第7章 函数装饰器和闭包
装饰器这个名称可能更适合在编译器领域使用,因为它会遍历并注解句法树
函数装饰器用于在源码中“标记”函数,以某种方式增强函数的行为。这是一项强大的功能,但是若想掌握,必须理解
闭包
如果你想自己实现函数装饰器,那就必须了解闭包的方方面面,因此也就需要知道 nonlocal
闭包还是回调式异步编程和函数式编程风格的基础
本章的最终目标是解释清楚函数装饰器的工作原理,包括最简单的注册装饰器和较复杂的参数化装饰器
讨论如下话题
- Python 如何计算装饰器句法
- Python 如何判断变量是不是局部的
- 闭包存在的原因和工作原理
- nonlocal 能解决什么问题
再进一步探讨
- 实现行为良好的装饰器
- 标准库中有用的装饰器
- 实现一个参数化装饰器
7.1 装饰器基础知识
装饰器是可调用的对象,其参数是另一个函数(被装饰的函数)
装饰器可能会处理被装饰的函数,然后把它返回,或者将其替换成另一个函数或可调用对象
@decorate
def target():
print('running target()')
等价于
def target():
print('running target()')
target = decorate(target)
此处的decorate是你定义好的装饰器,姑且认为是个函数
这个函数被更改了,这也是网上流传装饰器万能公式,记住了这点其实理解装饰器或写个简单的装饰器是很容易的。
装饰器的适用范围非常广泛,你可以参考《7.12 延伸阅读- 关于装饰器的一个典型应用》
来看一个完整的例子
def deco(func):
def inner():
func() # 注: 此处我加的
print('running inner()')
return inner #➊
@deco
def target(): #➋
print('running target()')
target() #➌
print(target) #➍
➊ deco 返回 inner 函数对象。
➋ 使用 deco 装饰 target。
➌ 调用被装饰的 target 其实会运行 inner。
➍ 审查对象,发现 target 现在是 inner 的引用
执行结果
running target()
running inner()
<function deco.<locals>.inner at 0x00000190D7E77D30>
可以看到如果target没加这个装饰器,肯定是单单执行running target(),但加了装饰器后
看似target执行可以多出来running inner(),实际上此时的target已经不再是原来的它了,它变了
根据万能公式
@deco
def target():
pass
你这样后会让target变为target = deco(target)
再根据deco的定义
def deco(func):
...
return inner #➊
你在执行deco(target)的时候,返回的是一个叫inner的东西
因为你最终执行的是target(),所以也就是inner()
再看inner定义
def inner():
func()
print('running inner()')
inner()的时候,会执行func(),func来自deco的实参,此处对应target,所以你会先执行target(),再执行print('running inner()')
装饰器只是语法糖
装饰器可以像常规的可调用对象那样调用,其参数是另一个函数。有时,这样做更方便,尤其是做元编程(在运行时改变程序的行为)时
装饰器的一大特性是,能把被装饰的函数替换成其他函数
第二个特性是,装饰器在加载模块时立即执行
7.2 Python何时执行装饰器
装饰器的一个关键特性是,它们在被装饰的函数定义之后立即运行。这通常是在导入时(即 Python 加载模块时)
书中的示例 registration.py 模块
registry = [] #➊
def register(func): #➋
print('running register(%s)' % func) #➌
registry.append(func) #➍
return func #➎
@register #➏
def f1():
print('running f1()')
@register
def f2():
print('running f2()')
def f3(): #➐
print('running f3()')
def main(): #➑
print('running main()')
print('registry ->', registry)
f1()
f2()
f3()
if __name__=='__main__':
main() # ➒
➊ registry 保存被 @register 装饰的函数引用。
➋ register 的参数是一个函数。
➌ 为了演示,显示被装饰的函数。
➍ 把 func 存入 registry。
➎ 返回 func:必须返回函数;这里返回的函数与通过参数传入的一样。
➏ f1 和 f2 被 @register 装饰。
➐ f3 没有装饰。
➑ main 显示 registry,然后调用 f1()、f2() 和 f3()。
➒ 只有把 registration.py 当作脚本运行时才调用 main()。
我做了一些测试
- 21行的main()不写,直接就一个pass,也会执行
running register(<function f1 at 0x000001940F3D7EE0>)
running register(<function f2 at 0x000001940F3F6040>)
- 这个跟你import 这个py文件的效果是一样的,也充分说明了
在导入时立即运行 - 这也是为何你在打印registry这个列表的时候已经能看到里面有2个
- 类似的你把21行改为f1(),会打印如下。注意,有了上面的概念,你可能反而会觉得是不是会多打印一个
running register...,实则不然。
running register(<function f1 at 0x0000021998027E50>)
running register(<function f2 at 0x0000021998027D30>)
running f1()
- 最终写上main()的运行效果
running register(<function f1 at 0x000002A0F6CF7E50>)
running register(<function f2 at 0x000002A0F6CF7D30>)
running main()
registry -> [<function f1 at 0x000002A0F6CF7E50>, <function f2 at 0x000002A0F6CF7D30>]
running f1()
running f2()
running f3()
函数装饰器在导入模块时立即执行,而被装饰的函数只在明确调用时运行。这突出了 Python 程序员所说的导入时和运行时之间的区别
- 装饰器函数与被装饰的函数在同一个模块中定义。实际情况是,装饰器通常在一个模块中定义,然后应用到其他模块中的函数上。
- register 装饰器返回的函数与通过参数传入的相同。实际上,大多数装饰器会在内部定义一个函数,然后将其返回。
装饰器原封不动地返回被装饰的函数,但是这种技术并非没有用处。很多 Python Web 框架使用这样的装饰器把函数添加到某种中央注册处,例如把URL 模式映射到生成 HTTP 响应的函数上的注册处。这种注册装饰器可能会也可能不会修改被装饰的函数
7.3 使用装饰器改进“策略”模式
策略模式是第6章的内容,比较的拗口,就先不写了。
TODO
7.4 变量作用域规则
>>> def f(a): print(a)
... print(b)
File "<stdin>", line 2
print(b)
IndentationError: unexpected indent
>>> def f(a):
... print(a)
... print(b)
...
>>> f(1)
1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 3, in f
NameError: name 'b' is not defined
在书中,最后一行是这样的
NameError: global name 'b' is not defined
虽然显示不同(从Python3.5开始的),但的确b还是那个global,用生成的字节码可以说明这点
>>> from dis import dis
>>> dis(f)
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_FAST 0 (a)
4 CALL_FUNCTION 1
6 POP_TOP
3 8 LOAD_GLOBAL 0 (print)
10 LOAD_GLOBAL 1 (b) # 看这里
12 CALL_FUNCTION 1
14 POP_TOP
16 LOAD_CONST 0 (None)
18 RETURN_VALUE
加一个b的定义就能正常输出了
>>> b=2
>>> f(1)
1
2
再看另外一个例子
>>> b = 1
>>> def func(a):
... print(a)
... print(b)
... b = 1
...
