-
算法特征
①. 以真实reward训练Q-function; ②. 从最大Q方向更新policy \(\pi\) -
算法推导
Part Ⅰ: RL之原理
整体交互流程如下,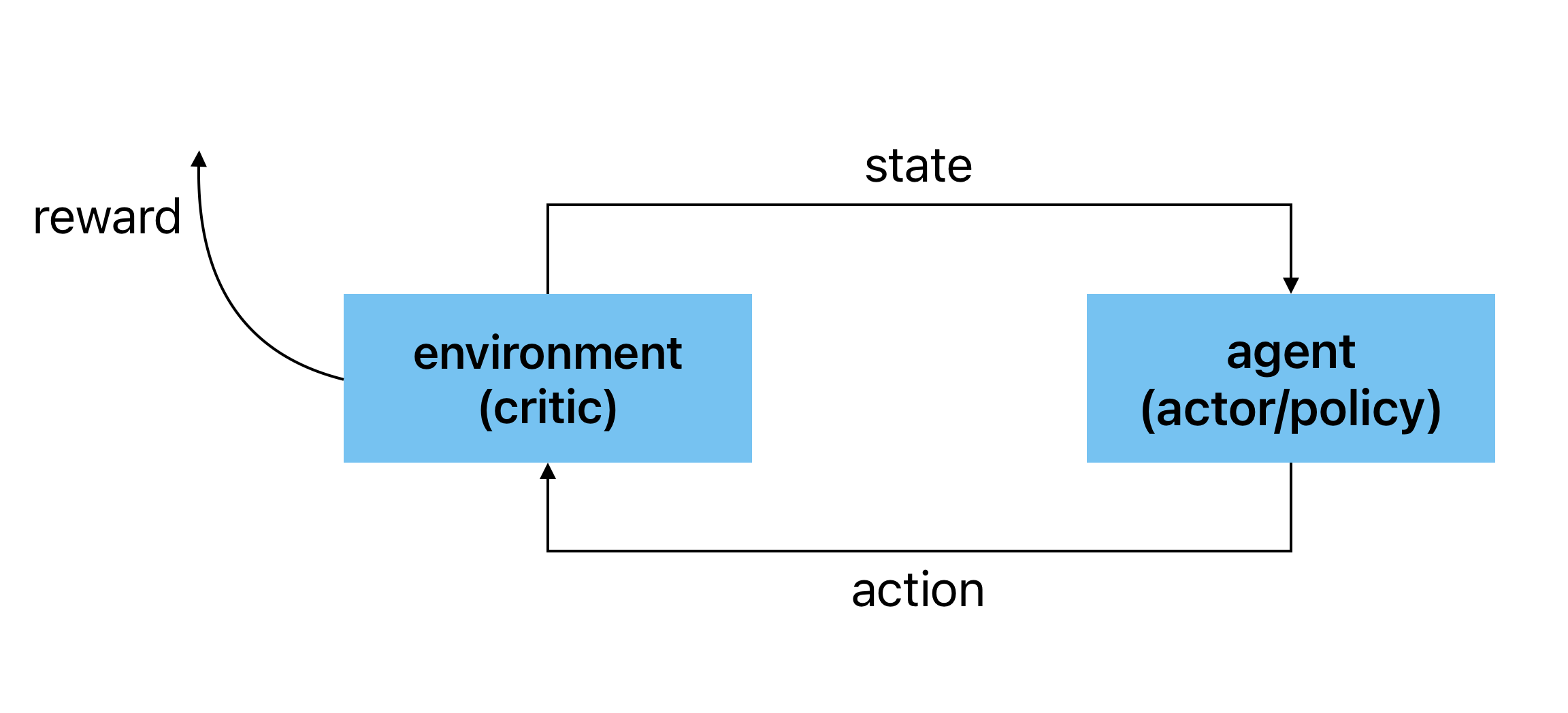
定义策略函数(policy)\(\pi\), 输入为状态(state)\(s\), 输出为动作(action)\(a\), 则,
\[\begin{equation*} a = \pi(s) \end{equation*} \]令交互序列为\(\{\cdots, s_t, a_t, r_t, s_{t+1}, \cdots\}\). 定义状态值函数(state value function)\(V^{\pi}(s)\), 表示agent在当前状态\(s\)下采取策略\(\pi\)与environment持续交互所得累计奖励之期望(cumulated reward expectation), 则,
\[\begin{equation*} V^{\pi}(s_t) = r_t + V^{\pi}(s_{t+1}) \end{equation*} \]定义状态动作值函数(state-action value function)\(Q^{\pi}(s, a)\), 表示agent在当前状态\(s\)下强制采取动作\(a\)接下来采取策略\(\pi\)与environment持续交互所得累计奖励之期望, 则,
\[\begin{equation*} \begin{split} Q^{\pi}(s_t, a_t) &= r_t + Q^{\pi}(s_{t+1},\pi(s_{t+1})) \\ &= r_t + V^{\pi}(s_{t+1}) \end{split} \end{equation*} \]定义最优\(\pi^*\), 使状态值函数\(V^{\pi}\)最大化, 即,
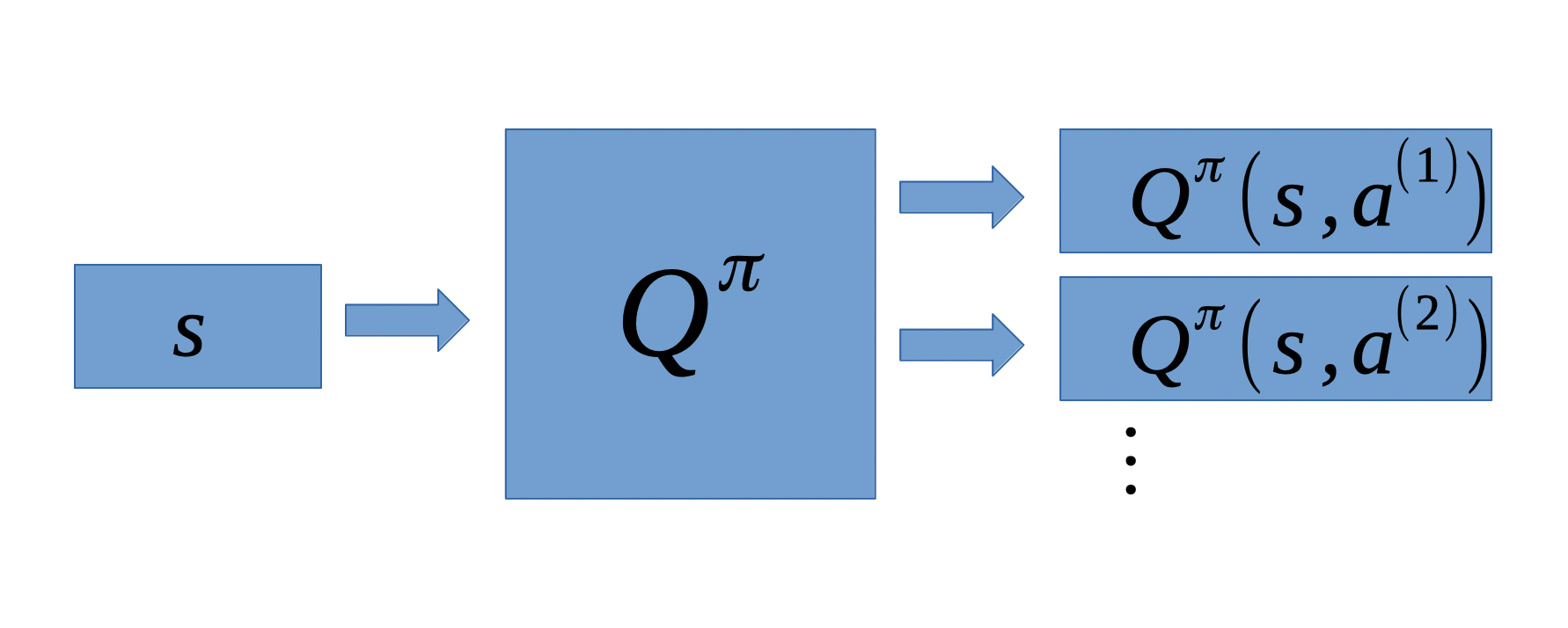
\[\begin{equation*} \begin{split} \pi^* &= \mathop{\arg\max}_{\pi}\ V^{\pi}(s) \\ &= \mathop{\arg\max}_{\pi}\ Q^{\pi}(s, \pi(s)) \end{split} \end{equation*} \]连续空间中, Q-function实现如下,

