack()
elevator_counts.plot(kind='bar', stacked=True)
plt.title('四城区距离地铁远近')
plt.text(0.25, 0.95,"1--距地铁近\n0--距地铁不近", ha='right', va='top', transform=plt.gca().transAxes)
plt.xlabel('四城区')
plt.ylabel('远近')
plt.show()
def drawfindYear(df):#为每个城区分别绘制年份柱状图
districts = df['城区'].unique()
# 遍历每个城区
for district in districts:
data = df[df['城区'] == district]#筛选城区对应数据
plt.figure(figsize=(10, 6))#设置图片大小
data['建造年份'].value_counts().sort_index().plot(kind='bar')#绘制柱状图
plt.title(f"建造年份by: {district}")
plt.xlabel('建造年份')
plt.ylabel('房数')
plt.show()
def drawHouseType(df):#绘制四城区二手房种类饼状图
# 获取所有区域的列表
districts = df['城区'].unique()
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(20, 10), subplot_kw=dict(aspect='equal'))
for ax, district in zip(axes.flatten(), districts):
data = df.loc[df['城区'] == district, '楼种类'].value_counts()
ax.pie(data, labels=data.index, autopct='%1.1f%%', startangle=90)
ax.set_title(district)
fig.suptitle('四城区房种类饼图', fontsize=20)
fig.tight_layout()
plt.show()
def drawDecorationByP(df):#使用饼状图绘制四城区的房屋装修情况
districts = df['城区'].unique()
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(20, 10), subplot_kw=dict(aspect='equal'))
for ax, district in zip(axes.flatten(), districts):
data = df.loc[df['城区'] == district, '装修'].value_counts()
ax.pie(data, labels=data.index, autopct='%1.1f%%', startangle=90)
ax.set_title(district)
fig.suptitle('四城区房屋装修饼图', fontsize=20)
fig.tight_layout()
plt.show()
def drawDecorationByC(df):#使用柱状图绘制四城区的房屋装修情况
year_counts = df.groupby('城区')['装修'].value_counts().unstack()#统计不同城区房屋装修情况
year_counts.plot(kind='bar', stacked=False)
plt.title('四城区房屋装修情况条形图')
plt.xlabel('四城区')
plt.ylabel('数量')
plt.legend(title='装修情况')#添加图例
plt.show()
def draw_p_vs_area_byALL(df):#绘制四城区面积与二手房总价关系散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(data=df, x='面积', y='总价', hue='城区', palette='Set1')
plt.title('四城区总的面积与房价关系散点图')
plt.xlabel('面积')
plt.ylabel('价格')
plt.show()
def draw_p_vs_area_byOne(df):#绘制每一城区房价与面积分别散点图
districts = df['城区'].unique()
fig, axs = plt.subplots(len(districts), figsize=(8, 5 * len(districts)))
for i, district in enumerate(districts):
axs[i].scatter(df[df['城区'] == district]['面积'],
df[df['城区'] == district]['总价'])
axs[i].set_xlabel('面积')
axs[i].set_ylabel('价格')
plt.tight_layout()
plt.title("四城区房价与面积分别的散点图")
plt.show()
def draw_p_vs_area_byALLbyC(df):#绘制四城区面积与二手房总价关系柱状图
df['平均面积'] = df['面积'].apply(lambda x: str(math.floor(x / 30) * 30) + '-' + str(math.floor(x / 30 + 1) * 30))
average_price = df.groupby('平均面积')['总价'].mean()
plt.bar(average_price.index, average_price.values)
# 设置图表标题和坐标轴标签
plt.title("四城区面积与总房价关系柱状图")
plt.xlabel("面积")
plt.ylabel("对应面积组总房价均值")
# 显示图表
plt.show()
def draw_p_vs_de_byALLbyBox(df):#绘制四城区总的装修种类与二手房单价箱线图
zhuangxiu = [list(df[df['装修'] =="精装" ]["单价"]),
list(df[df['装修'] =="简装" ]["单价"]),
list(df[df['装修'] =="毛坯" ]["单价"]),
list(df[df['装修'] =="其他" ]["单价"])]
plt.figure(figsize=(10,6))
plt.title("四城区总的装修-单价箱线图")
plt.boxplot(zhuangxiu, labels = ['精装', '简装', '毛坯','其他'],patch_artist=True,boxprops={'facecolor':'cornflowerblue'})