>>> func(2) 你可以思考下会输出什么?为什么?
2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 3, in func
UnboundLocalError: local variable 'b' referenced before assignment
你可能会觉得应该打印b的值6,因为外面定义了一个全局变量b,而在print(b)之后的b=9是后面执行的, 不会打印9才是。
事实是,Python 编译函数的定义体时,它判断 b 是局部变量,因为在函数中给它赋值了
也就是说在函数中加了一句b = 1,下面的就是b就从global变成了local variable
而且在函数外定义了全局变量b=1,这个函数是用不了的
从生成的字节码看下
>>> from dis import dis
>>> dis(func)
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_FAST 0 (a)
4 CALL_FUNCTION 1
6 POP_TOP
3 8 LOAD_GLOBAL 0 (print)
10 LOAD_FAST 1 (b) # 这里
12 CALL_FUNCTION 1
14 POP_TOP
4 16 LOAD_CONST 1 (1)
18 STORE_FAST 1 (b)
20 LOAD_CONST 0 (None)
22 RETURN_VALUE
10 LOAD_FAST 1 (b)这一行暴露了b是个local variable
这不是缺陷,而是设计选择:Python 不要求声明变量,但是假定在函数定义体中赋值的变量是局部变量
这比 JavaScript 的行为好多了,JavaScript 也不要求声明变量,但是如果忘记把变量声明为局部变量(使用 var),可能会在不知情的情况下获取全局变量
b = 6
def fun(a):
global b
print(a)
print(b)
b=9
fun(3)
print(b)
这个global必须要在fun中定义
此时的字节码
12 0 LOAD_GLOBAL 0 (print)
2 LOAD_FAST 0 (a)
4 CALL_FUNCTION 1
6 POP_TOP
13 8 LOAD_GLOBAL 0 (print)
10 LOAD_GLOBAL 1 (b)
12 CALL_FUNCTION 1
14 POP_TOP
14 16 LOAD_CONST 1 (9)
18 STORE_GLOBAL 1 (b)
20 LOAD_CONST 0 (None)
22 RETURN_VALUE
7.5 闭包
人们有时会把闭包和匿名函数弄混。这是有历史原因的:在函数内部定义函数不常见,直到开始使用匿名函数才会这样做。而且,只有涉及嵌套函数时才有闭包问题。因此,很多人是同时知道这两个概念的
闭包指延伸了作用域的函数,其中包含函数定义体中引用、但是不在定义体中定义的非全局变量。
函数是不是匿名的没有关系,关键是它能访问定义体之外定义的非全局变量
书中的一个例子,要实现类似下面的效果
它的作用是计算不断增加的系列值的均值;例如,整个历史中某个商品的平均收盘价。每天都会增加新价格,因此平均值要考虑至目前为止所有的价格
>>> avg(10)
10.0
>>> avg(11)
10.5
>>> avg(12)
11.0
乍一看这个题,你肯定会想到这是个函数,这个函数传入1个参数,内部有个东西可以记录它的值,并计算出迄今为止所有数据的平均值
难道是这样的?V1
def avg(value):
values = []
values.append(value)
return sum(values)/len(values)
print(avg(10))
print(avg(11))
显然不对,每次调用的时候values会被重新初始化成[],所以始终就一个值
难道是这样的?V2
values = []
def avg(value):
values.append(value)
return sum(values)/len(values)
print(avg(10))
print(avg(11))
print(avg(12))
竟然对了,但是这values不能在外面啊,你拿到外面去算啥吗~
上面是我写的,来看作者写的
class Averager():
def __init__(self):
self.series = []
def __call__(self, new_value):
self.series.append(new_value)
total = sum(self.series)
return total/len(self.series)
avg = Averager()
print(avg(10))
print(avg(11))
print(avg(12))
看到avg()你指应该想到它是一个可调用对象,类实例也可以进行调用,实现__call__就行啦
那在类这里你要实现这个代码就简单了,上面的代码应该可以想通,跟我们之前的蹩脚代码异曲同工。
来看看函数式的实现:示例 7-9 average.py:计算移动平均值的高阶函数
def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total/len(series)
return averager
avg = make_averager() # 你得到的是 averager 函数名这个一等对象
print(avg(10)) # averager(10) 就是平均值
print(avg(11))
print(avg(12))
书中给出的类和函数的实现有共通之处:调用 Averager() 或 make_averager() 得到一个可调用对象avg,它会更新历史值,然后计算当前均值
这个函数为何能进行累加呢?当然你能看得到这个写法的特殊之处,函数里面有局部变量(series),又有内部函数averager。但注意这个内部函数用到了上面的局部变量
Averager 类的实例 avg 在哪里存储历史值很明显:self.series 实例属性。
但是第二个示例中的 avg 函数在哪里寻找 series 呢?
而且调用 avg(10) 时,make_averager 函数已经返回了,而它的本地作用域也一去不复返了。来看原文给的图,我稍微拟合了下。

def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total/len(series)
return averager
avg = make_averager()
avg(10)
avg(11)
avg(12)
# 审查返回的 averager 对象,我们发现 Python 在 __code__ 属性(表示编译后的函数定义体)中保存局部变量和自由变量的名称
# 局部变量
print(avg.__code__.co_varnames)
# 自由变量
print(avg.__code__.co_freevars)
# avg.__closure__ 中的各个元素对应于 avg.__code__.co_freevars 中的一个名称。这些元素是 cell 对象,有个 cell_contents 属性,保存着真正的值
print(avg.__closure__)
print(avg.__closure__[0].cell_contents)
输出
('new_value', 'total') # 局部变量
('series',) #自由变量
(<cell at 0x00000197FA6B4FD0: list object at 0x00000197FA083240>,)#包含该函数可用变量的绑定的单元的元组
[10, 11, 12] # 单元的值
这里再说明下这几个属性的作用
| 属性 | 作用 |
|---|---|
| co_varnames | 参数名和局部变量的元组 |
| co_freevars | 自由变量的名字组成的元组(通过函数闭包引用) |
__closesure__ |
None 或包含该函数可用变量的绑定的单元的元组。有关 cell_contents 属性的详情见下。 |
| cell_contents | 单元对象具有 cell_contents 属性。这可被用来获取以及设置单元的值 |
引用自
https://docs.python.org/zh-cn/3.9/reference/datamodel.html?highlight=closure#the-standard-type-hierarchy
https://docs.python.org/zh-cn/3.9/library/inspect.html?highlight=inspect#module-inspect
avg.__closure__中的各个元素对应于avg.__code__.co_freevars中的一个名称。这些元素是 cell 对象,有个 cell_contents 属性,保存着真正的值
划重点: 闭包是一种函数,它会保留定义函数时存在的自由变量的绑定,这样调用函数时,虽然定义作用域不可用了,但是仍能使用那些绑定
注意,只有嵌套在其他函数中的函数才可能需要处理不在全局作用域中的外部变量
7.6 nonlocal声明
def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total/len(series)
return averager
在上面的做法中
实现 make_averager 函数的方法效率不高
我们把所有值存储在历史数列中,然后在每次调用 averager 时使用 sum 求和
更好的实现方式是,只存储目前的总值和元素个数,然后使用这两个数计算均值
书中也给了个示例,但是个陷阱,你还能看出来问题所在?
