一、Batch Normalization
如果设定了合适的权重初始值,则各层的激活值分布会有适当的广度,从而可以顺利地进行学习。
为了使各层拥有适当的广度(激活值分布不能太广,易饱和),Batch Normalization 试图在学习过程中“强制性”地调整激活值的分布会怎样呢?缓解内部协变量偏移。
直观地说,机器学习就是要拟合数据的分布。在训练过程中,神经网络参数不断更新,导数中间层的数据分布频繁地变化。
- 每层的参数需不断适应新的输入数据分布,降低学习速度,增大学习的难度(层数多)
- 输入可能趋向于变大或者变小(分布变广),导致激活值落入饱和区,阻碍学习
为了提高优化效率(最开始的动机是缓解内部协变量偏移,但后来的研究者发现其主要优点是归一化会导致更平滑的优化地形),就要使得净输入? (?) 的分布一致,比如都标准化。类似于归一化对sgd的影响
BN优点(稳定学习过程)
- 可以使学习快速进行(可以增大学习率)。
- 不那么依赖参数初始值。
- 抑制过拟合(降低Dropout等的必要性)。
Batch Norm的思路是调整各层的激活值分布使其拥有适当的广度。为此,要向神经网络中插入对数据分布进行归一化的层,即BatchNormalization层(下文简称Batch Norm层)。
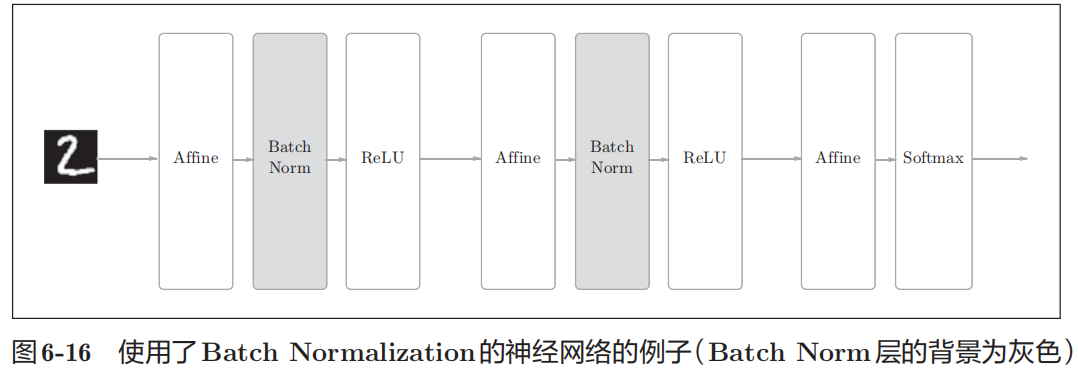
Batch Norm,顾名思义,以进行学习时的mini-batch为单位,按mini-batch进行正规化。具体而言,就是进行使数据分布的均值为0、方差为1的标准化。

伪代码
if self.training: mean = input.mean([0, 2, 3]) # 计算当前 batch 的均值 var = input.var([0, 2, 3], unbiased=False) # 计算当前 batch 的方差 n = input.numel() / input.size(1) with torch.no_grad(): # 使用移动平均更新对数据集均值的估算 self.running_mean = exponential_average_factor * mean\ + (1 - exponential_average_factor) * self.running_mean # 使用移动平均更新对数据集方差的估算 self.running_var = exponential_average_factor * var * n / (n - 1)\ + (1 - exponential_average_factor) * self.running_var else: mean = self.running_mean var = self.running_var # 使用均值和方差将每个元素标准化 input = (input - mean[None, :, None, None]) / (torch.sqrt(var[None, :, None, None] + self.eps)) # 对标准化的结果进行缩放(可选) if self.affine: input = input * self.weight[None, :, None, None] + self.bias[None, :, None, None]

均值和标准差是在mini-batches的每一个特征(通道)维度上计算的
γ and β 是维度为C的可学习参数向量 (C是输入的特征数或通道数).