离散空间中, Q-function实现如下,
Part Ⅱ: RL之实现
训练tips:
①. target network中Q-function在一定训练次数内可以保持不变
②. exploration使数据采集更加丰富- Epsilon Greedy\[\begin{equation*} a = \left\{ \begin{split} \mathop{\arg\max}_{a}\ Q(s, a), \quad & \text{with probability }1-\varepsilon\\ \text{random}, \quad\quad\quad & \text{with probability }\varepsilon \\ \end{split} \right. \end{equation*} \]\(\varepsilon\)取值在训练期间逐渐减小
- Boltzmann Exploration\[P(a|s) = \frac{\exp(Q(s,a))}{\sum_a\exp(Q(s,a))} \]
③. Replay Buffer中以\((s_t, a_t, r_t, s_{t+1})\)为单位进行数据存储, 数据可以来源于不同的policy \(\pi\). buffer中保存新数据剔除旧数据, 每次迭代中随机抽取某个batch进行训练.
算法流程如下,
Initialize Q-function \(Q\), target Q-function \(\bar{Q} = Q\) (Note: target nework)
for each episode
\(\quad\) for each time step \(t\)
\(\qquad\) Given state \(s_t\), take action \(a_t\) based on \(Q\) (Note: exploration)
\(\qquad\) Obtain reward \(r_t\), and reach new state \(s_{t+1}\)
\(\qquad\) Store \((s_t,a_t,r_t,s_{t+1})\) into buffer (Note: replay buffer)