def make_averager():
total = 0
count = 0
def averager(new_value):
total += new_value
count += 1
return count/length
return averager
avg = make_averager()
avg(10)
在Pycharm中定义函数就是红色的警告,会提示类似未解析的引用 'count' ,里面三行都红的。
但执行的时候会提示
Traceback (most recent call last):
File "demo_fluent7.py", line 10, in <module>
avg(10)
File "demo_fluent7.py", line 5, in averager
count += new_value
UnboundLocalError: local variable 'count' referenced before assignment
你上一次遇到它是在这里
>>> b = 1
>>> def func(a):
... print(a)
... print(b)
... b = 1
说明,这个count又成了一个局部变量?
看下dis
def make_averager():
...#省略
avg = make_averager()
from dis import dis
dis(avg)
输出
5 0 LOAD_FAST 1 (count)
2 LOAD_FAST 0 (new_value)
4 INPLACE_ADD
6 STORE_FAST 1 (count)
6 8 LOAD_FAST 2 (total )
10 LOAD_CONST 1 (1)
12 INPLACE_ADD
14 STORE_FAST 2 (total )
7 16 LOAD_FAST 1 (count) # 看此处
18 LOAD_FAST 2 (total )
20 BINARY_TRUE_DIVIDE
22 RETURN_VALUE
为何会这样呢?其实之前讲过
当 count 是数字或任何不可变类型时,count += 1 语句的作用其实与 count =count + 1 一样。因此,我们在 averager 的定义体中为 count 赋值了,
这会把 count 变成局部变量。total 变量也受这个问题影响。
当你写series = []的时候,我们利用了列表是可变的对象这一事实,你在内部函数体中只是做了series.append,这个对象并没有改变
但是对数字、字符串、元组等不可变类型来说,只能读取,不能更新。如果尝试重新绑定,例如 count = count + 1,其实会隐式创建局部变量 count。这样,count 就不是自由变量了,因此不会保存在闭包中
这个细节在本书《第2章 数据结构》的2.6 序列的增量赋值有描述,就是对数字而言,做count+=1的时候count不再是原来的count了
那是不是这样的思路就不行了呢?倒也不是,就是稍微有点牵强
为了解决这个问题,Python 3 引入了 nonlocal 声明。它的作用是把变量标记为自由变量,即使在函数中为变量赋予新值了,也会变成自由变量。如果为 nonlocal 声明的变量赋予新值,闭包中保存的绑定会更新
最终可以替代前面的例子的代码如下
def make_averager():
total = 0
count = 0
def averager(new_value):
nonlocal count,total
count += 1
total += new_value
return total/count
return averager
avg = make_averager()
print(avg(10))
print(avg(11))
print(avg(12))
在没有实现nonlocal的情况下(比如Python2中)
http://www.python.org/dev/peps/pep-3104/
PEP 3104—Access to Names inOuter Scopes
其中的第三个代码片段给出了一种方法。基本上,这种处理方式是把内部函数需要修改的变量(如 count 和 total)存储为可变对象(如字典或简单的实例)的元素或属性,并且把那个对象绑定给一个自由变量
7.7 实现一个简单的装饰器
示例 7-15 一个简单的装饰器,输出函数的运行时间
import time
def clock(func):
def clocked(*args): # ➊
t0 = time.perf_counter()
result = func(*args) # ➋
elapsed = time.perf_counter() - t0
name = func.__name__
arg_str = ', '.join(repr(arg) for arg in args)
print('[%0.8fs] %s(%s) -> %r' % (elapsed, name, arg_str, result))
return result
return clocked # ➌
@clock
def get_time():
from time import sleep
sleep(2)
get_time()
➊ 定义内部函数 clocked,它接受任意个定位注:位置参数。
➋ 这行代码可用,是因为 clocked 的闭包中包含自由变量 func。
➌ 返回内部函数,取代被装饰的函数
关于第2点,用代码说明下
test = clock(get_time)
print(test.__code__.co_freevars) # ('func',)
示例 7-16 使用 clock 装饰器
需要用到上面的代码
import time
@clock
def snooze(seconds):
time.sleep(seconds)
@clock
def factorial(n):
return 1 if n < 2 else n*factorial(n-1)
if __name__=='__main__':
print('*' * 40, 'Calling snooze(.123)')
snooze(.123)
print('*' * 40, 'Calling factorial(6)')
print('6! =', factorial(6))
print(factorial.__name__)
执行效果
**************************************** Calling snooze(.123)
[0.12786180s] snooze(0.123) -> None
**************************************** Calling factorial(6)
[0.00000050s] factorial(1) -> 1
[0.00000770s] factorial(2) -> 2
[0.00001190s] factorial(3) -> 6
[0.00001650s] factorial(4) -> 24
[0.00002100s] factorial(5) -> 120
[0.00002730s] factorial(6) -> 720
6! = 720
clocked
工作原理
@clock
def factorial(n):
return 1 if n < 2 else n*factorial(n-1)
等价于
def factorial(n):
return 1 if n < 2 else n*factorial(n-1)
factorial = clock(factorial)
factorial成为了clock的实参,指向func形参;调用后clock(factorial)返回的是clocked
看上面我加的调试代码print(factorial.__name__)得到的就是clocked
现在 factorial 保存的是 clocked 函数的引用。自此之后,每次调用 factorial(n),执行的都是 clocked(n)。
代码上clocked做了以下事情:
(1) 记录初始时间 t0。 # t0 = time.perf_counter()
(2) 调用原来的 factorial 函数,保存结果。 # result = func(*args) # ➋
(3) 计算经过的时间。 # elapsed = time.perf_counter() - t0
(4) 格式化收集的数据,然后打印出来。
# 收集的数据:包括前面的 elapsed 和 result
# name = func.__name__
# arg_str = ', '.join(repr(arg) for arg in args)
# print('[%0.8fs] %s(%s) -> %r' % (elapsed, name, arg_str, result))
(5) 返回第 2 步保存的结果。 # return result
装饰器的典型行为:
1. 把被装饰的函数替换成新函数
2. 二者接受相同的参数
3. 而且(通常)返回被装饰的函数本该返回的值
4. 同时还会做些额外操作
Gamma 等人写的《设计模式:可复用面向对象软件的基础》一书是这样概述“装饰器”模式的:“动态地给一个对象添加一些额外的职责。”函数装饰器符合这一说法。
但在实现层面,Python 装饰器与《设计模式:可复用面向对象软件的基础》中所述的“装饰器”没有多少相似之处
示例 7-15 中实现的 clock 装饰器有几个缺点:不支持关键字参数,而且遮盖了被装饰函数的
__name__和__doc__属性
import time
def clock(func):
'''doc of clock'''
def clocked(*args): # ➊
'''doc of clocked'''
t0 = time.perf_counter()
result = func(*args) # ➋
elapsed = time.perf_counter() - t0
name = func.__name__
arg_str = ', '.join(repr(arg) for arg in args)
print('[%0.8fs] %s(%s) -> %r' % (elapsed, name, arg_str, result))
return result
return clocked # ➌
@clock
def snooze(seconds):
time.sleep(seconds)
@clock
def factorial(n):
'''doc of fact'''
return 1 if n < 2 else n*factorial(n-1)
if __name__=='__main__':
print(factorial.__doc__)
print(factorial.__name__)
print('*' * 40, 'Calling snooze(.123)')
snooze(.123)
snooze(seconds=.123)
注意上面的代码,做了一些更改
- 加了factorial、clock和clocked等函数的doc,你可以看到,
print(factorial.__doc__)输出的是clocked的doc - 测试了下关键字输入方式
snooze(seconds=.123)提示如下
TypeError: clocked() got an unexpected keyword argument 'seconds'
如果要支持关键字只需做如下更改
def clock(func):
'''doc of clock'''
def clocked(*args,**kwargs): # ➊
'''doc of clocked'''
t0 = time.perf_counter()
result = func(*args,**kwargs) # ➋
➊ clocked本身要支持**kwargs
➋ 内部调用的时候要接受**kwargs
输出大致如下
doc of clocked
clocked
**************************************** Calling snooze(.123)
[0.13518720s] snooze(0.123) -> None
[0.12407520s] snooze() -> None
问题1: 你可以看到,factorial的__doc__和__name__被遮挡了,这点在前面的万能公式中我们也有提到
怎么处理呢?