plt.xlabel("\n装修")
plt.ylabel('单价')
plt.show()
def draw_p_vs_de_byALLbyLine(df):#绘制四城区总的装修种类及其对应的单位平均房价折线图
mean=[]
zhong=df['装修'].unique()
for i in range (len(zhong)):
per_data = df[ df['装修'] == zhong[i] ]
mean.append(round(per_data['单价'].mean(),2))
plt.figure(figsize=(10,6))
plt.title("四城区单位房价与装修折线图")
plt.plot(range(len(zhong)), mean, '--^', label="单位价格")
plt.xticks(range(len(zhong)), labels =zhong)
plt.legend()
plt.show()
def analyse_p_vs_area(df):#分析房价与面积的关系
draw_p_vs_area_byALL(df)#绘制总散点图
draw_p_vs_area_byOne(df)#绘制分别的散点图
draw_p_vs_area_byALLbyC(df)#绘制总的柱状图
def analyse_p_vs_de(df):#分析房价与装修的关系
draw_p_vs_de_byALLbyBox(df)
draw_p_vs_de_byALLbyLine(df)
df=pd.read_csv('house_bj_new.csv')
print(df.shape[0])#查看未处理数据前总行数
print(df.columns)#查看数据集里所有的列名
print(df.dtypes)#查看数据集里所有类的类型
#分析四城区在售二手房特点
drawBoxByAll(df)#绘制四城区总价箱线图
drawBoxByOne(df)#绘制四城区单价箱线图
drawisNearSubway(df)#绘制四城区距离地铁远近柱状堆叠图
drawfindYear(df)#绘制四城区住房年份柱状图
drawHouseType(df)#绘制四城区房种类饼图
drawDecorationByC(df)#绘制四城区装修柱状图
drawDecorationByP(df)#绘制四城区装修饼图
#分析影响房价的主要因素
analyse_p_vs_area(df)#分析房价与面积的关系
analyse_p_vs_de(df)#分析房价与装修的关系
import pandas as pd
import re
import numpy as np
def extract_floor_number(x):
floors = re.findall(r'\d+', x)
if len(floors) > 0:
return int(floors[0])
else:
if x[0]=="高":
return int(15)
elif x[0]=="顶":
return int(20)
elif x[0]=="中":
return int(8)
else:
return int(3)
def extract_mian_number(text):
#pattern = r"\d+\.\d+"
pattern = r"\d+(\.\d+)?"
match = re.search(pattern, text)
if match:
return float(match.group())
else:#异常格式,用缺省值填补,处理完所有数据后删除
return np.nan
def extract_year_number(text):
pattern = r"\d+"
match = re.search(pattern, text)
if match:
return int(match.group())
else:
return None
df=pd.read_csv('house_bj.csv')
print(df.shape[0])#查看未处理数据前总行数
print(df.columns)#查看数据集里所有的列名
#进行数据预处理
#删除完全相同的重复行,并保留最后一个出现的行
df=df.drop_duplicates(keep='last')
print(df.shape[0])
#删除有缺失值的行
print(df.isnull().sum()) #检查缺失值
df = df.dropna()#删除所有有缺失值的行
#其他预处理部分
print(df.dtypes)#查看数据类型
df['房本是否满五年']=df['房本是否满五年'].replace('yes', '1')#房本满五年列转为整型,方便后续处理
df['房本是否满五年']=df['房本是否满五年'].replace('no','0')
df['房本是否满五年']=df['房本是否满五年'].astype('float')#转为浮点型
df['距离地铁']=df['距离地铁'].replace('None','0')
df['距离地铁']=df['距离地铁'].replace('近地铁','1')
df['距离地铁']=df['距离地铁'].astype('float')#转为浮点型
df['单价']=df['单价'].astype('float')#转为浮点型
df['楼层']=df['楼层'].apply(extract_floor_number)#将楼层抽象为整型
df['面积']=df['面积'].apply(extract_mian_number)#将面积提取出来
df['建造年份'] = df['建造年份'].apply(lambda x: x.strip())
df['装修'] = df['装修'].apply(lambda x: x.strip())
df['楼种类']=df['楼种类'].apply(lambda x: x.strip())
df['建造年份']=df['建造年份'].apply(extract_year_number)#将年份提取出来
#df['建造年份']=df['建造年份'].astype('int')
df['楼种类']=df['楼种类'].replace('暂无数据',np.nan)#将暂无数据行替换为缺省值,等待后续删除
print(df.dtypes)#查看处理后数据结果
print(df.isnull().sum()) #检查缺失值
df = df.dropna()#删除所有有缺失值的行
df['建造年份']=df['建造年份'].astype('int')#转换为整型
# 将数据保存到新CSV中
df.to_csv('house_bj_new.csv', encoding='utf-8', index=None)
print(df.shape[0])