\(\qquad\) Sample \((s_i, a_i, r_i, s_{i+1})\) from buffer (usually a batch)
\(\qquad\) Target \(\bar{y}=r_i + \max_a\ \bar{Q}(s_{i+1}, a)\)
\(\qquad\) Update the parameters of \(Q\) to make \(Q(s_i, a_i)\) close to \(\bar{y}\) (regression)
\(\qquad\) Every \(c\) steps reset \(\bar{Q}=Q\) - Epsilon Greedy
-
代码实现
本文以SnakeGame为例进行算法实施, 将游戏网格化, 并将输入feature分配在不同channel上, 最后利用卷积抽取并识别该feature. 具体实现如下,
Q-Learning-for-SnakeGame -
结果展示

可以看到, SnakeGame之训练效果符合预期.
-
使用建议
①. Batch Normalization使特征分布在原点附近, 不容易数值溢出
②. 复杂特征可以由二元特征组成, 具体含义自定义 -
参考文档
①. Q-Learning强化学习 - 李宏毅
②. Python + PyTorch + Pygame Reinforcement Learning – Train an AI to Play Snake
- Learning Reinforcement Q-Learning Pythonlearning reinforcement q-learning python q-learning q-learning learning网络 reinforcement learning 优缺点 算法q-learning learning 迷宫 算法q-learning learning 算法q-learning learning dqn noise reinforcement exploration learning reinforcement distillation teachable learning 差分法 时态q-learning learning