使用 functools.wraps 装饰器把相关的属性从 func复制到 clocked 中
import time
import functools
def clock(func):
@functools.wraps(func)
def clocked(*args,**kwargs): # ➊
t0 = time.perf_counter()
result = func(*args,**kwargs) # ➋
elapsed = time.perf_counter() - t0
name = func.__name__
arg_str = ', '.join(repr(arg) for arg in args)
print('[%0.8fs] %s(%s) -> %r' % (elapsed, name, arg_str, result))
return result
return clocked # ➌
@clock
def snooze(seconds):
time.sleep(seconds)
@clock
def factorial(n):
'''doc of fact'''
return 1 if n < 2 else n*factorial(n-1)
if __name__=='__main__':
print(factorial.__doc__) # doc of fact
print(factorial.__name__) # factorial
可以看到__doc__和__name__改过来了
问题2:snooze(seconds=.123)这种调用方式在结果中没有输出参数
原因很简单,你没有处理,你处理的只是args,你还要处理kwargs,参考代码如下
import time
import functools
def clock(func):
@functools.wraps(func)
def clocked(*args,**kwargs): # ➊
t0 = time.perf_counter()
result = func(*args,**kwargs) # ➋
elapsed = time.perf_counter() - t0
name = func.__name__
arg_lst = []
if args:
arg_lst.append(', '.join(repr(arg) for arg in args))
if kwargs:
pairs = ['%s=%r' % (k, w) for k, w in sorted(kwargs.items())]
arg_lst.append(', '.join(pairs))
arg_str = ''.join(arg_lst)
print('[%0.8fs] %s(%s) -> %r' % (elapsed, name, arg_str, result))
return result
return clocked # ➌
@clock
def snooze(seconds):
time.sleep(seconds)
@clock
def factorial(n):
'''doc of fact'''
return 1 if n < 2 else n*factorial(n-1)
if __name__=='__main__':
print(factorial.__doc__)
print(factorial.__name__)
print('*' * 40, 'Calling snooze(.123)')
snooze(.123)
snooze(seconds=.123)
7.8 标准库中的装饰器
Python 内置了三个用于装饰方法的函数:property、classmethod 和 staticmethod
另一个常见的装饰器是 functools.wraps,它的作用是协助构建行为良好的装饰器
标 准 库 中 最 值 得 关 注 的 两 个 装 饰 器 是 lru_cache 和 全 新 的singledispatch(Python 3.4 新增)
7.8.1 使用functools.lru_cache做备忘
functools.lru_cache 是非常实用的装饰器,它实现了备忘(memoization)功能。这是一项优化技术,它把耗时的函数的结果保存起来,避免传入相同的参数时重复计算。LRU 三个字母是“Least Recently Used”的缩写,表明缓存不会无限制增长,一段时间不用的缓存条目会被扔掉
示例 7-18 生成第 n 个斐波纳契数,递归方式非常耗时
@clock
def fibonacci(n):
if n < 2:
return n
return fibonacci(n-1) + fibonacci(n-2)
if __name__=='__main__':
print(fibonacci(6))
这对你理解递归也是有帮助的
输出如下(这个调用顺序实在有点...)