m = nn.BatchNorm1d(100) # With Learnable Parameters m = nn.BatchNorm1d(100, affine=False) # Without Learnable Parameters input = torch.randn(20, 100) output = m(input)
Batch Norm层会对标准化后的数据进行缩放和平移的变换(对净输入?(?) 的标准归一化会使得其取值集中到 0 附近,如果使用 Sigmoid型激活函数时,这个取值区间刚好是接近线性变换的区间,减弱了神经网络的非线性-降低表达能力)。
为了使得标准化不削弱网络的表示能力(有可能降低神经网络的非线性表达能力),可通过一个附加的缩放和平移变换改变取值区间,从而补偿标准化后神经网络的表达力:
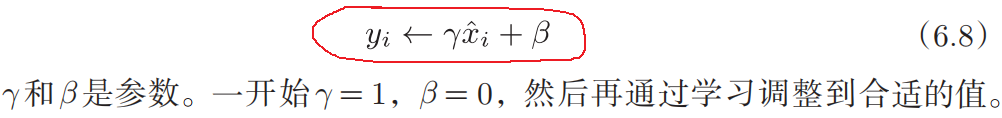
从最保守的角度,可通过标准化的逆变换来使得标准化后的变量可被还原为原始值。
通过将BN插入到激活函数的前面(或者后面),可以减小数据分布的偏向。
在测试阶段,将使用训练时收集的均值和方差来进行推断。
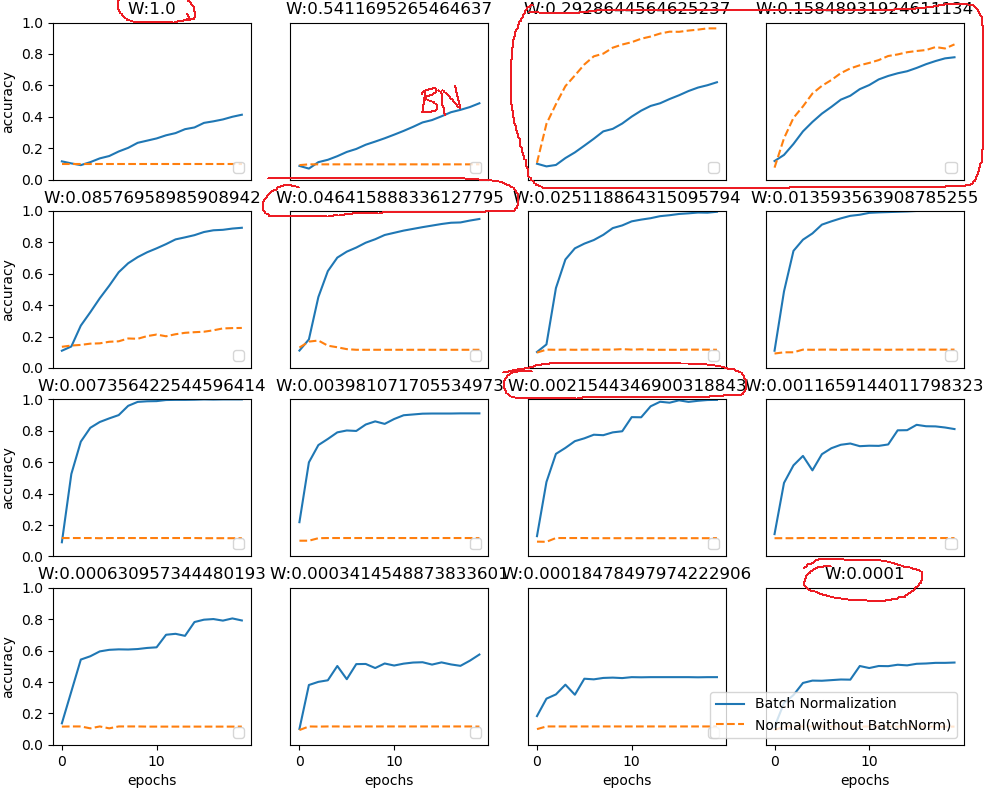
使用Batch Norm后,学习进行得更快了。
接着,给予不同的初始值尺度,观察学习的过程如何变化。几乎所有的情况下都是使用Batch Norm时学习进行得更快 (对参数初始值不敏感)。同时也可以发现,实际上,在不使用Batch Norm的情况下,如果不赋予一个尺度好的初始值(方差),学习将完全无法进行。
逐层归一化不但可以提高优化效率,还可以作为一种隐形的正则化方法。在因为训练时,它使得神经网络对一个样本的预测不仅和该样本自身相关,也和同一批次中的其他样本相关。
解释: 由于在选取批次时具有随机性,因此使得神经网络不会“过拟合”到某个特定样本,从而提高网络的泛化能力。
深入理解Pytorch的BatchNorm操作(含部分源码)
BN究竟起了什么作用?一个闭门造车的分析