[0.00000030s] fibonacci(1) -> 1
[0.00000030s] fibonacci(0) -> 0
[0.00002610s] fibonacci(2) -> 1
[0.00000020s] fibonacci(1) -> 1
[0.00003430s] fibonacci(3) -> 2
[0.00000020s] fibonacci(1) -> 1
[0.00000020s] fibonacci(0) -> 0
[0.00000760s] fibonacci(2) -> 1
[0.00004960s] fibonacci(4) -> 3
[0.00000010s] fibonacci(1) -> 1
[0.00000020s] fibonacci(0) -> 0
[0.00000750s] fibonacci(2) -> 1
[0.00000020s] fibonacci(1) -> 1
[0.00001490s] fibonacci(3) -> 2
[0.00007280s] fibonacci(5) -> 5
[0.00000020s] fibonacci(1) -> 1
[0.00000020s] fibonacci(0) -> 0
[0.00000750s] fibonacci(2) -> 1
[0.00000010s] fibonacci(1) -> 1
[0.00001470s] fibonacci(3) -> 2
[0.00000020s] fibonacci(1) -> 1
[0.00000020s] fibonacci(0) -> 0
[0.00000750s] fibonacci(2) -> 1
[0.00002930s] fibonacci(4) -> 3
[0.00010970s] fibonacci(6) -> 8
8
画个图
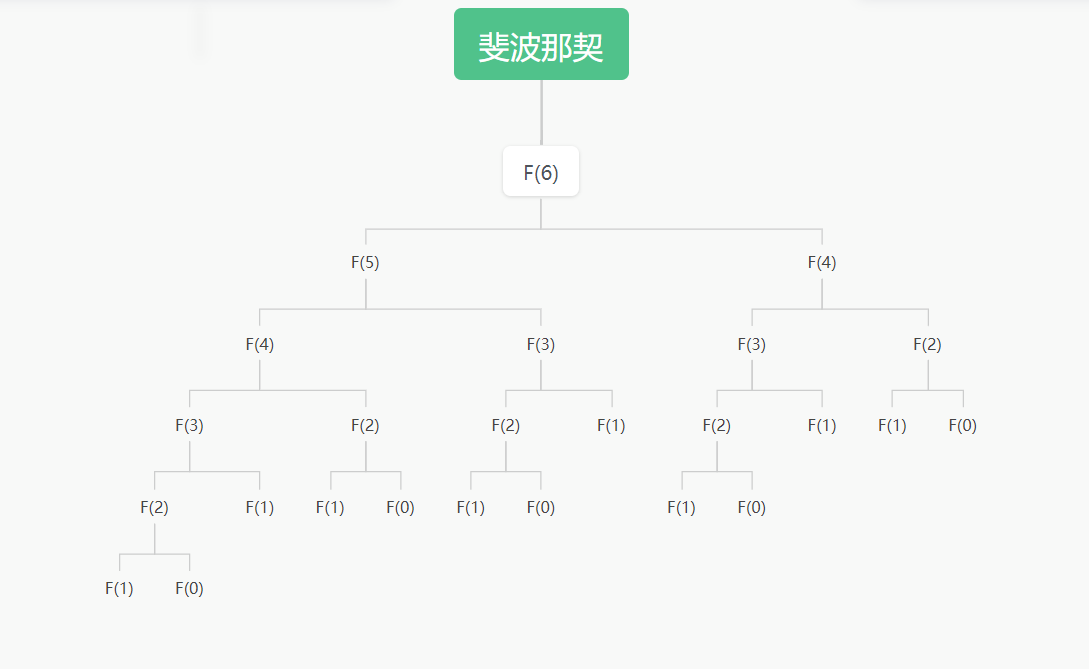
从图上可以看到,这里存在大量的重复操作
增加两行代码,使用 lru_cache,性能会显著改善
@functools.lru_cache()
@clock
def fibonacci(n):
if n < 2:
return n
return fibonacci(n-1) + fibonacci(n-2)
if __name__=='__main__':
print(fibonacci(6))
注意@functools.lru_cache()必须放@clock前面
这时候的输出就是这样,重复的调用都没了
[0.00000040s] fibonacci(1) -> 1
[0.00000030s] fibonacci(0) -> 0
[0.00002740s] fibonacci(2) -> 1
[0.00003230s] fibonacci(3) -> 2
[0.00003680s] fibonacci(4) -> 3
[0.00004120s] fibonacci(5) -> 5
[0.00004570s] fibonacci(6) -> 8
8
另外一个注意的点是:必须像常规函数那样调用 lru_cache,后面有个()
作者做了个测试,可以看出,提升是巨大的
示例 7-19 中的版本(加了lru_cache的)在 0.0005 秒内调用了 31 次fibonacci 函数
示例 7-18 中未缓存版本调用 fibonacci 函数 2 692 537 次,在使用Intel Core i7 处理器的笔记本电脑中耗时 17.7 秒
lru_cache签名
functools.lru_cache(maxsize=128, typed=False)
- maxsize指定存储多少个调用的结果,缓存满了之后,旧的结果会被扔掉,腾出空间。为了得到最佳性能,maxsize 应该设为 2 的幂
- typed 参数如果设为 True,把不同参数类型得到的结果分开保存,即把通常认为相等的浮点数和整数参数区分开
- lru_cache 使用字典存储结果,而且键根据调用时传入的定位参数和关键字参数创建,所以被 lru_cache 装饰的函数,
它的所有参数都必须是可散列的,即不可变的
7.8.2 单分派泛函数
背景: 假设我们在开发一个调试 Web 应用的工具,我们想生成 HTML,显示不同类型的 Python对象
import html
def htmlize(obj):
content = html.escape(repr(obj))
return '<pre>{}</pre>'.format(content)
想改造这个函数,以期达到下面的效果
- str:把内部的换行符替换为
<br>\n';不使用<pre>,而是使用<p>。 - int:以十进制和十六进制显示数字。
- list:输出一个 HTML 列表,根据各个元素的类型进行格式化
示例 7-20 生成 HTML 的 htmlize 函数,调整了几种对象的输出
>>> htmlize({1, 2, 3}) ➊
'<pre>{1, 2, 3}</pre>'
>>> htmlize(abs)
'<pre><built-in function abs></pre>'
>>> htmlize('Heimlich & Co.\n- a game') ➋
'<p>Heimlich & Co.<br>\n- a game</p>'
>>> htmlize(42) ➌
'<pre>42 (0x2a)</pre>'
>>> print(htmlize(['alpha', 66, {3, 2, 1}])) ➍
<ul>
<li><p>alpha</p></li>
<li><pre>66 (0x42)</pre></li>
<li><pre>{1, 2, 3}</pre></li>
</ul>
➊ 默认情况下,在 <pre></pre> 中显示 HTML 转义后的对象字符串表示形式。
➋ 为 str 对象显示的也是 HTML 转义后的字符串表示形式,不过放在 <p></p> 中,而且使用 <br> 表示换行。
➌ int 显示为十进制和十六进制两种形式,放在<pre></pre> 中。
➍ 各个列表项目根据各自的类型格式化,整个列表则渲染成 HTML 列表。
因为 Python 不支持重载方法或函数,所以我们不能使用不同的签名定义 htmlize 的变体,也无法使用不同的方式处理不同的数据类型。
重载overload,java中可以。Python只有override(重写)。
不同的签名是不支持的
def htmlize(obj:int):
pass
def htmlize(obj:str):
pass
def htmlize(obj:list):
pass
但我知道的一种做法是可以用第三方库,类似于这样
from multipledispatch import dispatch
@dispatch(int)
def htmlize(obj):
print('int')
@dispatch(str)
def htmlize(obj):
print('str')
@dispatch(list)
def htmlize(obj):
print('list')
htmlize(1) # int
htmlize('1') # str
htmlize([1,]) # list
htmlize((1,)) # 报错
# NotImplementedError: Could not find signature for htmlize: <tuple>
书中还说了一句也无法使用不同的方式处理不同的数据类型,我没太理解,不是可以用isinstance来处理吗?莫非在写的时候
没有这个玩意
第二版英文原文如下
Because we don’t have Java-style method overloading in Python, we can’t simply cre‐ate variations of htmlize with different signatures for each data type we want to han‐dle differently
在 Python 中,一种常见的做法是把 htmlize变成一个分派函数,使用一串 if/elif/elif,调用专门的函数,如 htmlize_str、htmlize_int,等等。这样不便于模块的用户扩展,还显得笨拙:时间一长,分派函数 htmlize 会变
得很大,而且它与各个专门函数之间的耦合也很紧密
书中给出的示例 7-21 singledispatch 创建一个自定义的 htmlize.register 装饰器,把多个函数绑在一起组成一个泛函数
from functools import singledispatch
from collections import abc
import numbers
import html
@singledispatch # ➊
def htmlize(obj):
content = html.escape(repr(obj))
return '<pre>{}</pre>'.format(content)
@htmlize.register(str) # ➋
def _(text): # ➌
content = html.escape(text).replace('\n', '<br>\n')
return '<p>{0}</p>'.format(content)
@htmlize.register(numbers.Integral) # ➍
def _(n):
return '<pre>{0} (0x{0:x})</pre>'.format(n)
@htmlize.register(tuple) # ➎
@htmlize.register(abc.MutableSequence)
def _(seq):
inner = '</li>\n<li>'.join(htmlize(item) for item in seq)
return '<ul>\n<li>' + inner + '</li>\n</ul>'
# 测试数据
print(htmlize({1, 2, 3}))
print(htmlize(abs))
print(htmlize('Heimlich & Co.\n- a game') )
print(htmlize(42) )
print(htmlize(['alpha', 66, {3, 2, 1}]))
➊ @singledispatch 标记处理 object 类型的基函数。
➋ 各个专门函数使用 @«base_function».register(«type») 装饰。
➌ 专门函数的名称无关紧要;_ 是个不错的选择,简单明了。
➍ 为每个需要特殊处理的类型注册一个函数。numbers.Integral 是 int 的虚拟超类。
➎ 可以叠放多个 register 装饰器,让同一个函数支持不同类型。
只要可能,注册的专门函数应该处理抽象基类(如 numbers.Integral 和 abc.MutableSequence),不要处理具体实现(如 int 和 list)。这样,代码支持的兼容类型更广泛。例如,Python扩展可以子类化 numbers.Integral,使用固定的位数实现 int 类型
使用抽象基类检查类型,可以让代码支持这些抽象基类现有和未来的具体子类或虚拟子类
singledispatch 机制的一个显著特征是,你可以在系统的任何地方和任何模块中注册专门函数。
如果后来在新的模块中定义了新的类型,可以轻松地添加一个新的专门函数来处理那个类型。
此外,你还可以为不是自己编写的或者不能修改的类添加自定义函数。
singledispatch 是经过深思熟虑之后才添加到标准库中的,它提供的特性很多 , 详见
PEP 443 — Single-dispatch generic functions
https://www.python.org/dev/peps/pep-0443/
@singledispatch 不是为了把 Java 的那种方法重载带入 Python。在一个类中为同一个方法定义多个重载变体,比在一个函数中使用一长串 if/elif/elif/elif 块要更好。但是这两种方案都有缺陷,因为它们让代码单元(类
或函数)承担的职责太多。@singledispath 的优点
是支持模块化扩展:各个模块可以为它支持的各个类型注册一个专门函数
7.9 叠放装饰器
装饰器是函数,因此可以组合起来使用(即,可以在已经被装饰的函数上应用装饰器)
前面已经多次这样使用,比如
@functools.lru_cache()
@clock
def fibonacci(n):
pass
但要注意顺序
@d1
@d2
def f():
print('f')
等价于f = d1(d2(f)),就近原则,最近@的最先装饰
7.10 参数化装饰器
解析源码中的装饰器时,Python 把被装饰的函数作为第一个参数传给装饰器函数。
那怎么让装饰器接受其他参数呢?
答案是:创建一个装饰器工厂函数,把参数传给它,返回一个装饰器,然后再把它应用到要装饰的函数上
书中给了个示例示例 7-22 示例 7-2 中 registration.py 模块的删减版
registry = []
def register(func):
print('running register(%s)' % func)
registry.append(func)
return func
@register
def f1():
print('running f1()')
print('running main()')
print('registry ->', registry)
f1()
7.10.1 一个参数化的注册装饰器
为了便于启用或禁用 register 执行的函数注册功能,我们为它提供一个可选的 active 参数,设为 False 时,不注册被装饰的函数
从概念上看,这个新的 register 函数不是装饰器,而是装饰器工厂函数。调用它会返回真正的装饰器,这才是应用到目标函数上的装饰器。
示例 7-23 为了接受参数,新的 register 装饰器必须作为函数调用
registry = set() #➊
def register(active=True): #➋
def decorate(func): #➌
print('running register(active=%s)->decorate(%s)'% (active, func))
if active: #➍
registry.add(func)
else:
registry.discard(func) #➎
return func #➏
return decorate #➐
@register(active=False) #➑
def f1():
print('running f1()')
@register() #➒
def f2():
print('running f2()')
def f3():
print('running f3()')
➊ registry 现在是一个 set 对象,这样添加和删除函数的速度更快。
➋ register 接受一个可选的关键字参数。
➌ decorate 这个内部函数是真正的装饰器;注意,它的参数是一个函数。
➍ 只有 active 参数的值(从闭包中获取)是 True 时才注册 func。
➎ 如果 active 不为真,而且 func 在 registry 中,那么把它删除。
➏ decorate 是装饰器,必须返回一个函数。
➐ register 是装饰器工厂函数,因此返回 decorate。然后把它应用到被装饰的函数上
➑ @register 工厂函数必须作为函数调用,并且传入所需的参数。
➒ 即使不传入参数,register 也必须作为函数调用(@register()),即要返回真正的装饰器 decorate
在终端下你可以测试出以下结果,假设文件是demo.py
>>> import demo
running register(active=False)->decorate(<function f1 at 0x000002860CF2CEE0>)
running register(active=True)->decorate(<function f2 at 0x000002860CF2CF70>)
>>> demo.registry
{<function f2 at 0x000002860CF2CF70>}
跟之前7.2说的一样导入的时候就会执行
只有 f2 函数在 registry 中;f1 不在其中,因为传给 register 装饰器工厂函数的参数是 active=False,所以应用到 f1 上的 decorate 没有把它添加到 registry 中
如果不使用 @ 句法,那就要像常规函数那样使用 register;若想把 f 添加到 registry中,则装饰 f 函数的句法是 register()(f);不想添加(或把它删除)的话,句法是register(active=False)(f)
上面这部分是关键
@clock
def fibonacci(n):
pass
你知道,fibonacci=clock(fibonacci)
那你现在要做的是
@clock(param='xxx')
def fibonacci(n):
pass
那自然fibonacci=clock(param='xxx')(fibonacci)
所以你应该定义一个
def clock(param='xxx'):
pass
而这个clock的返回需要是一个函数,参数应该是一个函数(比如fibonacci)
def clock(param='xxx'):
def decorate(func):
pass
decorate
书中还给你做了下如下测试
>>> from registration_param import * # 我上面的测试改了此处的名字 demo
running register(active=False)->decorate(<function f1 at 0x10073c1e0>)
running register(active=True)->decorate(<function f2 at 0x10073c268>)
>>> registry # ➊
{<function f2 at 0x10073c268>}
>>> register()(f3) # ➋
running register(active=True)->decorate(<function f3 at 0x10073c158>)
<function f3 at 0x10073c158>
>>> registry # ➌
{<function f3 at 0x10073c158>, <function f2 at 0x10073c268>}
>>> register(active=False)(f2) # ➍
running register(active=False)->decorate(<function f2 at 0x10073c268>)
<function f2 at 0x10073c268>
>>> registry # ➎
{<function f3 at 0x10073c158>}
➊ 导入这个模块时,f2 在 registry 中。
➋ register() 表达式返回 decorate,然后把它应用到 f3 上。
➌ 前一行把 f3 添加到 registry 中。
➍ 这次调用从 registry 中删除 f2。
➎ 确认 registry 中只有 f3。
7.10.2 参数化clock装饰器
上面的装饰器比较简单,但通常参数化装饰器的原理相当复杂,
参数化装饰器通常会把被装饰的函数替换掉,而且结构上需要多一层嵌套。
import time
DEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}'
def clock(fmt=DEFAULT_FMT): # ➊
def decorate(func): # ➋
def clocked(*_args): # ➌
t0 = time.time()
_result = func(*_args) # ➍
elapsed = time.time() - t0
name = func.__name__
args = ', '.join(repr(arg) for arg in _args) # ➎
result = repr(_result) # ➏
print(fmt.format(**locals())) # ➐
return _result # ➑
return clocked # ➒
return decorate # ➓
➊ clock 是参数化装饰器工厂函数。
➋ decorate 是真正的装饰器。
➌ clocked 包装被装饰的函数。
➍ _result 是被装饰的函数返回的真正结果。
➎ _args 是 clocked 的参数,args 是用于显示的字符串。
➏ result 是 _result 的字符串表示形式,用于显示。
➐ 这里使用**locals()是为了在 fmt 中引用 clocked 的局部变量。
➑ clocked 会取代被装饰的函数,因此它应该返回被装饰的函数返回的值。
➒ decorate 返回 clocked。
➓ clock 返回 decorate。在这个模块中测试,不传入参数调用 clock(),因此应用的装饰器使用默认的格式 str。应该是DEFAULT_FMT
**locals()** 函数会以字典类型返回当前位置的全部局部变量,配合fmt来用,还是挺巧妙的~
locals: {'_args': (0.123,), 't0': 1699234406.3928096, '_result': None, 'elapsed': 0.12681794166564941, 'name': 'snooze', 'args': '0.123', 'result': 'None', 'fmt': '[{elapsed:0.8f}s] {name}({args}) -> {result}', 'func': <function snooze at 0x0000026ED4107F70>}
DEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}' # 在上面也有
另外一点就是
参数化装饰器通常会把被装饰的函数替换掉,而且结构上需要多一层嵌套。
考虑上面的结构
def clock(fmt=DEFAULT_FMT):
def decorate(func):
def clocked(*_args):
...
return _result
return clocked
return decorate
@clock()
def snooze(seconds):
pass
结合万能公式
snooze=clock()(snooze) #注意此处的第一个()
snooze=decorate(snooze) # 转换下
snooze=clocked # 替换了
最终
for i in range(3):
snooze(.123)
就相当于
for i in range(3):
clocked(.123)
所以下面的几个测试结果
测试1
if __name__ == '__main__':
@clock()
def snooze(seconds):
time.sleep(seconds)
for i in range(3):
snooze(.123)
输出
[0.13555145s] snooze(0.123) -> None
[0.12589598s] snooze(0.123) -> None
[0.12798786s] snooze(0.123) -> None
测试2
if __name__ == '__main__':
@clock('{name}: {elapsed}s')
def snooze(seconds):
time.sleep(seconds)
for i in range(3):
snooze(.123)
输出
snooze: 0.12915396690368652s
snooze: 0.1259920597076416s
snooze: 0.1258389949798584s
测试3
if __name__ == '__main__':
@clock('{name}({args}) dt={elapsed:0.3f}s')
def snooze(seconds):
time.sleep(seconds)
for i in range(3):
snooze(.123)
输出
snooze(0.123) dt=0.126s
snooze(0.123) dt=0.126s
snooze(0.123) dt=0.126s
Graham Dumpleton 和 Lennart Regebro(本书的技术审校之一)认为,
装饰器最好通过实现 __call__ 方法的类实现,不应该像本章的示例那样通过函数实现
import time
DEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}'
class Clock:
def __init__(self,fmt=DEFAULT_FMT):
self.fmt = fmt
def __call__(self, func):
def clocked(*_args):
t0 = time.time()
_result = func(*_args)
elapsed = time.time() - t0
name = func.__name__
args = ', '.join(repr(arg) for arg in _args)
result = repr(_result)
#print('locals:',locals())
print(self.fmt.format(**locals()))
return _result
return clocked
if __name__ == '__main__':
@Clock()
def snooze(seconds):
time.sleep(seconds)
for i in range(3):
snooze(.123)
@Clock('{name}: {elapsed}s')
def snooze(seconds):
time.sleep(seconds)
for i in range(3):
snooze(.123)
@Clock('{name}({args}) dt={elapsed:0.3f}s')
def snooze(seconds):
time.sleep(seconds)
for i in range(3):
snooze(.123)
同样的推导
snooze=Clock()(snooze)
其中Clock()是个实例,假设为clock_instance
那clock_instance(snnoze)就是在调用__call__,返回的就是clocked,也发生了替换
从写法上更让清晰一些
7.11 本章小结
从本章开始进入元编程领域
开始,我们先编写了一个没有内部函数的 @register 装饰器;最后,我们实现了有两层嵌套函数的参数化装饰器 @clock()
参数化装饰器基本上都涉及至少两层嵌套函数,如果想使用 @functools.wraps 生成装饰器,为高级技术提供更好的支持,嵌套层级可能还会更深,比如前面简要介绍过的叠放装饰器
讨论了标准库中 functools 模块提供的两个出色的函数装饰器:@lru_cache() 和@singledispatch
若想真正理解装饰器,需要区分导入时和运行时,还要知道变量作用域、闭包和新增的nonlocal 声明。掌握闭包和 nonlocal 不仅对构建装饰器有帮助,还能协助你在构建 GUI程序时面向事件编程,或者使用回调处理异步 I/O
7.12 延伸阅读
| 素材 | URL | 相关信息 |
|---|---|---|
| Python Cookbook(第 3 版)中文版》第 9 章“元编程” | 有几个诀窍构建了基本的装饰器和特别复杂的装饰器 9.6 定义一个能接收可选参数的装饰器”一节中的装饰器可以作为常规的装饰器调用,也可以作为装饰器工厂函数调用,例如 @clock 或 @clock() |
|
| Graham Dumpleton 博 客 文 章 | https://github.com/GrahamDumpleton/wrapt/blob/develop/blog/README.md | 深入剖析了如何实现行为良好的装饰器 |
| How You Implemented Your Python Decorator is Wrong | https://github.com/GrahamDumpleton/wrapt/blob/develop/blog/01-how-you-implemented-your-python-decorator-is-wrong.md | |
| wrapt 模块 | http://wrapt.readthedocs.org/en/latest | 这个模块的作用是简化装饰器和动态函数包装器的实现,即使多层装饰也支持内省,而且行为正确,既可以应用到方法上,也可以作为描述符使用 |
| Michele Simionato的decorator包 | https://pypi.python.org/pypi/decorator | 简化普通程序员使用装饰器的方式,并且通过各种复杂的示例推广装饰器 |
| Python Decorator Library 维基页面 | https://wiki.python.org/moin/PythonDecoratorLibrary | 里面有很多示例 |
| PEP 443 | http://www.python.org/dev/peps/pep-0443 | 对单分派泛函数的基本原理和细节做了说明 |
| Five-Minute Multimethods in Python | http://www.artima.com/weblogs/viewpost.jsp?thread=101605 | 详细说明了如何使用装饰器实现泛函数(也叫多方法),他给出的代码支持多分派(即根据多个定位参数进行分派) |
| Martijn Faassen 开发的 Reg | http://reg.readthedocs.io/en/latest/ | 如果想使用现代 的技术实现多分派泛函数,并支持在生产环境中使用,可以用 它 |
| Fredrik Lundh 写的一篇短文Closures in Python | http://effbot.org/zone/closure.htm | 解说了闭包这个术语 |
| PEP 3104—Access to Names in Outer Scopes | http://www.python.org/dev/peps/pep-3104 | 说明了引入 nonlocal 声明的原因:重新绑定既不在本地作用域中也不在全局作用域中的名称。这份 PEP 还概述了其他动态语言(Perl、Ruby、JavaScript,等等)解决这个问题的方式,以及 Python 中可用设计方案的优缺点 |
| PEP 227—Statically Nested Scopes | http://www.python.org/dev/peps/pep-0227/ | 说明了 Python 2.1 引入的词法作用域;这份 PEP 还说明了 Python 中闭包的基本原理和实现方式的选择 |
杂谈
-
任何把函数当作一等对象的语言,它的设计者都要面对一个问题:作为一等对象的函数在某个作用域中定义,但是可能会在其他作用域中调用。问题是,如何计算自由变量?首先出现的最简单的处理方式是使用“动态作用域”。也就是说,根据函数调用所在的环境计算自由变量。
-
动态作用域易于实现,这可能就是 John McCarthy 创建 Lisp(第一门把函数视作一等对象的语言)时采用这种方式的原因
-
Python 函数装饰器符合 Gamma 等人在《设计模式:可复用面向对象软件的基础》一书中对“装饰器”模式的一般描述:“动态地给一个对象添加一些额外的职责。就扩展功能而言,装饰器模式比子类化更灵活。”
-
在设计模式中,Decorator 和 Component 是抽象类。为了给具体组件添加行为,具体装饰器的实例要包装具体组件的实例
-
装饰器与它所装饰的组件接口一致,因此它对使用该组件的客户透明。它将客户请求转发给该组件,并且可能在转发前后执行一些额外的操作(例如绘制一个边框)。透明性使得你可以递归嵌套多个装饰器,从而可以添加任意多的功能
-
一般来说,实现“装饰器”模式时最好使用类表示装饰器和要包装的组件
还有很多,不再一一罗列了啦,杂谈部分就当看Python历史了
关于装饰器的一个典型应用
引自 刘江的博客
有一个大公司,下属的基础平台部负责内部应用程序及API的开发。另外还有上百个业务部门负责不同的业务,这些业务部门各自调用基础平台部提供的不同函数,也就是API处理自己的业务,情况如下:
# 基础平台部门开发了上百个函数API
def f1():
print("业务部门1的数据接口......")
def f2():
print("业务部门2的数据接口......")
def f3():
print("业务部门3的数据接口......")
def f100():
print("业务部门100的数据接口......")
#各部门分别调用自己需要的API
f1()
f2()
f3()
f100()
公司还在创业初期时,基础平台部就开发了这些函数。由于各种原因,比如时间紧,比如人手不足,比如架构缺陷,比如考虑不周等等,没有为函数的调用进行安全认证。现在,公司发展壮大了,不能再像初创时期的“草台班子”一样将就下去了,基础平台部主管决定弥补这个缺陷,于是(以下场景纯属虚构,调侃之言,切勿对号入座):
第一天:主管叫来了一个运维工程师,工程师跑上跑下逐个部门进行通知,让他们在代码里加上认证功能,然后,当天他被开除了。
第二天:主管又叫来了一个运维工程师,工程师用shell写了个复杂的脚本,勉强实现了功能。但他很快就回去接着做运维了,不会开发的运维不是好运维....
第三天:主管叫来了一个python自动化开发工程师。哥们是这么干的,只对基础平台的代码进行重构,让N个业务部门无需做任何修改。这哥们很快也被开了,连运维也没得做。
def f1():
#加入认证程序代码
print("业务部门1数据接口......")
def f2():
# 加入认证程序代码
print("业务部门2数据接口......")
def f3():
# 加入认证程序代码
print("业务部门3数据接口......")
def f100():
#加入认证程序代码
print("业务部门100数据接口......")
#各部门分别调用
f1()
f2()
f3()
f100()
第四天:主管又换了个开发工程师。他是这么干的:定义个认证函数,在原来其他的函数中调用它,代码如下。
def login():
print("认证成功!")
def f1():
login()
print("业务部门1数据接口......")
def f2():
login()
print("业务部门2数据接口......")
def f3():
login()
print("业务部门3数据接口......")
def f100():
login()
print("业务部门100数据接口......")
#各部门分别调用
f1()
f2()
f3()
f100()
但是主管依然不满意,不过这一次他解释了为什么。主管说:写代码要遵循开放封闭原则,简单来说,已经实现的功能代码内部不允许被修改,但外部可以被扩展。如果将开放封闭原则应用在上面的需求中,那么就是不允许在函数f1 、f2、f3......f100的内部进行代码修改,但是可以在外部对它们进行扩展。
第五天:已经没有时间让主管找别人来干这活了,他决定亲自上阵,使用装饰器完成这一任务,并且打算在函数执行后再增加个日志功能。主管的代码如下:
def outer(func):
def inner():
print("认证成功!")
result = func()
print("日志添加成功")
return result
return inner
@outer
def f1():
print("业务部门1数据接口......")
@outer
def f2():
print("业务部门2数据接口......")
@outer
def f3():
print("业务部门3数据接口......")
@outer
def f100():
print("业务部门100数据接口......")
#各部门分别调用
f1()
f2()
f3()
f100()
使用装饰器@outer,也是仅需对基础平台的代码进行拓展,就可以实现在其他部门调用函数API之前都进行认证操作,在操作结束后保存日志,并且其他业务部门无需对他们自己的代码做任何修改,调用方式也不用变